【python】python3 Face++ api 调用
准备做一个树莓派的人脸识别系统,查了下Face++是免费的而且比较好用,找了一下网上的资料都是python2.7的,所以在此记录下整个开发过程。
调用face++的api首先需要注册账号,然后创建api key,这些都很简单就不说了。
先上测试代码
注意:
这里我遇到了两个问题
第一个是绝对路径的问题,我使用的时候不能用“\” 而要用“\”才行
第二个是No module named ‘requests’
解决方法是去下载这个东西,而下载这个东西又要先下载pip,方法在这
不过我是按评论里的用powershell安装的,博主的方法在我这不知道为什么没用。
powershell的用法和linux一样,先到下载的文件目录下,然后使用博主给的命令就可以了。最后结果如下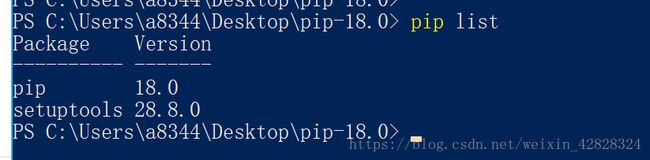
pip安装成功,再去安装’requests’,
这里是方法
注意第二条命令里地址,例如我的是这样的![]()
最后结果如下

然后在pycharm里还是不行,好像是环境配置有点问题,这个等下个博客再写这个问题的解决办法,目前我是直接打开python3.6然后输入代码解决的。
import requests
from json import JSONDecoder
http_url ="https://api-cn.faceplusplus.com/facepp/v3/detect"
#你要调用API的URL
key ="公钥"
secret ="私钥"
#face++提供的一对密钥
filepath1 ="D:\py\image\WIN_20180412_21_52_13_Pro.jpg"
#图片文件的绝对路径
data = {"api_key":key, "api_secret": secret, "return_attributes": "gender,age,smiling,beauty"}
#必需的参数,注意key、secret、"gender,age,smiling,beauty"均为字符串,与官网要求一致
files = {"image_file": open(filepath1, "rb")}
'''以二进制读入图像,这个字典中open(filepath1, "rb")返回的是二进制的图像文件,所以"image_file"是二进制文件,符合官网要求'''
response = requests.post(http_url, data=data, files=files)
#POTS上传
req_con = response.content.decode('utf-8')
#response的内容是JSON格式
req_dict = JSONDecoder().decode(req_con)
#对其解码成字典格式
print(req_dict)
#输出大概现象如下
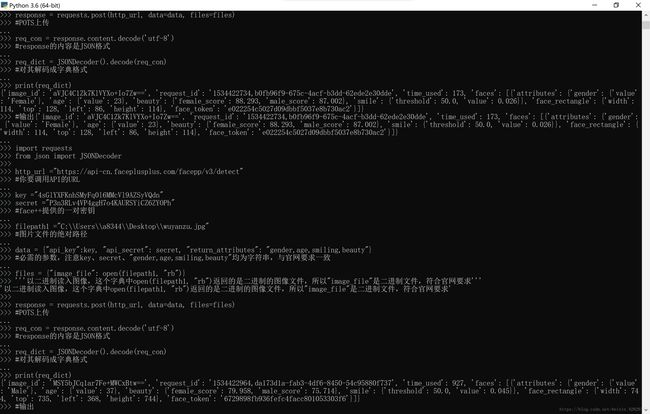
我使用的两张图片如下


将返回结果格式化
得到以下结果
#刘亦菲的结果
{
'image_id': 'aVJC4C1Zk7KlVYXo+Io7Zw==', 'request_id': '1534422734,b0fb96f9-675c-4acf-b3dd-62ede2e30dde', 'time_used': 173, 'faces': [
{
'attributes':
{
'gender':
{
'value': 'Female'
}
, 'age':
{
'value': 23
}
, 'beauty':
{
'female_score': 88.293, 'male_score': 87.002
}
, 'smile':
{
'threshold': 50.0, 'value': 0.026
}
}
, 'face_rectangle':
{
'width': 114, 'top': 128, 'left': 86, 'height': 114
}
, 'face_token': 'e022254c5027d09dbbf5037e8b730ac2'
}
]
}
#吴彦祖的结果
print(req_dict)
{
'image_id': 'MSY5bJCq1ar7Fe+MWCxBtw==', 'request_id': '1534422964,da173d1a-fab3-4df6-8450-54c95880f737', 'time_used': 927, 'faces': [
{
'attributes':
{
'gender':
{
'value': 'Male'
}
, 'age':
{
'value': 37
}
, 'beauty':
{
'female_score': 79.958, 'male_score': 75.714
}
, 'smile':
{
'threshold': 50.0, 'value': 0.045
}
}
, 'face_rectangle':
{
'width': 744, 'top': 735, 'left': 368, 'height': 744
}
, 'face_token': '6729898fb936fefc4facc801053303f6'
}
]
}
>>> #输出
感觉还是挺准的,第一个api的调用就这样结束了。想自己调用其他函数的可以看这个博客
其他api的调用我会在近期更新。
加入图片的api:
import requests
from json import JSONDecoder
http_url ="https://api-cn.faceplusplus.com/facepp/v3/faceset/create"
#你要调用API的URL
key =""
secret =""
#face++提供的一对密钥
data = {"api_key":key,
"api_secret": secret,
"display_name":"test_1",
"outer_id":"wuyanzu_1",
'face_tokens':'a8c6e778b6fcdcaf7f6f477e3740fa65'}
#必需的参数,注意key、secret、"gender,age,smiling,beauty"均为字符串,与官网要求一致
response = requests.post(http_url, data=data)
#POTS上传
req_con = response.content.decode('utf-8')
#response的内容是JSON格式
req_dict = JSONDecoder().decode(req_con)
#对其解码成字典格式
print(req_dict)
#输出对比两个图片的api,这里用的都是token上传的。
import requests
from json import JSONDecoder
http_url ="https://api-cn.faceplusplus.com/facepp/v3/compare"
#你要调用API的URL
key =""
secret =""
#face++提供的一对密钥
data = { "api_key":key,
"api_secret": secret,
"face_token1": '94c40c1912685e3bf75fd57de0b7c9e8',
"face_token2": 'bba4b045c886beb7d6574d4fb265841a'
}
#必需的参数,注意key、secret、"gender,age,smiling,beauty"均为字符串,与官网要求一致
response = requests.post(http_url, data=data)
#POTS上传
req_con = response.content.decode('utf-8')
#response的内容是JSON格式
req_dict = JSONDecoder().decode(req_con)
#对其解码成字典格式
print(req_dict)
#输出上传图片并在图片库中找是否有相同的人脸:
注意,上传文件的参数名很奇怪,和官网上所要求的参数名不一样,不知道是什么原因。
import requests
from json import JSONDecoder
http_url ="https://api-cn.faceplusplus.com/facepp/v3/search"
#你要调用API的URL
key =""
secret =""
#face++提供的一对密钥
filepath1 ="C:\\Users\\a8344\\Desktop\\lwx.jpg"
#图片文件的绝对路径
data = { "api_key":key,
"api_secret": secret,
"outer_id": 'wuyanzu_2'}
#必需的参数.
files= {"image_file": open(filepath1, "rb")}
'''以二进制读入图像,这个字典中open(filepath1, "rb")返回的是二进制的图像文件,所以"image_file"是二进制文件,符合官网要求'''
response = requests.post(http_url, data=data,files=files)
#POTS上传
req_con = response.content.decode('utf-8')
#response的内容是JSON格式
req_dict = JSONDecoder().decode(req_con)
#对其解码成字典格式
print(req_dict)
#输出结果如下
这是与不同人相比较:
print(req_dict)
{
'image_id': 'XjuXSJFVwa9Nh6XzHY2lFw==', 'faces': [
{
'face_rectangle':
{
'width': 685, 'top': 608, 'left': 761, 'height': 685
}
, 'face_token': '8e53c8cc4c49c17706831ca57a3f67a9'
}
], 'time_used': 1531, 'thresholds':
{
'1e-3': 62.327, '1e-5': 73.975, '1e-4': 69.101
}
, 'request_id': '1534647939,0ea24d19-bb1e-4377-8ccf-93794b197147', 'results': [
{
'confidence': 18.285, 'user_id': '', 'face_token': 'a8c6e778b6fcdcaf7f6f477e3740fa65'
}
]
}这是与相同人作比较:
print(req_dict)
{
'image_id': 'lGmy5DTEXERAnBPU91v6Dw==', 'faces': [
{
'face_rectangle':
{
'width': 252, 'top': 135, 'left': 213, 'height': 252
}
, 'face_token': '3e9fb3c503adf757cc15920a80466288'
}
], 'time_used': 595, 'thresholds':
{
'1e-3': 62.327, '1e-5': 73.975, '1e-4': 69.101
}
, 'request_id': '1534648193,45ffb84f-be36-4e66-93cc-c4c1efcf69cf', 'results': [
{
'confidence': 87.416, 'user_id': '', 'face_token': 'a8c6e778b6fcdcaf7f6f477e3740fa65'
}
]
}