python-中文分词词频统计
本文主要内容是进行一次中文词频统计。涉及内容包括多种模式下的分词比较和分词词性功能展示。
本次使用的是python的jieba库。该库可在命令提示符下,直接输入pip install jieba进行安装。
Jieba库常用的分词模式有三种:精确模式,全模式和搜索引擎模式。
精确模式:jieba.lcut(str),尽可能地将文本精确地分开,比较适合于文本分析
全模式:jieba.lcut(str,cut_all=True),把文本中可以成词的词语尽可能地分出来,速度较快,但不能解决歧义问题
搜索引擎模式:jieba.lcut_for_search(str),在精确模式的基础上,对长词进行再次切分,提高召回率,适合于搜索引擎。
基本思路
下面用一个案例简单说明一下,分词词频统计的基本思路:
#我是用的是文言文《大学》作为案例文本。
os.chdir(r'C:\Users\分词')
txt = open("大学.txt", encoding="gb18030").read()
#使用精确模式进行分词
count = jieba.lcut(txt)
#定义空字典,对分词结果进行词频统计
word_count={}
for word in count:
word_count[word] = word_count.get(word, 0) + 1
#按词频对分词进行排序
items = list(word_count.items())
items.sort(key=lambda x: x[1], reverse=True)
以上,就是分词的基本步骤。以下是分词结果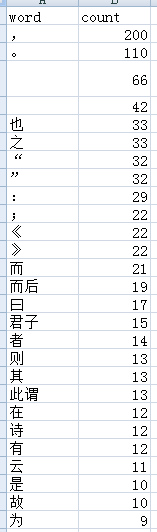
停用词
在以上的分词结果中,我们看到了很多没有用的分词,比如标点符号,之,也等无用词。所以,现在需要引入一个概念:停用词。
停用词是指在信息检索中,为节省存储空间和提高搜索效率,在处理自然语言数据(或文本)之前或之后会自动过滤掉的某些字或词,这些字或词即被称为Stop Words(停用词)。所有停用词可以组成一个停词表。那在分词词频统计时,只要是在停词表里出现的词,我们都过滤掉,同时也把一个字的词过滤,再看看效果。
修改后代码如下:
#添加停词表
stopwords = [line.strip() for line in open("stopword.txt",encoding="gb18030").readlines()]
for word in count:
if word not in stopwords:
# 不统计字数为一的词
if len(word) == 1:
continue
else:
word_count[word] = word_count.get(word, 0) + 1
运行结果如下: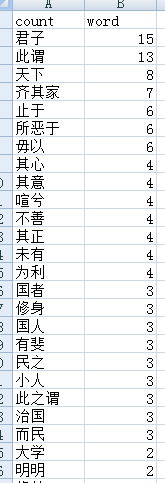
可以看到,分词的质量有了明显的提升。
三种分词模式的比较
接下来,我对《大学》,分别使用了精确模式,全模式和搜索引擎模式进行分词词频统计。结果如下,搜索引擎模式分词量最多,分出了430个词,精确模式次之,分出409个词,全模式最少,199个词(其中还有三个是符号)。
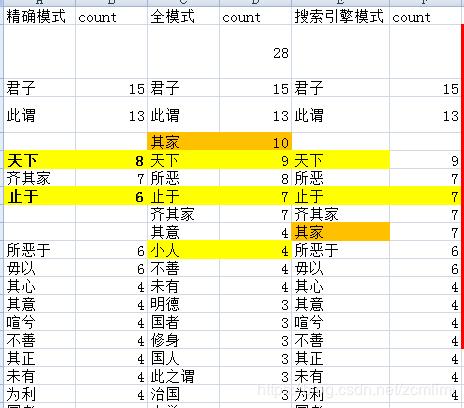
下面单独说一下,对于“所恶”这个词的分词结果。精确模式分出来的的是“所恶于(6)”,“之所恶(1)”,“恶恶(1)”;全模式分出来的是“所恶(8)”;搜索引擎模式分出来的是“所恶(7)”,“所恶于(6)”,“之所恶(1)”,“恶恶(1)”。
原文涉及到“所恶”的句子如下:
“所恶于上,毋以使下,所恶于下,毋以事上;所恶于前,毋以先后;所恶于后,毋以从前;所恶于右,毋以交于左;所恶于左,毋以交于右;此之谓絜矩之道。”;
“民之所好好之,民之所恶恶之,此之谓民之父母”;
“好人之所恶,恶人之所好,是谓拂人之性,灾必逮夫身”。
原文一共8个带 “所恶”的,从以上统计结果,可以看出,精确模式会在保证词频与原文一致的情况下,尽可能的把分词种类增多;全模式则是分词单一,但速度快(因为分词的模式少);搜索引擎模式则是会把分词种类尽量扩大,把有可能组成的词都放出来。这也正好印证了三种模式下的分词结果中,搜索引擎分词量最多,精确模式次之,全模式最少的情况。
词性分析
Jieba可以判断分词的词性,但不是每个分词都可以被判断出词性。
代码如下:
import jieba.posseg as pseg
cixing = pseg.lcut(txt)
#词性统计
for w in cixing:
word_flag[w.word] = w.flag
结果如下:

n 表示是名词,u 表示是助词,具体的词性符号对应表请看:https://blog.csdn.net/ebzxw/article/details/80306463
代码展示
下面针对 “对《大学》全文进行精确模式分词,求出分词词频和词性,然后按词频排序。将结果导出到csv”的要求,给出全部代码。
# -*-coding:utf-8 -*-
import os
import csv
import codecs
import jieba
import jieba.posseg as pseg
os.chdir(r'C:\Users\zhuchaoming\Desktop\任务\其他文件\分词')
txt = open("大学.txt", encoding="gb18030").read()
#词频统计
stopwords = [line.strip() for line in open("stopword.txt",encoding="gb18030").readlines()]
cixing = pseg.lcut(txt)
count = jieba.lcut(txt)
word_count = {}
word_flag = {}
all=[]
with codecs.open(filename='daxue_word_count_cixing.csv', mode='w', encoding='gb18030')as f:
write = csv.writer(f, dialect='excel')
write.writerow(["word","count","flag"])
#词性统计
for w in cixing:
word_flag[w.word] = w.flag
#词频统计
for word in count:
if word not in stopwords:
# 不统计字数为一的词
if len(word) == 1:
continue
else:
word_count[word] = word_count.get(word, 0) + 1
items = list(word_count.items())
#按词频排序
items.sort(key=lambda x: x[1], reverse=True)
#查询词频字典里关键字的词性
for i in range(len(items)):
word=[]
word.append(items[i][0])
word.append(items[i][1])
# 若词频字典里,该关键字有分辨出词性,则记录,否则为空
if items[i][0] in word_flag.keys():
word.append(word_flag[items[i][0]])
else:
word.append("")
all.append(word)
for res in all:
write.writerow(res)最终结果如下图:
