吴恩达机器学习笔记
本文为吴恩达机器学习视频听课笔记,仅记录课程大纲及对于部分关键点、疑难点的理解。
课程链接: 吴恩达机器学习.
说明:这篇博客已经躺在草稿箱里很久了 由于整理公式等耗费大量时间 仅仅梳理了前 7章的内容 后续内容若有时间再做整理
目录
- Chapter1 绪论
- Chapter2 单变量线性回归
- 模型表示
- 代价函数
- 梯度下降
- 线性回归中的梯度下降
- Chapter3 线性代数回顾
- Chapter4 多变量线性回归
- Notation
- 多变量梯度下降法
- 正规方程法
- 多项式回归
- Chapter 5 逻辑回归
- 假设函数
- 决策边界
- 代价函数
- 梯度下降
- 多类别分类问题
- Chapter6 正则化
- 过拟合问题
- 正则化代价函数
- 线性回归、逻辑回归的正则方法
- Chapter7 神经网络
- 背景
- 模型表示
- 多元分类
Chapter1 绪论
本章主要介绍了机器学习的定义、算法分类及应用场景。

Chapter2 单变量线性回归
模型表示
- 符号说明
| 项目 | Value |
|---|---|
| m | Number of training examples |
| x’s | “input” variable |
| y’s | “output” variable |
| (x,y) | one training example |
| ( x ( i ) x^{(i)} x(i), y ( i ) y^{(i)} y(i)) | the i t h i^{th} ith training example |
-
监督学习算法工作过程

-
Linear Regression Model
h θ ( x ) = θ 0 + θ 1 x h_{θ}(x)=θ_0+θ_1x hθ(x)=θ0+θ1x
J ( θ 0 , θ 1 ) = 1 2 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) 2 \mathrm J(θ_0,θ_1)=\cfrac {1}{2m}\displaystyle\sum_{i=1}^m(h_{θ}(x^{(i)})-y^{{(i)}})^{2} J(θ0,θ1)=2m1i=1∑m(hθ(x(i))−y(i))2
代价函数
| 项目 | Value |
|---|---|
| 假设函数 | h θ ( x ) = θ 0 + θ 1 x h_{θ}(x)=θ_0+θ_1x hθ(x)=θ0+θ1x |
| 参数 | θ 0 θ_0 θ0, θ 1 θ_1 θ1 |
| 代价函数 | J ( θ 0 , θ 1 ) = 1 2 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) 2 \mathrm J(θ_0,θ_1)=\cfrac {1}{2m}\displaystyle\sum_{i=1}^m(h_{θ}(x^{(i)})-y^{{(i)}})^{2} J(θ0,θ1)=2m1i=1∑m(hθ(x(i))−y(i))2 |
| 目标 | m i n i m i z e J ( θ 0 , θ 1 ) {minimize} \mathrm J(θ_0,θ_1) minimizeJ(θ0,θ1) |
注意:
- 选择合适的 θ 0 θ_0 θ0,和 θ 1 θ_1 θ1使得假设函数表示的直线更好地与数据点拟合,定义为最小化问题
- 代价函数中,系数为 1 2 \cfrac {1}{2} 21,目的是在梯度下降时便于求解
梯度下降
- 定义:
repeat until convergence{
θ j : = θ j − α ∂ ∂ θ j J ( θ 0 , θ 1 ) θ_j:= θ_j-α\cfrac {\partial}{\partialθ_j}\mathrm J(θ_0,θ_1) θj:=θj−α∂θj∂J(θ0,θ1) (for j=0 and j=1)
} - 关于α(学习率)
(1)学习率表示在控制梯度下降时,以多大的幅度更新参数(采用同时更新的方法,即 θ 0 θ_0 θ0和 θ 1 θ_1 θ1同时更新)
(2)if α is too small, gradient descent can be slow
(3)if α is too large, gradient descent can overshoot the minimum. It may fail to converge, or even diverge.
线性回归中的梯度下降
-
线性回归模型
h θ ( x ) = θ 0 + θ 1 x h_{θ}(x)=θ_0+θ_1x hθ(x)=θ0+θ1x
J ( θ 0 , θ 1 ) = 1 2 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) 2 \mathrm J(θ_0,θ_1)=\cfrac {1}{2m}\displaystyle\sum_{i=1}^m(h_{θ}(x^{(i)})-y^{{(i)}})^{2} J(θ0,θ1)=2m1i=1∑m(hθ(x(i))−y(i))2
-
梯度下降算法
repeat until convergence{
θ j : = θ j − α ∂ ∂ θ j J ( θ 0 , θ 1 ) θ_j:= θ_j-α\cfrac {\partial}{\partialθ_j}\mathrm J(θ_0,θ_1) θj:=θj−α∂θj∂J(θ0,θ1) (for j=0 and j=1)
} -
Apply gradient descent to minimize squared error cost function
求偏导:
∂ ∂ θ j J ( θ 0 , θ 1 ) = ∂ ∂ θ j 1 2 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) 2 = ∂ ∂ θ j 1 2 m ∑ i = 1 m ( θ 0 + θ 1 x ( i ) − y ( i ) ) 2 \cfrac {\partial}{\partialθ_j}\mathrm J(θ_0,θ_1)=\cfrac {\partial}{\partialθ_j}\cfrac {1}{2m}\displaystyle\sum_{i=1}^m(h_{θ}(x^{(i)})-y^{{(i)}})^{2}=\cfrac {\partial}{\partialθ_j}\cfrac {1}{2m}\displaystyle\sum_{i=1}^m(θ_0+θ_1x^{(i)}-y^{{(i)}})^{2} ∂θj∂J(θ0,θ1)=∂θj∂2m1i=1∑m(hθ(x(i))−y(i))2=∂θj∂2m1i=1∑m(θ0+θ1x(i)−y(i))2j=0时 , ∂ ∂ θ 0 J ( θ 0 , θ 1 ) = 1 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) \cfrac {\partial}{\partialθ_0}\mathrm J(θ_0,θ_1)=\cfrac {1}{m}\displaystyle\sum_{i=1}^m(h_{θ}(x^{(i)})-y^{{(i)}}) ∂θ0∂J(θ0,θ1)=m1i=1∑m(hθ(x(i))−y(i))
j=1时 , ∂ ∂ θ 1 J ( θ 0 , θ 1 ) = 1 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) x ( i ) \cfrac {\partial}{\partialθ_1}\mathrm J(θ_0,θ_1)=\cfrac {1}{m}\displaystyle\sum_{i=1}^m(h_{θ}(x^{(i)})-y^{{(i)}})x^{(i)} ∂θ1∂J(θ0,θ1)=m1i=1∑m(hθ(x(i))−y(i))x(i)
结果:
repeat until convergence{
θ 0 : = θ 0 − α 1 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) θ_0:= θ_0-α\cfrac {1}{m}\displaystyle\sum_{i=1}^m(h_{θ}(x^{(i)})-y^{{(i)}}) θ0:=θ0−αm1i=1∑m(hθ(x(i))−y(i))
θ 1 : = θ 1 − α 1 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) x ( i ) θ_1:= θ_1-α\cfrac {1}{m}\displaystyle\sum_{i=1}^m(h_{θ}(x^{(i)})-y^{{(i)}})x^{(i)} θ1:=θ1−αm1i=1∑m(hθ(x(i))−y(i))x(i)
}
Chapter3 线性代数回顾
- 矩阵和向量
(1)矩阵(Matrix):由数字组成的矩形阵列(Rectangular array of numbers)
矩阵的维度(Dimension of matrix): 矩阵的行数乘以列数(Number of rows × number of columns)
矩阵的项(Entry): A i j A_{ij} Aij=" i,j entry" in the i t h i_{th} ith row, j t h j_{th} jth column.
Function:矩阵提供了一种快速整理、索引和访问大量数据的方式
(2)向量(Vector):一种特殊的矩阵(An n×1 matrix ) - 矩阵的加减法、乘法
(1)加减法:两个矩阵的每一个元素逐个相加减(只有相同维度的矩阵才能相加)
(2)标量乘法:将矩阵中所有元素逐一与3相乘(标量,在这里指的是实数)
(3)乘法:条件:第一个矩阵的列数等于第二个矩阵的行数;相乘得到的结果: 行数等于第一个矩阵的行数,列数等于第二个矩阵的列数;矩阵的乘法不符合交换律,符合结合律
(4)单位矩阵:对角线元素为1,其他位置为0 - 逆和转置
(1)逆矩阵:
if A is an m×m matrix, and if it has an inverse, A A − 1 = A − 1 A = I AA^{-1}= A^{-1}A=I AA−1=A−1A=I.
(2) 矩阵的转置
Let A be an m×n matrix, and let B= A T A^T AT. Then B is an n×m matrix, and B i j = A j i B_{ij}=A_{ji} Bij=Aji.
Chapter4 多变量线性回归
Notation
| 项目 | Value |
|---|---|
| n | number of features |
| x ( i ) x^{(i)} x(i) | input of i t h i^{th} ith training example |
| x j ( i ) {x^{(i)}_j} xj(i) | value of feature j in i t h i^{th} ith training example |
假设函数: h θ ( x ) = θ T x = θ 0 x 0 + θ 1 x 1 + θ 2 x 2 + . . . + θ n x n h_θ(x)=θ^Tx=θ_0x_0+θ_1x_1+θ_2x_2+...+θ_nx_n hθ(x)=θTx=θ0x0+θ1x1+θ2x2+...+θnxn 其中, x 0 = 1 x_0=1 x0=1
参数:θ ,为n+1维向量
代价函数: J ( θ ) = 1 2 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) 2 \mathrm J(θ)=\cfrac {1}{2m}\displaystyle\sum_{i=1}^m(h_{θ}(x^{(i)})-y^{{(i)}})^{2} J(θ)=2m1i=1∑m(hθ(x(i))−y(i))2
多变量梯度下降法
(使用梯度下降法处理多元线性回归)
Repeat {
θ j : = θ j − α 1 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) x j ( i ) θ_j:= θ_j-α\cfrac {1}{m}\displaystyle\sum_{i=1}^m(h_{θ}(x^{(i)})-y^{{(i)}})x^{(i)}_j θj:=θj−αm1i=1∑m(hθ(x(i))−y(i))xj(i) ( simultaneously update θ j θ_j θj for j = 0,…,n )
}
注意:
- 特征缩放:
由于各特征值范围不一,可能影响代价函数的收敛速度。通过特征缩放,使得他们的值的范围更相近,这样,收敛所需的迭代次数更少。
Feature Scalling:Get every feature into approximately a -1 ≤ x i x_i xi ≤ 1 range.
方法:
(1)将特征值除以最大值
(2)归一 法
x i = x i − a v g ( x ) m a x ( x ) − m i n ( x ) x_i=\cfrac {x_i-avg(x)}{max(x)-min(x)} xi=max(x)−min(x)xi−avg(x) - 如何选择学习率?
通过绘制代价函数随迭代步数变化的曲线,确定学习率的取值。
If α is too small:slow convergence
If α is too large:J(θ) may not decrease on every iteration;may not converge.
To choose α, try…,0.001, 0.003, 0.01, 0.03, 0.1, 0.3, 1,…
正规方程法
(梯度下降算法需要经过梯度下降的多次迭代,获得最小代价函数J(θ)。而正规方程则不须运行迭代算法,只需一步求解θ的最优值)
- 使用步骤:
(1)构建矩阵X、向量y。本例中,矩阵X维度为:m×(n+1);y为m维向量
(2)利用公式求解最优θ值(最小化线性回归的代价函数J(θ))
注意:
使用正规方程法不需要特征缩放 - 梯度下降法与正规方程法的区别
(1)梯度下降需要选择学习率α,而正规方程法不需要
(2)梯度下降算法需要多次迭代,而正规方程法不需要
(3)由于逆矩阵计算代价较高(以矩阵维度的三次方增长, X T X X^{T}X XTX维度为n×n时,代价为O( n 3 n^{3} n3))。因此,当n的值很大时,正规方程方法运行慢。故当特征数目<=10000时,选用正规方程法;当特征数目n>10000时,选用梯度下降方法
(4)在线性回归模型中,正规方程方法适用(并且比梯度下降算法更快);在一些更复杂的算法中(例如分类算法、logistic回归算法),正规方程并不适用
多项式回归
(使用线性回归的方法来拟合复杂函数、甚至非线性函数)
例:
h θ ( x ) = θ 0 + θ 1 x 1 + θ 2 x 2 + θ 3 x 3 = θ 0 + θ 1 ( s i z e ) + θ 2 ( s i z e ) 2 + θ 3 ( s i z e ) 3 h_θ(x)=θ_0+θ_1x_1+θ_2x_2+θ_3x_3=θ_0+θ_1(size)+θ_2(size)^{2}+θ_3(size)^{3} hθ(x)=θ0+θ1x1+θ2x2+θ3x3=θ0+θ1(size)+θ2(size)2+θ3(size)3
h θ ( x ) = θ 0 + θ 1 ( s i z e ) + θ 2 ( s i z e ) h_θ(x)=θ_0+θ_1(size)+θ_2\sqrt{(size)} hθ(x)=θ0+θ1(size)+θ2(size)
在使用多项式回归时,注意特征的缩放
Chapter 5 逻辑回归
逻辑回归是一种常用的分类算法,其输出值永远在 0 到 1 之间。
假设函数
定义:
h θ ( x ) = g ( θ T x ) h_θ(x)=g(θ^Tx) hθ(x)=g(θTx)
其中, h θ ( x ) h_θ(x) hθ(x) 的范围为 (0,1)
其含义为: x x x 及 θ 情况下,y = 1 的可能性
h θ ( x ) = P ( y = 1 ∣ x ; θ ) = 1 − P ( y = 0 ∣ x ; θ ) h_θ(x)=P(y=1|x;θ)=1-P(y=0|x;θ) hθ(x)=P(y=1∣x;θ)=1−P(y=0∣x;θ)
将sigmoid函数 g ( z ) = 1 1 + e − z g(z)=\cfrac{1}{1+e^{-z}} g(z)=1+e−z1代入逻辑回归模型,得到:
h θ ( x ) = 1 1 + e − θ T x h_θ(x)=\cfrac{1}{1+e^{-θ^Tx}} hθ(x)=1+e−θTx1
决策边界
决策边界即为分类的边界线
举例:

代价函数
J ( θ ) = 1 m ∑ i = 1 m ( h θ ( x ) , y ( i ) ) \mathrm J(θ)=\cfrac {1}{m}\displaystyle\sum_{i=1}^m(h_{θ}(x),y^{{(i)}}) J(θ)=m1i=1∑m(hθ(x),y(i))
C o s t ( h θ ( x ) , y ) = − l o g ( h θ ( x ) ) Cost(h_θ(x),y)=-log(h_θ(x)) Cost(hθ(x),y)=−log(hθ(x)) if y=1
C o s t ( h θ ( x ) , y ) = − l o g ( 1 − h θ ( x ) ) Cost(h_θ(x),y)=-log(1-h_θ(x)) Cost(hθ(x),y)=−log(1−hθ(x)) if y=0
简化:
对于二元分类问题:
C o s t ( h θ ( x ) , y ) = − y l o g ( h θ ( x ) ) − ( 1 − y ) l o g ( 1 − h θ ( x ) ) Cost(h_θ(x),y)=-ylog(h_θ(x))-(1-y)log(1-h_θ(x)) Cost(hθ(x),y)=−ylog(hθ(x))−(1−y)log(1−hθ(x))
J ( θ ) = − 1 m ∑ i = 1 m [ y ( i ) l o g ( h θ ( x ( i ) ) ) + ( 1 − y ( i ) ) l o g ( 1 − h θ ( x ( i ) ) ) ] \mathrm J(θ)=-\cfrac {1}{m}\displaystyle\sum_{i=1}^m[y^{(i)}log(h_θ(x^{(i)}))+(1-y^{(i)})log(1-h_θ(x^{(i)}))] J(θ)=−m1i=1∑m[y(i)log(hθ(x(i)))+(1−y(i))log(1−hθ(x(i)))]
梯度下降
(最小化代价函数)
Repeat {
θ j : = θ j − α ∂ ∂ θ j J ( θ ) θ_j:= θ_j-α\cfrac {\partial}{\partialθ_j}J(θ) θj:=θj−α∂θj∂J(θ)
}
(simultaneously update all θ j θ_j θj)
解偏导得:
Repeat {
θ j : = θ j − α ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) x j ( i ) θ_j:= θ_j-α\displaystyle\sum_{i=1}^m(h_θ(x^{(i)})-y^{(i)})x_j^{(i)} θj:=θj−αi=1∑m(hθ(x(i))−y(i))xj(i)
}
(simultaneously update all θ j θ_j θj)
区分:
线性回归与Logistic回归的梯度下降算法中,更新规则形式相同,但其中假设函数hθ(x)的含义不同。
线性回归中, h θ ( x ) = θ T x h_θ(x)=θ^Tx hθ(x)=θTx ;Logistic回归中, h θ ( x ) = 1 1 + e − θ T x h_θ(x)=\cfrac {1}{1+e^{-θ^Tx}} hθ(x)=1+e−θTx1 。
除梯度下降外,还有其他优化算法:
Conjugate gradient
BFGS
L-BFGS
以上三种方法不需要手动选择学习率,相比梯度下降更快,但更加复杂。
多类别分类问题
原理:转化成多个二元分类问题
Train a logistic regression classifier h θ ( i ) ( x ) h_θ^{(i)}(x) hθ(i)(x) for each class i to predict the probability that y=i.
On a new input x, to make a prediction, pick the class i that maximizes.(即选出k个分类器中可信度最高、效果最好的)
h θ ( i ) ( x ) = p ( y = i ∣ x ; θ ) h_θ^{(i)}(x)=p(y=i|x;θ) hθ(i)(x)=p(y=i∣x;θ) i=(1,2,3…k)
其中,k表示类别数量; h θ ( i ) ( x ) h_θ^{(i)}(x) hθ(i)(x)表示输出 y=i 的可能性
Chapter6 正则化
过拟合问题
欠拟合(Underfitting):不能很好地拟合训练数据
过拟合(Overfitting):过度地拟合了训练数据,而没有考虑到泛化能力
解决过拟合问题的方法:
解决过拟合问题:
(1) 减少变量数量
人工检查变量清单,选择要保留的变量/ 模型选择算法
(2)正则化
基本思想:惩罚各个参数大小,降低模型复杂度,改善或减少过拟合问题。
正则化代价函数
J ( θ ) = 1 2 m [ ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) 2 − λ ∑ j = 1 n θ j 2 ] \mathrm J(θ)=\cfrac {1}{2m}[\displaystyle\sum_{i=1}^m({h_θ(x^{(i)})-y^{(i)})}^{2}-λ\sum_{j=1}^n{θ_{j}}^{2}] J(θ)=2m1[i=1∑m(hθ(x(i))−y(i))2−λj=1∑nθj2]
其中,
λ ∑ j = 1 n θ j 2 λ\sum_{j=1}^n{θ_{j}}^{2} λ∑j=1nθj2为正则化项
正则化参数λ:控制两个目标(更好地拟合训练集的目标、将参数控制得更小)之间的平衡关系
线性回归、逻辑回归的正则方法
将正则化的思想用在线性回归和Logistic回归,来避免过拟合问题。
一、线性回归正则化
拟合线性回归模型的两种算法:
(1)梯度下降
Repeat {
θ 0 : = θ 0 − α 1 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) x 0 ( i ) θ_0:= θ_0-α\cfrac {1}{m}\displaystyle\sum_{i=1}^m(h_θ(x^{(i)})-y^{(i)})x_0^{(i)} θ0:=θ0−αm1i=1∑m(hθ(x(i))−y(i))x0(i)
θ j : = θ j − α [ 1 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) x j ( i ) + λ m θ j ] θ_j:= θ_j-α[\cfrac {1}{m}\displaystyle\sum_{i=1}^m(h_θ(x^{(i)})-y^{(i)})x_j^{(i)}+\cfrac {λ}{m}θ_j] θj:=θj−α[m1i=1∑m(hθ(x(i))−y(i))xj(i)+mλθj]
}
(2)正规方程
X = [ ( x ( 1 ) ) T . . . . . . ( x ( m ) ) T ] X= \left[ \begin{matrix} (x^{(1)})^{T} \\ ...\\ ...\\ (x^{(m)})^{T} \end{matrix} \right] X=⎣⎢⎢⎡(x(1))T......(x(m))T⎦⎥⎥⎤
y = [ y ( 1 ) . . . . . . y ( m ) ] y= \left[ \begin{matrix} y^{(1)} \\ ...\\ ...\\ y^{(m)} \end{matrix} \right] y=⎣⎢⎢⎡y(1)......y(m)⎦⎥⎥⎤
θ = ( X T X + λ M ) − 1 X T y θ=(X^{T}X+λM)^{-1}X^{T}y θ=(XTX+λM)−1XTy
M为(n+1)*(n+1)矩阵:
M = [ 0 1 . . . 1 ] M= \left[ \begin{matrix} 0& & & \\ & 1 & & \\ & & ... & \\ & & & 1 \end{matrix} \right] M=⎣⎢⎢⎡01...1⎦⎥⎥⎤
二、逻辑回归正则化
正则化的逻辑回归代价函数:
J ( θ ) = − 1 m ∑ i = 1 m [ y ( i ) l o g ( h θ ( x ( i ) ) ) + ( 1 − y ( i ) ) l o g ( 1 − h θ ( x ( i ) ) ) ] + λ 2 m ∑ j = 1 n θ j ] \mathrm J(θ)=-\cfrac {1}{m}\displaystyle\sum_{i=1}^m[y^{(i)}log(h_θ(x^{(i)}))+(1-y^{(i)})log(1-h_θ(x^{(i)}))]+\cfrac {λ}{2m}\sum_{j=1}^nθ_j] J(θ)=−m1i=1∑m[y(i)log(hθ(x(i)))+(1−y(i))log(1−hθ(x(i)))]+2mλj=1∑nθj]
正则化的逻辑回归梯度下降算法:
Repeat {
θ 0 : = θ 0 − α 1 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) x 0 ( i ) θ_0:= θ_0-α\cfrac {1}{m}\displaystyle\sum_{i=1}^m(h_θ(x^{(i)})-y^{(i)})x_0^{(i)} θ0:=θ0−αm1i=1∑m(hθ(x(i))−y(i))x0(i)
θ j : = θ j − α [ 1 m ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) x j ( i ) + λ m θ j ] θ_j:= θ_j-α[\cfrac {1}{m}\displaystyle\sum_{i=1}^m(h_θ(x^{(i)})-y^{(i)})x_j^{(i)}+\cfrac {λ}{m}θ_j] θj:=θj−α[m1i=1∑m(hθ(x(i))−y(i))xj(i)+mλθj]
}
Chapter7 神经网络
背景
在特征过多的情况下,简单逻辑回归算法不适合学习复杂非线性假设。而神经网络可以处理特征量过大的情况。
- 神经网络起源:人们尝试设计模仿大脑的算法
- 广泛应用:1980s-1990s
- 没落:1990后期
- 再次兴起:重要原因: 计算机运行速度变快
模型表示
类比大脑神经元,树突表示输入,接受来自其他神经元的信息;细胞核表示激活单元;轴突表示输出,向其他神经元传递信号。
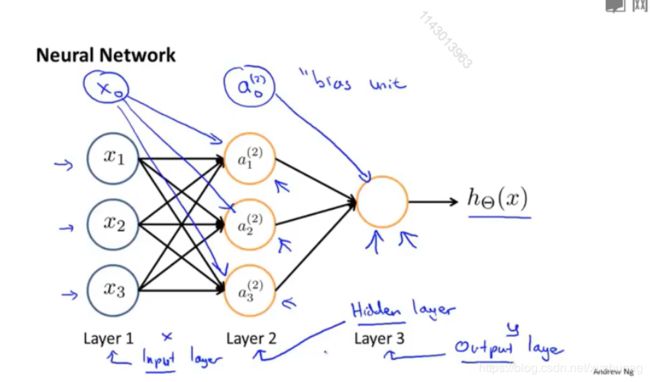
符号说明:
| 项目 | Value |
|---|---|
| 输入层 | 对应训练集中的特征 x x x |
| 输出层 | 对应训练集中的结果 y y y |
| x 0 x_0 x0 | 值为1,偏置单元,根据具体例子中是否方便选择加或不加 x 0 x_0 x0 |
| activation function | 激活函数,非线性函数g(z) |
| θ | 参数(parameters),文献中也称为权重(weights) |
| a i ( j ) a_i^{(j)} ai(j) | 第 j j j层的第 i i i个激活单元 |
| θ ( j ) θ^{(j)} θ(j) | 第 j j j层映射到第 j + 1 j+1 j+1层的权重矩阵 |
计算:
(1)前向传播
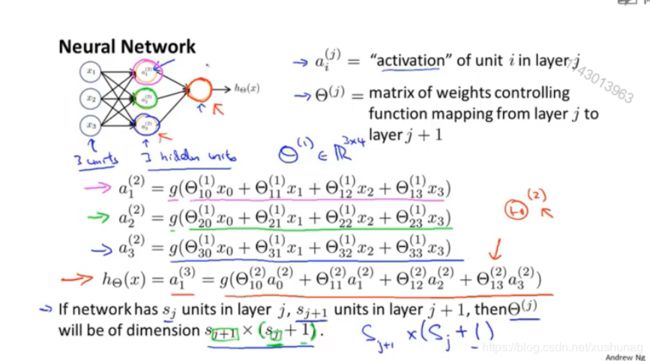
注:
逻辑回归使用原始的 x 1 , x 2 , x 3 x_1,x_2,x_3 x1,x2,x3作为特征
神经网络使用隐藏层计算的数值 a 1 ( 2 ) , a 2 ( 2 ) , a 3 ( 2 ) a_1^{(2)},a_2^{(2)},a_3^{(2)} a1(2),a2(2),a3(2)作为特征
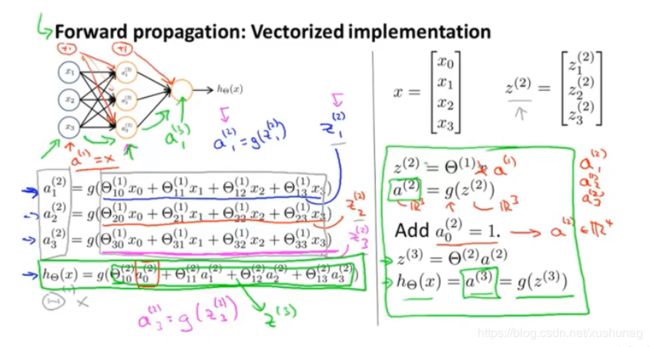
(2)计算h(x)的高效方法:向量化
多元分类
利用神经网络解决多类别分类问题
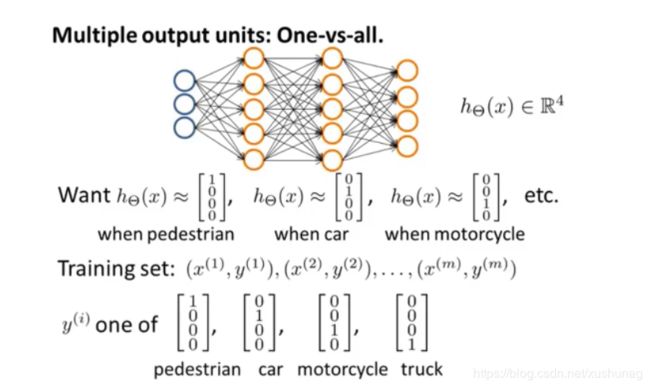
输出层输出单元个数即为类别数