
引言
今天周末,我在家坐着掐指一算,马上又要到一年一度的金九银十招聘季了,国内今年上半年受到 YQ 冲击,金三银四泡汤了,这就直接导致很多今年毕业的同学会和明年毕业的同学一起参加今年下半年的秋招,这个竞争就比较激烈了。
最近后台有一些朋友给我留言,希望我能写写招聘相关的内容,毕竟虽然说是金九银十,但是很多大公司的校招从 7 、 8 月份就开始了。
本来是想写点面试技巧和简历技巧的,但我转念一想,大家都是搞技术的,问题的核心还是技术能力要过关,面试技巧这东西最多只能用作锦上添花,而技术能力过不去,机会送到手里都抓不住。
再说简历这件事儿,说实话,这个不是短时间内能进行弥补的,之前我也有文章分享过我是怎么挑简历的,无外乎先看学校,再参考下实习公司,项目经验这一栏就看心情了。
尤其是校招,学校放在第一位,在金矿里淘金子肯定要比在沙堆上淘金子效率高得多,当然,如有能有大厂的实习经验,也会成为简历上的一个亮点,能去大厂实习,不管最后什么原因没有留下,本身已经可以说明很多问题了。
MD ,老说实话,实话这么讲下去得罪的人有点多啊。
当然哈,如果这两样都没有出彩的地方,就只能在项目经验上下点功夫了,在 Github 上多找找能拿来练手的项目,多动动手,动起来总比整天怨天尤人要来的强。
第一份工作可以找的不好,至少先混口饭吃,在工作中再接着学习,夯实自己的基础,做个两三年工作还是可以换的嘛。
Redis 安装
扯远了,强行扯回来,我思来想去还是用 Redis 开头,就是因为这玩意使用频率以及使用场景太多了,不管什么语言,做什么方向,最终都能和 Redis 扯上关系(emmm,扯不上的我也能强行扯上)。
先简单介绍下我认为的本地最简安装方案,这个方案顺便还实现了跨平台(一开始我并没有想到这个,直到我写到这才忽然想起来)。
Docker + Redis ,Docker 在各个平台都有自己的安装包,请各位同学去官网自行下载安装,我就不多介绍了, Windows 环境下官网提供了现成的 exe 程序,直接双击一路 next 到底就完。
Docker 安装成功后,不管在哪个平台都是打开命令行模式,或者找个输入命令的地方,Windows 平台下可以使用 CMD 、 PowerShell 或者 Windows Terminal 等工具,其他常见平台包括 MacOS 、 CentOS 或者 Ubuntu ,就不用我多说了吧,如果自己找不到的话,我估摸着我也找不到。
然后用下面三个命令安装 Redis :
# 下载最新版本 Redis 镜像
docker pull redis
# 查看当前镜像
docker images
# 启动命令
docker run --name redis -p 6380:6379 -d redis:latest --requirepass "02wKdSs7NvWT5TdlRyN4dxkXvIDnI1uroh5t"
# 查看运行容器
docker ps
# 进入容器
docker exec -it 013a252b24d6 redis-cli
稍微解释下容器的启动命令 --name 是对这个启动的容器进行命名, -p 是指定映射的端口, -d 是指后台运行容器,并返回容器的 ID , --requirepass 是指定了当前启动的 Redis 的访问密码。
然后一个 Redis 就启动好了,我们进入容器执行几条命令看下是否正常:
# 使用刚才设置的密码登录
127.0.0.1:6379> auth 02wKdSs7NvWT5TdlRyN4dxkXvIDnI1uroh5t
OK
# 写入一个 key-value
127.0.0.1:6379> set name geekdigging
OK
# 查询 key
127.0.0.1:6379> get name
"geekdigging"
# 查询所有 key
127.0.0.1:6379> keys *
1) "name"
# 删除 key
127.0.0.1:6379> del name
(integer) 1
# 查询所有 key
127.0.0.1:6379> keys *
(empty array)
# 退出
127.0.0.1:6379> quit
Redis 入门结束,看完这一段,在简历上写个 Redis 达到了解级别我觉得木有任何问题。
基础知识
既然是从面试出发,那么接下来的内容将会以面试题为导向进行解答,面试题来源于网络或者我自己的杜撰。
为什么在项目中使用 Redis ?
现在基本上只要问到缓存,第一个问题基本上都是哪里用了缓存?为啥要用?不用行不行?用了以后会不会有什么风险?
就是单纯的看你背后对缓存有没有思考,还是说只是单纯的傻乎乎的用。如果没办法给一个还可以的回答,那这个映像分一下就降下来了。
首先哈,我们在项目中使用 Redis 肯定是为了更高的性能和更好的并发。因为传统的关系型数据库已经无法满足现在所有的使用场景了,最常见的秒杀场景,或者查询时的流量洪峰等等,都很容易把传统的 MySQL 或者是 Oracle 打崩,所以引入了缓存中间件 Redis 。
高性能:
假设一个场景,一个请求过来,开始查询数据库,乱七八糟一顿 SQL 操作,查了个结果,结果耗时可能有个 500ms 左右,就比如商城的首页,各种类目的商品信息,各种推荐信息,如果走数据库查询,并且查完了可能接下来好几个小时都没什么变化,那每次请求都走到数据库里,就有点不大合适了。
这时,我们把查到的结果放到扔到缓存里面,下次再来查询,不走数据库,直接走缓存查询,算上网络消耗可能 10ms 左右就能响应结果了,性能瞬间提升 50 倍。
这就是说,对于一些需要复杂操作耗时查出来的结果,且确定后面不怎么变化,但是有很多读请求,那么直接将查询出来的结果放在缓存中,后面直接读缓存就好了。
高并发:
MySQL 或者 Oracle 这种关系型数据库压根就不是用来玩并发的,虽然也可以支撑一定的并发,单机 8C16G 的 MySQL 优化基本上极限能撑到 900 左右的 TPS , QPS 极限能撑到 9000 左右。别看这个数字不小,请注意是极限情况,这个情况下 CPU 全都已经爆表,整个服务已经处于不健康的状态。
这时业务场景如果 1s 有 1w 的请求过来,使用一个 MySQL 单机肯定直接崩掉,但是如果使用 Redis 缓存,把大量的热点数据放在缓存,因为是走内存的操作,单机轻松支撑几万甚至于几十万的访问。单机的并发承载量是 MySQL 的几十倍。
除了 Redis 还有考虑过其他缓存么?
这个问题实际上是在问知识广度,因为现在市面上比较常见的缓存有两个,一个是 Redis 还有一个是 Memcached ,而大家现在基本上都在用 Redis 而逐渐的抛弃掉了 Memcached ,这么做肯定是由原因的,说明 Memcached 是存在明显的短板的。
- Redis 相比较 Memcached 而言,它支持更复杂的数据结构,能支持更丰富的数据操作。
- Redis 在 3.x 版本以后,原生支持了集群模式,而 Memcached 没有原生的集群模式,需要依靠客户端来实现往集群中分片写入数据。
- Redis 拥有更加丰富的附加功能,如:pub/sub 功能, Lua 脚本支持, 序列化支持等等。
- Redis 支持数据持久化, RDB 和 AOF。
Redis 的线程模型是什么?为什么 Redis 单线程却能支撑高并发?
这两个问题我放在一起,实际上是一个递进的关系。
首先明确第一点, Redis 是单线程的模型。
而单线程却能拥有很好的性能以及支撑高并发则得益于它自身的另一套机制「 I/O 多路复用机制」。
Redis 内部使用文件事件处理器( file event handler ) 是单线程的,所以 Redis 才叫做单线程的模型。
它采用 IO 多路复用机制同时监听多个 socket ,将产生事件的 socket 压入内存队列中,事件分派器根据 socket 上的事件类型来选择对应的事件处理器进行处理。
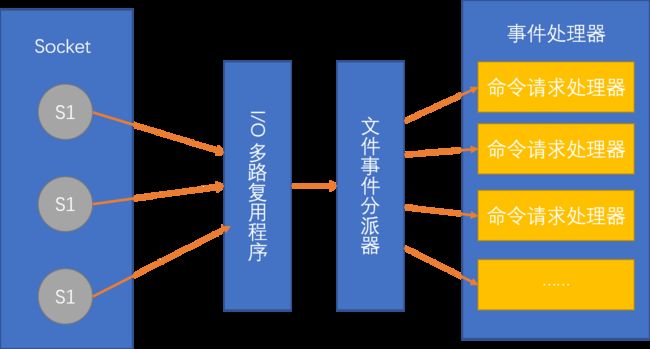
尽管多个文件事件操作可能会并发的出现,但 I/O 多路复用系统总是会将所有产生的套接字( Socket ) 放到一个队列里面,然后通过这个队列,以有序、同步、每次一个套接字的方式向文件分派器传送套接字。只有当上一个套接字产生的事件被处理完毕之后, I/O 多路复用系统才会继续向文件分派器传送下一个套接字。
同时,单线程的模型反而带来了另一个好处是无需频繁的切换上下文,预防了多线程可能产生的竞争问题。
注意: Redis 6.0 之后的版本抛弃了单线程模型这一设计,原本使用单线程运行的 Redis 也开始选择性地使用多线程模型。
前面还在强调 Redis 单线程模型的高效性,现在为什么又要引入多线程?这其实说明 Redis 在有些方面,单线程已经不具有优势了。因为读写网络的 Read/Write 系统调用在 Redis 执行期间占用了大部分 CPU 时间,如果把网络读写做成多线程的方式对性能会有很大提升。
Redis 的多线程部分只是用来处理网络数据的读写和协议解析,执行命令仍然是单线程。 之所以这么设计是不想 Redis 因为多线程而变得复杂,需要去控制 key、lua、事务、LPUSH/LPOP 等等的并发问题。
Redis 的数据结构有哪些呀?
首先最基础的五种数据结构必须烂熟于心:String 、 Hash 、 List 、 Set 、 SortedSet 。
如果连这五种基础数据结构都记不住的话那就真的需要自己多补补课了。
那么,是不是只有这五种基础数据结构,答案并不是,比如在 2.8.9 版本添加的 HyperLogLog ,或者在 3.2 版本提供的 GEO ,又或者在 2.2 版本后新增的 Bitmap 以及在比较近的 5.0 版本新增的 Stream 。
- HyperLogLog: 基数统计,这个结构可以非常省内存的去统计各种计数,比如注册 IP 数、每日访问 IP 数、页面实时UV)、在线用户数等。但是它也有局限性,就是只能统计数量,而没办法去知道具体的内容是什么。
- GEO: 这个功能可以将用户给定的地理位置信息储存起来, 并对这些信息进行操作。
- Bitmap: BitMap 就是通过一个 bit 位来表示某个元素对应的值或者状态, 其中的 key 就是对应元素本身,实际上底层也是通过对字符串的操作来实现。
- Stream: 从功能层面来讲, Streams 加上它的指令实现了一个完备的分布式消息队列。
上面这几种种数据结构都不复杂,大家百度下看看文章就能和面试官吹牛皮了。
能答出来后面这几种数据类型,基本上面试官都会对你另眼相看,如果还能接着说出来使用场景以及具体应用,那么这道题基本上你的发挥已经超出了面试官的预期。
这时你还可以接着聊下去,比如你还用过一些 Redis 的第三方模块,这个是 Redis 在 4.0 版本以后提供了插件功能,比如非常常用的一个插件布隆过滤器「 BloomFilter 」。
布隆过滤器主要是用来去重使用的,在空间上可以节省 90% 以上,但是稍微有点不精确,有一定的误判概率。可以简单的把布隆过滤器理解成一个不怎么精确的 set 结构,当使用它的 contains 方案判断某个对象是否存在时,它可能会误判。但是布隆过滤器也不是特别不精确,只要参数设置的合理,它的精确度也可以控制的相对足够精确,只会有小小的误判概率。
除了 「BloomFilter」 ,还有一些比较常用的,如: 「RedisSearch」 和 「rediSQL」 。
「RedisSearch」 是一个强大全文检索插件而 「rediSQL」 则是一个使得 Redis 能使用 SQL 做查询的插件。
Redis 的持久化有哪几种方式?
Redis 数据持久化有两种方式: RDB 和 AOF 。
- RDB:RDB 持久化机制,是对 Redis 中的数据执行定期的持久化。
- AOF: AOF 机制对每条写入命令作为日志,以
append-only的模式写入一个日志文件中,在 Redis 重启的时候,可以通过回放 AOF 日志中的写入指令来重新构建整个数据集。
通过 RDB 或者 AOF ,都可以将 Redis 内存中的数据持久化到硬盘上面,如果有需要,还可以将硬盘上的数据备份到其他地方去。
如果 Redis 挂了,这时止不仅 Redis 服务挂掉,内存数据丢失,同时产生硬件损坏,硬盘上的数据也丢失或者复发恢复,我们还可以从其他地方将数据拷贝回来进行数据恢复。
不同的持久化机制都有什么优缺点?
RDB 的优缺点:
- RDB 持久化既可以通过手动执行,也可以通过配置文件选项定期执行,它可以使得某个时间点上的数据库的状态保存到一个 RDB 文件中。有两个命令可以用于生成 RDB 文件,一个是
save,另一个是bgsave。save命令会阻塞当前的 Redis 进程,直到 RDB 文件创建完毕,在这期间,服务器不能处理任何命令请求。而bgsave则会派生出一个子进程,然后由子进程生成 RDB 文件,服务进程不受干扰,继续处理命令请求。 - RDB 会生成多个数据文件,每个数据文件都代表了某一个时刻中 Redis 的数据,这种多个数据文件的方式,非常适合做冷备,可以将这种完整的数据文件发送到一些远程的安全存储上去。
- RDB 对 Redis 对外提供的读写服务,影响非常小,可以让 Redis 保持高性能,因为 Redis 主进程只需要 fork 一个子进程,让子进程执行磁盘 IO 操作来进行 RDB 持久化即可。
- 相对于 AOF 持久化机制来说,直接基于 RDB 数据文件来重启和恢复 Redis 进程,更加快速。
- 在 Redis 故障时,尽可能少的丢失数据,那么 RDB 没有 AOF 好。一般来说,RDB 数据快照文件,都是每隔 5 分钟,或者更长时间生成一次,这个时候就得接受一旦 Redis 进程宕机,那么会丢失最近 5 分钟的数据。
- RDB 每次在 fork 子进程来执行 RDB 快照数据文件生成的时候,如果数据文件特别大,可能会导致对客户端提供的服务暂停数毫秒,或者甚至数秒。
AOF 的优缺点:
- AOF 可以更好的保护数据不丢失,一般 AOF 会每隔 1 秒,通过一个后台线程执行一次 fsync 操作,最多丢失 1 秒钟的数据。
- AOF 日志文件以
append-only模式写入,所以没有任何磁盘寻址的开销,写入性能非常高,而且文件不容易破损,即使文件尾部破损,也很容易修复。 - AOF 日志文件即使过大的时候,出现后台重写操作,也不会影响客户端的读写。因为在
rewrite log的时候,会对其中的指令进行压缩,创建出一份需要恢复数据的最小日志出来。在创建新日志文件的时候,老的日志文件还是照常写入。当新的merge后的日志文件ready的时候,再交换新老日志文件即可。 - AOF 日志文件的命令通过可读较强的方式进行记录,这个特性非常适合做灾难性的误删除的紧急恢复。
- 对于同一份数据来说,AOF 日志文件通常比 RDB 数据快照文件更大。
- AOF 开启后,支持的写 QPS 会比 RDB 支持的写 QPS 低,因为 AOF 一般会配置成每秒 fsync 一次日志文件,当然,每秒一次 fsync ,性能也还是很高的。(如果实时写入,那么 QPS 会大降,Redis 性能会大大降低)
- 以前 AOF 发生过 bug,就是通过 AOF 记录的日志,进行数据恢复的时候,没有恢复一模一样的数据出来。所以说,类似 AOF 这种较为复杂的基于命令日志 / merge / 回放的方式,比基于 RDB 每次持久化一份完整的数据快照文件的方式,更加脆弱一些,容易有 bug。不过 AOF 就是为了避免 rewrite 过程导致的 bug,因此每次 rewrite 并不是基于旧的指令日志进行 merge 的,而是基于当时内存中的数据进行指令的重新构建,这样健壮性会好很多。
两种持久化方式选择:
- 不要仅仅使用 RDB,因为那样会导致你丢失很多数据。
- 也不要仅仅使用 AOF,因为那样有两个问题:第一,你通过 AOF 做冷备,没有 RDB 做冷备来的恢复速度更快;第二,RDB 每次简单粗暴生成数据快照,更加健壮,可以避免 AOF 这种复杂的备份和恢复机制的 bug。
- Redis 支持同时开启开启两种持久化方式,我们可以综合使用 AOF 和 RDB 两种持久化机制,用 AOF 来保证数据不丢失,作为数据恢复的第一选择; 用 RDB 来做不同程度的冷备,在 AOF 文件都丢失或损坏不可用的时候,还可以使用 RDB 来进行快速的数据恢复。
参考
https://github.com/doocs/advanced-java/blob/master/docs/high-concurrency/redis-persistence.md