声明:
本文转自我的个人博客,有兴趣的可以查看原文。
转发请注明来源。
最近工作开始接触Spark,本系列博客可以作为学习思考的纪录。
如果无特殊说明,均针对Spark 2.2 。
1. Spark 介绍
1.1 Spark 是什么
Apache Spark is a fast and general engine for large-scale data processing.
Spark 官网将Spark 定义为一个大型可扩展数据的快速和通用处理引擎。
首先,Spark 采用了先进的DAG执行引擎,支持循环数据流和内存计算,使得 Spark 速度更快,在内存中的速度是Hadoop MR的百倍,在磁盘上的速度是Hadoop MR的十倍(官网数据) 。
其次,Spark 是一个通用的处理引擎。Spark 被设计用来做批处理、迭代运算、交互式查询、流处理、机器学习等。
另外,Spark 易用,可以用Scala、Java、Python、R等快速开发分布式应用,Spark 提供了大量的高级API,方便开发(对比MapReduce...)。
最后,Spark 集成了多种数据源,并且可以通过Yarn、Mesos、Standalone(Spark 提供的部署方式)等各种模式运行。
1.2 为什么需要Spark
在Spark 之前,我们已经有了Hadoop,Hadoop 作为大数据时代企业首选技术,方兴未艾,我们为什么还需要Spark 呢?
我的理解是,Hadoop 对某些工作并不是最优的选择:
- 中间输出到磁盘,会产生较高的延迟。
- 缺少对迭代运算的支持。
总的来说,Hadoop 设计得比较适合处理离线数据,在实时查询、迭代计算方面存在不足,而业界对实时查询和迭代计算有着越来越多的需求。Spark 的出现正好能解决这些问题,快速、易用、通用,而且对有效支持Hadoop。
1.3 Spark 核心生态圈与重要扩展
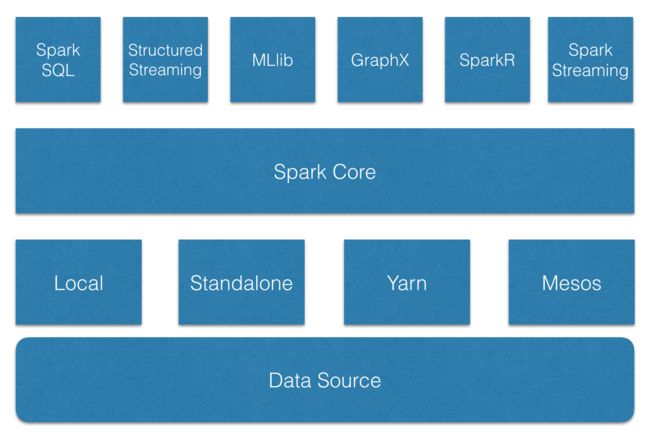
上图是一个比较常见的以 Spark 为核心的大数据处理框架。
其中,Spark Core 提供了 Spark 中的任务调度、内存管理、错误恢复、与存储系统交互等基本功能,而且,Spark Core 定义了RDDs(resilient distributed datasets,弹性分布式数据集,是Spark 的核心抽象)和操作RDDs的各种APIs。
基于Spark Core,提供六大核心扩展。Spark SQL 提供交互式SQL查询功能;Spark 2.0 引入了 Structured Streaming,Structured Streaming 是建立在Spark SQL 之上的可扩展、高容错的流处理引擎;MLlib 提供机器学习;GraphX提供图计算服务;Spark Streaming 基于 Spark 核心 API 提供可扩展、高吞吐量、高容错的实时流处理;SparkR 是Spark的一个R开发包。这些核心扩展,除了Structured Streaming,都基于Spark 核心API处理问题,方法几乎是通用的,处理的数据可共享,大大提高了数据集成的灵活性。
Spark 可扩展至大量节点,为实现这个目的并最大程度的保证灵活性,Spark 支持多种资源管理器(cluster manageers),包括 Yarn、Mesos 以及 Spark 提供的Standalone,另外,local模式主要用于开发测试。
最后,Spark 可支持多种数据集,包括本地文件系统、HDFS、Hbase、Cassandra等。
可见,Spark 提供了一站式数据处理能力,这是大数据时代相对很多专用引擎来说所不具备的。
2. Spark核心概念
2.1 基本抽象
Spark 基于两个抽象,分别是RDDs和Shared Variables。
2.1.1 RDDs
Spark 提出了一种分布式的数据抽象,称为 RDDs(resilient distributed datasets,弹性分布式数据集),是一个可并行处理且支持容错的数据集,同时,也是一个受限的数据集,RDDs是一个只读的、记录分区的数据集,仅支持transformation和action两种操作,这些受限,使得RDDs可以以较小的成本实现高容错性、可靠性。
RDDs有两种创建方式,一种是从外部数据源创建,另一种是从其它RDDs transform而来。transformation 是对RDDs进行确定性的操作,输入是RDDs,输出RDDs。action 是向应用程序返回值或者将结果写到外部存储。
最后,transformation具有 LAZY 的特点,当在RDDs上进行一次transformation时,并不会立即执行,只会在进行action时,前面的transformation才会真正执行。这个特点,被 Spark 用来优化整个工作链路,可以有效减少网络沟通、传输时间(大数据处理过程中,网络传输可以说是最大的性能杀手),从而大幅提高运行速度。
举个例子,我们具有如下代码:
lines = spark.textFile("hdfs://...")
errors = lines.filter(_.startsWith("ERROR"))
errors.cache()
errors.count()
第一行,读取外部数据源,生成一个RDDs;第二行,在RDDs lines上做了一次transformation运算 filter,取出以"ERROR" 开头的所有行,得到一个新的RDDs errors;第三行,缓存RDDs;第四行,在errors 上执行action,得到errors的行数。在整个过程中,只有在执行count()时,才会真正开始读取数据、过滤、缓存、计算行数。
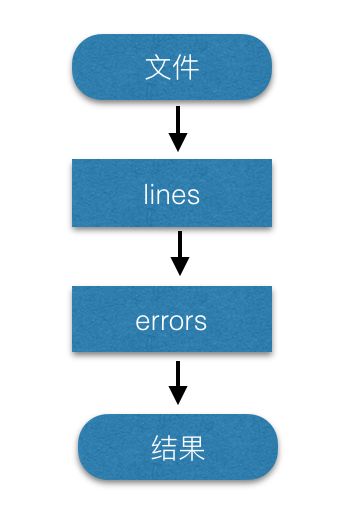
如上图所示,展示了整个过程,称为lineage,根据lineage,可以从具体的物理数据,计算出相应的结果。在Spark中,实现容错就是根据 lineage,当某个分区失败后,重新进行一次计算即可,而不是采用检查点、回滚等代价高昂的方式。同时,lineage 是Spark用来优化计算流程的依据。
最后,Spark 支持RDD persist/cache。当第一次执行action时,会将调用 persist() 或cache()的RDD缓存下来,在下次进行action操作时,直接使用缓存数据,这使得后边的action操作速度更快,在迭代运算或交互运算中,缓存使用较多。
2.1.2 Shared variables
在Spark中,具体的运算都在集群的节点上进行,这些运算操作的是从driver program 拷贝的变量的副本,且不会更新driver program上的变量,而要实现多任务共享的可读写变量会非常低效,Spark在这方面仅支持受限的共享变量。
Broadcast variables
广播变量是支持每台机器持有而不是每个task持有的只读变量,比如,给每台机器分发大型的输入数据集就会变得更加高效,同时,Spark 采用了高效的分发算法来实现广播变量的分发。
Accumulators
累加器是只被相关变量累加的变量,可以用于计数(sum)。在Spark中,原生支持数值类型的累加器,并且可以自己实现对其他类型的累加器。
3. 总结
本文主要简单介绍Spark的基础,包括Spark的基本介绍与Spark的核心概念。在下一篇,介绍如何搭建Spark项目。
4. 参阅
Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing
官方文档
Learning Spark
Spark核心技术与高级应用