记录-爬取智联招聘
最近准备找工作了,想从智联上爬一下青岛和上海的python和java相关岗位信息,所以决定写个爬虫,记录一下。
封装好的程序:
个人网站下载
(网址:http://123.206.72.236:8080/)
封装加壳的程序会让杀毒软件报毒
使用说明:
爬取上海和青岛的python和java岗位,参数不可改,懒=w=
前戏
正式开搞之前先揉捏一下要爬取的智联的搜索界面:
1、动态还是静态?
2、url,headers,params?
首先是第一个问题,F12找了一下需要爬取的信息在class="contentpile"的div中。

源代码中看了一眼,发现里面除了有个加载中显示的图片外没有别的内容,确定是动态网页。决定直接怼ajax接口。

接下来要找xhr。开发者工具中搜索ajax没有结果,过滤xhr后发现只有四个,挨个查看响应内容锁定了需要的xhr。
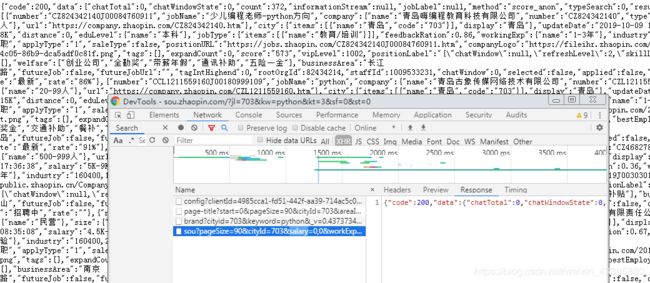
至此第一步结束。
第二步在开发者工具中可以很容易找到url以及headers,params的字段信息,重点在于找到headers,params变化规律。
这里要考虑两种情况:
a.搜索条件相同,页数不同。
b.搜索条件不同。
对于第一种情况,对比后找到增加内容(红框)和变化内容(篮框)

Referer反爬肯定要搞,能分析出p=3是当前页数,第一页为空;start是根据当前页数减一与pageSize字段相乘得到的值,第一页也是空;最后两个参数先搁置,先继续分析第二种情况。
第二种情况选择了不同的搜索条件,同样对比后找到增加内容(红框)和变化内容(篮框)
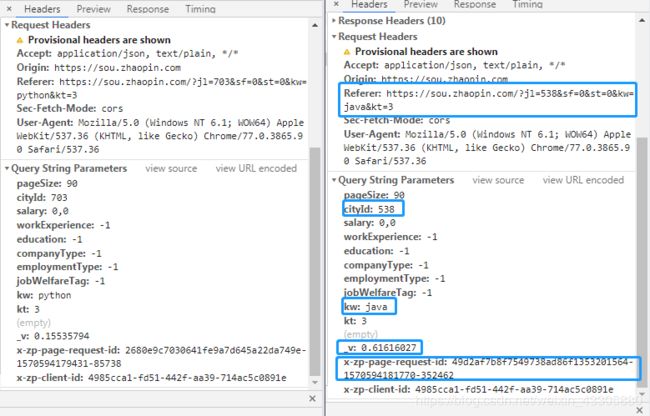
Referer变动的内容与cityId,kw的内容是一致的;cityId是搜索条件城市的id,因为只想找青岛和上海,所以就当成了两个常量,没有去找对应关系;kw是搜索内容。
其他的头信息和参数是常量,放着不管。
接下来是最困难的最后三个,根据感觉应该是反爬措施。
_v经多台电脑多种网络环境测试,_v毫无规律,也没有找到构造方法,应该是八位随机数。
x-zp-page-request-id为三段组成,查网页源代码找到其构造函数如下:

分析其三段组成为随机MD5加密+时间戳+6位随机数。
x-zp-client-id和cookie有关,查找源代码找到对应构造函数:

代码片段如下:
!
function(e) {
"function" == typeof define && define.amd ? define(e) : e()
} (function() {
"use strict";
var i = [".zhaopin.com", ".zhaopin.cn", ".highpin.cn"];
var t = {
get: function(e) {
var t = "; ".concat(document.cookie).split("; ".concat(e, "="));
return 2 === t.length ? t.pop().split(";").shift() : null
},
set: function(e, t, n) {
for (var o = null,
a = 0; a < i.length; a++) RegExp("".concat(i[a], "$")).test(window.location.hostname) && (o = i[a]);
o || console.warn("当前域名不在白名单内,白名单列表:".concat(i.join(", ")));
var c = new Date;
c.setTime(c.getTime() + 24 * n * 60 * 60 * 1e3),
document.cookie = "".concat(e, "=").concat(t, "; expires=").concat(c.toUTCString(), "; domain=").concat(o, "; path=/")
}
},
n = function() {
var n = (new Date).getTime();
return void 0 !== window.performance && "function" == typeof window.performance.now && (n += window.performance.now()),
"xxxxxxxx-xxxx-4xxx-yxxx-xxxxxxxxxxxx".replace(/[xy]/g,
function(e) {
var t = (n + 16 * Math.random()) % 16 | 0;
return ("x" === e ? t: 7 & t | 8).toString(16)
})
};
function e() {
var e = t.get("x-zp-client-id");
return e || (e = n(), t.set("x-zp-client-id", e, 36500)),
e
}
........
可以看出代码先尝试从cookie中取x-zp-client-id的值,如果没有的话会用函数n构造。
开搞
大概思路是根据城市和条件爬取第一页,然后根据返回的信息确定页数,爬取每页内容。
为了提高速度准备用协程嵌套并发爬取,因为要爬青岛的python和java以及上海的python和java,外层封装四个task处理,每个task内部根据再根据分页嵌套数个task。
代码如下:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# ~ import random
# ~ import time
# ~ import hashlib
# ~ import requests
import copy
import json
import math
import asyncio
import aiohttp
class Capturer():
'''headers,params
支持异步io的get方法
简单的数据处理'''
def __init__(self,kw,city,p=None):
self.citydic = {"703": "青岛","538":"上海"}
self.kw = kw
self.city = city
self.data = []
self.p = 0
self.getlist = []
self.url = r'https://fe-api.zhaopin.com/c/i/sou'
self.params = {
'pageSize': '90',
'cityId': self.city,
'salary': '0,0',
'workExperience': '-1',
'education': '-1',
'companyType': '-1',
'employmentType': '-1',
'jobWelfareTag': '-1',
'kw': self.kw,
'kt': '3',
'_v': '0.32382072',
'x-zp-page-request-id': 'b8c20281ecf44e229b9160dc4cccc6bf-1570632639468-862496',
'x-zp-client-id': 'd5b33ddb-6532-4f4f-86b2-1494956f5b49'
# ~ '_v': v,
# ~ 'x-zp-page-request-id': request_id,
# ~ 'x-zp-client-id': client_id
}
self.headers = {
'Accept': r'application/json, text/plain, */*',
'Origin': r'https://sou.zhaopin.com',
'Referer': r'https://sou.zhaopin.com/?jl='+self.city+r'&sf=0&st=0&kw='+self.kw+r'&kt=3',
'Sec-Fetch-Mode': r'cors',
'User-Agent': r'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.132 Safari/537.36',
}
#对于非第一页修改url继续爬取
if p:
self.params['start'] = str((p-1)*90)
self.headers['Referer'] = r'https://sou.zhaopin.com/?p='+str(p)+r'&jl='+self.city+r'&sf=0&st=0&kw='+self.kw+r'&kt=3'
async def asyncget(self):
async with aiohttp.ClientSession() as session:
async with session.get(url=self.url,params=self.params,headers=self.headers) as resp:
response = await resp.json()
return(response)
async def getdata(self):
response = await self.asyncget()
print('{} 的 {} 职位 {} 个'\
.format(self.citydic[self.city],self.kw,str(response['data']['count'])))
self.p = math.ceil(response['data']['count']/90)
self.data += response['data']['results']
for i in range(2,self.p+1):
_ = Capturer(self.kw, self.city, i)
self.getlist.append(_.asyncget())
tasks = [asyncio.ensure_future(i) for i in self.getlist]
dones, pendings = await asyncio.wait(tasks)
for task in dones:
self.data += task.result()['data']['results']
print('{} 的 {} 职位共找到 {} 个'\
.format(self.citydic[self.city],self.kw,len(self.data)))
self.data.append([self.citydic[self.city],self.kw])
return self.data
class DataProcessor():
'''数据处理'''
def __init__(self):
self.data = '地点\t语言\t公司\tbase\t职位\t薪资\t学历\t工作年限\t网址\n'
def datacleaning(self,datalist):
for tasks_data in datalist:
data_from = tasks_data[-1]
for job_data in tasks_data[:-1]:
cleanup = copy.deepcopy(data_from)
cleanup.append(job_data.setdefault('company',{}).setdefault('name',''))
cleanup.append(job_data.setdefault('businessArea',''))
cleanup.append(job_data.setdefault('jobName',''))
cleanup.append(job_data.setdefault('salary',''))
cleanup.append(job_data.setdefault('eduLevel',{}).setdefault('name',''))
cleanup.append(job_data.setdefault('workingExp',{}).setdefault('name',''))
cleanup.append(job_data.setdefault('positionURL','')+'l\n')
self.data += '\t'.join(cleanup)
with open('data.txt','w',encoding='utf-8') as f:
f.write(self.data)
# ~ def get_params():
# ~ random_str = str(random.random())
# ~ md5 = hashlib.md5()
# ~ md5.update(random_str.encode('utf-8'))
# ~ request_id = '{}-{}-{}'.format((md5.hexdigest()),int(time.time() * 1000),int(random.random() * 1000000))
# ~ v = str(random_str[0:10])
# ~ return request_id, v
# ~ def get_client_id():
# ~ headers = {
# ~ 'Accept': r'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3',
# ~ 'accept-encoding': r'gzip, deflate, br',
# ~ 'accept-language': r'zh-CN,zh;q=0.9',
# ~ 'cache-control': r'max-age=0',
# ~ 'referer': r'https://www.zhaopin.com/',
# ~ 'sec-fetch-mode': r'navigate',
# ~ 'sec-fetch-site': r'same-origin',
# ~ 'sec-fetch-user': r'?1',
# ~ 'upgrade-insecure-requests': r'1',
# ~ 'user-agent': r'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36',
# ~ }
# ~ params = {
# ~ 'jl': '703',
# ~ 'kw': 'python',
# ~ 'kt': '3'
# ~ }
# ~ url = r'https://sou.zhaopin.com'
# ~ response = requests.get(url=url, headers=headers, params=params)
# ~ for k,v in response.cookies.items():
# ~ if k == 'x-zp-client-id':
# ~ return v
def run():
# ~ global client_id, request_id, v
# ~ client_id = get_client_id()
# ~ request_id, v = get_params()
dp = DataProcessor()
c_1 = Capturer(kw='python', city='703')
c_2 = Capturer(kw='python', city='538')
c_3 = Capturer(kw='java', city='703')
c_4 = Capturer(kw='java', city='538')
coroutine1, coroutine2, coroutine3, coroutine4 = \
c_1.getdata(), c_2.getdata(), c_3.getdata(), c_4.getdata()
tasks = [asyncio.ensure_future(i) for i in [coroutine1, coroutine2, coroutine3, coroutine4]]
loop = asyncio.get_event_loop()
loop.run_until_complete(asyncio.wait(tasks))
datalist = [i.result() for i in tasks]
dp.datacleaning(datalist)
run()
事后
1)最初没使用aiohttp模块,而是使用的async关键字封装了requests模块的get方法,发现虽然可以封装tasks扔进loop中,但是由于内部io是阻塞的,所以实际运行并没有实现并发。所以关键不在于async关键字声明,而是io是否是非阻塞。
2)关于参数的_v;x-zp-page-request-id;x-zp-client-id,代码注释掉的部分是获取他们的函数,但是发现无论是用相同的还是不同的,都会导致ip被ban,并且_v和x-zp-page-request-id似乎还有关联。最终代码使用的是某次正常访问用开发者工具查到的值。没研究透智联的反爬虫策略,应对这种反爬果然还是要靠ip池。代码注释保留了,将来有空再研究研究。
需要掌握的新姿势
1)研究如何获取x-zp-client-id时发现第一次访问智联主页(https://www.zhaopin.com/)时只有一个Set-Cookie,键是acw_tc,再次访问会有很多Cookie,包括x-zp-client-id,考虑是js生成的,具体机制需要搞明白。
2)对于这种怎么获取后续的Cookie。