pandas 学习手记-创建文件
pandas 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的,是数据分析必学的一个库。
运行环境和编译工具
Python环境是Python3
安装pandans库
pip install pandas
我使用的编译工具是 jupyter notebook
首先暗转jupyter
pip install jupyter
然后在命令行中输入
jupyter notebook
就能在浏览器中打开编译器了,后面的代码都是在上面敲的。
创建文件
import pandas as pd # 导入pandas库,为了方便一般简写为 pd
df = pd.DataFrame() # 创建一个表格对象,先不创建内容
df.to_excel('D:/temp/test.xlsx') # 将对象保存为一个 test.xlsx 文件
运行上面代码后就能在对应的目录下看到生成了一个excel文件
上面生成的是一个空文件,现在我往里面添加一些数据
import pandas as pd
df = pd.DataFrame({'id': [1, 2, 3, 4], 'name': ['张三', '李四', '王五', '麻花']})
df.to_excel('D:/temp/test.xlsx')
现在打开这个excel文件查看里面的内容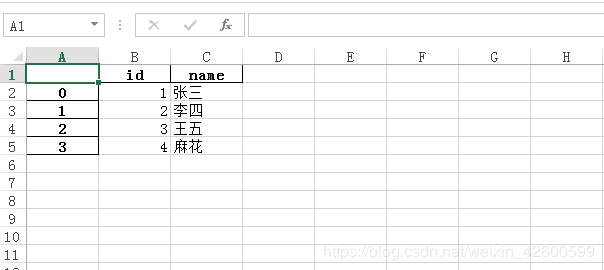
它会自动生成一个索引列,所以我们的数据都是从第二列开始的。可以把指定列设为索引,比如现在我们把id设为索引。
df = df.set_index('id') # 把上面数据中的id列设为索引
df.to_excel('D:/temp/test.xlsx')
现在表格里面的数据应该是这样的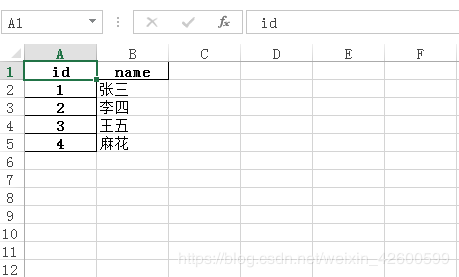
@快乐是一切的博客