R数据读取方式的选择
今天是个好日子,特地花时间看了R Data Import/Export,不仅萌生了导入各种不同的数据方式,看看哪个更适合自己的需要,仅仅算是娱乐吧!!!

文件不是特别大,先让他们走一波,细小的看一看,对比一波,再看大的数据集。
system.time(readLines('D:/R/data/Scorecard/mydata.txt'))
用户 系统 流逝
0.11 0.01 0.13
system.time(read.csv("D:/R/data/Scorecard/model_sample.csv"))
用户 系统 流逝
1.36 0.05 1.43
system.time(read.delim("D:/R/data/Scorecard/model_sample.csv"))
用户 系统 流逝
0.45 0.02 0.47
system.time(read.delim2("D:/R/data/Scorecard/model_sample.csv"))
用户 系统 流逝
0.51 0.00 0.52
library(readr)
system.time(read_delim("D:/R/data/Scorecard/model_sample.csv",delim = '\001'))
用户 系统 流逝
0.03 0.06 0.10
system.time(read_csv("D:/R/data/Scorecard/model_sample.csv"))
用户 系统 流逝
0.58 0.04 0.72
system.time(read_csv2("D:/R/data/Scorecard/model_sample.csv"))
用户 系统 流逝
0.04 0.02 0.05
system.time(read_table("D:/R/data/Scorecard/model_sample.csv"))
用户 系统 流逝
0.03 0.00 0.03
system.time(read_table2("D:/R/data/Scorecard/model_sample.csv"))
用户 系统 流逝
0.14 0.00 0.14
system.time(read.csv2("D:/R/data/Scorecard/model_sample.csv"))
用户 系统 流逝
0.42 0.00 0.42
发现read_csv2和read_delim比较强有力啊
library(readxl)
system.time(read_excel("D:/R/data/Scorecard/model_sample.xlsx"))
用户 系统 流逝
1.34 0.24 1.73
system.time(read_xlsx("D:/R/data/Scorecard/model_sample.xlsx"))
用户 系统 流逝
1.13 0.23 1.36
library(data.table)
system.time(fread("D:/R/data/Scorecard/model_sample.csv"))
用户 系统 流逝
0.24 0.00 0.27
data.table这个包确实强啊,需要继续深凿。
读取excel数据确实很难受啊,怪不得大家都建议转成csv,或者tsv呢!!!
后面碰到了好点儿的,继续加餐!

其实啊,这个数据集也就124M,才拿到手不久。不过数据集里面就不好看了啊。
开始继续测试:
system.time(read.csv("D:/R/data/mydata.csv"))
用户 系统 流逝
30.71 0.20 31.79
system.time(read.delim("D:/R/data/mydata.csv"))
用户 系统 流逝
44.54 0.14 44.73
system.time(read.delim2("D:/R/data/mydata.csv"))
用户 系统 流逝
45.47 0.03 45.58
system.time(read_delim("D:/R/data/mydata.csv",delim = '\001'))
用户 系统 流逝
3.38 0.55 4.42
system.time(read.csv("D:/R/data/mydata.csv"))
用户 系统 流逝
28.75 0.14 28.94
system.time(read_csv("D:/R/data/mydata.csv"))
用户 系统 流逝
1.36 0.07 1.44
system.time(read_csv2("D:/R/data/mydata.csv"))
用户 系统 流逝
3.07 0.58 3.66
system.time(read_table("D:/R/data/mydata.csv"))
用户 系统 流逝
4.96 0.17 5.22
system.time(read_table2("D:/R/data/mydata.csv"))
用户 系统 流逝
10.71 0.19 10.93
system.time(read.csv2("D:/R/data/mydata.csv"))
用户 系统 流逝
44.56 0.17 44.80
system.time(fread("D:/R/data/mydata.csv"))
用户 系统 流逝
1.14 0.02 1.16
看来大数据集还得看fread啊。罪过,一切都是罪过。
最近加一点在导入数据的时候,有些变量的类型怎么确定吧,比如有些是数值型,导入之后就成了字符串,而且转成数值型的时候,会发生局部数据缺失。
就 readr 包里 read_csv 中有这样一个参数col_types ,举例:
mydf <- read_csv("df.csv",
col_types = cols(county = col_factor(levels = c("1","2", "3", "4")),
hba21 = col_factor(levels = c("0", "1")),
hba22 = col_factor(levels = c("0", "1")),
nation = col_factor(levels = c("0","1", "2", "3", "4", "5", "6", "7",
"8", "9", "10", "11", "12", "13", "14",
"15","16", "17", "18", "19", "20", "21",
"22", "23", "24", "25")),
sex = col_factor(levels = c("1", "2")),
y = col_factor(levels = c("0","1")))) #不适宜较多因子化变量读取
另外 readxl 包中的 read_excel 函数同样有参数 col_types ,举例:
mydata<- read_excel("table/xingshuzhi.xlsx",col_types = c("text", "numeric"))
当遇到变量特别多的时候,最好自己能在数据打开之前预览一下。确定各个变量的属性,自己生成一个 向量 ,然后传给 col_types 即可。
另外在 Rstudio 中的 Import Dataset 中可以自选,但是直接去取因子类型,需要自己指定水平,假设指定的水平过多,就觉得很麻烦,类似上面的代码。碰到多的话,最好是先把数据读进来,然后再对变量的类型进行转化。
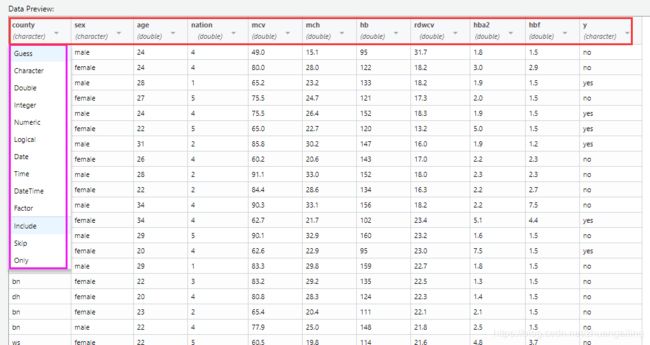
在import datasets中遇到下面的问题是属于编码的问题
进行编码选择
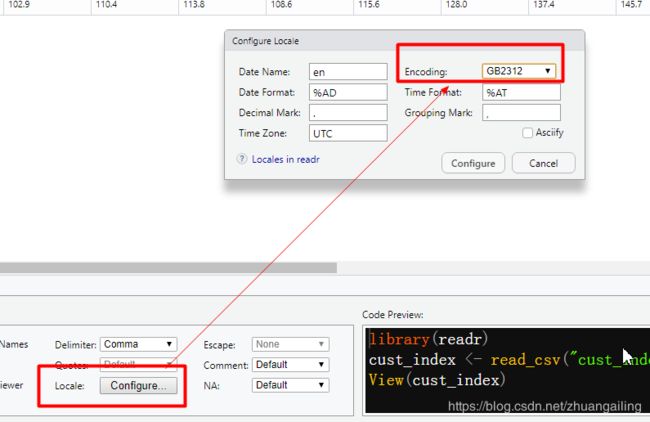
随后Configure即可!
**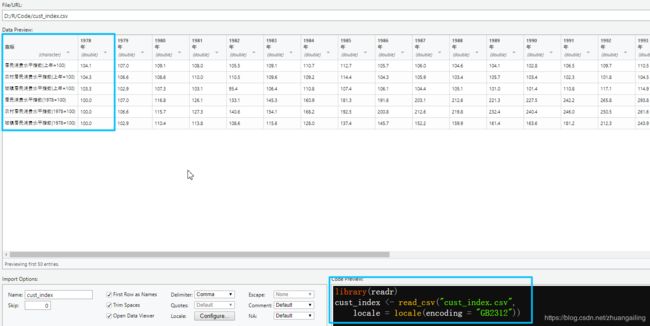
或者自己在界面添加:
library(readr)
cust_index <- read_csv("cust_index.csv",
locale = locale(encoding = "GB2312"))
上半年6月底出了一个新的包:vroom
这个也是挺厉害了!
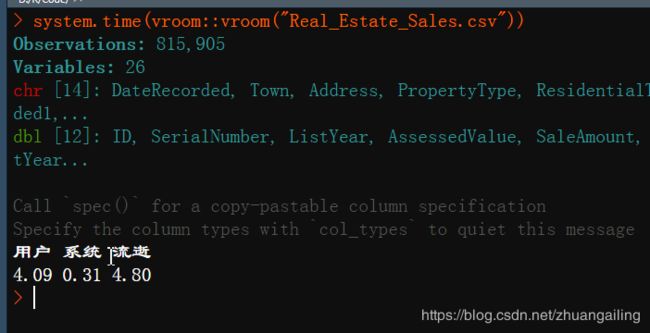
再用data.table中的fread函数对比一下
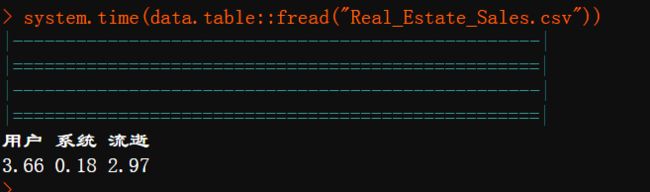
可能是数据量太小了