Keras实现用于文本分类的attention机制
- keras没有提供attention机制的实现,这里参考kaggle上一个kernel中的attention机制的实现,也学习一下keras中如何自定义层。
- 也是想熟悉一下attention机制的代码实现。本文中的attention layer用于文本分类,和encoder-decoder的attention有些不同。
1 Keras源码参考
- keras官网 写的非常简洁,给了一个类的框架,然后直接说参考源码中其他Layer的写法。这里直接参考一个最简单的Dense吧,Keras中的Dense Layer也就是全连接层。说起来每个框架里全连接层起名都不一样…caffe叫InnerProduct(内积),IP层, pytorch叫linear,tf叫matmul,现在也改叫dense了,毕竟和keras一家的。
- 我下载的源码版本是2.2.4。Dense类在
keras/layers/core.py中。 - Dense类中的
call()函数如下,call函数中写具体逻辑,可以看到逻辑非常简单,就是做一个点乘,有bias加bias,有activation做activation。self.kernel的初始化在函数build()里。
def call(self, inputs):
output = K.dot(inputs, self.kernel)
if self.use_bias:
output = K.bias_add(output, self.bias, data_format='channels_last')
if self.activation is not None:
output = self.activation(output)
return output
- Dense类中的
build()函数如下。其中对self.kernel做了初始化,其shape为input_shape[-1], self_units,self_units就是创建Dense对象时传进来的参数。自己从numpy写神经网络,或者使用框架时都非常需要ndarray要有一个维度是表示batch,这是我容易忽略的。
这里为参数分配空间时,显然是不需要考虑batch的,因为每batch显然都是使用同样的参数,可以看到其shape = (input_dim, self.units)。
def build(self, input_shape):
assert len(input_shape) >= 2
input_dim = input_shape[-1]
self.kernel = self.add_weight(shape=(input_dim, self.units),
initializer=self.kernel_initializer,
name='kernel',
regularizer=self.kernel_regularizer,
constraint=self.kernel_constraint)
if self.use_bias:
self.bias = self.add_weight(shape=(self.units,),
initializer=self.bias_initializer,
name='bias',
regularizer=self.bias_regularizer,
constraint=self.bias_constraint)
else:
self.bias = None
self.input_spec = InputSpec(min_ndim=2, axes={-1: input_dim})
self.built = True
可以注意到除了最后两行,其他代码都很清楚,self.built = True是必须要写的,大概是表示分配空间,调用super(MyLayer, self).build(input_shape)也是可以的,Layer类中的build()函数里就一句self.built = True。
InputSpec()类可以看一下其源码,在engine/base_layer.py中,它有一个__repr__函数,是python类自带的一个方法,是用来显示的,print该类的对象时就会调用__repr__函数,也就是我们可以这样,print(model.layer[2].input_spec)查看当前层的dtype,shape等信息。但是print(model.summary)更好用,能看到model结构更详细的信息,以及每层之间怎么连接的。
- Dense类中的
compute_output_shape()如下。可以看到这里是计算输出的shape, keras中间结果为向量时,shape为(None, dim),类的说明写了,shape[0]表示batch维度(即batch_size),这里写None表示与任何数值兼容。
# now: model.output_shape == (None, 32)
# note: `None` is the batch dimension
显然全连接层的输出shape为(None, self.units)
def compute_output_shape(self, input_shape):
assert input_shape and len(input_shape) >= 2
assert input_shape[-1]
output_shape = list(input_shape)
output_shape[-1] = self.units
return tuple(output_shape)
2 Attention机制
- 这是ICLR14论文Neural machine translation by jointly learning to align and translate论文的部分截图,也是最早提出attention的论文。

attention机制的权重怎么来的用红框标出来了,可以看到 e i j e_{ij} eij是通过 s i − 1 , h j s_{i-1}, h_j si−1,hj得出的,论文里也说了这种机制就是基于encoder-decoder的,论文里 h j h_j hj成为annotation, s i s_i si称为hidden state,其实 s i s_i si就是decoder的第i个隐状态, h j h_j hj就是encoder的第j个隐状态。注意这里 s i s_i si也和 y i − 1 y_{i-1} yi−1有关,但是图里没画出来,论文的附录里有讲具体推导。
s i − 1 s_{i-1} si−1和 h j h_j hj都是向量,向量 s i − 1 s_{i-1} si−1显然等于decoder的每个timestep的输出 y i y_i yi维度, h j h_j hj的维度则是手动设置的RNN的hidden units的维度。
3 Attention机制用于文本分类
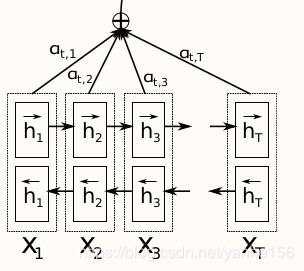
- encoder-decoder主要是解决输入序列和输出序列长度不同的问题,如语音识别中语音信息到文本,机器翻译中的不同语言。对应文本分类来说,用不到encoder-decoder模型,只需要取出Neural machine translation by jointly learning to align and translate中的模型的一部分结构就可以用于文本分类。此时求 e i j e_{ij} eij的公式也变成了
e j = a ( h j ) e_{j} = a(h_j) ej=a(hj) - 这也是naacl16的论文Hierarchical Attention Networks for Document Classification 中的做法。有的文章可能觉得用到的数据集太常见了,所以也没用说明,这篇文章用一个表格介绍了一下。这里的Document Classification指的就是文本分类,用到的数据集文本长度也都是比较短的。
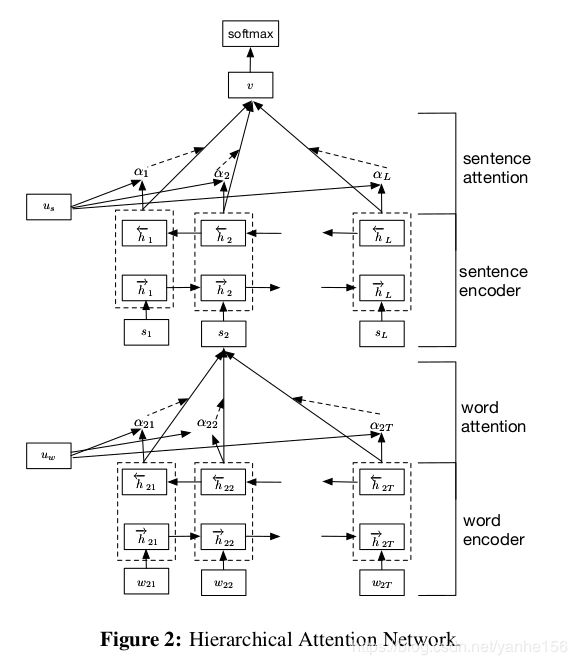
- 题目中的Hierarchical指的是做了两种层次的attention。论文我还没详细看,只看了模型结构。但是从结构上来说,这篇文章因为一段文本包括多句话(由句号或问号等标点符号分开),每句话包含多个词,所以先使用GRU+Attention对每句话的词向量进行训练,得到sentence representation,然后用GRU+Attention进行分类。
这篇文章结果不错,我的理解如下:
这篇文章里分层,也就是先用词向量训练句向量,然后再对句向量用GRU的意义在哪啊? 我感觉直接用词向量训练,然后attention应该也没差,文章里也没说这样做的目的,也可能是我看的还不够仔细。我觉得这篇文章的结果好,可能是因为直接用词向量进行分类,输入序列较长;但是用sentence representation进行分类,输入序列长度较短,此时document representation能够保留更多的信息,同时sentence representation是用词向量训练得到的,每个句子的长度也有限,也帮助保留了信息。可能这才是Hierarchical的意义所在吧。
- 另外,用attention非常好的一点是还能知道文本中的每个句子对结果的影响程度,和句子中的每个词对结果的影响程度。
(等等,我为什么想到了InfoGAN能够查看随机变量的每个维度对生成的复杂样本的影响,是否和attention有什么共通的地方)
4 代码实现及注释
- 首先明确这里的Attention的输入输出是什么,输入显然是RNN的输出,Keras中RNN的输出shape在注释里有写,如下:
# Output shape
- if `return_state`: a list of tensors. The first tensor is
the output. The remaining tensors are the last states,
each with shape `(batch_size, units)`.
- if `return_sequences`: 3D tensor with shape
`(batch_size, timesteps, units)`.
- else, 2D tensor with shape `(batch_size, units)`.
return_state这个参数不用在意,对单层RNN没影响(看了源码,但是没测试),因为其hidden state等于输出(这里单指RNN作为模型中一个组件的输出,不加softmax之类的函数)。
显然用attention时需要return_sequences = True。
参考代码:
class Attention(Layer):
'''
返回值:
返回的不是attention权重,而是每个timestep乘以权重后相加得到的向量。
输入:
输入是rnn的timesteps,也是最长输入序列的长度。keras
'''
def __init__(self, step_dim,
W_regularizer=None, b_regularizer=None,
W_constraint=None, b_constraint=None,
bias=True, **kwargs):
self.supports_masking = True
self.init = initializers.get('glorot_uniform')
self.W_regularizer = regularizers.get(W_regularizer)
self.b_regularizer = regularizers.get(b_regularizer)
self.W_constraint = constraints.get(W_constraint)
self.b_constraint = constraints.get(b_constraint)
self.bias = bias
self.step_dim = step_dim
self.features_dim = 0
super(Attention, self).__init__(**kwargs)
def build(self, input_shape):
assert len(input_shape) == 3
self.W = self.add_weight((input_shape[-1],),
initializer=self.init,
name='{}_W'.format(self.name),
regularizer=self.W_regularizer,
constraint=self.W_constraint)
self.features_dim = input_shape[-1]
if self.bias:
self.b = self.add_weight((input_shape[1],),
initializer='zero',
name='{}_b'.format(self.name),
regularizer=self.b_regularizer,
constraint=self.b_constraint)
else:
self.b = None
self.built = True
def compute_mask(self, input, input_mask=None):
# 后面的层不需要mask了,所以这里可以直接返回none
return None
def call(self, x, mask=None):
features_dim = self.features_dim
# 这里应该是 step_dim是我们指定的参数,它等于input_shape[1],也就是rnn的timesteps
step_dim = self.step_dim
# 输入和参数分别reshape再点乘后,tensor.shape变成了(batch_size*timesteps, 1),之后每个batch要分开进行归一化
# 所以应该有 eij = K.reshape(..., (-1, timesteps))
eij = K.reshape(K.dot(K.reshape(x, (-1, features_dim)),
K.reshape(self.W, (features_dim, 1))), (-1, step_dim))
if self.bias:
eij += self.b
# RNN一般默认激活函数为tanh, 对attention来说激活函数差别不打,因为要做softmax
eij = K.tanh(eij)
a = K.exp(eij)
if mask is not None:
# 如果前面的层有mask,那么后面这些被mask掉的timestep肯定是不能参与计算输出的,也就是将他们的attention权重设为0
a *= K.cast(mask, K.floatx())
# cast是做类型转换,keras计算时会检查类型,可能是因为用gpu的原因
a /= K.cast(K.sum(a, axis=1, keepdims=True) + K.epsilon(), K.floatx())
# a = K.expand_dims(a, axis=-1) , axis默认为-1, 表示在最后扩充一个维度。
# 比如shape = (3,)变成 (3, 1)
a = K.expand_dims(a)
# 此时a.shape = (batch_size, timesteps, 1), x.shape = (batch_size, timesteps, units)
weighted_input = x * a
# weighted_input的shape为 (batch_size, timesteps, units), 每个timestep的输出向量已经乘上了该timestep的权重
# weighted_input在axis=1上取和,返回值的shape为 (batch_size, 1, units)
return K.sum(weighted_input, axis=1)
def compute_output_shape(self, input_shape):
# 返回的结果是c,其shape为 (batch_size, units)
return input_shape[0], self.features_dim
5 比喻
- LSTM就像人因为记忆力有限,有些事该忘就忘。
- Attention机制就像我们一生中会遇到很多人很多事,当回顾自己漫长的记忆时,对某个人,某件事,大概只有那么几件事是相关的,是有着光彩的吧。