从浏览器地址栏输入url到页面显示的过程
文章目录
- 1、输入地址(回车前)
- 2、浏览器查看缓存(回车后)
- 3、URL解析/域名解析
- 4、浏览器与目标服务器建立TCP连接(tcp三次握手)
- 5、浏览器通过http协议向目标服务器发送请求
- 6、服务器处理请求并返回HTTP报文
- 7、断开连接
- 8、浏览器解析渲染页面(HTML解析过程中会逐步显示页面)
1、输入地址(回车前)
当我们开始在浏览器中输入网址的时候,浏览器可能会做一些预处理,已经在智能的匹配可能得 url 了,他会从历史记录,书签等地方,找到已经输入的字符串可能对应的URL,来预估所输入字符对应的网站,然后给出智能提示,比如输入了「ba」,根据之前的历史发现 90% 的概率会访问「www.baidu.com 」,
因此就会在输入回车前就马上开始建立 TCP 链接了。对于 Chrome这种变态的浏览器,他甚至会直接从缓存中把网页渲染出来,就是说,你还没有按下「回车」键,页面就已经出来了;
2、浏览器查看缓存(回车后)
2.1如果资源未缓存,发起新的http请求;
2.2如果已缓存,检验是否足够”新鲜”,足够”新鲜”直接提供给客户端,否则发送http请求与服务器进行验证。
检验”新鲜”通常有两个HTTP头进行控制Expires和Cache-Control:
HTTP1.0提供Expires,值为一个绝对时间表示缓存”新鲜”日期;
HTTP1.1增加了Cache-Control: max-age=,值为以秒为单位的最大”新鲜”时间;
PS:关于浏览器缓存可参考:
https://blog.csdn.net/LANNY8588/article/details/85054338
https://www.sohu.com/a/260358906_658302
https://imweb.io/topic/5795dcb6fb312541492eda8c
https://imweb.io/topic/55c6f9bac222e3af6ce235b9
3、URL解析/域名解析
3.1完整的URL由这几部分构成:协议、网络地址、资源路径、文件名、动态参数,
URL完整格式为:协议://用户名:密码@子域名.域名.顶级域名:端口号/目录/文件名.文件后缀?参数=值#标志
例如:https://www.zhihu.com/question/55998388/answer/166987812
协议部分:https
网络地址:www.zhihu.com(依次为 子/三级域名.二级域名.顶/一级域名)
资源路径:/question/55998388/answer/166987812
浏览器对 URL 进行检查时首先判断协议,如果是 http/https 就按照 Web 来处理,另外还会对 URL 进行安全检查,然后直接调用浏览器内核中的对应方法,接下来是对网络地址进行处理,如果地址不是一个IP地址而是域名则通过DNS(域名系统)将该地址解析成IP地址。
3.2在发送http之前,需要进行DNS解析即域名解析,DNS服务器都会存在缓存。
通过域名查找IP地址的过程:
浏览器缓存→操作系统缓存→hosts文件→路由缓存→ISP DNS缓存(本地名称服务器)→DNS查询 (DNS服务器查询更新到:https://blog.csdn.net/weixin_43828011/article/details/98627764)
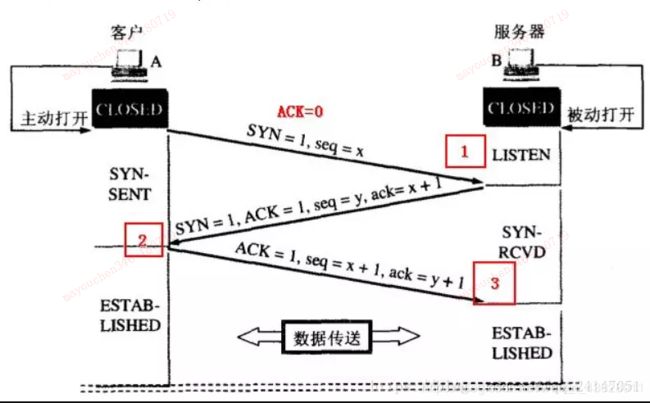
4、浏览器与目标服务器建立TCP连接(tcp三次握手)
(1)客户端向服务器发送连接请求报文;
(2)服务器端接受客户端发送的连接请求后后回复ACK报文,并为这次连接分配资源。
(3)客户端接收到ACK报文后也向服务器端发生ACK报文,并分配资源。
5、浏览器通过http协议向目标服务器发送请求
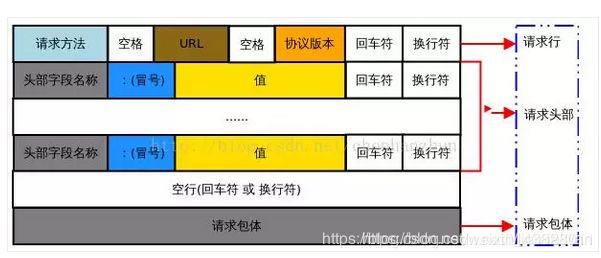
Http请求报文,由4个部分组成(包含一个空行):
(1)请求行 (request-line)请求行包含了请求的方法,资源的位置,以及协议的版本,举个例子:GET /index.html HTTP/1.1
(2)请求头部 (headers)头部是有多个 Key-Value 组成的
(3)空行 (blank line)这个空行是一定要有的,它是用来区分请求头部和请求数据的,它代表着不再有头部的 Key-Value 键值对,接下来是请求数据了
(4)请求数据 (request-body)请求主体一般是用于 POST 方法提交数据
实例:
//请求首行
GET /hello/index.jsp HTTP/1.1
//请求头信息,因为GET请求没有正文
Host: localhost
User-Agent: Mozilla/5.0 (Windows NT 5.1; rv:5.0) Gecko/20100101 Firefox/5.0
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: zh-cn,zh;q=0.5
Accept-Encoding: gzip, deflate
Accept-Charset: GB2312,utf-8;q=0.7,*;q=0.7
Connection: keep-alive
Cookie: JSESSIONID=369766FDF6220F7803433C0B2DE36D98
//空行
//因为GET没有正文,所以下面为空
6、服务器处理请求并返回HTTP报文
服务器接受请求并解析,将请求转发到服务程序,服务端脚本处理我们的请求,访问我们的数据库,获取需要获取的内容等等,然后会把它的处理结果返回,也就是返回一个HTPP响应;
HTTP响应也由4个部分构成:
(1)状态行 (status-line)状态行中包含着协议版本,状态码以及文本描述,状态码和文本描述就代表了服务器所返回的响应结果是怎样的
(2)响应头部 (headers)与请求头部类似,也是 Key-Value 键值对的组合;
(3)空行 (blank line)用来分隔响应头部和响应正文;
(4)响应正文,如果之前请求的是数据,就返回数据,如果请求的是网页,就返回HTML代码;
6.1常用的状态码:
1xx:信息性状态码,表示服务器已接收了客户端请求,客户端可继续发送请求。
100 Continue
101 Switching Protocols
2xx:成功状态码,表示服务器已成功接收到请求并进行处理。
200 OK 表示客户端请求成功
204 No Content 成功,但不返回任何实体的主体部分
206 Partial Content 成功执行了一个范围(Range)请求
3xx:重定向状态码,表示服务器要求客户端重定向。
301 Moved Permanently 永久性重定向,响应报文的Location首部应该有该资源的新URL,客户端浏览器收到重定向响应报文后,将发起一个向新地址的请求;
302 Found 临时性重定向,与301类似,但是,客户端应该使用Location首部给出的URL来临时定位资源,将来的请求仍应使用老的URL
303 See Other 请求的资源存在着另一个URI,客户端应使用GET方法定向获取请求的资源
304 Not Modified 服务器内容没有更新,可以直接读取浏览器缓存
307 Temporary Redirect 临时重定向。与302 Found含义一样。302禁止POST变换为GET,但实际使用时并不一定,307则更多浏览器可能会遵循这一标准,但也依赖于浏览器具体实现
4xx:客户端错误状态码,表示客户端的请求有非法内容。
400 Bad Request 表示客户端请求有语法错误,不能被服务器所理解
401 Unauthonzed 表示请求未经授权,该状态代码必须与 WWW-Authenticate 报头域一起使用
403 Forbidden 表示服务器收到请求,但是拒绝提供服务,通常会在响应正文中给出不提供服务的原因
404 Not Found 请求的资源不存在,例如,输入了错误的URL
5xx:服务器错误状态码,表示服务器未能正常处理客户端的请求而出现意外错误。
500 Internel Server Error 表示服务器发生不可预期的错误,导致无法完成客户端的请求
503 Service Unavailable 表示服务器当前不能够处理客户端的请求,在一段时间之后,服务器可能会恢复正常
7、断开连接
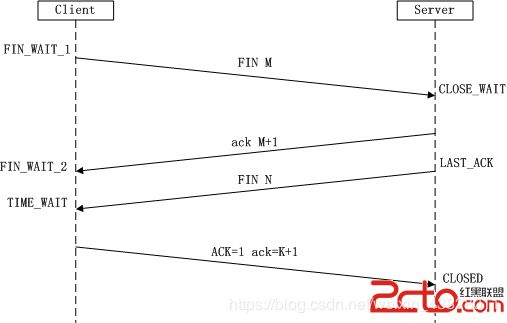
数据传送完,需断开tcp连接,此时发起tcp四次挥手;
第一次挥手:Client发送一个FIN,用来关闭Client到Server的数据传送,Client进入FIN_WAIT_1状态。
第二次挥手:Server收到FIN后,发送一个ACK给Client,确认序号为收到序号+1(与SYN相同,一个FIN占用一个序号),Server进入CLOSE_WAIT状态。
第三次挥手:Server发送一个FIN,用来关闭Server到Client的数据传送,Server进入LAST_ACK状态。
第四次挥手:Client收到FIN后,Client进入TIME_WAIT状态,接着发送一个ACK给Server,确认序号为收到序号+1,Server进入CLOSED状态,完成四次挥手。
8、浏览器解析渲染页面(HTML解析过程中会逐步显示页面)
当服务器提供了资源之后(HTML,CSS,JS,图片等),浏览器会执行下面的操作:
解析 —— HTML,CSS,JS
渲染 —— 构建 DOM 树 -> 渲染 -> 布局 -> 绘制
浏览器收到http响应后,判断http响应状态码,当得到一个正确的200响应之后然后进行编码解析;构建dom树,根据css样式和dom树,构建渲染树,执行js脚本,这些操作没有严格的先后顺序
浏览器在解析html文件时,会”自上而下“加载,并在加载过程中进行解析渲染。在解析过程中,如果遇到请求外部资源时,如图片、外链的CSS、iconfont等,请求过程是异步的,并不会影响html文档进行加载。
解析过程中,浏览器首先会解析HTML文件构建DOM树,然后解析CSS文件构建渲染树,等到渲染树构建完成后,浏览器开始布局渲染树并将其绘制到屏幕上。这个过程比较复杂,涉及到两个概念: reflow(回流)和repain(重绘)。
DOM节点中的各个元素都是以盒模型的形式存在,这些都需要浏览器去计算其位置和大小等,这个过程称为relow;
当盒模型的位置,大小以及其他属性,如颜色,字体,等确定下来之后,浏览器便开始绘制内容,这个过程称为repain。
页面在首次加载时必然会经历reflow和repain。reflow和repain过程是非常消耗性能的,尤其是在移动设备上,它会破坏用户体验,有时会造成页面卡顿。所以我们应该尽可能少的减少reflow和repain。
当文档加载过程中遇到js文件,html文档会挂起渲染(加载解析渲染同步)的线程,不仅要等待文档中js文件加载完毕,还要等待解析执行完毕,才可以恢复html文档的渲染线程。
(因为JS有可能会修改DOM,最为经典的document.write,这意味着,在JS执行完成前,后续所有资源的下载可能是没有必要的,这是js阻塞后续资源下载的根本原因。所以我明平时的代码中,js是放在html文档末尾的。)
JS的解析是由浏览器中的JS解析引擎完成的,比如谷歌的是V8。JS是单线程运行,也就是说,在同一个时间内只能做一件事,所有的任务都需要排队,前一个任务结束,后一个任务才能开始。但是又存在某些任务比较耗时,如IO读写等,所以需要一种机制可以先执行排在后面的任务,这就是:同步任务(synchronous)和异步任务(asynchronous)。
9、浏览器发送请求获取嵌入在 HTML 中的资源(如图片、音频、视频、CSS、JS等等)
其实这个步骤可以并列在步骤8中,在浏览器显示HTML时,它会注意到需要获取其他地址内容的标签。这时,浏览器会发送一个获取请求来重新获得这些文件。比如我要获取外图片,CSS,JS文件等,类似于下面的链接:
图片:http://static.ak.fbcdn.net/rsrc.php/z12E0/hash/8q2anwu7.gif
CSS式样表:http://static.ak.fbcdn.net/rsrc.php/z448Z/hash/2plh8s4n.css
JavaScript 文件:http://static.ak.fbcdn.net/rsrc.php/zEMOA/hash/c8yzb6ub.js
这些地址都要经历一个和HTML读取类似的过程。所以浏览器会在DNS中查找这些域名,发送请求,重定向等等…
不像动态页面,静态文件会允许浏览器对其进行缓存。有的文件可能会不需要与服务器通讯,而从缓存中直接读取,或者可以放到CDN中。