python 爬虫/隐藏
网络爬虫:
网络类似于蜘蛛网 ,爬虫就是蜘蛛️
那么python 要访问互联网 ,怎么联网?
python有自己的“电池”: url + lib 形成 urllib
协议: + hostname + post + path (+…)

简单的爬取一张喵星人图片:
import urllib.request
response = urllib.request.urlopen("http://placekitten.com/400/400")
html = response.read()
#with 可以使我们不用自己关闭描述符f
with open('miao2.jpg','wb') as f:
f.write(html)

response = urllib.request.urlopne(url) 原理就是下边的代码:
或者
url = urllib.request.Request(url) 得到一个Request类型 url对象
response = urllib.request.urlopen(url)
我们写第一种方法,他会默认先生成Request对象 ,再调用 urlopen
那我们来模拟一下python 爬虫的响应:
首先我们知道: python 的爬虫需要进行: urllib.request.urlopen()函数。
之前正常访问 ,我们只需带一个URL 作为参数 ,
现在我们模拟回应,参数设为两个。

此时默认的get 方法,变为Post方法了。

我们打印的其实是一个字符串, 其实是一个json 结构
关于谷歌浏览器审查元素不显示method 直接右击,在添加method 即可
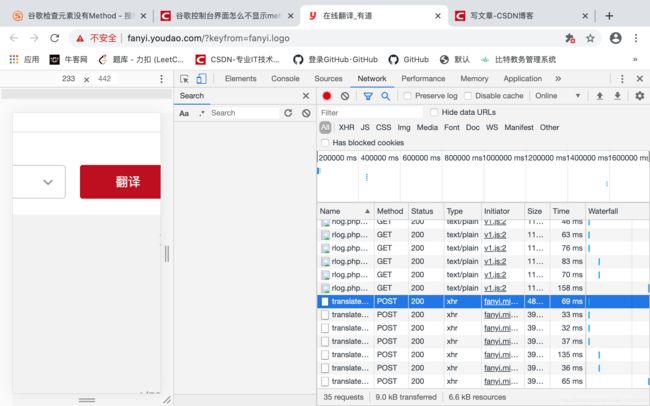
response(接收到的响应)的方法

getcode() 状态码
info()相关报文信息
geturl (获取网址)
parse 模块
import urllib.parse
parse是一个独立的解析模块 ,像urlencode urldecode这种都在内部
python 默认是unicode 编码方式,
有的平台需要将urlencode的unicode 编码在进行转变才能使用
data 为一个字典,这里需要将其编码:
data = urllib.parse.urlencode(data).encode(‘utf-8’)
eg: response = urllib.request.urlopen(url, data)
encode : 将unicode 编码成 encode 内的方式
decode : 将其他编码方式 转化为unicode 编码方式。
反爬虫机制
很多服务器端上都有反爬虫机制, 因为代码访问服务器频率是非常高的,容易导致服务器崩溃。 因此 ,服务器需要进行识别是人工访问还是代码访问。 : 称为反爬虫机制
那么服务器怎么识别呢?
还是依靠 header中的 user-Agent: 进行识别 , 另外还会在服务器上维护一个单位时间的访问率 ,根据这些来识别是代码访问,还是人工正常访问。
这就是一个正常访问了:

具体怎么做呢? -->验证码
来看看访问和接受响应对应的包信息
先来看 Post 响应数据包(post)信息


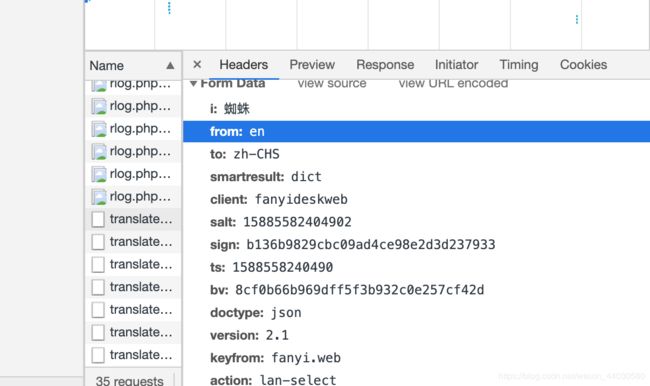

再来看 接受访问包(Get)的信息:
**响应数据包并不存在Form Data**



隐藏方式有两种方式:
方式一: 增加User-Agent:
1 在Request 对象生成之前设置User-Agent项
2 在Request 对象生成之后 增加 add_header =(key, value) // addheaders[(key, value)]
同时在代码中加入睡眠机制: sleep(4);
方式二:使用代理 proxy
什么是代理?
简单讲; 就是你干不了的事情他来做 ,你的爬虫访问不了,那么你使用代理,代理去访问 你去查看结果就行。 服务器看到的是代理的地址。
那么我们可以使用很多个代理同时去去访问代理
代理的步骤:
第一步; 设置一个字典:{‘类型’ : ‘代理IP : 端口’}
注: 代理IP 可以网上搜,有免费的
proxy_support = urllib.request.ProxyHandler({}); //参数是字典
第二步: 创建一个 opener (私人订制)
opener = urllib.request.build_opener(proxy_support)
第三步: 安装 opener
a: 一劳永逸工作:永久代理:opener: urllib.request.install_opener(opener)
b: opener.open(url)
use :
使用:
urllib.request.urlopen(url)
代码如下:
注意: 不一定能成功: 跟代理还有很大关系
