python利用selenium爬取京东数据
一直以来都是看别人博客学习,这次就自己发个,回馈回馈
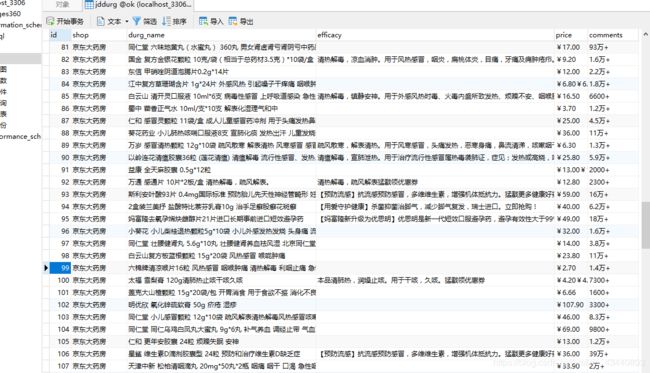
先放上成功图,表示可用(末尾有打包的百度云链接供下载测试)

需要的模块,selenium pyquery,pymysql,还需要谷歌浏览器及其chromedriver
京东大药房药品数据,是js渲染,用requests只能抓取静态页面,动态页面无法扑着,可以用selenium自动化模拟登陆页面,这样就做到可见及可爬,废话不多说,开干!
放上 京东大药房:链接
第一步,打开页面F12即开发者工具,查看源码。找到药品信息节点。
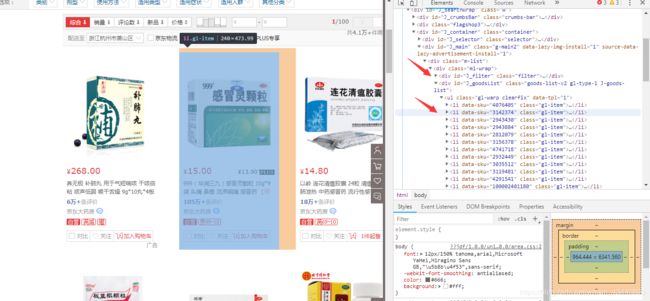
然后就是抓取药品信息,如店铺名,药效,价格,评论人数等等
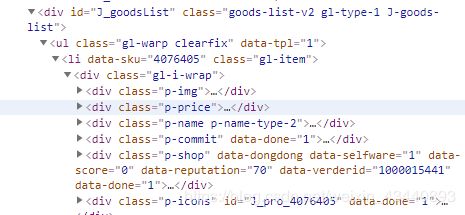
知道位子了,那就可以写代码了
from selenium import webdriver
from pyquery import PyQuery as pq
browser = webdriver.Chrome()
html = browser.page_source
doc = pq(html)
items = doc('#J_goodsList li').items()
for item in items:
shop = item('.p-shop').text() #店铺名
durg_name = item('.p-name em').text() #药品名
efficacy = item('.p-name .promo-words').text() #疗效
price = item('.p-price').text() #价格
comments = item('.p-commit a').text() #评论人数
print(shop,durg_name,efficacy,price,comments)
这是一个页面的抓取,翻页,那就需要selenium自动帮我们做了。
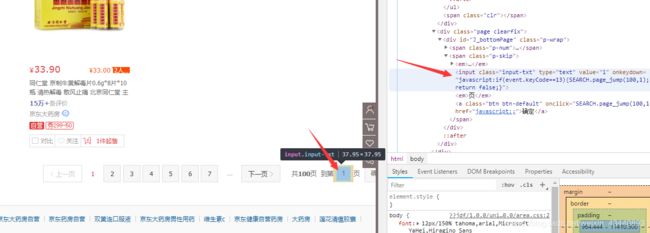
这里可以点下一页,也可以输入页码进行跳转,我们这用输入页码来进行翻页,然后点击确定翻页,但难受的是,很多时候执行一次达不到预期效果,所以在这要进行一次是否翻页成功判断
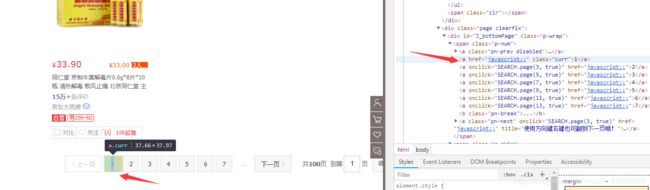
如上图所示,判断页面是否在是我们所要的,ok思路有了那就写吧
import time
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
from selenium.common.exceptions import TimeoutException,StaleElementReferenceException,ElementNotInteractableException
if page > 1:
input = wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR,'#J_bottomPage .p-skip > input')) #找到输入页码的地方
)
submit = wait.until(
EC.element_to_be_clickable((By.CSS_SELECTOR,'#J_bottomPage .p-skip > a')) #找到确定按钮
)
input.clear() #清空
input.send_keys(page) #输入页码
submit.click() #点击进行翻页
wait.until(
EC.text_to_be_present_in_element((By.CSS_SELECTOR,'#J_bottomPage .p-num > a.curr'),str(page))
) #比较当面页面是否是我们想要的页面
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,'#J_goodsList li')))
browser.execute_script('window.scrollTo(0,document.body.scrollHeight)') #用js进行下拉操作,如不这样,有部分数据加载不出来
time.sleep(2)
get_products()
except TimeoutException:
print('出错,重新爬取')
index_page(page)
except StaleElementReferenceException:
print('等待刷新,重新爬取')
index_page(page)
except ElementNotInteractableException:
print('不可交互,重新爬取')
index_page(page)
好了,让我们把抓取的数据放到数据库里吧!单独写个,以后就不用在写,干净整洁
import pymysql
import threading
from settings import MYSQL_HOST, MYSQL_DB, MYSQL_PWD, MYSQL_USER
class DataManager():
# 单例模式,确保每次实例化都调用一个对象。
_instance_lock = threading.Lock()
def __new__(cls, *args, **kwargs):
if not hasattr(DataManager, "_instance"):
with DataManager._instance_lock:
DataManager._instance = object.__new__(cls)
return DataManager._instance
return DataManager._instance
def __init__(self):
# 建立连接
self.conn = pymysql.connect(MYSQL_HOST, MYSQL_USER, MYSQL_PWD, MYSQL_DB, charset='utf8')
# 建立游标
self.cursor = self.conn.cursor()
def save_data(self, data):
# 数据库操作----写入
sql = 'insert into jddurg(shop,durg_name,efficacy,price,comments) values(%s,%s,%s,%s,%s)'
try:
self.cursor.execute(sql, data)
print('保存成功!恭喜!')
self.conn.commit()
except Exception as e:
print('插入数据失败!', e)
self.conn.rollback() # 回滚
def __del__(self):
# 关闭游标
self.cursor.close()
# 关闭连接
'''
数据库建表格
CREATE TABLE `jddurg` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`shop` varchar(20) DEFAULT NULL,
`durg_name` varchar(100) DEFAULT NULL,
`efficacy` varchar(150) DEFAULT NULL,
`price` varchar(50) DEFAULT NULL,
`comments` varchar(50) DEFAULT NULL,
PRIMARY KEY (`id`)
)
'''
配置文件,也单独拉出来,方便以后嘛
# 该文件存储项目中的所有配置参数
MYSQL_HOST = '127.0.0.1' #地址
MYSQL_USER = 'root' #数据库账户
MYSQL_PWD = '123456' #数据库密码
MYSQL_DB = 'ok' #数据库名
好了爬虫那段逻辑我在这整理一下
import time
from mysqldb import DataManager
from selenium import webdriver
from pyquery import PyQuery as pq
from selenium.webdriver.common.by import By
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.support.wait import WebDriverWait
from selenium.common.exceptions import TimeoutException,StaleElementReferenceException,ElementNotInteractableException
browser = webdriver.Chrome()
wait = WebDriverWait(browser,10) #最多等待时间
db = DataManager()
def index_page(page):
'''
自动切换页码
:param page: 当前页码
'''
print('正在爬取第',page,'页')
try:
url = 'https://search.jd.com/Search?keyword=%E4%BA%AC%E4%B8%9C%E5%A4%A7%E8%8D%AF%E6%88%BF&enc=utf-8&pvid=20ed755a83784fd5b13356e7bb8f2008'
browser.get(url)
if page > 1:
input = wait.until(
EC.presence_of_element_located((By.CSS_SELECTOR,'#J_bottomPage .p-skip > input')) #找到输入页码的地方
)
submit = wait.until(
EC.element_to_be_clickable((By.CSS_SELECTOR,'#J_bottomPage .p-skip > a')) #找到确定按钮
)
input.clear() #清空
input.send_keys(page) #输入页码
submit.click() #点击进行翻页
wait.until(
EC.text_to_be_present_in_element((By.CSS_SELECTOR,'#J_bottomPage .p-num > a.curr'),str(page))
) #比较当面页面是否是我们想要的页面
wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,'#J_goodsList li')))
browser.execute_script('window.scrollTo(0,document.body.scrollHeight)') #用js进行下拉操作,如不这样,有部分数据加载不出来
time.sleep(2)
get_products()
except TimeoutException:
print('出错,重新爬取')
index_page(page)
except StaleElementReferenceException:
print('等待刷新,重新爬取')
index_page(page)
except ElementNotInteractableException:
print('不可交互,重新爬取')
index_page(page)
def get_products():
'''
爬取药品信息
'''
html = browser.page_source
doc = pq(html)
items = doc('#J_goodsList li').items()
for item in items:
shop = item('.p-shop').text() #店铺名
durg_name = item('.p-name em').text() #药品名
efficacy = item('.p-name .promo-words').text() #疗效
price = item('.p-price').text() #价格
comments = item('.p-commit a').text() #评论人数
print(shop,durg_name,efficacy,price,comments)
product = [
shop,durg_name,efficacy,price,comments
]
db.save_data(product)
if __name__ == '__main__':
page = 3 #最多100页
for i in range(1,(page+1)):
index_page(i)
文件打包百度云,自己测试玩玩吧:百度云 密码:kh7i