机器学习之逻辑回归
一、前言:
logistic回归又称为逻辑回归,是经典的二分类算法,虽然其名称中含有“回归”一词,但其并不是用于回归,而是主要用于分类,其决策边界可以是非线性的。
二、Sigmoid函数
- 公式:
g ( z ) = 1 1 + e ( − z ) (1) g(z) = \frac{1}{1 + e ^{(-z)} } \tag{1} g(z)=1+e(−z)1(1)
其中·e为欧拉常数, z z z为自变量(实际为样本特征值的线性组合), z = W T X = w 0 x 0 + w 1 x 1 + . . . + w n x n z = W^TX = w_0x_{0} + w_1x_{1}+...+w_nx_{n} z=WTX=w0x0+w1x1+...+wnxn。 - 函数图像:

- 函数特点:Sigmoid函数定义域为[- ∞ \infty ∞,+ ∞ \infty ∞],值域为[0,1],即无论输入任何值 z z z,总可以将结果映射到0~1区间内,很明显它可以作为概率分类。
三、推导
假设我们有1 * m个样本为 Y Y Y,则:
Y = [ y 0 y 1 . . . y n ] Y = \begin{bmatrix} y_0 & y_1 & ... & y_n \\ \end{bmatrix} Y=[y0y1...yn]
y 0 、 y 1 、 y 2 、 . . . 、 y n y_0、y_1、y_2、...、y_n y0、y1、y2、...、yn分别为每个样本值。
设有n * m 的特征矩阵为 X X X:
X = ∣ x 11 x 12 . . . x 1 m x 21 x 22 . . . x 2 m ⋮ ⋮ . . . ⋮ x n 1 x n 2 . . . x n m ∣ X = \begin{vmatrix} x_{11} & x_{12} & ... & x_{1m} \\x_{21} & x_{22}& ...& x_{2m}\\ \vdots & \vdots& ...& \vdots\\ x_{n1} & x_{n2}& ...& x_{nm}\\ \end{vmatrix} X=∣∣∣∣∣∣∣∣∣x11x21⋮xn1x12x22⋮xn2............x1mx2m⋮xnm∣∣∣∣∣∣∣∣∣
x i 1 、 x i 2 、 . . . 、 x i m x_{i1}、x_{i2}、...、x_{im} xi1、xi2、...、xim为每个样本的特征值。
一般为了得到偏置项 w 0 w_0 w0,我们一般在特征矩阵加一列 x i 0 x_{i0} xi0,一般将 x i 0 x_{i0} xi0设为1,则得到n * m+1 的特征矩阵 X X X:
X = ∣ 1 x 11 x 12 . . . x 1 m 1 x 21 x 22 . . . x 2 m ⋮ ⋮ ⋮ . . . ⋮ 1 x n 1 x n 2 . . . x n m ∣ X = \begin{vmatrix} 1 & x_{11} & x_{12} & ... & x_{1m} \\ 1 & x_{21} & x_{22}& ...& x_{2m}\\ \vdots & \vdots & \vdots& ...& \vdots\\ 1 & x_{n1} & x_{n2}& ...& x_{nm}\\ \end{vmatrix} X=∣∣∣∣∣∣∣∣∣11⋮1x11x21⋮xn1x12x22⋮xn2............x1mx2m⋮xnm∣∣∣∣∣∣∣∣∣
提醒一下,矩阵是从下标 x i 0 x_{i0} xi0开始,这里从 x i 0 x_{i0} xi0开始,为了方便看成矩阵。
则参数为1 * m+1的矩阵 W W W:
W = [ w 0 w 1 . . . w m ] W = \begin{bmatrix} w_0 & w_1 & ... & w_m \\ \end{bmatrix} W=[w0w1...wm]
w 1 、 w 2 、 . . . 、 w m w_1、w_2、...、w_m w1、w2、...、wm为权重系数, w 0 w_0 w0为偏置项,(一般称为截距)
三、如何将数据进行分类?
通过将每个样本的特征 x i x_i xi乘以一个回归参数 w i w_i wi,求和得 h w ( x i ) h_w(x_i) hw(xi),则:
h w ( x i ) = W X i T = w 0 x i 0 + w 1 x i 1 + . . . + w m x i m ,单个样本 (2) h_w(x_i) = WX_i^T= w_0x_{i0} + w_1x_{i1}+...+w_mx_{im} \tag{2} \text{,单个样本} hw(xi)=WXiT=w0xi0+w1xi1+...+wmxim,单个样本(2)
其中· h w ( x i ) h_w(x_i) hw(xi)表示第 i i i个样本的特征 x i x_i xi与 w i w_i wi的线性和, i ∈ { 1 、 2 、 . . . 、 n } i \in\lbrace 1、2、...、n\rbrace i∈{1、2、...、n},因为总共n个样本。
将每个样本的线性特征的累加和 h w ( x i ) h_w(x_i) hw(xi),作为自变量 z i z_i zi带入Sigmoid函数:
由题知: z i = h w ( x i ) (3) z_i = h_w(x_i) \tag{3} zi=hw(xi)(3)
带入 h w ( x i ) h_w(x_i) hw(xi):
g w ( z i ) = ( h w ( x i ) ) = 1 1 + e − h w ( x i ) g_w(z_i) =(h_w(x_i)) = \frac{1}{1 + e ^{-h_w(x_i)} } gw(zi)=(hw(xi))=1+e−hw(xi)1
为了便于推导理解,我们有:
p w ( x i ) = g w ( z i ) p_w(x_i) = g_w(z_i) pw(xi)=gw(zi)
p w ( z i ) p_w(z_i) pw(zi)表示每个样本的概率值,范围为[0,1],这样我们就将 h w ( x i ) h_w(x_i) hw(xi)映射到[0,1]区间上了。
为了便于以后计算我们把所有的样本 h w ( x i ) h_w(x_i) hw(xi)用一个矩阵 h w ( x ) h_w(x) hw(x)来表示,即:
h w ( x ) = W X T = [ h w ( x 1 ) h w ( x 2 ) . . . h w ( x n ) ] h_w(x) =WX^T = {\begin{bmatrix} h_w(x_1) & h_w(x_2)& ... & h_w(x_n)\\ \end{bmatrix} } hw(x)=WXT=[hw(x1)hw(x2)...hw(xn)]
四、由样本值到概率的的转换
我们将每个样本值 h w ( x i ) h_w(x_i) hw(xi)作为自变量带入Sigmoid函数中, h w ( x i ) h_w(x_i) hw(xi)被映射到了[0,1]区间,这样就完成了由值到概率的转换,假设我们取阈值为0.5,则任何大于0.5的数据被归为1类,小于0.5的数据被分归为0类,所以logistic回归也可以看成一种概率估计,根据题意知 z i = h w ( x i ) z_i = h_w(x_i) zi=hw(xi)。
p w ( x i ) = g ( h w ( x i ) ) = 1 1 + e ( − h w ( x i ) ) (3) p_w(x_i) = g(h_w(x_i)) =\frac{1}{1 + e ^{(-h_w(x_i))} }\tag{3} pw(xi)=g(hw(xi))=1+e(−hw(xi))1(3)
这里 p w ( x ) p_w(x) pw(x)为预测值,范围为0~1之间
根据Sigmoid图形可以看出,根据 p w ( x i ) p_w(x_i) pw(xi)的不同,可分为三种情况:
p w ( x ) = { p w ( x i ) > 0.5 , h w ( x i ) > 0,归为1类 p w ( x i ) = 0.5 , h w ( x i ) = 0,称为决策边界 p w ( x i ) < 0.5 , h w ( x i ) < 0,归为0类 p_w(x) = \begin{cases} p_w(x_i) > 0.5,& \text{$h_w(x_i)$ > 0,归为1类} \\ p_w(x_i)= 0.5,&\text{$h_w(x_i)$ = 0,称为决策边界}\\ p_w(x_i) < 0.5,& \text{$h_w(x_i)$ < 0,归为0类} \end{cases} pw(x)=⎩⎪⎨⎪⎧pw(xi)>0.5,pw(xi)=0.5,pw(xi)<0.5,hw(xi) > 0,归为1类hw(xi) = 0,称为决策边界hw(xi) < 0,归为0类
这里 i ∈ { 1 , 2 , . . . , n } i \in \lbrace1,2,...,n\rbrace i∈{1,2,...,n}表示第 i i i个样本的概率值.
当样本值 h w ( x i ) = W X i T = w 0 x i 0 + w 1 x i 1 + . . . + w m x i m = 0 h_w(x_i) = WX_i^T =w_0x_{i0} + w_1x_{i1}+...+w_mx_{im} = 0 hw(xi)=WXiT=w0xi0+w1xi1+...+wmxim=0时,
p ( 0 ) = 1 1 + e ( − 0 ) = 1 2 = 0.5 p(0) = \frac{1}{1 + e ^{(-0)} } = \frac{1}{2} = 0.5 p(0)=1+e(−0)1=21=0.5
p ( z ) p(z) p(z) = 0.5,即表示该样本既不属于1类也不属于0类,称为决策边界,我们一般用它来区分0类和1类。利用logistic函数最终求的结果只有两种可能要么是有y = 0类要么是y = 1类,这里的y表示样本的类别标签, p ( z i ) p(z_i) p(zi)表示y为0类或1类的概率。
从而我们假设y = 1或y = 0得概率分别为:
P ( y i = 1 ∣ x , w ) = h w ( x i ) ,表示为1类的概率 P(y_i = 1|x_,w) = h_w(x_i) \text{,表示为1类的概率} P(yi=1∣x,w)=hw(xi),表示为1类的概率
P ( y i = 0 ∣ x i , w ) = 1 − h w ( x i ) ,表示为0类的概率 P(y_i = 0|x_i,w) =1 - h_w(x_i) \text{,表示为0类的概率} P(yi=0∣xi,w)=1−hw(xi),表示为0类的概率
这里 y i y_i yi表示第 i i i个样本的类别标签,只有0或1两种可能, h w ( x i ) h_w(x_i) hw(xi)表示第 i i i个样本为1类的概率大小,则 1 − h w ( x i ) 1 - h_w(x_i) 1−hw(xi)为0类的概率,则 x i x_i xi表示第 i i i个样本的特征值, w w w表示参数矩阵,
由题意可知 y i y_i yi要么等于0,要么等于1:
P ( y i ∣ x i , w ) = { p w ( x i ) , 当 y i = 1时,表示为1类的概率 1 − p w ( x i ) , 当 y i = 0时,表示为0类的概率 P(y_i |x_i,w) = \begin{cases} p_w(x_i), & \text{当$y_i$ = 1时,表示为1类的概率} \\ 1 - p_w(x_i), & \text{当$y_i$ = 0时,表示为0类的概率} \end{cases} P(yi∣xi,w)={pw(xi),1−pw(xi),当yi = 1时,表示为1类的概率当yi = 0时,表示为0类的概率
为了便于求解我们将上式整合下面:
P ( y i ∣ x i , w ) = ( h w ( x i ) ) y i ( 1 − h w ( x i ) ) 1 − y i P(y_i |x_i,w) ={( h_w(x_i))}^{y_i}(1 - h_w(x_i))^{1 - y_i} P(yi∣xi,w)=(hw(xi))yi(1−hw(xi))1−yi
五、Logistic回归的优缺点:
优点:计算代价不高,易于理解和实现。
缺点:容易欠拟合,分类精度可能不高。
六、最大似然函数
说到这里,我们就是希望找到一组参数 w w w,使 p w ( x i ) p_w(x_i) pw(xi)预测得总体正确率最高,根据最大似然估计(这里涉及到概率论知识)就是所有样本预测正确的概率 p w ( x i ) p_w(x_i) pw(xi)相乘得到的总体 P ( y i ∣ x i , w ) P(y_i |x_i,w) P(yi∣xi,w)正确概率最大。
于是我们就得到 最 大 似 然 估 计 \color{red}{最大似然估计} 最大似然估计:
l ( w ) = 1 n ∏ i = 1 n P ( y i ∣ x i , w ) = 1 n ∏ i = 1 n ( p w ( x i ) ) y i ( 1 − p w ( x i ) ) 1 − y i l(w) =\frac{1}{n} \prod_{i=1}^{n}P(y_i |x_i,w) = \frac{1}{n}\prod_{i=1}^{n}{(p_w(x_i))}^{y_i} {(1 - p_w(x_i))}^{1 - y_i} l(w)=n1i=1∏nP(yi∣xi,w)=n1i=1∏n(pw(xi))yi(1−pw(xi))1−yi
其中, y ( x i ) y(x_i) y(xi)为根据参数 w w w和特征值 x x x预测出的分类标识。 y i ∈ { 0 , 1 } y_i \in \lbrace 0,1\rbrace yi∈{0,1} ,似然函数表示预测值正确的概率值,当似然函数的概率值最大时,即预测正确的可能性越高, w w w的值最优,还要注意我们的代价函数不管是最小二乘法、误差均方、似然函数等,都要求平均,就是前面加上 1 n \frac{1}{n} n1。
对于这种函数我们很难求解,所以要对其求对数得到 对 数 似 然 函 数 \color{red}{对数似然函数} 对数似然函数:
L ( w ) = l o g l ( w ) = 1 n ∑ i = 1 n y i l o g ( p w ( x i ) ) − ( 1 − y i ) l o g ( 1 − p w ( x i ) ) L(w) = logl(w) = \frac{1}{n}\sum_{i = 1}^n{y_ilog(p_w(x_i))} - (1 - y_i)log{(1 - p_w(x_i))} L(w)=logl(w)=n1i=1∑nyilog(pw(xi))−(1−yi)log(1−pw(xi))注意:到这就变成了求出对数似然的概率最大值。
我们本次主要使用梯度下降法求解参数W,前面要加个负号,即求对数依然的最小值,所以:
L ( w ) = 1 n ∑ i = 1 n ( − y i l o g ( p w ( x i ) ) − ( 1 − y ) l o g ( 1 − p w ( x i ) ) L(w) = \frac{1}{n}\sum_{i = 1}^n{(- y_ilog(p_w(x_i))} - (1 - y)log{(1 - p_w(x_i))} L(w)=n1i=1∑n(−yilog(pw(xi))−(1−y)log(1−pw(xi))
这个函数就是我们逻辑回归(logistics regression)的损失函数,我们叫它交叉熵损失函数,logistic回归问题就是根据训练样本求解代价函数在取得最小值的参数问题,此时有参数确定的分类界限可将两类样本相对准确的分开。
七、求解交叉熵损失函数
求损失函数的梯度部分同样是对损失函数求偏导,注意在求偏导时我们求的是梯度的累加和,所以我们要乘以 1 / n 1/n 1/n来取梯度的均值,考虑总体样本, (错误想法),( L ( w ) L(w) L(w)为代价函数求解出来的偏导就是其梯度,不存在累加和什么的,只存在 1 / n 1/n 1/n考虑总体样本)过程如下:(求解的偏导是关于 w w w的梯度,表示 w w w的梯度方向和倾斜程度)

我们注意到这个迭代公式和线性回归的迭代公式形式是一样的,只是在线性回归中 h w ( x i ) h_w(x_i) hw(xi)为 x i x_i xi的各维度线性叠加即 h w ( x i ) = W T x i h_w(x_i)=W^Tx_i hw(xi)=WTxi,而这里逻辑回归 x i x_i xi的各维度线性叠加 W T x i W^Tx_i WTxi以后,还要进行一次非线性映射(即logistic映射),非线性的映射到(0,1)之间即 p w ( x i ) p_w(x_i) pw(xi)。所以也可以认为logstic回归也是处理的线性问题,即也是求的各维度线性叠加的权重系数,只是求得了各维度线性叠加和以后,不是与 x i x_i xi所属的类别 y i y_i yi进行比较,而是非线性映射到所属类别的概率 p w ( x i ) p_w(x_i) pw(xi),然后最大似然函数法求模型参数 w w w(也就是那个各维度线性叠加的权重,而后面的非线性映射logstic那里没有参数),回归过程大概可以表示为:
逻辑回归主要过程: z = h w ( x ) = W T X z = h_w(x)= W^{T}X z=hw(x)=WTX, p w ( x ) = g ( z ) = g ( h w ( x ) ) p_{w}(x) = g(z) = g(h_w(x)) pw(x)=g(z)=g(hw(x)),即得出的特征与参数的线性组合 h w ( x ) h_w(x) hw(x)要带入Sigmoid函数,映射到[0,1]内,
而线性回归的过程: h w ( x ) = W T X h_{w}(x) = W^{T}X hw(x)=WTX。
w w w参数更新:
w i + 1 = w i − α 1 n ∑ i = 1 m ( p w ( x i ) − y i ) x i j i ∈ { 1 , 2 , . . . , n } , j ∈ { 0 , 1 , 2 , . . . , m } w_{i+1} = w_i - \alpha \frac{1}{n} \sum_{i = 1}^m(p_w(x_i) - y_i)x_i^j \\i \in \lbrace1,2,...,n\rbrace,j \in \lbrace0,1,2,...,m\rbrace wi+1=wi−αn1i=1∑m(pw(xi)−yi)xiji∈{1,2,...,n},j∈{0,1,2,...,m}
α \alpha α为梯度下降学习率即步长, w i w_i wi为当前位置, w i + 1 w_{i+1} wi+1为梯度的下一个位置, y i y_i yi表示样本的真实标签,也就是第 i i i个样本所属的类别(0或1), p w ( x i ) p_w(x_i) pw(xi)表示的是回归模型预测的第i个样本向量为1的概率, x i j x_i^j xij表示样本 x i x_i xi的第k个分量,并设 x i 0 = 1 x_i^0 = 1 xi0=1,
在这里要解释,对于求出的梯度值 1 n ∑ i = 1 m ( p w ( x i ) − y i ) x i j \frac{1}{n} \sum_{i = 1}^m(p_w(x_i) - y_i)x_i^j n1i=1∑m(pw(xi)−yi)xij
表示所有样本在权重为 w w w时的梯度之和并求均值目的是考虑整体样本,梯度的正负表示梯度的方向,梯度的模表示梯度的倾斜程度以及长度,乘以 α \alpha α学习率表示每次下降的步长, 1 n \frac{1}{n} n1可以不带,不影响求解。
所以权重的迭代更新公式为:
w i + 1 = w 1 − s t e p ∗ ∑ i = 1 m ( p w ( x i ) − y i ) x i j w_{i+1} = w_1- step * \sum_{i = 1}^m(p_w(x_i) - y_i)x_i^j wi+1=w1−step∗i=1∑m(pw(xi)−yi)xij
可以写成下面形式:
w i + 1 = w 1 − s t e p ∗ g r a d i e n t w w_{i+1} = w_1- step * gradient_w wi+1=w1−step∗gradientw
更新梯度值由 w i w_i wi到 w i + 1 w_i+1 wi+1, g r a d i e n t w gradient_w gradientw表示梯度方向和倾斜程度, w 1 w_1 w1不断减去梯度的方向,想象一个三维凹函数,不断地迭代, w i w_i wi的值不断地更新,一直往下降, w w w 值朝着梯度方向不断迭代。


七、代码精讲
下面我们说一个例子,通过sklearn库中datasets的API中的函数make_moons我们生成一个1000 * 2的矩阵 x x x,1 * 1000的矩阵 y y y,其中 y ∈ { 0 , 1 } y \in \lbrace 0,1\rbrace y∈{0,1},假设y的值由x值确定,求 y = w 0 x 0 + w 1 x 1 + w 2 x 2 y = w_0x_0+w_1x_1+w_2x_2 y=w0x0+w1x1+w2x2中, w 0 、 w 1 、 w 2 w_0、w_1、w_2 w0、w1、w2的值,其中 x 0 = 1 x_0 = 1 x0=1
首先生成实验数据
#生成实验数据
from sklearn.datasets import make_moons
import matplotlib as mpl
import matplotlib.pyplot as plt
x, y = make_moons(1000, noise = 0.3) #生成月亮形状的数据
cm_pt=mpl.colors.ListedColormap(['w', 'g']) #设置颜色映射
plt.scatter(x[:,0],x[:,1],c=y, cmap=cm_pt, marker='o',edgecolors='k')
plt.show()

2、定义Logistic回归类
#2.定义Logistic回归类
class LR:
def __init__(self):
self.w = np.zeros(3) #初始参数[w0,w1,w2] = [0,0,0],
#表示样本Xi各个元素叠加的权重系数,这里以向量形式表示,且初始都为0,三维向量
self.step = 0.2 #学习率alpha
def sigmoid(self, x): #sigmoid映射函数,值域-->[0,1],定义域-->[-infity,+infity]
return 1.0/(1+np.exp(-x))
def logistic_regression(self,x,y,step):#Logistic函数,核心
iter = 0#迭代计数
self.step = step #设置步长
row=np.shape(x)[0] #样本数row = 1000
while iter <= 1000: #迭代1000次(可设置)
#求取梯度
X = np.hstack([np.ones([row,1]),x]) #为求偏置项w0,特征矩阵第一列为1
fx = np.dot(self.w, X.T) #求出参数特征值的线性组合[h(x1),h(x2),...,h(xn)]。
#fx是一个列向量,每一个元素是每一个样本Xi的线性叠加和,因为X是所有的样本,因此这里不是一个一个样本算的,而是所有样本一块算的,因此fx是一个包含所有样本Xi的线性叠加和的向量。在公式中,是单个样本表示法,而在matlab中都是所有的样本一块来。
hx = self.sigmoid(fx) #调用Sigmoid函数使h(x_i)映射到区间[0,1]范围内,这个hx就是样本Xi所对应的yi=1时,映射的概率。如果一个样本Xi所对应的yi=0时,对应的映射概率写成1-h。
hx_y = (hx-y) #求出预测值与真实值概率的差值
hx_y_ext = np.vstack([hx_y.T, hx_y.T, hx_y.T]).T #在水平方向上连接矩阵
s = np.multiply(hx_y_ext,X) #表示矩阵对应元素相乘
gradient_w = np.mean(s, 0) #求和平取均值,求出损失函数L(x)
#更新参数
self.w -= self.step * gradient_w #更新梯度值由w_i到w_i+1
iter += 1 #计算迭代次数。
#3.实验结果:
lr = LR() #logistic类实例化
lr.logistic_regression(x,y,step = 0.5) #logistic回归
print(lr.w)#输出参数[w0,w1,w2]
-->[w0,w1,w2]=[0.28848812 1.29301211 -3.74713688]
那么问题来了,如何画出分类界限?
对于两分类问题,当 p w ( x ) > 0.5 p_w(x) > 0.5 pw(x)>0.5时将样本 x x x归为 1 1 1类,当 p w ( x ) > 0.5 p_w(x) > 0.5 pw(x)>0.5时将样本 x x x归为 0 0 0类,因此当 p w ( x ) = 0.5 p_w(x) = 0.5 pw(x)=0.5时,为分类界限既不属于 0 0 0类也不属于 1 1 1类。
p w ( x ) = 1 1 + e ( − h w ( x ) = 0 ) = 1 1 + e ( 0 ) = 1 2 = 0.5 p_w(x) = \frac{1}{1 + e ^{(-h_w(x) = 0)} }\\ = \frac{1}{1 + e ^{(0)} }\\ = \frac{1}{2}=0.5 pw(x)=1+e(−hw(x)=0)1=1+e(0)1=21=0.5
可以看出当 h w ( x ) = w 0 x 0 w 1 x 1 + w 2 x 2 + . . . + w n x n = 0 h_w(x) = w_0x_0w_1x_1 + w_2x_2 + ...+w_nx_n = 0 hw(x)=w0x0w1x1+w2x2+...+wnxn=0时, p w ( x ) = 0.5 p_w(x) = 0.5 pw(x)=0.5,可根据分类界限,绘制相应的分类直线。
所以根据上述公式,当 p ( x ) = 0.5 p(x)= 0.5 p(x)=0.5时,为分类界限,此时 h w ( x ) = w 0 x 0 + w 1 x 1 + w 2 x 2 = 0 h_w(x) = w_0x_0+w_1x_1 + w_2x_2 = 0 hw(x)=w0x0+w1x1+w2x2=0,又因为 x 0 = 1 x_0 = 1 x0=1, w 0 w_0 w0为偏置项,所以解方程可得:
x 2 = ( w 0 + w 1 x 1 ) / w 2 x_2 = (w_0 + w_1x_1)/w_2 x2=(w0+w1x1)/w2如果不理解可以将 x 2 x_2 x2也可以看成一元一次方程的 y y y,他是特征值 x 1 x_1 x1关于 x 2 x_2 x2的方程。
1、我们解出来以后发现,这个方程是一个直线方程: w 1 x 1 + w 1 x 1 x 2 + w 2 x 2 = 0 w_1x_1+w_1x_1x2+w_2x_2=0 w1x1+w1x1x2+w2x2=0 ,注意我们不能因为这个分界面是直线,就认为logistic回归是一个线性分类器,注意logistic回归不是一个分类器,他没有分类的功能,这个logistic回归是用来预测概率的,这里具有分类功能是因为我们硬性规定了一个分类标准:把 p w ( x i ) > 0.5 p_w(x_i)>0.5 pw(xi)>0.5的归为一类, p w ( x i ) < 0.5 p_w(x_i)<0.5 pw(xi)<0.5的归于另一类。这是一个很强的假设,因为本来我们可能预测了一个样本所属某个类别的概率是0.6,这是一个不怎么高的概率,但是我们还是把它预测为这个类别,只因为它 p w ( x i ) > 0.5 p_w(x_i)>0.5 pw(xi)>0.5.所以最后可能logistic回归加上这个假设以后形成的分类器的分界面对样本分类效果不是很好,这不能怪logistic回归,因为logistic回归本质不是用来分类的,而是求的概率。
2、那么分界面怎么画呢?
问题也就是在 x 1 x1 x1, x 2 x2 x2坐标图中找到那些将 w 1 x 1 1 w_1x_11 w1x11, w 2 x 2 w_2x_2 w2x2带入 1 ( 1 + e x p ( − w x ) ) \frac{1}{(1+exp(-wx))} (1+exp(−wx))1后,使其值 p w ( x i ) > 0.5 p_w(x_i)>0.5 pw(xi)>0.5的(x1,x2)坐标形成的区域,因为我们知道 1 ( 1 + e x p ( − w x ) ) > 0.5 \frac{1}{(1+exp(-wx))}>0.5 (1+exp(−wx))1>0.5意味着该区域的(x1,x2)表示为1类的概率大于0.5,那么其他的区域就是0类,那么 1 ( 1 + e x p ( − w x ) ) = 0.5 \frac{1}{(1+exp(-wx))}=0.5 (1+exp(−wx))1=0.5解出来的一个就是关于x1,x2的方程就是那个分界面。我们解出来以后发现,这个方程是一个直线方程: w 1 x 1 + w 1 x 1 x 2 + w 2 x 2 = 0 w_1x_1+w_1x_1x2+w_2x_2=0 w1x1+w1x1x2+w2x2=0 注意我们不能因为这个分界面是直线,就认为logistic回归是一个线性分类器,注意logistic回归不是一个分类器,他没有分类的功能,这个logistic回归是用来预测概率的,这里具有分类功能是因为我们硬性规定了一个分类标准:把>0.5的归为一类,<0.5的归于另一类。这是一个很强的假设,因为本来我们可能预测了一个样本所属某个类别的概率是0.6,这是一个不怎么高的概率,但是我们还是把它预测为这个类别,只因为它>0.5,所以最后可能logistic回归加上这个假设以后形成的分类器的分界面对样本分类效果不是很好,这不能怪logistic回归,因为logistic回归本质不是用来分类的,而是求的概率。
于是得到下面代码:
#定义结果显示函数如下
def show_result(self):#显示结果
x1 = np.linspace(-1, 2)
cm_pt=mpl.colors.ListedColormap(['w', 'g']) #设置颜色映射
plt.scatter(x[:,0],x[:,1],c=y,cmap=cm_pt,marker='o',edgecolors='k')
x2 = (self.w[1] * x1 + self.w[0])/(-self.w[2]) #根据p = 0.5所得,h(x) = 0解的方程。
plt.plot(x1,x2,'b-',linewidth=2)
plt.show()
#显示函数调用:
lr.show_result()
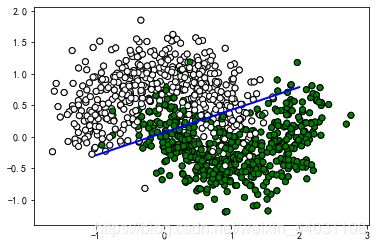
那么问题又来了如何根据样本预测该样本的类别?
很简单,按照上面的思路推就出来了,第一步根据所得特征值 x x x,乘以参数 w w w得到 h w ( x ) h_w(x) hw(x)带入Sigmoid函数,求得所得的概率 p w ( x ) p_w(x) pw(x),当 p w ( x ) > 0.5 p_w(x) > 0.5 pw(x)>0.5时将样本 x x x归为 1 1 1类,当 p w ( x ) > 0.5 p_w(x) > 0.5 pw(x)>0.5时将样本 x x x归为 0 0 0类,因此当 p w ( x ) = 0.5 p_w(x) = 0.5 pw(x)=0.5时,该样本正好处于分类界限位置,他既不属于 0 0 0类也不属于 1 1 1类。
def predict(self,x): #预测
row=np.shape(x)[0] #样本数
X = np.hstack([np.ones([row,1]),x])
fx = np.dot(self.w, X.T) #求代价函数梯度
P = self.sigmoid(fx) #sigmoid函数输出值
#利用阈值0.5进行分类
C = P.copy() #复制P值指向另一个内存,修改其值并不影响P值。
C[C >= 0.5] = 1
C[C < 0.5] = 0
return P, C
#显示函数调用:
P, C = lr.predict(x[1:5,:]) #预测4个样本的类别
print(P) #=> [ 0.9930546 0.21428264 0.01606024 0.69586661] #概率
print(C) #=> [ 1. 0. 0. 1.] #类别
整体代码:
from sklearn.datasets import make_moons
x, y = make_moons(1000, noise = 0.3) #产生数据
import matplotlib as mpl
import matplotlib.pyplot as plt
import numpy as np
cm_pt=mpl.colors.ListedColormap(['w', 'g']) #设置颜色映射
plt.scatter(x[:,0],x[:,1],c=y, cmap=cm_pt, marker='o',edgecolors='k')
#plt.show()
#2.定义Logistic回归类
class LR:
def __init__(self):
self.w = np.zeros(3) #初始参数[w0,w1,w2]
self.step = 0.2 #学习率
def sigmoid(self, x): #sigmoid函数
# print(x)
return 1.0/(1+np.exp(-x))
def logistic_regression(self,x,y,step):#Logistic函数
iter = 0#迭代计数
self.step = step #设置步长
row=np.shape(x)[0] #样本数
while iter <= 1: #迭代1000次(可设置)
#求取梯度
X = np.hstack([np.ones([row,1]),x])
fx = np.dot(self.w, X.T)
# print(fx)
hx = self.sigmoid(fx)
# print(hx)
hx_y = (hx-y)
hx_y_ext = np.vstack([hx_y.T, hx_y.T, hx_y.T]).T
# print(X.shape)
s = np.multiply(hx_y_ext,X) #矩阵对应位置相乘即样本的各个分量相乘
gradient_w = np.mean(s, 0) #axis = 0压缩行,对各列求和并取均值,求取梯度的均值,返回 3*1 矩阵
#更新参数
self.w -= self.step * gradient_w #利用梯度值,更新W参数值
iter += 1
#定义结果显示函数如下
def show_result(self,a):#显示结果
x1 = np.linspace(-1, 2)
# ro=np.shape(x1)[0] #样本数
cm_pt=mpl.colors.ListedColormap(['w', 'g']) #设置颜色映射
plt.scatter(x[:,0],x[:,1],c=y,cmap=cm_pt,marker='o',edgecolors='k')
# print(a.shape,ro)
# x2 = np.dot(self.w,np.hstack([np.ones([ro,1]),a]).T)
x2 = (self.w[1] * x1 + self.w[0])/(-self.w[2])
plt.plot(x1,x2,'b-',linewidth=2)
plt.show()
#预测样本
def predict(self,x): #预测
row=np.shape(x)[0] #样本数
X = np.hstack([np.ones([row,1]),x])
fx = np.dot(self.w, X.T)
P = self.sigmoid(fx) #sigmoid函数输出值
#利用阈值0.5进行分类
C = P.copy() #复制P的内容,使其指向另一个内存
C[C >= 0.5] = 1
C[C < 0.5] = 0
return P, C
#3.实验结果:
lr = LR() #logistic类实例化
lr.logistic_regression(x,y,step = 0.5) #logistic回归
#print("参数w:",lr.w)#输出参数[w0,w1,w2]
a, b = make_moons(50, noise = 0.3) #产生数据
#显示函数调用:
lr.show_result(a)
#[w0,w1,w2]=[0.28848812 1.29301211 -3.74713688]
#显示函数调用:
P, C = lr.predict(x[1:5,:]) #预测4个样本的类别
print("参数w:",lr.w)#输出参数[w0,w1,w2]
print("概率P:",P) # => [ 0.9930546 0.21428264 0.01606024 0.69586661] #概率
print("类别C:",C) #=> [ 1. 0. 0. 1.] #类别
结果:

参数w: [-0.00455566 0.2295211 -0.18620505]
概率P: [0.50581431 0.55949027 0.59123491 0.45818361]
类别C: [1. 1. 1. 0.]
参考链接:
1 - ->Logistic回归深入理解和matlab程序注释 -->新浪
2 - ->机器学习实战之Logistic回归
3 - ->Logistic回归 机器学习
4 - ->解释logistic回归为什么要使用sigmoid函数
5 - ->逻辑回归(logistics regression)
6 - - >梯度下降法
7 - ->机器学习逻辑回归
8 - - >机器学习logistic回归
9- - >Logistic回归
梯度下降法的三种形式BGD、SGD以及MBGD
线性回归、logistic回归、广义线性模型
10 - ->logistic