TextCNN
本文选择使用2013年Kim提出的Text-CNN模型作为文本分类模型,在文本分类任务中,CNN模型已经能够取到比较好的结果,虽然在某些数据集上效果可能会比RNN稍差一点,但是CNN模型训练的效率更高。所以,一般认为CNN模型在文本分类任务中是兼具效率与质量的理想模型。
下面我们先来看一下深度学习中样本数据的处理流程
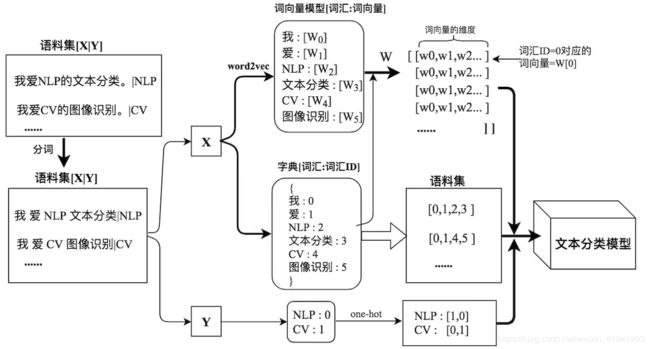
- 首先需要对待处理的文本(语料集)进行预处理,包括一些无用的网络标签和分词等。
- 对分词后的文本进行向量化,构建词向量模型和字典,同时对标签进行处理。
- 将词向量和字典扩展成矩阵。
- 将上面所有的过程联合起来,得到文本分类模型
深度学习领域有许多进行NLP的办法,下面为文本分类的技术路线
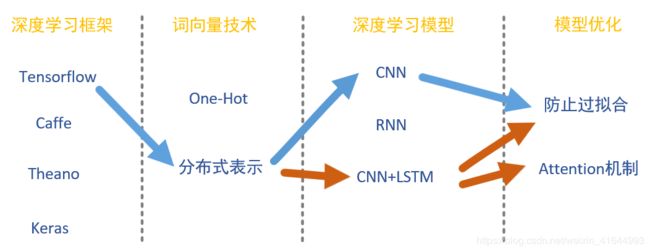
其中分布式表示中具有代表性的word2vec,防止过拟合有L2、BN、DropOut,RNN可以说是LSTM的前身。
word2vec工具,它是一种无监督的学习模型,可以在一个语料集上,实现词汇信息到语义空间的映射,最终获得一个词向量模型(每个词汇对应一个指定维度的数组)。它的核心优势就是实现了两个词汇信息之间的语义相似度的可计算性,也可以理解为是一种迁移学习的思想,word2vec获取的意义空间信息作为后续文本分类模型的输入。
python 中使用word2vec工具也是非常的便利,通过pip install gensim安装gensim工具包,此包汇总包含了word2vec工具。具体实现可以参考:使用自己的语料训练word2vec模型
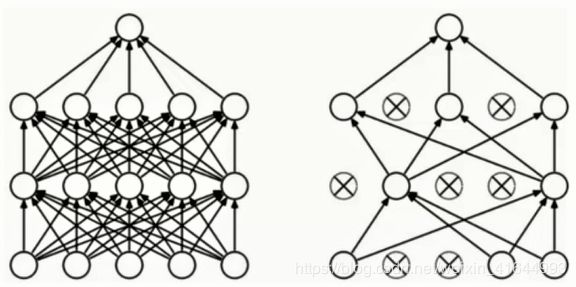
上面的图左图为全连接的网络,右图为dropout后的网络。全连接的网络容易过拟合,所以对其dropout,可以降低过拟合的风险,计算量也变小 ,可以使用迭代次数弥补数量少的问题。
未完待续。。。