java的集合学习
笔记来源毕向东视频
- 1.集合类的由来
- 2.集合的特点
- 3.集合框架图
- 4.Collection的共性方法
- 5.迭代器的使用
- 6.有序重复同步问题
- 7.List
- 7.1特有常见方法
- 7.2list取出元素方法
- 7.3ListIterator介绍
- 8.LinkedList
- 9.ArrayList
- 10.哈希表确定元素是否相同
- 11.集合框架Collection练习
- 11.1定义功能去除ArrayList中的重复元素
- 12.TreeSet中的比较
- 12.1 方法一 实现 Comparable 接口
- 12.2 方法二 构造一个比较器 Comparator
- 12.3比较的原理——二叉树
- 12.4TreeSet集合练习-字符串长度排序
- 13.Map 集合
- 13.1.Map 遍历
- *集合使用选择技巧
- **泛型
1.集合类的由来
对象封装特有数据,对象多了,需要存储,如果对象的个数不确定就用集合容器进行存储。
2.集合的特点
用于存储对象的容器。
集合的长度是可以改变的。
集合中不可以存储基本数据类型值。
3.集合框架图
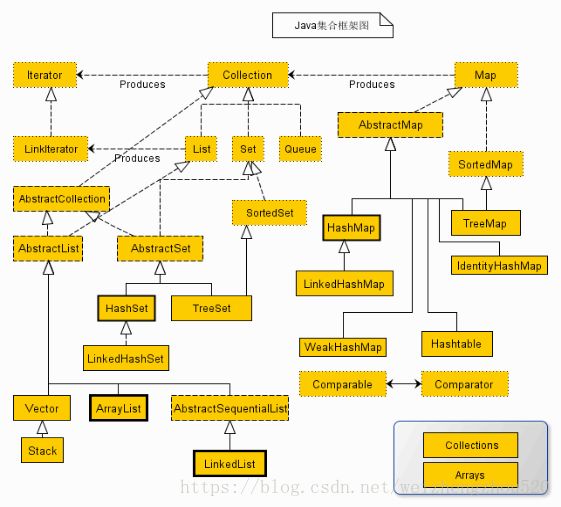
4.Collection的共性方法
| 说明 | 共性方法 |
|---|---|
| 添加 | boolean add(Object obj)boolean addAll(Collection c) |
| 删除 | boolean remove(Object obj)boolean removeAll(Collection coll)void clear() |
| 判断集合存在 | boolean contains(object obj)boolean containsAll(Collection coll) |
| 判断非空 | boolean isEmpty() |
| 获取个数 | int size() |
| 取出元素 | Iterator iterator()迭代器 |
| 取交集 | boolean retainAll(Collection coll) |
| 集合转数组 | Object toArray() |
5.迭代器的使用
public static void main(){
//使用Collection 中的iterator()方法
Collection coll = new ArrayList();
//Iterator it = coll.iterator();
//while(it.hasNext(){System.out.println(it.next());}//it浪费内存,改成for
for(Iterator it = coll.iterator(); it.hasNext(); ){
System.out.println(it.next());
}
}6.有序重复同步问题
Collection:
|--List: 存取有序 可重复 有索引
|--Vector: 可增长的对象数组 同步 效率低 增长100%空间浪费 查询增删都慢
|--ArrayList: 可增长的对象数组 不同步 效率高,替代了Vector。增长50%空间浪费 查询快
|--LinkedList: 内部是链表数据结构 不同步 增删快
|--set: 不可重复 不同步 set接口中的方法和Collection一致
|--HashSet 内部数据结构是哈希表 无序 不同步
|--LinkedHashSet 存取有序
|--TreeSet 有字典排序
Map 无序
|--Hashtable:内部结构 哈希表 同步 不支持空键空值
|--Properties:用来存储键值对型的配置文件的信息。可以IO技术相结合。
|--HashMap:内部结构 哈希表 不同步 支持空键空值
|--LinkedHashMap 存取有序
|--TreeMap:内部结构二叉树 不同步
7.List
7.1特有常见方法
【特有】可以操作角标
| 说明 | 特性方法 |
|---|---|
| 添加 插入 |
void add(index,element)void add(index,Collection) |
| 删除 | Object remove(index) |
| 修改 | Object set(index,element ) |
| 获取 查询 |
Object get(index)int indexOf(object)int lastIndexOf(object)List subList(from,to)包含form不包含to |
| 遍历 | ListIterator listIterator() listIterator(int index) |
7.2list取出元素方法
1.通过迭代器取出
2.使用get()
for(int x = 0; x < list.size(); x++){
System.out.println(list.get(x));
}7.3ListIterator介绍
ListIterator是Iterator的子接口,因为iterator接口中只有,hasNext() next() remove()三个方法,所以并不能完成在集合操作中,继续操作iterator,否则会出现ConcurrentModificationException异常。
使用方法:
可以实现在迭代中完成对元素的增删改查,只有list有这个
ListIterator it = list.listIterator();//获取列表迭代器对象
white(it.hasNext()){
Object obj = it.next();
if(obj.equals("abc2")){
it.add("abc9");
//it.set("abc9");
}
}
System.out.println("list:" + list);
/**************************
结果:
list:[abc1,abc2,abc9,abc3]
**************************/附录ListIterator主要方法
| 说明 | 特性方法 |
|---|---|
| 添加 | void add(E e) |
| 判断 | boolean hasNext()boolean hasPrevious() |
| 获取 | Object next()Object previous()int nextIndex()int previousIndex() |
| 替换 | void set(E e) |
| 删除 | void remove() |
8.LinkedList
| 说明 | 特性方法 |
|---|---|
| 添加 | void addFirst()void addLast()jdk1.6后 offerFirst()offerLast() |
| 获取 | E removeFirst() 获取删除头,如果链表为空,抛出NoSuchElementException E removeLast() 获取删除尾jdk1.6后 E pollFirst(),如果链表为空,抛出NullE pollLast()E getFirst() 获取不删除头,如果链表为空,抛出NoSuchElementExceptionE getLast() 获取不删除尾jdk1.6之后 E peekFirst() 获取不删除头,如果链表为空,抛出NullE peekLast() |
9.ArrayList
引用类型的集合
ArrayList a1 = new ArrayList();
a1.add(new Person("lisi1",21));
a1.add(new Person("lisi2",22));
Iterator it = a1.iterator();
while(it.hasNext()){
Person p = (Person) it.next();
System.out.println(p.getName()+"--"+p.getAge());
}
/************
结果:
lisi1--21
lisi2--22
*************/
10.哈希表确定元素是否相同
1.判断的是两个元素的哈希值是否相同。如果如果相同,再判断两个对象的内容是否相同。
2.判断哈希值相同,其实就是对象的hashCode方法。判断内容用的是equals
注意:如果哈希值不同,是不需要判断内容的。
11.集合框架Collection练习
11.1定义功能去除ArrayList中的重复元素
public class Main {
public static void main(String[] args) {
ArrayList a1 = new ArrayList();
a1.add("acb1");
a1.add("acb2");
a1.add("acb1");
System.out.println(a1);
a1 = getSingleElement(a1);
System.out.println(a1);
}
private static ArrayList getSingleElement(ArrayList a1) {
//1.定义一个临时容器
ArrayList temp = new ArrayList();
//2.迭代a1集合
Iterator it = a1.iterator();
while (it.hasNext()) {
Object obj = it.next();
//3.判断被迭代到的元素是否在临时容器中
if (!temp.contains(obj)) {
temp.add(obj);
}
}
return temp;
}
/**********
结果:
[acb1, acb2, acb1]
[acb1, acb2]
*********/
注意: 对于ArrayList来说,去重复自定义对象时,自定义的对象需要和 equals 方法,因为 contains 方法依据的还是equals方法
12.TreeSet中的比较
TreeSet判断元素唯一的方法就是根据返回值是否是0,是0,就是元素相同,不存。
12.1 方法一 实现 Comparable 接口
此接口强行对实现它的每个类的对象进行整体排序。这种排序称为类的自然排序,
类的compareTo方法称为他的自然比较法。
Person implements Comparable{
...
@Override
public int compareTo(Person p){
/*以Person对象的年龄从小到大的顺序排*/
/*年龄相同,以字典顺序比较姓名*/
int temp = this.age-p.age;
return temp == 0 ? this.name.compareTo(p.name) : temp;
}
}
12.2 方法二 构造一个比较器 Comparator
如果不要按照对象中具备的自然顺序进行排序。如果对象中不具备自然顺序。
比较器 Comparator 强行对某个对象collection进行整体排序。
方法:
int compare(T o1,T o2)
boolean equals(Object obj)
public class ComparatorByName implements Comparator<Person> {
@Override
public int compare(Person p1, Person p2) {
int temp = p1.getName().compareTo(p2.getName());
return temp == 0 ? p1.getAge() - p2.getAge() : temp;
}
}使用:
TreeSet ts = new TreeSet(new ComparatorByName());12.3比较的原理——二叉树
12.4TreeSet集合练习-字符串长度排序
public class ComparatorByLength implements Comparator {
@Override
public int compare(Object o1, Object o2) {
String s1 = (String) o1;
String s2 = (String) o2;
int temp = s1.length() - s2.length();
return temp == 0 ? s1.compareTo(s2) : temp;
}
}
13.Map集合
Map与Collection区别?
Map一次添加一对数据,Collection一次添加一个元素
Map的Key不能重复,Value可以重复
常见方法:
| 说明 | 共性方法 |
|---|---|
| 添加 | V put(K,V) 返回前一个和key关联的值,如果没有则返回null。存相同键,值会覆盖 |
| 删除 | void clear() 清空集合 V remove(Object K) 根据指定的key删除值 |
| 判断存在 | boolean containsKey(key)boolean containsValue(value) |
| 判断是否有键值对 | boolean isEmpty() |
| 获取 | V get(key) 通过键拿值 如果无该key,则返回null。当然可以通过返回null,来判断是否包含指定键。 int size() 获取键值对的个数Collection values() 获取集合中所有的值不要键 |
| 键集 | Set keySet() 返回此映射中所有包含的键的 Set 视图Set entrySet() 用于遍历 |
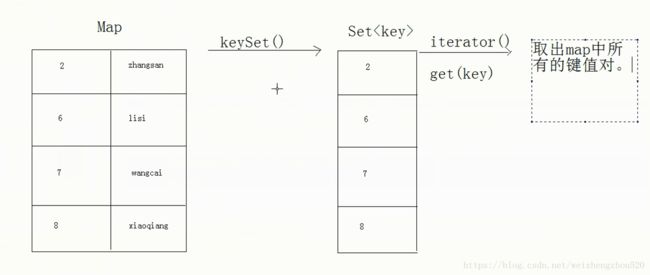
13.1.Map 遍历
方法一:KeySet() 将键作为对象存储在set中
public static void main(String[] args) {
HashMap map = new HashMap();
method(map);
}
public static void method(Map map) {
map.put(1, "abc1");
map.put(2, "abc2");
map.put(5, "abc5");
map.put(7, "abc7");
Set keySet = map.keySet();
Iterator it = keySet.iterator();
while (it.hasNext()) {
Integer key = it.next();
String value = map.get(key);
System.out.println(key+":::"+value);
}
}
/***********
1:::abc1
2:::abc2
5:::abc5
7:::abc7
***********/ 
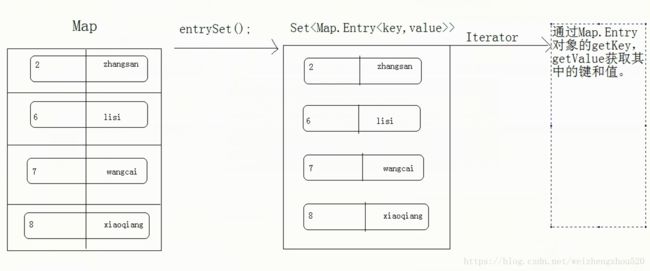
方法二:entrySet() 该方法将键和值的映射关系作为对象,存储到了Set集合中,而这个映射关系类型就是Map.Entry类型
public static void main(String[] args) {
HashMap map = new HashMap();
method(map);
}
public static void method(Map map) {
map.put(1, "abc1");
map.put(2, "abc2");
map.put(5, "abc5");
map.put(7, "abc7");
Set> entrySet = map.entrySet();
Iterator> it = entrySet.iterator();
while (it.hasNext()) {
Map.Entry next = it.next();
Integer key = next.getKey();
String value = next.getValue();
System.out.println(key+":::"+value);
}
}
/***********
1:::abc1
2:::abc2
5:::abc5
7:::abc7
***********/ 
*集合使用选择技巧
集合需要唯一吗?
需要:Set
需要制定顺序吗?
需要:TreeSet
不需要:HashSet
想要一个和存储一致顺序:LinkedHashSet
不需要:List
需要频繁增删吗?
需要:LinkedList
不需要:ArrayList
如何记录每一个容器的结构和所属体系呢?
看名字!
List
|--ArrayList
|--LinkedList
Set
|--HashSet
|--TreeSet
看到array 就要想到数组,就要想到查询快,有角标。
看到link 就要想到链表,就要想到增删快,就要想到 add get remove first last的方法
看到hash 就要想到哈希表,就要想到唯一性,就要想到元素需要覆盖hashcode方法和equals方法。
看到tree 就要想到二叉树,就要想到要排序,就要想到两个接口`Comparable` `Comparator`
而且通常这些常见的集合容器是不同步的。
**泛型
1.jdk1.5后出现的安全机制。
2.将运行时期的问题ClassCastException 转到了编译时期。
3.避免了强制转换的麻烦。
<>:什么时候用?当操作的引用数据类型不确定的时候,就用<>.
4.泛型技术是给编译器使用的技术,用于编译时期,确保了类型的安全。运行时,会去泛型,生成的class文件中是不带泛型的,这个称为泛型的擦除。为什么擦除?为了兼容运行的类加载器。
5.泛型的补偿:在运行时,通过获取元素的类型进行转换动作。不必强制转换类型。