python 爬取百度搜索图片
爬取百度“街拍”前两页的图片,本人新手,如果你有更好的方法,希望能多多交流!
1.爬取数据,分析url。百度的图片加载是通过滚动条动态加载。每页30条数据,通过pn参数控制页数:第二页pn=30,第三页pn=60,以此类推。
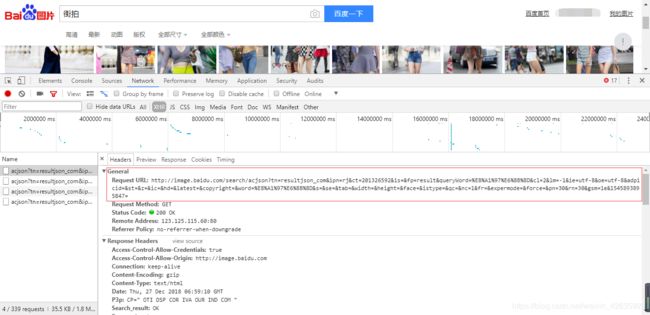
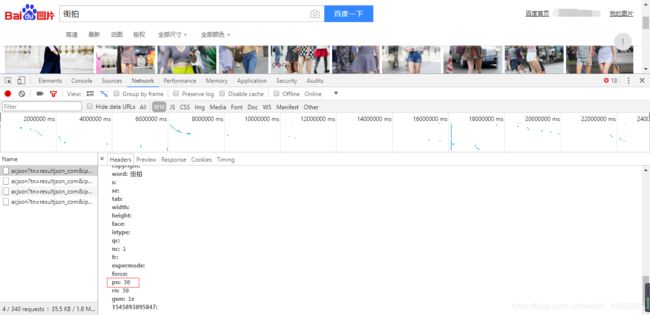
2.解析数据,返回的数据有五个图片地址,分别是:fromURL,hoverURL,middleURL,objURL,thumbURL。
据说是只有objURL可用,现在objURL也进行了加密,需要进行解密才能得到正确的url。解密函数请参考:百度图片链接解密
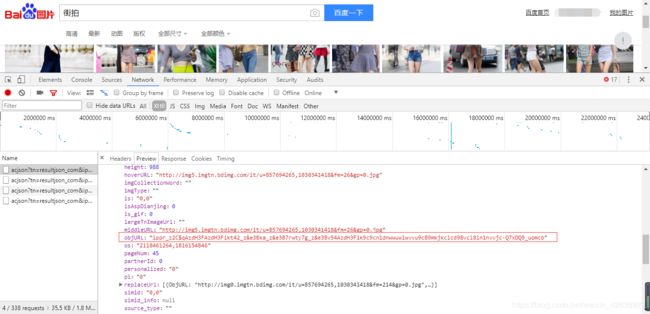
3.得到正确的url之后就可以下载图片了。
完整代码:
#爬取百度搜索街拍图片
import os,time,json,requests,re,sys,urllib
from urllib.parse import urlencode
def decryptionUrl(url):
'''解码百度图片链接'''
res = ''
c = ['_z2C$q', '_z&e3B', 'AzdH3F']
d= {'w':'a', 'k':'b', 'v':'c', '1':'d', 'j':'e', 'u':'f', '2':'g', 'i':'h', 't':'i', '3':'j', 'h':'k', 's':'l', '4':'m', 'g':'n', '5':'o', 'r':'p', 'q':'q', '6':'r', 'f':'s', 'p':'t', '7':'u', 'e':'v', 'o':'w', '8':'1', 'd':'2', 'n':'3', '9':'4', 'c':'5', 'm':'6', '0':'7', 'b':'8', 'l':'9', 'a':'0', '_z2C$q':':', '_z&e3B':'.', 'AzdH3F':'/'}
if(url==None or 'http' in url):
return url
else:
j= url
for m in c:
j=j.replace(m,d[m])
for char in j:
if re.match('^[a-w\d]+$',char):
char = d[char]
res= res+char
return res
def getPage(keyword,offset,gsm):
'''爬取街拍信息'''
#将关键词进行编码
word=urllib.parse.quote(keyword, safe='/')
#这是网上的方法
'''
old_url = 'http://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word='
url = old_url+ word + "&pn=" +str(offset) + "&gsm="+str(hex(offset))+"&ct=&ic=0&lm=-1&width=0&height=0"
'''
#我自己的方法:一
# url = 'http://image.baidu.com/search/acjson?tn=resultjson_com&ipn=rj&ct=201326592&is=&fp=result&queryWord='+word+'&cl=2&lm=-1&ie=utf-8&oe=utf-8&adpicid=&st=&z=&ic=&hd=&latest=©right=&word='+word+'&s=&se=&tab=&width=&height=&face=&istype=&qc=&nc=1&fr=&expermode=&force=&pn='+str(offset)+'&rn=30&gsm='+str(gsm)+'&1545893895847='
#我自己的方法:二
params = {
'tn':'resultjson_com',
'ipn':'rj',
'ct':'201326592',
'is':'',
'fp':'result',
'queryWord':word,
'cl':'2',
'lm':'-1',
'ie':'utf-8',
'oe':'utf-8',
'adpicid':'',
'st':'',
'z':'',
'ic':'',
'hd':'',
'latest':'',
'copyright':'',
'word':word,
's':'',
'se':'',
'tab':'',
'width':'',
'height':'',
'face':'',
'istype':'',
'qc':'',
'nc':'1',
'fr':'',
'expermode':'',
'force':'',
'pn':offset,
'rn':'30',
'gsm':gsm,
'1545893895847':'',
}
url = 'http://image.baidu.com/search/acjson?'+urlencode(params)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36',
"referer":"https://image.baidu.com"
}
try:
res = requests.get(url,headers=headers)
if res.status_code == 200:
return res.text
except Exception as e:
print('没有数据,原因:%s'%e)
return None
def parsePage(html):
'''解析数据'''
pat = '"objURL":"(.*?)",'
html = str(html)
items = re.findall(pat,html,re.S)
return items
def savePage(item,j):
'''保存图片'''
try:
pic = requests.get(item,timeout=15)
string =str(j) + '.jpg'
with open('./images/baidu/'+string, 'wb') as f:
f.write(pic.content)
print('成功下载第%s张图片: %s' % (str(j), str(item)))
except Exception as e:
print('下载第%s张图片时失败: %s' % (str(j), str(item)))
print(e)
def main(keyword,offset,gsm):
'''主函数'''
#判断当前路径是否存在images文件夹
if not os.path.exists('./images/baidu'):
os.makedirs('./images/baidu')
#j用于图片按顺序命名
j = offset+1
html = getPage(keyword,offset,gsm)
items = parsePage(html)
for item in items:
item1 = decryptionUrl(item)
savePage(item1,j)
j += 1
if __name__ == '__main__':
keyword = input('请输入关键词:')
for i in range(2):
offset = i*30
gsm = hex(offset)
main(keyword,offset,gsm)
print((i+1)*30)
time.sleep(1)