
一、前言
作者:Jack Cui
经过上两篇文章的学习,Python爬虫三步走:发起请求、解析数据、保存数据,已经掌握,算入门爬虫了吗?
不,还远远不够!只掌握这些,还只能算门外汉级别。
今天,就来带大家继续学习,怎么爬的更优雅!
按照惯例,还是从实战出发,今天咱们就爬个图片,盘点那些遇到的问题,和优雅的解决方案。
本文男女老少皆宜,什么妹子图、肌肉男,学会了本文的方法,一切尽收囊中!
很多人学习python,不知道从何学起。
很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手。
很多已经做案例的人,却不知道如何去学习更加高深的知识。
那么针对这三类人,我给大家提供一个好的学习平台,免费领取视频教程,电子书籍,以及课程的源代码!
QQ群:1097524789
二、实战背景
咱不来吸睛劲爆的图片下载,咱来点清淡的家常菜。
动漫之家漫画下载!

这个实战,你会遇到动态加载、初级反爬,会了本文的方法,你还怕爬不到心心念的"美图"吗?

三、漫画下载
咱不下载整站资源,就挑一本下载,别给服务器太大压力。
挑来挑去,找了本动漫之家排名靠前的一本《妖神记》,说实话,看了漫画第一章的内容,浓浓的火影气息。
URL:https://www.dmzj.com/info/yaoshenji.html

想下载这本动漫,我们需要保存所有章节的图片到本地。我们先捋捋思路:
- 拿到所有章节名和章节链接
- 根据章节链接章节里的所有漫画图片
- 根据章节名,分类保存漫画
看似简单,实际做起来,可能遇到各种各样的问题,让我们一起优雅的解决这些问题吧!
1、获取章节名和章节链接
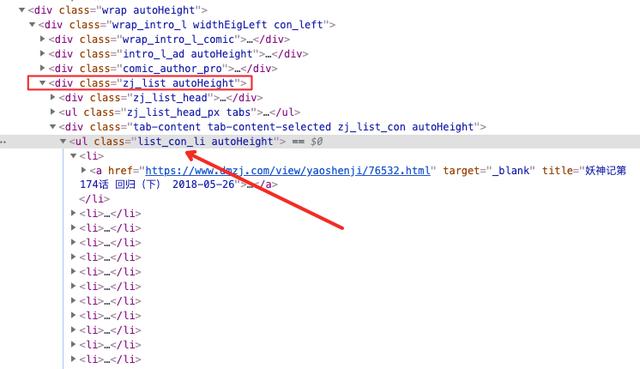
一个网页,是由很多div元素组成的
不同的div存放不同的内容,如上图,有存放标题Jack Cui的div,有存放菜单的div,有存放正文内容的div,有存放版权信息的div。

瞧,不难发现,只要拿到class属性为zj_list的div标签,就能拿到章节名和章节链接,都存放在这个div标签下的a标签中。
再仔细观察一番,你会发现,div标签下还有个ul标签,ul标签是距离a标签最近的标签。
用上一篇文章讲解的BeautifulSoup,实际上直接匹配最近的class属性为list_con_li的ul标签即可。编写如下代码:
Python
import requests
from bs4 import BeautifulSoup
target_url = "https://www.dmzj.com/info/yaoshenji.html"
r = requests.get(url=target_url)
bs = BeautifulSoup(r.text, 'lxml')
list_con_li = bs.find('ul', class_="list_con_li")
comic_list = list_con_li.find_all('a')
chapter_names = []
chapter_urls = []
for comic in comic_list:
href = comic.get('href')
name = comic.text
chapter_names.insert(0, name)
chapter_urls.insert(0, href)
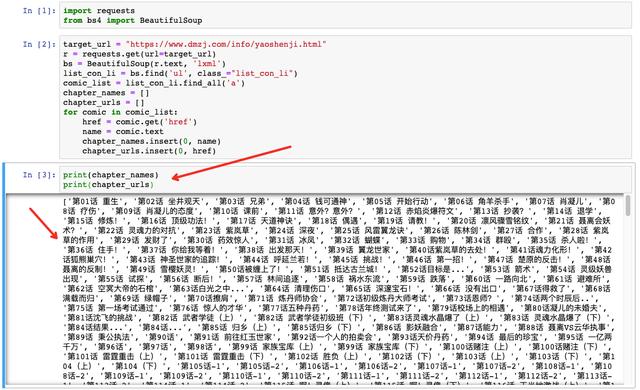
print(chapter_names)
print(chapter_urls)瞧,章节名和章节链接搞定了!
没有难度啊?别急,难的在后面。
2、获取漫画图片地址
我们只要分析在一个章节里怎么获取图片,就能批量的在各个章节获取漫画图片。
我们先看第一章的内容。
URL:https://www.dmzj.com/view/yaoshenji/41917.html
打开第一章的链接,你会发现,链接后面自动添加了#@page=1。
你翻页会发现,第二页的链接是后面加了#@page=2,第三页的链接是后面加了#@page=3,以此类推。
但是,这些并不是图片的地址,而是这个展示页面的地址,要下载图片,首先要拿到图片的真实地址。
审查元素找图片地址,你会发现,这个页面不能右键!
这就是最最最最低级的反爬虫手段,这个时候我们可以通过键盘的F12调出审查元素窗口。
有的网站甚至把F12都禁掉,这种也是很低级的反爬虫手段,骗骗刚入门的手段而已。
面对这种禁止看页面源码的初级手段,一个优雅的通用解决办法是,在连接前加个view-source:。
Shell
view-source:https://www.dmzj.com/view/yaoshenji/41917.html用这个链接,直接看的就是页面源码。

更简单的办法是,将鼠标焦点放在浏览器地址栏,然后按下F12依然可以调出调试窗口。
这个漫画网站,还是可以通过F12审查元素,调出调试窗口的。

我们可以在浏览器调试窗口中的Network里找到这个页面加载的内容,例如一些css文件啊、js文件啊、图片啊,等等等。
要找图片的地址,直接在这里找,别在html页面里找,html信息那么多,一条一条看得找到猴年马月。
在Network中可以很轻松地找到我们想要的图片真实地址,调试工具很强大,Headers可以看一些请求头信息,Preview可以浏览返回信息。
搜索功能,过滤功能等等,应有尽有,具体怎么用,自己动手点一点,就知道了!
好了,拿到了图片的真实地址,我们看下链接:
https://images.dmzj.com/img/chapterpic/3059/14237/14395217739069.jpg
这就是图片的真实地址,拿着这个链接去html页面中搜索,看下它存放在哪个img标签里了,搜索一下你会发现,浏览器中的html页面是有这个图片链接的。
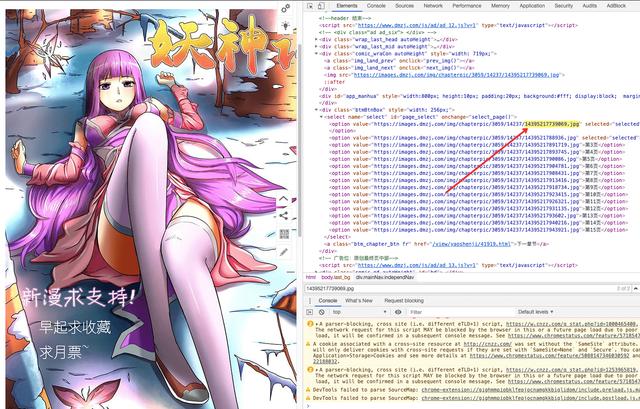
但你是用view-source:打开这个页面,你会发现你搜索不到这个图片链接。
Shell
view-source:https://www.dmzj.com/view/yaoshenji/41917.html
记住,这就说明,这个图片是动态加载的!

使用view-source:方法,就是看页面源码,并不管动态加载的内容。这里面没有图片链接,就说明图片是动态加载的。
是不是判断起来很简单?
遇到动态加载不要慌,使用JavaScript动态加载,无外乎两种方式:
- 外部加载
- 内部加载
外部加载就是在html页面中,以引用的形式,加载一个js,例如这样:
XHTML
这段代码得意思是,引用cuijiahua.com域名下的call.js文件。
内部加载就是Javascript脚本内容写在html内,例如这个漫画网站。
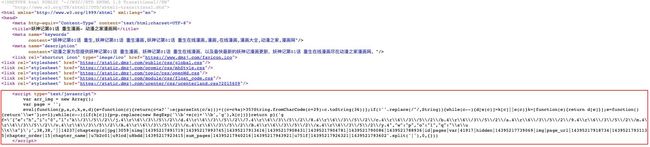
这时候,就可以用搜索功能了,教一个搜索小技巧。
https://images.dmzj.com/img/chapterpic/3059/14237/14395217739069.jpg
图片链接是这个,那就用图片的名字去掉后缀,也就是14395217739069在浏览器的调试页面搜索,因为一般这种动态加载,链接都是程序合成的,搜它准没错!
XHTML
不出意外,你就能看到这段代码,14395217739069就混在其中!
看不懂Javascript,怎么办啊?
没关系,说实话,我看着也费劲儿。
那咱们就找找规律,分析分析,看看能不能优雅的解决这个动态加载问题,我们再看这个图片链接:
https://images.dmzj.com/img/chapterpic/3059/14237/14395217739069.jpg
链接中的数字是不是眼熟?

这不就是这几个数字合成的吗?
好了,我有个大胆的想法!直接把这些长的数字搞出来,合成下链接试试看。
Python
import requests
from bs4 import BeautifulSoup
import re
url = 'https://www.dmzj.com/view/yaoshenji/41917.html'
r = requests.get(url=url)
html = BeautifulSoup(r.text, 'lxml')
script_info = html.script
pics = re.findall('\d{13,14}', str(script_info))
chapterpic_hou = re.findall('\|(\d{5})\|', str(script_info))[0]
chapterpic_qian = re.findall('\|(\d{4})\|', str(script_info))[0]
for pic in pics:
url = 'https://images.dmzj.com/img/chapterpic/' + chapterpic_qian + '/' + chapterpic_hou + '/' + pic + '.jpg'
print(url)运行代码,你可以得到如下结果:

踏破铁鞋无觅处,得来全不费工夫!
比对一下你会发现,这些,还真就是漫画图片的链接!
但是有个问题,这么合成的的图片链接不是按照漫画顺序的,这下载下来漫画图片都是乱的啊!不优雅!
这个网站也是人写的嘛!是人,就好办!惯性思维,要是你,是不是小数放在前面,大数放在后面?这些长的数字里,有13位的,有14位的,并且都是以14开头的数字,那我就赌它末位补零后的结果,就是图片的顺序!
Python
import requests
from bs4 import BeautifulSoup
import re
url = 'https://www.dmzj.com/view/yaoshenji/41917.html'
r = requests.get(url=url)
html = BeautifulSoup(r.text, 'lxml')
script_info = html.script
pics = re.findall('\d{13,14}', str(script_info))
for idx, pic in enumerate(pics):
if len(pic) == 13:
pics[idx] = pic + '0'
pics = sorted(pics, key=lambda x:int(x))
chapterpic_hou = re.findall('\|(\d{5})\|', str(script_info))[0]
chapterpic_qian = re.findall('\|(\d{4})\|', str(script_info))[0]
for pic in pics:
if pic[-1] == '0':
url = 'https://images.dmzj.com/img/chapterpic/' + chapterpic_qian + '/' + chapterpic_hou + '/' + pic[:-1] + '.jpg'
else:
url = 'https://images.dmzj.com/img/chapterpic/' + chapterpic_qian + '/' + chapterpic_hou + '/' + pic + '.jpg'
print(url)程序对13位的数字,末位补零,然后排序。

在跟网页的链接按顺序比对,你会发现没错!就是这个顺序!
不用读懂Javascript合成链接代码,直接分析测试,够不够优雅?
3、下载图片
万事俱备,只欠东风!
使用其中一个图片链接,用代码下载试试。
Python
import requests
from urllib.request import urlretrieve
dn_url = 'https://images.dmzj.com/img/chapterpic/3059/14237/14395217739069.jpg'
urlretrieve(dn_url,'1.jpg')通过urlretrieve方法,就可以下载,这是最简单的下载方法。第一个参数是下载链接,第二个参数是下载后的文件保存名。
不出意外,就可以顺利下载这张图片!
但是,意外发生了!
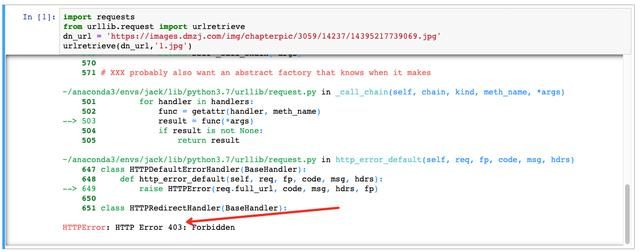
出现了HTTP Error,错误代码是403。
403表示资源不可用,这是又是一种典型的反扒虫手段。
别慌,我们再分析一波!
打开这个图片链接:
URL:https://images.dmzj.com/img/chapterpic/3059/14237/14395217739069.jpg
这个地址就是图片的真实地址,在浏览器中打开,可能直接无法打开,或者能打开,但是一刷新就又不能打开了!

如果再打开章节页面,再打开这个图片链接就又能看到图片了。
章节URL:https://www.dmzj.com/view/yaoshenji/41917.html
记住,这就是一种典型的通过Referer的反扒爬虫手段!
Referer可以理解为来路,先打开章节URL链接,再打开图片链接。打开图片的时候,Referer的信息里保存的是章节URL。
动漫之家网站的做法就是,站内的用户访问这个图片,我就给他看,从其它地方过来的用户,我就不给他看。
是不是站内用户,就是根据Referer进行简单的判断。
这就是很典型的,反爬虫手段!
解决办法也简单,它需要啥,咱给它就完了。Python
import requests
from contextlib import closing
download_header = {
'Referer': 'https://www.dmzj.com/view/yaoshenji/41917.html'
}
dn_url = 'https://images.dmzj.com/img/chapterpic/3059/14237/14395217739069.jpg'
with closing(requests.get(dn_url, headers=download_header, stream=True)) as response:
chunk_size = 1024
content_size = int(response.headers['content-length'])
if response.status_code == 200:
print('文件大小:%0.2f KB' % (content_size / chunk_size))
with open('1.jpg', "wb") as file:
for data in response.iter_content(chunk_size=chunk_size):
file.write(data)
else:
print('链接异常')
print('下载完成!')使用closing方法可以设置Headers信息,这个Headers信息里保存Referer来路,就是第一章的URL,最后以写文件的形式,保存这个图片。
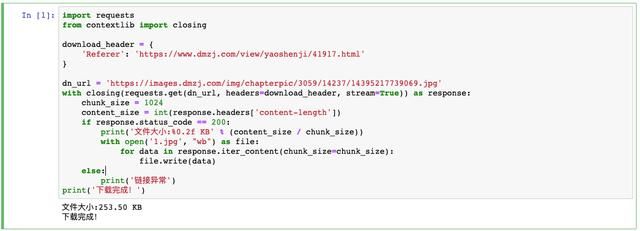
下载完成!就是这么简单!
四、漫画下载
将代码整合在一起,下载整部漫画。编写代码如下:Python
import requests
import os
import re
from bs4 import BeautifulSoup
from contextlib import closing
from tqdm import tqdm
import time
"""
Author:
Jack Cui
Wechat:
https://mp.weixin.qq.com/s/OCWwRVDFNslIuKyiCVUoTA
"""
# 创建保存目录
save_dir = '妖神记'
if save_dir not in os.listdir('./'):
os.mkdir(save_dir)
target_url = "https://www.dmzj.com/info/yaoshenji.html"
# 获取动漫章节链接和章节名
r = requests.get(url = target_url)
bs = BeautifulSoup(r.text, 'lxml')
list_con_li = bs.find('ul', class_="list_con_li")
cartoon_list = list_con_li.find_all('a')
chapter_names = []
chapter_urls = []
for cartoon in cartoon_list:
href = cartoon.get('href')
name = cartoon.text
chapter_names.insert(0, name)
chapter_urls.insert(0, href)
# 下载漫画
for i, url in enumerate(tqdm(chapter_urls)):
download_header = {
'Referer': url
}
name = chapter_names[i]
# 去掉.
while '.' in name:
name = name.replace('.', '')
chapter_save_dir = os.path.join(save_dir, name)
if name not in os.listdir(save_dir):
os.mkdir(chapter_save_dir)
r = requests.get(url = url)
html = BeautifulSoup(r.text, 'lxml')
script_info = html.script
pics = re.findall('\d{13,14}', str(script_info))
for j, pic in enumerate(pics):
if len(pic) == 13:
pics[j] = pic + '0'
pics = sorted(pics, key=lambda x:int(x))
chapterpic_hou = re.findall('\|(\d{5})\|', str(script_info))[0]
chapterpic_qian = re.findall('\|(\d{4})\|', str(script_info))[0]
for idx, pic in enumerate(pics):
if pic[-1] == '0':
url = 'https://images.dmzj.com/img/chapterpic/' + chapterpic_qian + '/' + chapterpic_hou + '/' + pic[:-1] + '.jpg'
else:
url = 'https://images.dmzj.com/img/chapterpic/' + chapterpic_qian + '/' + chapterpic_hou + '/' + pic + '.jpg'
pic_name = '%03d.jpg' % (idx + 1)
pic_save_path = os.path.join(chapter_save_dir, pic_name)
with closing(requests.get(url, headers = download_header, stream = True)) as response:
chunk_size = 1024
content_size = int(response.headers['content-length'])
if response.status_code == 200:
with open(pic_save_path, "wb") as file:
for data in response.iter_content(chunk_size=chunk_size):
file.write(data)
else:
print('链接异常')
time.sleep(10)大约40分钟,漫画即可下载完成!
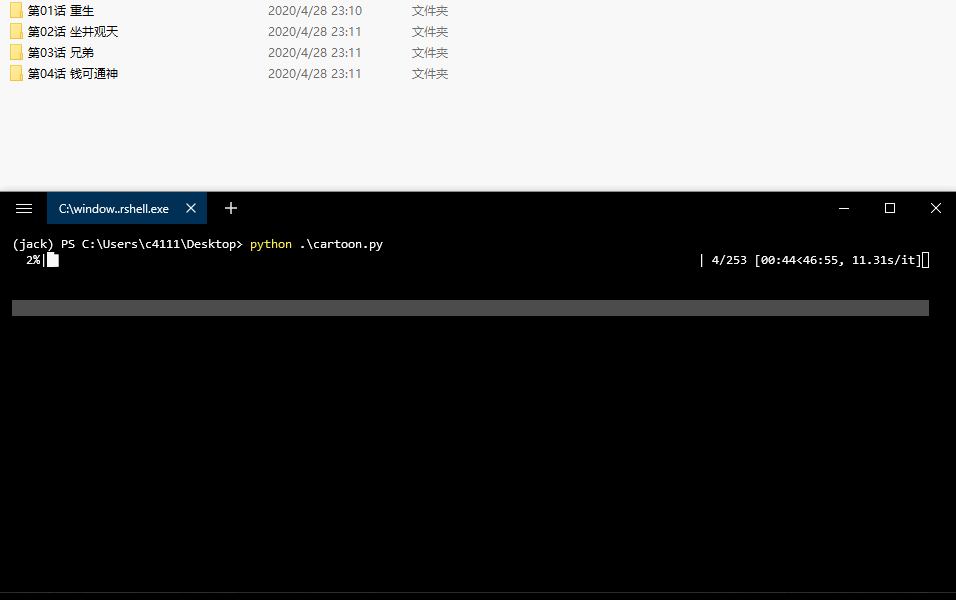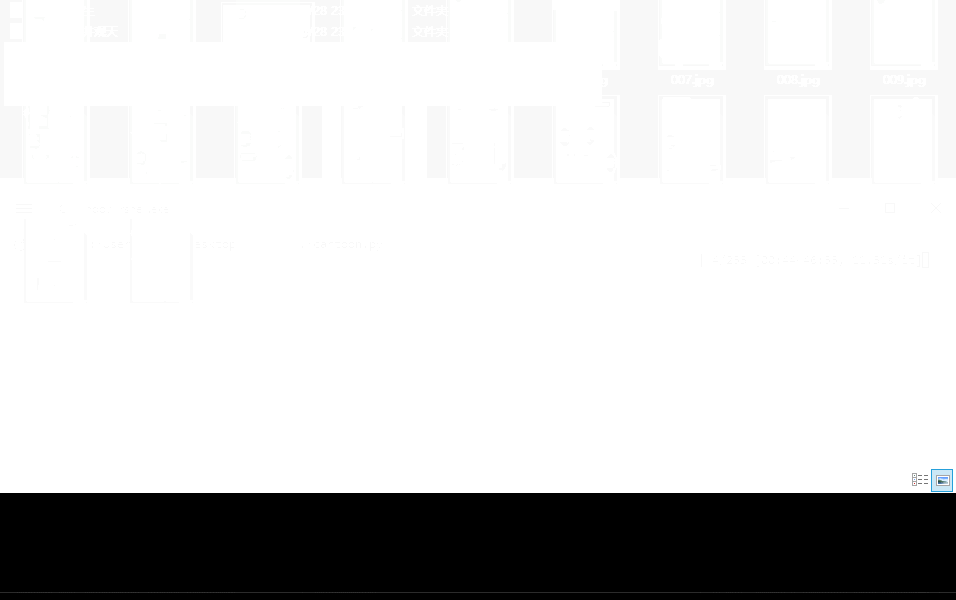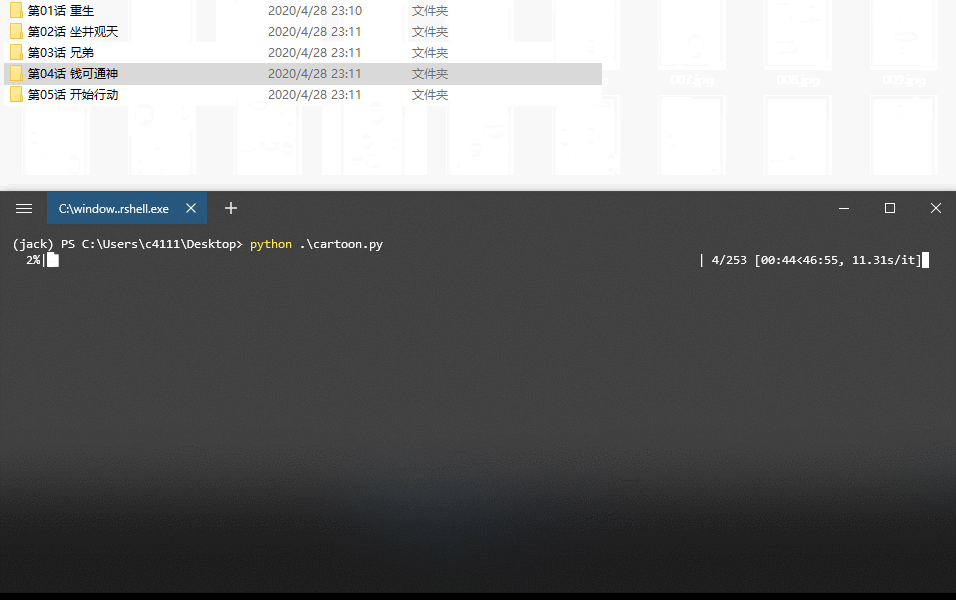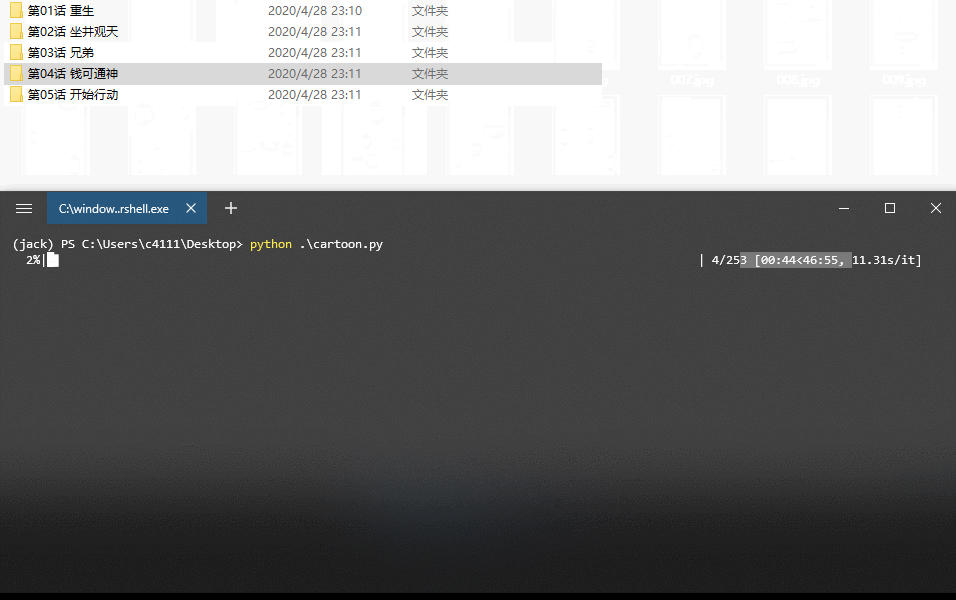
还是那句话,我们要做一个友好的爬虫。写爬虫,要谨慎,勿给服务器增加过多的压力,满足我们的获取数据的需求,这就够了。
你好,我也好,大家好才是真的好。
五、总结
- 本文讲解了如何判断页面信息是不是动态加载的,如何解决动态加载问题。
- 本文讲解了一些常见的反爬虫策略以及解决办法。