jvm内存模型
主要包含类加载器、jvm内存、字节码执行引擎、GC;

类加载器
类加载器主要包含:应用程序加载器、扩展类加载器、启动类加载器。
启动类加载器:主要进行加载java核心类,例如:rt.jar包下的类。
扩展类加载器:主要进行加载java中ext包下的类。
应用程序类加载器:主要加载我们自己写的java类。
类加载机制:双亲委派机制和全盘负责委托机制。
双签委派机制:当我们自己的java类加载的时候会查看是否有父级加载器,如果有委托父级,直道由启动类加载器加载,启动类加载器加载后,加载了核心类发现加载不了我们的类,所以又返回给子级加载,直到由应用程序类加载器加载。
全盘负责委托机制:当一个加载器加载的时候如果没有显性的让另一个加载器加载,则当前的加载器都会全部加载。
如果想打破双亲委派机制,也相对来说简单一些,我们可以查看底层源码:
1 protected Class loadClass(String name, boolean resolve) 2 throws ClassNotFoundException 3 { 4 synchronized (getClassLoadingLock(name)) { 5 // First, check if the class has already been loaded 6 Class c = findLoadedClass(name); 7 if (c == null) { 8 long t0 = System.nanoTime(); 9 try { 10 if (parent != null) { 11 c = parent.loadClass(name, false); 12 } else { 13 c = findBootstrapClassOrNull(name); 14 } 15 } catch (ClassNotFoundException e) { 16 // ClassNotFoundException thrown if class not found 17 // from the non-null parent class loader 18 } 19 20 if (c == null) { 21 // If still not found, then invoke findClass in order 22 // to find the class. 23 long t1 = System.nanoTime(); 24 c = findClass(name); 25 26 // this is the defining class loader; record the stats 27 sun.misc.PerfCounter.getParentDelegationTime().addTime(t1 - t0); 28 sun.misc.PerfCounter.getFindClassTime().addElapsedTimeFrom(t1); 29 sun.misc.PerfCounter.getFindClasses().increment(); 30 } 31 } 32 if (resolve) { 33 resolveClass(c); 34 } 35 return c; 36 } 37 }
我们可以看见有一个代码在查找parent.loadClass,所以我们需要重写一下loadclass、findclass方法即可。
jvm内存

我们理解一下操作数栈与局部变量表,有一个简单demo:
1 // 2 // Source code recreated from a .class file by IntelliJ IDEA 3 // (powered by Fernflower decompiler) 4 // 5 6 package com.tuling; 7 8 public class Main { 9 public Main() { 10 } 11 12 public int add() { 13 int a = 1; 14 int b = 2; 15 int c = (a + b) * 10; 16 return c; 17 } 18 19 public static void main(String[] args) { 20 Main main = new Main(); 21 main.add(); 22 System.out.println("aaa"); 23 } 24 }
我们进入main.class进行javap -c反编译。然后会得到这样一些代码:
1 Classfile /E:/ЙљПЁгъ/01java-vip/tuling-vip-spring/springannopriciple01/target/test-classes/com/tuling/Main.class 2 Last modified 2019-9-8; size 714 bytes 3 MD5 checksum 316510b260c590e9dd45038da671e84e 4 Compiled from "Main.java" 5 public class com.tuling.Main 6 minor version: 0 7 major version: 52 8 flags: ACC_PUBLIC, ACC_SUPER 9 Constant pool: 10 #1 = Methodref #8.#28 // java/lang/Object."":()V 11 #2 = Class #29 // com/tuling/Main 12 #3 = Methodref #2.#28 // com/tuling/Main."":()V 13 #4 = Methodref #2.#30 // com/tuling/Main.add:()I 14 #5 = Fieldref #31.#32 // java/lang/System.out:Ljava/io/PrintStream; 15 #6 = String #33 // aaa 16 #7 = Methodref #34.#35 // java/io/PrintStream.println:(Ljava/lang/String;)V 17 #8 = Class #36 // java/lang/Object 18 #9 = Utf819 #10 = Utf8 ()V 20 #11 = Utf8 Code 21 #12 = Utf8 LineNumberTable 22 #13 = Utf8 LocalVariableTable 23 #14 = Utf8 this 24 #15 = Utf8 Lcom/tuling/Main; 25 #16 = Utf8 add 26 #17 = Utf8 ()I 27 #18 = Utf8 a 28 #19 = Utf8 I 29 #20 = Utf8 b 30 #21 = Utf8 c 31 #22 = Utf8 main 32 #23 = Utf8 ([Ljava/lang/String;)V 33 #24 = Utf8 args 34 #25 = Utf8 [Ljava/lang/String; 35 #26 = Utf8 SourceFile 36 #27 = Utf8 Main.java 37 #28 = NameAndType #9:#10 // " ":()V 38 #29 = Utf8 com/tuling/Main 39 #30 = NameAndType #16:#17 // add:()I 40 #31 = Class #37 // java/lang/System 41 #32 = NameAndType #38:#39 // out:Ljava/io/PrintStream; 42 #33 = Utf8 aaa 43 #34 = Class #40 // java/io/PrintStream 44 #35 = NameAndType #41:#42 // println:(Ljava/lang/String;)V 45 #36 = Utf8 java/lang/Object 46 #37 = Utf8 java/lang/System 47 #38 = Utf8 out 48 #39 = Utf8 Ljava/io/PrintStream; 49 #40 = Utf8 java/io/PrintStream 50 #41 = Utf8 println 51 #42 = Utf8 (Ljava/lang/String;)V 52 { 53 public com.tuling.Main(); 54 descriptor: ()V 55 flags: ACC_PUBLIC 56 Code: 57 stack=1, locals=1, args_size=1 58 0: aload_0 59 1: invokespecial #1 // Method java/lang/Object."":()V 60 4: return 61 LineNumberTable: 62 line 10: 0 63 LocalVariableTable: 64 Start Length Slot Name Signature 65 0 5 0 this Lcom/tuling/Main; 66 67 public int add(); 68 descriptor: ()I 69 flags: ACC_PUBLIC 70 Code: 71 stack=2, locals=4, args_size=1 72 0: iconst_1 73 1: istore_1 74 2: iconst_2 75 3: istore_2 76 4: iload_1 77 5: iload_2 78 6: iadd 79 7: bipush 10 80 9: imul 81 10: istore_3 82 11: iload_3 83 12: ireturn 84 LineNumberTable: 85 line 13: 0 86 line 14: 2 87 line 15: 4 88 line 16: 11 89 LocalVariableTable: 90 Start Length Slot Name Signature 91 0 13 0 this Lcom/tuling/Main; 92 2 11 1 a I 93 4 9 2 b I 94 11 2 3 c I 95 96 public static void main(java.lang.String[]); 97 descriptor: ([Ljava/lang/String;)V 98 flags: ACC_PUBLIC, ACC_STATIC 99 Code: 100 stack=2, locals=2, args_size=1 101 0: new #2 // class com/tuling/Main 102 3: dup 103 4: invokespecial #3 // Method "":()V 104 7: astore_1 105 8: aload_1 106 9: invokevirtual #4 // Method add:()I 107 12: pop 108 13: getstatic #5 // Field java/lang/System.out:Ljava/io/PrintStream; 109 16: ldc #6 // String aaa 110 18: invokevirtual #7 // Method java/io/PrintStream.println:(Ljava/lang/String;)V 111 21: return 112 LineNumberTable: 113 line 20: 0 114 line 21: 8 115 line 22: 13 116 line 23: 21 117 LocalVariableTable: 118 Start Length Slot Name Signature 119 0 22 0 args [Ljava/lang/String; 120 8 14 1 main Lcom/tuling/Main; 121 } 122 SourceFile: "Main.java"
我们只看add方法的代码:需要用到jvm指令集,自己可以上网搜具体的代码;
iconst_1:将int型1推送至栈顶
istore_1:将栈顶int型数值存入第1个本地变量
这里的栈就是操作数栈。
GC算法:标记-清除、标记-整理算法、复制算法、分代算法
标记-清除:算法分为“标记”和“清除”阶段:首先标记出所有需要回收的对象,在标记完成后统一回收所有被标记的对象。它是最基础的收集算法。
标记-整理:标记过程仍然与“标记-清除”算法一样,但后续步骤不是直接对可回收对象回收,而是让所有存活的对象向一段移动,然后直接清理掉端边界以外的内存。
复制:它可以将内存分为大小相同的两块,每次使用其中的一块。当这一块的内存使用完后,就将还存活的对象复制到另一块去,然后再把使用的空间一次清理掉。这样就使每次的内存回收都是对内存区间的一半进行回收。
为什么要GC呢?
我们来看一下堆内存结构。

如果自己想看自己运行的类的堆信息,可以利用jps,查找到自己类的id,然后jmap -heap id,就可以查看当前堆的信息,例如:
1 Attaching to process ID 7964, please wait... 2 Debugger attached successfully. 3 Server compiler detected. 4 JVM version is 25.73-b02 5 6 using thread-local object allocation. 7 Parallel GC with 4 thread(s) 8 9 Heap Configuration: 10 MinHeapFreeRatio = 0 11 MaxHeapFreeRatio = 100 12 MaxHeapSize = 2128609280 (2030.0MB) 13 NewSize = 44564480 (42.5MB) 14 MaxNewSize = 709361664 (676.5MB) 15 OldSize = 89653248 (85.5MB) 16 NewRatio = 2 17 SurvivorRatio = 8 18 MetaspaceSize = 21807104 (20.796875MB) 19 CompressedClassSpaceSize = 1073741824 (1024.0MB) 20 MaxMetaspaceSize = 17592186044415 MB 21 G1HeapRegionSize = 0 (0.0MB) 22 23 Heap Usage: 24 PS Young Generation 25 Eden Space: 26 capacity = 34078720 (32.5MB) 27 used = 4771760 (4.5507049560546875MB) 28 free = 29306960 (27.949295043945312MB) 29 14.002169095552885% used 30 From Space: 31 capacity = 5242880 (5.0MB) 32 used = 0 (0.0MB) 33 free = 5242880 (5.0MB) 34 0.0% used 35 To Space: 36 capacity = 5242880 (5.0MB) 37 used = 0 (0.0MB) 38 free = 5242880 (5.0MB) 39 0.0% used 40 PS Old Generation 41 capacity = 89653248 (85.5MB) 42 used = 0 (0.0MB) 43 free = 89653248 (85.5MB) 44 0.0% used
只要old区没有use满就不会触发full gc,年轻代存满之后触发young gc,并不会STW。现在我们看一下垃圾回收器有哪些
垃圾回收器
种类:Serial收集器、ParNew收集器、Parallel Scavenge收集器、Serial Old收集器、Parallel Old收集器、CMS收集器、 G1收集器
Serial收集器:新生代采用复制算法,老年代采用标记-整理算法,利用单线程,直接在回收的过程中中断所有程序线程。

ParNew收集器:新生代采用复制算法,老年代采用标记-整理算法。利用多线程处理,单指GC线程。应用程序还是中断的
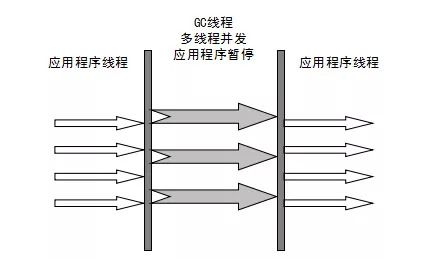
Parallel Scavenge收集器:新生代采用复制算法,老年代采用标记-整理算法。和ParNew收集器类似。

Serial Old收集器、Parallel Old收集器:是Serial收集器、Parallel Scavenge收集器的老年代版本。就相当于将老年代的算法单独提出来与其他收集器组合使用。
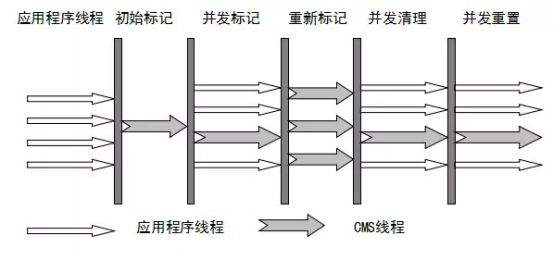
CMS收集器:开启GC时,直接将root的相连的节点拿到就可以,所以STW时间短。然后和应用程序争抢CPU,找到还能利用的对象进行标记,然后再次STW来标记并发的时候产生的新对象,最后清理没有标记的空间内存。
G1收集器:G1将Java堆划分为多个大小相等的独立区域(Region),虽保留新生代和老年代的概念,但不再是物理隔阂了,它们都是(可以不连续)Region的集合。分配大对象(直接进Humongous区,专门存放短期巨型对象,不用直接进老年代,避免Full GC的大量开销)不会因为无法找到连续空间而提前触发下一次GC
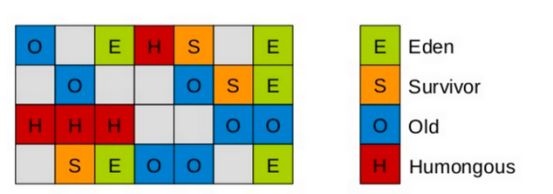
和上面的逻辑差不多,不过有一个过程是筛选回收,该收集器用户可以指定回收时间,所以jvm会判断回收成本并执行回收计划,来优先回收哪些对象


ps:关注一下本人公众号,每周都有新更新哦!