数据挖掘——常用数据预处理
0、读写数据
(1)读取txt文件
#读取txt并拼接data
import pandas as pd
data=pd.read_table('1.txt', delimiter=',',dtype={'id':'int32','index':'int8'})
all=data.merge(data2,on='id',how='left').merge(data3,on=['id','index'],how='left')
(2)读取和保存list文件
注意:list若存储在txt中,需转化为str,读取时也是str。为了防止破坏list结构,可以转化为np.array存储
#存
import numpy as np
a=np.array(test_courier_ids)
np.save('test_courier_ids.npy',a)
#读取
a=np.load('test_courier_ids.npy')
test_courier_ids=a.tolist() (3) 保存dataframe到csv
#dataframe保存为csv文件
data.to_csv(path_or_buf="data.csv", index=False) 1、排序
DataFrame.sort_values(by=‘##’,axis=0,ascending=True, inplace=False, na_position=‘last’)
参数 说明
by 指定列名(axis=0或’index’)或索引值(axis=1或’columns’)
axis 若axis=0或’index’,则按照指定列中数据大小排序;若axis=1或’columns’,则按照指定索引中数据大小排序,默认axis=0
ascending 是否按指定列的数组升序排列,默认为True,即升序排列
inplace 是否用排序后的数据集替换原来的数据,默认为False,即不替换
na_position {‘first’,‘last’},设定缺失值的显示位置
2、对dataframe append新的一列或一行
import pandas as pd
data = pd.DataFrame()
a = {"x":1,"y":2}#一行
data = data.append(a,ignore_index=True)
print(data)
a = [[1,2,3],[4,5,6]]#两列
data = data.append(a,ignore_index=True)
a = [[7,8,9],[10,11,12]]
data = data.append(a,ignore_index=True)
print(data)
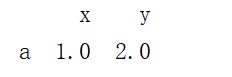

3、对数据拼接组合:merge 和join
注意:join只能用于行数一样的(根据行索引进行合并)
参考:https://blog.csdn.net/winnertakeall/article/details/86662669
4、分组内排序
df.groupby('B', group_keys=False).apply(lambda x: x.sort_values('C', ascending=False))
[Out] A B C
3 4 a 201003
0 2 a 200801
1 3 b 200902
2 5 b 200704
5、初始化新的一列
这一列全部赋值:
day1_all_train_data['date']='0201'用lamada判断条件赋值:lamada(表达式 if 条件 else (表达式 if 条件 else(…………)))
sourcedf['地区']=sourcedf['exam_district'].apply(lambda x:"全国" if x==1 else ("北京" if x==3 else("上海" if x==24 else "其他地区")) )6、pandas DataFrame中列太多,输出显示省略号
解决办法:设置最多显示的列数
pd.set_option('display.max_columns',20)
同理,可以设置显示多少行:
pd.set_option('display.max_rows',10)
7、对某一列进行编码
硬编码:1,2,3,4,5....
label = preprocessing.LabelEncoder()
data_raw[x] = label.fit_transform(data_raw[x])
#将feature的值从0(或者1)开始进行连续编码,比如color进行硬编码,color的值有三个,分别为编码为1,2,3
colorMap = {elem:index+1 for index,elem in enumerate(set(df["color"]))}
df['color'] = df['color'].map(colorMap)
onehot: 001 010 100
#将某个字段下所有值横向展开,对于每条数据,其在对应展开的值上的值就是1
data1 = pd.get_dummies(df[["color"]])
#对多个feature 进行onehot:
df[[fea1,fea2..]]
#onehot以后的数据,如果需要原有的数据合并,直接join onehot的数据即可
res = df.join(data1)
8、实现Unix时间戳(Unix timestamp) 和 普通时间转换
http://tool.chinaz.com/Tools/unixtime.aspx
9、pandas: 根据一列的条件来替换另一列的值
#当条件>0.99时,old的值替换成对应new的值
df['old'] = df['old'].mask(df['条件'] > 0.99, df['new'])https://blog.csdn.net/mym_74/article/details/102887459
10、强制类型转换
df[' Min Humidity']=df[' Min Humidity'].astype('float64')
df=df.astype({'Max Humidity':'float64','Max Dew PointF':'float64'})
11、经纬度geohash
https://www.jianshu.com/p/2fd0cf12e5ba
https://blog.csdn.net/wangyaninglm/article/details/78936475#31_python3__geohash_522
12、判断key是否存在于字典中
d = {'name':{},'age':{},'sex':{}}
#d.keys()是列出字典所有的key
print name in d.keys()
print name not in d.keys()
#结果返回True、False