概率统计学习笔记——1.随机事件与随机变量
概率统计学习笔记——1.随机事件与随机变量
注: 由于这都是《概率论与数理统计》一书中的知识,那么这里就不再过多重复阐述有关的概念定义了,我们整理一下其中重要的知识点。
一、随机事件
1.基本概念:
随机现象 、 样本空间 Ω \Omega Ω 、 样本点 ω \omega ω 、 随机事件 、必然事件( Ω \Omega Ω就是一个必然事件)、不可能事件
2.概率:
主要性质:
- 对于任一事件 A A A,均有 P ( A ‾ ) = 1 − P ( A ) P(\overline{A})=1-P(A) P(A)=1−P(A).
- 对于两个事件 A A A和 B B B,若 A ⊂ B A \subset B A⊂B,则有
P ( B − A ) = P ( B ) − P ( A ) , P ( B ) > P ( A ) P(B-A)=P(B)-P(A),P(B) >P(A) P(B−A)=P(B)−P(A),P(B)>P(A). - 对于任意两个事件 A A A和 B B B,有
P ( A ∪ B ) = P ( A ) + P ( B ) − P ( A ∩ B ) P(A \cup B) = P(A) + P(B) - P(A\cap B) P(A∪B)=P(A)+P(B)−P(A∩B).
3.等可能概型(古典概型)
古典概型概率公式:
若事件 A A A 包含个 m m m 个样本点,则事件 A A A 的概率定义为:
P ( A ) = m n = 事 件 A 包 含 的 基 本 事 件 数 基 本 事 件 总 数 P(A) = \frac{m} {n} = \frac{事件A包含的基本事件数} {基本事件总数} P(A)=nm=基本事件总数事件A包含的基本事件数。
概率论的历史上有一个颇为著名的问题生日问题:求 k 个同班同学没有两人生日相同的概率,就是一个古典概型。视一年365天,那么他们的生日各不同的概率为 365 ∗ 364 ∗ . . . ∗ ( 365 − k + 1 ) 36 5 k \frac{365*364*...*(365-k+1)}{365^k} 365k365∗364∗...∗(365−k+1),普遍性地写成公式:
P ( A ) = C l k ∗ k ! l k = l ! l k ∗ ( l − k ) ! P(A) = \frac {C^k_l*k!} {l^k} = \frac {l!} {l^k*(l-k)!} P(A)=lkClk∗k!=lk∗(l−k)!l!
编写一段简单Python来解决生日问题:
#只要稍加修改或者包装成一个函数就可以实现类似问题的求解
#我们采用函数的递归的方法计算阶乘:
def factorial(n):
if n == 0:
return 1;
else:
return (n*factorial(n-1))
l_fac = factorial(365); #l的阶乘
l_k_fac = factorial(365-40) #l-k的阶乘
l_k_exp = 365**40 #l的k次方
P_B = l_fac /(l_k_fac * l_k_exp) #P(B)
print("事件B的概率为:",P_B)
print("40个同学中至少两个人同一天过生日的概率是:",1 - P_B)4.条件概率
条件概率公式:
设 A A A 和 B B B 是两个事件,且 P ( B ) > 0 P(B)>0 P(B)>0,称
P ( A ∣ B ) = P ( A B ) P ( B ) P(A|B) = \frac {P(AB)} {P(B)} P(A∣B)=P(B)P(AB) 为在事件 B B B 发生的条件下,事件 A A A 发生的概率。
5.全概率公式和贝叶斯公式
-
重要的知识认知:
- 概率乘法公式:
P ( A B ) = P ( B ∣ A ) P ( A ) = P ( A ∣ B ) P ( B ) P(AB)=P(B|A)P(A) =P(A|B)P(B) P(AB)=P(B∣A)P(A)=P(A∣B)P(B) - 如果事件组,满足
- B 1 , B 2 , . . . B_1,B_2,... B1,B2,... 两两互斥,即 B i ∩ B j = ϕ , i ≠ j , i , j = 1 , 2 , . . . B_i\cap B_j = \phi,i \neq j ,i,j = 1,2,... Bi∩Bj=ϕ,i=j,i,j=1,2,...,且 P ( B i ) > 0 , i = 1 , 2 , . . . P(B_i)>0,i=1,2,... P(Bi)>0,i=1,2,...
- B 1 ∪ B 2 ∪ . . . = Ω B_1 \cup B_2 \cup ... = \Omega B1∪B2∪...=Ω
则称事件组 B 1 , B 2 , . . . B_1,B_2,... B1,B2,...是样本空间 Ω \Omega Ω 的一个划分。
- 概率乘法公式:
-
全概率公式:
设 B 1 , B 2 , . . . B_1,B_2,... B1,B2,...是样本空间 Ω \Omega Ω 的一个划分, A A A 为任一事件,则
P ( A ) = ∑ i = 1 ∞ P ( B i ) P ( A ∣ B i ) P(A) = \sum_{i=1}^{\infty } {P(B_i)}P(A|B_i) P(A)=∑i=1∞P(Bi)P(A∣Bi) 称为全概率公式。 -
贝叶斯公式
设 B 1 , B 2 , . . . B_1,B_2,... B1,B2,...是样本空间 Ω \Omega Ω 的一个划分,则对任一事件 A ( P ( A ) > 0 ) A(P(A)>0) A(P(A)>0) ,有
P ( B i ∣ A ) = P ( B i A ) P ( A ) = P ( A ∣ B i ) P ( B i ) ∑ j = 1 ∞ P ( B j ) P ( A ∣ B j ) , i = 1 , 2 , . . . P(B_i|A) =\frac {P(B_i A)} {P(A)} = \frac {P(A|B_i )P(B_i)} {\sum_{j=1}^{\infty }P( B_j)P(A|B_j)} ,i=1,2,... P(Bi∣A)=P(A)P(BiA)=∑j=1∞P(Bj)P(A∣Bj)P(A∣Bi)P(Bi),i=1,2,...
称上式为贝叶斯公式,称 P ( B i ) ( i = 1 , 2 , . . . ) P(B_i)(i=1,2,...) P(Bi)(i=1,2,...) 为先验概率, P ( B i ∣ A ) ( i = 1 , 2 , . . . ) P(B_i|A)(i=1,2,...) P(Bi∣A)(i=1,2,...)为后验概率。
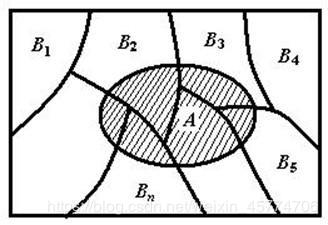
下面的图能很好的帮助理解贝叶斯公式含义~
二、随机变量
1.随机变量及其分布
- 随机变量的分布函数定义:
设 X X X 是一个随机变量,对任意的实数 x x x ,令
F ( x ) = P { X < = x } , x ∈ ( − ∞ , + ∞ ) F(x) = P \{ X<=x\} ,x \in (- \infty ,+ \infty) F(x)=P{X<=x},x∈(−∞,+∞)
则称 F ( x ) F(x) F(x) 为随机变量 x x x 的分布函数,也称为概率累积函数。
2. 离散型随机变量
如果随机变量 X X X 的全部可能取值只有有限多个或可列无穷多个,则称 X X X 为离散型随机变量。对于离散型随机变量 X X X 可能取值为 x k x_k xk的概率为:
P { X = x k } = p k , k = 1 , 2 , . . . P \{ X =x_k \} =p_k,k=1,2,... P{X=xk}=pk,k=1,2,...
则称上式为离散型随机变量 X X X 的分布律。当然分布律还可以用表格的方式表示。
离散型随机变量的分布函数为:
F ( x ) = P { X < = x } = ∑ x k < = x P { X = x k } = ∑ x k < = x P k F (x) = P \{ X<=x \} =\sum_{x_k <=x}{ P \{ X=x_k \} } = \sum_{x_k <=x}{ P_k} F(x)=P{X<=x}=xk<=x∑P{X=xk}=xk<=x∑Pk
3.常见的离散型分布
一.(0 - 1)分布
二.伯努利实验,二项分布:记作 B ( n , k ) B(n,k) B(n,k)
其分布律为:
P { X = k } = C n k p k ( 1 − p ) n − k , k = 0 , 1 , 2 , . . . n . P \{ X =k \} =C^k_np^k(1-p)^{n-k},k=0,1,2,...n. P{X=k}=Cnkpk(1−p)n−k,k=0,1,2,...n.
其分布函数为:
F ( x ) = ∑ k = [ x ] C n k p k ( 1 − p ) n − k , k = 0 , 1 , 2 , . . . n . F(x) = \sum_{k=}^{[x]} {C^k_np^k(1-p)^{n-k}},k=0,1,2,...n. F(x)=k=∑[x]Cnkpk(1−p)n−k,k=0,1,2,...n.
其中, [ x ] [x] [x] 表示下取整,即不超过 x x x 的最大整数。
4.随机变量的数字特征:
1.数学期望
-
离散型:设离散型随机变量 X X X 的分布律为 P { X = x i } = p i , i = 1 , 2 , . . . , P \{ X=x_i\} = p_i ,i =1,2,..., P{X=xi}=pi,i=1,2,..., 若级数 ∑ i ∣ x i ∣ p i \sum_{i} {|x_i|p_i} ∑i∣xi∣pi 收敛,(收敛指会聚于一点,向某一值靠近,相对于发散)。则称级数 ∑ i x i p i \sum_{i} {x_ip_i} ∑ixipi 的和为随机变量 X X X 的数学期望。记为 E ( X ) E(X) E(X) ,即:
E ( X ) = ∑ i x i p i E(X) = \sum_{i} {x_ip_i} E(X)=i∑xipi -
设连续型随机变量 X X X 的概率密度函数为 f ( x ) f(x) f(x) ,若积分 ∫ − ∞ + ∞ ∣ x ∣ f ( x ) d x \int_{- \infty}^{+ \infty}{|x|f(x)}dx ∫−∞+∞∣x∣f(x)dx 收敛, 称积分 ∫ − ∞ + ∞ x f ( x ) d x \int_{- \infty}^{+ \infty}{xf(x)}dx ∫−∞+∞xf(x)dx 的值为随机变量 X X X 的数学期望,记为 E ( X ) E(X) E(X) ,即:
E ( X ) = ∫ − ∞ + ∞ x f ( x ) d x E(X)= \int_{- \infty}^{+ \infty}{xf(x)}dx E(X)=∫−∞+∞xf(x)dx
E ( X ) E(X) E(X) 又称为均值 -
数学期望代表了随机变量取值的平均值,是一个重要的数字特征。数学期望具有如下性质:
- 若 c c c 是常数,则 E ( c ) = c E(c) =c E(c)=c ;
- E ( a X + b Y ) = a E ( X ) + b E ( Y ) E(aX+bY) = aE(X) +bE(Y) E(aX+bY)=aE(X)+bE(Y) , 其中a, b为任意常数;
- 若 X , Y X, Y X,Y 相互独立,则 E ( X Y ) = E ( X ) E ( Y ) E(XY) = E(X)E(Y) E(XY)=E(X)E(Y) ; (相互独立就是没有关系,不相互影响)。
2.方差
-
设 X X X 为随机变量,如果 E { [ X − E ( X ) ] 2 } E\{ [X-E(X)]^2\} E{[X−E(X)]2} 存在,则称 E { [ X − E ( X ) ] 2 } E\{ [X-E(X)]^2\} E{[X−E(X)]2} 为 X X X 的方差。记为 V a r ( X ) Var(X) Var(X) , 即:
V a r ( X ) = E { [ X − E ( X ) ] 2 } Var (X) =E\{ [X-E(X)]^2\} Var(X)=E{[X−E(X)]2}
并且称 V a r ( X ) \sqrt{Var(X)} Var(X) 为 X X X 的标准差或均方差。 -
方差是用来描述随机变量取值相对于均值的离散程度的一个量,也是非常重要的数字特征。方差有如下性质:
- 若 c c c 是常数,则 V a r ( c ) = 0 Var(c) =0 Var(c)=0 ;
- V a r ( a X + b ) = a 2 V a r ( X ) Var(aX+b) = a^2Var(X) Var(aX+b)=a2Var(X) , 其中a, b为任意常数;
- 若 X , Y X, Y X,Y 相互独立,则 V a r ( X + Y ) = V a r ( X ) + V a r ( Y ) Var(X+Y) = Var(X) +Var(Y) Var(X+Y)=Var(X)+Var(Y) 。
3.协方差和相关系数
-
协方差和相关系数都是描述随机变量 X X X 与随机变量 Y Y Y 之间的线性联系程度的数字量。
-
设 X , Y X, Y X,Y 为两个随机变量,称 E { [ X − E ( X ) ] [ Y − E ( Y ) ] } E\{ [X-E(X)] [Y-E(Y)]\} E{[X−E(X)][Y−E(Y)]} 为 X X X 和 Y Y Y 的协方差,记为 C o v ( X , Y ) Cov(X, Y) Cov(X,Y),即:
C o v ( X , Y ) = E { [ X − E ( X ) ] [ Y − E ( Y ) ] } Cov(X, Y) = E\{ [X-E(X)] [Y-E(Y)]\} Cov(X,Y)=E{[X−E(X)][Y−E(Y)]} -
协方差有如下性质:
-
C o v ( X , Y ) = C o v ( Y , X ) Cov(X, Y) = Cov(Y, X) Cov(X,Y)=Cov(Y,X)
-
C o v ( a X + b , c Y + d ) = a c C o v ( X , Y ) Cov(aX+b,cY+d) =ac Cov( X,Y) Cov(aX+b,cY+d)=acCov(X,Y) ,其中, a , b , c , d a,b,c,d a,b,c,d 为任意常数
-
C o v ( X 1 + X 2 , Y ) = C o v ( X 1 , Y ) + C o v ( X 2 , Y ) Cov(X_1+X_2,Y) =Cov( X_1,Y) +Cov( X_2,Y) Cov(X1+X2,Y)=Cov(X1,Y)+Cov(X2,Y)
-
C o v ( X , Y ) = E ( X , Y ) − E ( X ) E ( Y ) Cov(X,Y) =E( X,Y) -E( X)E(Y) Cov(X,Y)=E(X,Y)−E(X)E(Y) ; 当 X , Y X,Y X,Y 相互独立时,有 C o v ( X , Y ) = 0 Cov(X,Y) = 0 Cov(X,Y)=0
-
∣ C o v ( X , Y ) ∣ ≤ V a r ( X ) V a r ( Y ) |Cov(X,Y)| ≤ \sqrt {Var(X)} \sqrt {Var(Y)} ∣Cov(X,Y)∣≤Var(X)Var(Y) ;
-
C o v ( X , X ) = V a r ( X ) Cov(X,X) =Var( X) Cov(X,X)=Var(X)
-
-
当 V a r ( X ) > 0 , V a r ( Y ) > 0 \sqrt {Var(X)} >0 ,\sqrt {Var(Y)} >0 Var(X)>0,Var(Y)>0 时,称
ρ ( X , Y ) = C o v ( X , Y ) V a r ( X ) V a r ( Y ) \rho(X,Y) = \frac{Cov(X,Y)}{\sqrt {Var(X)} \sqrt {Var(Y)}} ρ(X,Y)=Var(X)Var(Y)Cov(X,Y)
为 X , Y X,Y X,Y 的相关系数,它是无纲量的量(也就是说没有单位,只是个代数值)。 -
基本上我们都会用相关系数来衡量两个变量之间的相关程度。相关系数在-1到1之间,小于零表示负相关,大于零表示正相关。绝对值 ∣ ρ ( X , Y ) ∣ |\rho(X,Y)| ∣ρ(X,Y)∣ 表示相关度的大小。越接近1,相关度越大。