(十八)从零开始学人工智能-智能推荐系统:矩阵分解
推荐系统系列之二:矩阵分解
文章目录
- 推荐系统系列之二:矩阵分解
- 1. 理论基础
- 2. 随机梯度下降法(SGD)
- 3. 改进
- 1). 带偏置的SVD(BiasSVD)
- 2). SVD++
- 3). timeSVD
- 4. 模型对比
- 5. 拓展
- 1) 与主题模型结合
- 2) 与社交网络结合
- 3) 与神经网络(CNN)结合
- 声明
- 参考文献
1. 理论基础
说明介绍:
从数学概率的角度,证明了 MF 的由来。这样使得 概率矩阵分解(PMF) 和其他模型的“搭配”有了理论的依据。
来源出处:
- Salakhutdinov et al. Probabilistic matrix factorization. NIPS(2008): 1257-1264.
定义和描述
假设现在有 n n n 个用户, m m m 个商品,形成一个 n × m n×m n×m 维的评分矩阵 R \mathbf{R} R,其中的元素 r u , i r_{u,i} ru,i 表示用户 u u u 对商品 i i i 的评分。假设潜在特征个数为 k k k,那么 n × k n×k n×k 维的 p \mathbf{p} p 表示用户的潜在特征矩阵,其中 p u \mathbf{p}_{u} pu 表示用户 u u u 的潜在特征向量; m × k m×k m×k 维的矩阵 q \mathbf{q} q 表示商品的潜在特征矩阵,其中 q i \mathbf{q}_{i} qi 商品 i i i 的潜在特征向量。概率模型图如下图所示:
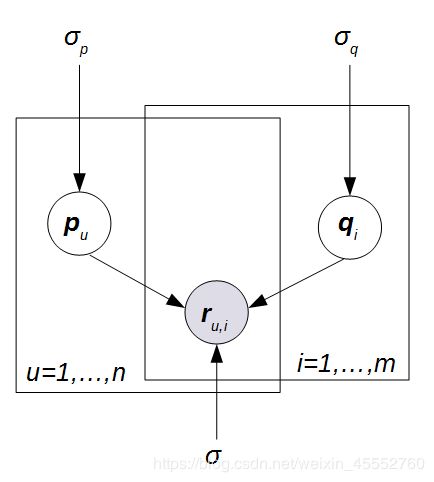
主要推导:
假设关于已知评分数据的条件分布满足高斯分布:
p ( R ∣ p , q , σ 2 ) = ∏ u = 1 n ∏ i = 1 m [ N ( r u , i ∣ p u q i T , σ 2 ) ] I i j , p\left( \mathbf{R}|\mathbf{p},\mathbf{q},\sigma^{2} \right)=\prod_{u=1}^{n}\prod_{i=1}^{m}\left[ N\left( r_{u,i}|\mathbf{p}_{u}\mathbf{q}_{i}^T,\sigma^{2} \right)\right]^{I_{ij}}, p(R∣p,q,σ2)=u=1∏ni=1∏m[N(ru,i∣puqiT,σ2)]Iij,
其中, I u , i I_{u,i} Iu,i 表示指示函数,当用户 u u u 与商品 i i i 有互动时, I u , i = 1 I_{u,i}=1 Iu,i=1,否则为0。
再假设用户潜在特征向量和商品潜在特征向量都服从均值为 0 的高斯先验分布,即:
p ( p ∣ σ p 2 ) = ∏ u = 1 n N ( p u ∣ 0 , σ p 2 I ) , p ( q ∣ σ q 2 ) = ∏ i = 1 m N ( q i ∣ 0 , σ q 2 I ) . p\left( \mathbf{p}|\sigma_{p}^{2} \right)=\prod_{u=1}^{n}N\left( \mathbf{p}_{u}|0,\sigma_{p}^{2}\mathbf{I} \right),p\left( \mathbf{q}|\sigma_{q}^{2} \right)=\prod_{i=1}^{m}N\left( \mathbf{q}_{i}|0,\sigma_{q}^{2}\mathbf{I} \right). p(p∣σp2)=u=1∏nN(pu∣0,σp2I),p(q∣σq2)=i=1∏mN(qi∣0,σq2I).
注意这个公式中的 I \mathbf{I} I 不是指示函数,表示一个对角阵。
然后,计算 p \mathbf{p} p 和 q \mathbf{q} q 的后验概率:
p ( p , q ∣ R , σ 2 , σ q 2 , σ p 2 ) = p ( p , q , R , σ 2 , σ q 2 , σ p 2 ) p ( R , σ 2 , σ q 2 , σ p 2 ) = p ( R ∣ p , q , σ 2 ) × p ( p , q ∣ σ q 2 , σ p 2 ) p ( R , σ 2 , σ q 2 , σ p 2 ) p\left( \mathbf{p},\mathbf{q}|R,\sigma^{2},\sigma_{q}^{2}, \sigma_{p}^{2}\right)=\frac{ p\left( \mathbf{p},\mathbf{q},R,\sigma^{2},\sigma_{q}^{2}, \sigma_{p}^{2}\right) }{ p\left( R,\sigma^{2},\sigma_{q}^{2}, \sigma_{p}^{2}\right) }=\frac{p\left( R|\mathbf{p},\mathbf{q},\sigma^{2}\right)\times p\left( \mathbf{p},\mathbf{q} |\sigma_{q}^{2}, \sigma_{p}^{2}\right)}{p\left( R,\sigma^{2},\sigma_{q}^{2}, \sigma_{p}^{2}\right)} p(p,q∣R,σ2,σq2,σp2)=p(R,σ2,σq2,σp2)p(p,q,R,σ2,σq2,σp2)=p(R,σ2,σq2,σp2)p(R∣p,q,σ2)×p(p,q∣σq2,σp2)
∼ p ( R ∣ p , q , σ 2 ) × p ( p , q ∣ σ q 2 , σ p 2 ) \sim p\left( R|\mathbf{p},\mathbf{q},\sigma^{2}\right)\times p\left( \mathbf{p},\mathbf{q} |\sigma_{q}^{2}, \sigma_{p}^{2} \right) ∼p(R∣p,q,σ2)×p(p,q∣σq2,σp2)
= p ( R ∣ p , q , σ 2 ) × p ( p ∣ σ p 2 ) × p ( q ∣ σ q 2 ) =p\left( R|\mathbf{p},\mathbf{q},\sigma^{2} \right)\times p\left( \mathbf{p} | \sigma_{p}^{2}\right)\times p\left( \mathbf{q} |\sigma_{q}^{2}\right) =p(R∣p,q,σ2)×p(p∣σp2)×p(q∣σq2)
= ∏ u = 1 n ∏ i = 1 m [ N ( r u , i ∣ p u q i T , σ 2 ) ] I u , i × ∏ u = 1 n [ N ( p u ∣ 0 , σ p 2 I ) ] × ∏ i = 1 m [ N ( q i ∣ 0 , σ q 2 I ) ] =\prod_{u=1}^{n}\prod_{i=1}^{m}\left[ N\left( r_{u,i}|\mathbf{p}_{u}\mathbf{q}_{i}^T,\sigma^{2} \right) \right]^{I_{u,i}}\times \prod_{u=1}^{n}\left[ N\left( \mathbf{p}_{u}|0,\sigma_{p}^{2}I \right) \right]\times \prod_{i=1}^{m}\left[ N\left( \mathbf{q}_{i}|0,\sigma_{q}^{2}I \right) \right] =u=1∏ni=1∏m[N(ru,i∣puqiT,σ2)]Iu,i×u=1∏n[N(pu∣0,σp2I)]×i=1∏m[N(qi∣0,σq2I)]
等式两边取对数 l n ln ln 后得到:
l n p ( p , q ∣ R , σ 2 , σ p 2 , σ q 2 ) = − 1 2 σ 2 ∑ u = 1 n ∑ i = 1 m I i j ( r u , i − p u q i T ) 2 − 1 2 σ p 2 ∑ i = 1 N p u p u T − 1 2 σ q 2 ∑ i = 1 M q i q i T lnp\left( \mathbf{p},\mathbf{q}|\mathbf{R},\sigma^{2},\sigma_{p}^{2}, \sigma_{q}^{2}\right)=-\frac{1}{2\sigma^{2}}\sum_{u=1}^{n}\sum_{i=1}^{m}{I_{ij}\left( r_{u,i}-\mathbf{p}_{u}\mathbf{q}_{i}^T \right)^2}-\frac{1}{2\sigma_{p}^{2}}\sum_{i=1}^{N}{\mathbf{p}_{u}\mathbf{p}_{u}^{T}}-\frac{1}{2\sigma_{q}^{2}}\sum_{i=1}^{M}{\mathbf{q}_{i}\mathbf{q}_{i}^{T}} lnp(p,q∣R,σ2,σp2,σq2)=−2σ21u=1∑ni=1∑mIij(ru,i−puqiT)2−2σp21i=1∑NpupuT−2σq21i=1∑MqiqiT
− 1 2 ( ( ∑ i = 1 n ∑ j = 1 m I u , i ) l n σ 2 + n K l n σ p 2 + m K l n σ q 2 ) + C , -\frac{1}{2}\left( \left( \sum_{i=1}^{n}{\sum_{j=1}^{m}{I_{u,i}}} \right) ln\sigma^{2}+nKln\sigma_{p}^{2}+mKln\sigma_{q}^{2}\right)+C, −21((i=1∑nj=1∑mIu,i)lnσ2+nKlnσp2+mKlnσq2)+C,
化简得:
L = 1 2 ∑ u = 1 n ∑ i = 1 m I u , i ∣ ∣ r u , i − p u q i T ∣ ∣ 2 + λ p 2 ∑ u = 1 n ∣ ∣ p u ∣ ∣ 2 + λ q 2 ∑ i = 1 m ∣ ∣ q i ∣ ∣ 2 L=\frac{1}{2}\sum_{u=1}^{n}\sum_{i=1}^{m}{I_{u,i}\left| \left| r_{u,i}-\mathbf{p}_{u} \mathbf{q}^T_{i} \right| \right|^2}+\frac{\lambda_{p}}{2}\sum_{u=1}^{n}{\left| \left|\mathbf{p}_{u} \right| \right| ^{2}}+\frac{\lambda_{q}}{2}\sum_{i=1}^{m}{\left| \left|\mathbf{q}_{i} \right| \right|^{2}} L=21u=1∑ni=1∑mIu,i∣∣∣∣ru,i−puqiT∣∣∣∣2+2λpu=1∑n∣∣pu∣∣2+2λqi=1∑m∣∣qi∣∣2
详细推导见:
https://zhuanlan.zhihu.com/p/34422451
2. 随机梯度下降法(SGD)
当 λ p = λ q \lambda_{p}=\lambda_{q} λp=λq 时,PMF 目标函数就如下:
目标函数:
min p , q 1 2 ∑ ( u , i ) ∈ O ∥ r u , i − p u q i T ∥ 2 + 1 2 λ ( ∥ p u ∥ 2 + ∥ q i ∥ 2 ) \min \limits_ {\mathbf{p},\mathbf{q}} \frac{1}{2}\sum_{\left ( u,i \right )\in \mathbf{O}} {\left \| r_{u,i}-\mathbf{p}_{u} \mathbf{q}^T_{i} \right \|^2} +\frac{1}{2}\lambda \left ( \left \| \mathbf{p}_{u} \right \|^2 + \left \| \mathbf{q}_{i} \right \|^2 \right ) p,qmin21(u,i)∈O∑∥∥ru,i−puqiT∥∥2+21λ(∥pu∥2+∥qi∥2)
目标函数 L L L 分别对 p u \mathbf{p}_{u} pu 和 q i \mathbf{q}_{i} qi 进行求导得:
∂ L ∂ q i = − ( r u , i − p u q i T ) p u + λ q i \frac{\partial L}{\partial \mathbf{q}_{i}}= - \left( r_{u,i}-\mathbf{p}_{u} \mathbf{q}^T_{i} \right)\mathbf{p}_{u}+ \lambda \mathbf{q}_{i} ∂qi∂L=−(ru,i−puqiT)pu+λqi
∂ L ∂ p u = − ( r u , i − p u q i T ) q i + λ p u \frac{\partial L}{\partial \mathbf{p}_{u}}= - \left( r_{u,i}-\mathbf{p}_{u} \mathbf{q}^T_{i} \right)\mathbf{q}_{i} + \lambda \mathbf{p}_{u} ∂pu∂L=−(ru,i−puqiT)qi+λpu
采用的是随机梯度下降法(SGD)进行求解,更新 p u \mathbf{p}_{u} pu 和 q i \mathbf{q}_{i} qi :
p u ← p u − η ∂ L ∂ p u = p u + η ( ( r u , i − p u q i T ) q i − λ p u ) \mathbf{p}_{u} \leftarrow \mathbf{p}_{u}-\eta \frac{\partial L}{\partial \mathbf{p}_{u}} =\mathbf{p}_{u}+ \eta \left( \left( r_{u,i}-\mathbf{p}_{u} \mathbf{q}^T_{i} \right)\mathbf{q}_{i}- \lambda \mathbf{p}_{u} \right) pu←pu−η∂pu∂L=pu+η((ru,i−puqiT)qi−λpu)
q i ← q i − η ∂ L ∂ q i = q i + η ( ( r u , i − p u q i T ) p u − λ q i ) \mathbf{q}_{i} \leftarrow \mathbf{q}_{i}-\eta \frac{\partial L}{\partial \mathbf{q}_{i}} =\mathbf{q}_{i} + \eta \left( \left( r_{u,i}-\mathbf{p}_{u} \mathbf{q}_{i}^T \right)\mathbf{p}_{u}-\lambda \mathbf{q}_{i} \right) qi←qi−η∂qi∂L=qi+η((ru,i−puqiT)pu−λqi)
令 e u i = r u , i − p u q i T e_{ui}= r_{u,i}-\mathbf{p}_{u} \mathbf{q}^T_{i} eui=ru,i−puqiT ,上述式子简化为:
p u ← p u + η ( e u i q i − λ p u ) \mathbf{p}_{u} \leftarrow \mathbf{p}_{u}+\eta \left( e_{ui}\mathbf{q}_{i}-\lambda \mathbf{p}_{u} \right) pu←pu+η(euiqi−λpu)
q i ← q i + η ( e u i p u − λ q i ) \mathbf{q}_{i} \leftarrow \mathbf{q}_{i} +\eta \left( e_{ui}\mathbf{p}_{u}-\lambda \mathbf{q}_{i} \right) qi←qi+η(euipu−λqi)
核心代码:
def update(p, q, r, learning_rate=0.001, lamda_regularizer=0.1):
error = r - np.dot(p, q.T)
p = p + learning_rate*(error*q - lamda_regularizer*p)
q = q + learning_rate*(error*p - lamda_regularizer*q)
loss = 0.5 * (error**2 + lamda_regularizer*(np.square(p).sum() + np.square(q).sum()))
return p,q,loss
实验结果:
数据集:Movielens100K,随机分割成训练集:测试集=8:2
| MAE | RMSE | Recall@10 | Precision@10 |
|---|---|---|---|
| 0.7347 | 0.9297 | 0.0293 | 0.0620 |
损失函数曲线:

3. 改进
1). 带偏置的SVD(BiasSVD)
来源出处:
- Koren et al. Matrix factorization techniques for recommender systems.Computer 42.8 (2009).
目标函数:
min p , q 1 2 ∑ ( u , i ) ∈ O ∥ r u , i − r ^ u , i ∥ 2 + 1 2 λ ( ∥ p u ∥ 2 + ∥ q i ∥ 2 + ∥ b u ∥ 2 + ∥ b i ∥ 2 ) \min \limits_ {\mathbf{p},\mathbf{q}} \frac{1}{2}\sum_{\left ( u,i \right )\in \mathbf{O}} {\left \| r_{u,i}-\widehat{r}_{u,i} \right \|^2} +\frac{1}{2}\lambda \left ( \left \| \mathbf{p}_{u} \right \|^2 + \left \| \mathbf{q}_{i} \right \|^2 + \left \| b_{u} \right \|^2 + \left \| b_{i} \right \|^2\right ) p,qmin21(u,i)∈O∑∥ru,i−r u,i∥2+21λ(∥pu∥2+∥qi∥2+∥bu∥2+∥bi∥2)
r ^ u , i = μ + b u + b i + p u q i T \widehat{r}_{u,i}=\mu + b_u + b_i + \mathbf{p}_u \mathbf{q}_i^T r u,i=μ+bu+bi+puqiT
μ \mu μ :全部评分的均值
b u b_u bu :用户 u u u 的评分均值
b i b_i bi :商品 i i i 的评分均值
说明介绍:
该方法考虑了实际生活中,用户的评分偏好和商品的特性评分。比如,有对于某商品的好与不好,有用户评分很鲜明,给5和1分;有用户评分比较委婉,给5和3分。由此产生了不同的评分习惯。加入这些因素,用潜在特征来预测用户的喜好与”均值“的偏差更合理。
更新公式:
p u ← p u + η ( e u i q i − λ p u ) \mathbf{p}_{u} \leftarrow \mathbf{p}_{u}+\eta \left( e_{ui}\mathbf{q}_{i}-\lambda \mathbf{p}_{u} \right) pu←pu+η(euiqi−λpu)
q i ← q i + η ( e u i p u − λ q i ) \mathbf{q}_{i} \leftarrow \mathbf{q}_{i} +\eta \left( e_{ui}\mathbf{p}_{u}-\lambda \mathbf{q}_{i} \right) qi←qi+η(euipu−λqi)
b u ← b u + η ( e u i − λ b u ) b_u\leftarrow b_u +\eta \left( e_{ui}-\lambda b_u \right) bu←bu+η(eui−λbu)
b i ← b i + η ( e u i − λ b i ) b_i\leftarrow b_i +\eta \left( e_{ui}-\lambda b_i \right) bi←bi+η(eui−λbi)
核心代码:
def update(p, q, bu, bi, aveg_rating, r, learning_rate=0.001, lamda_regularizer=0.1):
error = r - (aveg_rating + bu + bi + np.dot(p, q.T))
p = p + learning_rate*(error*q - lamda_regularizer*p)
q = q + learning_rate*(error*p - lamda_regularizer*q)
bu = bu + learning_rate*(error - lamda_regularizer*bu)
bi = bi + learning_rate*(error - lamda_regularizer*bi)
return p,q,bu,bi
实验结果:
数据集:Movielens100K,随机分割成训练集:测试集=8:2
| MAE | RMSE |
|---|---|
| 0.7210 | 0.9124 |
loss 曲线:
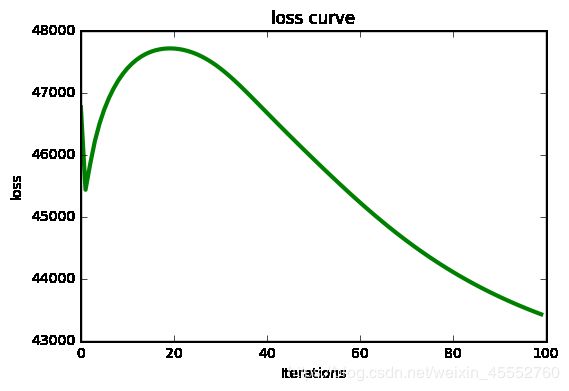
这图是参数与本文其他模型相同时的收敛曲线,并不好看。
BiasSVD 的学习率不好调,调小 loss 曲线完美收敛,但是 MAE 和 RMSE 结果并不好看,应该是陷入了局部收敛区间;当调大时,loss 曲线又不好看,不过实验结果会好很多。我个人感觉是 BiasSVD 太“精细”了,反而容易陷入局部最优解。
2). SVD++
来源出处:
- Koren Y. Factor in the neighbors: Scalable and accurate collaborative filtering[J]. ACM Transactions on Knowledge Discovery from Data (TKDD), 2010, 4(1): 1.
目标函数:
min 1 2 ∑ ( u , i ) ∈ O ∥ r u , i − r ^ u , i ∥ 2 + 1 2 λ ( ∥ p u ∥ 2 + ∥ q i ∥ 2 + ∥ b u ∥ 2 + ∥ b i ∥ 2 + ∥ y j ∥ 2 ) \min \limits_ {} \frac{1}{2}\sum_{\left ( u,i \right )\in \mathbf{O}} {\left \| r_{u,i}-\widehat{r}_{u,i} \right \|^2} +\frac{1}{2}\lambda \left ( \left \| \mathbf{p}_{u} \right \|^2 + \left \| \mathbf{q}_{i} \right \|^2 + \left \| b_{u} \right \|^2 + \left \| b_{i} \right \|^2+ \left \| \mathbf{y}_{j} \right \|^2\right ) min21(u,i)∈O∑∥ru,i−r u,i∥2+21λ(∥pu∥2+∥qi∥2+∥bu∥2+∥bi∥2+∥yj∥2)
r ^ u , i = μ + b u + b i + ( p u + ∣ I u ∣ − 1 2 ∑ j ∈ I u y j ) q i T \widehat{r}_{u,i}=\mu + b_u + b_i + \left( \mathbf{p}_u +\left | I_u \right |^{-\frac{1}{2}}\sum_{j \in I_u}^{}y_j \right)\mathbf{q}_i^T r u,i=μ+bu+bi+⎝⎛pu+∣Iu∣−21j∈Iu∑yj⎠⎞qiT
其中 I u I_u Iu 为用户 u u u 评价过的所有电影的集合; y j \mathbf{y}_j yj 为隐藏的对于商品 j j j 的隐含喜好; ∣ I u ∣ − 1 2 \left | I_u \right |^{-\frac{1}{2}} ∣Iu∣−21 是一个经验公式。
说明介绍:
SVD++ 是 BiasSVD 的改进版,它考虑了用户的历史评分行为,将这些行为数据作为一个偏置加入到模型中,使模型更“精细”。
更新公式:
p u ← p u + η ( e u i q i − λ p u ) \mathbf{p}_{u} \leftarrow \mathbf{p}_{u}+\eta \left( e_{ui}\mathbf{q}_{i}-\lambda \mathbf{p}_{u} \right) pu←pu+η(euiqi−λpu)
q i ← q i + η ( e u i ( p u + ∣ I u ∣ − 1 2 ∑ j ∈ I u y j ) − λ q i ) \mathbf{q}_{i} \leftarrow \mathbf{q}_{i} +\eta \left( e_{ui}\left( \mathbf{p}_u +\left | I_u \right |^{-\frac{1}{2}}\sum_{j \in I_u}^{}\mathbf{y}_j \right) -\lambda \mathbf{q}_{i} \right) qi←qi+η⎝⎛eui⎝⎛pu+∣Iu∣−21j∈Iu∑yj⎠⎞−λqi⎠⎞
b u ← b u + η ( e u i − λ b u ) b_u\leftarrow b_u +\eta \left( e_{ui}-\lambda b_u \right) bu←bu+η(eui−λbu)
b i ← b i + η ( e u i − λ b i ) b_i\leftarrow b_i +\eta \left( e_{ui}-\lambda b_i \right) bi←bi+η(eui−λbi)
y j ← y j + η ( e u i ∣ I u ∣ − 1 2 q i − λ y j ) \mathbf{y}_j \leftarrow \mathbf{y}_j +\eta \left( e_{ui} \left | I_u \right |^{-\frac{1}{2}}\mathbf{q}_{i} -\lambda \mathbf{y}_{j} \right) yj←yj+η(eui∣Iu∣−21qi−λyj)
核心代码:
def update(p,q,bu,bi,Y,aveg_rating,r,Ru,learning_rate=0.001,lamda_regularizer=0.1):
Iu = np.sum(Ru>0)
y_sum = np.sum(Y[np.where(Ru>0)],axis=0)
error = r - (aveg_rating + bu + bi + np.dot(p+Iu**(-0.5)*y_sum, q.T))
p = p + learning_rate*(error*q - lamda_regularizer*p)
q = q + learning_rate*(error*(p + Iu**(-0.5)*y_sum) - lamda_regularizer*q)
bu = bu + learning_rate*(error - lamda_regularizer*bu)
bi = bi + learning_rate*(error - lamda_regularizer*bi)
for j in np.where(Ru>0):
Y[j] = Y[j] + learning_rate*(error*Iu**(-0.5)*q - lamda_regularizer*Y[j])
return p,q,bu,bi,Y
实验结果:
数据集:Movielens100K,随机分割成训练集:测试集=8:2
| MAE | RMSE |
|---|---|
| 0.7162 | 0.9109 |
3). timeSVD
来源出处:
- Koren et al. Collaborative filtering with temporal dynamics. Communications of the ACM 53.4 (2010): 89-97.
目标函数:
min 1 2 ∑ ( u , i ) ∈ O ∥ r u , i − r ^ u , i ∥ 2 + 1 2 λ ( ∥ p u ∥ 2 + ∥ q i ∥ 2 + ∥ b u ∥ 2 + ∥ b i ∥ 2 ) \min \limits_ {} \frac{1}{2}\sum_{\left ( u,i \right )\in \mathbf{O}} {\left \| r_{u,i}-\widehat{r}_{u,i} \right \|^2} +\frac{1}{2}\lambda \left ( \left \| \mathbf{p}_{u} \right \|^2 + \left \| \mathbf{q}_{i} \right \|^2 + \left \| b_{u} \right \|^2 + \left \| b_{i} \right \|^2\right ) min21(u,i)∈O∑∥ru,i−r u,i∥2+21λ(∥pu∥2+∥qi∥2+∥bu∥2+∥bi∥2)
r ^ u , i = μ + b u ( t ) + b i ( t ) + p u ( t ) q i T \widehat{r}_{u,i}=\mu + b_u\left ( t\right) + b_i\left ( t\right) + \mathbf{p}_u\left ( t\right) \mathbf{q}_i^T r u,i=μ+bu(t)+bi(t)+pu(t)qiT
其中, t t t 为时间因子,表示不同的时间状态。
说明介绍:
文中假设:用户的兴趣是随时间变化的,即 p u \mathbf{p}_u pu 与时间 t t t 相关。而 q i \mathbf{q}_i qi 为商品的固有特征,与时间因素无关。比如,大部分用户夏天买短袖、短裤,冬天买长袖、羽绒服,时间效应明显。 q i \mathbf{q}_i qi 反映的是商品属性:你评价或者不评价,我都在这里,不增不减。同时,假设用户和商品的评分偏置也随时间 t t t 的变化而变化。
4. 模型对比
在相同学习率 η \eta η、相同正则项系数 λ \lambda λ、相同特征维度 K K K、相同迭代次数的情况下,
即 learning_rate = 0.005,lamda_regularizer = 0.1,K = 10,max_iteration = 100
| MAE (比前一个算法提升 %) | RMSE (比前一个算法提升 %) | |
|---|---|---|
| MF, SVD, Funk-SVD, PMF | 0.7279 (-) | 0.9297 (-) |
| BiasSVD | 0.7203 (+1.0%) | 0.9154 (+0.7%) |
| SVD++ | 0.7162 (+0.5%) | 0.9109 (+0.5%) |
从上到下,算法刚开始提升效果非常明显,到后来提升效果越来越小。当然,如果再调整参数,结果肯定还会有所提升。
5. 拓展
1) 与主题模型结合
来源出处:
- Wang, Chong, and David M. Blei. “Collaborative topic modeling for recommending scientific articles.” Proceedings of the 17th ACM SIGKDD international conference on Knowledge discovery and data mining. 2011.
示意图:
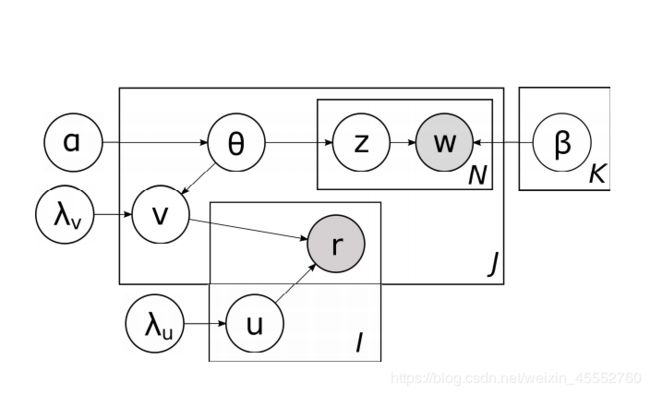
大的框架为 LDA 主题模型,小的框架为 PMF 模型。
目标函数:
min U , V 1 2 ∑ ( i , j ) ∈ O c i , j ∥ r u , i − u i v j T ∥ 2 + 1 2 λ u ∑ i ∥ u i ∥ 2 + 1 2 λ v ∑ j ∥ v j − θ j ∥ 2 − ∑ j ∑ h l o g ( ∑ k θ i , k β k , w j , h ) \min \limits_ {\mathbf{U},\mathbf{V}} \frac{1}{2}\sum_{\left ( i,j \right )\in \mathbf{O}}c_{i,j} {\left \| r_{u,i}-u_{i} v^T_{j} \right \|^2} +\frac{1}{2}\lambda_u \sum_{i} \left \| u_{i} \right \|^2 + \frac{1}{2}\lambda_v \sum_{j}\left \| v_{j}- \theta_j \right \|^2 -\sum_{j}\sum_{h}log \left(\sum_{k} \theta_{i,k}\beta_{k,w_{j,h}} \right) U,Vmin21(i,j)∈O∑ci,j∥∥ru,i−uivjT∥∥2+21λui∑∥ui∥2+21λvj∑∥vj−θj∥2−j∑h∑log(k∑θi,kβk,wj,h)
其中, θ j \theta_j θj 表示商品 j j j 文本信息的主题分布, β k , w j , h \beta_{k,w_{j,h}} βk,wj,h 表示文中 j j j 中主题 k k k 下词语 h h h 的分布。
简单说明:
有些领域它们除了有交互信息外,文本内容比较丰富,比如新闻,学术论文。用主题模型获取文本信息,弥补交互信息不足时的情况。当交互信息丰富时,PMF 依旧其主要作用。
2) 与社交网络结合
来源出处:
- Purushotham, Sanjay, Yan Liu, and C-C. Jay Kuo. “Collaborative topic regression with social matrix factorization for recommendation systems.” arXiv preprint arXiv:1206.4684 (2012).
示意图:
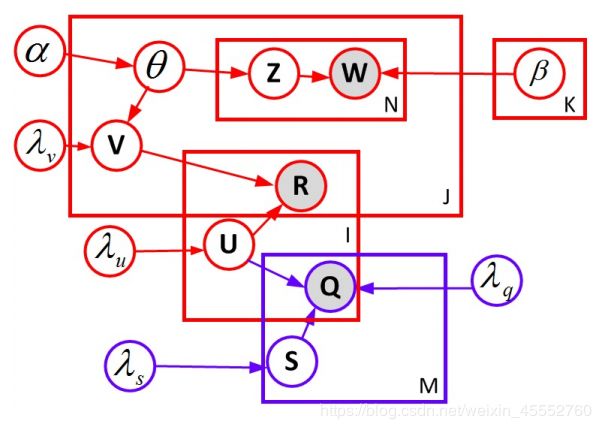
红色的框架为上一个模型,蓝色图为添加的社交信息框架。
目标函数:
min U , V 1 2 ∑ ( i , j ) ∈ O c i , j ∥ r u , i − u i v j T ∥ 2 + 1 2 λ u ∑ i ∥ u i ∥ 2 + 1 2 λ v ∑ j ∥ v j − θ j ∥ 2 − ∑ j ∑ h l o g ( ∑ k θ i , k β k , w j , h ) \min \limits_ {\mathbf{U},\mathbf{V}} \frac{1}{2}\sum_{\left ( i,j \right )\in \mathbf{O}}c_{i,j} {\left \| r_{u,i}-u_{i} v^T_{j} \right \|^2} +\frac{1}{2}\lambda_u \sum_{i} \left \| u_{i} \right \|^2 + \frac{1}{2}\lambda_v \sum_{j}\left \| v_{j}- \theta_j \right \|^2 -\sum_{j}\sum_{h}log \left(\sum_{k} \theta_{i,k}\beta_{k,w_{j,h}} \right) U,Vmin21(i,j)∈O∑ci,j∥∥ru,i−uivjT∥∥2+21λui∑∥ui∥2+21λvj∑∥vj−θj∥2−j∑h∑log(k∑θi,kβk,wj,h)
+ 1 2 λ g ∑ i , f ∥ g i , f − u i s f T ∥ 2 + 1 2 λ s ∑ k ∥ s k ∥ 2 +\frac{1}{2}\lambda_g \sum_{i,f}\left \| g_{i,f}- u_{i}s_f^T \right \|^2 +\frac{1}{2}\lambda_s \sum_{k} \left \| s_{k} \right \|^2 +21λgi,f∑∥∥gi,f−uisfT∥∥2+21λsk∑∥sk∥2
其中, s k s_{k} sk 为用户的社交矩阵。
简单说明:
上一个模型上“丰富”了商品的特征向量,这个模型采用用户的社交信息来“丰富”用户的特征矩阵。
3) 与神经网络(CNN)结合
来源出处:
- Kim, Donghyun, et al. “Convolutional matrix factorization for document context-aware recommendation.” Proceedings of the 10th ACM Conference on Recommender Systems. 2016.
示意图:
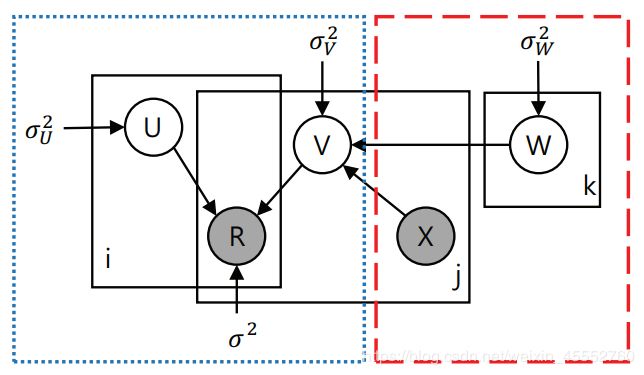
左侧为 PMF 模型,右侧为 CNN 构建。
目标函数:
min U , V 1 2 ∑ ( i , j ) ∈ O ∥ r u , i − u i v j T ∥ 2 + 1 2 λ u ∑ i ∥ u i ∥ 2 + 1 2 λ v ∑ j ∥ v j − c n n ( W , X j ) ∥ 2 + 1 2 λ k ∑ k ∥ w k ∥ 2 \min \limits_ {\mathbf{U},\mathbf{V}} \frac{1}{2}\sum_{\left ( i,j \right )\in \mathbf{O}} {\left \| r_{u,i}-u_i v^T_{j} \right \|^2} +\frac{1}{2}\lambda_u \sum_{i} \left \| u_{i} \right \|^2 + \frac{1}{2}\lambda_v \sum_{j}\left \| v_{j}-cnn\left( W,X_j\right) \right \|^2 +\frac{1}{2}\lambda_k \sum_{k} \left \| w_{k} \right \|^2 U,Vmin21(i,j)∈O∑∥∥ru,i−uivjT∥∥2+21λui∑∥ui∥2+21λvj∑∥vj−cnn(W,Xj)∥2+21λkk∑∥wk∥2
其中, X i X_i Xi 为商品 i i i 的文本评论, W W W 为 CNN 网络权重。
简单说明:
自从深度学习火了之后,很快就将深度学习的各种模型带入原来的 PMF 构架,来弥补 PMF 本身存在的不足。这里是是用 CNN 得到评论特征,丰富原来来自评分矩阵的特征向量。
声明
本博客所有内容仅供学习,不为商用,如有侵权,请联系博主谢谢。
参考文献
[1] Koren et al. Matrix factorization techniques for recommender systems.Computer 42.8 (2009).
[2] Koren Y. Factor in the neighbors: Scalable and accurate collaborative filtering[J]. ACM Transactions on Knowledge Discovery from Data (TKDD), 2010, 4(1).
[3] Koren et al. Collaborative filtering with temporal dynamics. Communications of the ACM 53.4 (2010): 89-97.
[4] Wang, Chong, and David M. Blei. “Collaborative topic modeling for recommending scientific articles.” Proceedings of the 17th ACM SIGKDD international conference on Knowledge discovery and data mining. 2011.
[5] Purushotham, Sanjay, Yan Liu, and C-C. Jay Kuo. “Collaborative topic regression with social matrix factorization for recommendation systems.” arXiv preprint arXiv:1206.4684 (2012).
[6] Kim, Donghyun, et al. “Convolutional matrix factorization for document context-aware recommendation.” Proceedings of the 10th ACM Conference on Recommender Systems. 2016.