DataWhale一周算法实践3---模型评估(accuracy、precision,recall和F-measure、auc值)
文章目录
- 1 参数详解
- 1.1 accuracy
- 1.2 precision
- 1.3 recall
- 1.4 F1-measure
- 1.5 auc值&roc曲线 TODO
- 2 基于本次项目对6个评分参数的理解
- 3 对于7个模型的6个参数的计算
- 3.1 逻辑回归
- 3.2 SVM
- 3.3 决策树
- 3.4 随机森林
- 3.5 GBDT
- 3.6 XGBoost
- 3.7 lightGBM
- 4 思考
1 参数详解
我们在在分类任务时,经常会对模型结果进行评估。评估模型好坏的指标有AUC、KS值等等。这些指标是通过预测概率进行计算的。而准确率、精准率和召回率也通过混淆矩阵计算出来的。
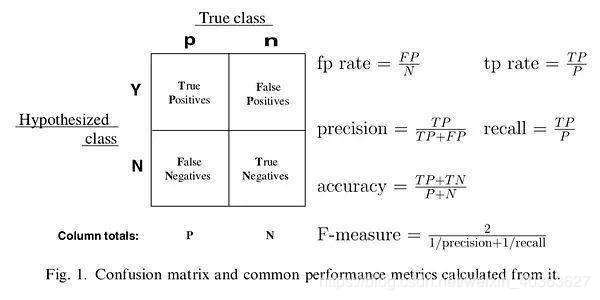
TP:样本为正,预测结果为正;
FP:样本为负,预测结果为正;
TN:样本为负,预测结果为负;
FN:样本为正,预测结果为负。
1.1 accuracy
准确率(accuracy):又称精度。其含义是对于给定的测试数据集,分类器正确分类的样本数与总样本数之比。精度(accuracy) = 1-错误率(error rate)
准确率(accuracy): (TP + TN )/( TP + FP + TN + FN)
准确率(accuracy)并不总是能有效的评价一个分类器的工作
举个例子,google抓取 了argcv 100个页面,而它索引中共有10,000,000个页面,随机抽一个页面,分类下,这是不是argcv的页面呢?如果以accuracy来判断我的工 作,那我会把所有的页面都判断为"不是argcv的页面",因为我这样效率非常高(return false,一句话),而accuracy已经到了99.999%(9,999,900/10,000,000),完爆其它很多分类器辛辛苦苦算的值,而我这个算法显然不是需求期待的,那怎么解决呢?这就是precision,recall和f1-measure出场的时间了.
1.2 precision
精准率(precision):它计算的是所有"正确被检索的item(TP)"占所有"实际被检索到的(TP+FP)"的比例
精准率(precision):TP / (TP + FP)
1.3 recall
召回率(recall):它计算的是所有"正确被检索的item(TP)"占所有"应该检索到的item(TP+FN)"的比例
召回率(recall): TP / (TP + FN)
1.4 F1-measure
F-measure:2(1/precision)+(1/recall)即调和均值的2倍
why use F-measure
精准率的分母为预测为正的样本数,召回率的分母为原来样本中所有的正样本数。
我们当然希望精准率和召回率都高,但是现实情况一般不是这样。
所以说precision和recall并不是正相关,有些时候可能还是矛盾的。所以F-measure应该是精准率和召回率之间的一个平衡点。
1.5 auc值&roc曲线 TODO
AUC(Area Under roc Curve):是评价分类器的指标.
ROC(Receiver Operating Characteristic):也是评价分类器的指标
ROC关注两个指标:
True Positive Rate ( TPR ) = TP / [ TP + FN] ,TPR代表能将正例分对的概率
False Positive Rate( FPR ) = FP / [ FP + TN] ,FPR代表将负例错分为正例的概率
用ROC curve来表示分类器的performance很直观好用。可是,人们总是希望能有一个数值来标志分类器的好坏。
AUC的值就是处于ROC curve下方的那部分面积的大小。通常,AUC的值介于0.5到1.0之间,较大的AUC代表了较好的Performance
reference:https://www.cnblogs.com/sddai/p/5696870.html
2 基于本次项目对6个评分参数的理解
accuracy预测贷款是否会逾期分类正确的占总样本数。
precision预测贷款会逾期的占实际被分类器分到的会逾期的。
recall预测贷款会逾期的占实际应该贷款会逾期的
3 对于7个模型的6个参数的计算
3.1 逻辑回归
log_model = LogisticRegression(random_state =2018)
log_model.fit(X_train_stand, y_train)
y_train_pred = log_model.predict(X_train_stand)
y_test_pred = log_model.predict(X_test_stand)
# accuracy
train_accuracy = metrics.accuracy_score(y_train, y_train_pred)
test_accuracy = metrics.accuracy_score(y_test, y_test_pred)
print("训练集准确率:"+ str(train_accuracy) + "测试集准确率"+ str(test_accuracy))
# precision
train_precision = metrics.precision_score(y_train, y_train_pred, average='micro')
test_precision = metrics.precision_score(y_test, y_test_pred, average='micro')
print("训练集精准率:"+ str(train_precision) + "测试集精准率"+ str(test_precision))
# recall
train_recall = metrics.recall_score(y_train, y_train_pred, average='micro')
test_recall = metrics.recall_score(y_test, y_test_pred, average='micro')
print("训练集召回率:"+ str(train_recall) + "测试集召回率"+ str(test_recall))
# F1-score
train_F1score = metrics.f1_score(y_train, y_train_pred, average='micro')
test_F1score = metrics.f1_score(y_test, y_test_pred, average='micro')
print("训练集F1-score:"+ str(train_F1score) + "测试集F1-score"+ str(test_F1score))
# auc值
train_auc = metrics.roc_auc_score(y_train, y_train_pred)
test_auc = metrics.roc_auc_score(y_test, y_test_pred)
print("训练集auc值:"+ str(train_auc) + "测试集auc值"+ str(test_auc))
# roc曲线
train_fprs,train_tprs,train_thresholds = metrics.roc_curve(y_train, y_train_pred)
test_fprs,test_tprs,test_thresholds = metrics.roc_curve(y_test, y_test_pred)
plt.plot(train_fprs, train_tprs)
plt.plot(test_fprs, test_tprs)
plt.plot([0,1], [0,1],"--")
plt.title("ROC curve")
plt.xlabel("FPR")
plt.ylabel("TPR")
plt.legend(labels=["Train AUC:"+str(round(train_auc, 5)),"Test AUC:"+str(round(test_auc,5))], loc="lower right")
plt.show()
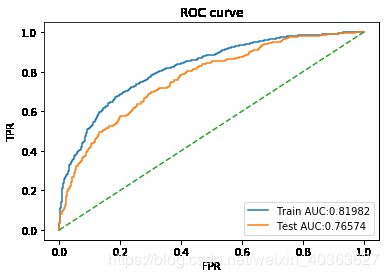
训练集准确率:0.8049293657950105测试集准确率0.7876664330763841
训练集精准率:0.7069351230425056测试集精准率0.6609195402298851
训练集召回率:0.37889688249400477测试集召回率0.3203342618384401
训练集F1-score:0.4933645589383294测试集F1-score0.4315196998123827
训练集auc值:0.819823563531846测试集auc值0.7657428562486308
3.2 SVM
svc=SVC(random_state =2018,probability=True)
svc.fit(X_train_stand, y_train)
y_train_pred = svc.predict(X_train_stand)
y_test_pred = svc.predict(X_test_stand)
y_train_proba = (svc.predict_proba(X_train_stand))[:, 1]
y_test_proba = (svc.predict_proba(X_test_stand))[:, 1]
# accuracy
train_accuracy = metrics.accuracy_score(y_train, y_train_pred)
test_accuracy = metrics.accuracy_score(y_test, y_test_pred)
print("训练集准确率:"+ str(train_accuracy) + "测试集准确率"+ str(test_accuracy))
# precision
train_precision = metrics.precision_score(y_train, y_train_pred)
test_precision = metrics.precision_score(y_test, y_test_pred)
print("训练集精准率:"+ str(train_precision) + "测试集精准率"+ str(test_precision))
# recall
train_recall = metrics.recall_score(y_train, y_train_pred)
test_recall = metrics.recall_score(y_test, y_test_pred)
print("训练集召回率:"+ str(train_recall) + "测试集召回率"+ str(test_recall))
# F1-score
train_F1score = metrics.f1_score(y_train, y_train_pred)
test_F1score = metrics.f1_score(y_test, y_test_pred)
print("训练集F1-score:"+ str(train_F1score) + "测试集F1-score"+ str(test_F1score))
# auc值
train_auc = metrics.roc_auc_score(y_train, y_train_proba)
test_auc = metrics.roc_auc_score(y_test, y_test_proba)
print("训练集auc值:"+ str(train_auc) + "测试集auc值"+ str(test_auc))
# roc曲线
train_fprs,train_tprs,train_thresholds = metrics.roc_curve(y_train, y_train_proba)
test_fprs,test_tprs,test_thresholds = metrics.roc_curve(y_test, y_test_proba)
plt.plot(train_fprs, train_tprs)
plt.plot(test_fprs, test_tprs)
plt.plot([0,1], [0,1],"--")
plt.title("ROC curve")
plt.xlabel("FPR")
plt.ylabel("TPR")
plt.legend(labels=["Train AUC:"+str(round(train_auc, 5)),"Test AUC:"+str(round(test_auc,5))], loc="lower right")
plt.show()
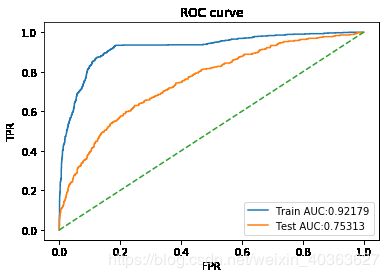
训练集准确率:0.8428013225127743测试集准确率0.7806587245970568
训练集精准率:0.9146666666666666测试集精准率0.7017543859649122
训练集召回率:0.41127098321342925测试集召回率0.22284122562674094
训练集F1-score:0.5674110835401158测试集F1-score0.3382663847780127
训练集auc值:0.9217853154299663测试集auc值0.7531297924947575
3.3 决策树
tre = DecisionTreeClassifier(random_state =2018)
tre.fit(X_train_stand, y_train)
y_train_pred = tre.predict(X_train_stand)
y_test_pred = tre.predict(X_test_stand)
y_train_proba = (tre.predict_proba(X_train_stand))[:, 1]
y_test_proba = (tre.predict_proba(X_test_stand))[:, 1]
# accuracy
train_accuracy = metrics.accuracy_score(y_train, y_train_pred)
test_accuracy = metrics.accuracy_score(y_test, y_test_pred)
print("训练集准确率:"+ str(train_accuracy) + "测试集准确率"+ str(test_accuracy))
# precision
train_precision = metrics.precision_score(y_train, y_train_pred)
test_precision = metrics.precision_score(y_test, y_test_pred)
print("训练集精准率:"+ str(train_precision) + "测试集精准率"+ str(test_precision))
# recall
train_recall = metrics.recall_score(y_train, y_train_pred)
test_recall = metrics.recall_score(y_test, y_test_pred)
print("训练集召回率:"+ str(train_recall) + "测试集召回率"+ str(test_recall))
# F1-score
train_F1score = metrics.f1_score(y_train, y_train_pred)
test_F1score = metrics.f1_score(y_test, y_test_pred)
print("训练集F1-score:"+ str(train_F1score) + "测试集F1-score"+ str(test_F1score))
# auc值
train_auc = metrics.roc_auc_score(y_train, y_train_proba)
test_auc = metrics.roc_auc_score(y_test, y_test_proba)
print("训练集auc值:"+ str(train_auc) + "测试集auc值"+ str(test_auc))
# roc曲线
train_fprs,train_tprs,train_thresholds = metrics.roc_curve(y_train, y_train_proba)
test_fprs,test_tprs,test_thresholds = metrics.roc_curve(y_test, y_test_proba)
plt.plot(train_fprs, train_tprs)
plt.plot(test_fprs, test_tprs)
plt.plot([0,1], [0,1],"--")
plt.title("ROC curve")
plt.xlabel("FPR")
plt.ylabel("TPR")
plt.legend(labels=["Train AUC:"+str(round(train_auc, 5)),"Test AUC:"+str(round(test_auc,5))], loc="lower right")
plt.show()
训练集准确率:1.0测试集准确率0.6860546601261388
训练集精准率:1.0测试集精准率0.3850129198966408
训练集召回率:1.0测试集召回率0.415041782729805
训练集F1-score:1.0测试集F1-score0.39946380697050937
训练集auc值:1.0测试集auc值0.5960976703911197

3.4 随机森林
rf = RandomForestClassifier(n_estimators=50,max_features=0.2,random_state =2018)
rf.fit(X_train_stand, y_train)
y_train_pred = rf.predict(X_train_stand)
y_test_pred = rf.predict(X_test_stand)
y_train_proba = (rf.predict_proba(X_train_stand))[:, 1]
y_test_proba = (rf.predict_proba(X_test_stand))[:, 1]
# accuracy
train_accuracy = metrics.accuracy_score(y_train, y_train_pred)
test_accuracy = metrics.accuracy_score(y_test, y_test_pred)
print("训练集准确率:"+ str(train_accuracy) + "测试集准确率"+ str(test_accuracy))
# precision
train_precision = metrics.precision_score(y_train, y_train_pred)
test_precision = metrics.precision_score(y_test, y_test_pred)
print("训练集精准率:"+ str(train_precision) + "测试集精准率"+ str(test_precision))
# recall
train_recall = metrics.recall_score(y_train, y_train_pred)
test_recall = metrics.recall_score(y_test, y_test_pred)
print("训练集召回率:"+ str(train_recall) + "测试集召回率"+ str(test_recall))
# F1-score
train_F1score = metrics.f1_score(y_train, y_train_pred)
test_F1score = metrics.f1_score(y_test, y_test_pred)
print("训练集F1-score:"+ str(train_F1score) + "测试集F1-score"+ str(test_F1score))
# auc值
train_auc = metrics.roc_auc_score(y_train, y_train_proba)
test_auc = metrics.roc_auc_score(y_test, y_test_proba)
print("训练集auc值:"+ str(train_auc) + "测试集auc值"+ str(test_auc))
# roc曲线
train_fprs,train_tprs,train_thresholds = metrics.roc_curve(y_train, y_train_proba)
test_fprs,test_tprs,test_thresholds = metrics.roc_curve(y_test, y_test_proba)
plt.plot(train_fprs, train_tprs)
plt.plot(test_fprs, test_tprs)
plt.plot([0,1], [0,1],"--")
plt.title("ROC curve")
plt.xlabel("FPR")
plt.ylabel("TPR")
plt.legend(labels=["Train AUC:"+str(round(train_auc, 5)),"Test AUC:"+str(round(test_auc,5))], loc="lower right")
plt.show()
训练集准确率:0.9996994289149383测试集准确率0.7785564120532585
训练集精准率:1.0测试集精准率0.6287425149700598
训练集召回率:0.9988009592326139测试集召回率0.2924791086350975
训练集F1-score:0.9994001199760048测试集F1-score0.39923954372623577
训练集auc值:0.9999995190369967测试集auc值0.7512101864313062

3.5 GBDT
model= GradientBoostingClassifier(learning_rate=1.0, random_state=2018)
model.fit(X_train_stand, y_train)
y_train_pred = model.predict(X_train_stand)
y_test_pred = model.predict(X_test_stand)
y_train_proba = (model.predict_proba(X_train_stand))[:, 1]
y_test_proba = (model.predict_proba(X_test_stand))[:, 1]
# accuracy
train_accuracy = metrics.accuracy_score(y_train, y_train_pred)
test_accuracy = metrics.accuracy_score(y_test, y_test_pred)
print("训练集准确率:"+ str(train_accuracy) + "测试集准确率"+ str(test_accuracy))
# precision
train_precision = metrics.precision_score(y_train, y_train_pred, average='micro')
test_precision = metrics.precision_score(y_test, y_test_pred, average='micro')
print("训练集精准率:"+ str(train_precision) + "测试集精准率"+ str(test_precision))
# recall
train_recall = metrics.recall_score(y_train, y_train_pred, average='micro')
test_recall = metrics.recall_score(y_test, y_test_pred, average='micro')
print("训练集召回率:"+ str(train_recall) + "测试集召回率"+ str(test_recall))
# F1-score
train_F1score = metrics.f1_score(y_train, y_train_pred, average='micro')
test_F1score = metrics.f1_score(y_test, y_test_pred, average='micro')
print("训练集F1-score:"+ str(train_F1score) + "测试集F1-score"+ str(test_F1score))
# auc值
train_auc = metrics.roc_auc_score(y_train, y_train_proba)
test_auc = metrics.roc_auc_score(y_test, y_test_proba)
print("训练集auc值:"+ str(train_auc) + "测试集auc值"+ str(test_auc))
# roc曲线
train_fprs,train_tprs,train_thresholds = metrics.roc_curve(y_train, y_train_proba)
test_fprs,test_tprs,test_thresholds = metrics.roc_curve(y_test, y_test_proba)
plt.plot(train_fprs, train_tprs)
plt.plot(test_fprs, test_tprs)
plt.plot([0,1], [0,1],"--")
plt.title("ROC curve")
plt.xlabel("FPR")
plt.ylabel("TPR")
plt.legend(labels=["Train AUC:"+str(round(train_auc, 5)),"Test AUC:"+str(round(test_auc,5))], loc="lower right")
plt.show()
训练集准确率:0.9933874361286444测试集准确率0.7351086194814296
训练集精准率:0.9933874361286444测试集精准率0.7351086194814296
训练集召回率:0.9933874361286444测试集召回率0.7351086194814296
训练集F1-score:0.9933874361286444测试集F1-score0.7351086194814296
训练集auc值:0.9995921433731475测试集auc值0.7147324549049064

3.6 XGBoost
xgb_model = XGBClassifier()
xgb_model.fit(X_train_stand, y_train)
y_train_pred = xgb_model.predict(X_train_stand)
y_test_pred = xgb_model.predict(X_test_stand)
# accuracy
train_accuracy = metrics.accuracy_score(y_train, y_train_pred)
test_accuracy = metrics.accuracy_score(y_test, y_test_pred)
print("训练集准确率:"+ str(train_accuracy) + "测试集准确率"+ str(test_accuracy))
# precision
train_precision = metrics.precision_score(y_train, y_train_pred, average='micro')
test_precision = metrics.precision_score(y_test, y_test_pred, average='micro')
print("训练集精准率:"+ str(train_precision) + "测试集精准率"+ str(test_precision))
# recall
train_recall = metrics.recall_score(y_train, y_train_pred, average='micro')
test_recall = metrics.recall_score(y_test, y_test_pred, average='micro')
print("训练集召回率:"+ str(train_recall) + "测试集召回率"+ str(test_recall))
# F1-score
train_F1score = metrics.f1_score(y_train, y_train_pred, average='micro')
test_F1score = metrics.f1_score(y_test, y_test_pred, average='micro')
print("训练集F1-score:"+ str(train_F1score) + "测试集F1-score"+ str(test_F1score))
# auc值
train_auc = metrics.roc_auc_score(y_train, y_train_pred)
test_auc = metrics.roc_auc_score(y_test, y_test_pred)
print("训练集auc值:"+ str(train_auc) + "测试集auc值"+ str(test_auc))
# roc曲线
train_fprs,train_tprs,train_thresholds = metrics.roc_curve(y_train, y_train_pred)
test_fprs,test_tprs,test_thresholds = metrics.roc_curve(y_test, y_test_pred)
plt.plot(train_fprs, train_tprs)
plt.plot(test_fprs, test_tprs)
plt.plot([0,1], [0,1],"--")
plt.title("ROC curve")
plt.xlabel("FPR")
plt.ylabel("TPR")
plt.legend(labels=["Train AUC:"+str(round(train_auc, 5)),"Test AUC:"+str(round(test_auc,5))], loc="lower right")
plt.show()
训练集准确率:0.8539224526600541测试集准确率0.7841625788367204
训练集精准率:0.8539224526600541测试集精准率0.7841625788367204
训练集召回率:0.8539224526600541测试集召回率0.7841625788367204
训练集F1-score:0.8539224526600541测试集F1-score0.7841625788367204
训练集auc值:0.9174710772897927测试集auc值0.7708522424963224
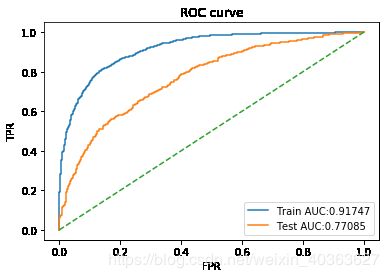
3.7 lightGBM
lgb_model = LGBMClassifier()
lgb_model.fit(X_train_stand, y_train)
y_train_pred = lgb_model.predict(X_train_stand)
y_test_pred = lgb_model.predict(X_test_stand)
# accuracy
train_accuracy = metrics.accuracy_score(y_train, y_train_pred)
test_accuracy = metrics.accuracy_score(y_test, y_test_pred)
print("训练集准确率:"+ str(train_accuracy) + "测试集准确率"+ str(test_accuracy))
# precision
train_precision = metrics.precision_score(y_train, y_train_pred, average='micro')
test_precision = metrics.precision_score(y_test, y_test_pred, average='micro')
print("训练集精准率:"+ str(train_precision) + "测试集精准率"+ str(test_precision))
# recall
train_recall = metrics.recall_score(y_train, y_train_pred, average='micro')
test_recall = metrics.recall_score(y_test, y_test_pred, average='micro')
print("训练集召回率:"+ str(train_recall) + "测试集召回率"+ str(test_recall))
# F1-score
train_F1score = metrics.f1_score(y_train, y_train_pred, average='micro')
test_F1score = metrics.f1_score(y_test, y_test_pred, average='micro')
print("训练集F1-score:"+ str(train_F1score) + "测试集F1-score"+ str(test_F1score))
# auc值
train_auc = metrics.roc_auc_score(y_train, y_train_pred)
test_auc = metrics.roc_auc_score(y_test, y_test_pred)
print("训练集auc值:"+ str(train_auc) + "测试集auc值"+ str(test_auc))
# roc曲线
train_fprs,train_tprs,train_thresholds = metrics.roc_curve(y_train, y_train_pred)
test_fprs,test_tprs,test_thresholds = metrics.roc_curve(y_test, y_test_pred)
plt.plot(train_fprs, train_tprs)
plt.plot(test_fprs, test_tprs)
plt.plot([0,1], [0,1],"--")
plt.title("ROC curve")
plt.xlabel("FPR")
plt.ylabel("TPR")
plt.legend(labels=["Train AUC:"+str(round(train_auc, 5)),"Test AUC:"+str(round(test_auc,5))], loc="lower right")
plt.show()
lightGBM kernel error
| Classification Scoring | Function | Comment |
|---|---|---|
| accuracy | metrics.accuracy_score | |
| f1 | metrics.f1_score | for binary targets |
| precision | metrics.precision_score | suffixes apply as with ‘f1’ |
| recall | metrics.recall_score | suffixes apply as with ‘f1’ |
| auc/roc | metrics.roc_auc_score |
reference:https://blog.csdn.net/shine19930820/article/details/78335550
https://scikit-learn.org/stable/modules/classes.html#sklearn-metrics-metrics
4 思考
1.归一化的scaler.fit和scaler.transform?
2.评估分数关于训练集和测试集的分数?
3.decision_function & predict_proba?
4.每个模型的accuracy、precision,recall和F1-score值都是一样的?
刚刚测试了一下 如果将设定的参数average='micro’去掉的话,每个值就不一样了。
5.roc曲线?
ROC曲线并不是根据roc_curve(y_train, y_train_pred)而是roc_curve(y_train, y_train_proba)
其中y_train_pred是由predict函数得出的。predict返回的是一个大小为n的一维数组,一维数组中的第i个值为模型预测第i个预测样本的标签
而y_train_proba由predict_proba得到的。predict_proba返回的是一个n行k列的数组,第i行第j列上的数值是模型预测第i个预测样本的标签为j的概率。此时每一行的和应该等于1。