otter项目开源地址:https://github.com/alibaba/otter
otter双向回环: https://github.com/alibaba/otter/
canal项目开源地址:https://github.com/alibaba/canal
基本需求
支持mysql/oracle的异构数据库的双向回环,早期有变态需求:杭州是mysql,美国是oracle,需要做双向同步。
需要支持级联同步,比如A<->B->C,A同步到B的数据,不能从B回到A,但需要同步到C
实现思路
利用事务机制,在事务头和尾中插入otter同步标识
解析时识别同步标识,判断是否需要屏蔽同步
几点注意:
基于标准SQL实现
可以支持mysql/oracle等异构数据库的双向同步
事务完整解析&完整可见性
事务被拆开同步,会出现部分回环同步,数据不一致. 比如一个事务被拆分为了3截,中间一截因为没有事务头和尾的标识,如果发生同步了,就会导致数据不一致.
实现示意图
数据一致性:
技术选型分析
需要处理一致性的业务场景:
多地修改 (双A机房)
同一记录,同时变更
同一记录定义:具体到某一张表,某一条pk,某一字段
同时变更定义:A地写入的数据在B地还未可见的一段时间范围
基本思路
事前控制:比如paoxs协议,在多地数据写入各自数据存储之前,就已经决定好最后保留哪条记录
事后处理:指A/B两地修改的数据,已经保存到数据库之后,通过数据同步后保证两数据的一致性
事前控制
paxos协议,相信大家研究的人也比较多,但是它有一些局限性,就拿zookeeper来说,它使用了paxos的一个变种,但基本原理还是相似的。
我们拿zookeeper的几种部署模式来看:
1. 先看: A地部署leader/follower集群,B地部署observer.
此时A地收到数据后,需要的网络操作基本为同机房的leader/follower的paxos协议,耗时基本可控
此时B地收到数据后,需要的网络操作为:
B地接收到请求,转发给A地,一次机房网络
A地接收到请求,由leader转发给follower进行投票决策,同机房网络
A地leader将投票的结构,反馈给B地,一次机房网络.
这样一来,也就是说,事务时间 = 一次异地机房RTT + 同机房paxos算法耗时. 比如中美网络延迟200ms,那事务时间基本就是200ms+ 。 但此时,B地机房基本是一个只读镜像,读数据也有延迟,其系统写扩展性全在A机房,某一天当A机房不够用时,A机房进行拆分,就会遇到下一个问题。
2. 再看:A地和B地组成leader/follower
此时A第收到数据后,需要的网络操作为:(假如A不是leader,B是leader)
首先需要发送数据到B,一次机房网络
B收到A的提议数据后,发起一个投票到A,一次机房网络
A收到提议后,返回一个投票结果到B,一次机房网络
B收到大部分投票结果,做出决定之后,将结果反馈给A,一次网络交互.
这种理想无冲突的情况,总共会有2次RTT,如果优化A发起的提议自己默认投票,不返回给A进行投票,可以优化为1次RTT. 针对中美网络延迟200ms,那事务时间基本是200ms+. 如果A地和B地同时写入,那事务时间可能会翻倍。
总结:如果你能接受事务时间的影响(比如你A地和B地的网络延迟只有10ms),那是可以考虑选择paxos协议. 但目前otter所要解决的需求为中美200ms的RTT,暂时无法接收paxos协议来解决一致性问题.
事后处理
针对事后处理,不管哪种方案,一定会是一个最终一致性,因为在你做处理前,A地和B地的数据内容已经不一致了,你不论选择任何一个版本,对另一边来说都是一个数据版本丢失,最终一致性。
针对数据最终一致性处理,goldengate文档中提到了几种case :
trusted source. 信任站点,数据出现冲突时,永远以某一边为准覆盖另一边
timestamp,基于数据的修改时间戳,修改时间新的覆盖旧的数据
数据类型merge, 比如针对库存信息,A地库存减一,B地库存减二,两边同步之后A地和B地的数据应该是减三,合并两者减一和减二的操作
针对trusted source/timestamp模型,一定需要建立一个冲突数据kv表,(比如trusted source场景,如果B地修改了记录,而A地没修改此记录,那B地可以覆盖A地,即使A地是trusted source) ,对应冲突数据KV表的插入和删除,如果插入和删除不及时,就会有各种各样的误判,导致数据不一致。
举个插入不及时的case: 比如A地和B地进行双向同步,同时修改了同一记录,但A地的binlog解析器因为异常挂起了,导致构建冲突数据KV表数据延迟了,而此时B地的数据就会认为无冲突,直接覆盖了A,即使A地是trusted source,然后A地数据解析恢复后,同步到B地时,因为A是trusted source,就会覆盖B地的数据,最后就是A和B两地各位两边之前的版本,导致数据不一致。
因为goldengate外部文档针对双A机房同步,数据一致性处理描述的比较少,我只能推测到这,基本结论是风险太大,所以otter需要有一种完全可靠的数据一致性方案,这也是本文讨论的重点。
单向回环补救 (基于trusted source的改进版)
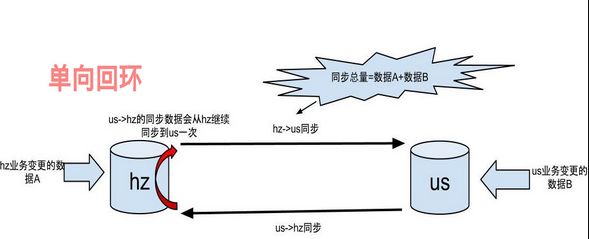
思路:最终一致性
适用场景: A地和B地数据不对等,比如A地为主,写入量比较高,B地有少量的数据写入
单向回环流程:(比如图中以HZ为trusted source站点)
us->hz同步的数据,会再次进入hz->us队列,形成一次单向回环
hz->us同步的数据,不会进入us->hz队列(回环终止,保证不进入死循环)
存在的问题:存在同步延迟时,会出现版本丢失高/数据交替性变化
比如US同一条记录变更了10个版本,而且很快同步到了HZ,而HZ因为同步数据大,同步延迟,后续单向回环中将10个版本又在US进行了一次重放,导致出现数据交替
比如HZ同一条记录变更了10个版本,而且很快同步到了US,而US因为同步延迟,将一个比较早的版本同步到了HZ,后续通过单向回环,将此记录重放到了US,导致之前HZ到US的10个版本丢失.
解决方案:
反查数据库同步 (以数据库最新版本同步,解决交替性,比如设置一致性反查数据库延迟阀值为60秒,即当同步过程中发现数据延迟超过了60秒,就会基于PK反查一次数据库,拿到当前最新值进行同步,减少交替性的问题)
字段同步 (降低冲突概率)
同步效率 (同步越快越好,降低双写导致版本丢失概率,不需要构建冲突数据KV表)
同步全局控制 (比如HZ->US和US->HZ一定要一起启动,一起关闭,保证不会出现一边数据一直覆盖另一边,造成比较多的版本丢失)
同步全局控制方案:(分布式Permit)

注意:A,B,C三点状态都正常才允许进行同步(解决数据单向覆盖)。 任何一边的canal不正常工作,都应该停掉整个双向同步,及时性越高越好。
时间交集补救
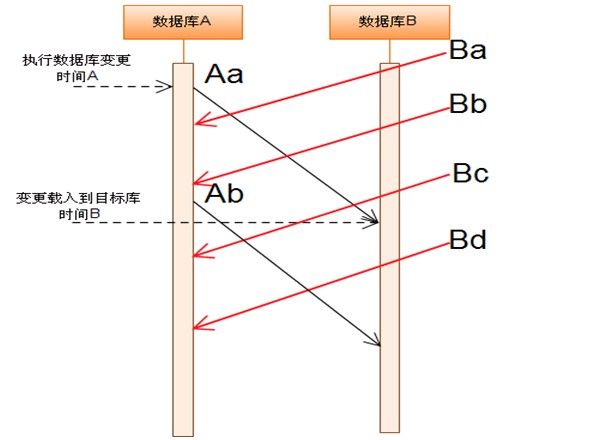
算法描述:
1. 首先定义两个时间概念
数据变更时间A :代表业务数据在A地数据库中产生的时间,即图中的时间A
数据同步时间B:代表数据变更载入到B地数据库的时间,即图中的时间B
2. 针对每条或者一批数据都记录变更时间A和同步时间B,同时保留历史同步过的数据记录
3. 图中纵轴为时间轴,Aa代表从数据库A同步到数据库B的一个同步过程,Ba代表从数据库B到同步到的数据库A的一个同步过程,每个同步过程在纵轴上会有两个点,分别代表变更时间A和同步时间B.
4. 根据同一时间的定义,在两边数据库的各自同步过程中,以数据库A为例,在数据库B的同步过程找到与Aa有时间交集的批次,比如这里就是Aa 与 (Ba , Bb , Bc)有时间交集
5. 针对步骤4中的批次,根据同一数据的定义,在交集的每个批次中,比如首先拿Aa和Ba的历史同步数据记录,根据同一数据定义进行查找,然后再是Aa和Bb,依次类推。
6. 针对步骤5中找到的同一数据,最后确定为需要进行单向回环的一致性算法的数据。
此方案相比于单向回环方案:减少单向回环同步的数据量,解决A和B地数据对等的case,不过目前开源版本暂未实现。