论文《A High Spatial Resolution Depth Sensing Method Based on Binocular Structured Light》学习
Abstract
(SCI二区)自从微软Kinect发布以来,深度信息以其低成本和易用性在许多领域得到了广泛的应用。然而,Kinect和Kinect类的RGB-D传感器在某些应用中表现出有限的性能,对深度信息的准确性和鲁棒性提出了很高的要求。然而,Kinect和Kinect类的RGB-D传感器在某些应用中表现出有限的性能,对深度信息的准确性和鲁棒性提出了很高的要求。为了提高空间分辨率,我们减小了匹配块的大小,但是较小的匹配块产生较低的匹配精度。为了解决这一问题,我们在视差估计过程中结合了双目模式和单目模式两种匹配模式。实验结果表明,与Kinect相比,该方法可以在不影响距离图像质量的前提下获得更高的空间分辨率深度。此外,我们的算法是在一个低成本的硬件平台上实现的,对于深度图像序列,该系统可以支持1280×960的分辨率,最高每秒60帧的速度。
关键词: 深度传感;双目结构光;空间分辨率;Kinect;散斑图
1. Introduction
目前,基于三维(3D)深度信息的人机交互技术在图像处理和计算机视觉领域具有很强的吸引力,进一步推动了三维深度采集技术的发展。此外,最近开发的三维深度传感器,如微软kinect(微软公司,redmond,华盛顿特区,美国)[1],已经应用于更多领域,如手势识别[2-5]、智能驾驶[6,7]、监视[8]、三维重建[9,10],等等。三维深度采集技术测量物体与深度传感器之间的距离信息。它代表了一种非接触、非破坏性的测量技术。
深入研究的获取深度信息的方法可以分为两大类:被动方法和主动方法。双目立体视觉是被动方法中的一个热门的研究课题。一些作者[11,12]在硬件平台上实现了整个立体视觉过程,同时伴随着算法和现场可编程门阵列(FPGA)技术的进步。然而,由于某些算法必须在定制的FPGA上实现,因此计算量大仍然限制了其产业化。另一方面,对于大面积的无纹理区域,如白墙,立体视觉仍然没有很好的方法来获得稠密的视差图。因此,目前尚未发布相关电子产品。
飞行时间(tof)和结构光(13,14)主要用于主动深度传感方法。飞行时间(tof)技术是在测量光路飞行时间的基础上获取距离信息的。三星于2012年发布了第一款基于互补金属氧化物半导体(CMOS)的ToF传感器,该传感器可以通过一个图像传感器[15]获得同步深度(480×360)和RGB图像(1920×720)。2013年微软发布的Kinect 2 (XBox One版Kinect)也是基于ToF原理[16]。然而,在小型化和集成化方面,基于结构光的技术优势不容忽视。除了微软的Kinect,其他公司也研究并发布了他们自己的深度感应相机,或者打算将它们集成到他们的电子产品中。例如,2013年,苹果公司购买了PrimeSense并申请了一项重要的发明专利:“深度感知设备和系统”[17],并打算将其用作其产品人机界面的输入设备。2014年初,英特尔宣布推出一款三维深度成像设备“RealSense 3D相机”,产品RealSense R200和SR300自2016年开始上市。2014年2月,谷歌宣布了一个新项目“探戈”,计划生产一款具备3D视觉识别能力的智能手机。2015年,微软全息遮阳板“全息镜片”上市。
然而,与二维成像系统相比,基于结构光的深度传感系统还不够成熟。深度图像的分辨率和精度较低,在使用移动对象或动态场景时性能不太可靠。在[18,19]中,作者结合彩色图像来恢复相应的深度图像。该方法可以提高图像质量,降低获取深度图的噪声,但对测量精度的提高是有限的。
此外,基于结构光的深度传感器的硬件实现在很大程度上在文献中还是一个黑盒子。在文献[20]中,我们提出了一种全超大规模集成(vlsi)实现方法,以获得基于随机散斑图的高分辨率和高精度深度图。结果表明,深度图的空间分辨率有进一步提高的潜力。因此,本文在激光投影仪右侧增加了一个红外摄像机,采用局部双目立体匹配算法来提高深度图的性能。
提出了几种利用双目结构光获取视差图的方法。采用了不同的投影模式和视差估计方法。Ma等人将基于垂直条纹的颜色编码模式与半全局立体匹配(SGM)算法相结合,得到了密集的人脸视差图[21]。An等人以面部重建[22]为视角,对各种结构照明技术进行了对比分析。Nguyen等人使用点编码模式来增强植物的纹理,并使用5对RGB相机重建整个植物的[23]。该系统采用立体块匹配的方法计算匹配结果。上面提到的灰色或彩色编码模式对环境光和物体表面的颜色是敏感的。Yang等人利用光带和相应的解码方法对三维表面[24]进行了测量。但是,这种方法不适用于移动对象。Dekiff等人提出的实验装置。还使用了散斑图和数字图像相关[25]。两台摄像机之间的三角测量角度约为30度。它是一个短程测量系统。测量距离小于1m,测量场尺寸约24cm×18cm。英特尔RealSense相机SR300包括两个红外相机,性能相似。
除了[20]之外,我们在本文的关键贡献是在激光投影仪的右侧增加了一个红外摄像机,然后利用捕捉到的左右模式之间的双目匹配模式来提高X-Y方向的空间分辨率。在双目匹配过程中不可避免地会出现错配和遮挡现象,因此也采用了左图与参考模式之间的单目匹配模式对匹配结果进行修正。最后,在一个低成本的硬件平台上,用激光投影仪和两台摄像机对整个系统进行了实现和验证。
本文的其余部分组织如下:在第2节中,简要介绍了我们的深度感知方法中提到的基本原理。第3节描述了从投影散斑图获取深度图的步骤。第4节给出了我们提出的方法的全管道结构。第五部分讨论了该方法的实用性,并给出了一些仿真结果。第六部分是本文的结论部分。
2. Related Ranging Principle
在[20]中,为了保证视差估计过程中的匹配精度,提出了一种一致性增强算法。然而,物体的表面材质也会影响投影模式,所以我们必须选择一个更大的块,而不是理论上最小的尺寸,来执行块匹配步骤。因此,我们在激光投影仪的右侧添加了一个红外摄像机,以便捕捉到与捕捉到的左侧图案几乎一致的图案。然后利用最小的图像块对采集到的左右模式进行双目匹配,从而提高深度图的空间分辨率。
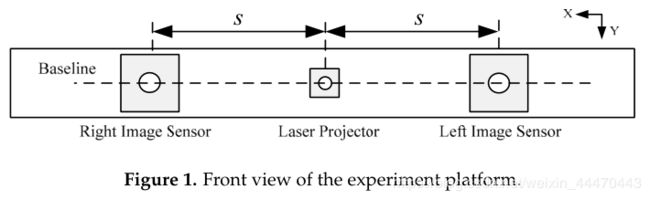
图1显示了投影仪和摄像机之间的位置关系。与传统的深度传感方法相比,在激光投影仪的右侧增加了一个摄像头。实验平台包含一个投影仪,投射出与Kinect类似的斑纹图案,以及两个性能参数相同的相机。投影仪在两个照相机之间。这三个单元位于同一直线上,并且每个单元的光轴平行。在我们的深度传感方法中,三角测量原理和数字图像相关(DIC)是相关的。三角测量原理是通过几何关系将视差转换成距离信息。通常,执行数字图像相关(DIC)以识别各个图像中的对应点。
2.1 Triangulation Principle
在双目立体视觉系统中,遮挡问题是不可避免的。因此,我们结合单目测距方法来补偿被遮挡体的视差。在这一部分中,介绍了测距原理和两种模式下两个位移矢量的转换关系。测距方法基于三角测量原理。如图2所示,点at是由散斑图案标记的3D空间中的任意点。 P l P_l Pl和 P r P_r Pr这两个点分别是 A t A_t At在左、右摄像机成像平面上的投影,因此它们是 A t A_t At在左、右两幅图像上的对应图像点。根据摄影测量,如果我们得到两幅图像中测试点 A t A_t At的位移,就可以得到点 A t A_t At到测距传感器的垂直距离。两个摄像机的位置如图1所示,它们的坐标仅随着X方向上平移距离的不同而不同。因此,两台相机的像平面在同一平面上,极线与图像扫描线对齐。因此,Y方向的位移 Δ y {\Delta}y Δy可以忽略,我们只需要估计在左右摄像机成像平面上 A t A_t At的投影点之间的X方向的位移 Δ x {\Delta}x Δx。我们假设图像传感器的光学焦距为f,μ为物理像素间距,s为激光投影仪和图像传感器之间的基线距离。根据相似三角形之间的关系,我们可以得到比例关系 d − f d = 2 s − l l − l r 2 s \frac{d-f}{d}=\frac{2s-l_l-l_r}{2s} dd−f=2s2s−ll−lr,其中参数d是传感器与点 A t A_t At之间的距离。那么点 A t A_t At的深度值可以计算为:

其中 Δ x b i {\Delta}x_{bi} Δxbi分别表示左图像和右图像上对应图像点 P l P_l Pl、 P r P_r Pr的位移。

其次,讨论了仅使用左侧相机的深度传感技术。在这个过程中,我们需要从左相机获取一个已知距离的参考图像。如图2所示,点 A r A_r Ar是点 A t A_t At在参考距离处的位置。根据相似三角形之间的关系,我们可以得到比例 d − f d = s − l l − l e s \frac{d-f}{d}=\frac{s-l_l-l_e}{s} dd−f=ss−ll−le和 d r e f − f d r e f = s − l l − l e − μ Δ x l e f t s \frac{d_{ref}-f}{d_{ref}}=\frac{s-l_l-l_e-{\mu\Delta}x_{left}}{s} drefdref−f=ss−ll−le−μΔxleft。则点 A t A_t At的深度值可计算为:

其中, ∆ x l e f t ∆x_{left} ∆xleft左为对应图像点 P l P_l Pl的位移, P r e f P_{ref} Pref分别为左侧及其参考图像。从方程(1)和(2)中,我们可以观察到距离d的倒数与位移 Δ x b i {\Delta}x_{bi} Δxbi或 Δ x l e f t {\Delta}x_{left} Δxleft呈线性关系;因此,两个差异之间存在简单的线性关系。点 A t A_t At可以位于参考点 A r e f A_{ref} Aref的前面或后面,因此左位移dx的值可以为正或负。在本文中,我们为位移设定了一个方向。投影点 P l P_l Pl被指定为向量的端点,投影点 P r P_r Pr或 P r e f P_{ref} Pref被指定为向量的起点。然后我们可以得到 Δ x l e f t → = P r e f P l → = − Δ x l e f t \overrightarrow{{\Delta}x_{left}}=\overrightarrow{P_{ref}P_l}=-{\Delta}x_{left} Δxleft=PrefPl=−Δxleft和 Δ x b i → = P r ′ P l → = Δ x b i {\Delta}\overrightarrow{x_{bi}}=\overrightarrow{P'_rP_l}={\Delta}x_{bi} Δxbi=Pr′Pl=Δxbi。结合式(1)和式(2),我们可以得到两个位移的关系如下:

2.2 Digital Image Correlation
数字图像相关(digital image correlation, DIC)算法是上世纪末发展起来的,被广泛用于分析变形,识别不同图像之间的对应点[25,26]。其原理是通过适当的相似度计算方法来匹配不同数字图像的子集。该过程是通过相关函数来保证位移形状函数中的参数。2.1节中提到的位移包含在这些参数中。
假设第一幅图像(左散斑图像)中的点 P l P_l Pl的坐标为(x0,y0)。为了确定第二幅图像(右或参考散斑图像)中的对应点(x’0,y’0),提取围绕中心点(x0,y0)的平方子集。子集中的每个点用(x,y)表示。如果所代表的子集的表面垂直于光轴,则只产生刚性位移;该子集中每个点的第二个图像中的映射位置(x’,y’)通过以下公式计算:
![]()
其中u为子集中心点在X方向上的位移(在本文中可以忽略Y方向上的位移),而在大多数情况下,投影在被测物体上的散斑图可能是变形的。引入一阶位移形状函数来逼近映射位置:
![]()
其中参数 u x u_x ux、 u y u_y uy为一阶位移梯度分量。卢和Cary[27]提出了一种利用二阶位移形状函数求解大变形的DIC算法,但由于参数的不确定性和复杂性,使得算法的计算难度和复杂度大大增加。因此,根据方程(5)估计位移。方程(4)和(5)中的位移u采用块匹配算法进行估计,方程(4)和(5)也是第2.1节中的 Δ x b i {\Delta}x_{bi} Δxbi或 Δ x l e f t {\Delta}x_{left} Δxleft。在实现过程中,首先对参数 u x u_x ux和 u y u_y uy赋予不同的初始值,然后从第二幅图像中提取m×m大小的不同子集。最后,将式(6)作为相似准则来寻找最佳匹配子集:
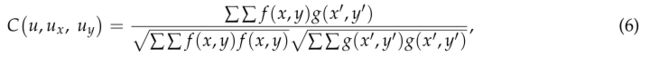
其中f (x,y), g (x’,y’)分别为第一种和第二种模式的离散灰度值。
数字图像相关(DIC)算法是一种局部立体匹配算法。除了该算法,还有其他立体匹配算法,如半全局块匹配[28]、信念传播、图割[29]等。然而,这些算法并不适合我们的系统。原因如下。首先,在结构光测距中,投影模式的编码遵循一定的原则。根据该编码方法设计了测距算法的译码方法。本文的散斑图是二进制的,由随机分布的孤立散斑组成。从模式中提取的每个图像块都是唯一的,因此块匹配算法足以解码模式。其次,其他立体匹配算法非常复杂,利用它们来优化深度图,如无纹理和遮挡问题。在我们的论文中,红外相机只能捕获投影图像本身,而不需要从周围环境中获取额外的信息,比如颜色或灰度信息。由于目标的边缘信息和其他特征很难从捕获的图像中计算出来,因此这些立体匹配算法对我们的结果的优化是有限的。另一方面,由于场景被投影点标记,因此不存在无纹理区域,而立体匹配中存在的遮挡区域可以通过单目匹配结果进行校正。第三,在硬件平台上对系统进行了实现和验证。在其它立体匹配算法中,由于每个像素或图像的迭代次数不同,往往采用迭代算法来寻找所建立能量函数的最优解,因此硬件成本不确定,不符合硬件设计原则。最后,考虑到精度和硬件成本的权衡,在系统设计中采用了块匹配算法。
3. The Depth-Sensing Method from Two Infrand Cameras Based on Structured Light
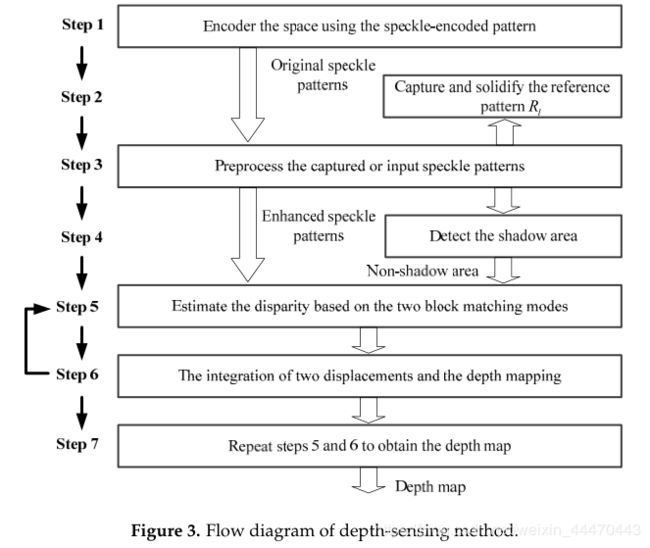
图3显示了我们的方法流程图。该方法可分为七个步骤,具体描述如下:
-
Step 1: Encode the space using the speckle-encoded pattern.
投影机根据活动模式投射散斑编码模式,对空间或物体进行编码或标记。模式是固定的,由相干激光束干涉形成的随机分布的光斑组成。投影模式的基本设计原则是,任何子窗口中的模式都是惟一的,并且是完全确定的。 -
Step 2: Capture and solidify the reference pattern R l R_l Rl from the left camera.
如图1所示,两个相同的摄像机对称地排列在模式投影仪的两侧,摄像机和投影仪的光轴彼此平行。窄带滤光片粘贴在两台摄像机的镜头上,这样投影仪所采用的一定波长范围内的红外光只能被捕捉到。本设计主要消除其他波长光源的干扰,获得清晰稳定的投影编码图案。
在工作之前,我们需要捕获并固化用于视差估计的左侧参考模式。通过捕捉投射在垂直于激光投影仪和相机的光轴(z轴)的标准平面上的散斑图案来生成参考图案。已知标准平面与深度传感器之间的垂直距离 D r e f D_{ref} Dref。选择必须确保大多数部分或整个散斑图案可以投影到标准平面上,并且也可以占据左图像传感器的整个视野。然后由步骤3所述的散斑图预处理模块对参考散斑图进行处理,并将固定图像存储在存储器中。在正常处理阶段,系统只需从存储器中读取参考散斑图,即可对采集到的散斑图图像进行视差估计。 -
Step 3: Preprocess the captured or input speckle patterns I l I_l Il , I r I_r Ir
from the two cameras.
对于直接从相机上拍摄的原始散斑图,激光干涉形成的斑的强度和大小随着投影距离的增加而减小,在整个图像中可能是不均匀的。因此,在[20]中提出了一种一致性增强算法来增强输入散斑模式,使其更具识别性,从而提高匹配精度。该算法结合灰度变换和直方图均衡,适用于硬件实现,可描述为:
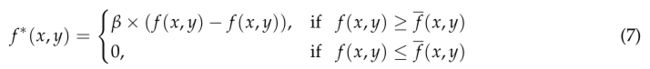
其 f ˉ ( x , y ) \bar{f}(x,y) fˉ(x,y)是具有中心像素(x,y)的子集的平均灰度值, β = g r a y r e f / f ˉ ( x , y ) β=gray_{ref}/\bar{f}(x,y) β=grayref/fˉ(x,y)是比例因子。 -
Step 4: Detect the shadow area of the enhanced patterns I l I_l Il, I r I_r Ir。
如图4所示,由于前景和背景之间的距离差,形成空白区域或无投影区域,即阴影区域。阴影区域的子集无法使用公式(6)计算相关系数。这将影响下一个视差估计步骤。因此,在图像 I l I_l Il和 I r I_r Ir的预处理模块中,检测并标记阴影区域。视差估计将不在标记区域中执行。阴影区域检测方法,用于检测在一定子集大小内的散斑点像素数。如果该数字小于阈值,则该子集的中心像素位于阴影区域,否则该像素位于投影区域。
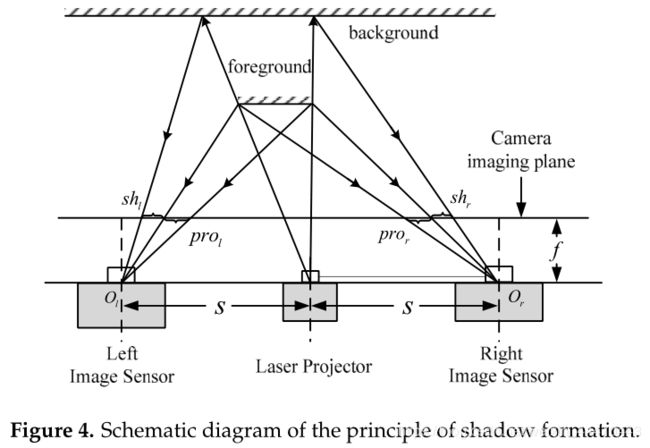
对于左侧相机,阴影区域 s h l sh_l shl位于前景投影 p r o l pro_l prol的左侧,而对于右侧相机,阴影 s h r sh_r shr位于 p r o r r pro_rr prorr的右侧。很明显,阴影区域的边缘与前景的边缘是相关的。此特性可用于分割位于前景中的对象。
对捕获的散斑图进行预处理后的结果如图5所示。显然,在图5b中,经过一致性增强后,整个散斑图中斑的强度更加一致。捕捉到的散斑图案来自于左侧相机,因此在图5c中,物体的阴影位于投影的左侧。

-
Step 5: Estimate the disparity based on the two block matching modes.
在双眼匹配中,遮挡是不可避免的。在左右模式的匹配中,存在着由遮挡引起的区域不匹配。为了解决这一问题,提高匹配精度,本文采用了两种匹配模式。一种是估计左右模式之间的差异,称为双眼模式;另一种是估计左模式与记忆中固定的参考模式之间的差异,称为单目模式。
对于单目模式,方程(4)用于估计位移。如图6所示,我们从左散斑图中提取尺寸为m×m的正方形图像块(或子集)。由于图像传感器和激光投影仪的位置关系,块匹配算法仅限于x轴方向。因此,从左参考散斑图中提取m×M大小的搜索窗口,并且图像块的中心像素和搜索窗口共享相同的y坐标。m参数是奇数, m ≪ M m{\ll}M m≪M。然后利用全搜索块匹配法和相关方程(6)找到最佳匹配块,估计图像块中心像素的位移xleft。最后,我们使用方程(3)将位移 x l e f t x_{left} xleft转换为 x b i ′ x'_{bi} xbi′。

对于双目模式,基线长度是单眼模式的两倍;因此,变形较大,需要考虑。在匹配过程中,采用式(5)对位移进行估计。参数 u x u_x ux设为0, u y u_y uy分别设为 − 3 / 8 , 0 , 3 / 8 - 3/8,0,3/8 −3/8,0,3/8。我们将计算出的像素位置四舍五入,从搜索窗口中提取一个正方形块。剩下的过程与单目模式相同,然后我们获取图像块中心像素的位移 Δ x b i {\Delta}x_{bi} Δxbi。 -
Step 6: The integration of two displacements and the depth mapping.
如图7所示,左图像传感器的视野(FOV)可分为两部分。一个是交叉部分的场,另一个是未交叉部分。对于交叉部分的像素,如果 ∣ Δ x b i ′ − Δ x b i ∣ < t h |{\Delta}x'_{bi}-{\Delta}x_{bi}|<th ∣Δxbi′−Δxbi∣<th,则 Δ x b i {\Delta}x_{bi} Δxbi被选为最终位移 Δ x {\Delta}x Δx,否则我们比较两个匹配模式的最大相关系数,并选择较大的一个作为最终位移 Δ x {\Delta}x Δx。对于未交叉部分的像素,我们无法得到位移 Δ x b i {\Delta}x_{bi} Δxbi,因此,选择 x b i ′ x'_{bi} xbi′作为最终位移 Δ x {\Delta}x Δx。

-
Step 7: Obtain the depth map.
将图像块的中心像素移动到同一行的下一个相邻像素,重复步骤5和步骤6,获取相邻像素的距离信息。然后在逐像素逐行的基础上得到整个深度图像。
4. Hardware Architecture and Implementation
本文在硬件平台上实现了该方法。图8展示了我们的深度感知方法的架构。在现场可编程门阵列中有三个主要模块,即一致性增强、阴影检测和视差估计,以及两个外部模块,微控制器单元(MCU和闪存)。一方面,MCU控制闪存的读写,在处理前,参考图像R需要预先固化在闪存中,因此MCU将通过内部集成电路(12CBU)发送一个写入信号来控制闪存。在处理阶段,fpga从flash存储器中读取参考数据,因此需要将写入信号作为一个读取信号来改变;另一方面,我们的方法也有一些阈值,如一致性增强中的7ayref和置换中的thh。步骤。MCU帮助我们在FPGA之外调整这些阈值。
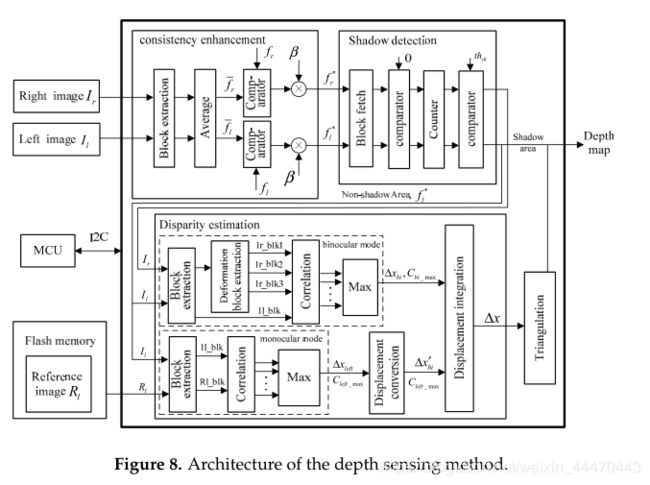
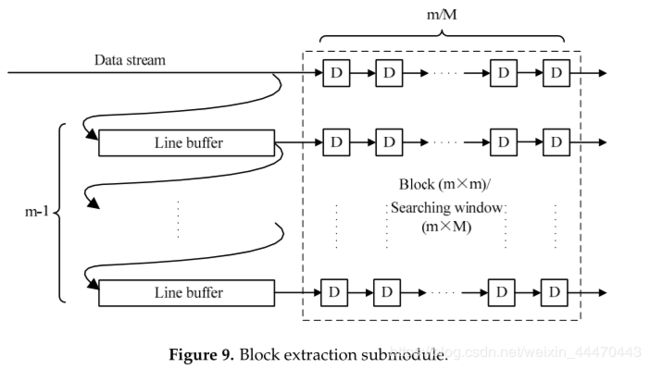
流水线框架是硬件实现的核心。例如,将输入图像从左上像素扫描到右下像素以生成固定数据流。然而,在步骤3、4和5中,使用周围像素处理每个像素。在这三个主要模块中,块提取子模块是必不可少的。如图9所示,在该子模块中使用m-1行缓冲器和m×m d触发器来提取m×m图像块。行缓冲区的长度等于图像宽度,并且每个D-触发器表示时钟周期延迟。搜索窗口的提取也使用相同的结构,只是D-触发器的长度改为M。
在一致性增强模块中,在块提取模块之后,有一个平均子模块来计算提取图像块的平均灰度值。然后根据公式(7)采用比较器和乘法器对中心像素进行增强,在阴影检测模块中,对提取的图像块采用比较器和计数器检测中心像素是否在阴影区域。
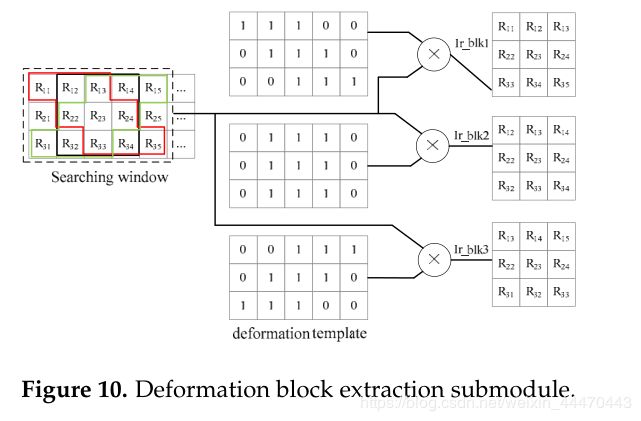
在视差估计中,在提取图像块和搜索窗口后,将搜索窗口和图像块中的m+1匹配块输入相关子模块,根据式(6)计算相关系数。然后,max子模块选择最大系数 C m a x C_{max} Cmax并获取相应的位移。但是,由于本文考虑了变形的影响,所以双目模式略有不同。匹配块提取包含一个额外的子模块,即变形块提取子模块,图10中给出了该子模块的一个例子,m=3, u x = 0 u_x=0 ux=0, u y = ± 1 , 0 u_y=±1,0 uy=±1,0。对于搜索窗口中的每个中心像素,我们提取三个用红色、黑色和绿色标记的匹配块。变形模板已存储在“高级”中。然后将中心像素为 R 23 R_{23} R23的3×5块与三个模板相乘。如果模板中的像素是1,则块中的对应像素将被保留以形成匹配块。
对于位移转换和三角剖分这两个子模块,分别根据方程(1)和方程(3)建立了两个查找表(luts),将计算结果存储在rom中。每个输入位移对应一个寄存器地址,结果从相应的地址读取。
5. Experiment Result and Discussion
我们设计了一个FPGA硬件平台,如图11所示,验证了本文提出的深度感知算法。在平台上,我们使用了与Kinect类似的近红外激光投影仪(发射激光散斑图)和两个相同的红外图像传感器(接收激光散斑图,输出分辨率支持1280×960,60hz)固定在一块铝板上。在Altera FPGA上验证了该方法的有效性
(型号:EP4CE115F23C8N, Intel Corporation, Santa Clara, CA, USA)

5.1 The Validation of the Transforming Relationship between Two Displacement
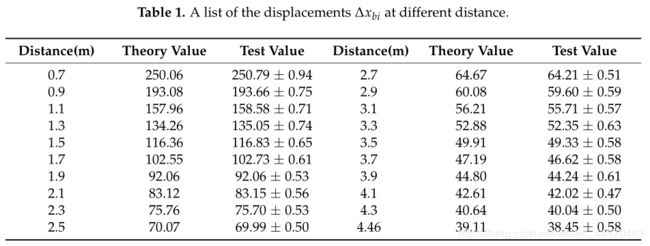
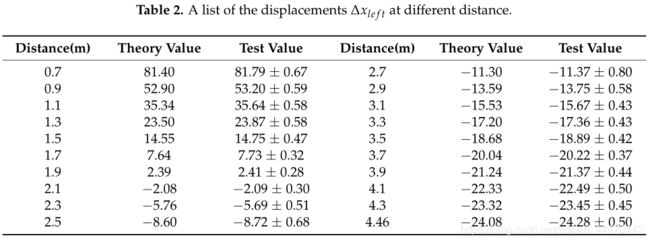
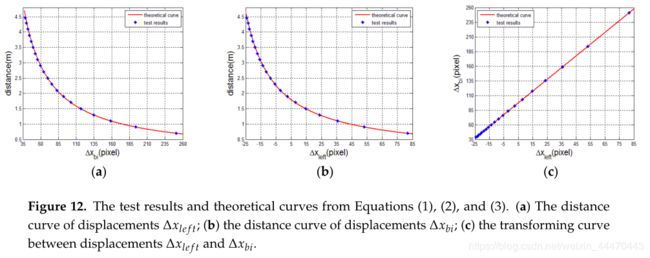
在这一部分中,我们从两个匹配模式验证了两个位移 Δ x b i {\Delta}x_{bi} Δxbi和 Δ x l e f t {\Delta}x_{left} Δxleft之间的转换关系。我们捕获一组左右散斑图,它们投影在垂直于激光投影仪光轴(Z轴)且平行于左参考散斑图平面的标准平面上。已知每个散斑图的距离信息,范围为0.7 m至4.46 m。估计每个图的测试位移 Δ x b i {\Delta}x_{bi} Δxbi和 Δ x l e f t {\Delta}x_{left} Δxleft,并在表1和表2中列出。在这两个表中,还列出了根据公式(1)和(2)计算的理论位移,其中相关相机参数f=4.387 mm,μ=3.75μm,基线s=74.6 mm, d r d_r dr=2 m。由表1和表2可以看出, Δ x b i {\Delta}x_{bi} Δxbi的误差略大于 Δ x l e f t {\Delta}x_{left} Δxleft的误差。原因是双目模式的基线长度是单眼模式基线长度的两倍。对于位移 Δ x b i {\Delta}x_{bi} Δxbi,从0.7 m到2.5 m,试验值的误差随着距离的增加而减小。2.5m后,误差波动稳定在0.47~0.61之间。对于位移 Δ x l e f t {\Delta}x_{left} Δxleft,测试值在参考距离附近的误差最小,理论值和测试值之间的误差不超过一个像素。在图12中,我们绘制了由方程式(1)和(2)计算的测距曲线和由方程式(3)计算的转换曲线,此外,还绘制和表示了试验位移,如蓝色图所示。它直观地表明,所有的蓝色地块基本上都在红线上。
5.2. The Spactial Resolution in X-Y Direction
在本文中,我们将散斑图分成块(或子集)来估计每个像素的视差。根据三角法原理,X-Y方向的空间分辨率与分块大小成正比,与距离成反比。关系可以表示为

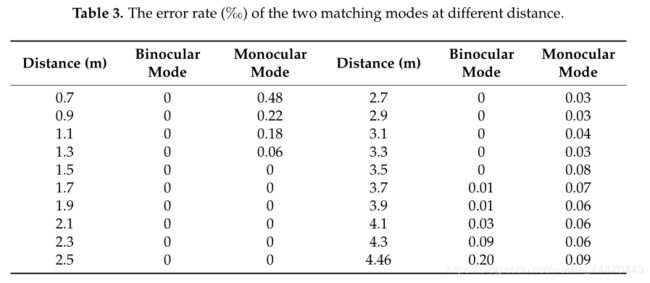
其中m表示块大小。该方法通过减小匹配块的大小来提高深度图的空间分辨率,但会降低匹配精度。因此,我们分析了不同尺寸块在不同距离下的错误率,以选择合适的块大小。这两种匹配模式在0.7 m到4.46 m范围内进行,块体尺寸分别为25×25和17×17, Δ x 25 {\Delta}x_{25} Δx25和 Δ x 17 {\Delta}x_{17} Δx17分别表示估计的位移。实验结果表明,当块大小为25×25时,两种匹配模式均不存在不匹配像素。然后,当使用17×17的较小块大小时,对于每个像素,如果 Δ x 25 − Δ x 17 > 0.25 {\Delta}x_{25}-{\Delta}x_{17}>0.25 Δx25−Δx17>0.25像素,我们假设匹配结果是错误的。表3列出了块大小为17×17的两种匹配模式的错误率。结果表明,在3.5 m之前,双目模式下几乎没有出现错配,错误率也很低,从3.7 m到4.1 m。因此,可以选择17×17块执行DIC算法。此外,很明显,在单目模式下,在参考距离附近的匹配结果非常好;在其他距离,特别是在0.7米处出现失配,失配非常严重。此外,在视差估计步骤(步骤5)中执行主计算。尽管在本方法中执行了两种匹配模式,但与25×25块大小相比,我们采用较小的块而不增加计算量。
5.3. The Analysis and Comparison of Results
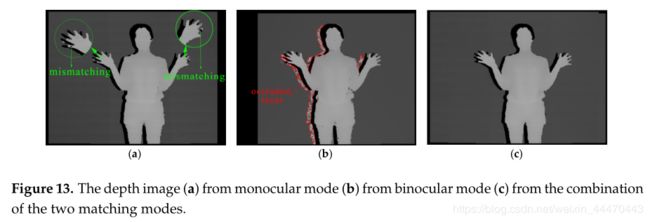
首先,我们采用基于硬件平台的方法对人进行测试,测试结果如图13所示。图13a为单眼模式下的输出深度图像,手指部分出现了一些不匹配,如图绿色圆圈所示。图13b为双目模式下手指更加清晰的输出深度图像。然而,红色曲线标记的遮挡区域会影响整个图像的质量。因此,我们通过图13a校正被遮挡的区域以生成最终的深度图像,如图13c所示。对比图13a和图13b,很明显,单目模式对微小物体的识别能力低于双目模式,且不匹配更容易。在减小块大小后以单目模式出现在类似对象上。相反,在图13b中,机身上的噪声稍微大一些。
原因是身体的表面相对复杂。表面也存在遮挡。人周围的黑色区域是检测到的阴影区域,最终的结果(图13c)证明了我们的方法主要可以综合图13a,b的优点。
为了测试我们的系统的空间分辨率和直观地比较结果与其他类似的设备,比如这款产品Pro,两Kinect, Kinect 2,和Realsense R200,连续几棍子上的深度地图与已知的宽度,如图14所示,得到,如图15所示。直杆的宽度从左到右分别为5、8、10、12、15、20和25 mm。如图15所示,我们的方法的结果总是优于Kinect、XTion Pro和RealSense的结果。例如,在图15F中1.5 m的测试距离处,第一根木棒仍然可以更好地识别,但在图15B、C、E中只能在0.7 m处识别。在1.9 m处,我们的深度图中仍然有六根木棒,但在其他三张图中只有三根木棒。此外,很明显,图15e中的噪声很大,平面物体上的深度图总是闪烁。原因是英特尔为了降低维度而牺牲了realsense的性能。realsense r200的尺寸只有101.56mm(长)×9.55mm(高)×3.8mm(宽),是目前最小的深度传感器。与kinect 2相比,由于kinect 2无法识别1.5m处的第一根棍子,所以在1.5m之前,我们的结果稍好一些。在1.5m的测试距离之外,我们的方法平滑了无法测试的较薄棍子的深度。然而,Kinect 2可以标记这些不确定的区域,尽管它也无法获得这些物体的深度值,例如第一根棍子的位置从1.5 m到3.1 m。虽然我们的方法存在一些问题,但是图13和图15的结果仍然证明了本方法的有效性。d不仅提高了深度图像的空间分辨率,而且保证了深度图像的质量。
在图15中,我们简化了测试场景和对象,在理想的环境下测量不同设备的空间分辨率。结果在很大程度上是最优的。在实际应用中,物体的场景和结构比较复杂,会影响测试结果。因此,在接下来的文章中,我们给出了更多的实验结果并进行了讨论。
如图16所示,我们在一些大写字母上尝试了我们的系统。笔画分别为10mm(上一行)和15mm(下一行),已在图16a中标注。测试距离约1.15 m。在图14和图15中,宽度为10mm和15mm的木棍分别是第三根和第五根。实验结果表明,在1.15 m的深度下,两根测棒都可以进行测试。图16中的测试结果与这个结论是一致的。所有的设备都能检测到这个位置有一些物体。然而,准确地识别它们是哪些字母是不同的。例如,对于图16b、c、e中的字母“N”,上面一行的测试结果很差。在下一行中,图16b、c中的结果略有改善,但它们看起来更像字母“H”。图16d,f显示了相对于其他三个的改进,但是在测试结果中也存在一些问题。字母“A”上的洞不会被我们的系统或Kinect 2检测到。



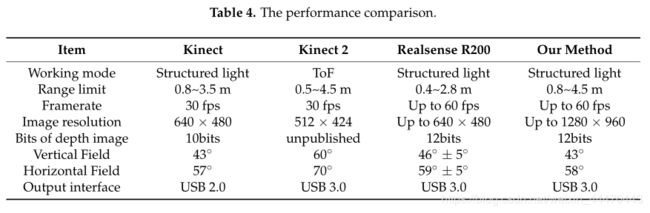
最后,我们在一个复杂的家具场景中进行了实验,实验结果如图17所示。表4给出了各设备的工作模式和性能特点。XTion和Kinect采用相同的芯片(PrimeSense p1080),性能特征几乎相同,因此我们不在此表中列出它们。首先,从图17可以看出,我们的系统和Kinect 2的深度捕获距离明显优于其他设备。图17d,f中只能测试物体8。其次,kinect 2采用了tof技术,而其他设备都是基于结构光的。物体6可以在图17b、c、f中进行测试。但是,Kinect 2在其范围限制内无法检测到它。因此,我们认为有时结构光技术比tof技术更好。最后,光学现象会影响测量结果。在图17d中,物体2上有一些噪声,这是一个镜面反射物体。物体3的表面吸收光线,这对基于主动视觉的深度测量性能有着重要影响。

6. Conclusion
为了提高双红外相机深度图像的空间分辨率,提出了一种基于主动结构光的深度传感系统的fpga硬件设计方法。首先,基于窄带通滤波的红外摄像机与红外激光配合,捕捉到激光投射的清晰的散斑图,并用于标记空间;其次,通过减小材料块的尺寸,提高了x-y方向的空间分辨率。但尺寸越小,匹配应变精度越低。因此,将这两种匹配模式结合起来以获得更精确的数据。此外,该方法还解决了传统双目立体视觉系统中存在的遮挡问题。再次,介绍了深度传感方法的全流水线结构,并在fpga平台上进行了验证。但是,如果我们的系统要在未来得到广泛的应用,就需要对硬件资源和功耗进行一些优化,并且还需要越来越多的各种场景来验证系统,这将是我们未来工作的重点。
Appendix A
在图15d中来自kinect 2的深度图像中,深度中的不确定区域由暗像素标记。这使得测量杆的深度难以与不确定区域区分开来。因此,我们在图15d中做了一个小的更改,如图alb所示,不确定的区域用白色像素标记。
