Tensorflow2.*教程之基本分类:对Fashion Mnist进行分类(1)
tensorflow版本:2.1.0
需要Python库:Numpy,Matplotlib
使用的数据集:Fashion Mnist
TF1.*
TF1.x 主要用于处理「静态计算图」的框架。计算图中的节点是 Tensors,当图形运行时,它将保持nn维数组;图中的边表示在运行图以实际执行有用计算时将在张量上运行的函数。
在 TensorFlow 2.0 之前,我们必须将图表分为两个阶段:
- 构建一个描述你要执行的计算的计算图。这个阶段实际上不执行任何计算;它只是建立来计算的符号表示。该阶段通常将定义一个或多个表示计算图输入的 “占位符”(placeholder)对象。
- 多次运行计算图。每次运行图形时(例如,对于一个梯度下降步骤),你将指定要计算的图形的哪些部分,并传递一个 “feed_dict” 字典,该字典将给出具体值为图中的任何 “占位符”。
TF2.*
使用 Tensorflow 2.*,我们可以简单地才用 “更像 python” 的功能形式,与 PyTorch 和 Numpy 操作直接相似。而不是带有计算图的两步范例,使其(除其他事项外)更容易调试 TF 代码。
TF 1.x 和 2.0 方法的主要区别在于 2.0 方法不使用 tf.Session,tf.run,placeholder,feed_dict。
Fashion Mnist类别
图像数据是28x28 NumPy数组,像素值范围是0到255。标签是整数数组,范围是0到9。这些对应于图像表示的衣服类别:
| 标签 | 类 |
|---|---|
| 0 | T恤/上衣 |
| 1 | 裤子 |
| 2 | 拉过来 |
| 3 | 连衣裙 |
| 4 | 涂层 |
| 5 | 凉鞋 |
| 6 | 衬衫 |
| 7 | 运动鞋 |
| 8 | 袋 |
构建模型图

接下来开始我们模型构建及分类
需要导入python库
import tensorflow as tf
from tensorflow import keras
import numpy as np
import matplotlib.pyplot as plt导入Fashion MNIST数据集
fashion_mnist = keras.datasets.fashion_mnist
(train_images, train_labels), (test_images, test_labels) = fashion_mnist.load_data()加载数据集将返回四个NumPy数组:
train_images和train_labels为训练集数据用来进行模型学习。test_images和test_labels用来对模型进行评估。
其中,训练数据有60000,测试数据有10000。
预处理数据
在训练网络之前,必须对数据进行预处理。上述图像数据像素值落在0到255之间,为了加快网络收敛速度,我们将这些值缩放到0到1的范围,然后再将其输入神经网络模型。
train_images = train_images / 255.0
test_images = test_images / 255.0建立模型
建立神经网络需要配置模型的各层,然后编译模型。我们使用tf.keras.Sequential完成网络层的堆叠。
model = keras.Sequential([
# 展平层,词为网络输入层
keras.layers.Flatten(input_shape=(28, 28)),
# 全连接层,128个神经单元
keras.layers.Dense(128, activation='relu'),
# 最终输出层,由于有10个类别,所以输出单元个数为10
keras.layers.Dense(10)
])该网络的第一层tf.keras.layers.Flatten将图像格式从二维数组(28 x 28像素)转换为一维数组(28 * 28 = 784像素)。可以将这一层看作是堆叠图像中的像素行并将它们排成一行。该层没有学习参数。它只会重新格式化数据。
像素展平后,网络由tf.keras.layers.Dense两层序列组成。这些是紧密连接或完全连接的神经层。第一Dense层有128个节点(或神经元)。第二层(也是最后一层)返回长度为10的logits数组。每个节点包含一个得分,该得分指示当前图像属于10个类之一。
编译模型
在准备训练模型之前,需要进行一些其他设置。这些是在模型的编译步骤中添加的:
- 损失函数 -衡量训练过程中模型的准确性。您希望最小化此功能,以在正确的方向上“引导”模型。
- 优化器 -这是基于模型看到的数据及其损失函数来更新模型的方式。
- 指标 -用于监视培训和测试步骤。以下示例使用precision,即正确分类的图像比例。
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])训练模型
训练神经网络模型需要执行以下步骤:
- 将训练数据输入模型。在此示例中,训练数据在
train_images和train_labels数组中。 - 该模型学习关联图像和标签。
- 您要求模型对测试集进行预测(在此示例中为
test_images数组)。 - 验证预测是否与
test_labels阵列中的标签匹配。
要开始训练,请调用model.fit方法,将训练数据和测试数据输入模型进行参数学习:
model.fit(train_images, train_labels, epochs=10)训练60000个样本
时代1/10
60000/60000 [==============================]-4s 61us / sample-损耗:0.4991-精度:0.8244
时代2/10
60000/60000 [=============================]-3秒53us /样本-损失:0.3771-准确性:0.8643
时代3/10
60000/60000 [==============================]-3s 53us / sample-损失:0.3381-准确性:0.8775
时代4/10
60000/60000 [==============================]-3s 53us / sample-损耗:0.3145-精度:0.8840
时代5/10
60000/60000 [==============================]-3s 53us / sample-损耗:0.2950-精度:0.8908
时代6/10
60000/60000 [==============================]-3s 52us / sample-损耗:0.2805-精度:0.8956
时代7/10
60000/60000 [==============================]-3s 53us / sample-损耗:0.2691-精度:0.9007
时代8/10
60000/60000 [==============================]-3s 53us / sample-损耗:0.2580-精度:0.9044
时代9/10
60000/60000 [==============================]-3s 53us / sample-损耗:0.2490-精度:0.9071
时代10/10
60000/60000 [==============================]-3s 53us / sample-损失:0.2381-准确性:0.9096
模型训练时,会显示损失和准确性指标。该模型在训练数据上达到约0.91(或91%)的精度。
评估准确性
接下来,比较模型在测试数据集上的表现:
test_loss, test_acc = model.evaluate(test_images, test_labels, verbose=2)
print('\nTest accuracy:', test_acc)10000/10000-1秒-损耗:0.3548-精度:0.8802
测试精度:0.8802
事实证明,测试数据集的准确性略低于训练数据集的准确性。训练准确性和测试准确性之间的差距代表过度拟合。当机器学习模型在新的,未见过的输入数据上的表现比训练数据上的表现差时,就会发生过度拟合。过度拟合的模型“存储”训练数据集中的噪声和细节,从而对新数据的模型性能产生负面影响。
作出预测
通过训练模型,您可以使用它来预测某些图像。模型的线性输出logits。附加一个softmax层,以将logit转换为更容易解释的概率。
probability_model = tf.keras.Sequential([model,
tf.keras.layers.Softmax()])
predictions = probability_model.predict(test_images)在这里,模型已经预测了测试集中每个图像的标签。让我们看一下第一个预测:
predictions[0]Array([9.6798196e-09,3.9551045e-12,1.1966002e-09,6.4597640e-11,
6.9501125e-09,1.3103469e-04,1.2785731e-07,2.0190427e-01,
1.3739854e-09,7.9796457e-01],dtype = float32)
预测是10个数字组成的数组。它们代表模型对图像对应于10种不同服装中的每一种的置信度。您可以看到哪个标签的置信度最高:
np.argmax(predictions[0])以图形方式查看完整的10个类预测。
def plot_image(i, predictions_array, true_label, img):
predictions_array, true_label, img = predictions_array, true_label[i], img[i]
plt.grid(False)
plt.xticks([])
plt.yticks([])
plt.imshow(img, cmap=plt.cm.binary)
predicted_label = np.argmax(predictions_array)
if predicted_label == true_label:
color = 'blue'
else:
color = 'red'
plt.xlabel("{} {:2.0f}% ({})".format(class_names[predicted_label],
100*np.max(predictions_array),
class_names[true_label]),
color=color)
def plot_value_array(i, predictions_array, true_label):
predictions_array, true_label = predictions_array, true_label[i]
plt.grid(False)
plt.xticks(range(10))
plt.yticks([])
thisplot = plt.bar(range(10), predictions_array, color="#777777")
plt.ylim([0, 1])
predicted_label = np.argmax(predictions_array)
thisplot[predicted_label].set_color('red')
thisplot[true_label].set_color('blue')验证预测
通过训练模型,您可以使用它来预测某些图像。
让我们看一下第0张图像,预测和预测数组。正确的预测标签为蓝色,错误的预测标签为红色。该数字给出了预测标签的百分比(满分为100)。
i = 0
plt.figure(figsize=(6,3))
plt.subplot(1,2,1)
plot_image(i, predictions[i], test_labels, test_images)
plt.subplot(1,2,2)
plot_value_array(i, predictions[i], test_labels)
plt.show()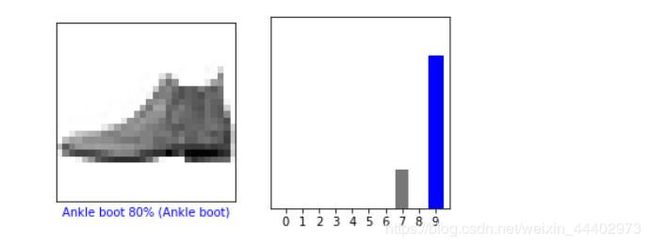
i = 12
plt.figure(figsize=(6,3))
plt.subplot(1,2,1)
plot_image(i, predictions[i], test_labels, test_images)
plt.subplot(1,2,2)
plot_value_array(i, predictions[i], test_labels)
plt.show()