卷积神经网络图像尺寸预处理-----图像裁剪
在全卷积网络(FCN)中可以输入任意大小的图像尺寸,但卷积网络(CNN)中就不是这样了,在CNN是有卷积层和全连接层。首先我们知道卷积层对输入的图像尺寸是没有限制的,而全连接层就对输入的图像像有要求了。因为全连接层输入向量的维数对应其层的神经元个数,如果输入向量的维数不固定,那么全链接的权值参数的数量也是不固定的,这样网络就是变化的,无法对模型训练。所以全连接层的输入必须是固定的大小。
为了让卷积网络学到更加真实一致特征,在深度学习时候一般需要对图像进行预处理裁剪。怎么样的调整裁剪图像尺寸才是最佳的呢? 如果忽略了高宽比, 图像变得压缩,扭曲了(下图input_1所示)。在不影响识别目标的前提下,我们可以牺牲部分图像,就是剪掉部分图像,来保持高宽比,这样图像不会看着失真和扭曲。
处理方法:沿图像宽高最短尺寸调整大小,然后以中心为原点裁剪图像
如: 原图大小为836 X 1236
假如现在要固定图像大小,要求把图像尺寸调整到512 X 512像素。
如下:
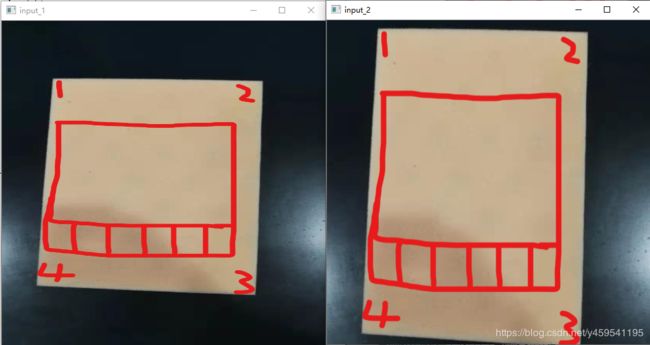
左图(input_1)直接resize到512x512像素(忽略纵横比), 右图(input_2)是裁剪沿最短尺寸调整并以图像中心裁剪到512x512
附代码如下:
import cv2
import imutils
def resize_crop_image(image,target_width,target_height):
(h, w) = image.shape[:2]
dH =0
dW=0
if w < h:
image = imutils.resize(image, width=target_width,
inter=cv2.INTER_AREA)
dH = int((image.shape[0] - target_height) / 2.0)
else:
image = imutils.resize(image, height=target_height,
inter=cv2.INTER_AREA)
dW = int((image.shape[1] - target_width) / 2.0)
(h, w) = image.shape[:2]
image = image[dH:h - dH, dW:w - dW]
return cv2.resize(image, (target_width, target_height),interpolation=cv2.INTER_AREA)
if __name__ =="__main__":
image_path = "F:\\yu_data\\002_a.jpg"
image = cv2.imread(image_path)
image_resize = cv2.resize(image,(512,512), cv2.INTER_AREA)
img = resize_crop_image(image,512,512)
cv2.namedWindow("input",cv2.WINDOW_NORMAL)
cv2.namedWindow("input_1",cv2.WINDOW_AUTOSIZE)
cv2.namedWindow("input_2",cv2.WINDOW_AUTOSIZE)
cv2.imshow("input",image)
cv2.imshow("input_1",image_resize)
cv2.imshow("input_2",img)
cv2.waitKey(0)
cv2.destroyAllWindows()
另外对于interpolation的选择
查看OpenCV的文档:
https://docs.opencv.org/4.1.1/da/d54/group__imgproc__transform.html#ga47a974309e9102f5f08231edc7e7529d
C++:
void cv::resize ( InputArray src,
OutputArray dst,
Size dsize,
double fx = 0,
double fy = 0,
int interpolation = INTER_LINEAR
)
Python:
dst = cv.resize( src, dsize[, dst[, fx[, fy[, interpolation]]]] )
#include Resizes an image.
The function resize resizes the image src down to or up to the specified size. Note that the initial dst type or size are not taken into account. Instead, the size and type are derived from the src,dsize,fx, and fy. If you want to resize src so that it fits the pre-created dst, you may call the function as follows:
// explicitly specify dsize=dst.size(); fx and fy will be computed from that.
resize(src, dst, dst.size(), 0, 0, interpolation);
If you want to decimate the image by factor of 2 in each direction, you can call the function this way:
// specify fx and fy and let the function compute the destination image size.
resize(src, dst, Size(), 0.5, 0.5, interpolation);
To shrink an image, it will generally look best with INTER_AREA interpolation, whereas to enlarge an image, it will generally look best with c::INTER_CUBIC (slow) or INTER_LINEAR (faster but still looks OK).
故缩小图像尺寸用了cv2.INTER_AREA
/******************************分割线 ***************************************************/
举个栗子:
训练YoloV3时, 在将图片输入模型之前,需要将图片尺寸 resize 成固定的大小,如 416X416 或 608X608 。如果直接对图片进行 resize 处理,那么会使得图片扭曲变形从而降低模型的预测精度。
import cv2
import numpy as np
def image_preporcess(image, target_size):
# resize 尺寸
ih, iw = target_size
# 原始图片尺寸
h, w, _ = image.shape
# 计算缩放后图片尺寸
scale = min(iw/w, ih/h)
nw, nh = int(scale * w), int(scale * h)
image_resized = cv2.resize(image, (nw, nh))
# 创建一张画布,画布的尺寸就是目标尺寸
# fill_value=120为灰色画布
image_paded = np.full(shape=[ih, iw, 3], fill_value=120)
dw, dh = (iw - nw) // 2, (ih-nh) // 2
# 将缩放后的图片放在画布中央
image_paded[dh:nh+dh, dw:nw+dw, :] = image_resized
# 归一化处理
image_paded = image_paded / 255.
return image_paded
if __name__=="__main__":
image_path = "/home/ubuntu/work/eagle.jpg"
image = cv2.imread(image_path)
img=image_preporcess(image,(416,416))
cv2.namedWindow("target_size_img",cv2.WINDOW_AUTOSIZE)
cv2.imshow("target_size_img",img)
cv2.imwrite("/home/ubuntu/work/target_size_img.jpg",img*255.)
cv2.waitKey(0)
cv2.destroyAllWindows()
效果:
| 原始图像773 x 512 | 目标图像 416 x 416 |
|---|---|
 |
 |
注:图像在显示前要除以255,为了保证更高精度,经过了运算的图像矩阵,其数据类型会从unit8型变成double型.若直接运行imshow(), 我们会看到时一张白色的图像. 这是因为imshow()显示图像时对double型认为是在0~1范围内, 也就是大于1时都是显示为白色, 而imshow()显示uint8型时是0~255范围.
完~