python处理大数据你选什么工具? pandas? or Dask?
Pandas是python的众多工具包中最著名一个,如果你使用python进行数据分析与建模,你一定会用到pandas,pandas已经越来越被广泛的应用于数据探索性分析(EDA),它可以完全媲美甚至超越Excel,目前越来越多的Excel数据分析师都在转向使用Python和Pandas,我之前写的大多数博客文章中都是使用pandas作为数据探索性分析(EDA)的工具,但是并不是所有的数据分析工作都适合pandas,例如在做大数据处理时,当你需要同时处理一大堆数据文件时使用pandas会效率较低,并且系统CPU的利用率也较低。
最近我找到了两个非常好用的python处理大数据的工具包Vaex和Dask,我之前的博客已经介绍过了Vaex,今天我为大家再简单介绍一下Dask。
认识Dask
dask是python用于并行计算的一个工具包,它可以让你在处理一大堆数据文件时变得更加有效率,它可以充分利用系统CPU的资源,并且它的操作非常简单,如果你熟悉pands的操作那么dask对你来说也不会是问题,关键是dask和众多优秀的python工具包一样它仍然是免费的。下面是dask官方文档中的对dask的介绍:
Dask由两部分组成:
- 动态任务调度针对计算进行了优化。这类似于 Airflow,Luigi,Celery或Make,但已针对交互式计算工作负载进行了优化。
- “大数据”集合(如并行数组,dataframe 和列表)将诸如NumPy,Pandas或Python迭代器之类的通用接口扩展到内存或分布式环境。这些并行集合在动态任务计划程序之上运行。
Dask有以下优点:
- 熟悉的:提供并行的NumPy数组和Pandas DataFrame对象
- 灵活:提供任务计划界面,以实现更多自定义工作负载并与其他项目集成。
- 本地化:在纯Python中启用分布式计算并可以访问PyData堆栈。
- 快速:以低开销,低延迟和快速数值算法所需的最少序列化操作
- 扩大:在具有1000个核心的集群上弹性运行
- 缩小:在单个过程中轻松设置并在笔记本电脑上运行
- 响应式:设计时考虑了交互式计算,它提供了快速的反馈和诊断功能,以帮助人类
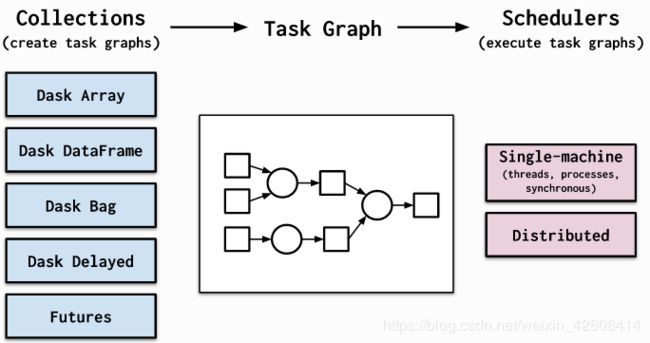
有关Dask分布式调度程序的更多技术信息,请参阅dask.distributed文档
使用Dask
下面我使用一个简单的例子来对比Pandas和Dask的各自表现,我们要测试一下Pandas和Dask他们各自处理一批大数据文件时的执行效率,首先我们利用sklearn来生成10个二分类的样本数据集文件,每个文件大约196M,每个文件的数据维度是10万x101列(这里只是为了测试方便我们生成10个数据集文件)。
import pandas as pd
from sklearn.datasets import make_classification
import glob
import dask.dataframe as dd
for i in range(1, 11):
print('创建 test_%d.csv' % i)
x, y = make_classification(n_samples=100_000, n_features=100)
df = pd.DataFrame(data=x)
df['y'] = y
df.to_csv('./data/dask_data/test_%d.csv' % i, index=False)
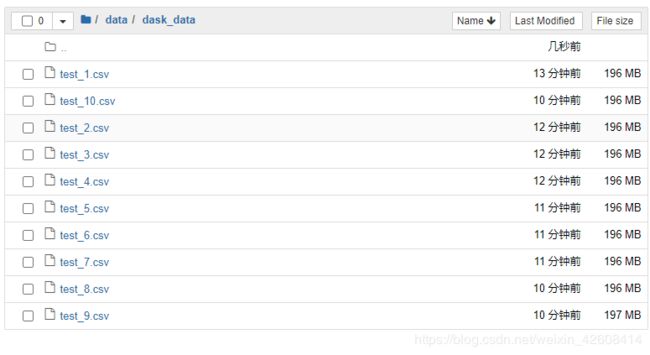
接下来我们利用pandas的dataframe将这10个csv文件合并为1个文件,同时我们观察pandas的执行时间:
%%time
df_list = []
for file in glob.glob('./data/dask_data/test_*.csv'):
df_ = pd.read_csv(file)
df_list.append(df_)
df = pd.concat(df_list)
df.shape
我们注意到pandas合并这10个csv文件花费了24秒左右,合并后的数据维度为100万x101列,下面我们看看合并后的数据集占用了多少内存:
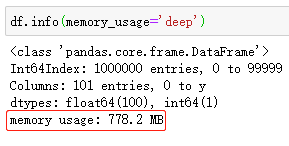

合并后的dataframe占用了778M内存。接下来我们使用Dask来测试一下同时加载这10个文件需要多少时间:
%%time
df = dd.read_csv('./data/dask_data/test_*.csv')
由于Dask是通过将数据分成多个块并指定任务链来处理不适合加载到内存的数据。我们发现Dask使用了非常简短的一句代码就可以同时加载所有的数据文件,并且耗时只有238毫秒。dask批量化读取文件的速度非常的惊人,其实dask使用了一种延迟数据加载机制,这种延迟机制类似于python的迭代器组件,只有当需要使用数据的时候才会去真正加载数据。下面我们dask的compute()方法来真正的加载数据:
%%time
df = dd.read_csv('./data/dask_data/test_*.csv').compute()
我们使用了compute()以后dask才真正加载了所有的数据,耗时也只有8秒左右,而pandas加载这些数据需要24秒,因此dask访问数据的速度是pandas的3倍。
Dask为什么快?
根据官方文档的描述,在默认情况下,Dask允许并发运行与CPU内核数量一样多的任务,也就是说CPU的内核数越多,Dask的速度也越快。而相比之下,Pandas未能充分利用CPU的内核资源,不能同时并发执行多个任务。
Dask如何并发执行任务?
Dask的DataFrame由多个Pandas的DataFrame组成,按索引来划分。 当我们使用Dask执行read_csv时,多个进程将读取一个文件。我们可以通过可视化的方法来观察Dask批量读取文件的过程:
exec_graph = dd.read_csv('./data/dask_data/test_*.csv')
exec_graph.visualize(filename='exec_graph.pdf')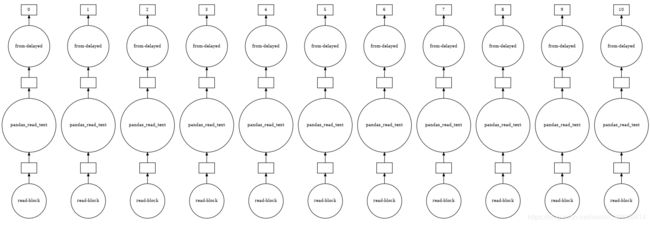
Dask的缺点
由于Dask是在pandas的基础上开发的,只是将pandas的某些可以被并发执行的功能移植到了dask上,但有些功能不能被并发执行如:给数据值排序、给未排序的列添加索引等。Dask可以看做是一个可并发执行的精简版Pandas,所以Dask并不能完全取代Pandas,pandas的某些功能是dask所不具有的,同样pandas的某些缺点也会体现在Dask上。
参考资料
Dask 官方文档:https://docs.dask.org/en/latest/