数据竞赛(四)模型及调优
一、模型
1. GBDT
GBoost = GradientBoostingRegressor(n_estimators=3000, learning_rate=0.04,
max_depth=6, max_features='sqrt',
min_samples_leaf=15, min_samples_split=10,
loss='huber', random_state = 2333)
GBoost.fit(train, target)
# 对训练集预测
pred_log1p = GBoost.predict(train)2. XGB
model_xgb = xgb.XGBRegressor(colsample_bytree=0.4603, gamma=0.0468,
learning_rate=0.05, max_depth=6,
min_child_weight=1.7817, n_estimators=2200,
reg_alpha=0.4640, reg_lambda=0.8571,
subsample=0.5213, silent=1,
random_state =7, nthread = -1,
)
# y_train = target
test.columns = train.columns
# 进行模型训练
model_xgb.fit(train, target)
# 对训练集预测
pred_log1p = model_xgb.predict(train)3. LGBM
folds = KFold(n_splits=5, shuffle=True, random_state=2333)
oof_lgb = np.zeros(len(train))
predictions_lgb = np.zeros(len(test))
feature_importance_df = pd.DataFrame()
for fold_, (trn_idx, val_idx) in enumerate(folds.split(train.values, target.values)):
print("fold {}".format(fold_))
trn_data = lgb.Dataset(train.iloc[trn_idx], label=target.iloc[trn_idx], categorical_feature=categorical_feats)
val_data = lgb.Dataset(train.iloc[val_idx], label=target.iloc[val_idx], categorical_feature=categorical_feats)
# trn_data = lgb.Dataset(train.iloc[trn_idx], label=target.iloc[trn_idx])
# val_data = lgb.Dataset(train.iloc[val_idx], label=target.iloc[val_idx])
num_round = 10000
clf = lgb.train(params, trn_data, num_round, valid_sets=[trn_data, val_data], verbose_eval=500,
early_stopping_rounds=200)
oof_lgb[val_idx] = clf.predict(train.iloc[val_idx], num_iteration=clf.best_iteration)
OOF_lgb = pd.DataFrame()
OOF_lgb[fold_] = clf.predict(train, num_iteration=clf.best_iteration)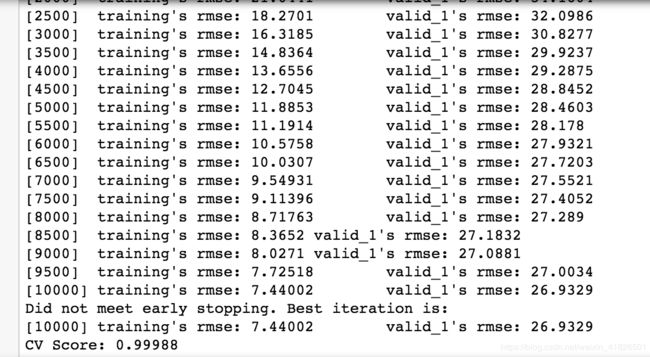
4. CatBoost
import catboost as cb
model_cb = cb.CatBoostRegressor(iterations=1000, depth=6, learning_rate=0.5,eval_metric = "R2",leaf_estimation_method = "Newton",
l2_leaf_reg=3
)
y_train = target
# 采用平滑后的y_train进行模型训练
model_cb.fit(train, y_train)
# 对训练集预测
pred_log1p = model_cb.predict(train)5. ENet
ENet = make_pipeline(RobustScaler(), ElasticNet(alpha=1e-9, l1_ratio=.59, random_state=5))
# 采用平滑后的y_train进行模型训练
ENet.fit(train, log1p_y_train)
# 对训练集预测
pred_log1p = ENet.predict(train)6. Lasso
lasso = make_pipeline(RobustScaler(), Lasso(alpha =1e-9, random_state=5))
# 采用平滑后的y_train进行模型训练
lasso.fit(train, log1p_y_train)
# 对训练集预测
pred_log1p = lasso.predict(train)二、模型调优
1. hyperopt
(英文原版)https://districtdatalabs.silvrback.com/parameter-tuning-with-hyperopt
(中文译版)https://www.jianshu.com/p/35eed1567463
2. 网格搜索和随机搜索
model_selection.GridSearchCV
model_selection.RandomizedSearchCV