python3 scrapy_redis 分布式爬取房天下存mongodb
(一)scrapy_redis 简单介绍
scrapy_redis基于scrapy框架的基础上集成了redis,通过了redis实现了去重,多台服务器进行分布式的爬取数据。
(二)scrapy_redis 简单配置
(1)settings.py 文件中加入两行代码:
#启用Redis调度存储请求队列
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
#确保所有的爬虫通过Redis去重
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"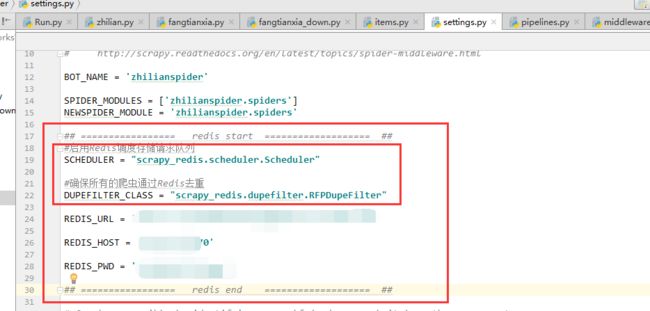
(2)spider文件中把scrapy.Spider改为RedisSpider; 加入redis_key
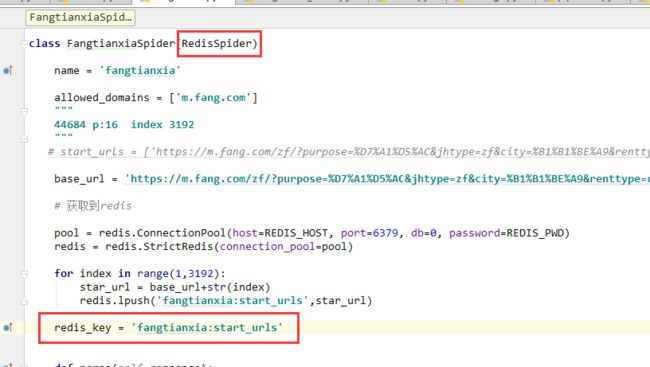
以上就是scrapy_redis在scrapy框架中的简单配置,更多的配置内容,请查看以往博客介绍
(三)房天下爬虫代码的编写
(一)获取的内容是优选房源
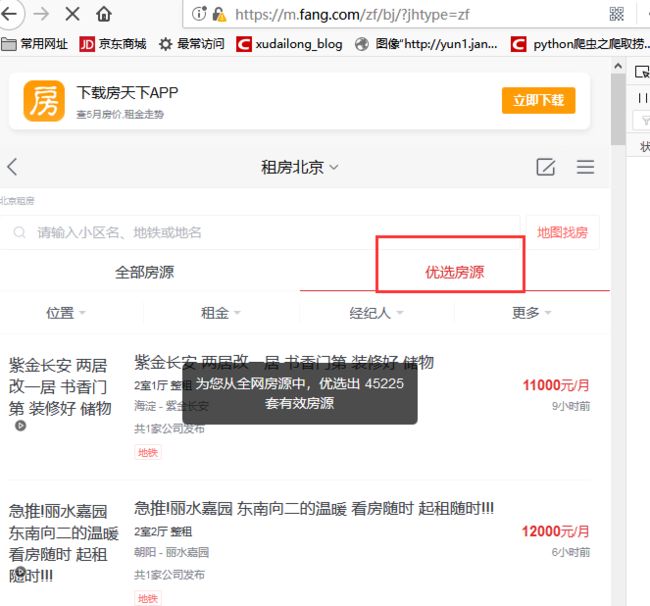
起始页:https://m.fang.com/zf/bj/?jhtype=zf
因为这个页面是下滑刷新的,并没有点击下一页的操作,而是动态JS进行加载的,我们可以使用审查元素中的网络,查看接口请求信息

其中的一个链接:
https://m.fang.com/zf/?purpose=%D7%A1%D5%AC&jhtype=zf&city=%B1%B1%BE%A9&renttype=cz&c=zf&a=ajaxGetList&city=bj&r=0.7838634037101673&page=3
我们可以看到 page=3 只要我们操控这个变量就完全可以了。
但是:当我们打开上面的链接的时候,出现一堆的乱码:
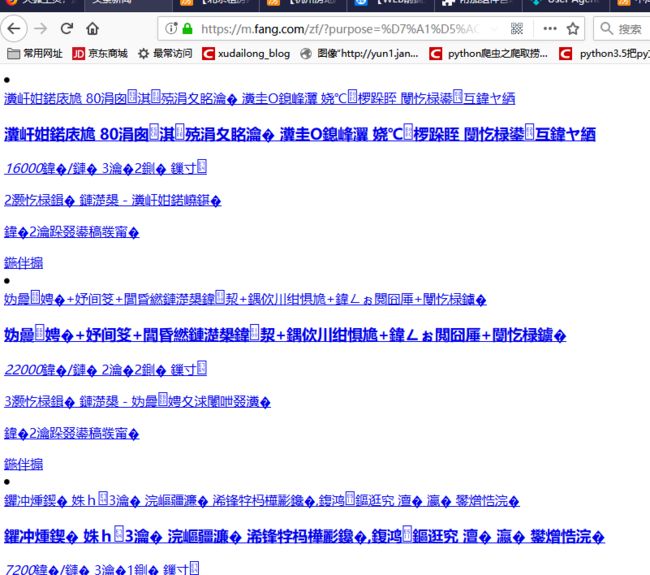
(二)我们在parse()方法中使用decode 方法解码一下,就可以显示正常了。
def parse(self,response):
print(response.body.decode('utf-8'))
敲黑板!!!
因为这里用了分布式,我使用的方法是一台专门爬url,就是列表页的url,另外一台专门进行列表页url的解析工作。
基于现在的情况,我现在只有一台电脑,所以我进行了两个爬虫进行运行,一个进行url的爬取,一个进行页面的解析工作。
(1)url爬取:
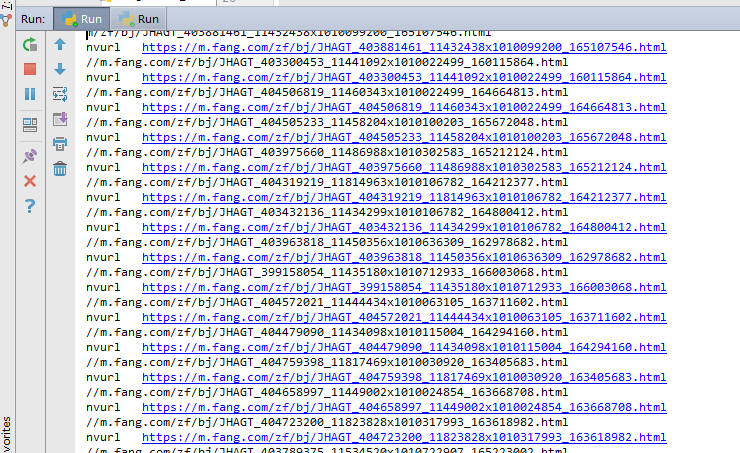
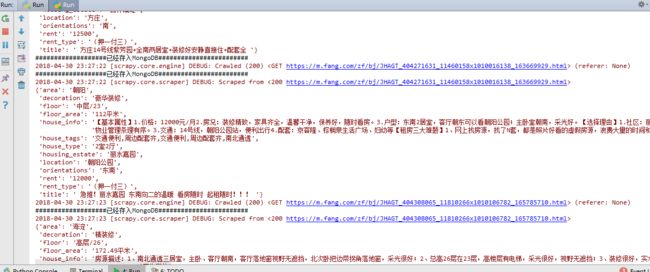
(2)页面解析:
(1)爬取url的spider代码:
# -*- coding: utf-8 -*-
# @Time : 2018/4/30 14:14
# @Author : 蛇崽
# @Email : [email protected]
# @File : fangtianxia.py(房天下)
import scrapy
import redis
from scrapy_redis.spiders import RedisSpider
from zhilianspider.settings import REDIS_HOST,REDIS_PWD
class FangtianxiaSpider(RedisSpider):
name = 'fangtianxia'
allowed_domains = ['m.fang.com']
"""
44684 p:16 index 3192
"""
# start_urls = ['https://m.fang.com/zf/?purpose=%D7%A1%D5%AC&jhtype=zf&city=%B1%B1%BE%A9&renttype=cz&c=zf&a=ajaxGetList&city=bj&r=0.7782449595236586&page=1']
base_url = 'https://m.fang.com/zf/?purpose=%D7%A1%D5%AC&jhtype=zf&city=%B1%B1%BE%A9&renttype=cz&c=zf&a=ajaxGetList&city=bj&r=0.7782449595236586&page='
# 获取到redis
pool = redis.ConnectionPool(host=REDIS_HOST, port=6379, db=0, password=REDIS_PWD)
redis = redis.StrictRedis(connection_pool=pool)
for index in range(1,3192):
star_url = base_url+str(index)
redis.lpush('fangtianxia:start_urls',star_url)
redis_key = 'fangtianxia:start_urls'
def parse(self,response):
#print(response.body.decode('utf-8'))
url = response.xpath("//*[@class='tongjihref']/@href").extract()
for v_url in url:
print(v_url)
n_v_url = 'https:'+v_url
print('nvurl ',n_v_url)
self.redis.rpush('fangtianxia:house_urls',n_v_url)
(2)解析页面的代码
# -*- coding: utf-8 -*-
# @Time : 2018/4/30 14:14
# @Author : 蛇崽
# @Email : 643435675@QQ.com
# @File : fangtianxia.py(房天下)
import scrapy
import redis
from scrapy_redis.spiders import RedisSpider
from zhilianspider.items import FanItem
from zhilianspider.settings import REDIS_HOST,REDIS_PWD
class FangtianxiaSpider(RedisSpider):
name = 'fangtianxia_down'
allowed_domains = ['m.fang.com']
redis_key = 'fangtianxia:house_urls'
# start_urls = ['https://m.fang.com/zf/bj/JHAGT_404572021_11444434x1010063105_163711602.html']
def parse(self,response):
item = FanItem()
item["title"] = response.xpath('//*[@class="xqCaption mb8"]/h1/text()')[0].extract()
item["area"] = response.xpath('//*[@class="xqCaption mb8"]/p/a[2]/text()')[0].extract()
item["location"] = response.xpath('//*[@class="xqCaption mb8"]/p/a[3]/text()')[0].extract()
item["housing_estate"] = response.xpath('//*[@class="xqCaption mb8"]/p/a[1]/text()')[0].extract()
item["rent"] = response.xpath('//*[@class="f18 red-df"]/text()')[0].extract()
item["rent_type"] = response.xpath('//*[@class="f12 gray-8"]/text()')[0].extract()
item["floor_area"] = response.xpath('//*[@class="flextable"]/li[3]/p/text()')[0].extract()
item["house_type"] = response.xpath('//*[@class="flextable"]/li[2]/p/text()')[0].extract()
item["floor"] = response.xpath('//*[@class="flextable"]/li[4]/p/text()')[0].extract()
item["orientations"] = response.xpath('//*[@class="flextable"]/li[5]/p/text()')[0].extract()
item["decoration"] = response.xpath('//*[@class="flextable"]/li[6]/p/text()')[0].extract()
item["house_info"] = response.xpath('//*[@class="xqIntro"]/p/text()')[0].extract()
item["house_tags"] = ",".join(response.xpath('//*[@class="stag"]/span/text()').extract())
yield item
(三)items.py代码:
class FanItem(scrapy.Item):
# 标题
title = scrapy.Field()
# 区(朝阳)
area = scrapy.Field()
# 区域 (劲松)
location = scrapy.Field()
# 小区 (劲松五区)
housing_estate = scrapy.Field()
# 租金
rent = scrapy.Field()
# 建筑面积
floor_area = scrapy.Field()
# 户型
house_type = scrapy.Field()
# 楼层
floor = scrapy.Field()
# 朝向
orientations = scrapy.Field()
# 装修
decoration = scrapy.Field()
# 房源描述
house_info = scrapy.Field()
# 标签
house_tags = scrapy.Field()
# 租房类型(押一付三etc)
rent_type = scrapy.Field()(四)数据展示
现在的数据还没有爬完,到现在redis的详情url已经是60万的数据了,怕要是撑爆了。

mongo数据库里面的数据是3万左右:

总结一下:scrapy_redis 中的url爬取,这是用这个框架以来第一次用的这种方式,或许这种方式更支持分布式操作,一个爬url,多个通过url进行页面的解析操作,比较解析页面是比较费时的。
其余代码都是跟前面爬取智联招聘的代码都差不多一样的,这里就不贴出来了,完整的代码我会上传上来。