base16、base32和base64转码原理
文章目录
- base16、base32和base64,转码原理
- 基本概念
- 基于base16编解码源码介绍
- Base-64编码
- Encoding VS. Encryption
- 作用及原理
- 索引表
- base64索引表:
- base32索引表:
- base16索引表:
- 转码原理
- 转码
- base64填充
- 示例:
base16、base32和base64,转码原理
基本概念
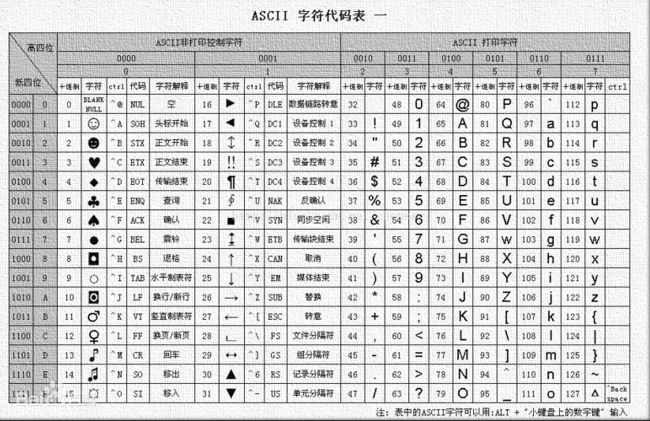
ASCII 是用128(2的8次方)个字符,对二进制数据进行编码的方式
base64编码是用64(2的6次方)个字符,对二进制数据进行编码的方式
base32就是用32(2的5次方)个字符,对二进制数据进行编码的方式
base16就是用16(2的4次方)个字符,对二进制数据进行编码的方式
基于base16编解码源码介绍
就是把二进制数据转成16进制,显示16进制的值就可以了
16进制一个字符是4位,正常一个字节是8位,切一半就转成16进制了。
所以,base16转码后空间扩大一倍,4位转成一个字符, 1个字节转成两个字符
#include 输出结果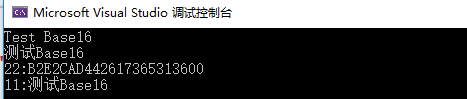
解码的时候’b’字符转换成ASCII码值位66,所以66位改为10的值。
Base-64编码
Encoding VS. Encryption
很多人都以为编码(Encoding)和加密(Encryption)是同一个意思。编码和加密都是对格式的一种转换,但是它们是有区别的。编码是 公开的,比如下面要介绍的Base 64编码,任何人都可以解码;而加密则相反,你只希望自己或者特定的人才可以对内容进行解密。
作用及原理
Base 64 Encoding有什么用?举个简单的例子,你使用SMTP协议 (Simple Mail Transfer Protocol 简单邮件传输协议)来发送邮件。因为这个协议是基于文本的协议,所以如果邮件中包含一幅图片,我们知道图片的存储格式是二进制数据(binary data),而非文本格式,我们必须将二进制的数据编码成文本格式,这时候Base 64 Encoding就派上用场了。
Base64编码的作用:由于某些系统中只能使用ASCII字符。Base64就是用来将非ASCII字符的数据转换成ASCII字符的一种方法。它使用下面表中所使用的字符与编码。
而且base64特别适合在http,mime协议下快速传输数据。
base64其实不是安全领域下的加密解密算法。虽然有时候经常看到所谓的base64加密解密。其实base64只能算是一个编码算法,对数据内容进行编码来适合传输。虽然base64编码过后原文也变成不能看到的字符格式,但是这种方式很初级,很简单。
X.509公钥证书也好,电子邮件数据也好,经常要用到Base64编码,那么为什么要作一下这样的编码呢?
我们知道在计算机中任何数据都是按ascii码存储的,而ascii码的128~255之间的值是不可见字符。而在网络上交换数据时,比如说从A地传到B地,往往要经过多个路由设备,由于不同的设备对字符的处理方式有一些不同,这样那些不可见字符就有可能被处理错误,这是不利于传输的。所以就先把数据先做一个Base64编码,统统变成可见字符,这样出错的可能性就大降低了。
如一个xml当中包含另一个xml数据,此时如果将xml数据直接写入显然不合适,将xml进行适当编码存入较为方便,事实上xml当中的字符一般都是可见字符(0-127之间),但是由于中文的存在,可能存在不可见字符,直接将字符打印在外层xml的数据中显然不合理,那么怎么办呢?
可以使用base64进行编码,然后存入xml,解码反之
其实还有个办法,将byte的值写在xml当中,空格或者,分开,这样也可以将byte数据传入,不过这样更浪费空间,并且不易保存.
另一个,比如http协议当中的key value字段,必须进行URLEncode 不然出现的等号可能使解析失败 空格也会使http请求解析出现问题,比如 请求行就是以空格来划分的 POST /guowuxin/hehe HTTP/1.1
又比如有些文本协议不支持不可见字符的传递,只能用大于32的可见字符来传递信息(协议规定)
索引表
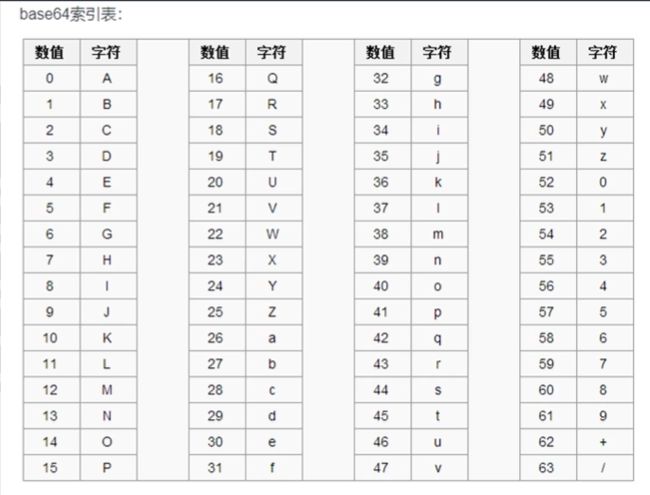
base64索引表:
base32索引表:
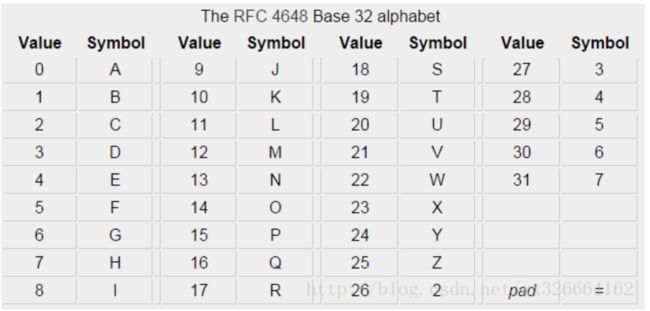
base16索引表:

转码原理
转码
这里只介绍Base-64转码,其他的原理一样
2的6次方即为64
Base-64编码将一个8位子节序列拆散为6位的片段,并为每6位分配一个字符(见索引表)。这64个字符都是很常见的,可以安全地放在HTTP首部字段中。这64个字符中包括大小写字母、数字、+和/,特殊字符=(即结尾处使用的=号)
示例: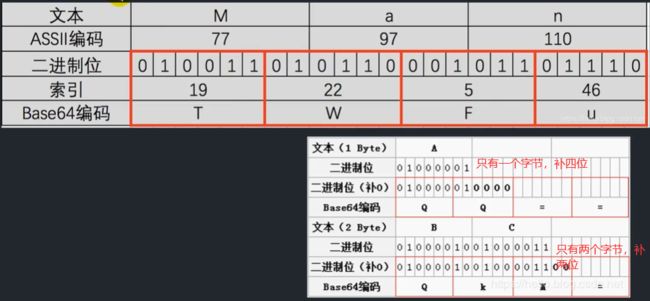
在结尾还差的补等于号。
上面的三个字符“Man”是原文,下面的四个字符“TWFu”是Base64编码后的字符
经过base64编码后,字符串理论上比之前长1/3,也就是原来的4/3。(除下面两种情况外)。
base64填充
base64编码收到一个8bit字节数据,将这个二进制序列每6bit划分一个块。二进制序列有时不能正好平均地分为6位的块,在这种情况下,就在序列末尾填充零位,使二进制序列的长度成为24的倍数(6和8的最小公倍数)。
- 6bit里面的数据,全部是填充的,它显示的符号是第65个符号”=”。
- 6bit里面的数据,部分是填充的,按照索引表正常显示
示例:
输入字符串为”a:a”为3个字节(24位)。24是24的倍数,因此按照上面给出的例子计算。无需填充就会得到base64编码为”YTph”。
输入字符串变为”a:aa”为4个字节(32位)。要凑为24的倍数,最小的值是48。因此要添加16个填充码。
a:a – 011000 010011 101001 100001 – YTph
a:aa – 011000 010011 101001 100001 011000 01xxxx xxxxxx xxxxxx – YTphYQ==
a:aaa – 011000 010011 101001 100001 011000 010110 0001xx xxxxxx – YTphYWE=
a:aaaa – 011000 010011 101001 100001 011000 010110 000101 1000001 – YTphYWFh