python经典爬虫之获取酷狗音乐TOP500信息
前几天小菌分享的博客《用python爬虫制作图片下载器(超有趣!)》收到了粉丝们较多的关注,小菌决定再分享一些简单的爬虫项目给爬虫刚入门的小伙伴们,希望大家能在钻研的过程中,感受爬虫的魅力~
"""
@File : 酷狗Top500.py
@Time : 2019/10/21 22:31
@Author : 封茗囧菌
@Software: PyCharm
转载请注明原作者
创作不易,仅供分享
"""
# 先导入相关的第三方库
import requests
from bs4 import BeautifulSoup
import time
# 定义一个请求头,伪装成浏览器,提高爬取数据的几率
headers={
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.103 Safari/537.36'
}
def get_info(url):
# 请求网页获取网页信息
web_data=requests.get(url,headers=headers)
# 利用BeautifulSoup库解析网页数据,得到soup对象
soup=BeautifulSoup(web_data.text,'html.parser')
# 分别利用soup对象的select方法获取到需要的数据
ranks=soup.select("span.pc_temp_num")
titles=soup.select("#rankWrap > div.pc_temp_songlist > ul > li > a")
times=soup.select("#rankWrap > div.pc_temp_songlist > ul > li > span.pc_temp_tips_r > span")
for rank,title,time in zip(ranks,titles,times):
# 定义一个字典
data={
'rank':rank.get_text().strip(),
'singer':title.get_text().split('-')[0],
'song':title.get_text().split('-')[1],
'time':time.get_text().strip()
}
# 获取爬虫信息并按字典格式打印
print(data)
# 程序主入口
if __name__ == '__main__':
# 观察网页组成结构,构造出多页URL
urls=['https://www.kugou.com/yy/rank/home/{}-8888.html?from=rank'.format(i)
for i in range(1,24)]
for url in urls:
print("开始爬取的URL:"+url)
# 调用方法,获取到每页的具体信息
get_info(url)
# 设置休眠时间
time.sleep(1)
效果图:

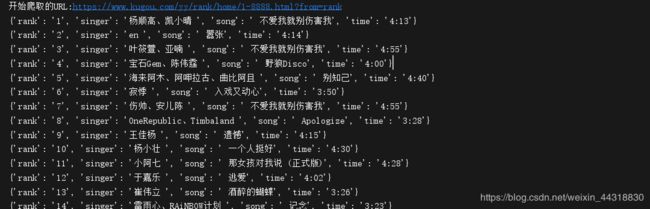
这次分享的爬虫项目非常适合爬虫初学者训练,希望大家能多多练习,本次的分享就到这里,喜欢的小伙伴们记得点赞加关注哦╰( ̄▽ ̄)╭