Python 基础打卡5
Python 基础打卡5
- 1.file
- a.打开文件方式(读写两种方式)
- b.文件对象的操作方法
- c.学习对excel及csv文件进行操作
- csv文件操作
- Excel文件操作
- 2.os模块
- 3.datetime模块
- 4.类和对象
- 5.正则表达式
- 6.re模块
- 7.http请求
参考: https://blog.csdn.net/weixin_33705053/article/details/87209036
https://blog.csdn.net/hxy199421/article/details/81033229
https://blog.csdn.net/colourful_sky/article/details/80160340
https://www.liaoxuefeng.com/wiki/0014316089557264a6b348958f449949df42a6d3a2e542c000
1.file
a.打开文件方式(读写两种方式)
open()打开文件
file_object = open(file_name [, access_mode][, buffering])
| 参数 | 描述 |
|---|---|
| file_name | 访问文件的路径名 |
| access_mode | 打开文件的模式,默认为只读 |
| buffering | 是否缓冲 (0=不缓冲,1=缓冲,<0缓存区为系统默认值,>1的int数=缓冲区大小) |
文件打开模式:
| 模式 | 描述 |
|---|---|
| r | 只读 |
| w | 只写 (会清空原始内容) |
| a | 追加 |
| rb | 以二进制模式打开,只读 |
| wb | 以二进制模式打开,只写 |
| r+ | 读和写 |
| w+ | 消除文件内容,之后可以读和写 |
| a+ | 追加,读和写 |
read()读取文件
有三种读取形式
| 读取形式 | 描述 |
|---|---|
| file_object.read() | 读取整个文件 |
| file_object.readline() | 读取一行 |
| file_object.readlines() | 读取文件的所有行,并自动将文件解析为一个行列表 |
for语句遍历read()读取的数据,再通过print()输出
write()写入文件
file_object.write(‘str’),str是要写入的字符串内容
file_object.writelines(list),把list中的字符串按行写入文件,连续写入,无换行
【写入多行,需要换行可以在写入的字符串最后加 \n】
close()关闭文件
文件读取完毕后,需要关闭文件,file_object.close()
小实验1:
#读取TXT文件
#要打开的文件与当前程序文件处于同一目录下
with open('haiTest.txt') as file_object:
#查找文件路径
#with open('E:\learning\python\jupyter\pyBase\haiTest.txt') as file_object:
contents = file_object.read()
print(contents)
#输出:Yesterday is history, tomorrow is a mystery, but today is a gift.
file_object = open('haiTest.txt')
contents = file_object.read()
print(contents)
#输出:Yesterday is history, tomorrow is a mystery, but today is a gift. b.文件对象的操作方法
| 操作方法 | 描述 |
|---|---|
| file_object.fileno() | 获得文件描述符,是一个数字 |
| file_object.flush() | 刷新输出缓存 |
| file_object.isatty() | 文件是否为交互终端,返回True/False |
| file_object.seek(offset[,where]) | 文件指针移动到相对于where的offset的位置 |
| file_object.tell() | 获取文件指针位置 |
| file_object.truncate([size]) | 截取文件(size为大小) |
| file_object.name | 返回文件名 |
| file_object.mode | 返回文件读取形式 |
c.学习对excel及csv文件进行操作
csv文件操作
打开CSV
需要提前导入CSV函数包— import csv
打开csv: csv_file=open(file_name[, access_mode])
读取CSV
读取csv: csv_file=csv.reader(csvfile);pandas.read_csv(file_name)[导入pandas库](读取后返回的是文件的内存地址)
写入CSV
实例化一个write对象: csv_writer = write(csv_file)
利用writerow函数写入: csv_writer.writerow(“new_information”)
小实验1:
import csv
csvfile = open('student.csv', encoding = 'utf-8')
data = csv.reader(csvfile) #data 返回内存地址
for line in data:
print (line)输出:
['\ufeff学号', '年龄', '性别']
['1', '20', '0']
['2', '17', '1']
['3', '18', '1']
['4', '21', '0']小实验2:
import pandas as pd
pandas.read_csv('student.csv')输出:
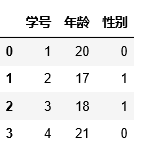
小实验3:
import csv
stu_new1 = [5,25,1]
stu_new2 = [6,23,0]
csvfile = open('student.csv','a', newline='')
csv_write = csv.writer(csvfile)
csv_write.writerow(stu_new1)
csv_write.writerow(stu_new2)Excel文件操作
利用xlrd库处理excel文件
import xlrd
data = xlrd.open_workbook('path') #path为文件路径
sheet_name = data.sheet_names()#获取所有sheet的名称
sheet = data.sheet_by_index(index)#根据索引获取sheet
sheet = data.sheet_by_name(name)#根据名称获取sheet
rows = sheet.nrows #获取行数
cols = sheet.ncols #获取列数
sheet.row_values(n) #获取整行的值,返回数组
sheet.col_values(n) #获取整列的值,返回数组
sheet.cell(r,c).value #获取(r,w)单元格的值利用xlwt库处理excel文件
import xlwt
workbook = xlwt.Workbook(encoding = 'utf-8') #创建一个Workbook对象
sheet = workbook.add_sheet('sheet')# 创建一个sheet
sheet.write(r,c,'string') #给(r,c)单元格添加数据
sheet.save('path_name.xls')#保存数据到指定文件2.os模块
os模块是python的内置模块,是一个可以访问操作系统的模块
import os #导入os模块
os.name #输出当前正在使用的系统,windows是'nt'
os.getcwd() #输出当前路径
os.listdir(path) #列举目录下的所有文件
os.path.abspath('.') #获取文件的绝对路径
os.chdir('new_path') #改变当前工作路径
os.mkdir('file_name') #创建file_name文件夹
os.makedirs(r'filname1\a\b\c')#递归创建问价夹
os.rmiir('filename) #删除目录
os.removedirs(r'filname1\a\b\c') #递归删除空目录
os.rename('old','new') #文价夹重命名
os.path.splitext('file.txt') #分离文件名和扩展名
os.path.basename('path_file.txt') #返回文件名
os.path.dirname('path_file.txt') #返回文件目录
os.path.existe(r'path') #检查输入路径是否存在
os.path.getsize(r'path') #文件的大小3.datetime模块
datetime是日期和时间的标准库
1、datetime类
(包含属性:year,month,day,hour,minute,second,microsecond)
from datetime import datetime
now = datetime.now() #获取当前日期+时间
type(now) #返回当前时间的类型
date = datetime.today() #获取当前日期和时间
t =date.timestamp() #把datetime转换为timestamp
date = datetime.fromtimestamp(t) #把timestamp转换为datetime
date = datetime.utcfromtimestamp(t) #把timestamp转换为UTC标准datetime
dt = datetime(2015, 4, 19, 12, 20) #用指定日期时间创建一个datetime对象
cday = datetime.strptime('2015-6-1 18:19:59', '%Y-%m-%d %H:%M:%S') #str转换为datetime
strdate = now.strftime('%a, %b %d %H:%M') #日期格式化为字符串显示给用户
now + datetime.timedelta(days=n,hours = h) #datetime 加减操作
now - datetime.timedelta(days=n,hours = h) #datetime 加减操作datetime转换为timestamp:1970年1月1日 00:00:00 UTC+00:00时区的时刻称为epoch time,记为0(1970年以前的时间timestamp为负数),当前时间就是相对于epoch time的秒数,称为timestamp。
2、date类
(包含属性:year,month,day)
from datetime import date
date =date.today() #获取当天日期
date.weekday() #当天属于本星期第几天(从0开始)
date.isoweekday() #当天属于本星期第几天(从1开始)
date.isoformat() #返回YYYY-MM-DD格式的字符串4.类和对象
类是抽象的模板,比如Student类,而实例是根据类创建出来的一个个具体的“对象”,每个对象都拥有相同的方法,但各自的数据可能不同。
class Student(): #创建类
def __init__(self,name,age): # __init__()方法初始化类 [前后均为两个下划线]
self.name = name
self.age = age
stu1 = Student('Tom',18) #创建实例
stu2 = Student('Lily',19)
print(stu1.name,stu1.age)
print(stu2.name,stu2.age)5.正则表达式
正则表达式是一种用来匹配字符串的强有力的武器。它的设计思想是用一种描述性的语言来给字符串定义一个规则,凡是符合规则的字符串,我们就认为它“匹配”了,否则,该字符串就是不合法的。
1、用该正则表达式去匹配用户的输入来判断是否合法
在正则表达式中,如果直接给出字符,就是精确匹配。用\d可以匹配一个数字,\w可以匹配一个字母或数字,.可以匹配任意字符,所以:
'00\d'可以匹配'007',但无法匹配'00A';
'\d\d\d'可以匹配'010';
'\w\w\d'可以匹配'py3';
'py.'可以匹配'pyc'、'pyo'、'py!'等等。2、要匹配变长的字符
在正则表达式中,用*表示任意个字符(包括0个),用+表示至少一个字符,用?表示0个或1个字符,用{n}表示n个字符,用{n,m}表示n-m个字符:
来看一个复杂的例子:\d{3}\s+\d{3,8}。
\d{3}表示匹配3个数字,例如’010’;
\s可以匹配一个空格(也包括Tab等空白符),所以\s+表示至少有一个空格;
\d{3,8}表示3-8个数字,例如’1234567’。
综合起来,上面的正则表达式可以匹配以任意个空格隔开的带区号的电话号码。如果要匹配’010-12345’这样的号码呢?由于’-‘是特殊字符,在正则表达式中,要用’‘转义,所以,上面的正则是\d{3}-\d{3,8}。但是,仍然无法匹配’010 - 12345’,因为带有空格。所以我们需要更复杂的匹配方式。
3、进阶
要做更精确地匹配,可以用[]表示范围,比如:
[0-9a-zA-Z\_]可以匹配一个数字、字母或者下划线;
[0-9a-zA-Z\_]+可以匹配至少由一个数字、字母或者下划线组成的字符串,比如'a100','0_Z','Py3000'等等;
[a-zA-Z\_][0-9a-zA-Z\_]*可以匹配由字母或下划线开头,后接任意个由一个数字、字母或者下划线组成的字符串,也就是Python合法的变量;
[a-zA-Z\_][0-9a-zA-Z\_]{0, 19}更精确地限制了变量的长度是1-20个字符(前面1个字符+后面最多19个字符)。
A|B可以匹配A或B,所以(P|p)ython可以匹配'Python'或者'python'。
^表示行的开头,^\d表示必须以数字开头。
$表示行的结束,\d$表示必须以数字结束。正则表达式模式语法
| 元素 | 含义 |
|---|---|
| . | 匹配\n以外的任何字符 |
| \d | 匹配一个数字[0-9] |
| \s | 匹配一个空白字符 |
| \w | 匹配一个字母或数字字符 |
| \ | 匹配一个反斜杠字符 |
| ? | 匹配0个或1个字符 |
| + | 匹配多个字符,至少一个 |
| * | 匹配0个或多个字符 |
| {n,m} | 匹配n-m个字符 |
| ^ | 匹配字符串的起始部分 |
| $ | 匹配字符串的结束部分 |
| a|b | 匹配a或b |
6.re模块
Python提供re模块,包含所有正则表达式的功能。
match()方法判断是否匹配,如果匹配成功,返回一个Match对象,否则返回None。
import re
re.match(r'^\d{3}\-\d{3,8}$', '010-12345')
#输出:7.http请求
python是实现http请求有三种方式——
1、urllib-是标准库
2、urllib3-与urllib类似,但属于扩展库,需要安装
from urllib import request
with request.urlopen('https://blog.csdn.net/hxy199421/article/details/81033229') as f:
data = f.read() 3、requests
import requests
data = requests.get('https://blog.csdn.net/duozhishidai/article/details/89095517',timeout=10)
print(data.content) #返回字节形式