elastic-job2 项目接入(spring,maven)
最近系统在使用esjob进行定时任务管理,现将接入过程分享给大家:
引入依赖
com.dangdang
elastic-job-lite-core
2.1.2
com.dangdang
elastic-job-lite-spring
2.1.2
简单任务
指定分片数后,当分片数大于机器数量的时候,每台机器分配到的片数会是平均的,例如:第一片是从0开始的,比如总共分6片,有两台机器,则第一台机器会分得0,1,2三片,而第二台机器会分得3,4,5三片;当有机器宕机了或者有新机器加入的时候都会触发重新分片。如果有多台机器,而分片总数是1的时候即相当于1主多从的配置。sharding-item-parameters用于指定与分片对应的别名。sharding-item-parameters="0=A,1=B,2=C,3=D,4=E"job-sharding-strategy-class:可以通过它来指定作业分片策略,可选策略可参考官方文档http://elasticjob.io/docs/elastic-job-lite/02-guide/config-manual/。编写任务
package com.el.test.job;
import com.dangdang.ddframe.job.api.ShardingContext;
import com.dangdang.ddframe.job.api.simple.SimpleJob;
import com.el.test.model.Name;
import com.el.test.service.NameServiceBean;
import org.springframework.beans.factory.annotation.Autowired;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
/**
* 简单作业:
* 指定分片数后,当分片数大于机器数量的时候,每台机器分配到的片数会是平均的,
* 例如:第一片是从0开始的,比如总共分6片,有两台机器,
* 则第一台机器会分得0,1,2三片,而第二台机器会分得3,4,5三片;
* 当有机器宕机了或者有新机器加入的时候都会触发重新分片。
* 如果有多台机器,而分片总数是1的时候即相当于1主多从的配置。
* sharding-item-parameters用于指定与分片对应的别名。sharding-item-parameters="0=A,1=B,2=C,3=D,4=E"
* job-sharding-strategy-class:可以通过它来指定作业分片策略,
* 可选策略可参考官方文档http://elasticjob.io/docs/elastic-job-lite/02-guide/config-manual/。
*/
public class TestJob implements SimpleJob {
@Autowired
private NameServiceBean nameServiceBean;
/**
* 具体执行逻辑,包含根据分片信息获取数据与业务逻辑处理
* @param shardingContext 分片信息
*/
@Override
public void execute(ShardingContext shardingContext) {
System.out.println("SpringSimpleJob 简单任务-------------任务名:"+shardingContext.getJobName()+"\n"
+",---ShardingParameter:"+shardingContext.getShardingParameter()+"\n"
+",----TaskId:"+shardingContext.getTaskId()+"\n"
+",----JobParameter:"+shardingContext.getJobParameter()+"\n"
+",----tShardingItem:"+shardingContext.getShardingItem()+"\n"
+",----ShardingTotalCount:"+shardingContext.getShardingTotalCount()+"\n"
);
HashMap parm = new HashMap();
List shardingList=nameServiceBean.list(parm);
for(Name oneObj : shardingList){
System.out.println(
"SpringSimpleJob 简单任务-------------id为:"+oneObj.getId()+"\n" +
",----tShardingItem:"+shardingContext.getShardingItem()+"\n"
);
}
}
}
配置xml
流式任务
每次调度触发的时候都会先调fetchData获取数据,如果获取到了数据再调度processData方法处理数据。DataflowJob在运行时有两种方式,流式的和非流式的,通过属性streamingProcess控制,如果是基于SpringXML的配置方式则是streaming-process属性,boolean类型。当作业配置为流式的时候,每次触发作业后会调度一次fetchData获取数据,如果获取到了数据会调度processData方法处理数据,处理完后又继续调fetchData获取数据,再调processData处理,如此循环,就像流水一样。直到fetchData没有获取到数据或者发生了重新分片才会停止。
core code:com.dangdang.ddframe.job.executor.type.DataflowJobExecutor
DataflowJobExecutor
protected void process(ShardingContext shardingContext) {
DataflowJobConfiguration dataflowConfig = (DataflowJobConfiguration)this.getJobRootConfig().getTypeConfig();
if (dataflowConfig.isStreamingProcess()) {
this.streamingExecute(shardingContext);
} else {
this.oneOffExecute(shardingContext);
}
}
private void streamingExecute(ShardingContext shardingContext) {
for(List data = this.fetchData(shardingContext); null != data && !data.isEmpty(); data = this.fetchData(shardingContext)) {
this.processData(shardingContext, data);
if (!this.getJobFacade().isEligibleForJobRunning()) {
break;
}
}
}
private void oneOffExecute(ShardingContext shardingContext) {
List编写任务
package com.el.test.job;
import com.dangdang.ddframe.job.api.ShardingContext;
import com.dangdang.ddframe.job.api.dataflow.DataflowJob;
import com.el.test.model.Name;
import com.el.test.service.NameServiceBean;
import org.springframework.beans.factory.annotation.Autowired;
import java.util.HashMap;
import java.util.List;
/**
* 流式作业:
* 每次调度触发的时候都会先调fetchData获取数据,
* 如果获取到了数据再调度processData方法处理数据。
* DataflowJob在运行时有两种方式,流式的和非流式的,
* 通过属性streamingProcess控制,如果是基于Spring XML的配置方式则是streaming-process属性,
* boolean类型。当作业配置为流式的时候,每次触发作业后会调度一次fetchData获取数据,
* 如果获取到了数据会调度processData方法处理数据,处理完后又继续调fetchData获取数据,
* 再调processData处理,如此循环,就像流水一样。直到fetchData没有获取到数据或者发生了
* 重新分片才会停止。
* core code:com.dangdang.ddframe.job.executor.type.DataflowJobExecutor
*
* protected void process(ShardingContext shardingContext) {
DataflowJobConfiguration dataflowConfig = (DataflowJobConfiguration)this.getJobRootConfig().getTypeConfig();
if (dataflowConfig.isStreamingProcess()) {
this.streamingExecute(shardingContext);
} else {
this.oneOffExecute(shardingContext);
}
}
private void streamingExecute(ShardingContext shardingContext) {
for(List data = this.fetchData(shardingContext); null != data && !data.isEmpty(); data = this.fetchData(shardingContext)) {
this.processData(shardingContext, data);
if (!this.getJobFacade().isEligibleForJobRunning()) {
break;
}
}
}
private void oneOffExecute(ShardingContext shardingContext) {
List配置xml
搭建运维平台
从git上down下代码,https://github.com/elasticjob/elastic-job-lite
编译elastic-job-lite-console项目
本人有一套直接编译成功的,欢迎大家下载 【elastic-job-lite-console-2.1.2.tar.gz】
解压缩elastic-job-lite-console-2.1.2.tar.gz并执行bin\start.sh。打开浏览器访问http://localhost:8899/即可访问控制台。8899为默认端口号,可通过启动脚本输入-p自定义端口号。
运维平台提供两种账户,管理员及访客,管理员拥有全部操作权限,访客仅拥有察看权限。默认管理员用户名和密码是root/root,访客用户名和密码是guest/guest,可通过conf\auth.properties修改管理员及访客用户名及密码。
主页如下:

添加zk

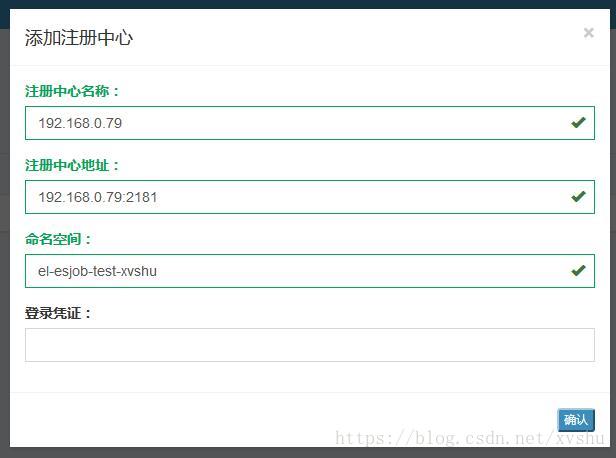
附录:
spring完整配置