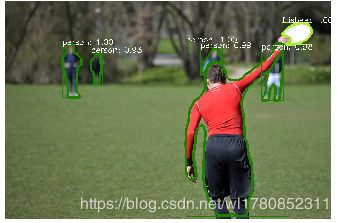
计算机视觉:maskrcnn_benchmark代码平铺
在jupyter notebook上运行:
#!/usr/bin/env python
# coding: utf-8
# In[1]:
#导包
import torch.distributed as dist
from torch.autograd import Function
from torch.autograd.function import once_differentiable
from torch.nn.modules.utils import _pair
import pickle
import sys
import imp
import logging
import os
from torchvision.transforms import functional as F
import cv2
import numpy as np
import math
import torch
from torch import nn
from torch.nn.modules.utils import _ntuple
import matplotlib.pyplot as plt
import matplotlib.pylab as pylab
from torchvision import transforms as T
from torch.nn import functional as FU
import torch.nn.functional as FUC
from maskrcnn_benchmark.config import cfg
from maskrcnn_benchmark.modeling.roi_heads.box_head.roi_box_feature_extractors import ResNet50Conv5ROIFeatureExtractor #(看不懂)
from maskrcnn_benchmark.modeling import registry
from maskrcnn_benchmark.layers import nms as _box_nms
from collections import OrderedDict
from apex import amp
from maskrcnn_benchmark import _C
from maskrcnn_benchmark import layers
# In[2]:
config_file="../configs/caffe2/e2e_mask_rcnn_R_50_FPN_1x_caffe2.yaml" #配置文件
cfg.merge_from_file(config_file)
# In[3]:
def _register_generic(module_dict, module_name, module):
assert module_name not in module_dict
module_dict[module_name] = module
class Registry(dict):
'''
A helper class for managing registering modules, it extends a dictionary
and provides a register functions.
Eg. creeting a registry:
some_registry = Registry({"default": default_module})
There're two ways of registering new modules:
1): normal way is just calling register function:
def foo():
...
some_registry.register("foo_module", foo)
2): used as decorator when declaring the module:
@some_registry.register("foo_module")
@some_registry.register("foo_modeul_nickname")
def foo():
...
Access of module is just like using a dictionary, eg:
f = some_registry["foo_modeul"]
'''
def __init__(self, *args, **kwargs):
super(Registry, self).__init__(*args, **kwargs)
def register(self, module_name, module=None):
# used as function call
if module is not None:
_register_generic(self, module_name, module)
return
# used as decorator
def register_fn(fn):
_register_generic(self, module_name, fn)
return fn
return register_fn
# In[4]:
def get_rank():
if not dist.is_available():
return 0
if not dist.is_initialized():
return 0
return dist.get_rank()
def is_main_process():
return get_rank() == 0
# In[5]:
FLIP_LEFT_RIGHT = 0
FLIP_TOP_BOTTOM = 1
class BoxList(object):
"""
This class represents a set of bounding boxes.
The bounding boxes are represented as a Nx4 Tensor.
In order to uniquely determine the bounding boxes with respect
to an image, we also store the corresponding image dimensions.
They can contain extra information that is specific to each bounding box, such as
labels.
"""
def __init__(self, bbox, image_size, mode="xyxy"):
device = bbox.device if isinstance(bbox, torch.Tensor) else torch.device("cpu")
bbox = torch.as_tensor(bbox, dtype=torch.float32, device=device)
if bbox.ndimension() != 2:
raise ValueError(
"bbox should have 2 dimensions, got {}".format(bbox.ndimension())
)
if bbox.size(-1) != 4:
raise ValueError(
"last dimension of bbox should have a "
"size of 4, got {}".format(bbox.size(-1))
)
if mode not in ("xyxy", "xywh"):
raise ValueError("mode should be 'xyxy' or 'xywh'")
self.bbox = bbox
self.size = image_size # (image_width, image_height)
self.mode = mode
self.extra_fields = {}
def add_field(self, field, field_data):
self.extra_fields[field] = field_data
def get_field(self, field):
return self.extra_fields[field]
def has_field(self, field):
return field in self.extra_fields
def fields(self):
return list(self.extra_fields.keys())
def _copy_extra_fields(self, bbox):
for k, v in bbox.extra_fields.items():
self.extra_fields[k] = v
def convert(self, mode):
if mode not in ("xyxy", "xywh"):
raise ValueError("mode should be 'xyxy' or 'xywh'")
if mode == self.mode:
return self
# we only have two modes, so don't need to check
# self.mode
xmin, ymin, xmax, ymax = self._split_into_xyxy()
if mode == "xyxy":
bbox = torch.cat((xmin, ymin, xmax, ymax), dim=-1)
bbox = BoxList(bbox, self.size, mode=mode)
else:
TO_REMOVE = 1
bbox = torch.cat(
(xmin, ymin, xmax - xmin + TO_REMOVE, ymax - ymin + TO_REMOVE), dim=-1
)
bbox = BoxList(bbox, self.size, mode=mode)
bbox._copy_extra_fields(self)
return bbox
def _split_into_xyxy(self):
if self.mode == "xyxy":
xmin, ymin, xmax, ymax = self.bbox.split(1, dim=-1)
return xmin, ymin, xmax, ymax
elif self.mode == "xywh":
TO_REMOVE = 1
xmin, ymin, w, h = self.bbox.split(1, dim=-1)
return (
xmin,
ymin,
xmin + (w - TO_REMOVE).clamp(min=0),
ymin + (h - TO_REMOVE).clamp(min=0),
)
else:
raise RuntimeError("Should not be here")
def resize(self, size, *args, **kwargs):
"""
Returns a resized copy of this bounding box
:param size: The requested size in pixels, as a 2-tuple:
(width, height).
"""
ratios = tuple(float(s) / float(s_orig) for s, s_orig in zip(size, self.size))
if ratios[0] == ratios[1]:
ratio = ratios[0]
scaled_box = self.bbox * ratio
bbox = BoxList(scaled_box, size, mode=self.mode)
# bbox._copy_extra_fields(self)
for k, v in self.extra_fields.items():
if not isinstance(v, torch.Tensor):
v = v.resize(size, *args, **kwargs)
bbox.add_field(k, v)
return bbox
ratio_width, ratio_height = ratios
xmin, ymin, xmax, ymax = self._split_into_xyxy()
scaled_xmin = xmin * ratio_width
scaled_xmax = xmax * ratio_width
scaled_ymin = ymin * ratio_height
scaled_ymax = ymax * ratio_height
scaled_box = torch.cat(
(scaled_xmin, scaled_ymin, scaled_xmax, scaled_ymax), dim=-1
)
bbox = BoxList(scaled_box, size, mode="xyxy")
# bbox._copy_extra_fields(self)
for k, v in self.extra_fields.items():
if not isinstance(v, torch.Tensor):
v = v.resize(size, *args, **kwargs)
bbox.add_field(k, v)
return bbox.convert(self.mode)
def transpose(self, method):
"""
Transpose bounding box (flip or rotate in 90 degree steps)
:param method: One of :py:attr:`PIL.Image.FLIP_LEFT_RIGHT`,
:py:attr:`PIL.Image.FLIP_TOP_BOTTOM`, :py:attr:`PIL.Image.ROTATE_90`,
:py:attr:`PIL.Image.ROTATE_180`, :py:attr:`PIL.Image.ROTATE_270`,
:py:attr:`PIL.Image.TRANSPOSE` or :py:attr:`PIL.Image.TRANSVERSE`.
"""
if method not in (FLIP_LEFT_RIGHT, FLIP_TOP_BOTTOM):
raise NotImplementedError(
"Only FLIP_LEFT_RIGHT and FLIP_TOP_BOTTOM implemented"
)
image_width, image_height = self.size
xmin, ymin, xmax, ymax = self._split_into_xyxy()
if method == FLIP_LEFT_RIGHT:
TO_REMOVE = 1
transposed_xmin = image_width - xmax - TO_REMOVE
transposed_xmax = image_width - xmin - TO_REMOVE
transposed_ymin = ymin
transposed_ymax = ymax
elif method == FLIP_TOP_BOTTOM:
transposed_xmin = xmin
transposed_xmax = xmax
transposed_ymin = image_height - ymax
transposed_ymax = image_height - ymin
transposed_boxes = torch.cat(
(transposed_xmin, transposed_ymin, transposed_xmax, transposed_ymax), dim=-1
)
bbox = BoxList(transposed_boxes, self.size, mode="xyxy")
# bbox._copy_extra_fields(self)
for k, v in self.extra_fields.items():
if not isinstance(v, torch.Tensor):
v = v.transpose(method)
bbox.add_field(k, v)
return bbox.convert(self.mode)
def crop(self, box):
"""
Crops a rectangular region from this bounding box. The box is a
4-tuple defining the left, upper, right, and lower pixel
coordinate.
"""
xmin, ymin, xmax, ymax = self._split_into_xyxy()
w, h = box[2] - box[0], box[3] - box[1]
cropped_xmin = (xmin - box[0]).clamp(min=0, max=w)
cropped_ymin = (ymin - box[1]).clamp(min=0, max=h)
cropped_xmax = (xmax - box[0]).clamp(min=0, max=w)
cropped_ymax = (ymax - box[1]).clamp(min=0, max=h)
# TODO should I filter empty boxes here?
if False:
is_empty = (cropped_xmin == cropped_xmax) | (cropped_ymin == cropped_ymax)
cropped_box = torch.cat(
(cropped_xmin, cropped_ymin, cropped_xmax, cropped_ymax), dim=-1
)
bbox = BoxList(cropped_box, (w, h), mode="xyxy")
# bbox._copy_extra_fields(self)
for k, v in self.extra_fields.items():
if not isinstance(v, torch.Tensor):
v = v.crop(box)
bbox.add_field(k, v)
return bbox.convert(self.mode)
# Tensor-like methods
def to(self, device):
bbox = BoxList(self.bbox.to(device), self.size, self.mode)
for k, v in self.extra_fields.items():
if hasattr(v, "to"):
v = v.to(device)
bbox.add_field(k, v)
return bbox
def __getitem__(self, item):
bbox = BoxList(self.bbox[item], self.size, self.mode)
for k, v in self.extra_fields.items():
bbox.add_field(k, v[item])
return bbox
def __len__(self):
return self.bbox.shape[0]
def clip_to_image(self, remove_empty=True):
TO_REMOVE = 1
self.bbox[:, 0].clamp_(min=0, max=self.size[0] - TO_REMOVE)
self.bbox[:, 1].clamp_(min=0, max=self.size[1] - TO_REMOVE)
self.bbox[:, 2].clamp_(min=0, max=self.size[0] - TO_REMOVE)
self.bbox[:, 3].clamp_(min=0, max=self.size[1] - TO_REMOVE)
if remove_empty:
box = self.bbox
keep = (box[:, 3] > box[:, 1]) & (box[:, 2] > box[:, 0])
return self[keep]
return self
def area(self):
box = self.bbox
if self.mode == "xyxy":
TO_REMOVE = 1
area = (box[:, 2] - box[:, 0] + TO_REMOVE) * (box[:, 3] - box[:, 1] + TO_REMOVE)
elif self.mode == "xywh":
area = box[:, 2] * box[:, 3]
else:
raise RuntimeError("Should not be here")
return area
def copy_with_fields(self, fields, skip_missing=False):
bbox = BoxList(self.bbox, self.size, self.mode)
if not isinstance(fields, (list, tuple)):
fields = [fields]
for field in fields:
if self.has_field(field):
bbox.add_field(field, self.get_field(field))
elif not skip_missing:
raise KeyError("Field '{}' not found in {}".format(field, self))
return bbox
def __repr__(self):
s = self.__class__.__name__ + "("
s += "num_boxes={}, ".format(len(self))
s += "image_width={}, ".format(self.size[0])
s += "image_height={}, ".format(self.size[1])
s += "mode={})".format(self.mode)
return s
# In[6]:
def findContours(*args, **kwargs):
"""
Wraps cv2.findContours to maintain compatiblity between versions
3 and 4
Returns:
contours, hierarchy
"""
if cv2.__version__.startswith('4'):
contours, hierarchy = cv2.findContours(*args, **kwargs)
elif cv2.__version__.startswith('3'):
_, contours, hierarchy = cv2.findContours(*args, **kwargs)
else:
raise AssertionError(
'cv2 must be either version 3 or 4 to call this method')
return contours, hierarchy
# In[7]:
class _NewEmptyTensorOp(torch.autograd.Function):
@staticmethod
def forward(ctx, x, new_shape):
ctx.shape = x.shape
return x.new_empty(new_shape)
@staticmethod
def backward(ctx, grad):
shape = ctx.shape
return _NewEmptyTensorOp.apply(grad, shape), None
def get_group_gn(dim, dim_per_gp, num_groups):
"""get number of groups used by GroupNorm, based on number of channels."""
assert dim_per_gp == -1 or num_groups == -1, "GroupNorm: can only specify G or C/G."
if dim_per_gp > 0:
assert dim % dim_per_gp == 0, "dim: {}, dim_per_gp: {}".format(dim, dim_per_gp)
group_gn = dim // dim_per_gp
else:
assert dim % num_groups == 0, "dim: {}, num_groups: {}".format(dim, num_groups)
group_gn = num_groups
return group_gn
def group_norm(out_channels, affine=True, divisor=1):
out_channels = out_channels // divisor
dim_per_gp = cfg.MODEL.GROUP_NORM.DIM_PER_GP // divisor
num_groups = cfg.MODEL.GROUP_NORM.NUM_GROUPS // divisor
eps = cfg.MODEL.GROUP_NORM.EPSILON # default: 1e-5
return torch.nn.GroupNorm(
get_group_gn(out_channels, dim_per_gp, num_groups),
out_channels,
eps,
affine
)
class _SigmoidFocalLoss(Function):
@staticmethod
def forward(ctx, logits, targets, gamma, alpha):
ctx.save_for_backward(logits, targets)
num_classes = logits.shape[1]
ctx.num_classes = num_classes
ctx.gamma = gamma
ctx.alpha = alpha
losses = _C.sigmoid_focalloss_forward(
logits, targets, num_classes, gamma, alpha
)
return losses
@staticmethod
@once_differentiable
def backward(ctx, d_loss):
logits, targets = ctx.saved_tensors
num_classes = ctx.num_classes
gamma = ctx.gamma
alpha = ctx.alpha
d_loss = d_loss.contiguous()
d_logits = _C.sigmoid_focalloss_backward(
logits, targets, d_loss, num_classes, gamma, alpha
)
return d_logits, None, None, None, None
sigmoid_focal_loss_cuda = _SigmoidFocalLoss.apply
def sigmoid_focal_loss_cpu(logits, targets, gamma, alpha):
num_classes = logits.shape[1]
gamma = gamma[0]
alpha = alpha[0]
dtype = targets.dtype
device = targets.device
class_range = torch.arange(1, num_classes+1, dtype=dtype, device=device).unsqueeze(0)
t = targets.unsqueeze(1)
p = torch.sigmoid(logits)
term1 = (1 - p) ** gamma * torch.log(p)
term2 = p ** gamma * torch.log(1 - p)
return -(t == class_range).float() * term1 * alpha - ((t != class_range) * (t >= 0)).float() * term2 * (1 - alpha)
# In[8]:
def synchronize():
"""
Helper function to synchronize (barrier) among all processes when
using distributed training
"""
if not dist.is_available():
return
if not dist.is_initialized():
return
world_size = dist.get_world_size()
if world_size == 1:
return
dist.barrier()
# In[9]:
class _ROIAlign(Function):
@staticmethod
def forward(ctx, input, roi, output_size, spatial_scale, sampling_ratio):
ctx.save_for_backward(roi)
ctx.output_size = _pair(output_size)
ctx.spatial_scale = spatial_scale
ctx.sampling_ratio = sampling_ratio
ctx.input_shape = input.size()
output = _C.roi_align_forward(
input, roi, spatial_scale, output_size[0], output_size[1], sampling_ratio
)
return output
@staticmethod
@once_differentiable
def backward(ctx, grad_output):
rois, = ctx.saved_tensors
output_size = ctx.output_size
spatial_scale = ctx.spatial_scale
sampling_ratio = ctx.sampling_ratio
bs, ch, h, w = ctx.input_shape
grad_input = _C.roi_align_backward(
grad_output,
rois,
spatial_scale,
output_size[0],
output_size[1],
bs,
ch,
h,
w,
sampling_ratio,
)
return grad_input, None, None, None, None
roi_align = _ROIAlign.apply
class ROIAlign(nn.Module):
def __init__(self, output_size, spatial_scale, sampling_ratio):
super(ROIAlign, self).__init__()
self.output_size = output_size
self.spatial_scale = spatial_scale
self.sampling_ratio = sampling_ratio
@amp.float_function
def forward(self, input, rois):
return roi_align(
input, rois, self.output_size, self.spatial_scale, self.sampling_ratio
)
def __repr__(self):
tmpstr = self.__class__.__name__ + "("
tmpstr += "output_size=" + str(self.output_size)
tmpstr += ", spatial_scale=" + str(self.spatial_scale)
tmpstr += ", sampling_ratio=" + str(self.sampling_ratio)
tmpstr += ")"
return tmpstr
# In[10]:
def align_and_update_state_dicts(model_state_dict, loaded_state_dict):
"""
Strategy: suppose that the models that we will create will have prefixes appended
to each of its keys, for example due to an extra level of nesting that the original
pre-trained weights from ImageNet won't contain. For example, model.state_dict()
might return backbone[0].body.res2.conv1.weight, while the pre-trained model contains
res2.conv1.weight. We thus want to match both parameters together.
For that, we look for each model weight, look among all loaded keys if there is one
that is a suffix of the current weight name, and use it if that's the case.
If multiple matches exist, take the one with longest size
of the corresponding name. For example, for the same model as before, the pretrained
weight file can contain both res2.conv1.weight, as well as conv1.weight. In this case,
we want to match backbone[0].body.conv1.weight to conv1.weight, and
backbone[0].body.res2.conv1.weight to res2.conv1.weight.
"""
current_keys = sorted(list(model_state_dict.keys()))
loaded_keys = sorted(list(loaded_state_dict.keys()))
# get a matrix of string matches, where each (i, j) entry correspond to the size of the
# loaded_key string, if it matches
match_matrix = [
len(j) if i.endswith(j) else 0 for i in current_keys for j in loaded_keys
]
match_matrix = torch.as_tensor(match_matrix).view(
len(current_keys), len(loaded_keys)
)
max_match_size, idxs = match_matrix.max(1)
# remove indices that correspond to no-match
idxs[max_match_size == 0] = -1
# used for logging
max_size = max([len(key) for key in current_keys]) if current_keys else 1
max_size_loaded = max([len(key) for key in loaded_keys]) if loaded_keys else 1
log_str_template = "{: <{}} loaded from {: <{}} of shape {}"
logger = logging.getLogger(__name__)
for idx_new, idx_old in enumerate(idxs.tolist()):
if idx_old == -1:
continue
key = current_keys[idx_new]
key_old = loaded_keys[idx_old]
model_state_dict[key] = loaded_state_dict[key_old]
logger.info(
log_str_template.format(
key,
max_size,
key_old,
max_size_loaded,
tuple(loaded_state_dict[key_old].shape),
)
)
def strip_prefix_if_present(state_dict, prefix):
keys = sorted(state_dict.keys())
if not all(key.startswith(prefix) for key in keys):
return state_dict
stripped_state_dict = OrderedDict()
for key, value in state_dict.items():
stripped_state_dict[key.replace(prefix, "")] = value
return stripped_state_dict
def load_state_dict(model, loaded_state_dict):
model_state_dict = model.state_dict()
# if the state_dict comes from a model that was wrapped in a
# DataParallel or DistributedDataParallel during serialization,
# remove the "module" prefix before performing the matching
loaded_state_dict = strip_prefix_if_present(loaded_state_dict, prefix="module.")
align_and_update_state_dicts(model_state_dict, loaded_state_dict)
# use strict loading
model.load_state_dict(model_state_dict)
# In[11]:
def _rename_conv_weights_for_deformable_conv_layers(state_dict, cfg):
import re
logger = logging.getLogger(__name__)
logger.info("Remapping conv weights for deformable conv weights")
layer_keys = sorted(state_dict.keys())
for ix, stage_with_dcn in enumerate(cfg.MODEL.RESNETS.STAGE_WITH_DCN, 1):
if not stage_with_dcn:
continue
for old_key in layer_keys:
pattern = ".*layer{}.*conv2.*".format(ix)
r = re.match(pattern, old_key)
if r is None:
continue
for param in ["weight", "bias"]:
if old_key.find(param) is -1:
continue
new_key = old_key.replace(
"conv2.{}".format(param), "conv2.conv.{}".format(param)
)
logger.info("pattern: {}, old_key: {}, new_key: {}".format(
pattern, old_key, new_key
))
state_dict[new_key] = state_dict[old_key]
del state_dict[old_key]
return state_dict
def _rename_fpn_weights(layer_keys, stage_names):
for mapped_idx, stage_name in enumerate(stage_names, 1):
suffix = ""
if mapped_idx < 4:
suffix = ".lateral"
layer_keys = [
k.replace("fpn.inner.layer{}.sum{}".format(stage_name, suffix), "fpn_inner{}".format(mapped_idx)) for k in layer_keys
]
layer_keys = [k.replace("fpn.layer{}.sum".format(stage_name), "fpn_layer{}".format(mapped_idx)) for k in layer_keys]
layer_keys = [k.replace("rpn.conv.fpn2", "rpn.conv") for k in layer_keys]
layer_keys = [k.replace("rpn.bbox_pred.fpn2", "rpn.bbox_pred") for k in layer_keys]
layer_keys = [
k.replace("rpn.cls_logits.fpn2", "rpn.cls_logits") for k in layer_keys
]
return layer_keys
def _rename_basic_resnet_weights(layer_keys):
layer_keys = [k.replace("_", ".") for k in layer_keys]
layer_keys = [k.replace(".w", ".weight") for k in layer_keys]
layer_keys = [k.replace(".bn", "_bn") for k in layer_keys]
layer_keys = [k.replace(".b", ".bias") for k in layer_keys]
layer_keys = [k.replace("_bn.s", "_bn.scale") for k in layer_keys]
layer_keys = [k.replace(".biasranch", ".branch") for k in layer_keys]
layer_keys = [k.replace("bbox.pred", "bbox_pred") for k in layer_keys]
layer_keys = [k.replace("cls.score", "cls_score") for k in layer_keys]
layer_keys = [k.replace("res.conv1_", "conv1_") for k in layer_keys]
# RPN / Faster RCNN
layer_keys = [k.replace(".biasbox", ".bbox") for k in layer_keys]
layer_keys = [k.replace("conv.rpn", "rpn.conv") for k in layer_keys]
layer_keys = [k.replace("rpn.bbox.pred", "rpn.bbox_pred") for k in layer_keys]
layer_keys = [k.replace("rpn.cls.logits", "rpn.cls_logits") for k in layer_keys]
# Affine-Channel -> BatchNorm enaming
layer_keys = [k.replace("_bn.scale", "_bn.weight") for k in layer_keys]
# Make torchvision-compatible
layer_keys = [k.replace("conv1_bn.", "bn1.") for k in layer_keys]
layer_keys = [k.replace("res2.", "layer1.") for k in layer_keys]
layer_keys = [k.replace("res3.", "layer2.") for k in layer_keys]
layer_keys = [k.replace("res4.", "layer3.") for k in layer_keys]
layer_keys = [k.replace("res5.", "layer4.") for k in layer_keys]
layer_keys = [k.replace(".branch2a.", ".conv1.") for k in layer_keys]
layer_keys = [k.replace(".branch2a_bn.", ".bn1.") for k in layer_keys]
layer_keys = [k.replace(".branch2b.", ".conv2.") for k in layer_keys]
layer_keys = [k.replace(".branch2b_bn.", ".bn2.") for k in layer_keys]
layer_keys = [k.replace(".branch2c.", ".conv3.") for k in layer_keys]
layer_keys = [k.replace(".branch2c_bn.", ".bn3.") for k in layer_keys]
layer_keys = [k.replace(".branch1.", ".downsample.0.") for k in layer_keys]
layer_keys = [k.replace(".branch1_bn.", ".downsample.1.") for k in layer_keys]
# GroupNorm
layer_keys = [k.replace("conv1.gn.s", "bn1.weight") for k in layer_keys]
layer_keys = [k.replace("conv1.gn.bias", "bn1.bias") for k in layer_keys]
layer_keys = [k.replace("conv2.gn.s", "bn2.weight") for k in layer_keys]
layer_keys = [k.replace("conv2.gn.bias", "bn2.bias") for k in layer_keys]
layer_keys = [k.replace("conv3.gn.s", "bn3.weight") for k in layer_keys]
layer_keys = [k.replace("conv3.gn.bias", "bn3.bias") for k in layer_keys]
layer_keys = [k.replace("downsample.0.gn.s", "downsample.1.weight") for k in layer_keys]
layer_keys = [k.replace("downsample.0.gn.bias", "downsample.1.bias") for k in layer_keys]
return layer_keys
def _rename_weights_for_resnet(weights, stage_names):
original_keys = sorted(weights.keys())
layer_keys = sorted(weights.keys())
# for X-101, rename output to fc1000 to avoid conflicts afterwards
layer_keys = [k if k != "pred_b" else "fc1000_b" for k in layer_keys]
layer_keys = [k if k != "pred_w" else "fc1000_w" for k in layer_keys]
# performs basic renaming: _ -> . , etc
layer_keys = _rename_basic_resnet_weights(layer_keys)
# FPN
layer_keys = _rename_fpn_weights(layer_keys, stage_names)
# Mask R-CNN
layer_keys = [k.replace("mask.fcn.logits", "mask_fcn_logits") for k in layer_keys]
layer_keys = [k.replace(".[mask].fcn", "mask_fcn") for k in layer_keys]
layer_keys = [k.replace("conv5.mask", "conv5_mask") for k in layer_keys]
# Keypoint R-CNN
layer_keys = [k.replace("kps.score.lowres", "kps_score_lowres") for k in layer_keys]
layer_keys = [k.replace("kps.score", "kps_score") for k in layer_keys]
layer_keys = [k.replace("conv.fcn", "conv_fcn") for k in layer_keys]
# Rename for our RPN structure
layer_keys = [k.replace("rpn.", "rpn.head.") for k in layer_keys]
key_map = {k: v for k, v in zip(original_keys, layer_keys)}
logger = logging.getLogger(__name__)
logger.info("Remapping C2 weights")
max_c2_key_size = max([len(k) for k in original_keys if "_momentum" not in k])
new_weights = OrderedDict()
for k in original_keys:
v = weights[k]
if "_momentum" in k:
continue
# if 'fc1000' in k:
# continue
w = torch.from_numpy(v)
# if "bn" in k:
# w = w.view(1, -1, 1, 1)
logger.info("C2 name: {: <{}} mapped name: {}".format(k, max_c2_key_size, key_map[k]))
new_weights[key_map[k]] = w
return new_weights
_C2_STAGE_NAMES = {
"R-50": ["1.2", "2.3", "3.5", "4.2"],
"R-101": ["1.2", "2.3", "3.22", "4.2"],
"R-152": ["1.2", "2.7", "3.35", "4.2"],
}
C2_FORMAT_LOADER = Registry()
def _load_c2_pickled_weights(file_path):
with open(file_path, "rb") as f:
if torch._six.PY3:
data = pickle.load(f, encoding="latin1")
else:
data = pickle.load(f)
if "blobs" in data:
weights = data["blobs"]
else:
weights = data
return weights
@C2_FORMAT_LOADER.register("R-50-FPN")
def load_resnet_c2_format(cfg, f):
state_dict = _load_c2_pickled_weights(f)
conv_body = cfg.MODEL.BACKBONE.CONV_BODY
arch = conv_body.replace("-C4", "").replace("-C5", "").replace("-FPN", "")
arch = arch.replace("-RETINANET", "")
stages = _C2_STAGE_NAMES[arch]
state_dict = _rename_weights_for_resnet(state_dict, stages)
# ***********************************
# for deformable convolutional layer
state_dict = _rename_conv_weights_for_deformable_conv_layers(state_dict, cfg)
# ***********************************
return dict(model=state_dict)
def load_c2_format(cfg, f):
return C2_FORMAT_LOADER[cfg.MODEL.BACKBONE.CONV_BODY](cfg, f)
# In[12]:
try:
from torch.hub import _download_url_to_file
from torch.hub import urlparse
from torch.hub import HASH_REGEX
except ImportError:
from torch.utils.model_zoo import _download_url_to_file
from torch.utils.model_zoo import urlparse
from torch.utils.model_zoo import HASH_REGEX
# very similar to https://github.com/pytorch/pytorch/blob/master/torch/utils/model_zoo.py
# but with a few improvements and modifications
def cache_url(url, model_dir=None, progress=True):
r"""Loads the Torch serialized object at the given URL.
If the object is already present in `model_dir`, it's deserialized and
returned. The filename part of the URL should follow the naming convention
``filename-.ext`` where ```` is the first eight or more
digits of the SHA256 hash of the contents of the file. The hash is used to
ensure unique names and to verify the contents of the file.
The default value of `model_dir` is ``$TORCH_HOME/models`` where
``$TORCH_HOME`` defaults to ``~/.torch``. The default directory can be
overridden with the ``$TORCH_MODEL_ZOO`` environment variable.
Args:
url (string): URL of the object to download
model_dir (string, optional): directory in which to save the object
progress (bool, optional): whether or not to display a progress bar to stderr
Example:
>>> cached_file = maskrcnn_benchmark.utils.model_zoo.cache_url('https://s3.amazonaws.com/pytorch/models/resnet18-5c106cde.pth')
"""
if model_dir is None:
torch_home = os.path.expanduser(os.getenv("TORCH_HOME", "~/.torch"))
model_dir = os.getenv("TORCH_MODEL_ZOO", os.path.join(torch_home, "models"))
if not os.path.exists(model_dir):
os.makedirs(model_dir)
parts = urlparse(url)
filename = os.path.basename(parts.path)
if filename == "model_final.pkl":
# workaround as pre-trained Caffe2 models from Detectron have all the same filename
# so make the full path the filename by replacing / with _
filename = parts.path.replace("/", "_")
cached_file = os.path.join(model_dir, filename)
if not os.path.exists(cached_file) and is_main_process():
sys.stderr.write('Downloading: "{}" to {}\n'.format(url, cached_file))
hash_prefix = HASH_REGEX.search(filename)
if hash_prefix is not None:
hash_prefix = hash_prefix.group(1)
# workaround: Caffe2 models don't have a hash, but follow the R-50 convention,
# which matches the hash PyTorch uses. So we skip the hash matching
# if the hash_prefix is less than 6 characters
if len(hash_prefix) < 6:
hash_prefix = None
_download_url_to_file(url, cached_file, hash_prefix, progress=progress)
synchronize()
return cached_file
# In[13]:
def import_file(module_name, file_path, make_importable=None):
module = imp.load_source(module_name, file_path)
return module
# In[14]:
def keypoints_to_heat_map(keypoints, rois, heatmap_size):
if rois.numel() == 0:
return rois.new().long(), rois.new().long()
offset_x = rois[:, 0]
offset_y = rois[:, 1]
scale_x = heatmap_size / (rois[:, 2] - rois[:, 0])
scale_y = heatmap_size / (rois[:, 3] - rois[:, 1])
offset_x = offset_x[:, None]
offset_y = offset_y[:, None]
scale_x = scale_x[:, None]
scale_y = scale_y[:, None]
x = keypoints[..., 0]
y = keypoints[..., 1]
x_boundary_inds = x == rois[:, 2][:, None]
y_boundary_inds = y == rois[:, 3][:, None]
x = (x - offset_x) * scale_x
x = x.floor().long()
y = (y - offset_y) * scale_y
y = y.floor().long()
x[x_boundary_inds] = heatmap_size - 1
y[y_boundary_inds] = heatmap_size - 1
valid_loc = (x >= 0) & (y >= 0) & (x < heatmap_size) & (y < heatmap_size)
vis = keypoints[..., 2] > 0
valid = (valid_loc & vis).long()
lin_ind = y * heatmap_size + x
heatmaps = lin_ind * valid
return heatmaps, valid
# In[15]:
def interpolate(
input, size=None, scale_factor=None, mode="nearest", align_corners=None
):
if input.numel() > 0:
return torch.nn.functional.interpolate(
input, size, scale_factor, mode, align_corners
)
def _check_size_scale_factor(dim):
if size is None and scale_factor is None:
raise ValueError("either size or scale_factor should be defined")
if size is not None and scale_factor is not None:
raise ValueError("only one of size or scale_factor should be defined")
if (
scale_factor is not None
and isinstance(scale_factor, tuple)
and len(scale_factor) != dim
):
raise ValueError(
"scale_factor shape must match input shape. "
"Input is {}D, scale_factor size is {}".format(dim, len(scale_factor))
)
def _output_size(dim):
_check_size_scale_factor(dim)
if size is not None:
return size
scale_factors = _ntuple(dim)(scale_factor)
# math.floor might return float in py2.7
return [
int(math.floor(input.size(i + 2) * scale_factors[i])) for i in range(dim)
]
output_shape = tuple(_output_size(2))
output_shape = input.shape[:-2] + output_shape
return _NewEmptyTensorOp.apply(input, output_shape)
# In[16]:
class ConvTranspose2d(torch.nn.ConvTranspose2d):
def forward(self, x):
if x.numel() > 0:
return super(ConvTranspose2d, self).forward(x)
# get output shape
output_shape = [
(i - 1) * d - 2 * p + (di * (k - 1) + 1) + op
for i, p, di, k, d, op in zip(
x.shape[-2:],
self.padding,
self.dilation,
self.kernel_size,
self.stride,
self.output_padding,
)
]
output_shape = [x.shape[0], self.bias.shape[0]] + output_shape
return _NewEmptyTensorOp.apply(x, output_shape)
# In[17]:
class Conv2d(torch.nn.Conv2d):
def forward(self, x):
if x.numel() > 0:
return super(Conv2d, self).forward(x)
# get output shape
output_shape = [
(i + 2 * p - (di * (k - 1) + 1)) // d + 1
for i, p, di, k, d in zip(
x.shape[-2:], self.padding, self.dilation, self.kernel_size, self.stride
)
]
output_shape = [x.shape[0], self.weight.shape[0]] + output_shape
return _NewEmptyTensorOp.apply(x, output_shape)
# In[18]:
def make_conv3x3(
in_channels,
out_channels,
dilation=1,
stride=1,
use_gn=False,
use_relu=False,
kaiming_init=True
):
conv = Conv2d(
in_channels,
out_channels,
kernel_size=3,
stride=stride,
padding=dilation,
dilation=dilation,
bias=False if use_gn else True
)
if kaiming_init:
nn.init.kaiming_normal_(
conv.weight, mode="fan_out", nonlinearity="relu"
)
else:
torch.nn.init.normal_(conv.weight, std=0.01)
if not use_gn:
nn.init.constant_(conv.bias, 0)
module = [conv,]
if use_gn:
module.append(group_norm(out_channels))
if use_relu:
module.append(nn.ReLU(inplace=True))
if len(module) > 1:
return nn.Sequential(*module)
return conv
# In[19]:
class LevelMapper(object):
"""Determine which FPN level each RoI in a set of RoIs should map to based
on the heuristic in the FPN paper.
"""
def __init__(self, k_min, k_max, canonical_scale=224, canonical_level=4, eps=1e-6):
"""
Arguments:
k_min (int)
k_max (int)
canonical_scale (int)
canonical_level (int)
eps (float)
"""
self.k_min = k_min
self.k_max = k_max
self.s0 = canonical_scale
self.lvl0 = canonical_level
self.eps = eps
def __call__(self, boxlists):
"""
Arguments:
boxlists (list[BoxList])
"""
# Compute level ids
s = torch.sqrt(cat([boxlist.area() for boxlist in boxlists]))
# Eqn.(1) in FPN paper
target_lvls = torch.floor(self.lvl0 + torch.log2(s / self.s0 + self.eps))
target_lvls = torch.clamp(target_lvls, min=self.k_min, max=self.k_max)
return target_lvls.to(torch.int64) - self.k_min
class Pooler(nn.Module):
"""
Pooler for Detection with or without FPN.
It currently hard-code ROIAlign in the implementation,
but that can be made more generic later on.
Also, the requirement of passing the scales is not strictly necessary, as they
can be inferred from the size of the feature map / size of original image,
which is available thanks to the BoxList.
"""
def __init__(self, output_size, scales, sampling_ratio):
"""
Arguments:
output_size (list[tuple[int]] or list[int]): output size for the pooled region
scales (list[float]): scales for each Pooler
sampling_ratio (int): sampling ratio for ROIAlign
"""
super(Pooler, self).__init__()
poolers = []
for scale in scales:
poolers.append(
ROIAlign(
output_size, spatial_scale=scale, sampling_ratio=sampling_ratio
)
)
self.poolers = nn.ModuleList(poolers)
self.output_size = output_size
# get the levels in the feature map by leveraging the fact that the network always
# downsamples by a factor of 2 at each level.
lvl_min = -torch.log2(torch.tensor(scales[0], dtype=torch.float32)).item()
lvl_max = -torch.log2(torch.tensor(scales[-1], dtype=torch.float32)).item()
self.map_levels = LevelMapper(lvl_min, lvl_max)
def convert_to_roi_format(self, boxes):
concat_boxes = cat([b.bbox for b in boxes], dim=0)
device, dtype = concat_boxes.device, concat_boxes.dtype
ids = cat(
[
torch.full((len(b), 1), i, dtype=dtype, device=device)
for i, b in enumerate(boxes)
],
dim=0,
)
rois = torch.cat([ids, concat_boxes], dim=1)
return rois
def forward(self, x, boxes):
"""
Arguments:
x (list[Tensor]): feature maps for each level
boxes (list[BoxList]): boxes to be used to perform the pooling operation.
Returns:
result (Tensor)
"""
num_levels = len(self.poolers)
rois = self.convert_to_roi_format(boxes)
if num_levels == 1:
return self.poolers[0](x[0], rois)
levels = self.map_levels(boxes)
num_rois = len(rois)
num_channels = x[0].shape[1]
output_size = self.output_size[0]
dtype, device = x[0].dtype, x[0].device
result = torch.zeros(
(num_rois, num_channels, output_size, output_size),
dtype=dtype,
device=device,
)
for level, (per_level_feature, pooler) in enumerate(zip(x, self.poolers)):
idx_in_level = torch.nonzero(levels == level).squeeze(1)
rois_per_level = rois[idx_in_level]
result[idx_in_level] = pooler(per_level_feature, rois_per_level).to(dtype)
return result
# In[20]:
def cat(tensors, dim=0):
"""
Efficient version of torch.cat that avoids a copy if there is only a single element in a list
"""
assert isinstance(tensors, (list, tuple))
if len(tensors) == 1:
return tensors[0]
return torch.cat(tensors, dim)
# In[21]:
class BalancedPositiveNegativeSampler(object):
"""
This class samples batches, ensuring that they contain a fixed proportion of positives
"""
def __init__(self, batch_size_per_image, positive_fraction):
"""
Arguments:
batch_size_per_image (int): number of elements to be selected per image
positive_fraction (float): percentage of positive elements per batch
"""
self.batch_size_per_image = batch_size_per_image
self.positive_fraction = positive_fraction
def __call__(self, matched_idxs):
"""
Arguments:
matched idxs: list of tensors containing -1, 0 or positive values.
Each tensor corresponds to a specific image.
-1 values are ignored, 0 are considered as negatives and > 0 as
positives.
Returns:
pos_idx (list[tensor])
neg_idx (list[tensor])
Returns two lists of binary masks for each image.
The first list contains the positive elements that were selected,
and the second list the negative example.
"""
pos_idx = []
neg_idx = []
for matched_idxs_per_image in matched_idxs:
positive = torch.nonzero(matched_idxs_per_image >= 1).squeeze(1)
negative = torch.nonzero(matched_idxs_per_image == 0).squeeze(1)
num_pos = int(self.batch_size_per_image * self.positive_fraction)
# protect against not enough positive examples
num_pos = min(positive.numel(), num_pos)
num_neg = self.batch_size_per_image - num_pos
# protect against not enough negative examples
num_neg = min(negative.numel(), num_neg)
# randomly select positive and negative examples
perm1 = torch.randperm(positive.numel(), device=positive.device)[:num_pos]
perm2 = torch.randperm(negative.numel(), device=negative.device)[:num_neg]
pos_idx_per_image = positive[perm1]
neg_idx_per_image = negative[perm2]
# create binary mask from indices
pos_idx_per_image_mask = torch.zeros_like(
matched_idxs_per_image, dtype=torch.uint8
)
neg_idx_per_image_mask = torch.zeros_like(
matched_idxs_per_image, dtype=torch.uint8
)
pos_idx_per_image_mask[pos_idx_per_image] = 1
neg_idx_per_image_mask[neg_idx_per_image] = 1
pos_idx.append(pos_idx_per_image_mask)
neg_idx.append(neg_idx_per_image_mask)
return pos_idx, neg_idx
# In[22]:
def concat_box_prediction_layers(box_cls, box_regression):
box_cls_flattened = []
box_regression_flattened = []
# for each feature level, permute the outputs to make them be in the
# same format as the labels. Note that the labels are computed for
# all feature levels concatenated, so we keep the same representation
# for the objectness and the box_regression
for box_cls_per_level, box_regression_per_level in zip(
box_cls, box_regression
):
N, AxC, H, W = box_cls_per_level.shape
Ax4 = box_regression_per_level.shape[1]
A = Ax4 // 4
C = AxC // A
box_cls_per_level = permute_and_flatten(
box_cls_per_level, N, A, C, H, W
)
box_cls_flattened.append(box_cls_per_level)
box_regression_per_level = permute_and_flatten(
box_regression_per_level, N, A, 4, H, W
)
box_regression_flattened.append(box_regression_per_level)
# concatenate on the first dimension (representing the feature levels), to
# take into account the way the labels were generated (with all feature maps
# being concatenated as well)
box_cls = cat(box_cls_flattened, dim=1).reshape(-1, C)
box_regression = cat(box_regression_flattened, dim=1).reshape(-1, 4)
return box_cls, box_regression
# In[23]:
def _cat(tensors, dim=0):
"""
Efficient version of torch.cat that avoids a copy if there is only a single element in a list
"""
assert isinstance(tensors, (list, tuple))
if len(tensors) == 1:
return tensors[0]
return torch.cat(tensors, dim)
def cat_boxlist(bboxes):
"""
Concatenates a list of BoxList (having the same image size) into a
single BoxList
Arguments:
bboxes (list[BoxList])
"""
assert isinstance(bboxes, (list, tuple))
assert all(isinstance(bbox, BoxList) for bbox in bboxes)
size = bboxes[0].size
assert all(bbox.size == size for bbox in bboxes)
mode = bboxes[0].mode
assert all(bbox.mode == mode for bbox in bboxes)
fields = set(bboxes[0].fields())
assert all(set(bbox.fields()) == fields for bbox in bboxes)
cat_boxes = BoxList(_cat([bbox.bbox for bbox in bboxes], dim=0), size, mode)
for field in fields:
data = _cat([bbox.get_field(field) for bbox in bboxes], dim=0)
cat_boxes.add_field(field, data)
return cat_boxes
# In[24]:
def boxlist_iou(boxlist1, boxlist2):
"""Compute the intersection over union of two set of boxes.
The box order must be (xmin, ymin, xmax, ymax).
Arguments:
box1: (BoxList) bounding boxes, sized [N,4].
box2: (BoxList) bounding boxes, sized [M,4].
Returns:
(tensor) iou, sized [N,M].
Reference:
https://github.com/chainer/chainercv/blob/master/chainercv/utils/bbox/bbox_iou.py
"""
if boxlist1.size != boxlist2.size:
raise RuntimeError(
"boxlists should have same image size, got {}, {}".format(boxlist1, boxlist2))
boxlist1 = boxlist1.convert("xyxy")
boxlist2 = boxlist2.convert("xyxy")
N = len(boxlist1)
M = len(boxlist2)
area1 = boxlist1.area()
area2 = boxlist2.area()
box1, box2 = boxlist1.bbox, boxlist2.bbox
lt = torch.max(box1[:, None, :2], box2[:, :2]) # [N,M,2]
rb = torch.min(box1[:, None, 2:], box2[:, 2:]) # [N,M,2]
TO_REMOVE = 1
wh = (rb - lt + TO_REMOVE).clamp(min=0) # [N,M,2]
inter = wh[:, :, 0] * wh[:, :, 1] # [N,M]
iou = inter / (area1[:, None] + area2 - inter)
return iou
# In[25]:
class RPNLossComputation(object):
"""
This class computes the RPN loss.
"""
def __init__(self, proposal_matcher, fg_bg_sampler, box_coder,
generate_labels_func):
"""
Arguments:
proposal_matcher (Matcher)
fg_bg_sampler (BalancedPositiveNegativeSampler)
box_coder (BoxCoder)
"""
# self.target_preparator = target_preparator
self.proposal_matcher = proposal_matcher
self.fg_bg_sampler = fg_bg_sampler
self.box_coder = box_coder
self.copied_fields = []
self.generate_labels_func = generate_labels_func
self.discard_cases = ['not_visibility', 'between_thresholds']
def match_targets_to_anchors(self, anchor, target, copied_fields=[]):
match_quality_matrix = boxlist_iou(target, anchor)
matched_idxs = self.proposal_matcher(match_quality_matrix)
# RPN doesn't need any fields from target
# for creating the labels, so clear them all
target = target.copy_with_fields(copied_fields)
# get the targets corresponding GT for each anchor
# NB: need to clamp the indices because we can have a single
# GT in the image, and matched_idxs can be -2, which goes
# out of bounds
matched_targets = target[matched_idxs.clamp(min=0)]
matched_targets.add_field("matched_idxs", matched_idxs)
return matched_targets
def prepare_targets(self, anchors, targets):
labels = []
regression_targets = []
for anchors_per_image, targets_per_image in zip(anchors, targets):
matched_targets = self.match_targets_to_anchors(
anchors_per_image, targets_per_image, self.copied_fields
)
matched_idxs = matched_targets.get_field("matched_idxs")
labels_per_image = self.generate_labels_func(matched_targets)
labels_per_image = labels_per_image.to(dtype=torch.float32)
# Background (negative examples)
bg_indices = matched_idxs == Matcher.BELOW_LOW_THRESHOLD
labels_per_image[bg_indices] = 0
# discard anchors that go out of the boundaries of the image
if "not_visibility" in self.discard_cases:
labels_per_image[~anchors_per_image.get_field("visibility")] = -1
# discard indices that are between thresholds
if "between_thresholds" in self.discard_cases:
inds_to_discard = matched_idxs == Matcher.BETWEEN_THRESHOLDS
labels_per_image[inds_to_discard] = -1
# compute regression targets
regression_targets_per_image = self.box_coder.encode(
matched_targets.bbox, anchors_per_image.bbox
)
labels.append(labels_per_image)
regression_targets.append(regression_targets_per_image)
return labels, regression_targets
def __call__(self, anchors, objectness, box_regression, targets):
"""
Arguments:
anchors (list[BoxList])
objectness (list[Tensor])
box_regression (list[Tensor])
targets (list[BoxList])
Returns:
objectness_loss (Tensor)
box_loss (Tensor
"""
anchors = [cat_boxlist(anchors_per_image) for anchors_per_image in anchors]
labels, regression_targets = self.prepare_targets(anchors, targets)
sampled_pos_inds, sampled_neg_inds = self.fg_bg_sampler(labels)
sampled_pos_inds = torch.nonzero(torch.cat(sampled_pos_inds, dim=0)).squeeze(1)
sampled_neg_inds = torch.nonzero(torch.cat(sampled_neg_inds, dim=0)).squeeze(1)
sampled_inds = torch.cat([sampled_pos_inds, sampled_neg_inds], dim=0)
objectness, box_regression = concat_box_prediction_layers(objectness, box_regression)
objectness = objectness.squeeze()
labels = torch.cat(labels, dim=0)
regression_targets = torch.cat(regression_targets, dim=0)
box_loss = smooth_l1_loss(
box_regression[sampled_pos_inds],
regression_targets[sampled_pos_inds],
beta=1.0 / 9,
size_average=False,
) / (sampled_inds.numel())
objectness_loss = FU.binary_cross_entropy_with_logits(
objectness[sampled_inds], labels[sampled_inds]
)
return objectness_loss, box_loss
# In[26]:
class SigmoidFocalLoss(nn.Module):
def __init__(self, gamma, alpha):
super(SigmoidFocalLoss, self).__init__()
self.gamma = gamma
self.alpha = alpha
def forward(self, logits, targets):
device = logits.device
if logits.is_cuda:
loss_func = sigmoid_focal_loss_cuda
else:
loss_func = sigmoid_focal_loss_cpu
loss = loss_func(logits, targets, self.gamma, self.alpha)
return loss.sum()
def __repr__(self):
tmpstr = self.__class__.__name__ + "("
tmpstr += "gamma=" + str(self.gamma)
tmpstr += ", alpha=" + str(self.alpha)
tmpstr += ")"
return tmpstr
# In[27]:
def smooth_l1_loss(input, target, beta=1. / 9, size_average=True):
"""
very similar to the smooth_l1_loss from pytorch, but with
the extra beta parameter
"""
n = torch.abs(input - target)
cond = n < beta
loss = torch.where(cond, 0.5 * n ** 2 / beta, n - 0.5 * beta)
if size_average:
return loss.mean()
return loss.sum()
# In[28]:
def permute_and_flatten(layer, N, A, C, H, W):
layer = layer.view(N, -1, C, H, W)
layer = layer.permute(0, 3, 4, 1, 2)
layer = layer.reshape(N, -1, C)
return layer
# In[29]:
class RPNPostProcessor(torch.nn.Module):
"""
Performs post-processing on the outputs of the RPN boxes, before feeding the
proposals to the heads
"""
def __init__(
self,
pre_nms_top_n,
post_nms_top_n,
nms_thresh,
min_size,
box_coder=None,
fpn_post_nms_top_n=None,
fpn_post_nms_per_batch=True,
):
"""
Arguments:
pre_nms_top_n (int)
post_nms_top_n (int)
nms_thresh (float)
min_size (int)
box_coder (BoxCoder)
fpn_post_nms_top_n (int)
"""
super(RPNPostProcessor, self).__init__()
self.pre_nms_top_n = pre_nms_top_n
self.post_nms_top_n = post_nms_top_n
self.nms_thresh = nms_thresh
self.min_size = min_size
if box_coder is None:
box_coder = BoxCoder(weights=(1.0, 1.0, 1.0, 1.0))
self.box_coder = box_coder
if fpn_post_nms_top_n is None:
fpn_post_nms_top_n = post_nms_top_n
self.fpn_post_nms_top_n = fpn_post_nms_top_n
self.fpn_post_nms_per_batch = fpn_post_nms_per_batch
def add_gt_proposals(self, proposals, targets):
"""
Arguments:
proposals: list[BoxList]
targets: list[BoxList]
"""
# Get the device we're operating on
device = proposals[0].bbox.device
gt_boxes = [target.copy_with_fields([]) for target in targets]
# later cat of bbox requires all fields to be present for all bbox
# so we need to add a dummy for objectness that's missing
for gt_box in gt_boxes:
gt_box.add_field("objectness", torch.ones(len(gt_box), device=device))
proposals = [
cat_boxlist((proposal, gt_box))
for proposal, gt_box in zip(proposals, gt_boxes)
]
return proposals
def forward_for_single_feature_map(self, anchors, objectness, box_regression):
"""
Arguments:
anchors: list[BoxList]
objectness: tensor of size N, A, H, W
box_regression: tensor of size N, A * 4, H, W
"""
device = objectness.device
N, A, H, W = objectness.shape
# put in the same format as anchors
objectness = permute_and_flatten(objectness, N, A, 1, H, W).view(N, -1)
objectness = objectness.sigmoid()
box_regression = permute_and_flatten(box_regression, N, A, 4, H, W)
num_anchors = A * H * W
pre_nms_top_n = min(self.pre_nms_top_n, num_anchors)
objectness, topk_idx = objectness.topk(pre_nms_top_n, dim=1, sorted=True)
batch_idx = torch.arange(N, device=device)[:, None]
box_regression = box_regression[batch_idx, topk_idx]
image_shapes = [box.size for box in anchors]
concat_anchors = torch.cat([a.bbox for a in anchors], dim=0)
concat_anchors = concat_anchors.reshape(N, -1, 4)[batch_idx, topk_idx]
proposals = self.box_coder.decode(
box_regression.view(-1, 4), concat_anchors.view(-1, 4)
)
proposals = proposals.view(N, -1, 4)
result = []
for proposal, score, im_shape in zip(proposals, objectness, image_shapes):
boxlist = BoxList(proposal, im_shape, mode="xyxy")
boxlist.add_field("objectness", score)
boxlist = boxlist.clip_to_image(remove_empty=False)
boxlist = remove_small_boxes(boxlist, self.min_size)
boxlist = boxlist_nms(
boxlist,
self.nms_thresh,
max_proposals=self.post_nms_top_n,
score_field="objectness",
)
result.append(boxlist)
return result
def forward(self, anchors, objectness, box_regression, targets=None):
"""
Arguments:
anchors: list[list[BoxList]]
objectness: list[tensor]
box_regression: list[tensor]
Returns:
boxlists (list[BoxList]): the post-processed anchors, after
applying box decoding and NMS
"""
sampled_boxes = []
num_levels = len(objectness)
anchors = list(zip(*anchors))
for a, o, b in zip(anchors, objectness, box_regression):
sampled_boxes.append(self.forward_for_single_feature_map(a, o, b))
boxlists = list(zip(*sampled_boxes))
boxlists = [cat_boxlist(boxlist) for boxlist in boxlists]
if num_levels > 1:
boxlists = self.select_over_all_levels(boxlists)
# append ground-truth bboxes to proposals
if self.training and targets is not None:
boxlists = self.add_gt_proposals(boxlists, targets)
return boxlists
def select_over_all_levels(self, boxlists):
num_images = len(boxlists)
# different behavior during training and during testing:
# during training, post_nms_top_n is over *all* the proposals combined, while
# during testing, it is over the proposals for each image
# NOTE: it should be per image, and not per batch. However, to be consistent
# with Detectron, the default is per batch (see Issue #672)
if self.training and self.fpn_post_nms_per_batch:
objectness = torch.cat(
[boxlist.get_field("objectness") for boxlist in boxlists], dim=0
)
box_sizes = [len(boxlist) for boxlist in boxlists]
post_nms_top_n = min(self.fpn_post_nms_top_n, len(objectness))
_, inds_sorted = torch.topk(objectness, post_nms_top_n, dim=0, sorted=True)
inds_mask = torch.zeros_like(objectness, dtype=torch.uint8)
inds_mask[inds_sorted] = 1
inds_mask = inds_mask.split(box_sizes)
for i in range(num_images):
boxlists[i] = boxlists[i][inds_mask[i]]
else:
for i in range(num_images):
objectness = boxlists[i].get_field("objectness")
post_nms_top_n = min(self.fpn_post_nms_top_n, len(objectness))
_, inds_sorted = torch.topk(
objectness, post_nms_top_n, dim=0, sorted=True
)
boxlists[i] = boxlists[i][inds_sorted]
return boxlists
# In[30]:
def remove_small_boxes(boxlist, min_size):
"""
Only keep boxes with both sides >= min_size
Arguments:
boxlist (Boxlist)
min_size (int)
"""
# TODO maybe add an API for querying the ws / hs
xywh_boxes = boxlist.convert("xywh").bbox
_, _, ws, hs = xywh_boxes.unbind(dim=1)
keep = (
(ws >= min_size) & (hs >= min_size)
).nonzero().squeeze(1)
return boxlist[keep]
# In[31]:
def boxlist_nms(boxlist, nms_thresh, max_proposals=-1, score_field="scores"):
"""
Performs non-maximum suppression on a boxlist, with scores specified
in a boxlist field via score_field.
Arguments:
boxlist(BoxList)
nms_thresh (float)
max_proposals (int): if > 0, then only the top max_proposals are kept
after non-maximum suppression
score_field (str)
"""
if nms_thresh <= 0:
return boxlist
mode = boxlist.mode
boxlist = boxlist.convert("xyxy")
boxes = boxlist.bbox
score = boxlist.get_field(score_field)
keep = _box_nms(boxes, score, nms_thresh)
if max_proposals > 0:
keep = keep[: max_proposals]
boxlist = boxlist[keep]
return boxlist.convert(mode)
# In[32]:
class BoxCoder(object):
"""
This class encodes and decodes a set of bounding boxes into
the representation used for training the regressors.
"""
def __init__(self, weights, bbox_xform_clip=math.log(1000. / 16)):
"""
Arguments:
weights (4-element tuple)
bbox_xform_clip (float)
"""
self.weights = weights
self.bbox_xform_clip = bbox_xform_clip
def encode(self, reference_boxes, proposals):
"""
Encode a set of proposals with respect to some
reference boxes
Arguments:
reference_boxes (Tensor): reference boxes
proposals (Tensor): boxes to be encoded
"""
TO_REMOVE = 1 # TODO remove
ex_widths = proposals[:, 2] - proposals[:, 0] + TO_REMOVE
ex_heights = proposals[:, 3] - proposals[:, 1] + TO_REMOVE
ex_ctr_x = proposals[:, 0] + 0.5 * ex_widths
ex_ctr_y = proposals[:, 1] + 0.5 * ex_heights
gt_widths = reference_boxes[:, 2] - reference_boxes[:, 0] + TO_REMOVE
gt_heights = reference_boxes[:, 3] - reference_boxes[:, 1] + TO_REMOVE
gt_ctr_x = reference_boxes[:, 0] + 0.5 * gt_widths
gt_ctr_y = reference_boxes[:, 1] + 0.5 * gt_heights
wx, wy, ww, wh = self.weights
targets_dx = wx * (gt_ctr_x - ex_ctr_x) / ex_widths
targets_dy = wy * (gt_ctr_y - ex_ctr_y) / ex_heights
targets_dw = ww * torch.log(gt_widths / ex_widths)
targets_dh = wh * torch.log(gt_heights / ex_heights)
targets = torch.stack((targets_dx, targets_dy, targets_dw, targets_dh), dim=1)
return targets
def decode(self, rel_codes, boxes):
"""
From a set of original boxes and encoded relative box offsets,
get the decoded boxes.
Arguments:
rel_codes (Tensor): encoded boxes
boxes (Tensor): reference boxes.
"""
boxes = boxes.to(rel_codes.dtype)
TO_REMOVE = 1 # TODO remove
widths = boxes[:, 2] - boxes[:, 0] + TO_REMOVE
heights = boxes[:, 3] - boxes[:, 1] + TO_REMOVE
ctr_x = boxes[:, 0] + 0.5 * widths
ctr_y = boxes[:, 1] + 0.5 * heights
wx, wy, ww, wh = self.weights
dx = rel_codes[:, 0::4] / wx
dy = rel_codes[:, 1::4] / wy
dw = rel_codes[:, 2::4] / ww
dh = rel_codes[:, 3::4] / wh
# Prevent sending too large values into torch.exp()
dw = torch.clamp(dw, max=self.bbox_xform_clip)
dh = torch.clamp(dh, max=self.bbox_xform_clip)
pred_ctr_x = dx * widths[:, None] + ctr_x[:, None]
pred_ctr_y = dy * heights[:, None] + ctr_y[:, None]
pred_w = torch.exp(dw) * widths[:, None]
pred_h = torch.exp(dh) * heights[:, None]
pred_boxes = torch.zeros_like(rel_codes)
# x1
pred_boxes[:, 0::4] = pred_ctr_x - 0.5 * pred_w
# y1
pred_boxes[:, 1::4] = pred_ctr_y - 0.5 * pred_h
# x2 (note: "- 1" is correct; don't be fooled by the asymmetry)
pred_boxes[:, 2::4] = pred_ctr_x + 0.5 * pred_w - 1
# y2 (note: "- 1" is correct; don't be fooled by the asymmetry)
pred_boxes[:, 3::4] = pred_ctr_y + 0.5 * pred_h - 1
return pred_boxes
# In[33]:
class Masker(object):
"""
Projects a set of masks in an image on the locations
specified by the bounding boxes
"""
def __init__(self, threshold=0.5, padding=1):
self.threshold = threshold
self.padding = padding
def forward_single_image(self, masks, boxes):
boxes = boxes.convert("xyxy")
im_w, im_h = boxes.size
res = [
paste_mask_in_image(mask[0], box, im_h, im_w, self.threshold, self.padding)
for mask, box in zip(masks, boxes.bbox)
]
if len(res) > 0:
res = torch.stack(res, dim=0)[:, None]
else:
res = masks.new_empty((0, 1, masks.shape[-2], masks.shape[-1]))
return res
def __call__(self, masks, boxes):
if isinstance(boxes, BoxList):
boxes = [boxes]
# Make some sanity check
assert len(boxes) == len(masks), "Masks and boxes should have the same length."
# TODO: Is this JIT compatible?
# If not we should make it compatible.
results = []
for mask, box in zip(masks, boxes):
assert mask.shape[0] == len(box), "Number of objects should be the same."
result = self.forward_single_image(mask, box)
results.append(result)
return results
# In[34]:
class Matcher(object):
"""
This class assigns to each predicted "element" (e.g., a box) a ground-truth
element. Each predicted element will have exactly zero or one matches; each
ground-truth element may be assigned to zero or more predicted elements.
Matching is based on the MxN match_quality_matrix, that characterizes how well
each (ground-truth, predicted)-pair match. For example, if the elements are
boxes, the matrix may contain box IoU overlap values.
The matcher returns a tensor of size N containing the index of the ground-truth
element m that matches to prediction n. If there is no match, a negative value
is returned.
"""
BELOW_LOW_THRESHOLD = -1
BETWEEN_THRESHOLDS = -2
def __init__(self, high_threshold, low_threshold, allow_low_quality_matches=False):
"""
Args:
high_threshold (float): quality values greater than or equal to
this value are candidate matches.
low_threshold (float): a lower quality threshold used to stratify
matches into three levels:
1) matches >= high_threshold
2) BETWEEN_THRESHOLDS matches in [low_threshold, high_threshold)
3) BELOW_LOW_THRESHOLD matches in [0, low_threshold)
allow_low_quality_matches (bool): if True, produce additional matches
for predictions that have only low-quality match candidates. See
set_low_quality_matches_ for more details.
"""
assert low_threshold <= high_threshold
self.high_threshold = high_threshold
self.low_threshold = low_threshold
self.allow_low_quality_matches = allow_low_quality_matches
def __call__(self, match_quality_matrix):
"""
Args:
match_quality_matrix (Tensor[float]): an MxN tensor, containing the
pairwise quality between M ground-truth elements and N predicted elements.
Returns:
matches (Tensor[int64]): an N tensor where N[i] is a matched gt in
[0, M - 1] or a negative value indicating that prediction i could not
be matched.
"""
if match_quality_matrix.numel() == 0:
# empty targets or proposals not supported during training
if match_quality_matrix.shape[0] == 0:
raise ValueError(
"No ground-truth boxes available for one of the images "
"during training")
else:
raise ValueError(
"No proposal boxes available for one of the images "
"during training")
# match_quality_matrix is M (gt) x N (predicted)
# Max over gt elements (dim 0) to find best gt candidate for each prediction
matched_vals, matches = match_quality_matrix.max(dim=0)
if self.allow_low_quality_matches:
all_matches = matches.clone()
# Assign candidate matches with low quality to negative (unassigned) values
below_low_threshold = matched_vals < self.low_threshold
between_thresholds = (matched_vals >= self.low_threshold) & (
matched_vals < self.high_threshold
)
matches[below_low_threshold] = Matcher.BELOW_LOW_THRESHOLD
matches[between_thresholds] = Matcher.BETWEEN_THRESHOLDS
if self.allow_low_quality_matches:
self.set_low_quality_matches_(matches, all_matches, match_quality_matrix)
return matches
def set_low_quality_matches_(self, matches, all_matches, match_quality_matrix):
"""
Produce additional matches for predictions that have only low-quality matches.
Specifically, for each ground-truth find the set of predictions that have
maximum overlap with it (including ties); for each prediction in that set, if
it is unmatched, then match it to the ground-truth with which it has the highest
quality value.
"""
# For each gt, find the prediction with which it has highest quality
highest_quality_foreach_gt, _ = match_quality_matrix.max(dim=1)
# Find highest quality match available, even if it is low, including ties
gt_pred_pairs_of_highest_quality = torch.nonzero(
match_quality_matrix == highest_quality_foreach_gt[:, None]
)
# Example gt_pred_pairs_of_highest_quality:
# tensor([[ 0, 39796],
# [ 1, 32055],
# [ 1, 32070],
# [ 2, 39190],
# [ 2, 40255],
# [ 3, 40390],
# [ 3, 41455],
# [ 4, 45470],
# [ 5, 45325],
# [ 5, 46390]])
# Each row is a (gt index, prediction index)
# Note how gt items 1, 2, 3, and 5 each have two ties
pred_inds_to_update = gt_pred_pairs_of_highest_quality[:, 1]
matches[pred_inds_to_update] = all_matches[pred_inds_to_update]
# In[35]:
class Checkpointer(object):
def __init__(
self,
model,
optimizer=None,
scheduler=None,
save_dir="",
save_to_disk=None,
logger=None,
):
self.model = model
self.optimizer = optimizer
self.scheduler = scheduler
self.save_dir = save_dir
self.save_to_disk = save_to_disk
if logger is None:
logger = logging.getLogger(__name__)
self.logger = logger
def save(self, name, **kwargs):
if not self.save_dir:
return
if not self.save_to_disk:
return
data = {}
data["model"] = self.model.state_dict()
if self.optimizer is not None:
data["optimizer"] = self.optimizer.state_dict()
if self.scheduler is not None:
data["scheduler"] = self.scheduler.state_dict()
data.update(kwargs)
save_file = os.path.join(self.save_dir, "{}.pth".format(name))
self.logger.info("Saving checkpoint to {}".format(save_file))
torch.save(data, save_file)
self.tag_last_checkpoint(save_file)
def load(self, f=None, use_latest=True):
if self.has_checkpoint() and use_latest:
# override argument with existing checkpoint
f = self.get_checkpoint_file()
if not f:
# no checkpoint could be found
self.logger.info("No checkpoint found. Initializing model from scratch")
return {}
self.logger.info("Loading checkpoint from {}".format(f))
checkpoint = self._load_file(f)
self._load_model(checkpoint)
if "optimizer" in checkpoint and self.optimizer:
self.logger.info("Loading optimizer from {}".format(f))
self.optimizer.load_state_dict(checkpoint.pop("optimizer"))
if "scheduler" in checkpoint and self.scheduler:
self.logger.info("Loading scheduler from {}".format(f))
self.scheduler.load_state_dict(checkpoint.pop("scheduler"))
# return any further checkpoint data
return checkpoint
def has_checkpoint(self):
save_file = os.path.join(self.save_dir, "last_checkpoint")
return os.path.exists(save_file)
def get_checkpoint_file(self):
save_file = os.path.join(self.save_dir, "last_checkpoint")
try:
with open(save_file, "r") as f:
last_saved = f.read()
last_saved = last_saved.strip()
except IOError:
# if file doesn't exist, maybe because it has just been
# deleted by a separate process
last_saved = ""
return last_saved
def tag_last_checkpoint(self, last_filename):
save_file = os.path.join(self.save_dir, "last_checkpoint")
with open(save_file, "w") as f:
f.write(last_filename)
def _load_file(self, f):
return torch.load(f, map_location=torch.device("cpu"))
def _load_model(self, checkpoint):
load_state_dict(self.model, checkpoint.pop("model"))
class DetectronCheckpointer(Checkpointer):
def __init__(
self,
cfg,
model,
optimizer=None,
scheduler=None,
save_dir="",
save_to_disk=None,
logger=None,
):
super(DetectronCheckpointer, self).__init__(
model, optimizer, scheduler, save_dir, save_to_disk, logger
)
self.cfg = cfg.clone()
def _load_file(self, f):
# catalog lookup
if f.startswith("catalog://"):
paths_catalog = import_file(
"maskrcnn_benchmark.config.paths_catalog", self.cfg.PATHS_CATALOG, True
)
catalog_f = paths_catalog.ModelCatalog.get(f[len("catalog://") :])
self.logger.info("{} points to {}".format(f, catalog_f))
f = catalog_f
# download url files
if f.startswith("http"):
# if the file is a url path, download it and cache it
cached_f = cache_url(f)
self.logger.info("url {} cached in {}".format(f, cached_f))
f = cached_f
# convert Caffe2 checkpoint from pkl
if f.endswith(".pkl"):
return load_c2_format(self.cfg, f)
# load native detectron.pytorch checkpoint
loaded = super(DetectronCheckpointer, self)._load_file(f)
if "model" not in loaded:
loaded = dict(model=loaded)
return loaded
# In[36]:
class ImageList(object):
"""
Structure that holds a list of images (of possibly
varying sizes) as a single tensor.
This works by padding the images to the same size,
and storing in a field the original sizes of each image
"""
def __init__(self, tensors, image_sizes):
"""
Arguments:
tensors (tensor)
image_sizes (list[tuple[int, int]])
"""
self.tensors = tensors
self.image_sizes = image_sizes
def to(self, *args, **kwargs):
cast_tensor = self.tensors.to(*args, **kwargs)
return ImageList(cast_tensor, self.image_sizes)
def to_image_list(tensors, size_divisible=0):
"""
tensors can be an ImageList, a torch.Tensor or
an iterable of Tensors. It can't be a numpy array.
When tensors is an iterable of Tensors, it pads
the Tensors with zeros so that they have the same
shape
"""
if isinstance(tensors, torch.Tensor) and size_divisible > 0:
tensors = [tensors]
if isinstance(tensors, ImageList):
return tensors
elif isinstance(tensors, torch.Tensor):
# single tensor shape can be inferred
if tensors.dim() == 3:
tensors = tensors[None]
assert tensors.dim() == 4
image_sizes = [tensor.shape[-2:] for tensor in tensors]
return ImageList(tensors, image_sizes)
elif isinstance(tensors, (tuple, list)):
max_size = tuple(max(s) for s in zip(*[img.shape for img in tensors]))
# TODO Ideally, just remove this and let me model handle arbitrary
# input sizs
if size_divisible > 0:
import math
stride = size_divisible
max_size = list(max_size)
max_size[1] = int(math.ceil(max_size[1] / stride) * stride)
max_size[2] = int(math.ceil(max_size[2] / stride) * stride)
max_size = tuple(max_size)
batch_shape = (len(tensors),) + max_size
batched_imgs = tensors[0].new(*batch_shape).zero_()
for img, pad_img in zip(tensors, batched_imgs):
pad_img[: img.shape[0], : img.shape[1], : img.shape[2]].copy_(img)
image_sizes = [im.shape[-2:] for im in tensors]
return ImageList(batched_imgs, image_sizes)
else:
raise TypeError("Unsupported type for to_image_list: {}".format(type(tensors)))
# In[37]:
FLIP_LEFT_RIGHT = 0
FLIP_TOP_BOTTOM = 1
class Keypoints(object):
def __init__(self, keypoints, size, mode=None):
# FIXME remove check once we have better integration with device
# in my version this would consistently return a CPU tensor
device = keypoints.device if isinstance(keypoints, torch.Tensor) else torch.device('cpu')
keypoints = torch.as_tensor(keypoints, dtype=torch.float32, device=device)
num_keypoints = keypoints.shape[0]
if num_keypoints:
keypoints = keypoints.view(num_keypoints, -1, 3)
# TODO should I split them?
# self.visibility = keypoints[..., 2]
self.keypoints = keypoints# [..., :2]
self.size = size
self.mode = mode
self.extra_fields = {}
def crop(self, box):
raise NotImplementedError()
def resize(self, size, *args, **kwargs):
ratios = tuple(float(s) / float(s_orig) for s, s_orig in zip(size, self.size))
ratio_w, ratio_h = ratios
resized_data = self.keypoints.clone()
resized_data[..., 0] *= ratio_w
resized_data[..., 1] *= ratio_h
keypoints = type(self)(resized_data, size, self.mode)
for k, v in self.extra_fields.items():
keypoints.add_field(k, v)
return keypoints
def transpose(self, method):
if method not in (FLIP_LEFT_RIGHT,):
raise NotImplementedError(
"Only FLIP_LEFT_RIGHT implemented")
flip_inds = type(self).FLIP_INDS
flipped_data = self.keypoints[:, flip_inds]
width = self.size[0]
TO_REMOVE = 1
# Flip x coordinates
flipped_data[..., 0] = width - flipped_data[..., 0] - TO_REMOVE
# Maintain COCO convention that if visibility == 0, then x, y = 0
inds = flipped_data[..., 2] == 0
flipped_data[inds] = 0
keypoints = type(self)(flipped_data, self.size, self.mode)
for k, v in self.extra_fields.items():
keypoints.add_field(k, v)
return keypoints
def to(self, *args, **kwargs):
keypoints = type(self)(self.keypoints.to(*args, **kwargs), self.size, self.mode)
for k, v in self.extra_fields.items():
if hasattr(v, "to"):
v = v.to(*args, **kwargs)
keypoints.add_field(k, v)
return keypoints
def __getitem__(self, item):
keypoints = type(self)(self.keypoints[item], self.size, self.mode)
for k, v in self.extra_fields.items():
keypoints.add_field(k, v[item])
return keypoints
def add_field(self, field, field_data):
self.extra_fields[field] = field_data
def get_field(self, field):
return self.extra_fields[field]
def __repr__(self):
s = self.__class__.__name__ + '('
s += 'num_instances={}, '.format(len(self.keypoints))
s += 'image_width={}, '.format(self.size[0])
s += 'image_height={})'.format(self.size[1])
return s
class PersonKeypoints(Keypoints):
NAMES = [
'nose',
'left_eye',
'right_eye',
'left_ear',
'right_ear',
'left_shoulder',
'right_shoulder',
'left_elbow',
'right_elbow',
'left_wrist',
'right_wrist',
'left_hip',
'right_hip',
'left_knee',
'right_knee',
'left_ankle',
'right_ankle'
]
FLIP_MAP = {
'left_eye': 'right_eye',
'left_ear': 'right_ear',
'left_shoulder': 'right_shoulder',
'left_elbow': 'right_elbow',
'left_wrist': 'right_wrist',
'left_hip': 'right_hip',
'left_knee': 'right_knee',
'left_ankle': 'right_ankle'
}
# In[38]:
def project_keypoints_to_heatmap(keypoints, proposals, discretization_size):
proposals = proposals.convert("xyxy")
return keypoints_to_heat_map(
keypoints.keypoints, proposals.bbox, discretization_size
)
def cat_boxlist_with_keypoints(boxlists):
assert all(boxlist.has_field("keypoints") for boxlist in boxlists)
kp = [boxlist.get_field("keypoints").keypoints for boxlist in boxlists]
kp = cat(kp, 0)
fields = boxlists[0].get_fields()
fields = [field for field in fields if field != "keypoints"]
boxlists = [boxlist.copy_with_fields(fields) for boxlist in boxlists]
boxlists = cat_boxlist(boxlists)
boxlists.add_field("keypoints", kp)
return boxlists
def _within_box(points, boxes):
"""Validate which keypoints are contained inside a given box.
points: NxKx2
boxes: Nx4
output: NxK
"""
x_within = (points[..., 0] >= boxes[:, 0, None]) & (
points[..., 0] <= boxes[:, 2, None]
)
y_within = (points[..., 1] >= boxes[:, 1, None]) & (
points[..., 1] <= boxes[:, 3, None]
)
return x_within & y_within
class KeypointRCNNLossComputation(object):
def __init__(self, proposal_matcher, fg_bg_sampler, discretization_size):
"""
Arguments:
proposal_matcher (Matcher)
fg_bg_sampler (BalancedPositiveNegativeSampler)
discretization_size (int)
"""
self.proposal_matcher = proposal_matcher
self.fg_bg_sampler = fg_bg_sampler
self.discretization_size = discretization_size
def match_targets_to_proposals(self, proposal, target):
match_quality_matrix = boxlist_iou(target, proposal)
matched_idxs = self.proposal_matcher(match_quality_matrix)
# Keypoint RCNN needs "labels" and "keypoints "fields for creating the targets
target = target.copy_with_fields(["labels", "keypoints"])
# get the targets corresponding GT for each proposal
# NB: need to clamp the indices because we can have a single
# GT in the image, and matched_idxs can be -2, which goes
# out of bounds
matched_targets = target[matched_idxs.clamp(min=0)]
matched_targets.add_field("matched_idxs", matched_idxs)
return matched_targets
def prepare_targets(self, proposals, targets):
labels = []
keypoints = []
for proposals_per_image, targets_per_image in zip(proposals, targets):
matched_targets = self.match_targets_to_proposals(
proposals_per_image, targets_per_image
)
matched_idxs = matched_targets.get_field("matched_idxs")
labels_per_image = matched_targets.get_field("labels")
labels_per_image = labels_per_image.to(dtype=torch.int64)
# this can probably be removed, but is left here for clarity
# and completeness
# TODO check if this is the right one, as BELOW_THRESHOLD
neg_inds = matched_idxs == Matcher.BELOW_LOW_THRESHOLD
labels_per_image[neg_inds] = 0
keypoints_per_image = matched_targets.get_field("keypoints")
within_box = _within_box(
keypoints_per_image.keypoints, matched_targets.bbox
)
vis_kp = keypoints_per_image.keypoints[..., 2] > 0
is_visible = (within_box & vis_kp).sum(1) > 0
labels_per_image[~is_visible] = -1
labels.append(labels_per_image)
keypoints.append(keypoints_per_image)
return labels, keypoints
def subsample(self, proposals, targets):
"""
This method performs the positive/negative sampling, and return
the sampled proposals.
Note: this function keeps a state.
Arguments:
proposals (list[BoxList])
targets (list[BoxList])
"""
labels, keypoints = self.prepare_targets(proposals, targets)
sampled_pos_inds, sampled_neg_inds = self.fg_bg_sampler(labels)
proposals = list(proposals)
# add corresponding label and regression_targets information to the bounding boxes
for labels_per_image, keypoints_per_image, proposals_per_image in zip(
labels, keypoints, proposals
):
proposals_per_image.add_field("labels", labels_per_image)
proposals_per_image.add_field("keypoints", keypoints_per_image)
# distributed sampled proposals, that were obtained on all feature maps
# concatenated via the fg_bg_sampler, into individual feature map levels
for img_idx, (pos_inds_img, neg_inds_img) in enumerate(
zip(sampled_pos_inds, sampled_neg_inds)
):
img_sampled_inds = torch.nonzero(pos_inds_img).squeeze(1)
proposals_per_image = proposals[img_idx][img_sampled_inds]
proposals[img_idx] = proposals_per_image
self._proposals = proposals
return proposals
def __call__(self, proposals, keypoint_logits):
heatmaps = []
valid = []
for proposals_per_image in proposals:
kp = proposals_per_image.get_field("keypoints")
heatmaps_per_image, valid_per_image = project_keypoints_to_heatmap(
kp, proposals_per_image, self.discretization_size
)
heatmaps.append(heatmaps_per_image.view(-1))
valid.append(valid_per_image.view(-1))
keypoint_targets = cat(heatmaps, dim=0)
valid = cat(valid, dim=0).to(dtype=torch.uint8)
valid = torch.nonzero(valid).squeeze(1)
# torch.mean (in binary_cross_entropy_with_logits) does'nt
# accept empty tensors, so handle it sepaartely
if keypoint_targets.numel() == 0 or len(valid) == 0:
return keypoint_logits.sum() * 0
N, K, H, W = keypoint_logits.shape
keypoint_logits = keypoint_logits.view(N * K, H * W)
keypoint_loss = FU.cross_entropy(keypoint_logits[valid], keypoint_targets[valid])
return keypoint_loss
def make_roi_keypoint_loss_evaluator(cfg):
matcher = Matcher(
cfg.MODEL.ROI_HEADS.FG_IOU_THRESHOLD,
cfg.MODEL.ROI_HEADS.BG_IOU_THRESHOLD,
allow_low_quality_matches=False,
)
fg_bg_sampler = BalancedPositiveNegativeSampler(
cfg.MODEL.ROI_HEADS.BATCH_SIZE_PER_IMAGE, cfg.MODEL.ROI_HEADS.POSITIVE_FRACTION
)
resolution = cfg.MODEL.ROI_KEYPOINT_HEAD.RESOLUTION
loss_evaluator = KeypointRCNNLossComputation(matcher, fg_bg_sampler, resolution)
return loss_evaluator
# In[39]:
class KeypointPostProcessor(nn.Module):
def __init__(self, keypointer=None):
super(KeypointPostProcessor, self).__init__()
self.keypointer = keypointer
def forward(self, x, boxes):
mask_prob = x
scores = None
if self.keypointer:
mask_prob, scores = self.keypointer(x, boxes)
assert len(boxes) == 1, "Only non-batched inference supported for now"
boxes_per_image = [box.bbox.size(0) for box in boxes]
mask_prob = mask_prob.split(boxes_per_image, dim=0)
scores = scores.split(boxes_per_image, dim=0)
results = []
for prob, box, score in zip(mask_prob, boxes, scores):
bbox = BoxList(box.bbox, box.size, mode="xyxy")
for field in box.fields():
bbox.add_field(field, box.get_field(field))
prob = PersonKeypoints(prob, box.size)
prob.add_field("logits", score)
bbox.add_field("keypoints", prob)
results.append(bbox)
return results
def heatmaps_to_keypoints(maps, rois):
"""Extract predicted keypoint locations from heatmaps. Output has shape
(#rois, 4, #keypoints) with the 4 rows corresponding to (x, y, logit, prob)
for each keypoint.
"""
# This function converts a discrete image coordinate in a HEATMAP_SIZE x
# HEATMAP_SIZE image to a continuous keypoint coordinate. We maintain
# consistency with keypoints_to_heatmap_labels by using the conversion from
# Heckbert 1990: c = d + 0.5, where d is a discrete coordinate and c is a
# continuous coordinate.
offset_x = rois[:, 0]
offset_y = rois[:, 1]
widths = rois[:, 2] - rois[:, 0]
heights = rois[:, 3] - rois[:, 1]
widths = np.maximum(widths, 1)
heights = np.maximum(heights, 1)
widths_ceil = np.ceil(widths)
heights_ceil = np.ceil(heights)
# NCHW to NHWC for use with OpenCV
maps = np.transpose(maps, [0, 2, 3, 1])
min_size = 0 # cfg.KRCNN.INFERENCE_MIN_SIZE
num_keypoints = maps.shape[3]
xy_preds = np.zeros((len(rois), 3, num_keypoints), dtype=np.float32)
end_scores = np.zeros((len(rois), num_keypoints), dtype=np.float32)
for i in range(len(rois)):
if min_size > 0:
roi_map_width = int(np.maximum(widths_ceil[i], min_size))
roi_map_height = int(np.maximum(heights_ceil[i], min_size))
else:
roi_map_width = widths_ceil[i]
roi_map_height = heights_ceil[i]
width_correction = widths[i] / roi_map_width
height_correction = heights[i] / roi_map_height
roi_map = cv2.resize(
maps[i], (roi_map_width, roi_map_height), interpolation=cv2.INTER_CUBIC
)
# Bring back to CHW
roi_map = np.transpose(roi_map, [2, 0, 1])
# roi_map_probs = scores_to_probs(roi_map.copy())
w = roi_map.shape[2]
pos = roi_map.reshape(num_keypoints, -1).argmax(axis=1)
x_int = pos % w
y_int = (pos - x_int) // w
# assert (roi_map_probs[k, y_int, x_int] ==
# roi_map_probs[k, :, :].max())
x = (x_int + 0.5) * width_correction
y = (y_int + 0.5) * height_correction
xy_preds[i, 0, :] = x + offset_x[i]
xy_preds[i, 1, :] = y + offset_y[i]
xy_preds[i, 2, :] = 1
end_scores[i, :] = roi_map[np.arange(num_keypoints), y_int, x_int]
return np.transpose(xy_preds, [0, 2, 1]), end_scores
class Keypointer(object):
"""
Projects a set of masks in an image on the locations
specified by the bounding boxes
"""
def __init__(self, padding=0):
self.padding = padding
def __call__(self, masks, boxes):
# TODO do this properly
if isinstance(boxes, BoxList):
boxes = [boxes]
assert len(boxes) == 1
result, scores = heatmaps_to_keypoints(
masks.detach().cpu().numpy(), boxes[0].bbox.cpu().numpy()
)
return torch.from_numpy(result).to(masks.device), torch.as_tensor(scores, device=masks.device)
def make_roi_keypoint_post_processor(cfg):
keypointer = Keypointer()
keypoint_post_processor = KeypointPostProcessor(keypointer)
return keypoint_post_processor
# In[40]:
@registry.ROI_KEYPOINT_PREDICTOR.register("KeypointRCNNPredictor")
class KeypointRCNNPredictor(nn.Module):
def __init__(self, cfg, in_channels):
super(KeypointRCNNPredictor, self).__init__()
input_features = in_channels
num_keypoints = cfg.MODEL.ROI_KEYPOINT_HEAD.NUM_CLASSES
deconv_kernel = 4
self.kps_score_lowres = layers.ConvTranspose2d(
input_features,
num_keypoints,
deconv_kernel,
stride=2,
padding=deconv_kernel // 2 - 1,
)
nn.init.kaiming_normal_(
self.kps_score_lowres.weight, mode="fan_out", nonlinearity="relu"
)
nn.init.constant_(self.kps_score_lowres.bias, 0)
self.up_scale = 2
self.out_channels = num_keypoints
def forward(self, x):
x = self.kps_score_lowres(x)
x = layers.interpolate(
x, scale_factor=self.up_scale, mode="bilinear", align_corners=False
)
return x
def make_roi_keypoint_predictor(cfg, in_channels):
func = registry.ROI_KEYPOINT_PREDICTOR[cfg.MODEL.ROI_KEYPOINT_HEAD.PREDICTOR]
return func(cfg, in_channels)
# In[41]:
@registry.ROI_KEYPOINT_FEATURE_EXTRACTORS.register("KeypointRCNNFeatureExtractor")
class KeypointRCNNFeatureExtractor(nn.Module):
def __init__(self, cfg, in_channels):
super(KeypointRCNNFeatureExtractor, self).__init__()
resolution = cfg.MODEL.ROI_KEYPOINT_HEAD.POOLER_RESOLUTION
scales = cfg.MODEL.ROI_KEYPOINT_HEAD.POOLER_SCALES
sampling_ratio = cfg.MODEL.ROI_KEYPOINT_HEAD.POOLER_SAMPLING_RATIO
pooler = Pooler(
output_size=(resolution, resolution),
scales=scales,
sampling_ratio=sampling_ratio,
)
self.pooler = pooler
input_features = in_channels
layers = cfg.MODEL.ROI_KEYPOINT_HEAD.CONV_LAYERS
next_feature = input_features
self.blocks = []
for layer_idx, layer_features in enumerate(layers, 1):
layer_name = "conv_fcn{}".format(layer_idx)
module = Conv2d(next_feature, layer_features, 3, stride=1, padding=1)
nn.init.kaiming_normal_(module.weight, mode="fan_out", nonlinearity="relu")
nn.init.constant_(module.bias, 0)
self.add_module(layer_name, module)
next_feature = layer_features
self.blocks.append(layer_name)
self.out_channels = layer_features
def forward(self, x, proposals):
x = self.pooler(x, proposals)
for layer_name in self.blocks:
x = FU.relu(getattr(self, layer_name)(x))
return x
def make_roi_keypoint_feature_extractor(cfg, in_channels):
func = registry.ROI_KEYPOINT_FEATURE_EXTRACTORS[
cfg.MODEL.ROI_KEYPOINT_HEAD.FEATURE_EXTRACTOR
]
return func(cfg, in_channels)
# In[42]:
def project_masks_on_boxes(segmentation_masks, proposals, discretization_size):
"""
Given segmentation masks and the bounding boxes corresponding
to the location of the masks in the image, this function
crops and resizes the masks in the position defined by the
boxes. This prepares the masks for them to be fed to the
loss computation as the targets.
Arguments:
segmentation_masks: an instance of SegmentationMask
proposals: an instance of BoxList
"""
masks = []
M = discretization_size
device = proposals.bbox.device
proposals = proposals.convert("xyxy")
assert segmentation_masks.size == proposals.size, "{}, {}".format(
segmentation_masks, proposals
)
# FIXME: CPU computation bottleneck, this should be parallelized
proposals = proposals.bbox.to(torch.device("cpu"))
for segmentation_mask, proposal in zip(segmentation_masks, proposals):
# crop the masks, resize them to the desired resolution and
# then convert them to the tensor representation.
cropped_mask = segmentation_mask.crop(proposal)
scaled_mask = cropped_mask.resize((M, M))
mask = scaled_mask.get_mask_tensor()
masks.append(mask)
if len(masks) == 0:
return torch.empty(0, dtype=torch.float32, device=device)
return torch.stack(masks, dim=0).to(device, dtype=torch.float32)
class MaskRCNNLossComputation(object):
def __init__(self, proposal_matcher, discretization_size):
"""
Arguments:
proposal_matcher (Matcher)
discretization_size (int)
"""
self.proposal_matcher = proposal_matcher
self.discretization_size = discretization_size
def match_targets_to_proposals(self, proposal, target):
match_quality_matrix = boxlist_iou(target, proposal)
matched_idxs = self.proposal_matcher(match_quality_matrix)
# Mask RCNN needs "labels" and "masks "fields for creating the targets
target = target.copy_with_fields(["labels", "masks"])
# get the targets corresponding GT for each proposal
# NB: need to clamp the indices because we can have a single
# GT in the image, and matched_idxs can be -2, which goes
# out of bounds
matched_targets = target[matched_idxs.clamp(min=0)]
matched_targets.add_field("matched_idxs", matched_idxs)
return matched_targets
def prepare_targets(self, proposals, targets):
labels = []
masks = []
for proposals_per_image, targets_per_image in zip(proposals, targets):
matched_targets = self.match_targets_to_proposals(
proposals_per_image, targets_per_image
)
matched_idxs = matched_targets.get_field("matched_idxs")
labels_per_image = matched_targets.get_field("labels")
labels_per_image = labels_per_image.to(dtype=torch.int64)
# this can probably be removed, but is left here for clarity
# and completeness
neg_inds = matched_idxs == Matcher.BELOW_LOW_THRESHOLD
labels_per_image[neg_inds] = 0
# mask scores are only computed on positive samples
positive_inds = torch.nonzero(labels_per_image > 0).squeeze(1)
segmentation_masks = matched_targets.get_field("masks")
segmentation_masks = segmentation_masks[positive_inds]
positive_proposals = proposals_per_image[positive_inds]
masks_per_image = project_masks_on_boxes(
segmentation_masks, positive_proposals, self.discretization_size
)
labels.append(labels_per_image)
masks.append(masks_per_image)
return labels, masks
def __call__(self, proposals, mask_logits, targets):
"""
Arguments:
proposals (list[BoxList])
mask_logits (Tensor)
targets (list[BoxList])
Return:
mask_loss (Tensor): scalar tensor containing the loss
"""
labels, mask_targets = self.prepare_targets(proposals, targets)
labels = cat(labels, dim=0)
mask_targets = cat(mask_targets, dim=0)
positive_inds = torch.nonzero(labels > 0).squeeze(1)
labels_pos = labels[positive_inds]
# torch.mean (in binary_cross_entropy_with_logits) doesn't
# accept empty tensors, so handle it separately
if mask_targets.numel() == 0:
return mask_logits.sum() * 0
mask_loss = FU.binary_cross_entropy_with_logits(
mask_logits[positive_inds, labels_pos], mask_targets
)
return mask_loss
def make_roi_mask_loss_evaluator(cfg):
matcher = Matcher(
cfg.MODEL.ROI_HEADS.FG_IOU_THRESHOLD,
cfg.MODEL.ROI_HEADS.BG_IOU_THRESHOLD,
allow_low_quality_matches=False,
)
loss_evaluator = MaskRCNNLossComputation(
matcher, cfg.MODEL.ROI_MASK_HEAD.RESOLUTION
)
return loss_evaluator
# In[43]:
class MaskPostProcessor(nn.Module):
"""
From the results of the CNN, post process the masks
by taking the mask corresponding to the class with max
probability (which are of fixed size and directly output
by the CNN) and return the masks in the mask field of the BoxList.
If a masker object is passed, it will additionally
project the masks in the image according to the locations in boxes,
"""
def __init__(self, masker=None):
super(MaskPostProcessor, self).__init__()
self.masker = masker
def forward(self, x, boxes):
"""
Arguments:
x (Tensor): the mask logits
boxes (list[BoxList]): bounding boxes that are used as
reference, one for ech image
Returns:
results (list[BoxList]): one BoxList for each image, containing
the extra field mask
"""
mask_prob = x.sigmoid()
# select masks coresponding to the predicted classes
num_masks = x.shape[0]
labels = [bbox.get_field("labels") for bbox in boxes]
labels = torch.cat(labels)
index = torch.arange(num_masks, device=labels.device)
mask_prob = mask_prob[index, labels][:, None]
boxes_per_image = [len(box) for box in boxes]
mask_prob = mask_prob.split(boxes_per_image, dim=0)
if self.masker:
mask_prob = self.masker(mask_prob, boxes)
results = []
for prob, box in zip(mask_prob, boxes):
bbox = BoxList(box.bbox, box.size, mode="xyxy")
for field in box.fields():
bbox.add_field(field, box.get_field(field))
bbox.add_field("mask", prob)
results.append(bbox)
return results
def expand_boxes(boxes, scale):
w_half = (boxes[:, 2] - boxes[:, 0]) * .5
h_half = (boxes[:, 3] - boxes[:, 1]) * .5
x_c = (boxes[:, 2] + boxes[:, 0]) * .5
y_c = (boxes[:, 3] + boxes[:, 1]) * .5
w_half *= scale
h_half *= scale
boxes_exp = torch.zeros_like(boxes)
boxes_exp[:, 0] = x_c - w_half
boxes_exp[:, 2] = x_c + w_half
boxes_exp[:, 1] = y_c - h_half
boxes_exp[:, 3] = y_c + h_half
return boxes_exp
def expand_masks(mask, padding):
N = mask.shape[0]
M = mask.shape[-1]
pad2 = 2 * padding
scale = float(M + pad2) / M
padded_mask = mask.new_zeros((N, 1, M + pad2, M + pad2))
padded_mask[:, :, padding:-padding, padding:-padding] = mask
return padded_mask, scale
def paste_mask_in_image(mask, box, im_h, im_w, thresh=0.5, padding=1):
# Need to work on the CPU, where fp16 isn't supported - cast to float to avoid this
mask = mask.float()
box = box.float()
padded_mask, scale = expand_masks(mask[None], padding=padding)
mask = padded_mask[0, 0]
box = expand_boxes(box[None], scale)[0]
box = box.to(dtype=torch.int32)
TO_REMOVE = 1
w = int(box[2] - box[0] + TO_REMOVE)
h = int(box[3] - box[1] + TO_REMOVE)
w = max(w, 1)
h = max(h, 1)
# Set shape to [batchxCxHxW]
mask = mask.expand((1, 1, -1, -1))
# Resize mask
mask = mask.to(torch.float32)
mask = interpolate(mask, size=(h, w), mode='bilinear', align_corners=False)
mask = mask[0][0]
if thresh >= 0:
mask = mask > thresh
else:
# for visualization and debugging, we also
# allow it to return an unmodified mask
mask = (mask * 255).to(torch.uint8)
im_mask = torch.zeros((im_h, im_w), dtype=torch.uint8)
x_0 = max(box[0], 0)
x_1 = min(box[2] + 1, im_w)
y_0 = max(box[1], 0)
y_1 = min(box[3] + 1, im_h)
im_mask[y_0:y_1, x_0:x_1] = mask[
(y_0 - box[1]) : (y_1 - box[1]), (x_0 - box[0]) : (x_1 - box[0])
]
return im_mask
class Masker(object):
"""
Projects a set of masks in an image on the locations
specified by the bounding boxes
"""
def __init__(self, threshold=0.5, padding=1):
self.threshold = threshold
self.padding = padding
def forward_single_image(self, masks, boxes):
boxes = boxes.convert("xyxy")
im_w, im_h = boxes.size
res = [
paste_mask_in_image(mask[0], box, im_h, im_w, self.threshold, self.padding)
for mask, box in zip(masks, boxes.bbox)
]
if len(res) > 0:
res = torch.stack(res, dim=0)[:, None]
else:
res = masks.new_empty((0, 1, masks.shape[-2], masks.shape[-1]))
return res
def __call__(self, masks, boxes):
if isinstance(boxes, BoxList):
boxes = [boxes]
# Make some sanity check
assert len(boxes) == len(masks), "Masks and boxes should have the same length."
# TODO: Is this JIT compatible?
# If not we should make it compatible.
results = []
for mask, box in zip(masks, boxes):
assert mask.shape[0] == len(box), "Number of objects should be the same."
result = self.forward_single_image(mask, box)
results.append(result)
return results
def make_roi_mask_post_processor(cfg):
if cfg.MODEL.ROI_MASK_HEAD.POSTPROCESS_MASKS:
mask_threshold = cfg.MODEL.ROI_MASK_HEAD.POSTPROCESS_MASKS_THRESHOLD
masker = Masker(threshold=mask_threshold, padding=1)
else:
masker = None
mask_post_processor = MaskPostProcessor(masker)
return mask_post_processor
# In[44]:
@registry.ROI_MASK_PREDICTOR.register("MaskRCNNC4Predictor")
class MaskRCNNC4Predictor(nn.Module):
def __init__(self, cfg, in_channels):
super(MaskRCNNC4Predictor, self).__init__()
num_classes = cfg.MODEL.ROI_BOX_HEAD.NUM_CLASSES
dim_reduced = cfg.MODEL.ROI_MASK_HEAD.CONV_LAYERS[-1]
num_inputs = in_channels
self.conv5_mask = ConvTranspose2d(num_inputs, dim_reduced, 2, 2, 0)
self.mask_fcn_logits = Conv2d(dim_reduced, num_classes, 1, 1, 0)
for name, param in self.named_parameters():
if "bias" in name:
nn.init.constant_(param, 0)
elif "weight" in name:
# Caffe2 implementation uses MSRAFill, which in fact
# corresponds to kaiming_normal_ in PyTorch
nn.init.kaiming_normal_(param, mode="fan_out", nonlinearity="relu")
def forward(self, x):
x = FU.relu(self.conv5_mask(x))
return self.mask_fcn_logits(x)
@registry.ROI_MASK_PREDICTOR.register("MaskRCNNConv1x1Predictor")
class MaskRCNNConv1x1Predictor(nn.Module):
def __init__(self, cfg, in_channels):
super(MaskRCNNConv1x1Predictor, self).__init__()
num_classes = cfg.MODEL.ROI_BOX_HEAD.NUM_CLASSES
num_inputs = in_channels
self.mask_fcn_logits = Conv2d(num_inputs, num_classes, 1, 1, 0)
for name, param in self.named_parameters():
if "bias" in name:
nn.init.constant_(param, 0)
elif "weight" in name:
# Caffe2 implementation uses MSRAFill, which in fact
# corresponds to kaiming_normal_ in PyTorch
nn.init.kaiming_normal_(param, mode="fan_out", nonlinearity="relu")
def forward(self, x):
return self.mask_fcn_logits(x)
def make_roi_mask_predictor(cfg, in_channels):
func = registry.ROI_MASK_PREDICTOR[cfg.MODEL.ROI_MASK_HEAD.PREDICTOR]
return func(cfg, in_channels)
# In[45]:
registry.ROI_MASK_FEATURE_EXTRACTORS.register(
"ResNet50Conv5ROIFeatureExtractor", ResNet50Conv5ROIFeatureExtractor
)
@registry.ROI_MASK_FEATURE_EXTRACTORS.register("MaskRCNNFPNFeatureExtractor")
class MaskRCNNFPNFeatureExtractor(nn.Module):
"""
Heads for FPN for classification
"""
def __init__(self, cfg, in_channels):
"""
Arguments:
num_classes (int): number of output classes
input_size (int): number of channels of the input once it's flattened
representation_size (int): size of the intermediate representation
"""
super(MaskRCNNFPNFeatureExtractor, self).__init__()
resolution = cfg.MODEL.ROI_MASK_HEAD.POOLER_RESOLUTION
scales = cfg.MODEL.ROI_MASK_HEAD.POOLER_SCALES
sampling_ratio = cfg.MODEL.ROI_MASK_HEAD.POOLER_SAMPLING_RATIO
pooler = Pooler(
output_size=(resolution, resolution),
scales=scales,
sampling_ratio=sampling_ratio,
)
input_size = in_channels
self.pooler = pooler
use_gn = cfg.MODEL.ROI_MASK_HEAD.USE_GN
layers = cfg.MODEL.ROI_MASK_HEAD.CONV_LAYERS
dilation = cfg.MODEL.ROI_MASK_HEAD.DILATION
next_feature = input_size
self.blocks = []
for layer_idx, layer_features in enumerate(layers, 1):
layer_name = "mask_fcn{}".format(layer_idx)
module = make_conv3x3(
next_feature, layer_features,
dilation=dilation, stride=1, use_gn=use_gn
)
self.add_module(layer_name, module)
next_feature = layer_features
self.blocks.append(layer_name)
self.out_channels = layer_features
def forward(self, x, proposals):
x = self.pooler(x, proposals)
for layer_name in self.blocks:
x = FU.relu(getattr(self, layer_name)(x))
return x
def make_roi_mask_feature_extractor(cfg, in_channels):
func = registry.ROI_MASK_FEATURE_EXTRACTORS[
cfg.MODEL.ROI_MASK_HEAD.FEATURE_EXTRACTOR
]
return func(cfg, in_channels)
# In[46]:
class FastRCNNLossComputation(object):
"""
Computes the loss for Faster R-CNN.
Also supports FPN
"""
def __init__(
self,
proposal_matcher,
fg_bg_sampler,
box_coder,
cls_agnostic_bbox_reg=False
):
"""
Arguments:
proposal_matcher (Matcher)
fg_bg_sampler (BalancedPositiveNegativeSampler)
box_coder (BoxCoder)
"""
self.proposal_matcher = proposal_matcher
self.fg_bg_sampler = fg_bg_sampler
self.box_coder = box_coder
self.cls_agnostic_bbox_reg = cls_agnostic_bbox_reg
def match_targets_to_proposals(self, proposal, target):
match_quality_matrix = boxlist_iou(target, proposal)
matched_idxs = self.proposal_matcher(match_quality_matrix)
# Fast RCNN only need "labels" field for selecting the targets
target = target.copy_with_fields("labels")
# get the targets corresponding GT for each proposal
# NB: need to clamp the indices because we can have a single
# GT in the image, and matched_idxs can be -2, which goes
# out of bounds
matched_targets = target[matched_idxs.clamp(min=0)]
matched_targets.add_field("matched_idxs", matched_idxs)
return matched_targets
def prepare_targets(self, proposals, targets):
labels = []
regression_targets = []
for proposals_per_image, targets_per_image in zip(proposals, targets):
matched_targets = self.match_targets_to_proposals(
proposals_per_image, targets_per_image
)
matched_idxs = matched_targets.get_field("matched_idxs")
labels_per_image = matched_targets.get_field("labels")
labels_per_image = labels_per_image.to(dtype=torch.int64)
# Label background (below the low threshold)
bg_inds = matched_idxs == Matcher.BELOW_LOW_THRESHOLD
labels_per_image[bg_inds] = 0
# Label ignore proposals (between low and high thresholds)
ignore_inds = matched_idxs == Matcher.BETWEEN_THRESHOLDS
labels_per_image[ignore_inds] = -1 # -1 is ignored by sampler
# compute regression targets
regression_targets_per_image = self.box_coder.encode(
matched_targets.bbox, proposals_per_image.bbox
)
labels.append(labels_per_image)
regression_targets.append(regression_targets_per_image)
return labels, regression_targets
def subsample(self, proposals, targets):
"""
This method performs the positive/negative sampling, and return
the sampled proposals.
Note: this function keeps a state.
Arguments:
proposals (list[BoxList])
targets (list[BoxList])
"""
labels, regression_targets = self.prepare_targets(proposals, targets)
sampled_pos_inds, sampled_neg_inds = self.fg_bg_sampler(labels)
proposals = list(proposals)
# add corresponding label and regression_targets information to the bounding boxes
for labels_per_image, regression_targets_per_image, proposals_per_image in zip(
labels, regression_targets, proposals
):
proposals_per_image.add_field("labels", labels_per_image)
proposals_per_image.add_field(
"regression_targets", regression_targets_per_image
)
# distributed sampled proposals, that were obtained on all feature maps
# concatenated via the fg_bg_sampler, into individual feature map levels
for img_idx, (pos_inds_img, neg_inds_img) in enumerate(
zip(sampled_pos_inds, sampled_neg_inds)
):
img_sampled_inds = torch.nonzero(pos_inds_img | neg_inds_img).squeeze(1)
proposals_per_image = proposals[img_idx][img_sampled_inds]
proposals[img_idx] = proposals_per_image
self._proposals = proposals
return proposals
def __call__(self, class_logits, box_regression):
"""
Computes the loss for Faster R-CNN.
This requires that the subsample method has been called beforehand.
Arguments:
class_logits (list[Tensor])
box_regression (list[Tensor])
Returns:
classification_loss (Tensor)
box_loss (Tensor)
"""
class_logits = cat(class_logits, dim=0)
box_regression = cat(box_regression, dim=0)
device = class_logits.device
if not hasattr(self, "_proposals"):
raise RuntimeError("subsample needs to be called before")
proposals = self._proposals
labels = cat([proposal.get_field("labels") for proposal in proposals], dim=0)
regression_targets = cat(
[proposal.get_field("regression_targets") for proposal in proposals], dim=0
)
classification_loss = FU.cross_entropy(class_logits, labels)
# get indices that correspond to the regression targets for
# the corresponding ground truth labels, to be used with
# advanced indexing
sampled_pos_inds_subset = torch.nonzero(labels > 0).squeeze(1)
labels_pos = labels[sampled_pos_inds_subset]
if self.cls_agnostic_bbox_reg:
map_inds = torch.tensor([4, 5, 6, 7], device=device)
else:
map_inds = 4 * labels_pos[:, None] + torch.tensor(
[0, 1, 2, 3], device=device)
box_loss = smooth_l1_loss(
box_regression[sampled_pos_inds_subset[:, None], map_inds],
regression_targets[sampled_pos_inds_subset],
size_average=False,
beta=1,
)
box_loss = box_loss / labels.numel()
return classification_loss, box_loss
def make_roi_box_loss_evaluator(cfg):
matcher = Matcher(
cfg.MODEL.ROI_HEADS.FG_IOU_THRESHOLD,
cfg.MODEL.ROI_HEADS.BG_IOU_THRESHOLD,
allow_low_quality_matches=False,
)
bbox_reg_weights = cfg.MODEL.ROI_HEADS.BBOX_REG_WEIGHTS
box_coder = BoxCoder(weights=bbox_reg_weights)
fg_bg_sampler = BalancedPositiveNegativeSampler(
cfg.MODEL.ROI_HEADS.BATCH_SIZE_PER_IMAGE, cfg.MODEL.ROI_HEADS.POSITIVE_FRACTION
)
cls_agnostic_bbox_reg = cfg.MODEL.CLS_AGNOSTIC_BBOX_REG
loss_evaluator = FastRCNNLossComputation(
matcher,
fg_bg_sampler,
box_coder,
cls_agnostic_bbox_reg
)
return loss_evaluator
# In[47]:
class PostProcessor(nn.Module):
"""
From a set of classification scores, box regression and proposals,
computes the post-processed boxes, and applies NMS to obtain the
final results
"""
def __init__(
self,
score_thresh=0.05,
nms=0.5,
detections_per_img=100,
box_coder=None,
cls_agnostic_bbox_reg=False,
bbox_aug_enabled=False
):
"""
Arguments:
score_thresh (float)
nms (float)
detections_per_img (int)
box_coder (BoxCoder)
"""
super(PostProcessor, self).__init__()
self.score_thresh = score_thresh
self.nms = nms
self.detections_per_img = detections_per_img
if box_coder is None:
box_coder = BoxCoder(weights=(10., 10., 5., 5.))
self.box_coder = box_coder
self.cls_agnostic_bbox_reg = cls_agnostic_bbox_reg
self.bbox_aug_enabled = bbox_aug_enabled
def forward(self, x, boxes):
"""
Arguments:
x (tuple[tensor, tensor]): x contains the class logits
and the box_regression from the model.
boxes (list[BoxList]): bounding boxes that are used as
reference, one for ech image
Returns:
results (list[BoxList]): one BoxList for each image, containing
the extra fields labels and scores
"""
class_logits, box_regression = x
class_prob = FUC.softmax(class_logits, -1)
# TODO think about a representation of batch of boxes
image_shapes = [box.size for box in boxes]
boxes_per_image = [len(box) for box in boxes]
concat_boxes = torch.cat([a.bbox for a in boxes], dim=0)
if self.cls_agnostic_bbox_reg:
box_regression = box_regression[:, -4:]
proposals = self.box_coder.decode(
box_regression.view(sum(boxes_per_image), -1), concat_boxes
)
if self.cls_agnostic_bbox_reg:
proposals = proposals.repeat(1, class_prob.shape[1])
num_classes = class_prob.shape[1]
proposals = proposals.split(boxes_per_image, dim=0)
class_prob = class_prob.split(boxes_per_image, dim=0)
results = []
for prob, boxes_per_img, image_shape in zip(
class_prob, proposals, image_shapes
):
boxlist = self.prepare_boxlist(boxes_per_img, prob, image_shape)
boxlist = boxlist.clip_to_image(remove_empty=False)
if not self.bbox_aug_enabled: # If bbox aug is enabled, we will do it later
boxlist = self.filter_results(boxlist, num_classes)
results.append(boxlist)
return results
def prepare_boxlist(self, boxes, scores, image_shape):
"""
Returns BoxList from `boxes` and adds probability scores information
as an extra field
`boxes` has shape (#detections, 4 * #classes), where each row represents
a list of predicted bounding boxes for each of the object classes in the
dataset (including the background class). The detections in each row
originate from the same object proposal.
`scores` has shape (#detection, #classes), where each row represents a list
of object detection confidence scores for each of the object classes in the
dataset (including the background class). `scores[i, j]`` corresponds to the
box at `boxes[i, j * 4:(j + 1) * 4]`.
"""
boxes = boxes.reshape(-1, 4)
scores = scores.reshape(-1)
boxlist = BoxList(boxes, image_shape, mode="xyxy")
boxlist.add_field("scores", scores)
return boxlist
def filter_results(self, boxlist, num_classes):
"""Returns bounding-box detection results by thresholding on scores and
applying non-maximum suppression (NMS).
"""
# unwrap the boxlist to avoid additional overhead.
# if we had multi-class NMS, we could perform this directly on the boxlist
boxes = boxlist.bbox.reshape(-1, num_classes * 4)
scores = boxlist.get_field("scores").reshape(-1, num_classes)
device = scores.device
result = []
# Apply threshold on detection probabilities and apply NMS
# Skip j = 0, because it's the background class
inds_all = scores > self.score_thresh
for j in range(1, num_classes):
inds = inds_all[:, j].nonzero().squeeze(1)
scores_j = scores[inds, j]
boxes_j = boxes[inds, j * 4 : (j + 1) * 4]
boxlist_for_class = BoxList(boxes_j, boxlist.size, mode="xyxy")
boxlist_for_class.add_field("scores", scores_j)
boxlist_for_class = boxlist_nms(
boxlist_for_class, self.nms
)
num_labels = len(boxlist_for_class)
boxlist_for_class.add_field(
"labels", torch.full((num_labels,), j, dtype=torch.int64, device=device)
)
result.append(boxlist_for_class)
result = cat_boxlist(result)
number_of_detections = len(result)
# Limit to max_per_image detections **over all classes**
if number_of_detections > self.detections_per_img > 0:
cls_scores = result.get_field("scores")
image_thresh, _ = torch.kthvalue(
cls_scores.cpu(), number_of_detections - self.detections_per_img + 1
)
keep = cls_scores >= image_thresh.item()
keep = torch.nonzero(keep).squeeze(1)
result = result[keep]
return result
def make_roi_box_post_processor(cfg):
use_fpn = cfg.MODEL.ROI_HEADS.USE_FPN
bbox_reg_weights = cfg.MODEL.ROI_HEADS.BBOX_REG_WEIGHTS
box_coder = BoxCoder(weights=bbox_reg_weights)
score_thresh = cfg.MODEL.ROI_HEADS.SCORE_THRESH
nms_thresh = cfg.MODEL.ROI_HEADS.NMS
detections_per_img = cfg.MODEL.ROI_HEADS.DETECTIONS_PER_IMG
cls_agnostic_bbox_reg = cfg.MODEL.CLS_AGNOSTIC_BBOX_REG
bbox_aug_enabled = cfg.TEST.BBOX_AUG.ENABLED
postprocessor = PostProcessor(
score_thresh,
nms_thresh,
detections_per_img,
box_coder,
cls_agnostic_bbox_reg,
bbox_aug_enabled
)
return postprocessor
# In[48]:
@registry.ROI_BOX_PREDICTOR.register("FPNPredictor")
class FPNPredictor(nn.Module):
def __init__(self, cfg, in_channels):
super(FPNPredictor, self).__init__()
num_classes = cfg.MODEL.ROI_BOX_HEAD.NUM_CLASSES
representation_size = in_channels
self.cls_score = nn.Linear(representation_size, num_classes)
num_bbox_reg_classes = 2 if cfg.MODEL.CLS_AGNOSTIC_BBOX_REG else num_classes
self.bbox_pred = nn.Linear(representation_size, num_bbox_reg_classes * 4)
nn.init.normal_(self.cls_score.weight, std=0.01)
nn.init.normal_(self.bbox_pred.weight, std=0.001)
for l in [self.cls_score, self.bbox_pred]:
nn.init.constant_(l.bias, 0)
def forward(self, x):
if x.ndimension() == 4:
assert list(x.shape[2:]) == [1, 1]
x = x.view(x.size(0), -1)
scores = self.cls_score(x)
bbox_deltas = self.bbox_pred(x)
return scores, bbox_deltas
def make_roi_box_predictor(cfg, in_channels):
func = registry.ROI_BOX_PREDICTOR[cfg.MODEL.ROI_BOX_HEAD.PREDICTOR]
return func(cfg, in_channels)
# In[49]:
def make_roi_box_feature_extractor(cfg, in_channels):
func = registry.ROI_BOX_FEATURE_EXTRACTORS[
cfg.MODEL.ROI_BOX_HEAD.FEATURE_EXTRACTOR
]
return func(cfg, in_channels)
# In[50]:
class RPNPostProcessor(torch.nn.Module):
"""
Performs post-processing on the outputs of the RPN boxes, before feeding the
proposals to the heads
"""
def __init__(
self,
pre_nms_top_n,
post_nms_top_n,
nms_thresh,
min_size,
box_coder=None,
fpn_post_nms_top_n=None,
fpn_post_nms_per_batch=True,
):
"""
Arguments:
pre_nms_top_n (int)
post_nms_top_n (int)
nms_thresh (float)
min_size (int)
box_coder (BoxCoder)
fpn_post_nms_top_n (int)
"""
super(RPNPostProcessor, self).__init__()
self.pre_nms_top_n = pre_nms_top_n
self.post_nms_top_n = post_nms_top_n
self.nms_thresh = nms_thresh
self.min_size = min_size
if box_coder is None:
box_coder = BoxCoder(weights=(1.0, 1.0, 1.0, 1.0))
self.box_coder = box_coder
if fpn_post_nms_top_n is None:
fpn_post_nms_top_n = post_nms_top_n
self.fpn_post_nms_top_n = fpn_post_nms_top_n
self.fpn_post_nms_per_batch = fpn_post_nms_per_batch
def add_gt_proposals(self, proposals, targets):
"""
Arguments:
proposals: list[BoxList]
targets: list[BoxList]
"""
# Get the device we're operating on
device = proposals[0].bbox.device
gt_boxes = [target.copy_with_fields([]) for target in targets]
# later cat of bbox requires all fields to be present for all bbox
# so we need to add a dummy for objectness that's missing
for gt_box in gt_boxes:
gt_box.add_field("objectness", torch.ones(len(gt_box), device=device))
proposals = [
cat_boxlist((proposal, gt_box))
for proposal, gt_box in zip(proposals, gt_boxes)
]
return proposals
def forward_for_single_feature_map(self, anchors, objectness, box_regression):
"""
Arguments:
anchors: list[BoxList]
objectness: tensor of size N, A, H, W
box_regression: tensor of size N, A * 4, H, W
"""
device = objectness.device
N, A, H, W = objectness.shape
# put in the same format as anchors
objectness = permute_and_flatten(objectness, N, A, 1, H, W).view(N, -1)
objectness = objectness.sigmoid()
box_regression = permute_and_flatten(box_regression, N, A, 4, H, W)
num_anchors = A * H * W
pre_nms_top_n = min(self.pre_nms_top_n, num_anchors)
objectness, topk_idx = objectness.topk(pre_nms_top_n, dim=1, sorted=True)
batch_idx = torch.arange(N, device=device)[:, None]
box_regression = box_regression[batch_idx, topk_idx]
image_shapes = [box.size for box in anchors]
concat_anchors = torch.cat([a.bbox for a in anchors], dim=0)
concat_anchors = concat_anchors.reshape(N, -1, 4)[batch_idx, topk_idx]
proposals = self.box_coder.decode(
box_regression.view(-1, 4), concat_anchors.view(-1, 4)
)
proposals = proposals.view(N, -1, 4)
result = []
for proposal, score, im_shape in zip(proposals, objectness, image_shapes):
boxlist = BoxList(proposal, im_shape, mode="xyxy")
boxlist.add_field("objectness", score)
boxlist = boxlist.clip_to_image(remove_empty=False)
boxlist = remove_small_boxes(boxlist, self.min_size)
boxlist = boxlist_nms(
boxlist,
self.nms_thresh,
max_proposals=self.post_nms_top_n,
score_field="objectness",
)
result.append(boxlist)
return result
def forward(self, anchors, objectness, box_regression, targets=None):
"""
Arguments:
anchors: list[list[BoxList]]
objectness: list[tensor]
box_regression: list[tensor]
Returns:
boxlists (list[BoxList]): the post-processed anchors, after
applying box decoding and NMS
"""
sampled_boxes = []
num_levels = len(objectness)
anchors = list(zip(*anchors))
for a, o, b in zip(anchors, objectness, box_regression):
sampled_boxes.append(self.forward_for_single_feature_map(a, o, b))
boxlists = list(zip(*sampled_boxes))
boxlists = [cat_boxlist(boxlist) for boxlist in boxlists]
if num_levels > 1:
boxlists = self.select_over_all_levels(boxlists)
# append ground-truth bboxes to proposals
if self.training and targets is not None:
boxlists = self.add_gt_proposals(boxlists, targets)
return boxlists
def select_over_all_levels(self, boxlists):
num_images = len(boxlists)
# different behavior during training and during testing:
# during training, post_nms_top_n is over *all* the proposals combined, while
# during testing, it is over the proposals for each image
# NOTE: it should be per image, and not per batch. However, to be consistent
# with Detectron, the default is per batch (see Issue #672)
if self.training and self.fpn_post_nms_per_batch:
objectness = torch.cat(
[boxlist.get_field("objectness") for boxlist in boxlists], dim=0
)
box_sizes = [len(boxlist) for boxlist in boxlists]
post_nms_top_n = min(self.fpn_post_nms_top_n, len(objectness))
_, inds_sorted = torch.topk(objectness, post_nms_top_n, dim=0, sorted=True)
inds_mask = torch.zeros_like(objectness, dtype=torch.uint8)
inds_mask[inds_sorted] = 1
inds_mask = inds_mask.split(box_sizes)
for i in range(num_images):
boxlists[i] = boxlists[i][inds_mask[i]]
else:
for i in range(num_images):
objectness = boxlists[i].get_field("objectness")
post_nms_top_n = min(self.fpn_post_nms_top_n, len(objectness))
_, inds_sorted = torch.topk(
objectness, post_nms_top_n, dim=0, sorted=True
)
boxlists[i] = boxlists[i][inds_sorted]
return boxlists
def make_rpn_postprocessor(config, rpn_box_coder, is_train):
fpn_post_nms_top_n = config.MODEL.RPN.FPN_POST_NMS_TOP_N_TRAIN
if not is_train:
fpn_post_nms_top_n = config.MODEL.RPN.FPN_POST_NMS_TOP_N_TEST
pre_nms_top_n = config.MODEL.RPN.PRE_NMS_TOP_N_TRAIN
post_nms_top_n = config.MODEL.RPN.POST_NMS_TOP_N_TRAIN
if not is_train:
pre_nms_top_n = config.MODEL.RPN.PRE_NMS_TOP_N_TEST
post_nms_top_n = config.MODEL.RPN.POST_NMS_TOP_N_TEST
fpn_post_nms_per_batch = config.MODEL.RPN.FPN_POST_NMS_PER_BATCH
nms_thresh = config.MODEL.RPN.NMS_THRESH
min_size = config.MODEL.RPN.MIN_SIZE
box_selector = RPNPostProcessor(
pre_nms_top_n=pre_nms_top_n,
post_nms_top_n=post_nms_top_n,
nms_thresh=nms_thresh,
min_size=min_size,
box_coder=rpn_box_coder,
fpn_post_nms_top_n=fpn_post_nms_top_n,
fpn_post_nms_per_batch=fpn_post_nms_per_batch,
)
return box_selector
# In[51]:
class BufferList(nn.Module):
"""
Similar to nn.ParameterList, but for buffers
"""
def __init__(self, buffers=None):
super(BufferList, self).__init__()
if buffers is not None:
self.extend(buffers)
def extend(self, buffers):
offset = len(self)
for i, buffer in enumerate(buffers):
self.register_buffer(str(offset + i), buffer)
return self
def __len__(self):
return len(self._buffers)
def __iter__(self):
return iter(self._buffers.values())
class AnchorGenerator(nn.Module):
"""
For a set of image sizes and feature maps, computes a set
of anchors
"""
def __init__(
self,
sizes=(128, 256, 512),
aspect_ratios=(0.5, 1.0, 2.0),
anchor_strides=(8, 16, 32),
straddle_thresh=0,
):
super(AnchorGenerator, self).__init__()
if len(anchor_strides) == 1:
anchor_stride = anchor_strides[0]
cell_anchors = [
generate_anchors(anchor_stride, sizes, aspect_ratios).float()
]
else:
if len(anchor_strides) != len(sizes):
raise RuntimeError("FPN should have #anchor_strides == #sizes")
cell_anchors = [
generate_anchors(
anchor_stride,
size if isinstance(size, (tuple, list)) else (size,),
aspect_ratios
).float()
for anchor_stride, size in zip(anchor_strides, sizes)
]
self.strides = anchor_strides
self.cell_anchors = BufferList(cell_anchors)
self.straddle_thresh = straddle_thresh
def num_anchors_per_location(self):
return [len(cell_anchors) for cell_anchors in self.cell_anchors]
def grid_anchors(self, grid_sizes):
anchors = []
for size, stride, base_anchors in zip(
grid_sizes, self.strides, self.cell_anchors
):
grid_height, grid_width = size
device = base_anchors.device
shifts_x = torch.arange(
0, grid_width * stride, step=stride, dtype=torch.float32, device=device
)
shifts_y = torch.arange(
0, grid_height * stride, step=stride, dtype=torch.float32, device=device
)
shift_y, shift_x = torch.meshgrid(shifts_y, shifts_x)
shift_x = shift_x.reshape(-1)
shift_y = shift_y.reshape(-1)
shifts = torch.stack((shift_x, shift_y, shift_x, shift_y), dim=1)
anchors.append(
(shifts.view(-1, 1, 4) + base_anchors.view(1, -1, 4)).reshape(-1, 4)
)
return anchors
def add_visibility_to(self, boxlist):
image_width, image_height = boxlist.size
anchors = boxlist.bbox
if self.straddle_thresh >= 0:
inds_inside = (
(anchors[..., 0] >= -self.straddle_thresh)
& (anchors[..., 1] >= -self.straddle_thresh)
& (anchors[..., 2] < image_width + self.straddle_thresh)
& (anchors[..., 3] < image_height + self.straddle_thresh)
)
else:
device = anchors.device
inds_inside = torch.ones(anchors.shape[0], dtype=torch.uint8, device=device)
boxlist.add_field("visibility", inds_inside)
def forward(self, image_list, feature_maps):
grid_sizes = [feature_map.shape[-2:] for feature_map in feature_maps]
anchors_over_all_feature_maps = self.grid_anchors(grid_sizes)
anchors = []
for i, (image_height, image_width) in enumerate(image_list.image_sizes):
anchors_in_image = []
for anchors_per_feature_map in anchors_over_all_feature_maps:
boxlist = BoxList(
anchors_per_feature_map, (image_width, image_height), mode="xyxy"
)
self.add_visibility_to(boxlist)
anchors_in_image.append(boxlist)
anchors.append(anchors_in_image)
return anchors
def make_anchor_generator(config):
anchor_sizes = config.MODEL.RPN.ANCHOR_SIZES
aspect_ratios = config.MODEL.RPN.ASPECT_RATIOS
anchor_stride = config.MODEL.RPN.ANCHOR_STRIDE
straddle_thresh = config.MODEL.RPN.STRADDLE_THRESH
if config.MODEL.RPN.USE_FPN:
assert len(anchor_stride) == len(
anchor_sizes
), "FPN should have len(ANCHOR_STRIDE) == len(ANCHOR_SIZES)"
else:
assert len(anchor_stride) == 1, "Non-FPN should have a single ANCHOR_STRIDE"
anchor_generator = AnchorGenerator(
anchor_sizes, aspect_ratios, anchor_stride, straddle_thresh
)
return anchor_generator
def make_anchor_generator_retinanet(config):
anchor_sizes = config.MODEL.RETINANET.ANCHOR_SIZES
aspect_ratios = config.MODEL.RETINANET.ASPECT_RATIOS
anchor_strides = config.MODEL.RETINANET.ANCHOR_STRIDES
straddle_thresh = config.MODEL.RETINANET.STRADDLE_THRESH
octave = config.MODEL.RETINANET.OCTAVE
scales_per_octave = config.MODEL.RETINANET.SCALES_PER_OCTAVE
assert len(anchor_strides) == len(anchor_sizes), "Only support FPN now"
new_anchor_sizes = []
for size in anchor_sizes:
per_layer_anchor_sizes = []
for scale_per_octave in range(scales_per_octave):
octave_scale = octave ** (scale_per_octave / float(scales_per_octave))
per_layer_anchor_sizes.append(octave_scale * size)
new_anchor_sizes.append(tuple(per_layer_anchor_sizes))
anchor_generator = AnchorGenerator(
tuple(new_anchor_sizes), aspect_ratios, anchor_strides, straddle_thresh
)
return anchor_generator
def generate_anchors(
stride=16, sizes=(32, 64, 128, 256, 512), aspect_ratios=(0.5, 1, 2)
):
"""Generates a matrix of anchor boxes in (x1, y1, x2, y2) format. Anchors
are centered on stride / 2, have (approximate) sqrt areas of the specified
sizes, and aspect ratios as given.
"""
return _generate_anchors(
stride,
np.array(sizes, dtype=np.float) / stride,
np.array(aspect_ratios, dtype=np.float),
)
def _generate_anchors(base_size, scales, aspect_ratios):
"""Generate anchor (reference) windows by enumerating aspect ratios X
scales wrt a reference (0, 0, base_size - 1, base_size - 1) window.
"""
anchor = np.array([1, 1, base_size, base_size], dtype=np.float) - 1
anchors = _ratio_enum(anchor, aspect_ratios)
anchors = np.vstack(
[_scale_enum(anchors[i, :], scales) for i in range(anchors.shape[0])]
)
return torch.from_numpy(anchors)
def _whctrs(anchor):
"""Return width, height, x center, and y center for an anchor (window)."""
w = anchor[2] - anchor[0] + 1
h = anchor[3] - anchor[1] + 1
x_ctr = anchor[0] + 0.5 * (w - 1)
y_ctr = anchor[1] + 0.5 * (h - 1)
return w, h, x_ctr, y_ctr
def _mkanchors(ws, hs, x_ctr, y_ctr):
"""Given a vector of widths (ws) and heights (hs) around a center
(x_ctr, y_ctr), output a set of anchors (windows).
"""
ws = ws[:, np.newaxis]
hs = hs[:, np.newaxis]
anchors = np.hstack(
(
x_ctr - 0.5 * (ws - 1),
y_ctr - 0.5 * (hs - 1),
x_ctr + 0.5 * (ws - 1),
y_ctr + 0.5 * (hs - 1),
)
)
return anchors
def _ratio_enum(anchor, ratios):
"""Enumerate a set of anchors for each aspect ratio wrt an anchor."""
w, h, x_ctr, y_ctr = _whctrs(anchor)
size = w * h
size_ratios = size / ratios
ws = np.round(np.sqrt(size_ratios))
hs = np.round(ws * ratios)
anchors = _mkanchors(ws, hs, x_ctr, y_ctr)
return anchors
def _scale_enum(anchor, scales):
"""Enumerate a set of anchors for each scale wrt an anchor."""
w, h, x_ctr, y_ctr = _whctrs(anchor)
ws = w * scales
hs = h * scales
anchors = _mkanchors(ws, hs, x_ctr, y_ctr)
return anchors
# In[52]:
class RPNLossComputation(object):
"""
This class computes the RPN loss.
"""
def __init__(self, proposal_matcher, fg_bg_sampler, box_coder,
generate_labels_func):
"""
Arguments:
proposal_matcher (Matcher)
fg_bg_sampler (BalancedPositiveNegativeSampler)
box_coder (BoxCoder)
"""
# self.target_preparator = target_preparator
self.proposal_matcher = proposal_matcher
self.fg_bg_sampler = fg_bg_sampler
self.box_coder = box_coder
self.copied_fields = []
self.generate_labels_func = generate_labels_func
self.discard_cases = ['not_visibility', 'between_thresholds']
def match_targets_to_anchors(self, anchor, target, copied_fields=[]):
match_quality_matrix = boxlist_iou(target, anchor)
matched_idxs = self.proposal_matcher(match_quality_matrix)
# RPN doesn't need any fields from target
# for creating the labels, so clear them all
target = target.copy_with_fields(copied_fields)
# get the targets corresponding GT for each anchor
# NB: need to clamp the indices because we can have a single
# GT in the image, and matched_idxs can be -2, which goes
# out of bounds
matched_targets = target[matched_idxs.clamp(min=0)]
matched_targets.add_field("matched_idxs", matched_idxs)
return matched_targets
def prepare_targets(self, anchors, targets):
labels = []
regression_targets = []
for anchors_per_image, targets_per_image in zip(anchors, targets):
matched_targets = self.match_targets_to_anchors(
anchors_per_image, targets_per_image, self.copied_fields
)
matched_idxs = matched_targets.get_field("matched_idxs")
labels_per_image = self.generate_labels_func(matched_targets)
labels_per_image = labels_per_image.to(dtype=torch.float32)
# Background (negative examples)
bg_indices = matched_idxs == Matcher.BELOW_LOW_THRESHOLD
labels_per_image[bg_indices] = 0
# discard anchors that go out of the boundaries of the image
if "not_visibility" in self.discard_cases:
labels_per_image[~anchors_per_image.get_field("visibility")] = -1
# discard indices that are between thresholds
if "between_thresholds" in self.discard_cases:
inds_to_discard = matched_idxs == Matcher.BETWEEN_THRESHOLDS
labels_per_image[inds_to_discard] = -1
# compute regression targets
regression_targets_per_image = self.box_coder.encode(
matched_targets.bbox, anchors_per_image.bbox
)
labels.append(labels_per_image)
regression_targets.append(regression_targets_per_image)
return labels, regression_targets
def __call__(self, anchors, objectness, box_regression, targets):
"""
Arguments:
anchors (list[BoxList])
objectness (list[Tensor])
box_regression (list[Tensor])
targets (list[BoxList])
Returns:
objectness_loss (Tensor)
box_loss (Tensor
"""
anchors = [cat_boxlist(anchors_per_image) for anchors_per_image in anchors]
labels, regression_targets = self.prepare_targets(anchors, targets)
sampled_pos_inds, sampled_neg_inds = self.fg_bg_sampler(labels)
sampled_pos_inds = torch.nonzero(torch.cat(sampled_pos_inds, dim=0)).squeeze(1)
sampled_neg_inds = torch.nonzero(torch.cat(sampled_neg_inds, dim=0)).squeeze(1)
sampled_inds = torch.cat([sampled_pos_inds, sampled_neg_inds], dim=0)
objectness, box_regression = concat_box_prediction_layers(objectness, box_regression)
objectness = objectness.squeeze()
labels = torch.cat(labels, dim=0)
regression_targets = torch.cat(regression_targets, dim=0)
box_loss = smooth_l1_loss(
box_regression[sampled_pos_inds],
regression_targets[sampled_pos_inds],
beta=1.0 / 9,
size_average=False,
) / (sampled_inds.numel())
objectness_loss = F.binary_cross_entropy_with_logits(
objectness[sampled_inds], labels[sampled_inds]
)
return objectness_loss, box_loss
# This function should be overwritten in RetinaNet
def generate_rpn_labels(matched_targets):
matched_idxs = matched_targets.get_field("matched_idxs")
labels_per_image = matched_idxs >= 0
return labels_per_image
def make_rpn_loss_evaluator(cfg, box_coder):
matcher = Matcher(
cfg.MODEL.RPN.FG_IOU_THRESHOLD,
cfg.MODEL.RPN.BG_IOU_THRESHOLD,
allow_low_quality_matches=True,
)
fg_bg_sampler = BalancedPositiveNegativeSampler(
cfg.MODEL.RPN.BATCH_SIZE_PER_IMAGE, cfg.MODEL.RPN.POSITIVE_FRACTION
)
loss_evaluator = RPNLossComputation(
matcher,
fg_bg_sampler,
box_coder,
generate_rpn_labels
)
return loss_evaluator
# In[53]:
class BufferList(nn.Module):
"""
Similar to nn.ParameterList, but for buffers
"""
def __init__(self, buffers=None):
super(BufferList, self).__init__()
if buffers is not None:
self.extend(buffers)
def extend(self, buffers):
offset = len(self)
for i, buffer in enumerate(buffers):
self.register_buffer(str(offset + i), buffer)
return self
def __len__(self):
return len(self._buffers)
def __iter__(self):
return iter(self._buffers.values())
class AnchorGenerator(nn.Module):
"""
For a set of image sizes and feature maps, computes a set
of anchors
"""
def __init__(
self,
sizes=(128, 256, 512),
aspect_ratios=(0.5, 1.0, 2.0),
anchor_strides=(8, 16, 32),
straddle_thresh=0,
):
super(AnchorGenerator, self).__init__()
if len(anchor_strides) == 1:
anchor_stride = anchor_strides[0]
cell_anchors = [
generate_anchors(anchor_stride, sizes, aspect_ratios).float()
]
else:
if len(anchor_strides) != len(sizes):
raise RuntimeError("FPN should have #anchor_strides == #sizes")
cell_anchors = [
generate_anchors(
anchor_stride,
size if isinstance(size, (tuple, list)) else (size,),
aspect_ratios
).float()
for anchor_stride, size in zip(anchor_strides, sizes)
]
self.strides = anchor_strides
self.cell_anchors = BufferList(cell_anchors)
self.straddle_thresh = straddle_thresh
def num_anchors_per_location(self):
return [len(cell_anchors) for cell_anchors in self.cell_anchors]
def grid_anchors(self, grid_sizes):
anchors = []
for size, stride, base_anchors in zip(
grid_sizes, self.strides, self.cell_anchors
):
grid_height, grid_width = size
device = base_anchors.device
shifts_x = torch.arange(
0, grid_width * stride, step=stride, dtype=torch.float32, device=device
)
shifts_y = torch.arange(
0, grid_height * stride, step=stride, dtype=torch.float32, device=device
)
shift_y, shift_x = torch.meshgrid(shifts_y, shifts_x)
shift_x = shift_x.reshape(-1)
shift_y = shift_y.reshape(-1)
shifts = torch.stack((shift_x, shift_y, shift_x, shift_y), dim=1)
anchors.append(
(shifts.view(-1, 1, 4) + base_anchors.view(1, -1, 4)).reshape(-1, 4)
)
return anchors
def add_visibility_to(self, boxlist):
image_width, image_height = boxlist.size
anchors = boxlist.bbox
if self.straddle_thresh >= 0:
inds_inside = (
(anchors[..., 0] >= -self.straddle_thresh)
& (anchors[..., 1] >= -self.straddle_thresh)
& (anchors[..., 2] < image_width + self.straddle_thresh)
& (anchors[..., 3] < image_height + self.straddle_thresh)
)
else:
device = anchors.device
inds_inside = torch.ones(anchors.shape[0], dtype=torch.uint8, device=device)
boxlist.add_field("visibility", inds_inside)
def forward(self, image_list, feature_maps):
grid_sizes = [feature_map.shape[-2:] for feature_map in feature_maps]
anchors_over_all_feature_maps = self.grid_anchors(grid_sizes)
anchors = []
for i, (image_height, image_width) in enumerate(image_list.image_sizes):
anchors_in_image = []
for anchors_per_feature_map in anchors_over_all_feature_maps:
boxlist = BoxList(
anchors_per_feature_map, (image_width, image_height), mode="xyxy"
)
self.add_visibility_to(boxlist)
anchors_in_image.append(boxlist)
anchors.append(anchors_in_image)
return anchors
def make_anchor_generator(config):
anchor_sizes = config.MODEL.RPN.ANCHOR_SIZES
aspect_ratios = config.MODEL.RPN.ASPECT_RATIOS
anchor_stride = config.MODEL.RPN.ANCHOR_STRIDE
straddle_thresh = config.MODEL.RPN.STRADDLE_THRESH
if config.MODEL.RPN.USE_FPN:
assert len(anchor_stride) == len(
anchor_sizes
), "FPN should have len(ANCHOR_STRIDE) == len(ANCHOR_SIZES)"
else:
assert len(anchor_stride) == 1, "Non-FPN should have a single ANCHOR_STRIDE"
anchor_generator = AnchorGenerator(
anchor_sizes, aspect_ratios, anchor_stride, straddle_thresh
)
return anchor_generator
def make_anchor_generator_retinanet(config):
anchor_sizes = config.MODEL.RETINANET.ANCHOR_SIZES
aspect_ratios = config.MODEL.RETINANET.ASPECT_RATIOS
anchor_strides = config.MODEL.RETINANET.ANCHOR_STRIDES
straddle_thresh = config.MODEL.RETINANET.STRADDLE_THRESH
octave = config.MODEL.RETINANET.OCTAVE
scales_per_octave = config.MODEL.RETINANET.SCALES_PER_OCTAVE
assert len(anchor_strides) == len(anchor_sizes), "Only support FPN now"
new_anchor_sizes = []
for size in anchor_sizes:
per_layer_anchor_sizes = []
for scale_per_octave in range(scales_per_octave):
octave_scale = octave ** (scale_per_octave / float(scales_per_octave))
per_layer_anchor_sizes.append(octave_scale * size)
new_anchor_sizes.append(tuple(per_layer_anchor_sizes))
anchor_generator = AnchorGenerator(
tuple(new_anchor_sizes), aspect_ratios, anchor_strides, straddle_thresh
)
return anchor_generator
def generate_anchors(
stride=16, sizes=(32, 64, 128, 256, 512), aspect_ratios=(0.5, 1, 2)
):
"""Generates a matrix of anchor boxes in (x1, y1, x2, y2) format. Anchors
are centered on stride / 2, have (approximate) sqrt areas of the specified
sizes, and aspect ratios as given.
"""
return _generate_anchors(
stride,
np.array(sizes, dtype=np.float) / stride,
np.array(aspect_ratios, dtype=np.float),
)
def _generate_anchors(base_size, scales, aspect_ratios):
"""Generate anchor (reference) windows by enumerating aspect ratios X
scales wrt a reference (0, 0, base_size - 1, base_size - 1) window.
"""
anchor = np.array([1, 1, base_size, base_size], dtype=np.float) - 1
anchors = _ratio_enum(anchor, aspect_ratios)
anchors = np.vstack(
[_scale_enum(anchors[i, :], scales) for i in range(anchors.shape[0])]
)
return torch.from_numpy(anchors)
def _whctrs(anchor):
"""Return width, height, x center, and y center for an anchor (window)."""
w = anchor[2] - anchor[0] + 1
h = anchor[3] - anchor[1] + 1
x_ctr = anchor[0] + 0.5 * (w - 1)
y_ctr = anchor[1] + 0.5 * (h - 1)
return w, h, x_ctr, y_ctr
def _mkanchors(ws, hs, x_ctr, y_ctr):
"""Given a vector of widths (ws) and heights (hs) around a center
(x_ctr, y_ctr), output a set of anchors (windows).
"""
ws = ws[:, np.newaxis]
hs = hs[:, np.newaxis]
anchors = np.hstack(
(
x_ctr - 0.5 * (ws - 1),
y_ctr - 0.5 * (hs - 1),
x_ctr + 0.5 * (ws - 1),
y_ctr + 0.5 * (hs - 1),
)
)
return anchors
def _ratio_enum(anchor, ratios):
"""Enumerate a set of anchors for each aspect ratio wrt an anchor."""
w, h, x_ctr, y_ctr = _whctrs(anchor)
size = w * h
size_ratios = size / ratios
ws = np.round(np.sqrt(size_ratios))
hs = np.round(ws * ratios)
anchors = _mkanchors(ws, hs, x_ctr, y_ctr)
return anchors
def _scale_enum(anchor, scales):
"""Enumerate a set of anchors for each scale wrt an anchor."""
w, h, x_ctr, y_ctr = _whctrs(anchor)
ws = w * scales
hs = h * scales
anchors = _mkanchors(ws, hs, x_ctr, y_ctr)
return anchors
# In[54]:
class RetinaNetLossComputation(RPNLossComputation):
"""
This class computes the RetinaNet loss.
"""
def __init__(self, proposal_matcher, box_coder,
generate_labels_func,
sigmoid_focal_loss,
bbox_reg_beta=0.11,
regress_norm=1.0):
"""
Arguments:
proposal_matcher (Matcher)
box_coder (BoxCoder)
"""
self.proposal_matcher = proposal_matcher
self.box_coder = box_coder
self.box_cls_loss_func = sigmoid_focal_loss
self.bbox_reg_beta = bbox_reg_beta
self.copied_fields = ['labels']
self.generate_labels_func = generate_labels_func
self.discard_cases = ['between_thresholds']
self.regress_norm = regress_norm
def __call__(self, anchors, box_cls, box_regression, targets):
"""
Arguments:
anchors (list[BoxList])
box_cls (list[Tensor])
box_regression (list[Tensor])
targets (list[BoxList])
Returns:
retinanet_cls_loss (Tensor)
retinanet_regression_loss (Tensor
"""
anchors = [cat_boxlist(anchors_per_image) for anchors_per_image in anchors]
labels, regression_targets = self.prepare_targets(anchors, targets)
N = len(labels)
box_cls, box_regression = concat_box_prediction_layers(box_cls, box_regression)
labels = torch.cat(labels, dim=0)
regression_targets = torch.cat(regression_targets, dim=0)
pos_inds = torch.nonzero(labels > 0).squeeze(1)
retinanet_regression_loss = smooth_l1_loss(
box_regression[pos_inds],
regression_targets[pos_inds],
beta=self.bbox_reg_beta,
size_average=False,
) / (max(1, pos_inds.numel() * self.regress_norm))
labels = labels.int()
retinanet_cls_loss = self.box_cls_loss_func(
box_cls,
labels
) / (pos_inds.numel() + N)
return retinanet_cls_loss, retinanet_regression_loss
def generate_retinanet_labels(matched_targets):
labels_per_image = matched_targets.get_field("labels")
return labels_per_image
def make_retinanet_loss_evaluator(cfg, box_coder):
matcher = Matcher(
cfg.MODEL.RETINANET.FG_IOU_THRESHOLD,
cfg.MODEL.RETINANET.BG_IOU_THRESHOLD,
allow_low_quality_matches=True,
)
sigmoid_focal_loss = SigmoidFocalLoss(
cfg.MODEL.RETINANET.LOSS_GAMMA,
cfg.MODEL.RETINANET.LOSS_ALPHA
)
loss_evaluator = RetinaNetLossComputation(
matcher,
box_coder,
generate_retinanet_labels,
sigmoid_focal_loss,
bbox_reg_beta = cfg.MODEL.RETINANET.BBOX_REG_BETA,
regress_norm = cfg.MODEL.RETINANET.BBOX_REG_WEIGHT,
)
return loss_evaluator
# In[55]:
class RetinaNetPostProcessor(RPNPostProcessor):
"""
Performs post-processing on the outputs of the RetinaNet boxes.
This is only used in the testing.
"""
def __init__(
self,
pre_nms_thresh,
pre_nms_top_n,
nms_thresh,
fpn_post_nms_top_n,
min_size,
num_classes,
box_coder=None,
):
"""
Arguments:
pre_nms_thresh (float)
pre_nms_top_n (int)
nms_thresh (float)
fpn_post_nms_top_n (int)
min_size (int)
num_classes (int)
box_coder (BoxCoder)
"""
super(RetinaNetPostProcessor, self).__init__(
pre_nms_thresh, 0, nms_thresh, min_size
)
self.pre_nms_thresh = pre_nms_thresh
self.pre_nms_top_n = pre_nms_top_n
self.nms_thresh = nms_thresh
self.fpn_post_nms_top_n = fpn_post_nms_top_n
self.min_size = min_size
self.num_classes = num_classes
if box_coder is None:
box_coder = BoxCoder(weights=(10., 10., 5., 5.))
self.box_coder = box_coder
def add_gt_proposals(self, proposals, targets):
"""
This function is not used in RetinaNet
"""
pass
def forward_for_single_feature_map(
self, anchors, box_cls, box_regression):
"""
Arguments:
anchors: list[BoxList]
box_cls: tensor of size N, A * C, H, W
box_regression: tensor of size N, A * 4, H, W
"""
device = box_cls.device
N, _, H, W = box_cls.shape
A = box_regression.size(1) // 4
C = box_cls.size(1) // A
# put in the same format as anchors
box_cls = permute_and_flatten(box_cls, N, A, C, H, W)
box_cls = box_cls.sigmoid()
box_regression = permute_and_flatten(box_regression, N, A, 4, H, W)
box_regression = box_regression.reshape(N, -1, 4)
num_anchors = A * H * W
candidate_inds = box_cls > self.pre_nms_thresh
pre_nms_top_n = candidate_inds.view(N, -1).sum(1)
pre_nms_top_n = pre_nms_top_n.clamp(max=self.pre_nms_top_n)
results = []
for per_box_cls, per_box_regression, per_pre_nms_top_n, per_candidate_inds, per_anchors in zip(
box_cls,
box_regression,
pre_nms_top_n,
candidate_inds,
anchors):
# Sort and select TopN
# TODO most of this can be made out of the loop for
# all images.
# TODO:Yang: Not easy to do. Because the numbers of detections are
# different in each image. Therefore, this part needs to be done
# per image.
per_box_cls = per_box_cls[per_candidate_inds]
per_box_cls, top_k_indices = per_box_cls.topk(per_pre_nms_top_n, sorted=False)
per_candidate_nonzeros = per_candidate_inds.nonzero()[top_k_indices, :]
per_box_loc = per_candidate_nonzeros[:, 0]
per_class = per_candidate_nonzeros[:, 1]
per_class += 1
detections = self.box_coder.decode(
per_box_regression[per_box_loc, :].view(-1, 4),
per_anchors.bbox[per_box_loc, :].view(-1, 4)
)
boxlist = BoxList(detections, per_anchors.size, mode="xyxy")
boxlist.add_field("labels", per_class)
boxlist.add_field("scores", per_box_cls)
boxlist = boxlist.clip_to_image(remove_empty=False)
boxlist = remove_small_boxes(boxlist, self.min_size)
results.append(boxlist)
return results
# TODO very similar to filter_results from PostProcessor
# but filter_results is per image
# TODO Yang: solve this issue in the future. No good solution
# right now.
def select_over_all_levels(self, boxlists):
num_images = len(boxlists)
results = []
for i in range(num_images):
scores = boxlists[i].get_field("scores")
labels = boxlists[i].get_field("labels")
boxes = boxlists[i].bbox
boxlist = boxlists[i]
result = []
# skip the background
for j in range(1, self.num_classes):
inds = (labels == j).nonzero().view(-1)
scores_j = scores[inds]
boxes_j = boxes[inds, :].view(-1, 4)
boxlist_for_class = BoxList(boxes_j, boxlist.size, mode="xyxy")
boxlist_for_class.add_field("scores", scores_j)
boxlist_for_class = boxlist_nms(
boxlist_for_class, self.nms_thresh,
score_field="scores"
)
num_labels = len(boxlist_for_class)
boxlist_for_class.add_field(
"labels", torch.full((num_labels,), j,
dtype=torch.int64,
device=scores.device)
)
result.append(boxlist_for_class)
result = cat_boxlist(result)
number_of_detections = len(result)
# Limit to max_per_image detections **over all classes**
if number_of_detections > self.fpn_post_nms_top_n > 0:
cls_scores = result.get_field("scores")
image_thresh, _ = torch.kthvalue(
cls_scores.cpu(),
number_of_detections - self.fpn_post_nms_top_n + 1
)
keep = cls_scores >= image_thresh.item()
keep = torch.nonzero(keep).squeeze(1)
result = result[keep]
results.append(result)
return results
def make_retinanet_postprocessor(config, rpn_box_coder, is_train):
pre_nms_thresh = config.MODEL.RETINANET.INFERENCE_TH
pre_nms_top_n = config.MODEL.RETINANET.PRE_NMS_TOP_N
nms_thresh = config.MODEL.RETINANET.NMS_TH
fpn_post_nms_top_n = config.TEST.DETECTIONS_PER_IMG
min_size = 0
box_selector = RetinaNetPostProcessor(
pre_nms_thresh=pre_nms_thresh,
pre_nms_top_n=pre_nms_top_n,
nms_thresh=nms_thresh,
fpn_post_nms_top_n=fpn_post_nms_top_n,
min_size=min_size,
num_classes=config.MODEL.RETINANET.NUM_CLASSES,
box_coder=rpn_box_coder,
)
return box_selector
# In[56]:
def vis_keypoints(img, kps, kp_thresh=2, alpha=0.7):
"""Visualizes keypoints (adapted from vis_one_image).
kps has shape (4, #keypoints) where 4 rows are (x, y, logit, prob).
"""
dataset_keypoints = PersonKeypoints.NAMES
kp_lines = PersonKeypoints.CONNECTIONS
# Convert from plt 0-1 RGBA colors to 0-255 BGR colors for opencv.
cmap = plt.get_cmap('rainbow')
colors = [cmap(i) for i in np.linspace(0, 1, len(kp_lines) + 2)]
colors = [(c[2] * 255, c[1] * 255, c[0] * 255) for c in colors]
# Perform the drawing on a copy of the image, to allow for blending.
kp_mask = np.copy(img)
# Draw mid shoulder / mid hip first for better visualization.
mid_shoulder = (
kps[:2, dataset_keypoints.index('right_shoulder')] +
kps[:2, dataset_keypoints.index('left_shoulder')]) / 2.0
sc_mid_shoulder = np.minimum(
kps[2, dataset_keypoints.index('right_shoulder')],
kps[2, dataset_keypoints.index('left_shoulder')])
mid_hip = (
kps[:2, dataset_keypoints.index('right_hip')] +
kps[:2, dataset_keypoints.index('left_hip')]) / 2.0
sc_mid_hip = np.minimum(
kps[2, dataset_keypoints.index('right_hip')],
kps[2, dataset_keypoints.index('left_hip')])
nose_idx = dataset_keypoints.index('nose')
if sc_mid_shoulder > kp_thresh and kps[2, nose_idx] > kp_thresh:
cv2.line(
kp_mask, tuple(mid_shoulder), tuple(kps[:2, nose_idx]),
color=colors[len(kp_lines)], thickness=2, lineType=cv2.LINE_AA)
if sc_mid_shoulder > kp_thresh and sc_mid_hip > kp_thresh:
cv2.line(
kp_mask, tuple(mid_shoulder), tuple(mid_hip),
color=colors[len(kp_lines) + 1], thickness=2, lineType=cv2.LINE_AA)
# Draw the keypoints.
for l in range(len(kp_lines)):
i1 = kp_lines[l][0]
i2 = kp_lines[l][1]
p1 = kps[0, i1], kps[1, i1]
p2 = kps[0, i2], kps[1, i2]
if kps[2, i1] > kp_thresh and kps[2, i2] > kp_thresh:
cv2.line(
kp_mask, p1, p2,
color=colors[l], thickness=2, lineType=cv2.LINE_AA)
if kps[2, i1] > kp_thresh:
cv2.circle(
kp_mask, p1,
radius=3, color=colors[l], thickness=-1, lineType=cv2.LINE_AA)
if kps[2, i2] > kp_thresh:
cv2.circle(
kp_mask, p2,
radius=3, color=colors[l], thickness=-1, lineType=cv2.LINE_AA)
# Blend the keypoints.
return cv2.addWeighted(img, 1.0 - alpha, kp_mask, alpha, 0)
# In[57]:
class ROIKeypointHead(torch.nn.Module):
def __init__(self, cfg, in_channels):
super(ROIKeypointHead, self).__init__()
self.cfg = cfg.clone()
self.feature_extractor = make_roi_keypoint_feature_extractor(cfg, in_channels)
self.predictor = make_roi_keypoint_predictor(
cfg, self.feature_extractor.out_channels)
self.post_processor = make_roi_keypoint_post_processor(cfg)
self.loss_evaluator = make_roi_keypoint_loss_evaluator(cfg)
def forward(self, features, proposals, targets=None):
"""
Arguments:
features (list[Tensor]): feature-maps from possibly several levels
proposals (list[BoxList]): proposal boxes
targets (list[BoxList], optional): the ground-truth targets.
Returns:
x (Tensor): the result of the feature extractor
proposals (list[BoxList]): during training, the original proposals
are returned. During testing, the predicted boxlists are returned
with the `mask` field set
losses (dict[Tensor]): During training, returns the losses for the
head. During testing, returns an empty dict.
"""
if self.training:
with torch.no_grad():
proposals = self.loss_evaluator.subsample(proposals, targets)
x = self.feature_extractor(features, proposals)
kp_logits = self.predictor(x)
if not self.training:
result = self.post_processor(kp_logits, proposals)
return x, result, {}
loss_kp = self.loss_evaluator(proposals, kp_logits)
return x, proposals, dict(loss_kp=loss_kp)
# In[58]:
def build_roi_keypoint_head(cfg, in_channels):
return ROIKeypointHead(cfg, in_channels)
# In[59]:
def keep_only_positive_boxes(boxes):
"""
Given a set of BoxList containing the `labels` field,
return a set of BoxList for which `labels > 0`.
Arguments:
boxes (list of BoxList)
"""
assert isinstance(boxes, (list, tuple))
assert isinstance(boxes[0], BoxList)
assert boxes[0].has_field("labels")
positive_boxes = []
positive_inds = []
num_boxes = 0
for boxes_per_image in boxes:
labels = boxes_per_image.get_field("labels")
inds_mask = labels > 0
inds = inds_mask.nonzero().squeeze(1)
positive_boxes.append(boxes_per_image[inds])
positive_inds.append(inds_mask)
return positive_boxes, positive_inds
class ROIMaskHead(torch.nn.Module):
def __init__(self, cfg, in_channels):
super(ROIMaskHead, self).__init__()
self.cfg = cfg.clone()
self.feature_extractor = make_roi_mask_feature_extractor(cfg, in_channels)
self.predictor = make_roi_mask_predictor(
cfg, self.feature_extractor.out_channels)
self.post_processor = make_roi_mask_post_processor(cfg)
self.loss_evaluator = make_roi_mask_loss_evaluator(cfg)
def forward(self, features, proposals, targets=None):
"""
Arguments:
features (list[Tensor]): feature-maps from possibly several levels
proposals (list[BoxList]): proposal boxes
targets (list[BoxList], optional): the ground-truth targets.
Returns:
x (Tensor): the result of the feature extractor
proposals (list[BoxList]): during training, the original proposals
are returned. During testing, the predicted boxlists are returned
with the `mask` field set
losses (dict[Tensor]): During training, returns the losses for the
head. During testing, returns an empty dict.
"""
if self.training:
# during training, only focus on positive boxes
all_proposals = proposals
proposals, positive_inds = keep_only_positive_boxes(proposals)
if self.training and self.cfg.MODEL.ROI_MASK_HEAD.SHARE_BOX_FEATURE_EXTRACTOR:
x = features
x = x[torch.cat(positive_inds, dim=0)]
else:
x = self.feature_extractor(features, proposals)
mask_logits = self.predictor(x)
if not self.training:
result = self.post_processor(mask_logits, proposals)
return x, result, {}
loss_mask = self.loss_evaluator(proposals, mask_logits, targets)
return x, all_proposals, dict(loss_mask=loss_mask)
# In[60]:
def build_roi_mask_head(cfg, in_channels):
return ROIMaskHead(cfg, in_channels)
# In[61]:
# ROIBoxHead类
class ROIBoxHead(torch.nn.Module):
"""
Generic Box Head class.
"""
def __init__(self, cfg, in_channels):
super(ROIBoxHead, self).__init__()
self.feature_extractor = make_roi_box_feature_extractor(cfg, in_channels)
self.predictor = make_roi_box_predictor(
cfg, self.feature_extractor.out_channels)
self.post_processor = make_roi_box_post_processor(cfg)
self.loss_evaluator = make_roi_box_loss_evaluator(cfg)
def forward(self, features, proposals, targets=None):
"""
Arguments:
features (list[Tensor]): feature-maps from possibly several levels
proposals (list[BoxList]): proposal boxes
targets (list[BoxList], optional): the ground-truth targets.
Returns:
x (Tensor): the result of the feature extractor
proposals (list[BoxList]): during training, the subsampled proposals
are returned. During testing, the predicted boxlists are returned
losses (dict[Tensor]): During training, returns the losses for the
head. During testing, returns an empty dict.
"""
if self.training:
# Faster R-CNN subsamples during training the proposals with a fixed
# positive / negative ratio
with torch.no_grad():
proposals = self.loss_evaluator.subsample(proposals, targets)
# extract features that will be fed to the final classifier. The
# feature_extractor generally corresponds to the pooler + heads
x = self.feature_extractor(features, proposals)
# final classifier that converts the features into predictions
class_logits, box_regression = self.predictor(x)
if not self.training:
result = self.post_processor((class_logits, box_regression), proposals)
return x, result, {}
loss_classifier, loss_box_reg = self.loss_evaluator(
[class_logits], [box_regression]
)
return (
x,
proposals,
dict(loss_classifier=loss_classifier, loss_box_reg=loss_box_reg),
)
# In[62]:
def build_roi_box_head(cfg, in_channels):
"""
Constructs a new box head.
By default, uses ROIBoxHead, but if it turns out not to be enough, just register a new class
and make it a parameter in the config
"""
return ROIBoxHead(cfg, in_channels)
# In[63]:
# CombinedROIHeads类
class CombinedROIHeads(torch.nn.ModuleDict):
"""
Combines a set of individual heads (for box prediction or masks) into a single
head.
"""
def __init__(self, cfg, heads):
super(CombinedROIHeads, self).__init__(heads)
self.cfg = cfg.clone()
if cfg.MODEL.MASK_ON and cfg.MODEL.ROI_MASK_HEAD.SHARE_BOX_FEATURE_EXTRACTOR:
self.mask.feature_extractor = self.box.feature_extractor
if cfg.MODEL.KEYPOINT_ON and cfg.MODEL.ROI_KEYPOINT_HEAD.SHARE_BOX_FEATURE_EXTRACTOR:
self.keypoint.feature_extractor = self.box.feature_extractor
def forward(self, features, proposals, targets=None):
losses = {}
# TODO rename x to roi_box_features, if it doesn't increase memory consumption
x, detections, loss_box = self.box(features, proposals, targets)
losses.update(loss_box)
if self.cfg.MODEL.MASK_ON:
mask_features = features
# optimization: during training, if we share the feature extractor between
# the box and the mask heads, then we can reuse the features already computed
if (
self.training
and self.cfg.MODEL.ROI_MASK_HEAD.SHARE_BOX_FEATURE_EXTRACTOR
):
mask_features = x
# During training, self.box() will return the unaltered proposals as "detections"
# this makes the API consistent during training and testing
x, detections, loss_mask = self.mask(mask_features, detections, targets)
losses.update(loss_mask)
if self.cfg.MODEL.KEYPOINT_ON:
keypoint_features = features
# optimization: during training, if we share the feature extractor between
# the box and the mask heads, then we can reuse the features already computed
if (
self.training
and self.cfg.MODEL.ROI_KEYPOINT_HEAD.SHARE_BOX_FEATURE_EXTRACTOR
):
keypoint_features = x
# During training, self.box() will return the unaltered proposals as "detections"
# this makes the API consistent during training and testing
x, detections, loss_keypoint = self.keypoint(keypoint_features, detections, targets)
losses.update(loss_keypoint)
return x, detections, losses
# In[64]:
class RPNModule(torch.nn.Module):
"""
Module for RPN computation. Takes feature maps from the backbone and outputs
RPN proposals and losses. Works for both FPN and non-FPN.
"""
def __init__(self, cfg, in_channels):
super(RPNModule, self).__init__()
self.cfg = cfg.clone()
anchor_generator = make_anchor_generator(cfg)
rpn_head = registry.RPN_HEADS[cfg.MODEL.RPN.RPN_HEAD]
head = rpn_head(
cfg, in_channels, anchor_generator.num_anchors_per_location()[0]
)
rpn_box_coder = BoxCoder(weights=(1.0, 1.0, 1.0, 1.0))
box_selector_train = make_rpn_postprocessor(cfg, rpn_box_coder, is_train=True)
box_selector_test = make_rpn_postprocessor(cfg, rpn_box_coder, is_train=False)
loss_evaluator = make_rpn_loss_evaluator(cfg, rpn_box_coder)
self.anchor_generator = anchor_generator
self.head = head
self.box_selector_train = box_selector_train
self.box_selector_test = box_selector_test
self.loss_evaluator = loss_evaluator
def forward(self, images, features, targets=None):
"""
Arguments:
images (ImageList): images for which we want to compute the predictions
features (list[Tensor]): features computed from the images that are
used for computing the predictions. Each tensor in the list
correspond to different feature levels
targets (list[BoxList): ground-truth boxes present in the image (optional)
Returns:
boxes (list[BoxList]): the predicted boxes from the RPN, one BoxList per
image.
losses (dict[Tensor]): the losses for the model during training. During
testing, it is an empty dict.
"""
objectness, rpn_box_regression = self.head(features)
anchors = self.anchor_generator(images, features)
if self.training:
return self._forward_train(anchors, objectness, rpn_box_regression, targets)
else:
return self._forward_test(anchors, objectness, rpn_box_regression)
def _forward_train(self, anchors, objectness, rpn_box_regression, targets):
if self.cfg.MODEL.RPN_ONLY:
# When training an RPN-only model, the loss is determined by the
# predicted objectness and rpn_box_regression values and there is
# no need to transform the anchors into predicted boxes; this is an
# optimization that avoids the unnecessary transformation.
boxes = anchors
else:
# For end-to-end models, anchors must be transformed into boxes and
# sampled into a training batch.
with torch.no_grad():
boxes = self.box_selector_train(
anchors, objectness, rpn_box_regression, targets
)
loss_objectness, loss_rpn_box_reg = self.loss_evaluator(
anchors, objectness, rpn_box_regression, targets
)
losses = {
"loss_objectness": loss_objectness,
"loss_rpn_box_reg": loss_rpn_box_reg,
}
return boxes, losses
def _forward_test(self, anchors, objectness, rpn_box_regression):
boxes = self.box_selector_test(anchors, objectness, rpn_box_regression)
if self.cfg.MODEL.RPN_ONLY:
# For end-to-end models, the RPN proposals are an intermediate state
# and don't bother to sort them in decreasing score order. For RPN-only
# models, the proposals are the final output and we return them in
# high-to-low confidence order.
inds = [
box.get_field("objectness").sort(descending=True)[1] for box in boxes
]
boxes = [box[ind] for box, ind in zip(boxes, inds)]
return boxes, {}
# In[65]:
# RetinaNetHead类
class RetinaNetHead(torch.nn.Module):
"""
Adds a RetinNet head with classification and regression heads
"""
def __init__(self, cfg, in_channels):
"""
Arguments:
in_channels (int): number of channels of the input feature
num_anchors (int): number of anchors to be predicted
"""
super(RetinaNetHead, self).__init__()
# TODO: Implement the sigmoid version first.
num_classes = cfg.MODEL.RETINANET.NUM_CLASSES - 1
num_anchors = len(cfg.MODEL.RETINANET.ASPECT_RATIOS) * cfg.MODEL.RETINANET.SCALES_PER_OCTAVE
cls_tower = []
bbox_tower = []
for i in range(cfg.MODEL.RETINANET.NUM_CONVS):
cls_tower.append(
nn.Conv2d(
in_channels,
in_channels,
kernel_size=3,
stride=1,
padding=1
)
)
cls_tower.append(nn.ReLU())
bbox_tower.append(
nn.Conv2d(
in_channels,
in_channels,
kernel_size=3,
stride=1,
padding=1
)
)
bbox_tower.append(nn.ReLU())
self.add_module('cls_tower', nn.Sequential(*cls_tower))
self.add_module('bbox_tower', nn.Sequential(*bbox_tower))
self.cls_logits = nn.Conv2d(
in_channels, num_anchors * num_classes, kernel_size=3, stride=1,
padding=1
)
self.bbox_pred = nn.Conv2d(
in_channels, num_anchors * 4, kernel_size=3, stride=1,
padding=1
)
# Initialization
for modules in [self.cls_tower, self.bbox_tower, self.cls_logits,
self.bbox_pred]:
for l in modules.modules():
if isinstance(l, nn.Conv2d):
torch.nn.init.normal_(l.weight, std=0.01)
torch.nn.init.constant_(l.bias, 0)
# retinanet_bias_init
prior_prob = cfg.MODEL.RETINANET.PRIOR_PROB
bias_value = -math.log((1 - prior_prob) / prior_prob)
torch.nn.init.constant_(self.cls_logits.bias, bias_value)
def forward(self, x):
logits = []
bbox_reg = []
for feature in x:
logits.append(self.cls_logits(self.cls_tower(feature)))
bbox_reg.append(self.bbox_pred(self.bbox_tower(feature)))
return logits, bbox_reg
# RetinaNetModule类
class RetinaNetModule(torch.nn.Module):
"""
Module for RetinaNet computation. Takes feature maps from the backbone and
RetinaNet outputs and losses. Only Test on FPN now.
"""
def __init__(self, cfg, in_channels):
super(RetinaNetModule, self).__init__()
self.cfg = cfg.clone()
anchor_generator = make_anchor_generator_retinanet(cfg)
head = RetinaNetHead(cfg, in_channels)
box_coder = BoxCoder(weights=(10., 10., 5., 5.))
box_selector_test = make_retinanet_postprocessor(cfg, box_coder, is_train=False)
loss_evaluator = make_retinanet_loss_evaluator(cfg, box_coder)
self.anchor_generator = anchor_generator
self.head = head
self.box_selector_test = box_selector_test
self.loss_evaluator = loss_evaluator
def forward(self, images, features, targets=None):
"""
Arguments:
images (ImageList): images for which we want to compute the predictions
features (list[Tensor]): features computed from the images that are
used for computing the predictions. Each tensor in the list
correspond to different feature levels
targets (list[BoxList): ground-truth boxes present in the image (optional)
Returns:
boxes (list[BoxList]): the predicted boxes from the RPN, one BoxList per
image.
losses (dict[Tensor]): the losses for the model during training. During
testing, it is an empty dict.
"""
box_cls, box_regression = self.head(features)
anchors = self.anchor_generator(images, features)
if self.training:
return self._forward_train(anchors, box_cls, box_regression, targets)
else:
return self._forward_test(anchors, box_cls, box_regression)
def _forward_train(self, anchors, box_cls, box_regression, targets):
loss_box_cls, loss_box_reg = self.loss_evaluator(
anchors, box_cls, box_regression, targets
)
losses = {
"loss_retina_cls": loss_box_cls,
"loss_retina_reg": loss_box_reg,
}
return anchors, losses
def _forward_test(self, anchors, box_cls, box_regression):
boxes = self.box_selector_test(anchors, box_cls, box_regression)
return boxes, {}
# In[66]:
# build_rpn所需函数
def build_retinanet(cfg, in_channels):
return RetinaNetModule(cfg, in_channels)
# In[67]:
# GeneralizedRCNN类初始化所需函数
def build_backbone(cfg):
assert cfg.MODEL.BACKBONE.CONV_BODY in registry.BACKBONES, "cfg.MODEL.BACKBONE.CONV_BODY: {} are not registered in registry".format(
cfg.MODEL.BACKBONE.CONV_BODY
)
return registry.BACKBONES[cfg.MODEL.BACKBONE.CONV_BODY](cfg)
def build_rpn(cfg, in_channels):
"""
This gives the gist of it. Not super important because it doesn't change as much
"""
if cfg.MODEL.RETINANET_ON:
return build_retinanet(cfg, in_channels)
return RPNModule(cfg, in_channels)
def build_roi_heads(cfg, in_channels):
# individually create the heads, that will be combined together
# afterwards
roi_heads = []
if cfg.MODEL.RETINANET_ON:
return []
if not cfg.MODEL.RPN_ONLY:
roi_heads.append(("box", build_roi_box_head(cfg, in_channels)))
if cfg.MODEL.MASK_ON:
roi_heads.append(("mask", build_roi_mask_head(cfg, in_channels)))
if cfg.MODEL.KEYPOINT_ON:
roi_heads.append(("keypoint", build_roi_keypoint_head(cfg, in_channels)))
# combine individual heads in a single module
if roi_heads:
roi_heads = CombinedROIHeads(cfg, roi_heads)
return roi_heads
# In[68]:
#GeneralizedRCNN类
class GeneralizedRCNN(nn.Module):
"""
Main class for Generalized R-CNN. Currently supports boxes and masks.
It consists of three main parts:
- backbone
- rpn
- heads: takes the features + the proposals from the RPN and computes
detections / masks from it.
"""
def __init__(self, cfg):
super(GeneralizedRCNN, self).__init__()
self.backbone = build_backbone(cfg)
self.rpn = build_rpn(cfg, self.backbone.out_channels)
self.roi_heads = build_roi_heads(cfg, self.backbone.out_channels)
def forward(self, images, targets=None):
"""
Arguments:
images (list[Tensor] or ImageList): images to be processed
targets (list[BoxList]): ground-truth boxes present in the image (optional)
Returns:
result (list[BoxList] or dict[Tensor]): the output from the model.
During training, it returns a dict[Tensor] which contains the losses.
During testing, it returns list[BoxList] contains additional fields
like `scores`, `labels` and `mask` (for Mask R-CNN models).
"""
if self.training and targets is None:
raise ValueError("In training mode, targets should be passed")
images = to_image_list(images)
features = self.backbone(images.tensors)
proposals, proposal_losses = self.rpn(images, features, targets)
if self.roi_heads:
x, result, detector_losses = self.roi_heads(features, proposals, targets)
else:
# RPN-only models don't have roi_heads
x = features
result = proposals
detector_losses = {}
if self.training:
losses = {}
losses.update(detector_losses)
losses.update(proposal_losses)
return losses
return result
# In[69]:
# 放大显示结果图片
# pylab.rcParams['figure.figsize'] = 20, 12
# In[70]:
def imshow(img):#显示图片函数
plt.imshow(img[:, :, [2, 1, 0]])
plt.axis("off")
plt.show
# In[71]:
# COCODemo类初始化所需函数
_DETECTION_META_ARCHITECTURES = {"GeneralizedRCNN": GeneralizedRCNN}
def build_detection_model(cfg):#build_detection_model函数
meta_arch = _DETECTION_META_ARCHITECTURES[cfg.MODEL.META_ARCHITECTURE]
return meta_arch(cfg)
# In[72]:
# 读取本地图片并显示
img=cv2.imread('6.jpg')
imshow(img)
# In[73]:
#Resize类
class Resize(object):
def __init__(self, min_size, max_size):
self.min_size = min_size
self.max_size = max_size
# modified from torchvision to add support for max size
def get_size(self, image_size):
w, h = image_size
size = self.min_size
max_size = self.max_size
if max_size is not None:
min_original_size = float(min((w, h)))
max_original_size = float(max((w, h)))
if max_original_size / min_original_size * size > max_size:
size = int(round(max_size * min_original_size / max_original_size))
if (w <= h and w == size) or (h <= w and h == size):
return (h, w)
if w < h:
ow = size
oh = int(size * h / w)
else:
oh = size
ow = int(size * w / h)
return (oh, ow)
def __call__(self, image):
size = self.get_size(image.size)
image = F.resize(image, size)
return image
# In[74]:
#COCODemo类
class COCODemo(object):
# COCO categories for pretty print
CATEGORIES = [
"__background",
"person",
"bicycle",
"car",
"motorcycle",
"airplane",
"bus",
"train",
"truck",
"boat",
"traffic light",
"fire hydrant",
"stop sign",
"parking meter",
"bench",
"bird",
"cat",
"dog",
"horse",
"sheep",
"cow",
"elephant",
"bear",
"zebra",
"giraffe",
"backpack",
"umbrella",
"handbag",
"tie",
"suitcase",
"frisbee",
"skis",
"snowboard",
"sports ball",
"kite",
"baseball bat",
"baseball glove",
"skateboard",
"surfboard",
"tennis racket",
"bottle",
"wine glass",
"cup",
"fork",
"knife",
"spoon",
"bowl",
"banana",
"apple",
"sandwich",
"orange",
"broccoli",
"carrot",
"hot dog",
"pizza",
"donut",
"cake",
"chair",
"couch",
"potted plant",
"bed",
"dining table",
"toilet",
"tv",
"laptop",
"mouse",
"remote",
"keyboard",
"cell phone",
"microwave",
"oven",
"toaster",
"sink",
"refrigerator",
"book",
"clock",
"vase",
"scissors",
"teddy bear",
"hair drier",
"toothbrush",
]
def __init__(self,cfg,confidence_threshold=0.7,show_mask_heatmaps=False,masks_per_dim=2,min_image_size=224,):
self.cfg = cfg.clone()
self.model = build_detection_model(cfg)
self.model.eval()
self.device = torch.device(cfg.MODEL.DEVICE)
self.model.to(self.device)
self.min_image_size = min_image_size
save_dir = cfg.OUTPUT_DIR
checkpointer = DetectronCheckpointer(cfg, self.model, save_dir=save_dir)
_ = checkpointer.load(cfg.MODEL.WEIGHT)
self.transforms = self.build_transform()
mask_threshold = -1 if show_mask_heatmaps else 0.5
self.masker = Masker(threshold=mask_threshold, padding=1)
# used to make colors for each class
self.palette = torch.tensor([2 ** 25 - 1, 2 ** 15 - 1, 2 ** 21 - 1])
self.cpu_device = torch.device("cpu")
self.confidence_threshold = confidence_threshold
self.show_mask_heatmaps = show_mask_heatmaps
self.masks_per_dim = masks_per_dim
def build_transform(self):
"""
Creates a basic transformation that was used to train the models
"""
cfg = self.cfg
# we are loading images with OpenCV, so we don't need to convert them
# to BGR, they are already! So all we need to do is to normalize
# by 255 if we want to convert to BGR255 format, or flip the channels
# if we want it to be in RGB in [0-1] range.
if cfg.INPUT.TO_BGR255:
to_bgr_transform = T.Lambda(lambda x: x * 255)
else:
to_bgr_transform = T.Lambda(lambda x: x[[2, 1, 0]])
normalize_transform = T.Normalize(
mean=cfg.INPUT.PIXEL_MEAN, std=cfg.INPUT.PIXEL_STD
)
min_size = cfg.INPUT.MIN_SIZE_TEST
max_size = cfg.INPUT.MAX_SIZE_TEST
transform = T.Compose(
[
T.ToPILImage(),
Resize(min_size, max_size),
T.ToTensor(),
to_bgr_transform,
normalize_transform,
]
)
return transform
def compute_colors_for_labels(self, labels):
"""
Simple function that adds fixed colors depending on the class
"""
colors = labels[:, None] * self.palette
colors = (colors % 255).numpy().astype("uint8")
return colors
def overlay_class_names(self, image, predictions):
"""
Adds detected class names and scores in the positions defined by the
top-left corner of the predicted bounding box
Arguments:
image (np.ndarray): an image as returned by OpenCV
predictions (BoxList): the result of the computation by the model.
It should contain the field `scores` and `labels`.
"""
scores = predictions.get_field("scores").tolist()
labels = predictions.get_field("labels").tolist()
labels = [self.CATEGORIES[i] for i in labels]
boxes = predictions.bbox
template = "{}: {:.2f}"
for box, score, label in zip(boxes, scores, labels):
x, y = box[:2]
s = template.format(label, score)
cv2.putText(
image, s, (x, y), cv2.FONT_HERSHEY_SIMPLEX, .5, (255, 255, 255), 1
)
return image
# In[75]:
coco_demo = COCODemo(cfg,confidence_threshold=0.7,min_image_size=800,)#引用COCODemo类
# In[76]:
#compute_prediction
image = coco_demo.transforms(img)
image_list = to_image_list(image, coco_demo.cfg.DATALOADER.SIZE_DIVISIBILITY)
image_list = image_list.to(coco_demo.device)
with torch.no_grad():
predictions = coco_demo.model(image_list)
predictions = [o.to(coco_demo.cpu_device) for o in predictions]
prediction = predictions[0]
height, width = img.shape[:-1]
prediction = prediction.resize((width, height))
if prediction.has_field("mask"):
masks = prediction.get_field("mask")
masks = coco_demo.masker([masks], [prediction])[0]
prediction.add_field("mask", masks)
predictions = prediction
#select_top_predictions
scores = predictions.get_field("scores")
keep = torch.nonzero(scores > coco_demo.confidence_threshold).squeeze(1)
predictions = predictions[keep]
scores = predictions.get_field("scores")
_, idx = scores.sort(0, descending=True)
top_predictions = predictions[idx]
# run_on_opencv_image--
result = img.copy()
if coco_demo.show_mask_heatmaps:
# composite = coco_demo.create_mask_montage(result, top_predictions)
# create_mask_montage
masks = top_predictions.get_field("mask")
masks_per_dim = coco_demo.masks_per_dim
masks = layers.interpolate(
masks.float(), scale_factor=1 / masks_per_dim
).byte()
height, width = masks.shape[-2:]
max_masks = masks_per_dim ** 2
masks = masks[:max_masks]
# handle case where we have less detections than max_masks
if len(masks) < max_masks:
masks_padded = torch.zeros(max_masks, 1, height, width, dtype=torch.uint8)
masks_padded[: len(masks)] = masks
masks = masks_padded
masks = masks.reshape(masks_per_dim, masks_per_dim, height, width)
result = torch.zeros(
(masks_per_dim * height, masks_per_dim * width), dtype=torch.uint8
)
for y in range(masks_per_dim):
start_y = y * height
end_y = (y + 1) * height
for x in range(masks_per_dim):
start_x = x * width
end_x = (x + 1) * width
result[start_y:end_y, start_x:end_x] = masks[y, x]
composite = cv2.applyColorMap(result.numpy(), cv2.COLORMAP_JET)
# run_on_opencv_image--
# result = coco_demo.overlay_boxes(result, top_predictions)
#overlay_boxes
labels = top_predictions.get_field("labels")
boxes = top_predictions.bbox
colors = coco_demo.compute_colors_for_labels(labels).tolist()
for box, color in zip(boxes, colors):
box = box.to(torch.int64)
top_left, bottom_right = box[:2].tolist(), box[2:].tolist()
image = cv2.rectangle(
result, tuple(top_left), tuple(bottom_right), tuple(color), 1
)
result = image
if coco_demo.cfg.MODEL.MASK_ON:
# result = coco_demo.overlay_mask(result, top_predictions)
#overlay_mask
masks = top_predictions.get_field("mask").numpy()
labels = top_predictions.get_field("labels")
colors = coco_demo.compute_colors_for_labels(labels).tolist()
for mask, color in zip(masks, colors):
thresh = mask[0, :, :, None]
contours, hierarchy = findContours(
thresh, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE
)
image = cv2.drawContours(result, contours, -1, color, 3)
composite = image
result = composite
if coco_demo.cfg.MODEL.KEYPOINT_ON:
# result = coco_demo.overlay_keypoints(result, top_predictions)
# overlay_keypoints
keypoints = top_predictions.get_field("keypoints")
kps = keypoints.keypoints
scores = keypoints.get_field("logits")
kps = torch.cat((kps[:, :, 0:2], scores[:, :, None]), dim=2).numpy()
for region in kps:
image = vis_keypoints(result, region.transpose((1, 0)))
result = image
# result = coco_demo.overlay_class_names(result, top_predictions)
#
scores = top_predictions.get_field("scores").tolist()
labels = top_predictions.get_field("labels").tolist()
labels = [coco_demo.CATEGORIES[i] for i in labels]
boxes = top_predictions.bbox
template = "{}: {:.2f}"
for box, score, label in zip(boxes, scores, labels):
x, y = box[:2]
s = template.format(label, score)
cv2.putText(
result, s, (x, y), cv2.FONT_HERSHEY_SIMPLEX, .5, (255, 255, 255), 1
)
result = result
composite = result
# In[77]:
# 展示结果
imshow(composite)
运行前:

运行后: