监控tomcat日志——flume+kafka
小编最近在研究使用flume监控tomcat的日志,以便及早发现问题,防止集群出现问题。初来乍到,确实踩了很多坑,一个简单的问题花了好几天的时间。在这做一个小小的总结。
最开始,我是在windows系统上做测试,在网上查了很多资料,网上的资料一般都是基于linux系统,所以很难借鉴。就是因此,导致了我再windows上测试了遇到许多问题,比如说tomcat日志没有catalina.out文件,tail命令windows系统不自带等等。最终是在linux上弄成功了,虽然我还是没有找到windows上的问题,但我还是建议大家就在linux系统上测试。下面阐述的一下我的整个过程。
1.了解tomcat日志的构成
大家可以看看tomcat的logs目录,我们可以发现tomcat是由一个大文件catalina.out和许多小文件构成。那个大文件其实就是所有的日志,一产生日志就追加,而小文件就是每一天的日志,每天产生的就追加到相应的文件里去。当然我采用的数据源是大文件catalina.out,具体原因待会再做讲解。
2.flume的安装及使用
1.认识flume
Flume是Cloudera提供的一个高可用、高可靠、分布式的海量日志采集、聚合和传输的系统.说白了,就是日志采集系统,而且是实时的。
我的认识就是:它是一个中间件,从别的数据源读取数据,再放到另外的地方去。
官方解释:Flume的数据流由事件(Event)贯穿始终。事件是Flume的基本数据单位,它携带日志数据(字节数组形式)并且携带有头信息,这些Event由Agent外部的Source生成,当Source捕获事件后会进行特定的格式化,然后Source会把事件推入(单个或多个)Channel中。可以把Channel看作是一个缓冲区,它将保存事件直到Sink处理完该事件。Sink负责持久化日志或者把事件推向另一个Source。
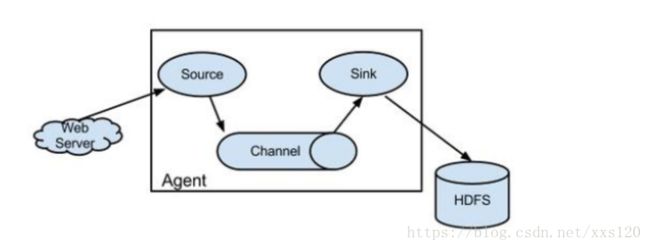
我们要特别注意三大部分:分别是:source,channel,sink
source:即数据源,主要有avro,spool,exec等等。其中Avro**可以发送一个给定的文件给Flume,Avro 源使用AVRO RPC机制。spool**是监听一个指定的目录,只要应用程序向这个指定的目录中添加新的文件,source组件就可以获取到该信息,并解析该文件的内容,然后写入到channl,写入完成后,标记该文件已完成或者删除该文件。exec**是监听一个指定的命令,获取一条命令的结果作为它的数据源,常用的是tail -F file指令,即只要应用程序向日志(文件)里面写数据,source组件就可以获取到日志(文件)中最新的内容。缺点就是必选使得file足够大才能看到输出内容。
以我的理解,我们知道我们所要监控的tomcat日志不仅每天有文件产生,而且文件的内容也是一直在增加,所以我选择使用exec方式监控大文件catalina.out.(资料很多显示建议使用spool,因为spool的安全性比较高,而exec channel接收的数据源如果有问题或抛出异常,exec并不能捕获异常,但是基于此文件是变化的,我还没有找到使用spool的方法,下来再继学习)
channel:作为缓存的
sink:接收数据源的,可以为,kafka,file,memory,hadoop,file_roll等等。
2.flume的安装配置
1.下载flume安装包
http://apache.mirrors.hoobly.com/flume/1.7.0/apache-flume-1.7.0-bin.tar.gz
我把安装包放在/home/hadoop文件下,然后解压。
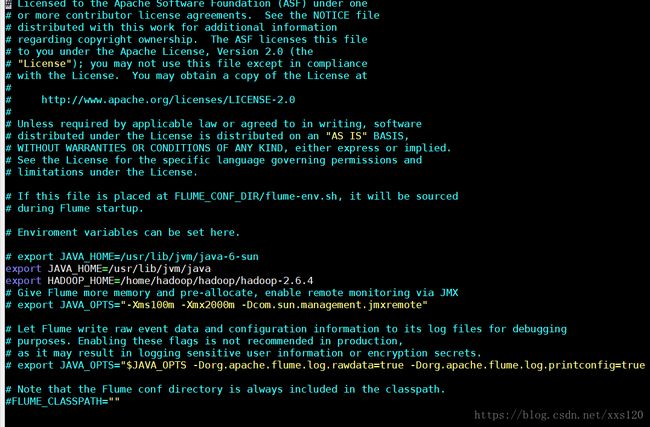
2.配置flume.env.sh(一定要配置,主要是java的环境变量的配置)
3.配置tomcat.conf
其实flume就是一个配置文件的事,只要配置文件对了就对了。
# A single-node Flume configuration
# Name the components on this agent
agent1.sources = source1
agent1.sinks = sink1
agent1.channels = channel1
# Describe/configure source1
#数据源
agent1.sources.source1.type=exec
agent1.sources.source1.command=tail -F /home/suitang/tomcat/logs/catalina.out
agent1.sources.source1.channels = channel1
# Describe sink1
#数据目的地
agent1.sinks.sink1.type = org.apache.flume.sink.kafka.KafkaSink
agent1.sinks.sink1.topic=test1
agent1.sinks.sink1.brokerList=192.168.1.208:9092
agent1.sinks.sink1.batchSize=20
agent1.sinks.sink1.channels=channel1
#缓存
# Use a channel which buffers events in memory
agent1.channels.channel1.type = file
agent1.channels.channel1.checkpointDir=/home/hadoop/flume/checkpoint
agent1.channels.channel1.dataDirs=/home/hadoop/flume/tmp
#agent1.channels.channel1.type = memory
#agent1.channels.channel1.capacity = 1000
#agent1.channels.channel1.transactionCapactiy = 100
# Bind the source and sink to the channel
agent1.sources.source1.channels = channel1
agent1.sinks.sink1.channel = channel1然后在flume的安装目录下执行:
bin/flume-ng agent -n agent1 -c conf -f conf/tomcat.conf -Dflume.root.logger=INFO,console
后台启动进程方式:
nohup bin/flume-ng agent -n agent1 -c conf -f conf/tomcat.conf -Dflume.root.logger=INFO,console &>flume.out &
3.kafka的使用
kafka的安装与配置前面已有大神讲解过,我在此就不细说了,有需要的可以看
https://rednum.cn/ViewListAction?method=detail&dataid=265&classfyid=1
我们在flume的flume.env.sh配置文件里已经配置好了,在此我们把zookeeper,kafka开启。然后进入kafka的安装目录,输入:
kafka生产者:
bin/kafka-console-producer.sh —broker-list 192.168.1.208:9092 —topic test1
另一个终端输入:
kafka消费者:
bin/kafka-console-consumer.sh —zookeeper 192.168.1.208:2183 —topic test1 —from-beginning
哇,我们就可以看到日志记录唰唰的就跑出来啦。到此,我们就成功的收集到了tomcat的日志,并以消息队列的方式产生。