多智能体强化学习博弈系列(1)- 差分博弈和模糊系统
几点说明:
- 这个系列重点关注多智能体和强化学习在差分博弈中的应用,文章中有尝试复现的主要是双人/多人混合策略多阶段随机差分零和游戏的模拟。关于智能体、关于强化学习、关于博弈论基础的介绍,在这个系列基本不涉及。
- 强化学习简简简介见我之前的文章。
- 多智能体简简简介见我之前的文章。
- 有关博弈论基础的内容,e.g. 双人/多人游戏、零和/变和游戏、单一/混合策略、单一/多阶段博弈等概念,本文不涉及,有兴趣的童鞋可以参考这里。
- 这个系列也不涉及各种均衡的求解。
- 希望更多关注神经网络类实现的童鞋可以不必再往下读了:本系列不涉及DQN或其他类型的由神经网络实现的RL系统。
差分博弈 differential games
在真实世界中经常遇到环境、状态、行为都处于连续空间的情况。这时一般选择用差分方程来表达连续空间。这类博弈成为差分博弈,在这种博弈中智能体的目标是学习如何适应和学习连续可变的环境和能力。
模糊系统 fuzzy systems
模糊系统通常使用离散空间(比如文字描述)作为标签表示状态或行为。方法是通过构造membership function。
定义Universe of discourse X X X 为一组元素x的集合,所有集合中的元素具有相同的特征标签。
定义membership function (MF) μ A ( x ) \mu_A(x) μA(x) 为映射集合元素到0-1的空间的方程。如果 μ A ( x ) \mu_A(x) μA(x)取值仅为0或1, 这个模糊集合称为crisp或classical集合:
A = { ( x , μ A ( x ) ) ∣ x ∈ X } A = \{(x,\mu_A(x))|x \in X \} A={(x,μA(x))∣x∈X}
membership function的交集intersection运算:
μ A ∩ B ( x ) = T ( μ A ( x ) , μ B ( x ) ) = μ A ( x ) ∗ μ B ( x ) \mu_{A \cap B}(x) = T(\mu_A(x), \mu_B(x)) = \mu_A(x) * \mu_B(x) μA∩B(x)=T(μA(x),μB(x))=μA(x)∗μB(x)
其中 T T T是泛化的t-norm运算符,代表比如如下运算:
- 求最小: T m i n ( a , b ) = m i n ( a , b ) T_{min}(a,b) = min(a,b) Tmin(a,b)=min(a,b)
- 代数乘积: T a p ( a , b ) = a b T_{ap}(a,b) = ab Tap(a,b)=ab
并集union运算:
μ A ∪ B ( x ) = S ( μ A ( x ) , μ B ( x ) ) = μ A ( x ) + ˙ μ B ( x ) \mu_{A \cup B}(x) = S(\mu_A(x), \mu_B(x)) = \mu_A(x) \dot{+} \mu_B(x) μA∪B(x)=S(μA(x),μB(x))=μA(x)+˙μB(x)
其中 S S S是泛化的s-norm运算符,代表比如如下运算:
- 求最大: S m a x ( a , b ) = m a x ( a , b ) S_{max}(a,b) = max(a,b) Smax(a,b)=max(a,b)
- 代数求和: S a p ( a , b ) = a + b − a b S_{ap}(a,b) = a + b - ab Sap(a,b)=a+b−ab
一些常用的membership function: singleton, gaussian, sigmodial, triangular, etc.
Fuzzy IF-THEN rules:用来实现不确定环境下的专家系统建模的一组规则:
R l \mathfrak{R}_l Rl : if x is A then y is B
其中 x, y是模糊变量,A 和 B是定义在空间X和Y的模糊集合,"x is A"称为_antecedent_ 或 premise, “y is B” 称为 consequence 或 conclusion.
generalized modus ponens 定义为:
premise1(rule): if x is A then y is B
premise2(fact): x is A’
conclusion: y is B’.
定义fuzzy inference engine 为一个可以组合多个模糊IF-THEN规则的推理系统,目的是将模糊规则映射到模糊集合。
Product inference engine:一种常见的模糊推理系统,通常包含以下三个特征:
- T运算是代数乘积,S运算是求最大值
- 使用Mamdani’s product implication (后面有介绍)
- 推理系统使用交集作为模糊规则的组合方式
Mamdani implication: 将模糊规则 l l l作为二进制的模糊关系处理:
μ R ( x , y ) = μ A l × B l ( x , y ) = μ A l → B l ( x , y ) = μ A l ( x ) ∗ μ B l ( x ) \mu_R(x,y) = \mu_{A^l \times B^l}(x,y) = \mu_{A^l \to B^l}(x,y) = \mu_{A^l}(x) * \mu_{B^l}(x) μR(x,y)=μAl×Bl(x,y)=μAl→Bl(x,y)=μAl(x)∗μBl(x)
其中 A l → B l A^l \to B^l Al→Bl是模糊关系的映射关系。在product inference engine 中,"*"代表代数乘积。
根据以上定义,一个模糊集合 B ′ l B^{'l} B′l可以这样被推理出来:
μ B ′ l ( y ) = s u p x ∈ X T [ μ A ′ ( x ) , μ A l → B l ( x , y ) ] \mu_{B^{'l}}(y) = sup_{x \in X} T[\mu_{A'}(x), \mu_{A^l \to B^l}(x,y)] μB′l(y)=supx∈XT[μA′(x),μAl→Bl(x,y)]
其中T[.]为t-norm运算符,sup为最大元素。有:
μ B ′ ( y ) = m a x l = 1 M μ B ′ l ( y ) \mu_{B'}(y) = max_{l=1}^M \mu_{B^{'l}}(y) μB′(y)=maxl=1MμB′l(y)
= m a x l = 1 M [ s u p x ∈ X ( μ A ′ ( x ) Π j = 1 n μ A j l ( x j ) μ B l ( y ) ) ] = max_{l=1}^M \left[ sup_{x \in X}\left( \mu_{A'}(x) \Pi_{j=1}^n \mu_{A_j^l}(x_j) \mu_{B^l}(y) \right) \right] =maxl=1M[supx∈X(μA′(x)Πj=1nμAjl(xj)μBl(y))]
其中 l ∈ M l \in M l∈M是规则,M是规则集合,j是antecedents的索引, n n n是每个premise里的antecedent个数。 A j l A_j^l Ajl是antecedent中用于第l个规则的第j个模糊集合, B l B^l Bl是第l个规则的推理结果(consequence)。
举例:
Premise 1 (rule 1): if x 1 x_1 x1 is A 1 1 A_1^1 A11 and x 2 x_2 x2 is A 2 1 A_2^1 A21 then y is B 1 B^1 B1 (j = (1,2), l = 1)
Premise 2 (rule 2): if x 1 x_1 x1 is A 1 2 A_1^2 A12 and x 2 x_2 x2 is A 2 2 A_2^2 A22 then y is B 2 B^2 B2 (j = (1,2), l = 2)
Premise 3 (fact): x 1 x_1 x1 is A 1 ′ A'_1 A1′ and x 2 x_2 x2 is A 2 ′ A'_2 A2′
Conclusion: y is B ′ B' B′
模糊系统构建:
一个模糊系统(FIS/fuzzy contollers)的结构:
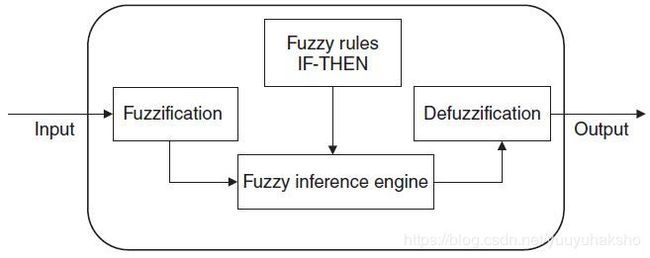
参考 “Multi-Agent Machine-Learning - A Reinforcement Approach” - Howard M. Schwartz.
模糊化Fuzzifier: 将连续输入空间映射到离散的membership function上,并用membership degree代表映射的强度。
以singleton membership function为例:
μ A ( x ) = { 1 if x = x ∗ 0 otherwise \mu_A(x) = \begin{cases} 1 & \quad \text{if } x = x^{*} \\ 0 & \quad \text{otherwise} \end{cases} μA(x)={10if x=x∗otherwise
其中 x ∗ x^{*} x∗是一个连续的值。
以Gaussian membership function为例:
μ A ( x ) = e − ( x 1 − x 1 ∗ a 1 ) 2 ∗ ⋯ ∗ e − ( x n − x n ∗ a n ) 2 \mu_A(x) = e^{-\big( \frac{x_1-x_1^{*}}{a_1} \big)^2} * \cdots * e^{-\big( \frac{x_n-x_n^{*}}{a_n} \big)^2} μA(x)=e−(a1x1−x1∗)2∗⋯∗e−(anxn−xn∗)2
其中 a a a是正的常量。
以 triangular membership function为例:
μ A ( x ) = { ( 1 − ∣ x 1 − x 1 ∗ ∣ b 1 ) ∗ ⋯ ∗ ( 1 − ∣ x n − x n ∗ ∣ b n ) if ∣ x i − x i ∗ ∣ ≥ b i 0 otherwise \mu_A(x) = \begin{cases} (1-\cfrac{|x_1-x_1^{*}|}{b_1}) * \cdots * (1-\cfrac{|x_n-x_n^{*}|}{b_n}) & \quad \text{if } |x_i-x_i^{*}| \geq b_i \\ 0 & \quad \text{otherwise} \end{cases} μA(x)=⎩⎨⎧(1−b1∣x1−x1∗∣)∗⋯∗(1−bn∣xn−xn∗∣)0if ∣xi−xi∗∣≥biotherwise
其中 b i b_i bi是一个正的常量。
去模糊化Defuzzifier: 将模糊的值重新映射回连续空间。常用的方法之一是加权平均去模糊化,计算量少好理解:
f = ∑ l = 1 M ( Π j = 1 J μ A j l ( x j ) ) f l ∑ l = 1 M ( Π j = 1 J μ A j l ( x j ) ) f = \cfrac{\sum_{l=1}^M \left( \Pi_{j=1}^J \mu^{A_j^l}(x_j) \right) \quad f_l}{\sum_{l=1}^M \left( \Pi_{j=1}^J \mu^{A_j^l}(x_j) \right)} f=∑l=1M(Πj=1JμAjl(xj))∑l=1M(Πj=1JμAjl(xj))fl
其中J是输入个数,M是规则个数。
更多去模糊化方法参考这里。
下一篇会介绍如何实现一个行走在连续状态和行为空间中,用加强学习方法寻找博弈中的纳什均衡点的智能体。这个智能体所使用的算法的输入和输出都经过了模糊系统的离散化和去离散化处理。