JAVA常用API
API:Application Programming Interface应用编程接口
文章目录
- API:Application Programming Interface应用编程接口
- Java.lang.Object
- Java.lang.String
- StringBuilder/StringBuffer
- Java.lang.Number
- 三大日期处理类:date/simpledateformat/Calendar
- Java.util.Date
- java.text.SimpleDateFormat
- java.util.Calendar
- JAVA.IO:数据的读写抽象成数据,在管道中流动。
- java.io.Serializable(序列化接口)
- java.io.Reader /java.io.Writer (字符流抽象超类)
- NIO- 非阻塞IO
- java.io.File(文件类)
- java.io.RandomAccessFile
- org.junit.Test:测试注解
- 数据格式
- XML:(Extensible Markup Language)可扩展标记语言:
- yaml - yet another markup language - 夜猫数据格式
- JSON(JavaScript Object Notation, JS 对象简谱)
- Dom API for Java(dom4j)
- java.util.Properties
- java.lang.Thread :线程
- ExecutorService(Interface )
- java.net.Socket
- java.net.Socket (client客户端)
- java.net.ServerSocketServer(Server服务端)
- java.util.Map(查找表)接口
- java.util.HashMap(哈希表/散列表)
- java.util.Colletction(集合框架)接口
- java.util.Collections(集合工具类):
- java.util.Iterator(迭代器接口)
- 二叉树
- 红黑树
- 爬虫:(org.jsoup.Jsoup)
- 手写Spring[控制反转(IOC)、依赖注入(DI)]
- 手写SpringMVC框架
- 手写双向循环链表
- 编码实现 使ArrayList能够线程安全。
一切可以调用的东西都是API。java.lang包:这个包会自动导入。
常用的类:
java.lang.Math ;Math.random():生成0到1之间的随机小数
java.lang.System;
java.util.Scanner;
java.util.Timer(计时器TimerTask(java.util));
Java.lang.Object
Object是所有类的顶级父类,常用方法如下:
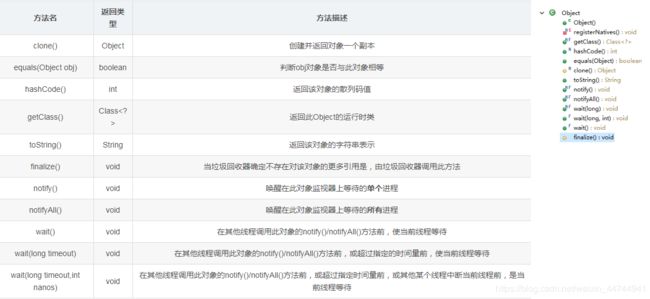
clone方法
保护方法,实现对象的浅复制,只有实现了Cloneable接口才可以调用该方法,否则抛出CloneNotSupportedException异常。
getClass:获取运行时类型、finalize方法:对象销毁之前执行该方法、
hashCode:该方法用于哈希查找,可以减少在查找中使用equals的次数,重写了equals方法一般都要重写hashCode方法
String toString():
默认返回类名@地址格式,来展示对象的地址值(并不是内存中的地址,只是一种转换);
如果想看属性值我们可以重写这个方法,重写后返回的就是把属性值拼接成一个字符串。
boolean equals(Object obj) :
当前对象和参数对象比较大小,默认是比较内存地址==,如果要比较对象的属性,可以重写该方法。
wait():wait方法就是使当前线程等待该对象的锁,当前线程必须是该对象的拥有者,也就是具有该对象的锁。wait()方法一直等待,直到获得锁或者被中断。wait(long timeout)设定一个超时间隔,如果在规定时间内没有获得锁就返回。
调用该方法后当前线程进入睡眠状态,直到以下事件发生。
(1)其他线程调用了该对象的notify方法。
(2)其他线程调用了该对象的notifyAll方法。
(3)其他线程调用了interrupt中断该线程。
(4)时间间隔到了。
此时该线程就可以被调度了,如果是被中断的话就抛出一个InterruptedException异常。
notify():唤醒沉睡线程, notifyAll():唤醒所有沉睡线程;
必须在synchronized内调用,等待通知的对象,必须是加锁的对象(synchronized同步监视器对象),wait外面,应该是一个循环条件判断;
生产者类: public class Producer extends Thread {
private LinkedList<Character> list;
public void run() {
while(true) {
char c = (char)('a'+new Random().nextInt(26));
//避免共享的数据的混乱,保证多线程共享数据的安全;
synchronized (list) {
list.add(c);//加至集合尾部
System.out.println("<<< << < "+c);
list.notifyAll();//通知所有的线程,有货了可以醒了}}}
public Producer(LinkedList<Character> list) {
this.list = list;}
消费者类: public class ConSumer extends Thread {
private LinkedList<Character> list;
public ConSumer(LinkedList<Character> list) {
this.list = list;}
public void run() {
while(true) {
synchronized (list) {
while(list.size()==0) {//没有数据的情况下
try {list.wait();//线程休眠;
} catch (InterruptedException e) {
e.printStackTrace();}}
Character c = list.removeFirst();//从头部移除
System.out.println(">>> >> > " +c);}} }
Java.lang.String
概述:String底层维护着一个char[]数组,并且字符串对象不可变,每次操作都会创建新对象,所有任何改变字符串的操作都应该赋值接收; 为何不许修改呢?只读,这有什么好处呢?好处大大的:字符串在实际开发中比重非常大,几乎代码都会涉及到字符串。字符串是引用类型,它的分配和其他的对象分配一样,耗费高昂的时间与空间代价,作为最基础的数据类型,大量频繁的创建字符串,极大程度地影响程序的性能。 JVM为了提高性能和减少内存开销,在实例化字符串常量的时候进行了一些优化。为字符串开辟一个字符串常量池,类似于缓存区。创建字符串常量时,首先判断字符串常量池是否存在该字符串,存在该字符串,返回引用实例,不存在,实例化该字符串并放入池中。 上面的意思就是,JVM实现字符串的共享,这就带来一个新的问题。多线程并发访问就会造成安全隐患。线程安全可是非常难解决的。加锁阻塞(就像商城去试衣间,就一间,你要进去,别人就得等着了。)可想而知,性能受到极大的影响。这个怎么好呢?java太厉害了,它就用了一招轻松化解。什么呢?字符串只读。啊,这样也可以,没错。 如果是第一次使用字符串,java会在字符串常量池创建一个对象。再次使用相同的内容时,会直接访问常量池中存在的对象。java中字符串字面量之间的拼接,编译器在编译期会进行优化,在.class文件中保存的是拼接后的结果;String str = new String(“a”+“b”);字符串变量之间的拼接,编译器不会优化,底层采用new的方式创建了一个新的String对象;

Stirngl类常用方法:
new String(byte数组,字符集);
new String(StringBuilder builder) ;
length(): int
indexOf(String str):int
indexOf(String str,int fromIndex):int
lastIndexOf(String str):int
substring(int fromIndex):String
substring(int start,int end):String
trim():String
charAt(int):char
startsWith(String str):boolean
endsWith(String str):boolean:
toUpperCase(): string
toLowerCase():String
s.contact(s1):s字符串拼接到s1末尾
s.contains(String str):是否包含给定字符串
s.toCharArray():转换成字符数组
Str = Str.replaceAll("\\s+", ""):
String 类实现了Comparable接口,并实现了compareTo()方法 方法在实现中,将两个字符串内容中的字符进行ASCII码值减的操作, 从前往后减,如果第一个字符相同,就操作第二个字符,再次减,直到 运行到不相同的字符,将结果返回,如果字符内容和大小写都相同,则返回0 ;
StringBuilder/StringBuffer
概述:是可变的字符序列,提供一组对内部字符修改方法,用来代替字符串,作高效率字符串连接运算
1、 封装了char[]数组,内部数组初始容量16,放满了容量翻倍+2;
2、 是可变的字符序列
3、 提供了一组可以对字符内容修改的方法
4、 常用append()来代替字符串做字符串连接
5、 内部字符数组默认初始容量是16:super(str.length() + 16);
6、 如果大于16会尝试将扩容,新数组大小原来的变成2倍+2,容量如果还不够,直接扩充到需要的容量大小。int newCapacity = value.length * 2 + 2;
集合扩容:
凡是利用数组实现的长度可变的存结构,都会使用数组复制实现扩容。
ArrayList
1.默认情况下创建 ArrayList时候,其数组容量是10;
2.可以在创建 ArrayList时候指定数组容量。
3.当元素数量超过数组容量时候,进行扩容(数组复制,更换数组),扩容到1.5倍。
4.添加元素多时候,频繁扩容会影响性能,所以建议在可以预知元素数量时候,采用指定容量创建ArraysList。
StringBuilder
1.内部封装的是一个“可变”字符数组,其默认容量是16元素。
2.向StringBuilder添加字符数量超过16时候,会自动扩容(复制更换数组),扩展规则 1倍+2
3.为了避免频繁扩容,可以在创建StringBuilder时候指定容量。
Sb常用方法:

StringBuilder sb = new StringBuilder(); 创建16位的空数组;
StringBuilder sb = newStringBuilder(String “str”):
创建一个包含‘s’‘t’‘r’字符的16位字符数组;
sb.append(String): 拼接字符串
sb.delete(int start,int end):
删除从start开始 到end结束的字符串
sb.insert(int index,String str):
将给定的字符串插入到index位置
sb.replace(int start,int end,String str)
使用给定的字符串替换(下标是包头不包尾)
sb.reverse(): 反转字符串,(判断回文)
StringBuffer和StringBuilder区别:
StringBuffer和StringBuilder功能相同,api的使用也是相同的,区别在于StringBuilder是非线程安全的,StringBuffer是线程安全的;
1.在执行效率上,StringBuilder 1.5> StringBuffer 1.0 > String
2.源码体现:本质上都是在调用父类抽象类AbstractStringBuilder来干活,只不过Buffer把代码加了同步关键字,使得程序可以保证线程安全问题;
Java.lang.Number
概述:数字包装类的抽象父类,提供了各种获取值的方式: (例如) int intvalue();以int形式返回指定的数值;以下是代表子类:
1 java.lang.Integer :
int的包装类,存在MAX_VALUE/MIN_VALUE常量
1、Integer i = new Integer(5);
2、Integer i = Integer.valueOf(5);
在Integer类中,包含256个Integer缓存对象,范围是-128到127。使用valueOf()时,如果指定范围内的值,访问缓存对象,而不新建;如果指定范围外的值,直接新建对象。
static int parseInt(String s): 将字符串参数作为有符号的十进制整数进行解析。
static Integer valueOf(String s): 返回保存指定的String的值的Integer对象。
2 java.lang. Double:
double的包装类
Double d = new Double(3.14)
Double d = Double.valueOf(3.14) //和 new 没有区别
static double parseDouble(String s)
返回一个新的 double 值,该值被初始化为用指定String表示的值,这与 Double 类的 valueOf 方法一样。
static Double valueOf(double d) //返回表示指定的double值的Double实例。
3 BigDecimal/BigInteger:
BigDecimal:常用来解决精确的浮点数运算。
BigInteger:常用来解决超大的整数运算。
BigDecimal.valueOf(2);
add(BigDecimal bd): 做加法运算
substract(BigDecimal bd) : 做减法运算
multiply(BigDecimal bd) : 做乘法运算
divide(BigDecimal bd) : 做除法运算
divide(BigDecimal bd,保留位数,舍入方式):除不尽时使用
setScale(保留位数,舍入方式):同上
pow(int n):求数据的几次幂
三大日期处理类:date/simpledateformat/Calendar

Java.util.Date
日期类,其每一个实例都用于表示一个确切的时间点。内部维护一个Long值,该值为UTC时间,表示的时自1970年1月1日00:00:00到当前Date表示的时间之间所经过的毫秒数;
Date date = new Date():封装的是系统当前时间的毫秒值.
long time = date.getTime():1970年到现在的毫秒数
date.setTime(671094845218L):设置毫秒数,使得date表示该日期,负数表示1970之前,正数表示1970之后
getMonth():获取当前月份
getHours():获取当前小时
int getDay():获得星期几
int getMinutes() :获得当前分钟数
long getTime() :1970-01-01到现在的毫秒
int getYear() :1900年到现在多少年;
String toLocaleString():2019-10-14 16:50:41
compareTo(Date):当前对象与参数对象比较。当前对象大返回正数,小返回负数,相同0。
java.text.SimpleDateFormat
SimpleDateFormat类可以按照指定的日期格式在Date与String之间相互转换
1、yyyy-MM-dd HH:mm:ss 示例:2019-1-1 12:12:12
2、MM/dd/yyyy 示例:10/14/2019
SimpleDateFormat sf = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
String d = format(Date) 把Date格式化成字符串
Date d = parse(String) 把String解析成Date
java.util.Calendar
日历类Calendar是一个抽象类,定义了操作时间的相关方法,常用实现类:GregorianCalendar(阳历)
Calendar calendar = Calendar.getInstance();
根据当前系统所在地区获取一个适用的实现类,通常返回的就是GregorianCalendar;
创建2019年7月15日的Calendar对象
Calendar c1 = Calendar.getInstance();
c1.set(2019, 7 - 1, 15); //月份从0月开始算起的
Date date = calendar.getTime();将当前Calendar表示的时间以一个Date实例返回
calendar.setTime(date);调整当前Calendar的时间为给定的Date所表示的时间。
Int get(int Field) 该方法可以获取指定的时间分量所对应的值,
时间分量为一个int值,无需记住每个值的含义,Calendar提供了大量的常量与之对应
void set(int field,int value) 调整指定的时间分量为指定的值
calendar.set(Calendar.YEAR, 2008): 调整时间为2008年
void add(int field,int amount)
对指定的时间分量加上给定的值,若给定的值为负数则是减去。
calendar.add(Calendar.MONTH,- 3):例如查看三个月前的此时此刻
JAVA.IO:数据的读写抽象成数据,在管道中流动。
Ø 流只能单方向流动
Ø 输入流用来读取in
Ø 输出流用来写出Out
Ø 数据只能从头到尾顺序的读写一次。
节点流(低级流):是实际连接程序与数据源的“管道”,针对二进制数据,用于实际搬运数据的流,读写一定是建立在低级流的基础上进行的。
处理流(高级流):高级流不能独立存在,必须连接在其他流上,目的是当数据“流经”当前流时可以对其进行某种加工处理,简化我们读写数据时的操作。
串联一组高级流最终连接到低级流上,在读写的过程中以流水线式的加工处理完成读写操作称为“流的连接”,这也是JAVA IO的精髓所在(学习重点);
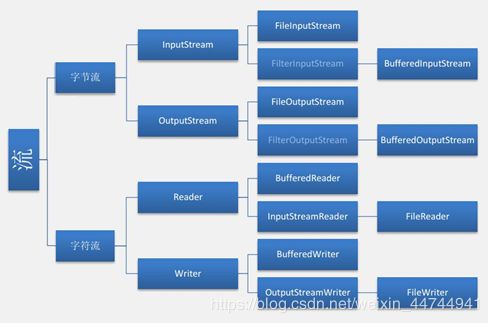
JAVA.IO.InputStream:字节输入流的抽象超类(read)。
JAVA.IO.OutputStream:字节输出流的抽象超类(write)。
void close()
关闭此输出流并释放与此流有关的所有系统资源。
void flush()
刷新此输出流并强制写出所有缓冲的输出字节。
void write(byte[] b)
将 b.length 个字节从指定的 byte 数组写入此输出流。
void write(byte[] b, int off, int len)
将指定 byte 数组中从偏移量 off 开始的 len 个字节写入此输出流。
abstract void write(int b)
将指定的字节写入此输出流。
FileInputStream /FileOutputStream(文件流):文件流是一对低级流,用于读写文件的流。文件流的两种创建方式:
覆盖原文件模式:new FileInputStream(File/路径);
追加至末尾模式:new FileInputStream(File路径,true);
randomAccessFile与文件流区别:
文件流其功能与RandomAccessFile一致。但是底层实际的读写方式不同,RandomAccessFile是以指针形式对文件进行随机读写的,并且RAF既可以读数据也可以写数据,能做到对文件部分数据的修改操作 ;
文件流以标准IO形式读写数据的,而标准IO是以顺序读写形式进行操作的(只能向后读或写,不能回退)所以在读写的灵活性上文件流不如RAF,但是由于文件流是以标准IO形式读写,可以利用强大的流连接将一个复杂的数据读写操作简单化,这是RAF做不到的;
缓冲字节流:(高级流)
- java.io.BufferedInputStream
- java.io.BufferedOutputStream
为另一个输入流添加一些功能,即缓冲输入以及支持 mark 和 reset 方法的能力。在创建 BufferedInputStream 时,会创建一个内部缓冲区数组(默认8M大小)。在读取或跳过流中的字节时,可根据需要从包含的输入流再次填充该内部缓冲区,一次填充多个字节.
缓冲流内部有一个字节数组作为缓冲区,当我们使用缓冲输入流读取一个字节(d = bis.read())时 实际上缓冲流会一次性读取一组字节并存入自己内部的字节数组中(块读),然后将第一个字节返回, 如果我们再次调用读取一字节方法时,缓冲流直接将 字节数组中第二个字节返回,直到所有字节均返回后,才会再次实际读取一组字节回来;因此,缓冲输入流就是将实际读取操作转换为块读取 操作来保证的读取效率;缓冲输出流也是一样的道理;
.flush() 强制将当前缓冲流中已缓存的字节一次性写出。
.close() 缓冲流在close时会自动调用flush方法一次;
//1、创建from文件
File from = new File("D:\\teach\\a\\1.jpg");
//2、字节流,读取源文件。
InputStream in = new BufferedInputStream(
new FileInputStream(from) );
//3、创建to文件,同时准备写出流。
File to = new File("D:\\teach\\a\\2.jpg");
OutputStream out = new BufferedOutputStream(
new FileOutputStream(to));
/*4、边读,边向to文件中写出数据
int b = 0;
while( ( b = in.read() ) !=-1) {//单字节读取文件
out.write(b);//写出数据到指定文件 }*/
int b = 0;
//缓存要操作的数据,底层源码一般设置的数组默认大小就是8m
byte[] bs = new byte[8*1024];
while( ( b = in.read(bs) ) !=-1) {//按照数组批量读取
out.write(bs);//按照数组批量写出 }
ObjectInputStream/ObjectOutputStream(对象流):
对象流是一对高级流,使用它们可以方便的在对象与字节之间进行转换,方便我们读写任何java对象。
对象输入流,用于读取一个JAVA对象, 需要注意,读取的这组字节必须是通过对象输出流将一个对象转换的一组字节,否则读取过程会抛出异常。
对象输入流将一组字节按照其描述结构还原该对象的过程称为:对象的序列化。 希望被对象流序列化的类必须实现接口Serializable
/*
* 编码转换流():
* InputStreamReader
* OutPutStreamWriter
* 处理换行的流:
* BufferedReader readLine();
* PrintWriter println()
* BR---ISR---网络输入流(inputStream):
* PW---OPR---网络输出流(outputStream):
*/
BufferedReader br = new BufferedReader(new InputStreamReader(socket.getInputStream(),"utf-8"));
PrintWriter pw = new PrintWriter(new OutputStreamWriter(socket.getOutputStream(),"utf-8"));
String line;
while((line = br.readLine())!= null) {
pw.println(line);
pw.flush();
java.io.Serializable(序列化接口)
- Java 提供了一种对象序列化的机制,该机制中,一个对象可以被表示为一个字节序列,该字节序列包括该对象的数据、有关对象的类型的信息和存储在对象中数据的类型。
将序列化对象写入文件之后,可以从文件中读取出来,并且对它进行反序列化,也就是说,对象的类型信息、对象的数据,还有对象中的数据类型可以用来在内存中新建对象。
整个过程都是 Java 虚拟机(JVM)独立的,也就是说,在一个平台上序列化的对象可以在另一个完全不同的平台上反序列化该对象。
序列化一般使用实现Serializable接口,它是一个空接口,只起到标识作用,当编译器在编译一个类的源代码时若发现其实现了可序列化接口,那么会在编译class文件时包含一个方法,这个方法的功能就是将这个类的实例转换为一组字节。对象流就是用这个方法将该对象转换为字节的。但是由于源代码中不需要体现,因此我们实现可序列化接口时不需要重写任何方法。当一个对象属性被关键字transient修饰后,那么这个对象在进行序列化时这个属性的值就会被忽略。
- 对象输出流:将给定对象按照其结构转换为一组字节并通过对象流连接的流将这组对象写出,将对象通过对象流写入文件这里经历两个过程:
- 当对象经过对象输出流时,对象输出流将这个对象按照其结构转换成了一组字节,这组字节包括了该对象的结构信息和实际数据。这个过程称为 “对象序列化”;
- 序列化后的这组字节再经过对象输入流后就被写入了文件中,写入文件就等于写入了磁盘做长久保存,而将数据写入磁盘的过程称为 “数据持久化” ;
- [了解]序列化/反序列化 概述:
序列化 (Serialization)是将对象的状态信息转换为可以存储或传输的形式的过程。
在序列化期间,对象将其当前状态写入到临时或持久性存储区。以后,可以通过从存储区中读取或反序列化对象的状态,重新创建该对象。
序列化:利用对象输出流,将对象的信息按固定格式转成一串字节值输出并持久保存。
反序列化:利用ObjectInputStream,读取序列化数据,重新恢复对象。
特点/应用场景;
序列化是将一个对象转换成一组字节写入磁盘,反序列化是将磁盘中的字节转换成一个对象(转换后的对象是一个新的对象),当我们需要拿到同一个对象数据的不同对象时,可以尝试序列化该对象,并反序列化。一般建议保存数据的对象类都实现序列化接口。因为很多框架底层都会转换该对象。
1、 需要序列化的文件必须实现Serializable接口以启用其序列化功能。
2、 每个被序列化的文件都有一个唯一id,如果没有添加编译器会根据类的定义信息计算产生一个版本号。
3、 不需要序列化的数据可被修饰为static的,由于static属于类,不随对象被序列化输出。
4、 不需要序列化的数据也可以被修饰为transient临时的,只在程序运行期间,在内存中存在不会被序列化持久保存。
5、 在反序列化时,如果和序列化的版本号不一致时,无法完成反序列化。
6、 常用于服务器之间的数据传输,序列化成文件,反序列化读取数据。
7、 常用于使用套接字流在主机之间传递对象。
8、 ObjectInputStream 和 ObjectOutputStream 是高层次的数据流,它们包含反序列化和序列化对象的方法。
import java.io.*;
public class SerializeDemo {
public static void main(String [] args) {
JavaBean b = new JavaBean();
b.name = "java_bean";
try {
FileOutputStream fileOut = new FileOutputStream("/tmp/javaBean");
ObjectOutputStream out = new ObjectOutputStream(fileOut);
out.writeObject(e);
out.close();
fileOut.close();
}catch(IOException e) {
e.printStackTrace(); }}}

如上图,序列化不会序列静态属性和transient修饰属性。
java.io.Reader /java.io.Writer (字符流抽象超类)
由于读写文本数据在实际开发中非常常见,因此java推出了一些列用于读写文本数据的流,并给他们单独分类为字符流;
- 字符流是以字符(char)为单位读写数据的,所以字符流只适合读写文本数据,读写时最好指定字符集,以免乱码;
字符流底层实际还是读写字节,只是字符(char)与字节(byte)的转换工作由字符流自行完成了。
int read()
读取单个字符。
int read(char[] cbuf)
将字符读入数组。
abstract int read(char[] cbuf, int off, int len)
将字符读入数组的某一部分。
int read(CharBuffer target)
试图将字符读入指定的字符缓冲区。
abstract void close()
关闭该流并释放与之关联的所有资源。
- 转换流,转换流是常见的字符流实现类,是一对高级流,实际开发中我们通常不会把它们作为终端流使用,但是它们在连接中起到重要的一环。
终端流:流连接完成后,我们实际操作的流。
OutputStreamWriter和inputStreamWriter:
字符转换流,转换流是唯一一个可以直接连接在字节流上的字符流。而其他字符流都要求只能连接在字符流上,这会导致这些字符流在作为终端流使用时不能直接串联底下的某些字节流,因此转换流在这里就有非常重要的作用了,我们通常使用它们来衔接字符流与字节流使用,起到“转换器”的作用。(在创建的时候可以指定第二个编码集参数)
创建对象
OutputStreamWriter(OutputStream out, String charsetName)
创建使用指定字符集的 OutputStreamWriter。
OutputStreamWriter(OutputStream out)
创建使用默认字符编码的 OutputStreamWriter。
java.io.PrintWriter:具有自动行刷新的缓冲字符输出流,内部总是连接BufferedWriter作为加速操作。
在流连接中创建PrintWriter时,可以再传入一个参数,该值为boolean值,若该值为true则当前PW具有了自动行刷新功能。
此时每当我们调用Println方法后,写出指定内容就会自动flush. BufferedReader:缓冲字符输入流 ,特点:读写效率高,可以按行读取字符串,提供的方法:
String readLine()
* 读取一行字符串,返回值不含有该行末尾的换行符。
* 如果返回值为null,则表示读取到了流的末尾。
* 若是读取的文件,则表示文件读取到了末尾。
NIO- 非阻塞IO
[NIO:]也叫new io,对比传统的同步阻塞IO操作,实际上NIO是同步非阻塞IO。NIO的优势主要体现在网络数据传输上。利用”信道”,进行多路复用。Channel:通道,类似于流
Buffer:缓冲,用缓冲的内存空间可以临时存放要读写的数据,用空间交换时间
BIO - 阻塞IO:
BIO读取过程:共三次复制拷贝过程
- jvm堆执行fileInputStream.read()请求操作系统,然后操作系统请求磁盘。
- 从磁盘中读取到数据,然后写到操作系统缓冲区中。
- 将数据从操作系统缓冲区放到jvm进程缓冲区(按字节流读取,即一个一个字节byte读取数据)。
- jvm将jvm进程中缓冲区东西拷贝到jvm堆内存中(应用部署位置)。
-
NIO 与BIO的区别有如下两点:
相对于bio的一个一个byte传,nio是以channel形式读取buffer缓冲区,然后以块数据传输;
nio减少了复制过程,直接把磁盘映射到JVM进程的虚拟地址空间,放置对应到页表上。 -
BIO、NIO、AIO的区别:
阻塞IO: BIO 就是传统的 java.io 包,它是基于流模型实现的,交互的方式是同步、阻塞方式,也就是说在读入输入流或者输出流时,在读写动作完成之前,线程会一直阻塞在那里,它们之间的调用时可靠的线性顺序。它的有点就是代码比较简单、直观;缺点就是 IO 的效率和扩展性很低,容易成为应用性能瓶颈。
非阻塞IO: NIO 是 Java 1.4 引入的 java.nio 包,提供了 Channel、Selector、Buffer 等新的抽象,可以构建多路复用的、同步非阻塞 IO 程序,同时提供了更接近操作系统底层高性能的数据操作方式。
异步IO: AIO 是 Java 1.7 之后引入的包,是 NIO 的升级版本,提供了异步非堵塞的 IO 操作方式,所以人们叫它 AIO(Asynchronous IO),异步 IO 是基于事件和回调机制实现的,也就是应用操作之后会直接返回,不会堵塞在那里,当后台处理完成,操作系统会通知相应的线程进行后续的操作。但目前还不够成熟,应用不多。
private static String from = "C:/迅雷下载/白象.rmvb";
private static String bioto = "c:/bioto.rmvb";
private static String nioto = "c:/nioto.rmvb";
public static void main(String[] args) throws Exception {
System.out.println("正在拷贝文件,请稍等...");
bioCopy();
nioCopy();
}
//阻塞IO方式
private static void bioCopy() throws Exception {
long startTime = System.currentTimeMillis();
* 开发步骤:
* 1、读取源文件放在输入流中
* 2、创建输出流,写文件
* 3、声明buf缓存区
* 4、读取缓冲区
* 5、写输出流
* 6、倒着关闭释放资源
InputStream is = new FileInputStream(from);
OutputStream os = new FileOutputStream(bioto);
byte[] buffer = new byte[8192];//习惯使用8192
int len;
while((len = is.read(buffer))>0) {
os.write(buffer, 0, len); }
is.close();
os.close();
long endTime = System.currentTimeMillis();
System.out.println("bioCopy 耗时:" + (endTime - startTime));
//非阻塞IO方式
private static void nioCopy() throws IOException {
long startTime = System.currentTimeMillis();
* 开发步骤:
* 1、使用nio的FileChannel通道技术,性能翻倍
* 2、复制文件要设置属性:可读+可写+创建新文件,如果已经存在保存
* 3、复制
* 4、关闭释放资源
FileChannel fcFrom = FileChannel.open(Paths.get(from), StandardOpenOption.READ);
FileChannel fcTo = FileChannel.open(Paths.get(nioto), StandardOpenOption.READ, StandardOpenOption.WRITE,
StandardOpenOption.CREATE_NEW);
fcTo.transferFrom(fcFrom, 0, fcFrom.size()); //复制
fcTo.close();
fcFrom.close();
long endTime = System.currentTimeMillis();
System.out.println("nioCopy 耗时:" + (endTime - startTime));
}}
执行结果:性能nio快接近bio的10倍啊!
复制0.8g的电影耗时:
正在拷贝文件,请稍等…
bioCopy 耗费时间:17053
nioCopy 耗费时间:1303
java.io.File(文件类)
是一个代表文件或目录(区分文件的路径)的类,file
封装一个磁盘路径字符串,对这个路径可以执行一次操作,可以用来封装文件路径、文件夹路径、不存在的路径。
File(String pathname)
File(File parent,String child)
File(String parent,String child) 通过将给定路径名字符串转换为抽象路径名来创建一个新 File 实例。
length():文件的字节量
exists():是否存在,存在返回true
isFile():是否为文件,是文件返回true
isDirectory():是否为文件夹,是文件夹返回true
getName():获取文件/文件夹名
getParent():获取父文件夹
getAbsolutePath():获取文件的完整路径
createNewFile():新建文件,文件夹不存在会异常,文件已经存在返回false
mkdirs():是否需要新建多层文件夹
mkdir():是否需要新建单层文件夹
delete():删除文件,删除空文件夹
list():返回String[],包含文件名
listFiles():返回File[],包含文件对象
listFiles(FileFilter filter):File[]获取指定目录下所有满足条件的File对象

递归(recursion):不断的调用方法本身。
- 递归三要素
自身调用自身
不同参数值,但处理过程一样
必须有结束条件,否则死循环
//递归求文件总大小
private static long method(File dir) {
File[] fs = dir.listFiles();//1、把dir目录的所有资源列出来
long size=0;//记录文件的总大小
for (int i = 0; i < fs.length; i++) {//2、遍历每个资源fs[i]
if( fs[i].isFile() ) {//判断是不是文件
size += fs[i].length();//每个文件求和
}else if( fs[i].isDirectory() ) {//判断是不是文件夹
//重复的干:继续列表,是文件就求和,是文件夹就继续遍历文件夹
size += method(fs[i]);//功能和method()一模一样就不再定义新方法了,直接使用自己本身的方法就可以了 ,这就形成了递归调用模式;
} } return size;}}
java.io.RandomAccessFile
该类的实例支持读取和写入随机访问文件。 随机访问文件的行为类似于存储在文件系统中的大量字节。 有一种游标,或索引到隐含的数组,称为文件指针 ; 输入操作读取从文件指针开始的字节,并使文件指针超过读取的字节。 如果在读/写模式下创建随机访问文件,则输出操作也可用;
RandomAccessFile(File/String dest,String mode)
RandomAccessFile raf = new RandomAccessFile("文件名/路径","r/rw");
write(int n): 向文件中写入一个字节 ,写入的是int值的低八位(int值32位,最后八位,int4个字节,即最后一个字节)
read():int 读取一个字节数据,以int形式返回,若读取到文件末尾,返回-1;
long pos = raf.getFilePointer();获取RAF当前指针的位置,返回一个long值,不论读写操作指针都会移动到操作位置下标处
seek():移动当前读取文件的位置指针;
WriteInt(int d):连续写四个字节;按照单字节方式复制效率低,为了提高效率,我们可以采取每次复制一个字节数组的字节量,从而减少复制的次数,提高效率
read(byte[] bys):int将从文件中读取到的字节数据存入此数组中,返回的int值表示实际读取到的字节长度(读取到数据末尾返回-1)
write(byte[]):向文件中写入一个字节数组
write(byte[] bys,int index,int len)向目标文件中写入bys中从index开始的连续len个字节
org.junit.Test:测试注解
使用方法没有参数、没有返回值、方可用@Test注解;
@Before: 在@Test注释的方法前执行
@After: 在@Test注释的方法后执行
- 单元测试特点
单元测试类独立,只用于测试阶段,其它无用
@Test注解修饰的方法可以独立执行,双击选中类名,右键RunAs“JUnit Test”
空白处右键RunAs“JUnit Test”,如果一个方法直接执行,如果多个方法乱序执行。因为单元测试方法之间是没有关系的,没有先后顺序的
jUnit包eclipse都支持,无需准备,直接导入即可 - 单元测试和main有什么区别
main函数是程序的唯一入口(跟普通方法唯一不同之处,main方法是JVM调用的),一个类只能有一个main函数,开发时没问题,唯一就不会引起歧义争抢,但对于测试就不好用,我有多个独立方法需要执行,这时main就显得无能为力,jUnit单元测试就有了用武之地,注意也只用于测试哦。
简单的说:main只能运行一个方法,jUnit可以支持多个方法。
数据格式
XML:(Extensible Markup Language)可扩展标记语言:
处理节点:必须写在第一行,可省略。
标记/标签(tag): ( <开始标记> )
标记规则:中文英文都可以作为标记名,建议使用英文,区分大小写,开始标记和结束标记要成对使用不能交叉嵌套,一个XML中只有唯一的根标记,标记名可以扩展,标记的嵌套关系可以扩展
注释(Comment):<!-- 写啥都行,注释不能嵌套使用 -->
内容(Content):开始标记和结束标记之间的信息称为内容。
文本内容,标记,多个标记和文本的混合,内容是可扩展的!
元素(Element):标记 + 内容 = 元素
XML 只有一个根元素(rootElement),元素中的元素称为子元素,外层元素称为父元素;
属性(attribute):在开始标记上定义元素的属性,可以定义多个属性,多个属性不分先后次序,属性之间需要有空格
属性名=“属性值” 属性和值之间等号前后不用写空格,属性值必须用 引号
实体 Entity:类似于 Java 的字符串中的转义字符"",一些用于替换表示XML语法的字符。 用来解决XML文字解析错误
常用实体:(< : <) (>: >) (&: &)
<![CDATA[ 文本内容 ]]> 使用CDATA包裹的文本,可以写任何字符,无需进行实体替换;
yaml - yet another markup language - 夜猫数据格式
夜猫不能使用tab制表符,都要使用空格,同一层次,必须对齐,至少两个空格2个,冒号后面需要加空格(jackson 提供了 yaml 数据处理工具,来读取解析yml配置文件);
夜猫格式:(本例三层map结构)
spring:
datasource:
driver: com.mysql.jdbc.Driver
username: root
password: "123456"
url: jdbc:mysql://127.0.0.1:3306/jt?character=utf-8
获得application.yml配置文件的路径
d://xx//xx/xx//application.yml绝对路径(移动,换平台就行不通了)
"/" ---- 表示当前类对象(.class文件)所在的文件夹(bin文件夹)
String path = 当前类.class.getResource("/application.yml").getPath();
// path 是经过URL编码的字符串,编译成d:/中/xxx----->d:/%e4%b8%ad/xxx --解码--> d:/中/xxx
// URLDecoder类的decode(String,编码集)方法可解码
path = URLDecoder.decode(path,"UTF-8");
ObjectMapper m = new ObjectMapper(new YAMLFactory());
Map cfg = m.readValue(new File(path), Map.class);
JSON(JavaScript Object Notation, JS 对象简谱)
是一种轻量级的数据交换格式,后面代替了xml:其中包含了若干个key-value结构,其中key只能是字符串(引号可以省略),value可以是任意类型:数值、字符串、布尔值、数组、null、object(json)、方法;
json语法1:{"name": "John Doe", "age": 18}; JS对象
Json语法2:[{"id":1,"name":"张","school":"培优班"},{"id":2,"name":"齐","school":"高手班"}]; 数组
Jackson:Jackson中有个ObjectMapper类很是实用,用于Java对象与JSON的互换。常用于序列化和反序列化;
序列化是指将程序中的java对象序列化成二进制文件保存到磁盘中永久存储。
反序列化时指将磁盘存储的二进制文件解析成java对象在程序中使用。
1、 把json串转化成Java对象/反序列化
ObjectMapper.readValue(json串,对象类.class);
2、 把Java对象转换成Json串/序列化
ObjectMapper.writeValueAsString(对象);
Dom API for Java(dom4j)
第三方java包,利用SAXReader对象把xml数据,读取在内存中,组织成一个树状结构,再用不同对象来表示其他节点;
jar:JAVA专属压缩包,JVM不需要解压就可以使用jar中的内容
模拟Mybatis框架解析XML:
<mapper namespace="cn.yhmis.mapper.OrderMapper">
<select id="list" resultType="Order">
SELECT * FROM tb_order
select>
<delete id="delete" parameterType="int">
DELETE FROM tb_order WHERE id=#{id}
delete>
mapper>
解析要求:根据传入的namespace和id找到对应的标签,然后解析出其SQL语句
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import java.util.Map.Entry;
import org.dom4j.Element;
import org.dom4j.io.SAXReader;
public class Test5MybatisXml {
private static Map<String, String> map = new HashMap<String, String>();
public void configuration() throws Exception {
String path = getClass().getResource("/OrderMapper.xml").getPath();
//读取解析xml文件,再获得xml的根元素,即元素
Element root = new SAXReader().read(path).getRootElement();
//获得namespace属性的值
String ns = root.attributeValue("namespace");
//获取根元素下一层的所有元素列表
List<Element> elements = root.elements();
//遍历元素列表
for (Element e : elements) {
String name = e.getName();//元素名称
String id = e.attributeValue("id");//id属性的值
String sql = e.getText().trim();//内部包含的文本,即sql语句
map.put(name+":"+ns+"."+id, sql);//数据放入map
} }
public static void main(String[] args) throws Exception {
Test5MybatisXml t = new Test5MybatisXml();
t.configuration();
for(Entry<String, String> e:map.entrySet()) {
String k = e.getKey();
String v = e.getValue();
System.out.println(k+"="+v);
}}}
执行结果:
select:cn.yhmis.mapper.OrderMapper.list=SELECT * FROM tb_order
delete:cn.yhmis.mapper.OrderMapper.delete=DELETE FROM tb_order WHERE id=#{id}
【了解】这部分课程了解即可,在实际项目使用中都被封装好了,我们直接使用即可,上面的过程只是模拟实现mybatis底层的工作原理,让大家将来学习mybatis框架时知道,底层到底干了什么,怎么干的。从而更加容易学习更难懂的知识,以及加深基础功底。了解会用即可,无需完全独立敲出来。
- properties:属性文件一般用来作为程序的配置文件,是纯文本类型,本质是txt文件;#后面写当行注释,尽量不要在属性文件中出现中文;每行都是key value结构,中间用=号分割,key不能重复,读取后的集合中只有value的值;例如,连接数据库时,需要知道数据库服务器的地址,用户名,密码等…这些连接信息,可以存储properties配置文件中,便于修改维护,java提供了专门的工具,来读写这种格式的数
java.util.Properties
java.util.Properties:继承自Hashtable,本质是个Hash表;(可以和流相关联的集合对象,一般用于生成配置文件和读取配置)
- 是一个可持久化的映射,键和值的类型默认是String,并且只能是String。
- Properties
.setProperty(String key,String value):给属列表添加键值对
.getProperty(String key)用指定的键在此属性列表中搜索属性
.load(Reader reader)将文本文件中的数据加载到属性集合中
例如:创建读取配置文件的对象
Properties prop = new Properties();
1:InputStream ips = 当前类名.class.getResourceAsStream("/jdbc.properties");
//通过类加载器,获取文件输入流,这种获取输入流方法输入流在寻找文件的时会自动在src/main/resources包下寻找文件
2:InputStream ips = 当前类名.class.getClassLoader().getResourceAsStream("jdbc.properties");
prop.load(ips); //加载输入流
String driver = prop.getProperty("driver");
String url = prop.getProperty("url");
String username = prop.getProperty("username");
String password = prop.getProperty("password");
java.lang.Thread :线程
进程(Process)与线程关系:就是正在运行的程序。也就是代表了程序所占用的内存区域。操作系统包含多个进程,当一个进程运行时,内部可能包含了多个顺序执行流,每个顺序执行流就是一个线程;
- 进程特点:
- 独立性:进程是系统中独立存在的实体,它可以拥有自己的独立的资源,每一个进程都拥有自己私有的地址空间。在没有经过进程本身允许的情况下,一个用户进程不可以直接访问其他进程的地址空间。
- 动态性:进程与程序的区别在于,程序只是一个静态的指令集合,而进程是一个正在系统中活动的指令集合。在进程中加入了时间的概念,进程具有自己的生命周期和各种不同的状态,这些概念在程序中都是不具备的。
- 并发:多个进程可以在单个处理器上并发执行,多个进程之间不会互相影响。
- 并行:假设计算机有多个CPU,每个CPU处理一个进程,发生的现象叫并行.
-
进程有自己的私有内存,这块内存会在主存中有一段映射,而所有的线程共享JVM中的内存。在现代的操作系统中,线程的调度通常都是集成在操作系统中的,操作系统能通过分析更多的信息来决定如何更高效地进行线程的调度,这也是为什么Java中会一直强调,线程的执行顺序是不会得到保证的,因为JVM自己管不了这个,所以只能认为它是完全无序的。
另外,类java.lang.Thread中的很多属性也会直接映射为操作系统中线程的一些属性。Java的Thread中提供的一些方法如sleep和yield其实依赖于操作系统中线程的调度算法。 -
时间片
即CPU分配给各个程序的时间,每个进程被分配一个时间段,称作它的时间片。即该进程允许运行的时间,使各个程序从表面上看是同时进行的。
如果在时间片结束时进程还在运行,则CPU将被剥夺并分配给另一个进程,将当前进程挂起。如果进程在时间片结束前阻塞或结束,则CPU当即进行切换,而不会造成CPU资源浪费。当又切换到之前执行的进程,把现场恢复,继续执行。
在宏观上:我们可以同时打开多个应用程序,每个程序并行,同时运行。
在微观上:由于只有一个CPU,一次只能处理程序要求的一部分,如何处理公平,一种方法就是引入时间片,每个程序轮流执行。多核提高了并发能力。

-
线程:
线程是操作系统能够进行运算调度的最小单位。
它被包含在进程之中,是进程中的实际运作单位。
一个进程可以开启多个线程。
多线程扩展了多进程的概念,使得同一个进程可以同时并发处理多个任务。
简而言之,一个操作系统中可以有多个进程,一个进程中可以有多个线程。每个进程有自己独立的内存,每个线程共享一个进程中的内存,每个线程又有自己独立的内存
多线程:多线程主要解决的问题是改变了代码的执行方式,将原有的多段代码之间“串行”操作(一句一句的先后执行)改为“并行”操作(多个代码片段可以一起执行)【扩展:JVM也是多线程,最少要启动main线程和GC线程。】;
-
同步一定是线程安全的,但线程安全不一定是同步的。线程不安全一定是异步的。
-
每个线程都拥有其他线程所需要的锁,同时又等待其他线程锁拥有的锁,并且每个线程在获得所需锁之前不会释放自己的锁,当多个线程完成功能需要同时获取多个共享资源的时候可能会导致死锁。
Thread线程:main方法也是靠一个线程运行的,通常我们称运行main方法的线程为主线程; -
并发编程三要素:
- 原子性:指的是一个或者多个操作,要么全部执行并且在执行的过程中不被其他操作打断,要么就全部都不执行。原子性是数据一致性的保障。
- 可见性:指多个线程操作一个共享变量时,其中一个线程对变量进行修改后,其他线程可以立即看到修改的结果。
- 有序性:程序的执行顺序按照代码的先后顺序来执行。单线程简单的事,多线程并发就不容易保障了。
- 线程生命周期,总共有五种状态:
- 新建状态(New):当线程对象对创建后,即进入了新建状态,如:Thread t = new MyThread();
- 就绪状态(Runnable):当调用线程对象的start()方法(t.start();),线程即进入就绪状态。处于就绪状态的线程,只是说明此线程已经做好了准备,随时等待CPU调度执行,并不是说执行了t.start()此线程立即就会执行;
- 运行状态(Running):当CPU开始调度处于就绪状态的线程时,此时线程才得以真正执行,即进入到运行状态。注:就绪状态是进入到运行状态的唯一入口,也就是说,线程要想进入运行状态执行,首先必须处于就绪状态中;
- 阻塞状态(Blocked):处于运行状态中的线程由于某种原因,暂时放弃对CPU的使用权,停止执行,此时进入阻塞状态,直到其进入到就绪状态,才有机会再次被CPU调用以进入到运行状态;
- 根据阻塞产生的原因不同,阻塞状态又可以分为三种:
5.1 等待阻塞:运行状态中的线程执行wait()方法,使本线程进入到等待阻塞状态;
5.2 同步阻塞:线程在获取synchronized同步锁失败(因为锁被其它线程所占用),它会进入同步阻塞状态;
5.3 其他阻塞:通过调用线程的sleep()或join()或发出了I/O请求时,线程会进入到阻塞状态。当sleep()状态超时、join()等待线程终止或者超时、或者I/O处理完毕时,线程重新转入就绪状态。 - 死亡状态(Dead):线程执行完了或者因异常退出了run()方法,该线程结束生命周期。
启动线程不要自己调用run()方法,那样就成普通方法了(不会并行),只能等待OS操作系统自己去调用;
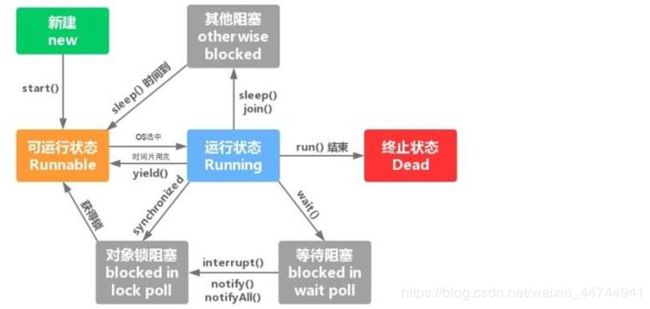
如果start()一个线程后想其立即执行,技巧:Thread.sleep(1)
一个多处理器的机器上,将会有多个线程并行(Parallel)执行,当线程数大于处理器数时,才会出现多个线程并发(Concurrent),在一个CPU上轮换执行
并行和并发的差异,一个是同时执行,一个是交替执行
线程在运行中,一般会被中断,目的是给其他线程执行机会,雨露均沾
线程调用sleep()方法主动放弃所占用的CPU资源
调用yield()方法可以让运行状态的线程转入就绪状态
join()方法是一个线程等待另外一个线程(在b中调a.join,让b等a运行完)

wait:释放资源,释放锁,是Object方法,可指定等待时间也可不指定,需要被唤醒,释放执行权,释放锁。是个普通的成员方法。
sleep:释放资源,不释放锁,是Thread方法,需要指定睡眠时间,到点自动醒,释放执行权,不释放锁。静态方法,通过类名直接调用。
notify:唤醒持有同一个监视器(锁)中调用wait的第一个线程。(被唤醒的线程是进入了可运行状态,cpu分配时间片)
notifyAll:唤醒持有同一监视器中调用wait的所有线程。

- 第一种创建线程的方式:继承Thread并重写run方法。
run方法是用来定义这个线程要执行的任务的,这种创建线程的方式结构简单,适合使用匿名内部类形式临时创建一个线程使用。但是这种创建线程的方式也存在这个一些不足:
- 由于Java是单继承的,这会导致我们继承线程就无法再 继承其他类来复用方法。这再实际开发中是很不方便的。
- 我们在继承线程后重写了run方法来定义线程要执行的任务代码,这会导致线程与任务存在一个必然的耦合关系,导致线程复用性差。
Thread类本质上是实现了Runnable接口的一个实例,代表一个线程的实例。启动线程的唯一方法就是通过Thread类的start()实例方法。Start()方法是一个native方法,它将通知底层操作系统,最终由操作系统启动一个新线程,操作系统将执行run()方法。这种方式实现多线程很简单,通过自己的类直接extend Thread,并复写run()方法,就可以启动新线程并执行自己定义的run()方法。
Thread t1 =new Thread(){public void run(){要执行的方法 };
t1.start;
第二种创建线程的方式:实现Runnable接口单独定义线程任务;
class MyRunnable1 implements Runnable{
public void run(){
for(int i=0;i<1000;i++) {
System.out.println("hello姐~");}
public static void main(String[] args) {
Runnable mr1 = new MyRunnable1();
Thread th1 = new Thread(mr1,"可加可不加:线程名");
th1.start();
第三种创建线程的方式(争议):实现call方法,可抛出异常,有返回值和future对象
Future future = 线城池.submit(Callable任务/Runnable任务);
返回值 = future.get(); Runnable任务没有返回值
class MyCallable implements Callable<Double>{
public Double call() throws Exception {//Callable重写call()
System.out.println("执行耗时计算....");
Thread.sleep(3000);
double d = Math.random();
return d;}}}
public class Test_Callable {
public static void main(String[] args) throws Exception {
ExecutorService threadPool = Executors.newFixedThreadPool(5);
MyCallable c = new MyCallable();
//把任务丢进线程池,并得到Future对象
Future<Double> future = threadPool.submit(c);
Double d = future.get();
System.out.println("主线程已经获取任务的结果:"+d);

线程常用方法:
线程主动放弃cpu时间片,让给其他线程: Thread.yield();
获取线程优先级 int priority = main.getPriority();
//线程的优先级分为10个等级,用整数1-10标识 * 其中1为最低优先级,10为最高优先级,5为默认值
设置线程优先级main.setPriority(Thread.MIN_PRIORITY(线程中的常量最小值1 Thread.MAX_PRIORITY最大10);
判断线程是否处于活动状态 boolean isAlive = main.isAlive();
判断线程是否是守护线程 boolean isDaemon = main.isDaemon()
判断线程是否被中断了 boolean isInterrupted = main.isInterrupted();
Thread()
分配新的 Thread 对象。
Thread(Runnable target)
分配新的 Thread 对象。
Thread(Runnable target, String name)
分配新的 Thread 对象。
Thread(String name)
分配新的 Thread 对象。
static Thread currentThread()
返回对当前正在执行的线程对象的引用。
long getId()
返回该线程的标识符。
String getName()
返回该线程的名称。
int getPriority()
返回线程的优先级。
StackTraceElement[] getStackTrace()
返回一个表示该线程堆栈转储的堆栈跟踪元素数组。
Thread.State getState()
返回该线程的状态。
void run()
如果该线程是使用独立的 Runnable 运行对象构造的,则调用该 Runnable 对象的 run 方法;否则,该方法不执行任何操作并返回。
static void sleep(long millis)
在指定的毫秒数内让当前正在执行的线程休眠(暂停执行),此操作受到系统计时器和调度程序精度和准确性的影响。
static void sleep(long millis, int nanos)
在指定的毫秒数加指定的纳秒数内让当前正在执行的线程休眠(暂停执行),此操作受到系统计时器和调度程序精度和准确性的影响。
void start()
使该线程开始执行;Java 虚拟机调用该线程的 run 方法。
- Cpu分时调度:时间片即CPU分配给各个程序的时间,每个进程被分配一个时间段,称作它的时间片,即该进程允许运行的时间,使各个程序从表面上看是同时进行的。如果在时间片结束时进程还在运行,则CPU将被剥夺并分配给另一个进程,将当前进程挂起。如果进程在时间片结束前阻塞或结束,则CPU当即进行切换,而不会造成CPU资源浪费。当又切换到之前执行的进程,把现场恢复,继续执行。
注意:进程在切换时有挂起和现场恢复,这些操作都是额外的,单进程就没有这个问题。进程如此线程亦如此,所以有时我们会发现开启多个线程,感觉会很快,可实际发现多线程有时不一定快,反而还慢,就是这个原因造成的。
在宏观上:我们可以同时打开多个应用程序,每个程序并行,同时运行。但在微观上:由于只有一个CPU,一次只能处理程序要求的一部分,如何处理公平,一种方法就是引入时间片,每个程序轮流执行。多核提高了并发能力,但本质不变。
- 当一个线程调用sleep方法进入阻塞状态时,若此时这个线程的中断方法interrupt被调用,那么这时该线程的阻塞状态就会被打断,与此同时sleep方法就会抛出异常(InterruptedExcepltion);
- void setDaemon(boolean tf)当参数为true时,该线程被设置为守护线程。设置守护线程的工作必须在线程启动前进行,守护线程在使用上与普通线程一致,但是在结束时机上有一点不同,即:当普通线程都结束时,所有正在运行的守护线程会被强制中断。
- void join()该方法会让调用这个方法的线程处于阻塞状态,直到该方法所属线程结束,才会取消阻塞线程的阻塞状态。(join方法常被用来协调线程之间同步运行使用,谁调用阻塞谁)
- 并发真实存在吗?:
我们一边听歌,一边看文档,除此之外,电脑还运行着其他很多程序,杀毒软件、QQ、微信、eclipse等等,这些进程看上去是同时工作。
但事实真相是,对于一个CPU而言,它在某个时间点只能执行一个程序,也就是说,只能运行一个进程,CPU不断地在这些进程之间轮换执行。那为什么我们感觉不到呢?这是因为CPU的执行速度惊人(如果启动的程序过多,我们还是能感受到速度变慢),所以虽然CPU在多个进程中切换执行,但我们感觉是多个程序同时在执行。
-
多线程并发安全问题:
当多个线程并发操作同一临界资源时,由于线程切换时机 不确定,导致操作代码执行顺序未按照设计顺序执行,从而出现操作混乱,严重时可能导致系统瘫痪;(解决:将并发操作同一临界资源改成同步操作:有先后秩序的排队干;用synchroinzed实现) -
同步:一个方法使用关键字synchroinzed修饰后,这个方法遍为“同步方法”,同步方法不允许多个线程同时到方法内部执行代码。 将多个线程并发操作同一资源改为先后顺序的同步执行就可以解决多线程并发的安全问题了。但是使用synchronized效率低,为了保证线程安全,必须牺牲性能,降低效率,尽量锁定越少的代码越好,须知抢哪个对象的锁? 哪段代码是在修改/访问数据?
在方法上直接使用synchronized,那么同步监视器对象就是当前方法所属对象,即方法中看到的this;
public synchronized void method() 抢当前实例(this)的锁
public static synchronized void method() 抢“类对象”的锁
同步块: synchronized(自定义同步监视器对象){
需要同步运行的代码片段、 }
- 同步块可以更准确的控制需要多个线程同步运行的代码片段。有效的缩小同步范围可以在保证并发安全的前提下尽可能的提高并发效率。
- 同步块在指定同步监视器对象(上锁的对象)时注意:这个对象可以是java任务类型的实例, 但是要保证需要同步运行该代码片段的线程看到的是同一个对象才可以!~
- 互斥锁:当使用synchronized控制不同代码段,并且他们指定的同步监视器对象是同一个时,这些代码片段就互为互斥的,多个线程不能同时在这些代码片段间一起执行。
- 死锁:两个线程同时标记了两个对象,并同时希望对方释放对象的标记,再去标记对方的对象,才能进入下一行代码。(南北方人吃饭喝汤拿勺子拿筷子)
- 静态方法若使用synchronized修饰,那么该方法一定具有同步效果 (因为静态方法所属于类,只有同一份,不论谁调用都是那个方法!)
- . 静态方法的同步监视器对象为这个类的类对象(科普:java中每个类都有且只有一个类对象(Class实例)与之对应,获取一个类的类对象比较简单的做法是调用这个类的静态属性lass得到。
例如:* String 类调用它的静态属性 String.class;
Class cls = String.class || Class cls = String.forName("String");
悲观锁和乐观锁:
- Synchronized 互斥锁(悲观锁,有罪假设)
悲观锁:Cpu时间片段内没有得到锁,直接让出CPU时间片段,该段代码效率低
采用synchronized修饰符实现的同步机制叫做互斥锁机制,它所获得的锁叫做互斥锁。每个对象都有一个monitor(锁标记),当线程拥有这个锁标记时才能访问这个资源,没有锁标记便进入锁池。任何一个对象系统都会为其创建一个互斥锁,这个锁是为了分配给线程的,防止打断原子操作。每个对象的锁只能分配给一个线程,因此叫做互斥锁。 - ReentrantReadWriteLock 读写锁(乐观锁,无罪假设)
乐观锁:在CPU分配到时间片段时,如果没有获得锁对象,会一直尝试抢锁,不会让出CPU时间片段(自旋),该代码执行效率比悲观锁高;
ReentrantLock是排他锁,排他锁在同一时刻仅有一个线程可以进行访问,实际上独占锁是一种相对比较保守的锁策略,在这种情况下任何“读/读”、“读/写”、“写/写”操作都不能同时发生,这在一定程度上降低了吞吐量。然而读操作之间不存在数据竞争问题,如果”读/读”操作能够以共享锁的方式进行,那会进一步提升性能。因此引入了ReentrantReadWriteLock,顾名思义,ReentrantReadWriteLock是Reentrant(可重入)Read(读)Write(写)Lock(锁),我们下面称它为读写锁。
读写锁内部又分为读锁和写锁,读锁可以在没有写锁的时候被多个线程同时持有,写锁是独占的。读锁和写锁分离从而提升程序性能,读写锁主要应用于读多写少的场景。
ReentrantReadWriteLock lock = new ReentrantReadWriteLock();
lock.writeLock().lock();//读上锁
lock.writeLock().unlock();//读解锁
lock.readLock().lock();//写上锁
lock.readLock().unlock();//写解锁
package javapro.thread;
悲观锁
public class TicketThread extends Thread{
//总票数,多个线程共享这个变量,能修改 ticket–
private int ticket = 10;
//执行业务,重写父类run方法
@Override
public void run() {
//业务处理,卖票:票–
while(true) { //线程非常多,我想尽量给我资源
synchronized (this) { //对象锁
//判断一个条件,出去条件
if(ticket<=0) { //多线程可能ticket=-1
break; //退出死循环
}
//不出现,线程run方法执行太快,不会发生线程冲突
try { //不能抛出异常,抛出就不是重写run方法
Thread.sleep(100);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(“窗口:” + Thread.currentThread().getName()
+”, 剩余票数:” + ticket-- );
}
}
}
//3个窗口都买这一个票
public static void main(String[] args) {
//目标
Thread target = new TicketThread();
for(int i=0; i<3; i++) {
new Thread(target).start(); //3个线程共同作用一个target
}
}
}
- 两种锁区别:
需要注意的是,用sychronized修饰的方法或者语句块在代码执行完之后锁会自动释放,而是用Lock需要我们手动释放锁,所以为了保证锁最终被释放(发生异常情况),要把互斥区放在try内,释放锁放在finally内!
与互斥锁相比,读写锁允许对共享数据进行更高级别的并发访问。虽然一次只有一个线程(writer 线程)可以修改共享数据,但在许多情况下,任何数量的线程可以同时读取共享数据(reader 线程)从理论上讲,与互斥锁定相比,使用读-写锁允许的并发性增强将带来更大的性能提高。
package javapro.thread;
import java.util.concurrent.locks.ReentrantReadWriteLock;
乐观锁
public class TicketLock implements Runnable {
private int ticket = 10;
//jdk1.6前,性能差异很大,1.6后synchronized底层实现类似Lock,性能伯仲之间
private ReentrantReadWriteLock lock = new ReentrantReadWriteLock(true);
@Override
public void run() {
while (true) {
try {
lock.writeLock().lock();
if (ticket <= 0) {
break;
}
try {
Thread.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(“线程:” + Thread.currentThread().getName() + “,还剩票数:” + ticket--);
} catch (Exception e) {
// TODO: handle exception
} finally {
lock.writeLock().unlock(); //防止死锁,会自动释放,而synchronized不会释放
}
}
}
public static void main(String[] args) {
Runnable target = new TicketLock ();
int windows = 3; // 窗口数量
for (int I = 1; I < windows + 1; i++) {
new Thread(target, “窗口” + i).start();
}
}
}
线程的辅助工具类:Executors/threadLocal/Callable/Future
- ThreadLocal类可在线程运行时,不同方法间绑定/获取对象,还可以删除对象(在调用不同的方法时传递对象),可指定泛型;
- ThreadLocalMap本质就是一个Map结构。其内部保存Entry对象,Entry的key是弱引用(用完就释放),value是强引用(GC回收,如果有引用回收不了)。ThreadLocal被保存在各自的线程Thread中,线程底层由操作系统保证其隔离。相当于共享变量再每个线程中复制了一份。这样共享变量就不会有访问冲突了。其本质是线程私有了。当然不会造成冲突,从而间接的解决了线程安全问题。
- 使用ThreadLocal最大一个缺点就是其会发生内存泄漏,那什么原因造成它会发生内存泄漏呢?由于ThreadLocalMap的key是弱引用,而Value是强引用。既然Key是弱引用,那么我们要做的事,就是在调用ThreadLocal的get()、set()方法完成后再调用remove方法,将Entry节点和Map的引用关系移除,这样整个Entry对象在GC Roots分析后就变成不可达了,下次GC的时候就可以被回收
- 线程锁同步机制采用了“以时间换空间”的方式,而ThreadLocal采用了“以空间换时间”的方式。前者仅提供一份变量,让不同的线程排队访问,而后者为每一个线程都提供了一份变量,因此可以同时访问而互不影响。
set():绑定值;
get(): 获取值
remove(): 删除绑定的值
线程B怎么知道线程A修改了变量
volatile修饰变量,提供多线程共享变量可见性和禁止指令重排序优化
synchronized修饰,它是悲观锁,属于抢占式,会引起其他线程阻塞
wait 释放对象锁,notify 通知
while轮询
Synchronized关键字
Lock锁实现
分布式锁:Redis、ZooKeeper
ExecutorService(Interface )
线程池(ThreadPool):底层是利用object的wait()和notifyAll()实现管理线程;(享元模式)
线程池是用来管理线程的,它主要有两个作用: 1>控制线程数量 2>重用线程
当线程执行完毕任务而没有任务分配时,线程会等待分配任务,而不会被销毁。除非调用线程池的shutdown方法;
//线程池的创建方法
ExecutorService threadPool = Executors.newFixedThreadPool(2);
创建固定参数条数的线程池,超过条数多余的线程任务会放在一个队列,等空余处理;
ExecutorService threadPool1 = Executors.newCachedThreadPool();
创建弹性的线城池;
ExecutorService threadPool2 = Executors.newSingleThreadExecutor();
创建单条线程的线程池;
threadPool.shutdown();
线程池的关闭:当调用此方法关闭线程池,线程池里的线程不再接受新任务,执行任务完毕关闭;
threadPool.shutdownNow():当调用此方法关闭线程池,将立刻强制调用方法关闭所有线程;
threadPool.execute(Runnable任务对象);
线城池添加任务:自动创建线程并执行线程的run方法;
threadPool.submit(Callable任务对象);
Callable:可以代替Runnable,它的call()可以有返回值(用submit丢进线程池时可返回一个future对象,future.get(取得返回值)),可指定泛型,可以在call()上抛出异常;
Future future = 线城池.submit(Callable任务/Runnable任务);
返回值 = future.get(); Runnable任务没有返回值
class MyCallable implements Callable<Double>{
public Double call() throws Exception {//Callable重写call()
System.out.println("执行耗时计算....");
Thread.sleep(3000);
double d = Math.random();
return d;}}}
public class Test_Callable {
public static void main(String[] args) throws Exception {
ExecutorService threadPool = Executors.newFixedThreadPool(5);
MyCallable c = new MyCallable();
//把任务丢进线程池,并得到Future对象
Future<Double> future = threadPool.submit(c);
Double d = future.get();
System.out.println("主线程已经获取任务的结果:"+d);
线城池运行,可返回一个Future对象,Future有一个get方法可以拿到run()的返回值,并且在执行到future.get()时,会等待run()运行完毕,在没有返回值的时候等同于(Runnable任务对象.join())
- Volatile:(易变,不稳定)修饰变量
- 保证数据的可见性(volatile 涉及一些底层cpu指令,可以让一个cpu监视其他cpu的缓存数据变化,当发现其他cpu修改了数据,会把该高速缓存数据标记成废弃,会重新从内存复制新数据);
- 还可以禁止指令的重排优化(cpu自以为是的代码优化而顺序更改执行)
- 不能保证原子性:有多线程安全问题;(加synchronized自己实现)
线程锁和ThreadLocal的区别:
- 线程锁实现了线程的同步,线程排队按顺序执行。线程阻塞,前面没有执行完成,后面就只能等待,前面的执行完成,后面才能进行执行。概括来说,对于多线程资源共享的问题,线程锁同步机制采用了“以时间换空间”的方式,而ThreadLocal采用了“以空间换时间”的方式。前者仅提供一份变量,让不同的线程排队访问,而后者为每一个线程都提供了一份变量,因此可以同时访问而互不影响。
- ThreadLocal是解决线程安全问题一个很好的思路,它通过为每个线程提供一个独立的变量副本解决了变量并发访问的冲突问题。在很多情况下,ThreadLocal比直接使用synchronized同步机制解决线程安全问题更简单,更方便,且结果程序拥有更高的并发性。
- 自定义线程池
package com.cy.pj.java.thread.pool;
import java.util.concurrent.ArrayBlockingQueue;
import java.util.concurrent.BlockingQueue;
import java.util.concurrent.ThreadFactory;
import java.util.concurrent.ThreadPoolExecutor;
import java.util.concurrent.ThreadPoolExecutor.CallerRunsPolicy;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.atomic.AtomicLong;
//任务执行时间=CPU计算时间+IO操作时间
//CPU密集型操作时,线程池的核心线程数一般会设计为CPU核数+1
//IO密集型操作时,线程池中的核心线程数一般会设计为CPU核数*(1+IO操作时间/CPU计算时间)
public class TestThreadPool01 {
//阻塞式工作队列
private static BlockingQueue<Runnable> workQueue=
new ArrayBlockingQueue<>(1);
//线程工厂对象
private static ThreadFactory factory=new ThreadFactory() {
private AtomicLong at=new AtomicLong(1);//CAS算法
@Override
public Thread newThread(Runnable r) {
return new Thread(r, "DB-thread-pool-"+at.getAndIncrement());
}
};
public static void main(String[] args)throws Exception {
int processors=
Runtime.getRuntime().availableProcessors();//获取cpu
//构建池对象
ThreadPoolExecutor tPool=
new ThreadPoolExecutor(
1, //corePoolSize 核心线程数
2,//maximumPoolSize 最大线程数
30, //keepAliveTime线程允许的空闲时间
TimeUnit.SECONDS,//unit 时间单位
workQueue,//工作队列(阻塞式队列),用于存储线程要执行的任务对象
factory,//线程工厂
new CallerRunsPolicy());//拒绝策略
//提交任务
tPool.execute(new Runnable() {
@Override
public void run() {
String tName=Thread.currentThread().getName();
System.out.println(tName+"==>task-01");
try{Thread.sleep(5000);}
catch(Exception e) {}
}
});
tPool.execute(new Runnable() {
@Override
public void run() {
String tName=Thread.currentThread().getName();
System.out.println(tName+"==>task-02");
try{Thread.sleep(5000);}
catch(Exception e) {}
}
});
tPool.execute(new Runnable() {
@Override
public void run() {
String tName=Thread.currentThread().getName();
System.out.println(tName+"==>task-03");
try{Thread.sleep(5000);}
catch(Exception e) {}
}
});
tPool.execute(new Runnable() {
@Override
public void run() {
String tName=Thread.currentThread().getName();
System.out.println(tName+"==>task-04");
try{Thread.sleep(5000);}
catch(Exception e) {}
}
});
}
}
java.net.Socket
套接字是基于网络进行传输的API
插头:一个ip端口插入另一个ip端口进行通信,封装了TCP协议的通讯细节,使得我们可以通过它来与远程计算机建立TCP连接,并利用两个流的读写完成数据交互。
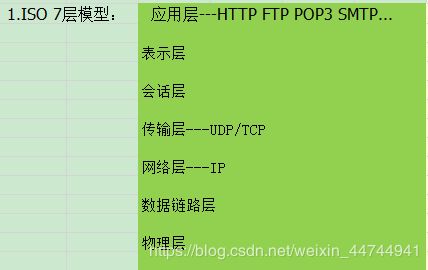

互联网层协议
IP(internet protocol)协议:提供关于数据应如何传输以及传输到何处的信息
ARP(Address Resolution Protocol)协议:处理信息的路由以及主机地址解析
传输层协议
TCP(Transmission Control Protocol)协议:传输控制协议,该协议主要用于在主机间建立一个虚拟连接,以实现高可靠性的数据包交换,如文件下载
TCP的三次握手与四次挥手
所谓三次握手即建立TCP连接,就是指建立一个TCP连接时,需要客户端和服务端总共发送3个包以确认连接的建立。在socket编程中,这一过程由客户端执行connect来触发。
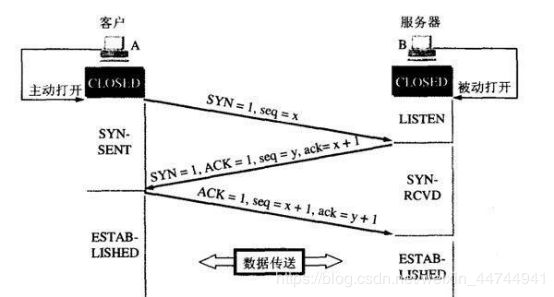
所谓四次挥手即终止TCP连接,就是指断开一个TCP连接时,需要客户端和服务端总共发送4个包以确认连接的断开。

UDP(User Datapram Protocol)协议:用户数据报协议,一种无连接的传输层协议,提供面向事务的简单不可靠信息传送服务,如早期的QQ聊天
应用层协议
HTTP(Hyper Text Transport Protocol):超文本传输协议,如网页
FTP(File Transfer Protocol):文件传输协议
TELNET:远程登录协议,用于远程联接服务的标准协议或者实现此协议的软件,利用远程计算机完成当前计算机不能完成的功能
- 端口号
逻辑意义上的数据传输通道,用整数形式表示,TCP/IP规定每台计算机拥有65535个逻辑通道。每个端口号为计算机某个特定应用程序服务。常用的有:www网页服务端口为80(默认不用写就按80访问),FTP服务端口为21,MYSQL数据库服务端口为3306,TOMCAT端口8080等。
注意:1024以内的端口号已绑定了相应的系统级的服务程序,用户编程中若用到端口号应选择1024以上的端口。 - DNS
域名系统(英文:Domain Name System,缩写:DNS)是互联网的一项服务。它作为将域名和IP地址相互映射的一个分布式数据库,能够使人更方便地访问互联网。对于每一级域名长度的限制是63个字符,域名总长度则不能超过253个字符。
通过操作系统的ping命令就可以知道域名对应的ip是多少。注意小网站一般只有一个域名对应一个ip。但大网站如百度,对应很多,减少服务器的压力。所以你ping的ip和我的可能不一样哦。 - 广播风暴
局域网是共用一条线路传输数据,这样网络上任何一台计算机发出信息都会被其他计算机接收到,也就是广播式信息发送。其缺点显而易见,闭着眼睛也能想到。随着连入网络的计算机越多,你也发,我也发,收到的信息就越多,会造成信息发送卡顿,甚至发不出去。
就像我们的教室,如果人很多,大家都在高声喧哗,哈哈大笑,相当于广播,随着教室中人的增多,大家基本上就谁也听不清楚每人在说什么了,有用的信息也就发送不出去了,这种情况就称为广播风暴。 - 网段
为了解决广播风暴,就出现了路由,把网络划分成很多小的网络,路由器把他们链接起来,路由器链接每个小网络(网段)的同时还起到了阻止网络广播的功能,因此每个网段的广播都不会扩散到其他网段去,相当于把一个大教室的人分隔到几个小教室去。 - 网关
有了网段,解决了广播风暴问题,形成网络的隔离。但同时也带来一个新的问题,如果两个不同网段的网络要通讯呢?
例如:有网络A和网络B,
网络A的IP地址范围:192.168.1.1~192.168.1.254子网掩码255.255.255.0;
网络B的IP地址范围:192.168.2.1~192.168.2.254子网掩码255.255.255.0;
按上面的规定,我们知道,这两个网络之间是不能进行通讯的,跨网段了,一个是xxx.xxx.1.xxx,一个是xxx.xxx.2.xxx。那如果我们想实现这两个网络之间的通信,怎么办呢?这就诞生了网关GateWay,就用来实现跨网段通信。
实现过程:如果网络A中的主机发现数据包的目的主机不在本地网络中,就会把数据包发给它自己的网关,再由网关转发给网络B的网关,网络B的网关再转发给网络B的某个主机。 - 子网掩码
子网掩码作用就一个,将某个IP地址划分成网络地址和主机地址两个部分。子网掩码的设定必须遵循一定的规则。习惯配置的子网掩码“255.255.255.0”。其它固定,最后一个数字取值在0255,0被系统占用,255作为广播地址,我们只能使用1254,所以只有256-2=254个主机。
也支持“255.255.0.0”,它可以支持254*254个主机,但要注意的是,这个值越大越好,还是稍小的就可以?日常小写好,计算机通信进行寻址,就是找到某台计算机,这个地址太大,寻址时间拉长,会影响通信效率。所以“255.255.255.0”实际中最常用。 - IP地址划分
在Internet上,每台计算机或网络设备的IP地址是全世界唯一的。IPV4(最新已经有IPV6,目前还不够成熟,大多还在使用IPV4)由32位组成,分成四段,每个段是一个字节,即4个字节,每个字节有8位,最大值是255(2^8=256)。格式是 xxx.xxx.xxx.xxx,其中xxx是 0 到 255 之间的任意整数。
IP地址=网络号+主机号

可用看到IP分为A,B,C,D,E类地址,0和255系统保留,可用1~254。
A类:1.0.0.0到126.255.255.255 分配给大型网络
B类:128.0.0.0到191.255.255.255 用于国际性大公司和政府机构
C类:192.0.0.0到223.255.255.255 用于一般小公司、校园网、研究机构等
D类:224.0.0.0到239.255.255.255 用于特殊用途. 又称做广播地址
E类:240.0.0.0到247.255.255.255 为暂时保留不可用
我们自己局域网配置的IP地址就属于C类地址:

IP地址是计算机在网络内的唯一标识,而子网掩码顾名思义是用于划分子网的。缺省子网掩码即未划分子网,对应的网络号的位都置1,主机号都置0。
如:c类IP地址:192.168.1.* 子网掩码:255.255.255.0

java.net.Socket (client客户端)
网络编程是指,多个计算机包含的程序,通过网络传输连接起来。
- UDP 基于流的,不建立连接,不可靠,传输速度比较快,限制数据的大小,会对数据进行封包,每个包不超过64K,适用于要求速度而不要求可靠性的场景(视频聊天)。
//创建一个UDP协议的套接字对象
DatagramSocket ds = new DatagramSocket(8070);
//准备一个数据包
DatagramPacket dp = new DatagramPacket(new byte[1024],1024);
//接收数据 阻塞
ds.receive(dp);
ds.close();//关流
byte[]bs = dp.getData();
dp.getAddress();//获取发送端的地址
- TCP基于流的,需要建立连接,经过三次握手,可靠的,传输速度相对较慢,不限制数据大小,适用于要求可靠性而对速度要求较低的场景。被称 TCP / IP。
基于TCP传输协议的类为Socket、URL、URLConnection和ServerSocket
基于UDP传输协议的类为DatagramPacket、DatagramSocket和MulticastSocket
Socket实例化是需要传入两个参数的:
- 参数1:服务端IP地址,我们通过IP可以找到网络上的服务端计算机,然后我们通过端口可以连接到服务端计算机上运行的服务端应用程序了。
回环ip:127.0.0.1 连接本机ip:Localhost
抽象端口(0-65535个):端口是独占的,0到1024是一些常见服务的默认端口(http:80 https:443 ftp:21....)
5万以后是系统保留端口,用来自动分配,我们选1024到5万之间的;
DNS服务器:解析域名,将域名与对应IP地址关联(首先在本地Hosts文件中查找)

- 参数2:服务端程序申请的端口:
注意: 实例化Socket的过程就是连接的过程,若服务端没有响应这里就会抛出异常。
//创建一个TCP连接的客户端对象
socket = new Socket("192.168.7.90",8088);
OutputStream out = socket.getOutputStream();
该方法获取的输出流是一个字节输出流,通过这个流写出的字节会通过网络发送到远端计算机上
对于客户端这边而言,远端计算机指的就是服务端了。

- 面试题
- TCP和UDP的区别
TCP面向连接(如打电话要先拨号建立连接);UDP是无连接的,即发送数据之前不需要建立连接
TCP提供可靠的服务,也就是说,通过TCP连接传送的数据,无差错,不丢失,不重复,且按序到达;UDP尽最大努力交付,即不保证可靠交付,会有丢包情况
TCP面向字节流,实际上是TCP把数据看成一连串无结构的字节流;UDP是面向报文的,有结构的一组数据
UDP没有拥塞控制,因此网络出现拥塞不会使源主机的发送速率降低(对实时应用很有用,如IP电话,实时视频会议等)
每一条TCP连接只能是点到点的;UDP支持一对一、一对多、多对一和多对多的交互通信
TCP首部开销20字节;UDP的首部开销小,只有8个字节
TCP的逻辑通信信道是全双工的可靠信道,UDP则是不可靠信道 - 一个 TCP 请求访问完就断开还是一直连接着?
在 HTTP/1.0 中,一个服务器在发送完一个 HTTP 响应后,会断开 TCP 链接。但是这样每次请求都会重新建立和断开 TCP 连接,代价过大。
持久连接:既然维持 TCP 连接好处这么多,HTTP/1.1 就把 Connection 头写进标准,并且默认开启持久连接,除非请求中写明 Connection: close,那么浏览器和服务器之间是会维持一段时间的 TCP 连接,不会一个请求结束就断掉。 - 浏览器对同一 Host 建立 TCP 连接到数量有没有限制?
假设我们还处在 HTTP/1.1 时代,那个时候没有多路传输,当浏览器拿到一个有几十张图片的网页该怎么办呢?肯定不能只开一个 TCP 连接顺序下载,那样用户肯定等的很难受,但是如果每个图片都开一个 TCP 连接发 HTTP 请求,那电脑或者服务器都可能受不了,要是有 1000 张图片的话总不能开 1000 个TCP 连接吧,你的电脑同意 NAT 也不一定会同意。
答案:有。Chrome 最多允许对同一个 Host 建立六个 TCP 连接。不同的浏览器有一些区别。
java.net.ServerSocketServer(Server服务端)
- ServerSocket 在服务器端,选择一个端口号,在指定端口上等待客户端发起连接
- 运行在服务端的ServerSocket主要有两个作用:
- 1:向系统申请服务端口,客户端就是通过这个端口与服务端建立连接的。
- 2:监听该端口,这样一旦一个客户端通过该端口尝试建立连接时,ServerSocket就会自动实例化一个Socket,那么通过这个Socket就可以与客户端对等并进行数据交互了。
ServerSocket server = new ServerSocket(8088);
Socket socket = server.accept();获得服务端的插头
accept() 就是一个阻塞方法,调用后会一直等待,直到一个客户端建立连接为止,
此时该方法会返回一个Socket实例,通过这个Socket就可以与刚连接上的
客户端进行数据交互了。多次调用accept可以等待不同客户端的连接。
InputStream in = socket.getInputStream();
通过Socket获取输入流,可以读取到远端计算机发送过来的字节。
String host =socket.getInetAddress().getHostAddress();
获取连接上的客户端地址
java.util.Map(查找表)接口
Map体现的结构是一个多行两列的表格。左列称为key,右列称为value。Map可以通过key获取对应的value,所以我们将要查询的数据作为value,查询的条件作为key将他们成对的保存到Map中。常用实现类:hashMap
java.util.HashMap(哈希表/散列表)
HashMap是使用散列算法实现的Map,当今查询速度最快的数据结构! key和value允许存放null;HashMap即是采用了数组+链表的数据结构
HashMap内部使用数组(Entry数组)存放数据(每组键值对都是一个Entry实例)默认初始容量16;当存放数据时调用key.hashCode()获取键的哈希值(int类型的整数),用哈希值和数组长度计算下标(假设为i),新建一个Entry实例来封装键值对数据,把Entry实例放入下标i位置,再放入同一个下标的时候会依次用equals()比较两个key是否一样(一样就覆盖原值),两个key不一样则会串在链表尾部(下标i处还是一个Entry实例);当负载率/加载因子(数据量/容量)到0.75时,会新建翻倍容量的新数组;所有的数据重新执行哈希运算放入新数组;在jdk1.8时,链表长度到8时会转成红黑树(当红黑树上的数据减少的6时会转回成链表)
Put(key,value) 放入键值对,放入重复的键,会覆盖原值;
Size() map中存放的键值对数
get(key) 用键,提取对应的值,键不存在,获得null值;
remove(key) 删除key对应键值对,返回key对应value
boolean = map.containsKey(key) 判断是否包含给定的key
boolean = map.containsValue(value); 判断是否包含给定的value
Set<String> keySet = map.keySet(); 将当前Map中所有的key以一个Set集合形式返回。
Collection<Integer> values = map.values(); 将当前Map中所有的value以一个集合形式返回。
Set<Entry<String,Integer>> entrySet = map.entrySet(); 将当前Map中每组键值对以若干Entry实例并存入Set集合进行返回;
for(java.util.Map.Entry<String,Integer> e:entrySet) {
String key = e.getKey();
Integer value = e.getValue();}
HashMap 非线程安全,全部方法不加锁,性能最好
Hashtable 线程安全,全部方法加锁,用同一把锁。慢,淘汰的API。
ConcurrentHashMap,线程安全,每个存储位置一把锁,性能好。
LinkeHashMap:可保证key的顺序的map
java.util.Colletction(集合框架)接口
- 集合与数组一样,都是用来保存一组数据的,但是集合提供了操作元素的相关方法使用起来更方便,并且集合有多种不同的数据结构实现;数组的缺点:长度固定,访问方式单一(下标),插入/删除数据操作繁琐
- 集合只能存引用类型元素(存的都是元素的地址)就算放了一个int值,也会自动装箱成包装类;因为集合存放的是地址,这就相当于原对象指向这个地址,集合里的该元素也指向该地址。所有当原对象改变属性之后,集合里的该元素也一并改变。
集合的常用方法有:添加元素:add 删除元素:remove 集合的元素个数:size 判断集合是否空集:isEmpty 清空集合元素:clear 判断是否包含元素:contains(o);
集合转换为数组:String[]arr = 原集合.toArray(new String[c.size()]);
数组转换为集合:Collection c = Arrays.asList(原数组);数组只可以转换成List集合,不可以转Set集合,对集合的操作就是原来数组的操作,因为数组的长度固定,所以不可以通过集合的方法增删元素,但是可以使用List集合的set方法更换元素内容;
集合和集合方法有:addAll©添加所有集合元素 removeAll(c)删除本集合共有的元素 contains©判断是否包含集合所有元素
所有的集合在new的时候都支持传入另外一个集合eg: List list2 = new ArrayList<>(list);
集合的排序(默认升序):Collections.sort(集合);Collections是Collection的工具类(类似于Array的Arrays类),存在着大量静态方法操作集合。
java中所有的集合都是该java.util.Colletction接口的实现类,它定义了所有集合都应当具备的功能(例如存取元素等等);
java.util.Collection接口下的子接口:Deque , List , NavigableSet , Queue , Set , SortedSet ;
java.util.List:可重复集合,并且有序 Colletction c = new ArrayList()
List除了可重复之外,还有一个特点是有序,因此List 集合提供了一套可通过下标操作元素的方法:
E get(int index): 返回下标元素
E set(int index,E e):元素设置到下标位置,返回原元素
void add(int index, E e):重载集合add,给定元素插入指定位置
E remove(int index):删除并返回指定下标处对应元素
List<Integer> subList = list.subList(3, 8):返回新集合:截取到的list集合下标位置包头不包尾的元素:注意此方法获取到的子集的增删改插元素依然会改变母集的元素(list.subList(2, 9).clear()删除list集合3-9下标位置元素)
List有两个常用的实现类:
- java.util.ArrayList:
使用数组实现,封装了数组的繁琐操作,初始长度0,第一次添加完数据,默认长度10,不够了1.5倍增长长度,访问任意位置效率高,添加或删除数据,效率可能降低。方法使用上与LinkedList相同,但没有首尾操作数据的方法;new时可指定长度; - java.util.LinkedList:
双向链表,增删效率好(尤其首尾),查询慢(尤其中间)它的常用方法有:(add、addFirst、last/get、getFirst、last/remove(下标、数据)、removeFirst、last/size/栈、队列的方法);
java.util.set:不可重复集合(LinkedHashSet有序,其余无序):
这里的重复指的是元素是否重复,而重复的判断依据是依靠元素自身equals比较的结果。set集合不允许存放equals比较为true的元素两次。重写equals就显得重要了Colletction c1 = new HashSet();
- java.util.hashSet:内部封装了一个HashMap,把数据当做map的key来存,value值直接弃掉,以达到不重复的目的;(add/size/remove/iterator)
- java.util.Queue (队列接口):
队列存取元素要求遵循先进先出,Queue接口继承自Collection,所以队列也是一个集合。
E poll()出队操作,获取队首元素的同时将该元素删除。
E peek()引用队首元素,不做出队操作。
- java.util.Deque双端队列:
Deque接口继承自Queue接口。双端队列是两端都可以做出入队操作的队列。常用实现类:java.util.LinkedList(Collection中定义的方法队列依然可用)
Deque<String> deque = new LinkedList<>();
deque.offer||deque.offerFirst(添加首/尾元素)
e = deque.pollFirst()||e = deque.pollLast(取出首/尾元素)
- java.util.Deque:
提供了栈结构(stack)的应用。(只从双端队列的同一侧出入就形成了栈结构)
栈结构:栈是经典的数据结构之一,可以保存一组元素,存取元素必须遵循先进后出原则,使用栈结构通常为了实现如"后退"这样的功能使用。
stack.push("one");//压入元素
String str = stack.pop();//弹出元素
java.util.Collections(集合工具类):
Collections.addAll(集合,值1,值2,值3....)批量添加值
Collections.binarySearch(list,目标值):二分法查找
Collections.swap(List,i,j)
Collections.sort(list)集合排序:默认首字符比大小,再比后续字符
该类提供了一个静态方法sort,可以对List集合进行自然排序。这种排序只能排实现了Comparable接口的类元素,否则编译不通过。当需要排序自定义的元素时,首先元素类实现Comparable接口,参照以下:
Collections.sort(list,new Comparator<Point>(){//比较器对象
* 该方法用来指定o1与o2的大小关系
* 返回值不关心具体取值,只关心取值范围
* 当返回值是正数:o1>o2
* 当返回值是负数:o1<o2
* 当返回值=0:o1与o2相等
public int compare(Point o1, Point o2) {
int len1 = o1.getX()*o1.getX()+o1.getY()*o1.getY();
int len2 = o2.getX()*o2.getX()+o2.getY()*o2.getY();
return len1-len2; }});
java.util.Iterator(迭代器接口)
用于遍历集合以及删除元素之类,该接口规定历所有迭代器实现类遍历集合的通用操作方法,而遍历结合遵循的步骤为:问,取,删,其中删除元素不是必要操作,不同的集合都提供了一个Iterator的实现类,我们无需,记住这些实现类的名字,以Iterator接口接受并调用方法遍历即可。
Iterator it = 集合.iterator;
while(it.hasNext){判断是否含有下一个元素,返回boolean值
Object o = it.next():获得的是Object类型,带泛型可直接获得
if("xxx".equals(o)){ 比对不想要的元素
it.remove;} }删除不想要的元素
二叉树
在计算机科学中,二叉树是每个结点最多有两个子树的树结构。通常子树被称作“左子树”和“右子树”。二叉树常被用于实现二叉查找树和二叉堆。
二叉树分类:
完全二叉树:若设二叉树的高度为h,除第 h 层外,其它各层 (1~h-1) 的结点数都达到最大个数,第h层有叶子结点,并且叶子结点都是从左到右依次排布,这就是完全二叉树。
满二叉树:除了叶子结点外每一个结点都有左右子叶且叶子结点都处在最底层的二叉树
平衡二叉树:它是一棵空树或它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二叉树。
二叉树的遍历:
前序遍历:
先访问根节点,然后访问左子树,最后访问右子树。对于左子树和右子树,也采用前序遍历。
中序遍历(重点):
先访问左子树,再访问根节点,最后访问右子树。对于左子树和右子树,也采用中序遍历。后序遍历:先访问左子树,再访问右子树,最后访问根节点。对于左子树和右子树,也采用后序遍历。
二叉树的失衡(不平衡二叉树)
对于某个节点,其左子树与右子树的高度差大于1.如果一树二叉树发生了失衡现象,会影响查找的效率(二叉树会退化成一个链表)。要将二叉树重新变成一个平衡的二叉树,需要对二叉树进行旋转,重新调整节点的位置。
红黑树
红黑树就是一种将不平衡的二叉树转换成弱平衡的二叉树的一种算法。
红黑树的规则:
a.节点可以是红色的或者是黑色的。
b.根节点必须是黑色的。
c.叶子节点必须是黑色的。
d.红色节点的子节点必须是黑色的。
e.从根节点到任何叶子节点的路径上,
包含的黑色节点的个数是一样的。
爬虫:(org.jsoup.Jsoup)
第三方开源API,执行http请求,并处理响应,方便从HTML中提取所需内容;
2 实战:爬虫京东
2.1 http协议
向服务器发送的 http 协议数据
GET / HTTP/1.1
Host: www.tedu.cn
Connection: keep-alive
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9
服务器返回的数据
HTTP/1.1 200 OK
Date: Tue, 24 Sep 2019 15:30:45 GMT
Content-Type: text/html
Content-Length: 275688
Connection: keep-alive
Server: tarena
Last-Modified: Tue, 24 Sep 2019 01:14:40 GMT
ETag: "5d896e00-434e8"
Accept-Ranges: bytes
Age: 7092
X-Via: 1.1 PShbsjzsxqo180:5 (Cdn Cache Server V2.0), 1.1 PSjlbswt4dm34:3 (Cdn Cache Server V2.0), 1.1 bdwt64:8 (Cdn Cache Server V2.0)
package day18;
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.io.OutputStream;
import java.net.Socket;
public class Test2 {
public static void main(String[] args) throws Exception {
String host = "www.tedu.cn";
Socket s = new Socket(host, 80);
System.out.println("已连接");
OutputStream out = s.getOutputStream();
String http = "GET / HTTP/1.1\n"+
"Host: "+host+"\n"+
"Connection: keep-alive\n"+
"User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/76.0.3809.100 Safari/537.36\n"+
"Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3\n"+
"Accept-Language: zh-CN,zh;q=0.9\n\n";
out.write(http.getBytes());
out.flush();
System.out.println("已发送");
BufferedReader in = new BufferedReader(new InputStreamReader(s.getInputStream(), "UTF-8"));
String line;
while((line = in.readLine()) != null) {
System.out.println(line);
}
}
}
2.3 爬虫
Jsoup 第三方开源API,方便的执行http请求,并处理响应,方便的从html中提取需要的内容
package day18;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import org.junit.Test;
import com.fasterxml.jackson.databind.JsonNode;
import com.fasterxml.jackson.databind.ObjectMapper;
public class Test3 {
@Test //抓整个页面
public void html() throws IOException{
String url = "http://tech.qq.com/a/20170330/003855.htm";
//doc代表一个页面
String html = Jsoup.connect(url).execute().body();
System.out.println(html);
}
@Test //抓整站,找到所有a链接,然后进行广度优先/深度优先进行遍历
public void getAllATag() throws IOException{
String url = "http://tech.qq.com/a/20170330/003855.htm";
//获取到页面
Document doc = Jsoup.connect(url).get();
//获取到页面中的所有a标签
Elements eles = doc.getElementsByTag("a");
for(Element ele : eles){
String title = ele.text(); //获取a标签的内容
String aurl = ele.attr("href"); //获取a标签的属性
System.out.println(title+" – "+aurl);
}
}
@Test //京东商城,商品标题
public void getItemTile() throws IOException{
String url = "https://item.jd.com/3882469.html";
String title = getTitle(url);
System.out.println(title);
}
private String getTitle(String url) throws IOException {
Document doc = Jsoup.connect(url).get();
Element ele = doc.select("div.sku-name").get(0);
String title = ele.text();
return title;
}
@Test //当当商城,商品标题
public void getDDItemTile() throws IOException{
String url = "http://product.dangdang.com/23579654.html";
Document doc = Jsoup.connect(url).get();
Element ele = doc.select("div.name_info h1").get(0);
String title = ele.text();
System.out.println(title);
}
@Test
public void price() throws IOException {
double price = getPrice("J_100003717483");
System.out.println(price);
}
public double getPrice(String id) throws IOException {
String url = "https://p.3.cn/prices/mgets?skuIds="+id;
String userAgent = "Mozilla/5.0 (Windows NT 5.1; zh-CN) AppleWebKit/535.12 (KHTML, like Gecko) Chrome/22.0.1229.79 Safari/535.12";
String json = Jsoup
.connect(url)
.userAgent(userAgent)
.ignoreContentType(true)
.execute()
.body();
//System.out.println(json);
ObjectMapper mapper =new ObjectMapper();
/*
* JsonNode可以是
* 对象: {"a":"1", "b":"2"}
* 数组: [{...}, {...}, {...}]
*
* isArray() 判断是否是一个数组
* get(i) 取数组中指定下标的节点
* get(name) 取对象中该属性的值
*/
JsonNode node = mapper.readTree(json);
double price = node.get(0).get("p").asDouble();
return price;
}
@Test //商品描述
public void getItemDesc() throws IOException{
ObjectMapper mapper =new ObjectMapper();
String url = "http://d.3.cn/desc/3882469";
String body = Jsoup.connect(url).ignoreContentType(true).execute().body();
System.out.println(body);
String json = body.substring(9, body.length()-1); //把函数名去掉
JsonNode jsonNode = mapper.readTree(json);
String desc = jsonNode.get("content").asText();
System.out.println(desc);
}
@Test
public void testCat3() throws IOException {
List<String> catList = getCat3();
for(String url : catList) {
System.out.println(url);
}
System.out.println("处理标准三级分类:"+catList.size());
}
//返回所有三级分类。京东三级分类:1286,标准有:1190
public static List<String> getCat3() throws IOException{
//所有分类都在里面
String url = "http://www.jd.com/allSort.aspx";
//通过选择器把三级分类过滤出来,集合
Elements els = Jsoup.connect(url).get()
.select("dl.clearfix dd a");
//存放爬取所有三级分类链接
List<String> catList = new ArrayList<String>();
for(Element e : els) {
//获取到三级分类a标签的链接值
String catUrl = e.attr("href");
//排除异常链接
if(catUrl.startsWith("//list.jd.com/list.html?cat=")) {
catList.add("http:"+catUrl);
}
}
return catList;
}
@Test
public void pageNum() throws IOException {
String catUrl = "http://list.jd.com/list.html?cat=1713,3274&jth=i";
int num = getPageNum(catUrl);
System.out.println(num);
}
//获取某个分类下总页数,参数就是分类链接
public static int getPageNum(String catUrl) throws IOException {
String p = Jsoup.connect(catUrl).get().select(".fp-text I").get(0).text();
int num = Integer.parseInt(p);
return num;
}
@Test //测试某个分类下的所有的分页链接
public void pageList() throws IOException {
String catUrl = "https://list.jd.com/list.html?cat=1713,3274";
Integer maxNum = getPageNum(catUrl);
List<String> itemList = getPageUrlList(catUrl, maxNum);
for(String item : itemList) {
System.out.println(item);
}
}
//https://list.jd.com/list.html?cat=1713,3274&page=1
//https://list.jd.com/list.html?cat=1713,3274&page=2
//拼接某个一个分类下的所有的分页链接
public static List<String> getPageUrlList(String catUrl, Integer maxNum){
List<String> pageUrlList = new ArrayList<String>();
//遍历所有页数
for(int i=1; i<=maxNum; i++) {
String pageUrl = catUrl + "&page=" + i;
pageUrlList.add(pageUrl);
}
return pageUrlList;
}
@Test //某个列表页面上所有商品链接地址
public void itemList() throws IOException {
String pageUrl = "http://list.jd.com/list.html?cat=1713,3274&page=2";
List<String> itemUrlList = getItemUrlList(pageUrl);
for(String itemUrl : itemUrlList) {
System.out.println(itemUrl);
}
}
//抓取某个列表页面中所有商品链接的地址,
public static List<String> getItemUrlList(String pageUrl) throws IOException{
Elements els = Jsoup.connect(pageUrl).get().select(".p-img a");
List<String> itemUrlList = new ArrayList<String>();
//所有a标签,过滤过的
for(Element e : els) {
//e是a标签,href属性值
String itemUrl = e.attr("href");
itemUrlList.add("http:"+itemUrl);
}
return itemUrlList;
}
@Test
public void site() throws IOException, InterruptedException {
//获取所有的三级分类
List<String> catUrlList = getCat3();
//遍历3级分类
for(String catUrl : catUrlList) {
//延时
Thread.sleep(10);
//返回当前分类的总页数
int maxNum = getPageNum(catUrl);
//某个分类下所有分页链接
List<String> pageUrlList = getPageUrlList(catUrl, maxNum);
//遍历当前分类下的所有分页链接
for(String pageUrl : pageUrlList) {
//当前分页商品链接
List<String> itemUrlList = getItemUrlList(pageUrl);
for(String itemUrl : itemUrlList) {
//获取其标题、价格。。。
String id = itemUrl.substring(itemUrl.lastIndexOf("/")+1, itemUrl.lastIndexOf("."));
double price = getPrice(id);
String title = getTitle(itemUrl);
System.out.println(itemUrl + " - "+ price + " - "+title);
System.out.println();
}
}
}
}
}
2.4 抓取的五种方式
2.4.1 抓取页面
@Test //抓整个页面
public void html() throws IOException{
String url = "http://tech.qq.com/a/20170330/003855.htm";
//doc代表一个页面
String html = Jsoup.connect(url).execute().body();
System.out.println(html);
}
2.4.2 抓取整个网站
@Test //抓整站,找到所有a链接,然后进行广度优先/深度优先进行遍历
public void getAllATag() throws IOException{
String url = "http://tech.qq.com/a/20170330/003855.htm";
//获取到页面
Document doc = Jsoup.connect(url).get();
//获取到页面中的所有a标签
Elements eles = doc.getElementsByTag("a");
for(Element ele : eles){
String title = ele.text(); //获取a标签的内容
String aurl = ele.attr("href"); //获取a标签的属性
log.debug(title+" – "+aurl);
}
}
2.4.3 抓取标题 – 页面上的内容
可以多级父子样式嵌套
@Test //京东商城,商品标题
public void getItemTile() throws IOException{
String url = "https://item.jd.com/3882469.html";
Document doc = Jsoup.connect(url).get();
Element ele = doc.select(".itemInfo-wrap .sku-name").get(0);
String title = ele.text();
log.debug(title);
}
@Test //当当商城,商品标题
public void getDDItemTile() throws IOException{
String url = "http://product.dangdang.com/1052875306.html";
Document doc = Jsoup.connect(url).get();
Element ele = doc.select("article").get(0);
String title = ele.text();
log.debug(title);
}
2.4.4 抓取价格 – json
2017年4月,京东开始对价格进行反爬虫控制,访问过多的IP地址会被禁止。
2019年8月,京东开始限定爬虫爬取价格,必须伪装请求头,让它觉得是浏览器访问
@Test
public void json() throws IOException {
String url = "https://p.3.cn/prices/mgets?skuIds=J_100003717483";
Connection cn = Jsoup.connect(url).userAgent("Mozilla/5.0 (Windows NT 5.1; zh-CN) AppleWebKit/535.12 (KHTML, like Gecko) Chrome/22.0.1229.79 Safari/535.12");
String json = cn.ignoreContentType(true).execute().body();
System.out.println(json);
ObjectMapper MAPPER =new ObjectMapper();
JsonNode node = MAPPER.readTree(json);
Double price = node.get(0).get("p").asDouble();
System.out.println(price);
}
2.4.5 抓取描述 – jsonp
@Test //商品描述
public void getItemDesc() throws IOException{
String url = "http://d.3.cn/desc/3882469";
String jsonp = Jsoup.connect(url).ignoreContentType(true).execute().body();
String json = jsonp.substring(9, jsonp.length()-1); //把函数名去掉
JsonNode jsonNode = MAPPER.readTree(json);
String desc = jsonNode.get("content").asText();
log.debug(desc);
}
2.5 爬取京东
抓取商品先要找到商品ID,有两个方案:
方案一:商品ID是一串数字,猜测它是自增的,于是我们可以是做一个自增的循环。但如果商品的ID不是连续,会造成很多访问无法继续访问,报链接超时。
方案二:找到网站的所有商品的列表页面,解析html找到商品的ID,这个方式解析麻烦些,但商品ID直接可以获得。所有一般来说都是采用第二种方案。
分类、商品列表、商品详情
那抓取京东网站就变成抓取所有分类,按分类找到商品列表页面,从商品列表页面抓取出商品ID,最终循环商品ID,抓取所有商品详情页面,解析商品详情页面,找到所有商品的详细信息。
断点抓取、离线分析
京东有近22个大类143个二级分类,1286三级分类,8615683种商品,近九百万种商品。如果持续在线抓取,会很快比屏蔽。也不方便测试。所以我们采取断点抓取,离线分析。先将分类抓取,将榨取后的信息保存到磁盘中,后期对磁盘中的文件进行分析入库。
2.5.1 商品三级分类
@Test
public void testCat3() throws IOException {
List<String> catList = JD.getCat3();
for(String url : catList) {
System.out.println(url);
}
System.out.println("处理标准三级分类:"+catList.size());
}
//返回所有三级分类。京东三级分类:1286,标准有:1190
public static List<String> getCat3() throws IOException{
//所有分类都在里面
String url = "http://www.jd.com/allSort.aspx";
//通过选择器把三级分类过滤出来,集合
Elements els = Jsoup.connect(url).get()
.select("div dl dd a");
//存放爬取所有三级分类链接
List<String> catList = new ArrayList<String>();
for(Element e : els) {
//获取到三级分类a标签的链接值
String catUrl = e.attr("href");
//排除异常链接
if(catUrl.startsWith("//list.jd.com/list.html?cat=")) {
catList.add("http:"+catUrl);
}
}
return catList;
}
2.5.2 某个分类下的列表总数
@Test
public void pageNum() throws IOException {
String catUrl = "http://list.jd.com/list.html?cat=1713,3274&jth=i";
int num = JD.getPageNum(catUrl);
System.out.println(num);
}
//获取某个分类下总页数,参数就是分类链接
public static int getPageNum(String catUrl) throws IOException {
Integer num = Integer.parseInt(
Jsoup.connect(catUrl).get()
.select(".fp-text I").get(0).text()
);
return num;
}
2.5.3 某个分类下所有分页链接
@Test //测试某个分类下的所有的分页链接
public void pageList() throws IOException {
String catUrl = "https://list.jd.com/list.html?cat=1713,3274";
Integer maxNum = JD.getPageNum(catUrl);
List<String> itemList = JD.getPageUrlList(catUrl, maxNum);
for(String item : itemList) {
System.out.println(item);
}
}
//https://list.jd.com/list.html?cat=1713,3274&page=1
//https://list.jd.com/list.html?cat=1713,3274&page=2
//拼接某个一个分类下的所有的分页链接
public static List<String> getPageUrlList(String catUrl, Integer maxNum){
List<String> pageUrlList = new ArrayList<String>();
//遍历所有页数
for(int i=1; i<=maxNum; i++) {
String pageUrl = catUrl + "&page=" + I;
pageUrlList.add(pageUrl);
}
return pageUrlList;
}
2.5.4 某个分页下所有商品链接
@Test //某个列表页面上所有商品链接地址
public void itemList() throws IOException {
String pageUrl = "http://list.jd.com/list.html?cat=1713,3274&page=210";
List<String> itemUrlList = JD.getItemUrlList(pageUrl);
for(String itemUrl : itemUrlList) {
System.out.println(itemUrl);
}
}
//抓取某个列表页面中所有商品链接的地址,
public static List<String> getItemUrlList(String pageUrl) throws IOException{
Elements els = Jsoup.connect(pageUrl).get()
.select(".p-img a");
List<String> itemUrlList = new ArrayList<String>();
//所有a标签,过滤过的
for(Element e : els) {
//e是a标签,href属性值
String itemUrl = e.attr("href");
itemUrlList.add("http:"+itemUrl);
}
return itemUrlList;
}
2.5.5 获取京东所有商品链接
@Test
public void site() throws IOException, InterruptedException {
//获取所有的三级分类
List<String> catUrlList = JD.getCat3();
//遍历3级分类
for(String catUrl : catUrlList) {
//延时
Thread.sleep(10);
//返回当前分类的总页数
int maxNum = JD.getPageNum(catUrl);
//某个分类下所有分页链接
List<String> pageUrlList = JD.getPageUrlList(catUrl, maxNum);
//遍历当前分类下的所有分页链接
for(String pageUrl : pageUrlList) {
//当前分页商品链接
List<String> itemUrlList = JD.getItemUrlList(pageUrl);
for(String itemUrl : itemUrlList) {
System.out.println(itemUrl);
//获取到当前商品链接,调用方法获取其标题、价格。。。
}
}
}
}
https://item.jd.com/100002795959.html
https://p.3.cn/prices/mgets?skuIds=100002795959
手写Spring[控制反转(IOC)、依赖注入(DI)]
l IoC - Inverse of Control
控制反转,自己不控制对象的创建,而是权利反转,交给工具来创建对象
需要对象,从工具来取用@component
l DI - Dependency Injection
依赖注入@Autowired
对象需要的数据,使用的其他对象,进行自动装配
import java.io.File;
import java.net.URLDecoder;
import java.util.HashMap;
import java.util.Map;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.fasterxml.jackson.dataformat.yaml.YAMLFactory;
import ognl.Ognl;
public class Configure {
private static Map<String,Map> cfg = new HashMap<String, Map>();
static {
try {
load();
} catch (Exception e) {
e.printStackTrace();
}
}
public static void load() throws Exception{
/*获得application.yml配置文件的路径
d://xx//xxx/xx//application.yml绝对路径(移动,换平台就行不通了)
"/" ---- 表示当前类对象(.class文件)所在的文件夹(bin文件夹)*/
String path = Configure.class.getResource("/application.yml").getPath();
// path 是经过URL编码(ISO8859-1)的字符串,
编译成d:/中/xxx----->d:/%e4%b8%ad/xxx --解码--> d:/中/xxx
path = URLDecoder.decode(path,"UTF-8");
ObjectMapper m = new ObjectMapper(new YAMLFactory());
//获得三层map
cfg = m.readValue(new File(path), Map.class);
}
public static String get(String ognl) {
// ognl表达式格式:${spring.datasource.driver}
// ---> 先拆除标记,获得内容:spring.datasource.driver
ognl = ognl.trim();
ognl = ognl.substring(2,ognl.length()-1);
try {//使用ognl表达式,从cfg集合提取数据
return (String)Ognl.getValue(ognl,cfg);
} catch (Exception e) {
e.printStackTrace();
return null; } } }
import java.io.File;
import java.lang.reflect.Field;
import java.net.URLDecoder;
import java.util.Collection;
import java.util.HashMap;
import java.util.Map;
//spring环境/上下文/容器对象
public class SpringContext {
private Map<String,Object> map = new HashMap<String, Object>();
//自动扫描,在文件夹中,自动找到所有的类,自动创建所有实例
public void autoScan() throws Exception{
String path = SpringContext.class.getResource("/").getPath();
path = URLDecoder.decode(path,"utf-8");
File dir = new File(path);
StringBuilder sb = new StringBuilder();
scan(dir,sb);
autowire();//自动装配
}
private void autowire()throws Exception{
Collection<Object> values = map.values();//从map取出所有的实例
for (Object object : values) {//遍历所有对象
Class<? extends Object> cls = object.getClass();//获得对象的类对象
Field[] a = cls.getDeclaredFields();//获得对象的所有成员变量
for (Field f : a) {//遍历成员变量
//判断变量上是否存在Autowired或者Value注解
if(f.isAnnotationPresent(Autowired.class)) {
injectObject(cls,object,f);//注入对象
}else if(f.isAnnotationPresent(Value.class)) {
injectValue(cls,object,f);//注入配置数据
}
}
}
}
private void injectValue(Class<? extends Object> cls, Object object, Field f) throws Exception{
/*
* @Value("${spring.datasource.username}")
* String username
*
* - 获得@Value注解
* - 获得注解的属性 name(value)
* - 从Configure类获取数据
* - 把配置数据保存到这个变量
*/
Value value = f.getAnnotation(Value.class);
String name = value.name();
if(name.equals("")) {
name = value.value();
}
String v = Configure.get(name);
f.setAccessible(true);
f.set(object, v);
}
private void injectObject(Class<? extends Object> cls, Object object, Field f) throws Exception {
/*
* @Autowired
* UserDao userDao
*
* -获得变量的类型(类对象)
* -用类对象来获得实例
* -把实例保存到这个变量
*/
Class<?> type = f.getType();
Object v = get(type);
f.setAccessible(true);
f.set(object, v);
}
private void scan(File dir, StringBuilder sb)throws Exception {
File[] list = dir.listFiles();
if(list == null) {
return;
}
for (File file : list) {
if(file.isFile()) {
String name = file.getName();
if(name.endsWith(".class")) {
name = name.substring(0,name.length()-6);
name = sb +"." + name;
handle(name);
}
} else {
if(sb.length()!=0) {//第一层包不加点
sb.append(".");
}
sb.append(file.getName());
scan(file,sb);
int index = sb.lastIndexOf(".");
if(index == -1) {
index = 0;
}
sb.delete(index, sb.length());
}
}
}
private void handle(String name)throws Exception{
Class<?> c = Class.forName(name);
if(c.isAnnotationPresent(Component.class) ||c.isAnnotationPresent(Service.class)
||c.isAnnotationPresent(Controller.class) ) {
Object obj = c.newInstance();
map.put(name, obj);
}
}
public <T> T get(Class<T> c) {
String name = c.getName();
return (T)map.get(name);
}
public static void main(String[] args)throws Exception {
SpringContext ctx = new SpringContext();
ctx.autoScan();
UserController controller = ctx.get(UserController.class);
controller.test();
// System.out.println(ctx.map);
//
// UserDao userDao = ctx.get(UserDao.class);
// System.out.println(userDao);
}
}
手写SpringMVC框架
step1. 在WEB-INF下添加hello.jsp。
<%@ page contentType="text/html; charset=UTF-8"
pageEncoding="UTF-8"%>
<html>
<head>
<title>Insert title heretitle>
head>
<body style="font-size:30px;">
Hello,SmartMVC!
body>
html>
step2. 在demo包下添加HelloController类。
参考代码:
public class HelloController {
@RequestMapping("/hello.do")
public String hello() {
System.out.println(
"HelloController's hello()");
/*
* 返回视图名。
* DispatcherServlet依据视图名定位到
* 某个视图对象,比如某个jsp。
*/
return "hello";
}
}
step3. 在base.annotation下添加@RequestMapping注解。
参考代码:
@Retention(RetentionPolicy.RUNTIME)
public @interface RequestMapping {
public String value();
}
step4. 在resources下添加smartmvc.xml。
<beans>
<bean class="demo.HelloController"/>
beans>
step5. 在base.web下添加DispatcherServlet。
在init方法里,先读取smartmvc.xml配置文件,然后将 处理器实例化,并有将处理器实例放到list集合里面,然后 将这些处理器实例交给HandlerMapping来处理。
参考代码:
public class DispatcherServlet extends HttpServlet {
private static final long serialVersionUID = 1L;
private HandlerMapping handlerMapping;
public DispatcherServlet() {
System.out.println(
"DispatcherServlet's constructor");
}
@Override
/**
* 读取smartmvc的配置文件(配置有处理器类名等信息),
* 然后将处理器实例化,最后将处理器实例交给
* HandlerMapping来处理。
*/
public void init() throws ServletException {
SAXReader saxReader = new SAXReader();
InputStream in =
getClass().getClassLoader()
.getResourceAsStream("smartmvc.xml");
try {
Document doc = saxReader.read(in);
Element root = doc.getRootElement();
List<Element> elements = root.elements();
//beans用于存放处理器实例
List beans = new ArrayList();
for(Element ele : elements) {
String className = ele.attributeValue("class");
//将处理器实例化
Object obj = Class.forName(className).newInstance();
beans.add(obj);
}
System.out.println("beans:" + beans);
//创建HandlerMapping对象
handlerMapping = new HandlerMapping();
//将处理器实例交给HandlerMapping来处理
handlerMapping.process(beans);
} catch (Exception e) {
e.printStackTrace();
}
}
}
step6. 在base.common下添加HandlerMapping类。
在process方法里,遍历处理器实例组成的集合,对于 每一个处理器实例,读取加在方法前的@RequestMapping注解中的 请求路径,然后以请求路径作为key,以处理器实例及method对象的 封装(Handler)作为value,创建maps。
参考代码:
public class HandlerMapping {
//maps存放了请求路径与处理器实例及方法的对应关系
private Map<String,Handler> maps =
new HashMap<String,Handler>();
/**
* 依据请求路径返回Handler对象
*/
public Handler getHandler(String path) {
return maps.get(path);
}
/**
* 创建一个maps集合,里面存放有请求路径与
* Handler的对应关系。其中,Handler封装了
* 处理器实例及method对象。
*/
public void process(List beans) {
//遍历处理器实例组成的集合
for(Object bean : beans) {
//获得处理器实例对应的class对象
Class clazz = bean.getClass();
//获得处理器的所有方法
Method[] methods =
clazz.getDeclaredMethods();
//对处理器的方法进行遍历
for(Method mh : methods) {
//获得加在方法前的@RequestMapping注解
RequestMapping rm =
mh.getAnnotation(
RequestMapping.class);
//获得@RequestMapping注解中配置的请求路径
String path = rm.value();
Handler handler = new Handler(bean,mh);
//将请求路径与handler的对应关系保存到map
maps.put(path, handler);
}
}
System.out.println("maps:" + maps);
}
}
step7. 在base.common下添加Handler类。
参考代码:
public class Handler {
private Object obj;
private Method mh;
public Handler(Object obj, Method mh) {
this.obj = obj;
this.mh = mh;
}
public Object getObj() {
return obj;
}
public void setObj(Object obj) {
this.obj = obj;
}
public Method getMh() {
return mh;
}
public void setMh(Method mh) {
this.mh = mh;
}
}
Step8.使用smartmvc
step1.导包
<dependency>
<groupId>dom4j</groupId>
<artifactId>dom4j</artifactId>
<version>1.6.1</version>
</dependency>
step2.将smartmvc核心类拷贝过来
step3.配置DispatcherServlet
<servlet>
<servlet-name>DispatcherServlet</servlet-name>
<servlet-class>base.web.DispatcherServlet</servlet-class>
<!--
配置启动加载:
当servlet容器启动之后,会立即将
配置有load-on-startup参数的servlet实例化。
参数值是一个大于等于零的整数,越小,越优先
被创建。
-->
<load-on-startup>1</load-on-startup>
</servlet>
<servlet-mapping>
<servlet-name>DispatcherServlet</servlet-name>
<url-pattern>*.do</url-pattern>
</servlet-mapping>
step4.添加jsp文件。
step5.添加处理器类。
step6.添加smartmvc配置文件。
练习2:
完成smartmvc,并增加一个简单的功能(可以在 web.xml文件中配置文件名):
提示
step1. 在web.xml中,使用初始化参数来配置文件名
configLocation
smartmvc.xml
step2. 在DispatcherServlet的init方法中,读取初始化 参数。 String fileName = getInitParameter(“configLocation”);
1.SmartMVC
(1)SmartMVC是什么?
是一个web mvc框架(类似于SpringMVC),主要是实现了一个通用的控制器。
注:开发人员借助于该框架,只需要写处理器类与视图(目前只支持jsp
作为视图层技术)就可以于开发基于MVC架构的web应用。
(2)SmartMVC架构
(3)SmartMVC各个组件之间的关系
(4)主要版本
第一版: 实现了一个通用的控制器(DispatcherServlet),只支持
转发。
第二版: 可以在web.xml配置文件名,并支持重定向(在返回的视图名
前添加"redirect:"。
第三版: 支持在处理器方法中添加参数(只支持添加request和response)。
第四版: @RequestMapping注解可以添加到类前。
(5)如何使用SmartMVC?
step1.导包
<dependency>
<groupId>dom4j</groupId>
<artifactId>dom4j</artifactId>
<version>1.6.1</version>
</dependency>
step2.将smartmvc核心类拷贝过来
step3.配置DispatcherServlet
<servlet>
<servlet-name>DispatcherServlet</servlet-name>
<servlet-class>base.web.DispatcherServlet</servlet-class>
<!--
配置启动加载:
当servlet容器启动之后,会立即将
配置有load-on-startup参数的servlet实例化。
参数值是一个大于等于零的整数,越小,越优先
被创建。
-->
<load-on-startup>1</load-on-startup>
</servlet>
<servlet-mapping>
<servlet-name>DispatcherServlet</servlet-name>
<url-pattern>*.do</url-pattern>
</servlet-mapping>
step4.添加jsp文件。
step5.添加处理器类。
step6.添加smartmvc配置文件。
手写双向循环链表
1.什么是链表:
链表由一系列节点构成,其中,每个节点包含两部分内容(一部分是数据,另外一部分是指针)。
注: 指针指向了下一个节点(也就是说通过该指针可以找到下一个节点)。
如果只有一个指向下一个节点的指针,称之为单向链表。
如果有两个指针(一个指向上一个节点,一个指)向下一个节点),称之为双向链表。
如果最后一个节点与第一个节点也通过指针连接起来,称之为双向循环链表。
jdk8.0之前的LinkedList是采用双向循环链表实现的,
jdk8.0之后,采用双向链表实现。
2.链表跟数组相比,优缺点是什么:
数组的优点:
依据下标可以非常快速的找到某个元素。
数组的缺点:
删除和插入操作比较耗费时间,需要重新移动大量元素(包括扩容)。
数组需要有连续的地址空间。
链表的优点:
删除和插入操作速度非常快。
链表不需要连续的地址空间。
链表的缺点:
依据下标查找某个元素比较慢。
链表节点需要保存节点的地址,同数组相比,
需要占用更多的内存(需存储前后指针)
public class LinkedList<E> {
//存放表头(即第一个节点)的地址(引用)
private Node head;
//存放节点的个数(链表的长度)
private int size;
/**
* 在指定位置插入某个元素
* @param index 位置
* @param e 要插入的元素
*/
public void add(int index,E e) {
if(index < 0 || index > size) {
throw new IndexOutOfBoundsException("下标越界");
}
//如果位置等于链表的长度,表示向
//链表末尾添加。
if(index == size) {
add(e);
return;
}
//先找到指定位置的节点
Node next = getNode(index);
Node prev = next.prev;
//将next和prev指定为新添加的节点的前驱
//和后继节点
Node node = new Node(e);
next.prev = node;
node.prev = prev;
prev.next = node;
node.next = next;
//如果添加的位置是0,则新添加的节点
//成为头节点。
if(index == 0) {
head = node;
}
size ++;
}
/**
* 返回指定位置的元素。
* @param index 位置(位置是从0开始的)
* @return 指定位置的元素
*/
public E get(int index) {
if(index < 0 || index >= size) {
throw new
IndexOutOfBoundsException("下标越界");
}
Node node = getNode(index);
return node.data;
}
/**
* 删除指定位置的元素
* @param index 位置
* @return 元素
*/
public E remove(int index) {
if(index < 0 || index >= size) {
throw new
IndexOutOfBoundsException("下标越界");
}
//只有一个节点
if(size == 1) {
E data = head.data;
head = null;
size --;
return data;
}
//找到要删除的节点
Node node = getNode(index);
//找到该节点的上一个(前驱)和
//下一个节点(后继)
Node prev = node.prev;
Node next = node.next;
//让前驱和后继建立引用关系
prev.next = next;
next.prev = prev;
//如果删除的是头节点,需要将下一个节点
//指定为头节点。
if(index == 0) {
head = next;
}
size --;
//返回删除的元素
return node.data;
}
private Node getNode(int index) {
Node node = head;
if(index < size /2) {
System.out.println("向后遍历");
for(int i = 0; i< index; i ++) {
node = node.next;
}
}else {
System.out.println("向前遍历");
for(int i = size; i > index; i--) {
node = node.prev;
}
}
return node;
}
/**
* 获得链表的长度。
* @return 链表的长度(即链表当中有几个节点)
*/
public int size() {
return size;
}
@Override
public String toString() {
//如果链表为空,返回[]
if(head == null) {
return "[]";
}
StringBuilder buf =
new StringBuilder("["
+ head.data);
Node node = head.next;
while(node != head) {
buf.append("," + node.data);
node = node.next;
}
return buf.append("]").toString();
}
/**
* 在链表的末尾添加某个元素。
* @param e 要添加的元素。
* @return 添加成功,返回true。
*/
public boolean add(E e) {
/*
* 如果当前链表为空,则该节点为头节点。
*/
if(head == null) {
head = new Node(e);
head.next = head;
head.prev = head;
size ++;
return true;
}
/*
* 如果当前链表不为空,则将该元素添加到
* 链表末尾。
*/
Node node = new Node(e);
//先找到链尾(最后一个节点)
Node end = head.prev;
//将新节点添加到链尾(即重新建
//立新的引用关系)
end.next = node;
node.next = head;
head.prev = node;
node.prev = end;
size ++;
return true;
}
/**
* 节点类:
* 用于封装要添加的元素
*
*/
private class Node{
//data是要添加的元素
E data;
//存放下一个节点的地址(引用)
Node next;
//存放上一个节点的地址
Node prev;
public Node(E e) {
data = e;
}
}
}
编码实现 使ArrayList能够线程安全。
/**
- 扩展线程同步功能的代理类
- 代理模式:在不改变原有功能情况下扩展新功能
*/
public class ProxyList<E> implements List<E> {
private List<E> target;//被代理的目标list对象
public ProxyList() {
target = new ArrayList<E>();
}
public ProxyList(List<E> list) {
target = list;
}
public void add(int index, E element) {
synchronized (this) {
target.add(index, element);
}
}
public synchronized int size() {
return target.size();
}
public synchronized boolean isEmpty() {
return target.isEmpty();
}
public synchronized boolean contains(Object o) {
return target.contains(o);
}
public synchronized Iterator<E> iterator() {
return target.iterator();
}
public synchronized Object[] toArray() {
return target.toArray();
}
public synchronized <T> T[] toArray(T[] a) {
return target.toArray(a);
}
public synchronized boolean add(E e) {
return target.add(e);
}
@Override
public synchronized String toString() {
return target.toString();
}
public synchronized boolean remove(Object o) {
return target.remove(o);
}
public synchronized boolean containsAll(Collection<?> c) {
return target.containsAll(c);
}
public synchronized boolean addAll(Collection<? extends E> c) {
return target.addAll(c);
}
public synchronized boolean addAll(int index, Collection<? extends E> c) {
return target.addAll(index, c);
}
public synchronized boolean removeAll(Collection<?> c) {
return target.removeAll(c);
}
public synchronized boolean retainAll(Collection<?> c) {
return target.retainAll(c);
}
public synchronized void clear() {
target.clear();
}
public synchronized E get(int index) {
return target.get(index);
}
public synchronized E set(int index, E element) {
return target.set(index, element);
}
public synchronized E remove(int index) {
return target.remove(index);
}
public synchronized int indexOf(Object o) {
return target.indexOf(o);
}
public synchronized int lastIndexOf(Object o) {
return target.lastIndexOf(o);
}
public synchronized ListIterator<E> listIterator() {
return target.listIterator();
}
public synchronized ListIterator<E> listIterator(int index) {
return target.listIterator(index);
}
public synchronized List<E> subList(int fromIndex, int toIndex) {
return target.subList(fromIndex, toIndex);
}
}
动态代理API
1.Java在反射包中提供的一个API
2.这个API用于实现代理模式编程
3.动态代理API可以动态的创建接口的实现类实例
动态代理:
/**
- 调用处理器
*/
public class ProxyHandler<E>
implements InvocationHandler {
private List<E> target;//被代理的目标对象
public ProxyHandler() {
target = new ArrayList<E>();
}
public ProxyHandler(List<E> target) {
this.target = target;
}
//返回值是目标方法执行以后的返回值
public Object invoke(
Object proxy, //动态生成的代理对象
Method method,//正在被调用的方法
Object[] args)//调用方法时候传递的实际参数
throws Throwable {
System.out.println("正在调用:"+method);
synchronized (proxy) {
//在target对象上执行method对应的方法
return method.invoke(target, args);
//假设 add() list e
//则执行了 : list.add(e)
}
}
}
public class Demo05 {
public static void main(String[] args) {
/**
* 使用动态代理API创建接口的实例
*/
List<String> list=(List<String>)
Proxy.newProxyInstance(
Demo05.class.getClassLoader(), //类加载器
new Class[] {List.class}, //实现接口类型列表
new ProxyHandler<String>());//调用处理器对象
list.add("Andy");
list.add("Jerry");
list.add("Tom");
list.add("Lee");
System.out.println(list);
//Java 线程安全解List决方案之一
List<String> lst=new ArrayList<String>();
lst=Collections.synchronizedList(lst);
}
}
ArrayList线程安全问题?
1.采用代理模式实现(繁琐)
2.采用动态代理API(简单)
3.synchronizedList() (淘汰了!)
4.Java并发包中提供的线程安全的CopyOnWriteArrayList可以解决线程并发安全问题,并且可以在遍历期间操作集合元素,不会发生并发修改异常!
5.Vector 线程安全的类,淘汰了!
编程建议:
1.单线程使用 ArrayList
多线程使用 CopyOnWriteArrayList