Extending Knowledge Bases using images翻译
文章来源:

1. Abstract
Traditional knowledge base generation extracts structured knowledge from text.
传统的知识库从文本中提取结构化知识。
However, many other sources of information, such as images, audio, or time series, can be leveraged into this process to build richer and more complete knowledge bases.
然而,很多其他信息来源,比如图像,录音或者时间序列,可以被用在这个过程中,去建立更加完善的知识库。
In this paper, we show how images can be converted to a structured semantic representation of their content.
在这个论文中,我们展示了图像是怎样被转化成关于他们内容的结构化语义表述的。
We achieve this by designing a mutual embedding space for images and knowledge graphs.
为完成这个目标,我们设计了一个图像和知识图谱的相互嵌入空间。
From this mutual embedding space we can then obtain relationships between an image and known entities in a knowledge graph.
通过这个相互嵌入空间,我们可以获取图像和知识图谱中已知实体之间的关系。
Based on these obtained relationships, we show how labeled images can be used to add new concepts to the knowledge base.
基于这些获得的关系,我们展示了被标注的图像如何给知识库增加新的概念。
Furthermore, this mutual embedding helps visual recognition systems generalize better to unknown object classes.
此外,这种相互嵌入有助于视觉识别系统更好地推广到未知对象类。
One key finding of this paper is that the smoothness constraint we impose on the semantic embedding space has significant impact in multimodal tasks, while leaving the performance unchanged on unimodal tasks.
本文的一个关键结论是,我们对语义嵌入空间施加的平滑度约束,对多模态任务有显著的影响,而对单模态任务的性能没有影响。
vision
Tasks involving multiple modalities like texts and images often use joint-semantic embeddings.
涉及文本和图像等多种模式的任务通常使用联合语义嵌入。
However, our finding that these semantic spaces can be optimized for specific tasks suggests that a single semantic space cannot serve as the nexus between all modalities simultaneously.
然而,我们发现这些语义空间可以针对特定任务进行优化,这表明单个语义空间不能同时充当所有模式之间的连接。
We hypothesize that a knowledge graph provides for a more universal semantic representation.
我们假设知识图谱提供了一个更加普遍的语义表述。
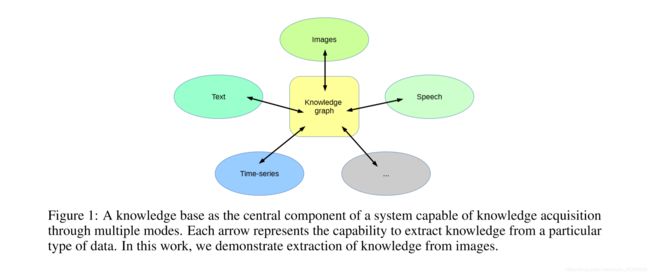
We envision an architecture where a knowledge graph forms the central component enabling perception through multiple modes (Figure 1).
我们设想一种架构,其中一个知识图形成了通过多种模式实现感知的中心组件。(图像1)
The knowledge base becomes the single representation of knowledge about the environment of the system.
知识库成为新系统环境知识的单一表示。
Each mode of perception would require bridging the gap between only that mode and the knowledge graph.
每一种感知模式都需要阔过知识图谱和这一模式之间的鸿沟。
The work presented in this paper fills the role of knowledge generation through images.
本文通过图像来完成知识生成的作用。
Because the unified representation takes the form of a graph, it can then be used in reasoning systems to
decide on an action.
因为graph 是统一的表示形式,它可以被用于推理系统中决定行动。
Furthermore, this approach is a step towards bridging the gap between statistical frameworks that learn from large amounts of data and reasoning-based frameworks that can infer newknowledge from a limited set of predicates.
此外,这种方法是缩小从大量数据中学习的统计框架与能够从有限的谓词集推断新知识的基于推理的框架之间差距的一个步骤。
Our finding that knowledge graphs can improve visual recognition (by enabling recognition of unknown classes), and that visual recognition can be used to extend knowledge graphs points to the potential of building a continuous learning system based on these two components.
我们发现,知识图可以提高视觉识别能力(通过识别未知类),并且视觉识别可以用来扩展知识图点,从而建立基于这两个组件的连续学习系统。
This is a step towards building more generally applicable human-like learning systems.
这是朝着建立更普遍适用的类人学习系统迈出的一步。
2 Related Work
The method proposed in this paper is situated at the crossroads of multiple domains, including semantic embedding, multi-relational knowledge bases, link prediction and zero-shot learning.
该方法位于多个领域的交叉点,包括语义嵌入、多关系知识库、链接预测和零次学习。
In this section, we position our work with respect to the most relevant approaches from these fields.
在本节中,我们将我们的工作定位于这些领域中最相关的方法。
semantic image embedding
A significant amount of work has been done to embed images into semantic vector spaces.
已有大量工作致力于将图像嵌入语义向量空间。
Deep visual-semantic embedding (DeViSE) (Frome et al., 2013) leverages images as well as unannotated text to provide a common representation.
深度视觉语义嵌入(Deep visual semantic embedding,devide)(Frome et al.,2013)利用图像和未标记文本提供共同的表示。
Our setup closely relates to Frome et al. (2013), as well as Socher et al. (2013b) where they make class label predictions about unknown classes.
我们的设置与Frome等人密切相关。(2013),以及Socher等人。(2013b)他们对未知类进行类标签预测。
In our setup, we focus on the prediction of semantic relationships, as opposed to class labels for new images.
在我们的设置中,我们关注语义关系的预测,而不是新图像的类标签。
To our knowledge, visual recognition using such a structured semantic space has not explicitly been explored.
据我们所知,使用这种结构化语义空间的视觉识别还没有得到明确的探索。
In Xie et al. (2016), knowledge representations are learned with both triples and images from a joint objective.
在 Xie et al.(2016),知识表示是从一个共同的目标中学习到的,既有三元组,也有图像。
However, they only consider knowledge generation for known entities, and do not add additional nodes to the knowledge base.
然而,他们只考虑了为已知实体产生的知识,没有为知识库增加新的节点。
A parallel thread for predicting zero-shot classes is to use their attribute signatures (Lampert et al., 2009; Shi et al., 2014; Huang et al., 2015).
另一种用来推测零次类的方法是使用他们的特征。
Although this has proven to be a successful approach, it requires explicit attribute labeling of the images and is therefore not suitable for knowledge base extension.
尽管已经被证明是一个很成功的方法,它需要图像明确的特征标签,所以对于知识库的扩展并不是很合适。
knowledge graph embedding
Finding practical representations for knowledge graphs has been the focus of an important body of work.
找到一个实用的知识图谱的表示形式是这个工作的焦点。
In the standard setting, the algorithm is presented with triples encoding existing edges in the graph.
在标准的设置中,该算法用图中存在的边的三元组编码表示。
Each triple (eh,r,et) links the head entity eh to the tail entity et through the relation r which holds true between them.
每一个三元组(eh,r,et),通过他们之间的关系r来链接头实体 eh,和尾实体et.
A major direction of research for knowledge representation are translation models which embed information into a low-dimensional vector space.
将信息嵌入到低维向量空间中的翻译模型是知识表示的一个主要研究方向。
TransE (Bordes et al., 2013) is one of the simplest, yet most effective, formulations of this type.
TransE (Bordes et al., 2013)是其中一个最简单,然而最有效的方法。
The problem of knowledge graph embedding has also been tackled via tensor factorization for link prediction(Nickeletal.,2011,2012), as well as latent factors models(Sutskeveretal.,2009;Jenatton et al., 2012) and semantic energy matching (Bordes et al., 2012, 2014).
知识图嵌入问题也通过链接预测的张量因子分解(Nickeletal.,20112012)以及潜在因素模型(Sutskeveretal.,2009;Jenatton et al.,2012)和语义能量匹配(Bordes et al.,2012,2014)来解决。
In this work, we build on the neural tensor layer (NTL) (Socher et al., 2013a) which considers multiplicative mixing of entity vectors in addition to linear mixing.
在这项工作中,我们建立在神经张量层(NTL)(SOHER等人,2013A),考虑除了线性混合之外的实体矢量的乘性混合。
We improve on this model by proposing a new objective function that enforces local smoothness on the scoring function.
在该模型的基础上,我们提出了一个新的目标函数,该目标函数对评分函数进行局部光滑化。
visual knowledge creation
The paradigm of never ending learning of Carlson et al. (2010) has been applied to the task of knowledge extraction from images (Chen et al., 2013).
卡尔森等人的永无止境的学习范式(2010)已应用于从图像中提取知识的任务(Chen等人,2013)。
This was achieved by modeling correlation between occurrences of detected objects in images.
这是通过图像中检测到的对象之间的相关性建模来实现的。
Vedantam et al. (2015) studied how common sense knowledge could be extracted from generated clip-art.
Vedantam等人(2015)学习了常识知识是怎样从剪切画中提取出来的。
Our work generalizes this and treats images and knowledge on equal footing.
我们的工作概括了这些并且同等对待图像和知识。
This enables us to extract knowledge directly from images without explicitly modeling correlations.
这让我们能够直接从图像中提取知识,而不需要显式的建模相关性。
Furthermore the knowledge we are able to extract contains relationships between images and concepts without images.
另外,我们能够提取的知识包含图像和没有图像的概念之间的关系。
3. Knowledge Graph Embedding for Visual Recognition
Our purpose is to find a semantic vector space in which entities from a knowledge graph and images can have a unified representation. We arrive at this common space using a two-step approach.
我们的目的式找到一个语义空间,这个语义空间可以让知识图谱和图像有一个统一的表示形式。我们通过一个两步的方法来实现。
First, a representation for the entities is learned using a knowledge-graph. Subsequently, a mapping from images to vectors in that same space is learned. This combination enables link-prediction for images (Figure 2).
首先,使用知识图学习实体的表示。随后,学习从图像到同一空间中的向量的映射。这种组合可以对图像进行链接预测(图2)。


用G表示知识图谱,T表示三元组,E为所有实体,R为实体间的关系。
包含在G中的三元组关系为true,而不在G中的为false。
D为带标签的图像,I为图像集合。
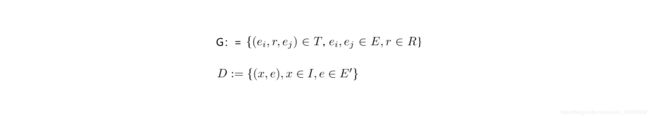
T的子集T’为已知的三元组,其包含E的子集E’ 和关系R。链接预测的目的是找到T\T’。在一般的任务中,T’ 和T\T’ 包含的实体(E’) 相同;但本文模型还能够预测未知实体(E\E’) 之间的关系。
该模型通过两个嵌入来实现。分别把图像和实体嵌入到相同的向量空间中。

所以本模型的任务就是找到 g 和 h 这两个对应关系。
(1) knowledge graph embedding
A. 神经网络搭建:
设打分函数f ,给(eh,r,et) 打分。正确分低,错误分高。

对于三元组得分,有不同的计算方法,该模型采用神经张量层(NTL)中使用的双线性模型(Bilinear Model)(Reasoning With Neural Tensor Networks for Knowledge Base Completion)
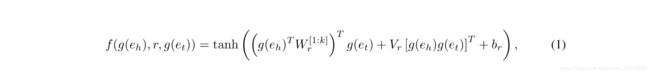
- g(eh)表示eh嵌入的向量空间
- f函数给一个三元组关系打分
Reasoning with Neural Tensor Networks for Knowledge Base Completion中模型:

- e1,e2为实体的特征向量(相当于上篇论文中的g(e1))
- 括号中第一项中W是和关系R有关的张量
- VR是第一层的权重
- U为第二层的权重
- bR为偏置
- f =tanh 为隐藏层激活函数
其主要优点是,它可以将两个输入以乘法形式关联起来,而不是仅通过标准神经网络的非线性隐式关联
Bilinear Model
模型通过一个关系特定的双线性形式来完成弱向量交互作用的问题。
它以一种简单有效的方式将两个实体向量的交互结合在一起。然而,该模型在表达能力和参数个数方面受到了词向量的限制。双线性形式只能模拟线性相互作用,不能得到更复杂的评分函数。该模型是NTNs的一个特例,VR=0,bR=0,k=1,f=identity。与双线性模型相比,神经张量具有更高的表达能力,特别是对于较大的数据库。对于较小的数据集,slice的数量可以减少,甚至在关系之间变化。
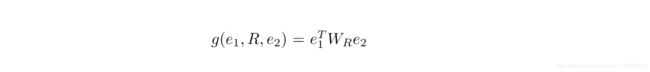
B. 损失函数
使用hinge loss 函数:
![]()
为使评分函数平滑变化,增加噪声项
![]()
(2) image embedding
使用卷积神经网络对图像嵌入h:I→V进行建模(Fukushima,1980)。
为了将图像嵌入先前获得的表示空间,使用最小二乘目标映射图像到其对应的实体上
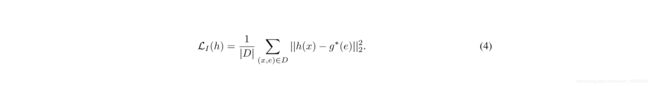
- 使用(x,e)表示带标签的图像,其中标记e∈E是知识图中的实体类型。
- g*为通过最小化等式3中的目标而得到的嵌入g的学习实体。
知识图谱的输出示例,top3的上位关系和top3的部分关系
(hypemym/hyponmym 上/下位关系 meronym 部分关系)
为了预测图像的知识图链接,我们首先计算h(x),x∈I。一旦映射到相互嵌入空间,图像v的表示就可以用来计算打分函数f,并根据其值预测真三元组。因此,可以单独使用image embedding来确定每个特定图像的属性(图2)。
此外,通过对同一对象类的图像嵌入向量集进行平均,可以推断出特定对象或概念的更一般的属性。
对于本文研究的任务,我们将使用后一种方法,以便根据某个新实体的图像实例来确定其表示和属性。这里,我们考虑这样的情况:系统可以访问属于同一类的图像集。
然而,在关于未知概念的未标记图像的真实数据集上,我们的算法将会结合自然扩展的算法,以确定两个图像是否描述相同概念(Learning Fine-grained Image Similarity with Deep Ranking,2014)。
4. Experiment
Dataset
创建一个新的数据集,其中的头和尾实体都是名词,而且只包含如下关系: hypernym, hyponym, part meronym, part holonym, member meronym, member holonym. 这个过程可以产生1000000个三元组关系,所以叫做Wordnet 1 million(WN1M)
这些三元组被分为三个互不交叉的组:
1)训练组:一个关于实体e(e属于E’)的1百万个三元组。
2)测试组:基于与训练组相同实体e的2万个三元组
3)硬测试组:包含从集合1和2中选出的50个实体相关联的三元组,并且有可用的图像。
为了训练图像嵌入,使用 ILSVRC-2012 数据集((Russakovsky et al., 2015)
分为四组:
1)包含750个类的图像的训练集
2)具有来自相同750个类的不同图像的验证集(VAL)
3)包含200个图像类的零次测试集(ZS),这些图像类在图像模型训练期没有,但存在于知识图谱中
4) 一个由50个类组成的open world 测试集(OW),这些类是从图像嵌入训练中漏掉的,对应于从知识图嵌入训练中漏掉的50个实体。
前几个分类的类别都是随机抽取的并且为所有的实验固定
遵循Xian等人的协议(2017年),我们还评估了1K个ImageNet最密集类的方法,这些类不是ILSVRC-2012的一部分。这些1K实体出现在知识图谱中,因此该集合属于ZS类别。
knowledge embedding
我们训练了两个知识图嵌入函数,一个基于原始NTL架构(Socher等人,2013a),另一个基于我们的自适应平滑NTL方法(SNTL,等式3)。对于这两种嵌入算法,我们选择嵌入空间的维数d=60,其中k=6层。通过将尾部实体替换为随机实体,为每个真正的三元组生成损坏的三元组。高斯噪声参数设置为s=0.1,略大于从图像嵌入模型(方程式4)在每个维度中获得的误差。
image embedding
对于图像模型,我们使用VGG16架构(Simonyan和Zisserman,2015)。按照Frome等人的方法。(2013),我们使用卷积滤波器权重,这些权重是为分类任务预先训练的。最后一层的单元数等于知识图嵌入的维数。输出被规范化为具有单元L2范数。我们训练了两个独立的图像嵌入模型,一个以NTL实体向量为目标,称之为图像NLT(INTL),另一个以光滑SNTL实体向量为目标(SINTL)。