Java面试题总结
一、Java语法
Java和 c++
不同点:
解释型,编译型
纯面向对象,面向对象兼顾面向过程
更加安全
单继承,多继承
垃圾回收(finalize()->析构函数)
java继承,封装,多态
1.封装是什么:隐藏对象的属性和实现细节,仅仅对外提供接口,控制在程序中属性的读和写的访问级别。将数据和行为有机结合在一起,形成“类”
2.封装有什么用:
使用者->简化编程,只要会使用外部暴露的接口即可。
java代码->增强安全性,规定特定的访问权限来使用类的成员。
3.封装的基本要求:把所有的字段都私有化,提供getset方法,如果有一个带参的构造器,必须提供不带参的构造器。
a.继承是什么:先抽象提取,形成一个类,基类A,如果类B要使用基类的属性和方法,需要使用extends关键字继承
b.继承的好处:实现代码复用,java不支持多继承,开发中应该少用继承,降低程序的耦合性,多组合少继承
c.继承的基本特征:子类不能继承父类private修饰成员变量和方法,但是子类可以重写父类的方法。
A:多态:编译时多态 + 运行时多态,
B: 方法的重载:重载是指同一个类中有多个同名方法,但这些方法的有着不同的参数个数参数类型参数顺序,因此在编译期间就确定到底调用哪个方法,他是编译时多态
C: 方法的覆盖(重写):子类可以覆盖父类的方法,相同方法不同表现形式,基类的引用变量不仅可以指向基类的实例对象,也可以指向子类的实例对象
重载和重写
Overload是重载的意思,Override是覆盖的意思,也就是重写。
\1. 重载:同一个类中可以有多个名称相同的方法,其参数列表各不相同。
\2. 重写:子类中的方法可以与父类中的某个方法的名称和参数完全相同。
1.通过子类创建的实例对象调用这个方法时,将调用子类中的定义方法,这相当于把父类中定义的那个完全相同的方法给覆盖了,这也是面向对象编程的多态性的一种表现。
2.子类覆盖父类的方法时,只能比父类抛出更少的异常,因为子类可以解决父类的一些问题,不能比父类有更多的问题。
3.子类方法的访问权限只能比父类的更大,不能更小。
4.如果父类的方法是private类型,那么,子类则不存在覆盖的限制,相当于子类中增加了一个全新的方法。
问:如果两个方法的参数列表完全一样,是否可以让它们的返回值不同来实现重载
答:这是不行的,我们可以用反证法来说明这个问题,因为我们有时候调用一个方法时也可以不定义返回结果变量,即不要关心其返回结果,例如,我们调用map.remove(key)方法时,虽然remove方法有返回值,但是我们通常都不会定义接收返回结果的变量,这时候假设该类中有两个名称和参数列表完全相同的方法,仅仅是返回类型不同,java就无法确定编程者倒底是想调用哪个方法了,因为它无法通过返回结果类型来判断。
即:不能通过访问权限、返回类型、抛出的异常进行重载;
构造方法能否被重写和重载?
构造方法是不能被重写的。构造方法可以被重载。
面向对象与面向过程的区别
1)认识问题角度:面向对象:死物 受规律被动操控 面向对象:活物 主动交互
2)解决问题方法:面向对象:函数 面向对象:对象
3)解决问题的中心思想:
面向过程:how 怎么样(流程被疯转到函数里,how如何 就是过程)
面向对 象:who,谁来做(谁,就是对象,如何做是他的事,多个对象合作完成一件事)
4)解决问题的步骤:面向过程:先具体逻辑细节,后抽象问题整体 面向函数:先抽象问题整体,在 具体实现
面向对象设计原则
单一职责原则(SRP)
开放封闭原则(OCP)
里氏替换原则(LSP)
依赖倒置原则(DIP)
接口隔离原则(ISP)
1.单一职责原则 —— 核心:高内聚,低耦合,分工明确,各司其职
2.开闭原则 —— 核心:开放扩展,关闭修改
3.里氏替换原则
——任何父类出现的地方,都可以用子类代替,子类方法的输入参数应该比相应父类方法的输入参数范围更宽松,输出结果 范围更小
4.依赖倒转原则 —— 核心:不依赖具体,依赖抽象
5.接口分离原则 —— 核心:接口的功能应该单一
6.合成复用原则 —— 核心:减少继承,增加组合
7.迪米特原则 —— 核心:一个类应该只关注自己的逻辑,尽量少的设计其他类的实现——最少知道
JDK 和 JRE
JDK(Java Development Kit )JDK是面向开发人员使用的SDK,它提供了Java的开发环境和运行环境。SDK一般指软件开发包,可以包括函数库、编译程序等。 JDK包含了JRE,同时还包含了编译java源码的编译器javac,还包含了很多java程序调试和分析的工具:jconsole,jvisualvm等工具软件,还包含了java程序编写所需的文档和demo例子程序。 JRE( Java Runtime Environment) 是指Java的运行环境,包含了java虚拟机,java基础类库 是面向Java程序的使用者,而不是开发者。
hashCode +equals
\2. equals在Object中与==的作用都是比较引用(地址值)是否相等。一般情况下会被重写,例如比较字符串比较的是字符串的值。没有重写的话就是比较的是地址是否相等。
\3. hashCode()根据这个对象内存储的数据及对象的一些特征来做散列返回一个有符号的 32 位哈希值,所以 hashCode() 方法返回的是一个散列值,而对于一个散列来说不同的内容也是可能会出现相同的散列值
hashCode方法的使用涉及到哈希表,在比较两个元素是否相同时先比较hashcode如果相同在比较equals,如果都相同,则是同一个元素
StringBuffer和StringBuilder
String类是重新生成了一个新的字符串对象。也就是说进行这些操作后,最原始的字符串并没有被改变。“对String对象的任何改变都不影响到原对象,相关的任何change操作都会生成新的对象”。
创建了一个 String 类的对象之后,很难对她进行增、删、改的操作,为了解决这个弊端,Java 语言就引入了 StringBuffer 类。StringBuffer 的内部实现方式和 String 不同,StringBuffer 在进行字符串处理时,不用生成新的对象,内存的使用上 StringBuffer 要优于 String 类。
在 JDK 5.0 之后,引入了 StringBuilder 类
1.对于操作效率而言,一般来说,StringBuilder > StringBuffer > String;
2.对于线程安全而言,StringBuffer 是线程安全的;而 StringBuilder 是非线程安全的;
3.对于频繁的字符串操作而言,无论是 StringBuffer 还是 StringBuilder,都优于 String。
Java程序的种类
(a)内嵌于Web文件中,由浏览器来观看的_Applet
(b)可独立运行的 Application
(c)服务器端的 Servlets
Application ―Java应用程序”是可以独立运行的Java程序。由Java解释器控制执行。 Applet ―Java小程序”不能独立运行(嵌入到Web页中)。由Java兼容浏览器控制执行。
Serverlets 是Java技术对CGI 编程的解决方案。 是运行于Web server上的、作为来自于Web browser 或其他HTTP client端的请求和在server上的数据库及其他应用程序之间的中间层程序。 Serverlets的工作是: 读入用户发来的数据(通常在web页的form中) 找出隐含在HTTP请求中的其他请求信息(如浏览器功能细节、请求端主机名等。) 产生结果(调用其他程序、访问数据库、直接计算) 格式化结果(网页) 设置HTTP response参数(如告诉浏览器返回文档格式) 将文档返回给客户端。
== 和 equals 的区别
== 比较的是变量(栈)内存中存放的对象的(堆)内存地址,用来判断两个对象的地址是否相同,即是否是指相同一个对象。比较的是真正意义上的指针操作。 equals用来比较内容是否相等,默认equals方法返回的是==的判断。
hashCode()相同,则 equals()也一定为 true?
不对;
hashCode() 的作用是获取散列码;它实际上是返回一个int整数。这个哈希码的作用是确定该对象在哈希表中的索引位置。 在散列表中, 1、如果两个对象相等,那么它们的hashCode()值一定要相同; 2、如果两个对象hashCode()相等,它们并不一定相等。
为什么重载了equals方法之后需要去重载hashCode方法?
为了保证Hash的时候调用对象的equals方法可以映射到同一个位置。
关键字:
静态块:用static申明,JVM加载类时执行,仅执行一次 构造块:类中直接用{}定义,每一次创建对象时执行 执行顺序优先级:静态块>main()>构造块>构造方法
分类
Java语言提供了很多修饰符,大概分为两类:
-
访问权限修饰符
-
非访问权限修饰符
访问权限修饰符
-
public:所有的类可见。
-
protected:同包可见,不同包子类可见。
-
default:同包可见,不同的包子类不可见。
-
private:同类可见。
非访问权限修饰符
-
static:类方法和类变量。
-
final:类不能够被继承,方法不能被重写,变量为常量。
-
abstract:抽象类和抽象方法。
-
synchronized 用于多线程的同步。
-
volatile :访问时,强制从共享内存中读取该成员变量的值。变化时,强制将变化值回写到共享内存。结果保证了可见性。
-
transient:序列化的对象包含被 transient 修饰的实例变量时,java 虚拟机(JVM)跳过该特定的变量。
类
内部类的分类
包括四种:成员内部类,局部内部类,匿名内部类,静态内部类 。
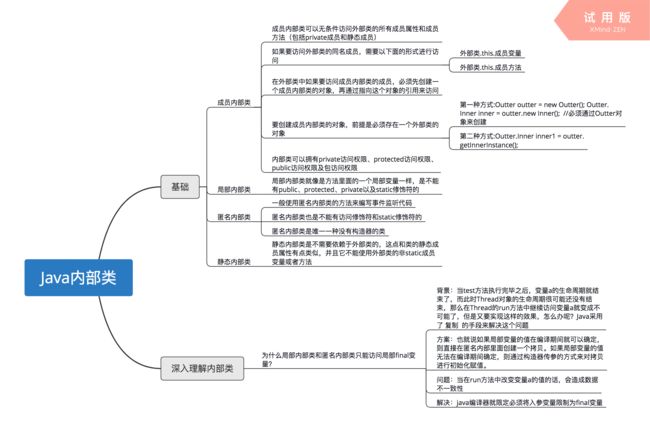
1.成员内部类
(1)该类像是外部类的一个成员,可以无条件的访问外部类的所有成员属性和成员方法(包括private成员和静态成员);
(2)同名的成员变量采用就近原则。要访问外部类中的成员,外部类.this.成员变量 /外部类.this.成员方法
(3)外部类中访问成员内部类的成员,要创建一个成员内部类的对象,再通过指向这个对象的引用来访问;
(4)成员内部类是依附外部类而存在的,也就是说,如果要创建成员内部类的对象,前提是必须存在一个外部类的对象;
(5)访问权限:全有
外部类只能被public和包访问两种权限修饰。
2.局部内部类
(1)定义在一个方法或者一个作用域里,访问仅限于方法内或者该作用域内;
(2)地位等同方法里面的一个局部变量一样,无修饰符的。
3.匿名内部类
(1)一般使用匿名内部类的方法来编写事件监听代码;
(2)匿名内部类是不能有访问修饰符和static修饰符的;
(3)匿名内部类是唯一一种没有构造器的类;
(4)匿名内部类用于继承其他类或是实现接口,并不需要增加额外的方法,只是对继承方法的实现或是重写。
匿名内部类的创建格式为: new 父类构造器(参数列表)|实现接口(){
//匿名内部类的类体实现
}
1、使用匿名内部类时,我们必须是继承一个类或者实现一个接口,但是两者不可兼得,同时也只能继承一个类或者实现一个接口。
2、匿名内部类中是不能定义构造函数的。
3、匿名内部类中不能存在任何的静态成员变量和静态方法。
4、匿名内部类为局部内部类,所以局部内部类的所有限制同样对匿名内部类生效。
5、匿名内部类不能是抽象的,它必须要实现继承的类或者实现的接口的所有抽象方法。
4.静态内部类
(1)静态内部类是不需要依赖于外部类的,这点和类的静态成员属性有点类似;
(2)不能使用外部类的非static成员变量或者方法。
外部类修饰符
-
public(访问控制符)一个程序的主类必须是公共类。
-
default(访问控制符)
-
abstract(非访问控制符)将一个类声明为抽象类,抽象类不能用来实例化对象,声明抽象类的唯一目的是为了将来对该类进行扩充,抽象类可以包含抽象方法和非抽象方法。
-
fina表示它不能被其他类继承。
注意:
1.protected 和 private 不能修饰外部类,是因为外部类放在包中,只有两种可能,包可见和包不可见。
-
final 和 abstract不能同时修饰外部类,因为该类要么能被继承要么不能被继承,二者只能选其一。
3.不能用static修饰类,因为类加载后才会加载静态成员变量。所以不能用static修饰类和接口,因为类还没加载,无法使用static关键字。
内部类修饰符
内部类与成员变量地位一直,所以可以public,protected、default和private,同时还可以用static修饰,表示嵌套内部类,不用实例化外部类,即可调用。
方法修饰符
-
public(公共控制符),包外包内都可以调用该方法。
-
protected(保护访问控制符)指定该方法可以被它的类和子类进行访问。
-
default(默认权限),指定该方法只对同包可见,对不同包(含不同包的子类)不可见。
-
private(私有控制符)指定此方法只能有自己类等方法访问,其他的类不能访问(包括子类),非常严格的控制。
-
final ,指定方法已完备,不能再进行继承扩充。
-
static,指定不需要实例化就可以激活的一个方法,即在内存中只有一份,通过类名即可调用。
-
synchronize,同步修饰符,在多个线程中,该修饰符用于在运行前,对它所属的方法加锁,以防止其他线程的访问,运行结束后解锁。
-
native,本地修饰符。指定此方法的方法体是用其他语言在程序外部编写的。
-
abstract ,抽象方法是一种没有任何实现的方法,该方法的的具体实现由子类提供。抽象方法不能被声明成 final 和 static。 任何继承抽象类的子类必须实现父类的所有抽象方法,除非该子类也是抽象类。 如果一个类包含若干个抽象方法,那么该类必须声明为抽象类。抽象类可以不包含抽象方法。 抽象方法的声明以分号结尾,例如:public abstract sample();。
成员变量修饰符
-
public(公共访问控制符),指定该变量为公共的,它可以被任何对象的方法访问。
-
protected(保护访问控制符)指定该变量可以被自己的类和子类访问。在子类中可以覆盖此变量。
-
default(默认权限),指定该变量只对同包可见,对不同包(含不同包的子类)不可见。
-
private(私有访问控制符)指定该变量只允许自己的类的方法访问,其他任何类(包括子类)中的方法均不能访问。
-
final,最终修饰符,指定此变量的值不能变。
-
static(静态修饰符)指定变量被所有对象共享,即所有实例都可以使用该变量。变量属于这个类。
-
transient(过度修饰符)指定该变量是系统保留,暂无特别作用的临时性变量。不持久化。
-
volatile(易失修饰符)指定该变量可以同时被几个线程控制和修改,保证两个不同的线程总是看到某个成员变量的同一个值。
final 和 static 经常一起使用来创建常量。
局部变量修饰符
only final is permitted。
为什么不能赋予权限修饰符?
因为局部变量的生命周期为一个方法的调用期间,所以没必要为其设置权限访问字段,既然你都能访问到这个方法,所以就没必要再为其方法内变量赋予访问权限,因为该变量在方法调用期间已经被加载进了虚拟机栈,换句话说就是肯定能被当前线程访问到,所以设置没意义。
为什么不能用static修饰
我们都知道静态变量在方法之前先加载的,所以如果在方法内设置静态变量,可想而知,方法都没加载,你能加载成功方法内的静态变量?
接口
接口修饰符
接口修饰符只能用public、default和abstract。
不能用final、static修饰。
接口默认修饰为abstract。
接口中方法修饰符:只能用 public abstract修饰,如果都不写,默认是public abstract。
注意:在Java1.8之后,接口可以用static来修饰
swtich:switch支持 int及以下(char, short, byte)&包装类型,String, Enum(整数表达式或者枚举常量(更大字体))String类型是Java7开始支持。
final
1、final成员变量表示常量,如果final指针,那么指针地址不可以改变,但是指针指向的对象可以改变 2、final类不能继承 3、final方法不能重写,但是可以继承 3、final不能修饰构造函数
static
作用于方法上:方法属于类,不属于类的实例对象;Static方法不需要实例对象就可以通过类名调用,且Static方法中不能有实例成员。
作用于变量上:变量属于类,可以用类型引用。
作用于类上:static类只能有static成员。
在什么时候执行:在代码
非static:
作用于方法上:属于类的实例对象,可以有static成员。
作用于变量上:属于实例对象或者是局部变量,创建类的实例对象才能引用。
作用于类上:可以有Static成员也可以有非Static成员。
static是在编译的时候被绑定,加载的时候就会被执行的。按顺序执行static变量和static代码块。
Java中static方法不能被覆盖,因为方法覆盖是基于运行时动态绑定的,而static方法是编译时静态绑定的。static方法跟类的任何实例都不相关,所以概念上不适用。
final finalize finally ?
final: 类被继承,final变量必须在声明时给定初值,而在以后的引用中只能读取,不可修改。方法不能重载。
finalize:
作用:垃圾收集器将对象从内存中清除出去之前做必要的清理工作。子类覆盖 finalize() 方法以整理系统资源或者执行其他清理工作。
时机:由垃圾收集器在确定这个对象没有被引用时对这个对象调用的。finalize() 方法是在垃圾收集器删除对象之前对这个对象调用的。
来源:在 Object 类中定义。
finally:异常处理时提供 finally 块来执行任何清除操作。
finally语句的执行 是在try / catch 中 return语句 执行之后,还是返回之前呢?
1:return语句执行之后返回之前 执行的
2:finally代码块中的return语句覆盖try代码块中的return语句
3:如果finally代码块,没有return语句对try代码块的return语句进行覆盖的话,那么原来的返回值会因为finally代码块中的修改,会导致返回值可能改变也可能不变。
如果返回值类型是传值类型:则不会改变返回值 /
如果返回值是传址类型:会对返回值造成影响(比如在finally代码块中对map进行添加时,key相同时,会进行添加覆盖)
传址:对象 / 数组 传值:8大基本数据类型 及其 包装类,字符常量
try代码块中的语句在异常情况下 不会继续向下执行。
Math.round()
Math.round()的原理是对传入的参数+0.5之后,再向下取整得到的数就是返回的结果,返回值为long型。这里的向下取整是说取比它小的第一个整数或者和它相等的整数。-1.5+0.5=-1向下取整为-1,。 向下取整:Math.floor(); 向上取整:Math.ceil();
基本类型
8个 1、字符类型:byte,char 2、基本整型:short,int,long 3、浮点型:float,double 4、布尔类型:boolean
String、StringBuffer、StringBuilder
string是值传入,不是引用传入。JVM运行程序主要的时间耗费是在创建对象和回收对象上。
String JDK1.0:字符常量被final修饰,当String初始化的时候等号右边以多个字符串常量拼接(+)来初始化时,效率等于用一个字符串初始化
StringBuffer JDK1.0:字符变量,被synchronize修饰,线程安全
StringBuilder JDK1.5:字符变量,无修饰 执行速度:在这方面运行速度快慢为:StringBuilder > StringBuffer > String
String:适用于少量的字符串操作的情况 StringBuilder:适用于单线程下在字符缓冲区进行大量操作的情况 StringBuffer:适用多线程下在字符缓冲区进行大量操作的情况
String str="i"与 String str=new String("i")一样吗
字符串反转
直接用StringBuffer自带的方法reverse() 把字符串转换成字符数组首位对调位置
String 常用方法
char charAt(int index);//返回指定索引处的 char 值。 int compareTo(String anotherString) ;//按字典顺序比较两个字符串。 String concat(String str) ;将指定字符串连接到此字符串的结尾。 boolean contains(CharSequence s);当且仅当此字符串包含指定的 char 值序列时,返回 true。 boolean endsWith(String suffix) ;//测试此字符串是否以指定的后缀结束。 boolean equals(Object anObject) ;//将此字符串与指定的对象比较。 byte[] getBytes();//使用平台的默认字符集将此 String 编码为 byte 序列,并将结果存储到一个新的 byte 数组中。 int indexOf(int ch);//返回指定字符在此字符串中第一次出现处的索引。 int lastIndexOf(int ch) ;//返回指定字符在此字符串中最后一次出现处的索引。 int length();//返回此字符串的长度。 String[] split(String regex);//根据给定正则表达式的匹配拆分此字符串。 boolean startsWith(String prefix);//测试此字符串是否以指定的前缀开始。 char[] toCharArray();//将此字符串转换为一个新的字符数组。 String toUpperCase();//使用默认语言环境的规则将此 String 中的所有字符都转换为大写。 String trim();//返回字符串的副本,忽略前导空白和尾部空白。 String toLowerCase(Locale locale);//使用给定 Locale 的规则将此 String 中的所有字符都转换为小写。
substring** 方法将返回一个包含从 start 到最后(不包含 end )的子字符串的字符串。
| 构造方法 | 描述 |
|---|---|
| StringBuilder() | 创建一个容量为16的StringBuilder对象(16个空元素) |
| StringBuilder(CharSequence cs) | 创建一个包含cs的StringBuilder对象,末尾附加16个空元素 |
| StringBuilder(int initCapacity) | 创建一个容量为initCapacity的StringBuilder对象 |
| StringBuilder(String s) | 创建一个包含s的StringBuilder对象,末尾附加16个空元素 |
不可变类:说的是一个类一旦被实例化,就不可改变自身的状态。常见的比如String和基本数据类型的包装类,对于这种不可变类,一旦在进行引用传递的时候,形参一开始就和实际参数指向的不是一个地址,所以在方法中对形参的改变,并不会影响实际参数。
抽象类必须要有抽象方法吗
抽象类可以不包含抽象方法,包含抽象方法的类一定是抽象类。
抽象类的特点
1、抽象类不能被实例化。 2、抽象类可以有构造函数,被继承时子类必须继承父类一个构造方法,抽象方法不能被声明为静态。 3、抽象方法只需申明,而无需实现,抽象类中可以允许普通方法有主体 4、含有抽象方法的类必须申明为抽象类 5、抽象的子类必须实现抽象类中所有抽象方法,否则这个子类也是抽象类。
抽象类能使用 final 修饰吗
不能
java类一旦被声明为abstract(抽象类),必须要继承或者匿名(其实匿名也是种继承)才能使用。 而final则是让该类无法被继承,所以final是必然不能和abstract同时声明的 但是private呢?一个类被声明为private的时候,它当然是内部类,内部类是可以被它的外部类访问到的,所以,可以继承,private和abstract不冲突。
抽象类和接口的区别
①在接口中不可以有构造方法
A. 构造方法用于初始化成员变量,但是接口成员变量是常量,无需修改。接口是一种规范,被调用 时,主要关注的是里边的方法,而方法是不需要初始化的,
B. 类可以实现多个接口,若多个接口都有自己的构造器,则不好决定构造器链的调用次序
C. 构造器是属于类自己的,不能继承。因为是纯虚的,接口不需要构造器。
②在抽象类中 可以有构造方法。
在抽象类中可以有构造方法,只是不能直接创建抽象类的实例对象,但实例化子类的时候,就会初始化父类,不管父类是不是抽象类都会调用父类的构造方法,初始化一个类,先初始化父类。
接口和抽象类
关于抽象类
JDK 1.8以前,抽象类的方法默认访问权限为protected
JDK 1.8时,抽象类的方法默认访问权限变为default
关于接口
JDK 1.8以前,接口中的方法必须是public的
JDK 1.8时,接口中的方法可以是public的,也可以是default的
JDK 1.9时,接口中的方法可以是private的
抽象类:
1.在Java中属于一种继承关系,一个类只能继承一次。
2.有自己的数据成员,可以有非抽象方法。
3.抽象类表示的关系是is-a。
4.实现抽象类和接口都必须实现其中的所有方法,抽象类中可以有非抽象方法。
5.抽象类中变量默认的方法是friendly型,其值可以在子类中重新定义,也可以重新赋值。
接口:
1.在Java中也属于一种继承关系,但是一个类可以实现多个接口。
2.必须是static final修饰的数据成员,所有的成员方法都是抽象的。
3.接口表示的关系是 like-a。
4.接口中不能有实现方法(除非用default关键字修饰)
5.接口中定义的变量默认是public static final型,所以在实现类不能改变其值,不能重新定义;方法默认是 public abstract。
java 中 IO 流分为几种
BIO、NIO、AIO
Java BIO : 同步并阻塞,客户端有连接请求时服务器端就需要启动一个线程进行处理,如果这个连接不做任何事情会造成不必要的线程开销,当然可以通过线程池机制改善。
Java NIO : 同步非阻塞,客户端发送的连接请求都会注册到多路复用器上,多路复用器轮询到连接有I/O请求时才启动一个线程进行处理。
Java AIO: 异步非阻塞,服务器实现模式为一个有效请求一个线程,客户端的I/O请求都是由OS先完成了再通知务器应用去启动线程进行处理。
NIO比BIO的改善之处是把一些无效的连接挡在了启动线程之前,减少了这部分资源的浪费(因为我们都知道每创建一个线程,就要为这个线程分配一定的内存空间)
AIO比NIO的进一步改善之处是将一些暂时可能无效的请求挡在了启动线程之前,比如在NIO的处理方式中,当一个请求来的话,开启线程进行处理,但这个请求所需要的资源还没有就绪,此时必须等待后端的应用资源,这时线程就被阻塞了。
适用场景分析:
BIO方式适用于连接数目比较小且固定的架构,这种方式对服务器资源要求比较高,并发局限于应用中,JDK1.4以前的唯一选择,但程序直观简单易理解,如之前在Apache中使用。
NIO方式适用于连接数目多且连接比较短(轻操作)的架构,比如聊天服务器,并发局限于应用中,编程比较复杂,JDK1.4开始支持,如在 Nginx,Netty中使用。
AIO方式使用于连接数目多且连接比较长(重操作)的架构,比如相册服务器,充分调用OS参与并发操作,编程比较复杂,JDK7开始支持,在成长中,Netty曾经使用过,后来放弃。
NIO实现原理
阻塞与非阻塞
传统的 IO 流都是阻塞式的。也就是说,当一个线程调用 read() 或 write() 时,该线程阻塞,直到有一些数据被读取或写入,该线程在此期间不能执行其他任务。
因此,在完成网络通信进行 IO 操作时,由于线程会阻塞,所以服务器端必须为每个客户端都提供一个独立的线程进行处理,当服务器端需要处理大量客户端时,性能急剧下降。
Java NIO 是非阻塞模式的。当线程从某通道进行读写数据时,若没有数据可用时,该线程可以进行其他任务。线程通常将非阻塞 IO 的空闲时间用于在其他通道上执行 IO 操作,所以单独的线程可以管理多个输入和输出通道。因此,NIO 可以让服务器端使用一个或有限几个线程来同时处理连接到服务器端的所有客户端。
同步与异步
如果调用方需要保持等待直到IO操作完成进而通过返回 获得结果,则是同步的;如果调用方在IO操作的执行过程中不需要保持等待,而是在操作完成后被动的接受(通过消息或回调)被调用方推送的结果,则是异步的。
选择器Selectors
选择器(Selector) 是 SelectableChannle 对象的多路复用器,Selector 可以同时监控多个 SelectableChannel 的 IO 状况,也就是说,利用 Selector 可使一个单独的线程管理多个 Channel。Selector 是非阻塞 IO 的核心.使用单个线程来处理多个channel相对于多线程来处理多个通道的好处显而易见;节省了开辟新线程和不同的线程之间切换的开销。
两个关键类: Channel和Selector。他们是NIO的核心概念。
可以将Channel比作汽车,selector比作车辆调度系统,他负责每辆车运行状态。Buffer类可以比作车上的座位.
通俗解释
首先创建Selector选择器,创建服务端Channel并绑定到一个Socket对象,并将该通信信道注册到选择器上设置为非阻塞模式。然后就可以调用Selector的selectedKeys方法检查已经注册的所有通信信道是否有事情发生,如有事情发生会返回所有selectionKey,通过这个对象的Channel方法就可以去的这个通信信道的对象,从而读取通信数据Buffer。
通常情况下,一个线程以阻塞方式专门负责监听客户端连接请求,另一个线程专门负责处理请求,这个处理请求的线程才会真正采用NIO的方式。
让Selector来监控一个集合中的所有的通道,当有的通道数据准备好了以后,就可以直接到这个通道获取数据。当线程2去问该线程时,它会知道告诉我们通道 N 已经准备好了,而不需要线程2去轮询
AIO异步IO
AIO 最主要的特点就是回调。
NIO 很好用,它解决了阻塞式 IO 的等待问题,但是它的缺点是需要我们去轮询才能得到结果。
而异步 IO 可以解决这个问题,线程只需要初始化一下,提供一个回调方法,然后就可以干其他的事情了。当数据准备好以后,系统会负责调用回调方法。
Files的方法?java.nio.file.Files
Files类是java.nio.file.Files,其提供了几种操作文件系统中的文件的方法。例如:Files.exists();Files.createDirectory();Files.copy();Files.move();Files.delete()
Java自动装箱
自动拆装箱:
1、基本型和基本型封装型进行“==”运算符的比较,基本型封装型将会自动拆箱变为基本型后再进行比较,因此Integer(0)会自动拆箱为int类型再进行比较,显然返回true; 2、两个Integer类型进行“==”比较,如果其值在-128至127,那么返回true,否则返回false, 这跟Integer.valueOf()的缓冲对象有关。 3、两个基本型的封装型进行equals()比较,首先equals()会比较类型,如果类型相同,则继续比较值,如果值也相同,返回true 4、基本型封装类型调用equals(),但是参数是基本类型,这时候,先会进行自动装箱,基本型转换为其封装类型,再进行3中的比较。
数据类型转换:
float占4个字节为什么比long占8个字节大呢,因为底层的实现方式不同。
浮点数的32位并不是简单直接表示大小,而是按照一定标准分配的。
第1位,符号位,即S
接下来8位,指数域,即E。
剩下23位,小数域,即M,取值范围为[1 ,2 ) 或[0 , 1)
然后按照公式: V=(-1)^s * M * 2^E
也就是说浮点数在内存中的32位不是简单地转换为十进制,而是通过公式来计算而来,通过这个公式虽然,只有4个字节,但浮点数最大值要比长整型的范围要大。
| 操作数 1 类型 | 操作数 2 类型 | 转换后的类型 |
|---|---|---|
| byte 、 short 、 char | int | int |
| byte 、 short 、 char 、 int | long | long |
| byte 、 short 、 char 、 int 、 long | float | float |
| byte 、 short 、 char 、 int 、 long 、 float | double | double |
总体主要分为两个方面 ①比较的是值 一、基本数据类型与引用数据类型进行比较时,引用数据类型会进行拆箱,然后与基本数据类型进行值的比较 举例: int i = 12; Integer j = new Integer(12); i == j 返回的是true 二、引用数据类型与基本数据类型进行比较(equals方法),基本数据类型会进行自动装箱,与引用数据类型进行比较,Object中的equals方法比较的是地址,但是Integer类已经重写了equals方法,只要两个对象的值相同,则可视为同一对象,具体看API文档,所以这归根到底也是值的比较! 举例: int i = 12; Integer j = new Integer(12); j.equals(i) 返回的是true ②比较的是地址 一、如果引用数据类型是这样 Integer i = 12;直接从常量池取对象,这是如果数值是在-128与127之间,则视为同一对象,否则视为不同对象 举例: Integer i = 12; Integer j = 12; i == j 返回的是true Integer i = 128; Integer j = 128; i == j 返回的是false 二、如果引用数据类型是直接new的话,不管值是否相同,这时两个对象都是不相同的,因为都会各自在堆内存中开辟一块空间 举例: Integer i =new Integer(12); Integer j = new Integer(12); i == j 这时返回的是false 三、从常量池取对象跟new出来的对象也是不同的 举例: Integer i = 12; Integer j = new Integer(12) i == j 这时返回的是false,因为第二个语句其实已经是new了两个对象了!!!
-
java 1.5 开始的自动装箱拆箱机制其实是编译时自动完成替换的,装箱阶段自动替换为了 valueOf 方法,拆箱阶段自动替换为了 xxxValue 方法。
-
对于 Integer 类型的 valueOf 方法参数如果是 -128~127 之间的值会直接返回内部缓存池中已经存在对象的引用,参数是其他范围值则返回新建对象;
-
而 Double 类型与 Integer 类型类似,一样会调用 Double 的 valueOf 方法,但是 Double 的区别在于不管传入的参数值是多少都会 new 一个对象来表达该数值(因为在指定范围内浮点型数据个数是不确定的,整型等个数是确定的,所以可以 Cache)。
注意:Integer、Short、Byte、Character、Long 的 valueOf 方法实现类似,而 Double 和 Float 比较特殊,每次返回新包装对象,对于两边都是包装类型的比较 == 比较的是引用,equals 比较的是值,对于两边有一边是表达式(包含算数运算)则 == 比较的是数值(自动触发拆箱过程),对于包装类型 equals 方法不会进行类型转换。
Java中包装类缓存
Integer包装类在自动装箱的过程中,是有缓冲池的。对于值在-128~127之间的数,会放在内存中进行重用;对于大于或者小于这个范围的数,有使用的时候都会new出一个新的对象。
java使用该机制是为了达到最小化数据输入和输出的目的,这是一种优化措施,提高效率(可以设置系统属性 java.lang.Integer.IntegerCache.high 修改缓冲区上限,默认为127。参数内容应为大于127的十进制数形式的字符串,否则将被忽略。取值范围为127-Long.MAX_VALUE,但是用时将 强转为int。当系统中大量使用Integer时,增大缓存上限可以节省小量内存)。
其他包装类缓存:Boolean(全部缓存)、Byte(全部缓存)、Character(<= 127缓存)、Short(-128~127缓存)、Long(-128~127缓存)、Float(没有缓存)、Double(没有缓存)。
内存泄漏
内存泄露的概念:可达+无用=无法回收
存在一些被分配的对象,这些对象有下面两个特点,首先,这些对象是可达的,即在有向图中,存在通路可以与其相连;其次,这些对象是无用的,即程序以后不会再使用这些对象。如果对象满足这两个条件,这些对象就可以判定为Java中的内存泄漏,这些对象不会被GC所回收,然而它却占用内存。
JVM工具
jps——查看java进程pid;
jinfo——查看java进程启动参数;
jstack——查看java进程线程栈信息;
jstat——统计java进程的内存占用和回收情况;
jmap——导出JVM堆进行分析,强制产生Full GC;
2、其他工具
jmeter——用于压测模拟线上业务请求;
MAT——用于分析JVM堆是否有内存泄露;
GDB——用于分析内存指定区域存放的具体信息;
gperftools——谷歌的内存问题排查工具,可以用来根据内存分配情况;
3、Linux命令
top——初步定为进程占用的内存,区分虚拟内存和实际占用内存;
free——查看系统内存消耗情况;
pmap——定位进程的内存占用情况;
内存泄露如何定位
泛型
泛型的实现原理:
Java的泛型是伪泛型,Java中的泛型基本上都是在编译器这个层次来实现的,在生成的Java字节码中是不包含泛型中的类型信息的,使用泛型的时候加上的类型参数,会在编译器在编译的时候去掉;
泛型的使用场景:
JAVA中泛型的使用:java中集合使用了泛型,Future
一些使用场景:
不想写多个重载函数的场景。
约束对象类型的场景,可以定义边界(T extends ...),如JDK集合List,Set。
用户希望返回他自定义类型的返回值场景,如Json返回Java bean。
在用反射的应用中,也经常会用到泛型,如Class
对网页,对资源的分析,返回场景,一般都有泛型。
泛型擦除:
类间关系
USES-A:依赖关系,A类会用到B类,这种关系具有偶然性,临时性。但B类的变化会影响A类。这种在代码中的体现为:A类方法中的参数包含了B类。
关联关系:A类会用到B类,这是一种强依赖关系,是长期的并非偶然。在代码中的表现为:A类的成员变量中含有B类。
HAS-A:聚合关系,拥有关系,是关联关系的一种特例,是整体和部分的关系。比如鸟群和鸟的关系是聚合关系,鸟群中每个部分都是鸟。
IS-A:表示继承。父类与子类,这个就不解释了。
要注意:还有一种关系:组合关系也是关联关系的一种特例,它体现一种contains-a的关系,这种关系比聚合更强,也称为强聚合。它同样体现整体与部分的关系,但这种整体和部分是不可分割的。
构造方法
本类的构造方法可以用this.相互调用
构造方法也是类的方法,可以在创建对象时为成员变量赋值
构造函数不能被继承,构造方法只能被显式或隐式的调用。
构造方法是一种特殊的方法,具有以下特点。
(1)构造方法的方法名必须与类名相同。
(2)构造方法没有返回类型,也不能定义为void,在方法名前面不声明方法类型。
(3)构造方法的主要作用是完成对象的初始化工作,它能够把定义对象时的参数传给对象的域。
(4)一个类可以定义多个构造方法,如果在定义类时没有定义构造方法,则编译系统会自动插入一个无参数的默认构造器,这个构造器不执行任何代码。
(5)构造方法可以重载,以参数的个数,类型,顺序。
new String("abc")时,其实会先在字符串常量区生成一个abc的对象,然后new String()时会在堆中分配空间,然后此时会把字符串常量区中abc复制一个给堆中的String
在一个子类被创建的时候,首先会在内存中创建一个父类对象,然后在父类对象外部放上子类独有的属性,两者合起来形成一个子类的对象。所以所谓的继承使子类拥有父类所有的属性和方法其实可以这样理解,子类对象确实拥有父类对象中所有的属性和方法,但是父类对象中的私有属性和方法,子类是无法访问到的,只是拥有,但不能使用。就像有些东西你可能拥有,但是你并不能使用。所以子类对象是绝对大于父类对象的,所谓的子类对象只能继承父类非私有的属性及方法的说法是错误的。可以继承,只是无法访问到而已。
父类没有无参的构造函数,所以子类需要在自己的构造函数中显式调用父类的构造函数, 添加 super("nm"); 否则报错:
如果子类构造器没有显示地调用超类的构造器,则将自动地调用超类默认(没有参数)的构造器。如果超类没有不带参数的构造器,并且在子类的构造器中有没有显示地调用超类的其他构造器,则Java编译器将报告错误。使用super调用构造器的语句必须是子类构造器的第一条语句。——p153《Java核心技术卷I》
自加
count = count++ 原理是 temp = count; count = count+1 ; count = temp; 因此count始终是0 这仅限于java 与c是不一样的
符号:
>>带符号右移
>>>无符号右移
Java中的位运算符:
>>表示右移,如果该数为正,则高位补0,若为负数,则高位补1;
>>>表示无符号右移,也叫逻辑右移,即若该数为正,则高位补0,而若该数为负数,则右移后高位同样补0。标识符
标识符是以字母开头的字母数字序列:
数字是指0~9,字母指大小写英文字母、下划线(_)和美元符号($),也可以是Unicode字符集中的字符,如汉字;
字母、数字等字符的任意组合,不能包含+、- *等字符;
不能使用关键字;
大小写敏感,不可以数字开头
实例方法
实例方法可以调用超类公有实例方法
实例方法可以直接调用超类的公有类方法
实例方法可以通过类名调用其他类的类方法
实例方法可直接调用本类的类方法
关于抽象类和抽象方法
抽象类是为了将一系列事务抽象出来,比如人有各种各样的人,那么我们将Person抽象出来作为一个父类,然后派生出子类,代表各种各样的人,而每个人都有名字,子类中都有getName()方法,但是Person类对名字的具体实现一无所知,所以我们将getName()声明为一个抽象方法,这样就可以不用实现这个方法了
public` `abstract` `String getName();同时,getName()所属的方法也需要声明为抽象方法
abstract` `class` `Person{` `public` `abstract` `String getName();` `......` `}-
当然,抽象类也可以拥有普通的成员变量和方法。
-
抽象类起到的是一种占位的作用,具体的实现交给子类,所以抽象类不能被实例化,比如 new Person("lxb") 就是错误的。
-
还需要注意一点就是,一个类只能继承一个抽象类,这个很好理解,小明是一个人,小明只能继承Person这个抽象类,而不能同时继承Fish这个抽象类,因为小明只是人,不是鱼。
java只有值传递
当一个类导入了多个不同包下相同类名的类时,会编译无法通过
执行对象实例化过程中遵循多态特性 ==> 调用的方法都是将要实例化的子类中的重写方法,只有明确调用了super.xxx关键词或者是子类中没有该方法时,才会去调用父类相同的同名方法
管道:管道实际上是一种固定大小的缓冲区,管道对于管道两端的进程而言,就是一个文件,但它不是普通的文件,它不属于某种文件系统,而是自立门户,单独构成一种文件系统,并且只存在于内存中。它类似于通信中半双工信道的进程通信机制,一个管道可以实现双向 的数据传输,而同一个时刻只能最多有一个方向的传输,不能两个方向同时进行。管道的容 量大小通常为内存上的一页,它的大小并不是受磁盘容量大小的限制。当管道满时,进程在 写管道会被阻塞,而当管道空时,进程读管道会被阻塞
父类静态域——》子类静态域——》父类成员初始化——》父类构造块——》1父类构造方法——》2子类成员初始化——》子类构造块——》3子类构造方法;初始化中,类的静态变量和静态代码块的执行顺序是根据他们定义的顺序来的,优先级是平等的。
接口(interface)可以说成是抽象类的一种特例,接口中的所有方法都必须是抽象的。接口中的方法定义默认为public abstract类型,接口中的成员变量类型默认为public static final。另外,接口和抽象类在方法上有区别:
1.抽象类可以有构造方法,接口中不能有构造方法。
2.抽象类中可以包含非抽象的普通方法,接口中的所有方法必须都是抽象的,不能有非抽象的普通方法。
3.抽象类中可以有普通成员变量,接口中没有普通成员变量
\4. 抽象类中的抽象方法的访问类型可以是public,protected和默认类型
\5. 抽象类中可以包含静态方法,接口中不能包含静态方法
\6. 抽象类和接口中都可以包含静态成员变量,抽象类中的静态成员变量的访问类型可以任意,但接口中定义的变量只能是public static final类型,并且默认即为public static final类型
\7. 一个类可以实现多个接口,但只能继承一个抽象类。二者在应用方面也有一定的区别:接口更多的是在系统架构设计方法发挥作用,主要用于定义模块之间的通信契约。而抽象类在代码实现方面发挥作用,可以实现代码的重用,例如,模板方法设计模式是抽象类的一个典型应用,假设某个项目的所有Servlet类都要用相同的方式进行权限判断、记录访问日志和处理异常,那么就可以定义一个抽象的基类,让所有的Servlet都继承这个抽象基类,在抽象基类的service方法中完成权限判断、记录访问日志和处理异常的代码,在各个子类中只是完成各自的业务逻辑代码。
总结一下
\1. 一个子类只能继承一个抽象类,但能实现多个接口
\2. 抽象类可以有构造方法,接口没有构造方法
\3. 抽象类可以有普通成员变量,接口没有普通成员变量
\4. 抽象类和接口都可有静态成员变量,抽象类中静态成员变量访问类型任意,接口只能public static final(默认)
\5. 抽象类可以没有抽象方法,抽象类可以有普通方法,接口中都是抽象方法
\6. 抽象类可以有静态方法,接口不能有静态方法
\7. 抽象类中的方法可以是public、protected;接口方法只有public
为什么java底层使用快排而不使用堆排序
最大的也是唯一的缺点就是——堆的维护问题,实际场景中的数据是频繁发生变动的,而对于待排序序列的每次更新(增,删,改),我们都要重新做一遍堆的维护,以保证其特性,这在大多数情况下都是没有必要的。(所以快排成为了实际应用中的老大,而堆排序只能在算法书里面顶着光环,当然这么说有些过分了,当数据更新不很频繁的时候,当然堆排序更好些
Final和finally和finalize
final 是一个修饰符,如果一个类被声明为 final 则其不能再派生出新的子类,所以一个类不能既被声明为 abstract 又被声明为 final 的;将变量或方法声明为 final 可以保证它们在使用中不被改变(对于对象变量来说其引用不可变,即不能再指向其他的对象,但是对象的值可变),被声明为 final 的变量必须在声明时给定初值,而在以后的引用中只能读取不可修改,被声明为 final 的方法也同样只能使用不能重载。使用 final 关键字如果编译器能够在编译阶段确定某变量的值则编译器就会把该变量当做编译期常量来使用,如果需要在运行时确定(譬如方法调用)则编译器就不会优化相关代码;将类、方法、变量声明为 final 能够提高性能,这样 JVM 就有机会进行估计并进行优化;接口中的变量都是 public static final 的。
finally 用来在异常处理时提供块来执行任何清除操作,如果抛出一个异常,则相匹配的 catch 子句就会执行,然后控制就会进入 finally 块。
finalize 是一个方法名,Java 允许使用 finalize() 方法在垃圾收集器将对象从内存中清除出去之前做必要的清理工作,这个方法是由垃圾收集器在确定这个对象没有被引用时对这个对象调用的,它是在 Object 类中定义的,因此所有的类都继承了它,子类覆盖 finalize() 方法以整理系统资源或者执行其他清理工作,finalize() 方法在垃圾收集器删除对象之前对这个对象调用的。
Final
finally
1.什么时候用到finally
某些事物在进行异常处理之后,需要回复到以前的状态。此时需要finally来帮助实现
2.finally语句的执行 是在try / catch 中 return语句 执行之后,还是返回之前呢?
2.1:finally代码块是在try代码块中 return语句执行之后返回之前 执行的
2.2:finally代码块中的return语句 覆盖try代码块中的return语句
2.3:如果finally代码块,没有return语句对try代码块的return语句进行覆盖的话,那么原来的返回值会因为finally代码块中的修改,会导致返回值可能改变 也可能不变。
如果返回值类型是传值类型:则不会改变返回值 /
如果返回值是传址类型:会对返回值造成影响(比如在finally代码块中对map进行添加时,key相同时,会进行添加覆盖)
传址:对象 / 数组 传值:8大基本数据类型 及其 包装类,字符常量
2.4:try代码块中的语句在异常情况下 不会继续向下执行。
3.总结:
3.1:try语句没有被执行,也就是说根本没有执行到try语句。就返回了,那么finally是不会被执行的。
说明了,finally执行的前提条件是 try语句一定被执行到。
3.2:如果在try代码块中,执行了System.exit(0),那么就会终止jvm,finally里面的语句肯定不会被执行到。
3.3:如果finally代码块中有return语句,则直接覆盖try/catch 语句直接返回
静态变量**、静态代码块、构造代码块、构造函数的执行顺序**
无父类的情况:
类加载:
静态变量、成员变量加载,初始化为零。
执行顺序:
静态变量>静态代码块>主函数(静态方法)>成员变量>构造代码块>构造函数
http://blog.csdn.net/csdn9988680/article/details/78236196
有父类的情况:
Instance of
java 中的 instanceof 运算符用来在运行时指出对象是否是特定类的一个实例,通过返回一个布尔值来指出这个对象是否是这个特定类或者是它的子类的一个实例;用法为 result = object instanceof class,参数 result 布尔类型,object 为必选项的实例,class 为必选项的任意已定义的对象类,如果 object 是 class 的一个实例则 instanceof 运算符返回 true,如果 object 不是指定类的一个实例或者 object 是 null 则返回 false;
abstract 的方法是否可同时是 static、是否可同时是 native、是否可同时是 synchronized 的?为什么?
答:都不可以,原因如下。
首先 abstract 是抽象的(指方法只有声明没有实现,实现要放入声明该类的子类中),static 是一种属于类而不属于对象的关键字,synchronized 是一种线程并发锁关键字,native 是本地方法,其与抽象方法类似,只有声明没有实现,但是它把具体实现移交给了本地系统的函数库。
对于 static 来说声明 abstract 的方法说明需要子类重写该方法,如果同时声明 static 和 abstract,用类名调用一个抽象方法是行不通的。
对于 native 来说这个东西本身就和 abstract 冲突,因为他们都是方法的声明,只是一个把方法实现移交给子类,另一个是移交给本地操作系统,如果同时出现就相当于即把实现移交给子类又把实现移交给本地操作系统,那到底谁来实现具体方法就是个问题了。
对于 synchronized 来说同步是需要有具体操作才能同步的,如果像 abstract 只有方法声明,则同步就不知道该同步什么了。
内部类
静态内部类是
1.定义在另一个类里面用 static 修饰 class 的类,
2.内部类不需要依赖于外部类(与类的静态成员属性类似)且无法使用其外部类的非 static 属性或方法(因为在没有外部类对象的情况下可以直接创建静态内部类的对象,如果允许访问外部类的非 static 属性或者方法就会产生矛盾)。
成员内部类
1.是没有用 static 修饰且定义在在外部类类体中的类,是最普通的内部类,可以看做是外部类的成员,可以无条件访问外部类的所有成员属性和成员方法(包括 private 成员和静态成员),而外部类无法直接访问成员内部类的成员和属性,要想访问必须得先创建一个成员内部类的对象然后通过指向这个对象的引用来访问;
2.当成员内部类拥有和外部类同名的成员变量或者方法时会发生隐藏现象(即默认情况下访问的是成员内部类的成员,如果要访问外部类的同名成员需要通过 OutClass.this.XXX 形式访问);成员内部类的 class 前面可以有 private 等修饰符存在。
方法内部类(局部内部类)
1.是定义在一个方法里面的类,和成员内部类的区别在于方法内部类的访问仅限于方法内;
2.方法内部类就像是方法里面的一个局部变量一样,所以其类 class 前面是不能有 public、protected、private、static 修饰符的,也不可以在此方法外对其实例化使用。
匿名内部类
1.是一种没有构造器的类(实质是继承类或实现接口的子类匿名对象),
2.由于没有构造器所以匿名内部类的使用范围非常有限,大部分匿名内部类用于接口回调,匿名内部类在编译的时候由系统自动起名为 OutClass$1.class,一般匿名内部类用于继承其他类或实现接口且不需要增加额外方法的场景(只是对继承方法的实现或是重写);匿名内部类的 class 前面不能有 pravite 等修饰符和 static 修饰符;匿名内部类访问外部类的成员属性时外部类的成员属性需要添加 final 修饰(1.8 开始可以不用)。
静态变量和**实例变量的区别**
\1. 实例变量必须创建了对象才能分配内存和使用,其属于对象;静态变量编译期分配内存,通过类名调用,其属于类
\2. 静态变量所有对象共享一个,实例变量每个对象都有
内部类的分类
在Java中,可以将一个类定义在另一个类里面或者一个方法里边,这样的类称为内部类,广泛意义上的内部类一般包括四种:成员内部类,局部内部类,匿名内部类,静态内部类 。
1.成员内部类
(1)该类像是外部类的一个成员,可以无条件的访问外部类的所有成员属性和成员方法(包括private成员和静态成员);
(2)成员内部类拥有与外部类同名的成员变量时,使用就近原则。如果要访问外部类中的成员,需要:【外部类.this.成员变量 或 外部类.this.成员方法】;
(3)在外部类中如果要访问成员内部类的成员,必须先创建一个成员内部类的对象,再通过指向这个对象的引用来访问;
(4)成员内部类是依附外部类而存在的,也就是说,如果要创建成员内部类的对象,前提是必须存在一个外部类的对象;
(5)内部类可以拥有private访问权限、protected访问权限、public访问权限及包访问权限。如果成员内部类用private修饰,则只能在外部类的内部访问;如果用public修饰,则任何地方都能访问;如果用protected修饰,则只能在同一个包下或者继承外部类的情况下访问;如果是默认访问权限,则只能在同一个包下访问。外部类只能被public和包访问两种权限修饰。
2.局部内部类
(1)局部内部类是定义在一个方法或者一个作用域里面的类,它和成员内部类的区别在于局部内部类的访问仅限于方法内或者该作用域内;
(2)局部内部类就像是方法里面的一个局部变量一样,是不能有public、protected、private以及static修饰符的。
3.匿名内部类
(1)一般使用匿名内部类的方法来编写事件监听代码;
(2)匿名内部类是不能有访问修饰符和static修饰符的;
(3)匿名内部类是唯一一种没有构造器的类;
(4)匿名内部类用于继承其他类或是实现接口,并不需要增加额外的方法,只是对继承方法的实现或是重写。
匿名内部类的创建格式为: new 父类构造器(参数列表)|实现接口(){
//匿名内部类的类体实现
}
1、使用匿名内部类时,我们必须是继承一个类或者实现一个接口,但是两者不可兼得,同时也只能继承一个类或者实现一个接口。
2、匿名内部类中是不能定义构造函数的。
3、匿名内部类中不能存在任何的静态成员变量和静态方法。
4、匿名内部类为局部内部类,所以局部内部类的所有限制同样对匿名内部类生效。
5、匿名内部类不能是抽象的,它必须要实现继承的类或者实现的接口的所有抽象方法。
4.内部静态类
(1)静态内部类是不需要依赖于外部类的,这点和类的静态成员属性有点类似;
(2)不能使用外部类的非static成员变量或者方法。
外部类修饰符
-
public(访问控制符),将一个类声明为公共类,它可以被任何对象访问,一个程序的主类必须是公共类。
-
default(访问控制符),类只对包内可见,包外不可见。
-
abstract(非访问控制符),将一个类声明为抽象类,抽象类不能用来实例化对象,声明抽象类的唯一目的是为了将来对该类进行扩充,抽象类可以包含抽象方法和非抽象方法。。
-
final(非访问控制符),将一个类生命为最终(即非继承类),表示它不能被其他类继承。
注意:
1.protected 和 private 不能修饰外部类,是因为外部类放在包中,只有两种可能,包可见和包不可见。
-
final 和 abstract不能同时修饰外部类,因为该类要么能被继承要么不能被继承,二者只能选其一。
3.不能用static修饰类,因为类加载后才会加载静态成员变量。所以不能用static修饰类和接口,因为类还没加载,无法使用static关键字。
内部类修饰符
内部类与成员变量地位一直,所以可以public,protected、default和private,同时还可以用static修饰,表示嵌套内部类,不用实例化外部类,即可调用。
方法修饰符
-
public(公共控制符),包外包内都可以调用该方法。
-
protected(保护访问控制符)指定该方法可以被它的类和子类进行访问。
-
default(默认权限),指定该方法只对同包可见,对不同包(含不同包的子类)不可见。
-
private(私有控制符)指定此方法只能有自己类等方法访问,其他的类不能访问(包括子类),非常严格的控制。
-
final ,指定方法已完备,不能再进行继承扩充。
-
static,指定不需要实例化就可以激活的一个方法,即在内存中只有一份,通过类名即可调用。
-
synchronize,同步修饰符,在多个线程中,该修饰符用于在运行前,对它所属的方法加锁,以防止其他线程的访问,运行结束后解锁。
-
native,本地修饰符。指定此方法的方法体是用其他语言在程序外部编写的。
-
abstract ,抽象方法是一种没有任何实现的方法,该方法的的具体实现由子类提供。抽象方法不能被声明成 final 和 static。 任何继承抽象类的子类必须实现父类的所有抽象方法,除非该子类也是抽象类。 如果一个类包含若干个抽象方法,那么该类必须声明为抽象类。抽象类可以不包含抽象方法。 抽象方法的声明以分号结尾,例如:public abstract sample();。
运算符:
1>逻辑运算符:
&:运算符两边只要有一个false,结果肯定是false;只有两边都是true,结果才是true。
|:或,运算符两边只要有一个true,结果就是true;只有两边结果都是false结果才是false。
^:异或,两边结果不同,结果为true,两边结果相同为false。
!:true<->false。
&&:短路与,结果与单&相同,但:
&:无论左边的运算结果是什么,右边都参与运算。
&&:当左边为false时,右边不再参与运算。
||:短路或,结果与单|相同,但:
|:无论左边的运算结果是什么,右边都参与运算。
||:当左边为true时,右边不再参与运算。
逻辑运算符的位运算:0假,1真
例:6&3=110&011=010=2
1>和1的与运算可以截取有效位(如后四位,或者前四位),
2>一个数异或同一个数两次还是这个数(可用于数据的加密解密)。
还可以用于实现两个数的交换:(可不使用第三方变量)
a=a^b;
b=a^b;
a=a^b;//但阅读性差,编程时还是使用第三方变量
3> ~数 取反
2>移位运算符(用于数值的二进制)(位运算最为高效)
<<:左移运算符:例:3<<2 3的二进制左移两位 (左移后左边溢出位不管右边空位补0,数值上左移几位就是该数乘以2的几次方,可以完成2的幂次方运算)
>>:右移运算符:(右移时最右边新出现的空位与原始最高位保持相同,数值上等于除以2的幂次方)
>>>:无符号右移:数据进行移位时,最高位出现的空位,无论符号位是什么总用0补。
三目运算符:的应用:获取两个数中较大的那个 if-else的简化格式
Int a,b;
Int max = (a>b)?a:b;
当if-else运算后有一个具体结果时可以用三目运算符简写;
二、容器
容器都有哪些
Java的容器从继承关系分为两个大类,分别是Collection接口和Map接口,实现类的种类有list,set,map。具体实现有arraylist,linkedlist,Vector,Stack,hashset,TreeSet ,LinkedSet ,Hashtable ,HashMap
Collection
-----List
-----LinkedList 非同步
----ArrayList 非同步,实现了可变大小的元素数组
----Vector 同步
-----Set 不允许有相同的元素
Map
-----HashTable 同步,实现一个key--value映射的哈希表,key和value都不允许出现null值
-----HashMap 非同步,
-----WeakHashMap 改进的HashMap,实现了“弱引用”,如果一个key不被引用,则被GC回收
注:
List接口中的对象按一定顺序排列,允许重复 Set接口中的对象没有顺序,但是不允许重复 Map接口中的对象是key、value的映射关系,key不允许重复
Sort函数
1.sort排序的内部实现原理:
首先会判断需要排序的数据量是否大于47?
小于的话使用 插入排序,因为插入排序是稳定的。
大于47的数据量会根据数据的基本类型选择排序方式:
如果是基本数据类型:会使用快排,因为基本数据类型,1,2,3都是指向同一个常量池
如果是Object类型的话:会使用归并排序,因为归并排序具有稳定性。
但是不管是快排还是归并排序,在二分的时候小于47的数据量依旧会进行插入排序。
2.Java API针对集合类型类型的排序提供了两种支持:
collection.sort(List):要求要排序的元素必须实现一个Comparable接口。
collection.sort(List,Compartor):要求实现一个Comparator接口。
这两个接口不但可以用于集合元素的排序也可以用于数组元素的排序。
3.Comparator
是一个接口,可重写compareTo,用于比较的功能;
compare(a,b)方法:根据第一个参数小于、等于、大于第二个参数分别返回负整数、0、正整数
-
Collections.sort(list,new priceComparator)
第二个参数返回一个int型的值,就相当于一个标志,告诉sort方法按什么顺序来对list进行排序。
3.通过查看源码我们可以发现collection.sort的实现是list.sort,而list.sort的实现是Array.sort->TimSort.sort->binarySort,这才是排序的实现,通过调用构造器的.compare方法进行真正的判断
fail-fast
1.“快速失败”也就是fail-fast,它是Java集合的一种错误检测机制。某个线程在对collection进行迭代时,不允许其他线程对该collection进行结构上的修改。
2.例如:假设存在两个线程(线程1、线程2),线程1通过Iterator在遍历集合A中的元素,在某个时候线程2修改了集合A的结构),那么这个时候程序就会抛出 ConcurrentModificationException 异常,从而产生fail-fast。
3.迭代器的快速失败行为无法得到保证,它不能保证一定会出现该错误,因此, 异常仅用于检测 bug。
4.Java.util包中的所有集合类都是快速失败的,而java.util.concurrent包中的集合类都是安全失败的;快速失败的迭代器抛出ConcurrentModificationException,而安全失败的迭代器从不抛出这个异常。
原理
1.产生fail-fast事件,是通过抛出ConcurrentModificationException异常来触发的
2.ConcurrentModificationException是在操作Iterator时抛出的异常。
3.通过查看源码,可以发现在调用 next() 和 remove()时,都会执行 checkForComodification()。若 “modCount 不等于 expectedModCount”,则抛出ConcurrentModificationException异常,产生fail-fast事件。
举个例子:
(01) 新建了一个ArrayList,名称为arrayList。
(02) 向arrayList中添加内容。
(03) 新建一个“线程a”,并在“线程a”中通过Iterator反复的读取arrayList的值。
(04) 新建一个“线程b”,在“线程b”中删除arrayList中的一个“节点A”。
(05) 这时,就会产生有趣的事件了。
在某一时刻,“线程a”创建了arrayList的Iterator。expectedModCount = modCount(假设它们此时的值为N)。此时“节点A”仍然存在于arrayList中,
在“线程a”在遍历arrayList过程中的某一时刻,“线程b”执行了,并且“线程b”删除了arrayList中的“节点A”。“线程b”执行remove()进行删除操作时,在remove()中执行了“modCount++”,此时modCount变成了N+1!
“线程a”接着遍历,当它执行到next()函数时,调用checkForComodification()比较“expectedModCount”和“modCount”的大小;而“expectedModCount=N”,“modCount=N+1”,这样,便抛出ConcurrentModificationException异常,产生fail-fast事件。
fail-fast解决办法
fail-fast机制,是一种错误检测机制。它只能被用来检测错误,因为JDK并不保证fail-fast机制一定会发生。若在多线程环境下使用fail-fast机制的集合,建议使用“java.util.concurrent包下的类”去取代“java.util包下的类”。
将ArrayList替换为CopyOnWriteArrayList则可以解决该办法。
4. 总结
1.由于HashMap(ArrayList)并不是线程安全的,因此如果在使用迭代器的过程中有其他线程修改了map,那么将要抛出ConcurrentModificationException 即为fail-fast策略
2.主要通过modCount域来实现,保证线程之间的可见性,modCount即为修改次数,对于HashMap内容的修改就会增加这个值, 那么在迭代器的初始化过程中就会将这个值赋值给迭代器的expectedModCount
3.但是fail-fast行为并不能保证,因此依赖于此异常的程序的做法是错误的
使用 for-each 时调用 List 的 remove 方法元素会抛出 ConcurrentModificationException 异常?
Java 提供了一个 Iterable 接口返回一个迭代器,常用的List
通过上面的源码发现迭代操作中都有判断 modCount!=expectedModCount 的操作,在 ArrayList 中 modCount 是当前集合的版本号,每次修改(增、删)集合都会加 1,expectedModCount 是当前迭代器的版本号,在迭代器实例化时初始化为 modCount=n,所以当调用 ArrayList.add() 或 ArrayList.remove() 时只是更新了 modCount n+1 的状态,而迭代器中的 expectedModCount 未修改,因此才会导致再次调用 Iterator.next() 方法时抛出 ConcurrentModificationException 异常。而使用 Iterator.remove() 方法没有问题,因为 Iterator 的 remove() 方法中有同步 expectedModCount 值,所以当下次再调用 next() 时检查不会抛出异常。这其实是一种快速失败机制,机制的规则就是当多个线程对 Collection 进行操作时若其中某一个线程通过 Iterator 遍历集合时该集合的内容被其他线程所改变,则抛出 ConcurrentModificationException 异常。
因此在使用 Iterator 遍历操作集合时应该保证在遍历集合的过程中不会对集合产生结构上的修改,如果在遍历过程中需要修改集合元素则一定要使用迭代器提供的修改方法而不是集合自身的修改方法,此外 feor-each 循环遍历的实质是迭代器,使用迭代器的 remove() 方法前必须先调用迭代器的 next() 方法且不允许调用一次 next() 方法后调用多次 remove() 方法。
Collection 和 Collections 的区别
Collection是一个最基本的集合接口,其中定义了一些容器的基本操作的接口,可以使子类依照自身情况来具体实现。而Collections是一个对容器进行操作的类,在 collection 上进行操作或返回 collection 的静态方法组成。比如利用它的方法可以对Collection进行查找,排序等。
List、Set、Map 之间的区别
List:元素有序,可重复。 ArrayList:数组。特点:有索引(脚标),所以查找快,增删后每个元素的索引都发生改变,所以增删慢,而且数组越长增删越慢 LinkedList:链表。特点:无索引,每个元素都包含下一元素地址,查找需要逐一进行,所以查找慢,但是增删快只需要改变元素后面的地址。 Vector:线程同步数组 基本抛弃使用。 Set:元素无序,不重复,无索引。 HashSet:哈希表。特点:线程非同步,保证元素唯一性原理:判断hashCode是个屁相同,洗过相同在判断equals方法是否为true。 TreeSet:二叉树。特点:可对用两种方法对集合中元素排序,1.实现comparable接口,覆盖compareTo方法。2.集合建立时规定,并自定义比较类。 Map:双列集合,用于存放键值对。键值是唯一的,不可重复
AbstractMap 根据名字 抽象Map 只听说过抽象类吧 所以AbstractMap是一个类 不是接口 下面这个摘录自jdk1.8中文版: public abstract class AbstractMap
HashSet 去重**原理的认识?**
答:HashSet 在存元素时会调用对象的 hashCode 方法计算出存储索引位置,如果其索引位置已经存在元素(哈希碰撞)则和该索引位置上所有的元素进行 equals 比较,如果该位置没有其他元素或者比较的结果都为 false 就存进去,否则就不存。所以可以看见元素是按照哈希值来找位置的,故而无序且可以保证无重复元素,因此我们在往 HashSet 集合中存储元素时,元素对象应该正确重写 Object 类的 hashCode 和 equals 方法,否则会出现不可预知的错误。
LinkedList 工作原理和实现?
答:LinkedList 是以双向链表实现,链表无容量限制,其内部主要成员为 first 和 last 两个 Node 节点, LinkedList 不仅仅实现了 List 接口,还实现了 Deque 双端队列接口,故 LinkedList 自动具备双端队列的特性,当我们使用下标方式调用列表的 get(index)、set(index, e) 方法时需要遍历链表将指针移动到位进行访问(会判断 index 是否大于链表长度的一半决定是首部遍历还是尾部遍历,访问的复杂度为 O(N/2)),无法像 ArrayList 那样进行随机访问。(如果i>数组大小的一半,会从末尾移起),只有在链表两头的操作(譬如 add()、addFirst()、removeLast())才不需要进行遍历寻找定位。
Vector
Vector 是线程安全的动态数组,同 ArrayList 一样继承自 AbstractList 且实现了 List、RandomAccess、Cloneable、Serializable 接口,内部实现依然基于数组,Vector 与 ArrayList 基本是一致的,唯一不同的是 Vector 是线程安全的,会在可能出现线程安全的方法前面加上 synchronized 关键字,其和 ArrayList 类似,随机访问速度快,插入和移除性能较差(数组原因),支持 null 元素,有顺序,元素可以重复,线程安全。
ArrayList 在默认数组容量10时默认扩展是 1.5 倍,Vector 在 capacityIncrement 大于 0 时扩容 capacityIncrement 大小,否则扩容为原始容量的 2 倍。Vector 属于线程安全级别的,而 ArrayList 是非线程安全的。
因为 Vector 实现并发安全的原理是在每个操作方法上加锁,这些锁并不是必须要的,在实际开发中一般都是通过锁一系列的操作来实现线程安全,也就是说将需要同步的资源放一起加锁来保证线程安全,如果多个 Thread 并发执行一个已经加锁的方法,但是在该方法中又有 Vector 的存在,Vector 本身实现中已经加锁了,双重锁会造成额外的开销,即 Vector 同 ArrayList 一样有 fail-fast 问题(即无法保证遍历安全),所以在遍历 Vector 操作时又得额外加锁保证安全,还不如直接用 ArrayList 加锁性能好
hashMap原理
Hashmap的底层实现原理:首先他的底层的数据结构是基于数组+链表实现的。这是hashmap1.7及其之前的。在1.8中引入了红黑树。
下来就是重点说说他对与数据的存取过程。首先他存一个是一个键值对。调用get方法时:他首先会计算key的hashode值,然后调用hash函数方法进行高位运算,得到他的哈数值,进行indexFor方法的调用,确定他在数组的具体位置,具体实现是hash值与上数组长度-1。在put时他首先会判断,在计算出来的那个数组下表位置处有没有元素的存在,如果没有就插入,如果有的话,也就是出现hash冲突,那么就以该数组结点作为头结点,遍历后面的元素。如果出现key相同的话,那么进行对应此key的value的修改,返回旧值。如果遍历结果没有key相同的话,就会进行头插。
下来就是说在插入的过程中可能会设计扩容的问题,就是hashmap实际存储的元素值大于最大的阈值,最大的阈值 = hashmap的初始容量 * 负载因子。一般情况下初始容量是16,负载因子是0.75,当然这个是可以变得。当出现这种情况,会把原来的数组长度变为员来的2倍。然后重进行key的hash计算,放到正确的位置上。
1.8在此基础进行了几点优化。1.就是在插入元素>8的时候,后面的链表会转化为红黑树
\2. 下来就是在进行高位运算的时候,处于对时间效率性能的考虑,1.7中计算hash值很复杂,进行三次异或运算,在1.8中只进行一次 异或运算,异或上hash值 异或hash无符号右移16位。
\3. 就是在扩容的时候,1.7要重新计算元素的hash值,1.8进行优化,优化的结果是比如 原先的很多元素在数组下表为5的位置,那么扩容后,这些元素要么在原位置,要么在原位置上+原先数组长度的位置上,极大提高的扩容效率。下来就是还有几个细节的地方,在put的时候,存在一个标志位onlyifAbsent,在插入时,如果存在相同的key,如果这个标志位是false进行覆盖,如果为true则不能进行覆盖。
再说他的get方法。在他进行get的时候,还是会进行hash运算和indexfor 的高位取模运算,确定他在数组中的下标位置,进行读取。
扩容机制
扩容(resize)就是重新计算容量,向HashMap对象里不停的添加元素,而HashMap对象内部的数组无法装载更多的元素时,对象就需要扩大数组的长度,以便能装入更多的元素。当然Java里的数组是无法自动扩容的,方法是使用一个新的数组代替已有的容量小的数组
l 扩容为之前的2倍。
就是使用一个容量更大的数组来代替已有的容量小的数组,transfer()方法将原有Entry数组的元素拷贝到新的Entry数组里。我们使用的是2次幂的扩展(指长度扩为原来2倍),所以,元素的位置要么是在原位置,要么是在原位置再移动2次幂的位置。
元素在重新计算hash之后,因为n变为2倍,那么n-1的mask范围在高位多1bit(红色),
因此,我们在扩充HashMap的时候,不需要像JDK1.7的实现那样重新计算hash,只需要看看原来的hash值新增的那个bit是1还是0就好了,是0的话索引没变,是1的话索引变成“原索引+oldCap”。
既省去了重新计算hash值的时间,而且同时,由于新增的1bit是0还是1可以认为是随机的,因此resize的过程,均匀的把之前的冲突的节点分散到新的bucket了。这一块就是JDK1.8新增的优化点。有一点注意区别,JDK1.7中rehash的时候,旧链表迁移新链表的时候,如果在新表的数组索引位置相同,则链表元素会倒置,但是从上图可以看出,JDK1.8不会倒置。
装载因子为什么是0.75
HshpMap的遍历
//第一种
Map map = new HashMap();
Iterator iter = map.entrySet().iterator();
while (iter.hasNext()) {
Map.Entry entry = (Map.Entry) iter.next();
Object key = entry.getKey();
Object val = entry.getValue();
}
//第二种
Map map = new HashMap();
Iterator iter = map.keySet().iterator();
while (iter.hasNext()) {
Object key = iter.next();
Object val = map.get(key);
}
第一种方式效率高且推荐用。
因为 HashMap 的这两种遍历是分别对 keySet 和 entrySet 进行迭代,对于 keySet 实质上是遍历了两次,一次是转为 iterator 迭代器遍历,一次就从 HashMap 中取出 key 所对于的 value 操作(通过 key 值 hashCode 和 equals 索引);而 entrySet 方式只遍历了一次,它把 key 和 value 都放到了 Entry 中,所以效率高。
HashMap**死循环问题**
答:对于 JDK1.7 和 JDK1.8 的 HashMap 中迭代器的 fail-fast 策略导致了并发不安全,即如果在使用迭代器的过程中有其他线程修改了 HashMap 就会抛出 ConcurrentModificationException 异常(fail-fast 策略)
JDK1.8 的 HashMap 并发 put 操作不会导致潜在的死循环。对于 JDK1.7 来说哈希冲突的链表结构在扩容前后会进行一次逆向首尾对调操作,而对于 JDK1.8 来说扩容前后链表顺序性不变,
对于 JDK1.8 中扩容链表的顺序是不会发生逆向的,所以自然怎么遍历都不会出现循环链表的情况,故 JDK1.8 中不会出现并发循环链表,但由于 JDK1.7 与 JDK1.8 中都是无锁保护的,所以依然是并发不安全的。
我们知道ConcurrentHashMap对整个桶数组进行了分割分段(Segment),然后在每一个分段上都用lock锁进行保护,相对于HashTable的syn关键字锁的粒度更精细了一些,并发性能更好,而HashMap没有锁机制,不是线程安全的。
H**ashMap的初始化长度为什么是16?为什么是以2的n次幂进行扩容。**
h:为插入元素的hashcode
length:为map的容量大小
&:与操作 比如 1101 & 1011=1001
如果length为2的次幂 则length-1 转化为二进制必定是11111……的形式,在于h的二进制与操作效率会非常的快,
而且空间不浪费;如果length不是2的次幂,比如length为15,则length-1为14,对应的二进制为1110,在于h与操作,
最后一位都为0,而0001,0011,0101,1001,1011,0111,1101这几个位置永远都不能存放元素了,空间浪费相当大,更糟的是这种情况中,数组可以使用的位置比数组长度小了很多,这意味着进一步增加了碰撞的几率,减慢了查询的效率!这样就会造成空间的浪费
HashMap在1.8后新特性
1.Entry改为Node
2.拉链链表超过8个元素,改用红黑树
3.在扩容时,不用重新计算结点的索引值,要么在原位置,要么在原位置上在移动2次幂的位置。
5.就是在进行高位运算时,从效率 速度 性能上进行优化 无符号右移16位。JDK1.8的实现中,优化了高位运算的算法,通过hashCode()的高16位异或低16位实现的:(h = k.hashCode()) ^ (h >>> 16),主要是从速度、功效、质量来考虑的,这么做可以在数组table的length比较小的时候,也能保证考虑到高低Bit都参与到Hash的计算中
HasHashMap和HashSet区别
i. HashSet里面的HashMap所有的value都是同一个Object
ii. HashSet实现了Set接口,HashMap实现了Map接口
iii. HashSet使用add()方法增添对象,HashMap使用put()方法增添对象
iv. HashSet使用元素进行hashcode,Hash使用key进行hashcode
HashSet存储对象,HashMap存储键值对
HashMap和Hashtable的区别:
(1)HashMap是Hashtable的轻量级实现,它们都实现了Map接口,主要区别在于HashMap允许空(null)键值(key),而Hashtalbe不允许。
(2)HashMap没有contains方法,而是containsValue和containsKey。
(3)Hashtable的方法是线程安全的,而HashMap不是线程安全的。
(4)HashMap使用Iterator,Hashtable使用Enumeration。
(5)HashMap和Hashtable采用的hash/rehash算法都几乎一样,所以性能不会有很大的差异。
(6)在Hashtable中,hash数组默认大小是11,增加的方式是old*2+1。在Has和Map中,hash数组的默认大小是16,而且一定是2的倍数。
(7)hash值的使用不同,Hashtable直接使用对象的hashCode。
l HashMap 是非 synchronized 的,而 Hashtable 是 synchronized 的。
l HashMap 可以接受 null 的键和值,而 Hashtable 的 key 与 value 均不能为 null 值。
l 单线程情况下使用 HashMap 性能要比 Hashtable 好,因为 HashMap 是没有同步操作的。
l HashTable 的默认容量为11,而 HashMap 为 16(安卓中为 4)。
l Hashtable 不要求底层数组的容量一定是 2 的整数次幂,而 HashMap 则要求一定为 2 的整数次幂。
l Hashtable 扩容时将容量变为原来的 2 倍加 1,而 HashMap 扩容时将容量变为原来的 2 倍。
l Hashtable 有 contains 方法,而 HashMap 有 containsKey 和 containsValue 方法。
1.hashMap线程不安全,HashTable线程安全 2.HashMap在单线程时性能很好 3.HashMap的key,value都可以是null,但key的null只能有一个;hashtable不能使用null值 4.这两个集合都不能保证元素的存储顺序
HashMap和TreeMap区别
TreeMap的key按自然增加顺序排序,HashMap没有顺序,HashMap速度快.
HashMap 的实现原理
transient修饰的变量不会被序列化
缓存的entrySet
(1)HashMap底层的数据结构是数组+链表形式的,在Jdk1.8以后是数组+链表+红黑树形式的。HashMap中,key值不能重复,只能put一个key为null的值。
(2)HashMap在Put时,经过了两次hash。一个是JDK自带的对对象的hash,然后对结果使用HashMap内部函数的hash(int h);这个函数会根据key的hashCode重新计算一次散列(看一下hash(int h)和indexFor(int h,int length)两个函数的理解。当key值为空的时候,会调用putForNullKey()方法进行值的添加
(3)在put时如果空间不够(小于长度*扩容因子)就会进行一次resize()
(4)HashMap是非线程安全的:
添加元素,删除元素,扩容时均有非线程安全的问题。随便提一种即可,以下简单叙述:
添加元素: 如果两个元素同时hash到同一个位置,这时候会有后面的插入覆盖前面的插入。
扩容: 如果两个插入同时需要扩容,则可能同时新建两个数组,导致数据丢失。
删除元素:
(5)HashMap和HashSet的关系:Set集合的特点是不能存储重复元素,不能保持元素插入时的顺序,且key值最多允许有一个null值。
(6)equals方法的特性:
· 自反性(reflexive)。对于任意不为null的引用值x,x.equals(x)一定是true
· 对称性(symmetric)。对于任意不为null的引用值x和y,当且仅当x.equals(y)是true时y.equals(x)也是true
· 传递性(transitive)。对于任意不为null的引用值x、y和z,如果x.equals(y)是true,同时y.equals(z)是true,那么x.equals(z)一定是true
· 一致性(consistent)。对于任意不为null的引用值x和y,如果用于equals比较的对象信息没有被修改的话,多次调用时x.equals(y)要么一致地返回true要么一致地返回false
(7)HashMap与HashSet的区别?HashSet的底层实现。
(8)ConcurrentModificationException异常发生的原因?
(9)高并发:在并发的多线程使用场景中,在resize扩容的时候,使得HashMap形成环链,造成死循环,CPU飙升至100%
(10)resize步骤:http://blog.csdn.net/qq_27093465/article/details/52270519
(11)HashMap为什么采用2的幂次方扩容
hashMap在单线程中使用大大提高效率,在多线程的情况下使用hashTable来确保安全。hashTable中使用synchronized关键字来实现安全机制,但是synchronized是对整张hash表进行锁定即让线程独享整张hash表,在安全同时造成了浪费。concurrentHashMap采用分段加锁的机制来确保安全
LinkedHashMap:
LinkedHashMap实现与HashMap的不同之处在于,后者维护着一个运行于所有条目的双重链接列表。此链接列表定义了迭代顺序,该迭代顺序可 以是插入顺序或者是访问顺序。最好画个图解释下。Entry对象在HashMap的时候包含key,value,hash值,以及一个next;而在LinkedHashMap中新增了before和after。
HashMap在1.8后新特性
1.Entry改为Node
2.拉链链表超过8个元素,改用红黑树
3.在扩容时,不用重新计算结点的索引值,要么在原位置,要么在原位置上在移动2次幂的位置。
5.就是在进行高位运算时,从效率 速度 性能上进行优化 无符号右移16位。JDK1.8的实现中,优化了高位运算的算法,通过hashCode()的高16位异或低16位实现的:(h = k.hashCode()) ^ (h >>> 16),主要是从速度、功效、质量来考虑的,这么做可以在数组table的length比较小的时候,也能保证考虑到高低Bit都参与到Hash的计算中
ConcurrentHashMap底层数据结构
1. JDK1.7
jdk1.7采用Sement+entry数组方式实现
\1. 它引入了一个“分段锁”的概念,在ConcurrentHashMap中,就是把Map分成了N个Segment(默认16个),put和get的时候,都是现根据key.hashCode()算出放到哪个Segment中。
\2. 其中Segment在实现上继承了ReentrantLock,这样就自带了锁的功能。
与HashMap不同的是,ConcurrentHashMap并不允许key或者value为null
\3. 主要使用Segment来实现减小锁粒度,把HashMap分割成若干个Segment,在put的时候需要锁住Segment,get时候不加锁,使用volatile来保证可见性
put**方法实现**
当执行put方法插入时,根据hashcode找到segment中的位置,如果segment相应位置还没有初始化,则使用CAS赋值,接着执行加锁的put方法。
若A、B两个线程同时插入:
1. 线程A执行tryLock获取到锁,把HashEntry对象插入到相应位置
2. 线程B获取锁失败,则执行scanAndLockForPut()方法,方法中,会通过重复执行tryLock()方法尝试获取锁,当执行次数达到上限(多处理器64次,单处理器1次),会执行lock方法挂起。
3. 线程A执行完毕插入操作,会执行unlock释放锁,然后唤醒线程B继续执行。
size方法**实现**
因为ConcurrentHashMap可以并发插入,所以在准确的计算元素数量有一定难度,因为在统计元素个数时,前面已经计算过的segment同时可能会有数据的插入和删除。
jdk1.7解决办法是:
先采用不加锁方式计算两次个数,如果容器count数量发生了变化,则再采用加锁的方式来统计所有segment的大小。
那么如何判断统计期间容器是否发生了变化?因为在put、remove、clean方法里操作元素都会将变量modCount加1,那么在统计完size前后比较modCount是否发生了变化,从而得知容器是否发生了变化
2. JDK1.8
JDK1.8摒弃了segment臃肿的设计,取而代之的是node+CAS+synchronized设计
Node’数组延迟加载,只有第一次调用put方法才会初始化node数组。
put实现
当执行put方法,根据key的hash值找到node数组相应位置,具体如下:
\1. 如果相应node还未初始化,则调用CAS操作插入相应数据。
\2. 如果相应位置node不为空,则加上synchronized,并遍历链表更新或插入节点。
\3. 若节点是TreeBin类型,说明是红黑树结构,则往红黑树中插入节点
\4. 当链表节点数达到8个,则转化为红黑树
\5. 若插入一个新节点,则执行addCount()方法尝试更新元素个数baseCount
size**实现**
使用volitile修饰的变量baseCount记录元素个数。当插入删除数据,都会更新basecount
24.说一下 HashSet 的实现原理?
List的继承体系:
(1)List的直接实现是两个抽象类,AbstactList和AbstractSequentialList.其中,AbstractList为随即访问(如数组)实现方案提供尽可能的封装 ,AbstractSequentialList为连续访问(如链表)实现方案提供了尽可能的封装。ArrayList,直接父类是AbstractList,数据结构是大小可变的数组, 它不是同步的。LinkedList,直接父类是AbstractSquentialList,数据结构是双向链表,它不是同步的,它同时实现了Deque(双向队列)和Queue(队 列)接口。同时它还提供了push和pop这两个堆栈操作的接口。Vector,直接父类是AbstractList,特性和ArrayList一样,只是它是线程同步的。Stack ,直接父类是Vector,实现堆栈这种数据结构。
(2)通过对象的equals方法。
25.ArrayList 和 LinkedList 的区别是什么?
ArrayList 采用的是数组形式来保存对象的,这种方式将对象放在连续的位置中,所以最大的缺点就是插入删除时非常麻烦 LinkedList 采用的将对象存放在独立的空间中,而且在每个空间中还保存下一个链接的索引 但是缺点就是查找非常麻烦 要丛第一个索引开始
(1) ArrayList是实现了基于动态数组的数据结构,LinkedList基于双向循环链表的数据结构。
(2) 对于随机访问get和set,ArrayList觉得优于LinkedList,因为LinkedList要移动指针。
(3) 对于新增和删除操作add和remove,LinedList比较占优势,因为ArrayList要移动数据。
(4) 查找操作indexOf,lastIndexOf,contains等,两者差不多。
(5) 随机查找指定节点的操作get,ArrayList速度要快于LinkedList. 当操作是在一列数据的后面添加数据而不是在前面或中间,并且需要随机地访问其中的元素时,使用ArrayList会提供比较好的性能;当你的操作是在 一列数据的前面或中间添加或删除数据,并且按照顺序访问其中的元素时,就应该使用LinkedList了。
扩容: 针对ArrayList,在新增的时候,容量不够就需要扩容,2倍。
数组和 List 之间的转换
List转数组:toArray(arraylist.size()方法 数组转List:Arrays的asList(a)方法
ArrayList 和 Vector
1.Vector的方法都是同步的(Synchronized),是线程安全的(thread-safe),而ArrayList的方法不是,由于线程的同步必然要影响性能,因此,ArrayList的性能比Vector好。 2.扩容机制:Vector会将它的容量翻倍,而ArrayList只增加50%的大小,ArrayList就有利于节约内存空间。
Array 和 ArrayList 有何区别?
数组:可以存储对象和基本数据类型,长度固定。 而集合(单列),用于存储对象、不能存储基本数据类型(int,char等),但可以存储基本数据类型包装类(int-Integer,char-Character等),长度可变。而且封装了一些操作方法。
Queue 中 poll()和 remove()的区别
remove():获取并移除此队列的头。此方法与 poll 唯一的不同在于:此队列为空时将抛出一个异常。 poll():获取并移除此队列的头,如果此队列为空,则返回 null。
线程安全的集合类
Vector:就比Arraylist多了个同步化机制(线程安全)。 Hashtable:就比Hashmap多了个线程安全。 ConcurrentHashMap:是一种高效但是线程安全的集合。 Stack:栈,也是线程安全的,继承于Vector。
迭代器 Iterator
迭代器是一种设计模式,它是一个对象,它可以遍历并选择序列中的对象,而开发人员不需要了解该序列的底层结构。迭代器通常被称为“轻量级”对象,因为创建它的代价小。 Java中的Iterator功能比较简单,并且只能单向移动: (1)使用方法iterator()要求容器返回一个Iterator。第一次调用Iterator的next()方法时,它返回序列的第一个元素。注意:iterator()方法是java.lang.Iterable接口,被Collection继承。 (2) 使用next()获得序列中的下一个元素。 (3) 使用hasNext()检查序列中是否还有元素。 (4) 使用remove()将迭代器新返回的元素删除。 Iterator是Java迭代器最简单的实现,为List设计的ListIterator具有更多的功能,它可以从两个方向遍历List,也可以从List中插入和删除元素。
32.Iterator 怎么使用?有什么特点?
33.Iterator 和 ListIterator 有什么区别?
主要区别在以下方面:
-
ListIterator有add()方法,可以向List中添加对象,而Iterator不能 2.ListIterator和Iterator都有hasNext()和next()方法,可以实现顺序向后遍历,但是ListIterator有hasPrevious()和previous()方法,可以实现逆向(顺序向前)遍历。Iterator就不可以。
-
ListIterator可以定位当前的索引位置,nextIndex()和previousIndex()可以实现。Iterator没有此功能。
-
都可实现删除对象,但是ListIterator可以实现对象的修改,set()方法可以实现。Iierator仅能遍历,不能修改。
34.怎么确保一个集合不能被修改?
map = Collections.unmodifiableMap(map);
分析:上述map是域安全,被初始化之后,不能被修改了。 补充(利用Collections和Guava提供的类可实现的不可变对象): Collections.unmodifiableXXX:Collection、List、Set、Map...
Guava:ImmutableXXX:Collection、List、Set、Map...
队列:
LinkedBlockingQueue是一个基于节点链接的可选是否有界的阻塞队列,不允许null值。 LinkedBlockingQueue是一个线程安全的阻塞队列,实现了先进先出等特性。 PriorityQueue是一个无界队列,不允许null值,入队和出队的时间复杂度是O(log(n))。 PriorityQueue是不同于先进先出队列的另一种队列。每次从队列中取出的是具有最高优先权的元素。ConcurrentLinkedQueue是一个基于链接节点的无界线程安全队列,该队列的元素遵循FIFO原则。
1、LinkedBlockingQueue:基于链接节点的可选限定的blocking queue 。 这个队列排列元素FIFO(先进先出)。 队列的头部是队列中最长的元素。 队列的尾部是队列中最短时间的元素。 新元素插入队列的尾部,队列检索操作获取队列头部的元素。 链接队列通常具有比基于阵列的队列更高的吞吐量,但在大多数并发应用程序中的可预测性能较低。
blocking queue说明:不接受null元素;可能是容量有限的;实现被设计为主要用于生产者 - 消费者队列;不支持任何类型的“关闭”或“关闭”操作,表示不再添加项目实现是线程安全的;
2、PriorityQueue:
2.1、基于优先级堆的无限优先级queue 。 优先级队列的元素根据它们的有序natural ordering ,或由一个Comparator在队列构造的时候提供,这取决于所使用的构造方法。 优先队列不允许null元素。 依靠自然排序的优先级队列也不允许插入不可比较的对象(这样做可能导致ClassCastException )。
2.2、该队列的头部是相对于指定顺序的最小元素。 如果多个元素被绑定到最小值,那么头就是这些元素之一 - 关系被任意破坏。 队列检索操作poll , remove , peek和element访问在队列的头部的元件。
2.3、优先级队列是无限制的,但是具有管理用于在队列上存储元素的数组的大小的内部容量 。 它始终至少与队列大小一样大。 当元素被添加到优先级队列中时,其容量会自动增长。 没有规定增长政策的细节。
2.4、该类及其迭代器实现Collection和Iterator接口的所有可选方法。 方法iterator()中提供的迭代器不能保证以任何特定顺序遍历优先级队列的元素。 如果需要有序遍历,请考虑使用Arrays.sort(pq.toArray()) 。
2.5、请注意,此实现不同步。 如果任何线程修改队列,多线程不应同时访问PriorityQueue实例。 而是使用线程安全的PriorityBlockingQueue类。
实现注意事项:此实现提供了O(log(n))的时间入队和出队方法( offer , poll , remove()和add ); remove(Object)和contains(Object)方法的线性时间; 和恒定时间检索方法( peek , element和size )。
3、ConcurrentLinkedQueue:基于链接节点的无界并发deque(deque是双端队列) 。 并发插入,删除和访问操作可以跨多个线程安全执行。 A ConcurrentLinkedDeque是许多线程将共享对公共集合的访问的适当选择。像大多数其他并发集合实现一样,此类不允许使用null元素。
copyonwrite集合
CopyOnWrite机制介绍
CopyOnWrite容器是 写时复制的容器,就是我们往容器里写东西时,不是直接写,而是先Copy当前容器,然后往新容器里添加元素,在将原容器的引用指向新容器。这样做的好处是:可以并发的读,而不需要加锁,因为当前容器不会添加任何元素。CopyOnWrite容器是一种读写分离的思想。 应用场景:应用于读多写少的并发场景, 注意:减少扩容开销;使用批量添加(减少复制次数); 缺点:内存占用问题;数据一致性问题(CopyOnWrite机制只能保证最终的数据一致,不能保证实时数据一致,因此如果希望写入的数据能马上读到,就不应该用CopyOnWrite);
\1. CopyOnWriteArrayList中的add、set、remove等方法,都是用了ReentrantLock的lock()来加锁,unlock()来解锁。 当增加元素扩容时使用Array.copyOf()来拷贝副本,在副本上增加元素,然后改变原引用指向副本,读操作不加锁。适合读操作远远多于写操作的应用。
\2. CopyOnWriteArraySet是在CopyOnWriteArrayList的基础上使用了Java的装饰模式。 List和Set的区别同样适用于CopyOnWriteArrayList和CopyOnWriteArrayList。
数组
在java 中,声明一个数组时,不能直接限定数组长度,只有在创建实例化对象时,才能对给定数组长度.。
Java一维数组有两种初始化方法 1、静态初始化
int array[] = new int[]{1,2,3,4,5}或者
int array[] = {1,2,3,4,5}需要注意的是,写成如下形式也是错误的
int array[] = new int[5]{1,2,3,4,5}2、动态初始化
int array[] = new int[5];
array[0] = 1;
array[1] = 2;
array[2] = 3;
array[3] = 4;
array[4] = 5;静态与动态初始化的区别就在于,前者是声明的时候就初始化,后者是先声明,再动态初始化。
数组:
\1. 定义一维数组时,必须显式指明数组的长度;
\2. 定义多维数组时,其一维数组的长度必须首先指明,其他维数组长度可以稍后指定;
\3. 采用给定值初始化数组时,不必指明长度;
\4. “[]” 是数组运算符的意思,在声明一个数组时,数组运算符可以放在数据类型与变量之间,也可以放在变量之后。
Hash冲突:
基于哈希算法在信息安全中主要应用在?
(1) 文件校验
(2) 数字签名
(3) 鉴权协议
银行家算法用在预防死锁策略中
解决哈希冲突常用的两种方法是:开放定址法和链地址法
has**h冲突的解决办法**
hash冲突的解决办法有
\1. 开放定址法
a) 线性探测再散列
b) 平方探测再散列
c) 随机探测再散列
\2. 拉链法
将所有hash冲突的的记录都存到一个链表里
\3. 再哈希法
再次计算另一个哈希值,直到不冲突
\4. 建立公共溢出区
将冲突的都放在另一个地方,不放在表里
链地址法:将所有关键字为同义词的结点链接在同一个单链表中。若选定的散列表长度为m,则可将散列表定义为一个由m个头指针组成的指针数 组T[0..m-1]。凡是散列地址为i的结点,均插入到以T[i]为头指针的单链表中。T中各分量的初值均应为空指针。
ConcurrentHashMap底层数据结构
1. JDK1.7
jdk1.7采用Sement+entry数组方式实现
\1. 它引入了一个“分段锁”的概念,在ConcurrentHashMap中,就是把Map分成了N个Segment(默认16个),put和get的时候,都是现根据key.hashCode()算出放到哪个Segment中。
\2. 其中Segment在实现上继承了ReentrantLock,这样就自带了锁的功能。
与HashMap不同的是,ConcurrentHashMap并不允许key或者value为null
\3. 主要使用Segment来实现减小锁粒度,把HashMap分割成若干个Segment,在put的时候需要锁住Segment,get时候不加锁,使用volatile来保证可见
put**方法实现**
当执行put方法插入时,根据hashcode找到segment中的位置,如果segment相应位置还没有初始化,则使用CAS赋值,接着执行加锁的put方法。
若A、B两个线程同时插入:
1. 线程A执行tryLock获取到锁,把HashEntry对象插入到相应位置
2. 线程B获取锁失败,则执行scanAndLockForPut()方法,方法中,会通过重复执行tryLock()方法尝试获取锁,当执行次数达到上限(多处理器64次,单处理器1次),会执行lock方法挂起。
3. 线程A执行完毕插入操作,会执行unlock释放锁,然后唤醒线程B继续执行。
size方法**实现**
因为ConcurrentHashMap可以并发插入,所以在准确的计算元素数量有一定难度,因为在统计元素个数时,前面已经计算过的segment同时可能会有数据的插入和删除。
jdk1.7解决办法是:
先采用不加锁方式计算两次个数,如果容器count数量发生了变化,则再采用加锁的方式来统计所有segment的大小。
那么如何判断统计期间容器是否发生了变化?因为在put、remove、clean方法里操作元素都会将变量modCount加1,那么在统计完size前后比较modCount是否发生了变化,从而得知容器是否发生了变化
2. JDK1.8
JDK1.8摒弃了segment臃肿的设计,取而代之的是node+CAS+synchronized设计
Node’数组延迟加载,只有第一次调用put方法才会初始化node数组。
put实现
当执行put方法,根据key的hash值找到node数组相应位置,具体如下:
\1. 如果相应node还未初始化,则调用CAS操作插入相应数据。
\2. 如果相应位置node不为空,则加上synchronized,并遍历链表更新或插入节点。
\3. 若节点是TreeBin类型,说明是红黑树结构,则往红黑树中插入节点
\4. 当链表节点数达到8个,则转化为红黑树
\5. 若插入一个新节点,则执行addCount()方法尝试更新元素个数baseCount
size**实现**
使用volitile修饰的变量baseCount记录元素个数。当插入删除数据,都会更新basecount
copyonwrite集合
CopyOnWrite机制介绍 CopyOnWrite容器是 写时复制的容器,就是我们往容器里写东西时,不是直接写,而是先Copy当前容器,然后往新容器里添加元素,在将原容器的引用指向新容器。这样做的好处是:可以并发的读,而不需要加锁,因为当前容器不会添加任何元素。CopyOnWrite容器是一种读写分离的思想。 应用场景:应用于读多写少的并发场景, 注意:减少扩容开销;使用批量添加(减少复制次数); 缺点:内存占用问题;数据一致性问题(CopyOnWrite机制只能保证最终的数据一致,不能保证实时数据一致,因此如果希望写入的数据能马上读到,就不应该用CopyOnWrite);
\1. CopyOnWriteArrayList中的add、set、remove等方法,都是用了ReentrantLock的lock()来加锁,unlock()来解锁。 当增加元素扩容时使用Array.copyOf()来拷贝副本,在副本上增加元素,然后改变原引用指向副本,读操作不加锁。适合读操作远远多于写操作的应用。
\2. CopyOnWriteArraySet是在CopyOnWriteArrayList的基础上使用了Java的装饰模式。 List和Set的区别同样适用于CopyOnWriteArrayList和CopyOnWriteArrayList。
copyonwrite集合
CopyOnWrite机制介绍 CopyOnWrite容器是 写时复制的容器,就是我们往容器里写东西时,不是直接写,而是先Copy当前容器,然后往新容器里添加元素,在将原容器的引用指向新容器。这样做的好处是:可以并发的读,而不需要加锁,因为当前容器不会添加任何元素。CopyOnWrite容器是一种读写分离的思想。 应用场景:应用于读多写少的并发场景, 注意:减少扩容开销;使用批量添加(减少复制次数); 缺点:内存占用问题;数据一致性问题(CopyOnWrite机制只能保证最终的数据一致,不能保证实时数据一致,因此如果希望写入的数据能马上读到,就不应该用CopyOnWrite);
\1. CopyOnWriteArrayList中的add、set、remove等方法,都是用了ReentrantLock的lock()来加锁,unlock()来解锁。 当增加元素扩容时使用Array.copyOf()来拷贝副本,在副本上增加元素,然后改变原引用指向副本,读操作不加锁。适合读操作远远多于写操作的应用。
\2. CopyOnWriteArraySet是在CopyOnWriteArrayList的基础上使用了Java的装饰模式。 List和Set的区别同样适用于CopyOnWriteArrayList和CopyOnWriteArrayList。
三、多线程
多进程与多线程:
多进程:操作系统能同时运行多个任务;
多线程:同一程序中有多个顺序流在执行多线程(充满未知性)多线程就是分时利用CPU,宏观上让所有线程一起执行 ,也叫并发。
一个进程(程序)运行时产生不止一个线程
并行与并发:
1.并行:多个cpu实例或者多台机器同时执行一段处理逻辑,是真正的同时。
2.并发:通过cpu调度算法,让用户看上去同时执行,实际上从cpu操作层面不是真正的同时。并发往往在场景中有公用的资源,那么针对这个公用的资源往往产生瓶颈,我们会用TPS或者QPS来反应这个系统的处理能力。
同步和异步的区别:
异步:A线程要请求某个资源,但是此资源正在被B线程使用中,因为没有同步机制存在,A线程仍然请求的到,A线程无需等待
同步:A线程要请求某个资源,但是此资源正在被B线程使用中,因为同步机制存在,A线程请求不到,怎么办,A线程只能等待下去
线程和进程的区别
主观上讲:就是说我们运行一个浏览器,一个QQ,其实就相当于开启了一个进程,在任务管理器中中可以看到QQ.exe这个进程,然后我们使用QQ的时候,可以进行QQ语音聊天,可以QQ听歌,这些其实就相当于一个个的线程。他的存在依赖于一个进程。
进程和线程的关系
联系:
(1)一个线程只能属于一个进程,而一个进程可以有多个线程,但至少有一个线程。
(2)资源分配给进程,同一进程的所有线程共享该进程的所有资源。
(3)处理机分给线程,即真正在处理机上运行的是线程。
(4)线程在执行过程中,需要协作同步。不同进程的线程间要利用消息通信的办法实现同步。线程是指进程内的一个执行单元,也是进程内的可调度实体.
区别:
(1)调度:线程作为调度和分配的基本单位,进程作为拥有资源的基本单位
(2)并发性:不仅进程之间可以并发执行,同一个进程的多个线程之间也可并发执行
(3)拥有资源:进程是拥有资源的一个独立单位,线程不拥有系统资源,但可以访问隶属于进程的资源.
(4)系统开销:在创建或撤消进程时,由于系统都要为之分配和回收资源,导致系统的开销明显大于创建或撤消线程时的开销。
线程和进程的区别
进程是系统进行资源分配和调度的基本单位,而线程是CPU调度和分配的基本单位,一个线程可以创建和撤销另一个线程
1.一个程序至少要有一个进程,一个进程至少要有一个线程; 2.线程的还分尺度小于进程,使得多个线程程序的并发性高; 3.进程在执行过程中有独立的内存单元,而多个线程共享内存,从而极大地提高了程序的运行效率; 4.线程在执行过程中与进程还是有区别的,每个独立的线程有一个程序运行的入口,顺序执行序列和程序的出口。但是线程不能够独立的执行,必须依赖于应用程序中,由应用程序提供多个线程执行控制。
保证高并发场景的线程安全衡量的四个维度:
数据单线程内可见;
只读对象;
线程安全类;
同步与锁机制;
多线程的使用场景
多线程最多的场景:web服务器本身;各种专用服务器(如游戏服务器); 多线程的常见应用场景: 1、后台任务,例如:定时向大量(100w以上)的用户发送邮件; 2、异步处理,例如:发微博、记录日志等; 3、分布式计算
1.最典型的应用比如tomcat,tomcat内部采用的就是多线程,上百个客户端访问同一个web应用,
tomcat接入后都是把后续的处理扔给一个线程池中的线程来处理,这个新的线程最后调用到我们的
servlet程序,比如doGet或者doPost方法。
如果不采用多线程机制,上百个人同时访问一个web应用的时候,tomcat就得排队串行处理了,那样客
户端根本是无法忍受那种访问速度的。
2.还有就是需要异步处理的时候,需要使用多线程。比如task a和task b要并行处理,单个线程只能
串行处理,先做完task a然后再做task b。如果想要多个task同时执行的话,就必须为每个task分配一
个线程,然后通过java虚拟机的线程调度,来同时执行多个任务。看起来是同步的话,只是cpu切换的
快。
进程与线程:
进程:每个进程都有独立的代码和数据空间(进程上下文)进程之间的切换会有较大开销,一个进程包含1-n个线程。(进程不能实现任何实际操作,要依靠线程)
当一个程序进入内存运行时,即变成一个进程。进程是处于运行过程中的程序。 进程是操作系统进行资源分配和调度的一个独立单位。
进程的三个特征:
1.独立性:独立存在的实体,每个进程都有自己独立私有的一块内存空间。
2.动态性:程序只是一个静态的指令集合,而进程是一个正在系统中活动的指令集合。
3.并发性:多个进程可在单处理器上并发执行。
线程:同一类线程共享代码和数据空间,每个线程有独立的运行栈和程序计数器(pc),线程切换开销小。 线程是操作系统能够进行运算调度的最小单位,它被包含在进程之中,是进程中的实际运作单位。线程也被称作轻量级进程。线程在进程中是独立,并发的执行流。
线程状态
创建,就绪,运行,阻塞,死亡
线程的生命周期及**转换图**
| NEW | 初始状态,线程被构建,但是还没有执行start()方法 |
|---|---|
| RUNNABLE | 运行状态,Java线程将操作系统中的就绪和运行状态笼统称为“运行中” |
| BLOKCED | 阻塞状态,线程阻塞于锁 sleep yied jion wait io |
| WAITING | 等待状态,线程需要其他线程做出一些特定动作(通知或中断) |
| TIME_WAITING | 超时等待状态,不同于WAITING,线程可在指定时间自行返回 |
| TERMINATED | 中止状态,当前线程已经执行完毕 |
(新建状态(New),就绪状态(Runnable),运行状态(Running),阻塞状态(Blocked),死亡状态(Dead))
创建:当线程对象对创建后,即进入了新建状态,如:Thread t = new MyThread();
就绪:当调用线程对象的start()方法(t.start();)(定时器例外调用:),线程即进入就绪状态。处于就绪状态的线程,只是说明此线程已经做好了准备,随时等待CPU调度执行,并不是说执行了t.start()此线程立即就会执行;
运行:当CPU开始调度处于就绪状态的线程时,此时线程才得以真正执行,即进入到运行状态。注:就绪状态是进入到运行状态的唯一入口,也就是说,线程要想进入运行状态执行,首先必须处于就绪状态中;
阻塞:(发生异常)处于运行状态中的线程由于某种原因,暂时放弃对CPU的使用权,停止执行,此时进入阻塞状态,阻塞解除时,重新进入到就绪状态,才有机会再次被CPU调用以进入到运行状态。根据阻塞产生的原因不同,阻塞状态又可以分为三种:
1.等待阻塞:运行状态中的线程执行wait()方法(必须加同步锁),jvm会将该线程放入锁池中,使本线程进入到等待阻塞状态;
2.同步阻塞 -- 线程在获取synchronized同步锁失败(因为锁被其它线程所占用),jvm会将该线程放入锁池中,进入同步阻塞状态;
3.其他阻塞 -- 通过调用线程的sleep()或join()或发出了I/O请求时,线程会进入到阻塞状态。当sleep()状态超时、join()等待线程终止或者超时、或者I/O处理完毕时,线程重新转入就绪状态。
终止:线程执正常行完了或者因异常退出了run()方法,该线程结束生命周期。线程终止后,不能被复活。
Java内存模型:原子性+可见性+重排序
(4)happens-before,即**先行发生原则,定义了操作A必然先行发生于操作B的一些规则,**
比如在同一个线程内控制流前面的代码一定先行发生于控制流后面的代码、
一个释放锁unlock的动作一定先行发生于后面对于同一个锁进行锁定lock的动作等等,只要符合这些规则,则不需要额外做同步措施,如果某段代码不符合所有的happens-before规则,则这段代码一定是线程非安全的
进程的区
“进程的区”属于操作系统里面的
一条进程的栈区、堆区、数据区和代码区在内存中的映射 1>栈区:主要用来存放局部变量, 传递参数, 存放函数的返回地址。.esp 始终指向栈顶, 栈中的数据越多, esp的值越小。 2>堆区:用于存放动态分配的对象, 当你使用 malloc和new 等进行分配时,所得到的空间就在堆中。动态分配得到的内存区域附带有分配信息, 所以你 能够 free和delete它们。 3>数据区:全局,静态和常量是分配在数据区中的,数据区包括bss(未初始化数据区)和初始化数据区。 注意: 1)堆向高内存地址生长; 2)栈向低内存地址生长; 3)堆和栈相向而生,堆和栈之间有个临界点,称为stkbrk。
1、一条进程在内存中的映射 假设现在有一个程序,它的函数调用顺序如下: main(...) ->; func_1(...) ->; func_2(...) ->; func_3(...),即:主函数main调用函数func_1; 函数func_1调用函数func_2; 函数func_2调用函数func_3。 当一个程序被操作系统调入内存运行, 其对应的进程在内存中的映射如下图所示:
创建线程方式
1.实现Runnable接口,重写run()方法; 2.继承Thread类 3.实现Callable接口和Future接口创建线程。Callable实现call()方法,并使用FutureTask类来包装Callable实现类的对象
runnable 和 callable 的区别
runnable:无返回值,callable有返回值
继承Thread类 其实这个Thread类自身也实现了Runnable接口,他们之间具有多态的关系。因为java是单继承,为了支持多继承,实现了接口,一边继承一边实现。
\1. 子类覆盖父类中的run方法,将线程运行的代码存放在run中。
\2. 建立子类对象的同时线程也被创建。
\3. 通过调用start方法开启线程。
实现Runnable接口
\1. 子类覆盖接口中的run方法。
\2. 通过Thread类创建线程,并将实现了Runnable接口的子类对象作为参数传递给Thread类的构造函数。
实现Callable
Runnable接口中的run()方法的返回值是void,它做的事情只是纯粹地去执行run()方法中的代码而已;Callable接口中的call()方法是有返回值的,是一个泛型,和Future、FutureTask配合可以用来获取**异步执行的结果。**
这其实是很有用的一个特性,因为多线程相比单线程更难、更复杂的一个重要原因就是因为多线程充满着未知性,某条线程是否执行了?某条线程执行了多久?某条线程执行的时候我们期望的数据是否已经赋值完毕?无法得知,我们能做的只是等待这条多线程的任务执行完毕而已。而Callable+Future/FutureTask却可以获取多线程运行的结果,可以在等待时间太长没获取到需要的数据的情况下取消该线程的任务,真的是非常有用。
FutureTask表示一个异步运算的任务。FutureTask里面可以传入一个Callable的具体实现类,可以对这个异步运算的任务的结果进行等待获取、判断是否已经完成、取消任务等操作。当然,由于FutureTask也是Runnable接口的实现类
多线程情况下成员变量保证线程安全
内存的管理策略:
为什么会有内存管理策略:是为了 同时将多个进程保存在内存中 以便允许多道程序设计,这些策略都以下的共同点:
\1. 一次性:作业一次性全部装入到内存当中,才能开始执行,但是这样的话会导致两种两种情况的发生:
(1) 当作业很大时,不能被全部装入内存时,将使该作业无法运行。
(2) 当大量作业要求运行时,由于内存不足,emmm就是当内存不足以容纳所有作业时,只有少数作业先运行,导致多道程序度的下降。
\2. 驻留性:就是说程序被装入到内存后,就一直驻留在内存中,其任何部分都不会被换出,知道作业运行结束。出现的问题是:
(1) 运行中的进程,会因为等待io而被阻塞,可能处于长期等待状态。
\3. 出现虚拟内存的原因:
内存的管理策略,存在很多问题。许多在程序运行中 不用或者暂时不用的程序 占据可大量的内存空间,而一些需要运行的作业又无法装入运行,显然浪费了宝贵的内存资源。所以促进了虚拟内存的出现。
虚拟内存:
1.我理解的 :虚拟内存技术实际就是:建立了“内存--外存”的两极存储器的结构,利用局部性原理实现高速缓存。
局部性原理:
他主要表现在两个方面,一个是时间一个是空间。
\1. 时间局部性:就是说如果程序中的某条指令一旦执行,不就以后该指令再被执行的可能性更大;如果某条数据被访问过,不久之后这条数据在被访问的几率也更大。产生时间局部性的原因就是:由于程序中可能存在大量的循环操作。
\2. 空间局部性:就是说一旦程序访问了某个存储单元后,在不久之后,他附近的相邻的存储单元也会被访问到的可能会跟大;这主要是因为程序在一段时间内访问的地址,可能都集中在一定的范围之内,下来说就是指令通常是顺序存放顺序执行的,数据也一般是以数组、向量的形式聚簇存储的。
进程的通信
管对信息socket共享
1)管道(pipe)及有名管道(named pipe):管道可用于具有亲缘关系的父子进程间的通信,有名管道除了具有管道所具有的功能外,它还允许无亲缘关系进程间的通信。
(2)信号(signal):信号是在软件层次上对中断机制的一种模拟,它是比较复杂的通信方式,用于通知进程有某事件发生,一个进程收到一个信号与处理器收到一个中断请求效果上可以说是一致的。
(3)消息队列(message queue):消息队列是消息的链接表,它克服了上两种通信方式中信号量有限的缺点,具有写权限得进程可以按照一定得规则向消息队列中添加新信息;对消息队列有读权限得进程则可以从消息队列中读取信息。
(4)共享内存(shared memory):可以说这是最有用的进程间通信方式。它使得多个进程可以访问同一块内存空间,不同进程可以及时看到对方进程中对共享内存中数据得更新。这种方式需要依靠某种同步操作,如互斥锁和信号量等。
(5)信号量:主要作为进程之间及同一种进程的不同线程之间得同步和互斥手段。
(6)套接字(socket):这是一种更为一般得进程间通信机制,它可用于网络中不同机器之间的进程间通信,应用非常广泛。
五种通讯方式总结
1.管道:速度慢,容量有限,只有父子进程能通讯
2.FIFO:任何进程间都能通讯,但速度慢
3.消息队列:容量受到系统限制,且要注意第一次读的时候,要考虑上一次没有读完数据的问题
4.信号量:不能传递复杂消息,只能用来同步
5.共享内存区:能够很容易控制容量,速度快,但要保持同步,比如一个进程在写的时候,另一个进程要注意读写的问题,相当于线程中的线程安全,当然,共享内存区同样可以用作线程间通讯,不过没这个必要,线程间本来就已经共享了同一进程内的一块内存
BIO、NIO和AIO的区别
Java BIO : 同步并阻塞,客户端有连接请求时服务器端就需要启动一个线程进行处理,如果这个连接不做任何事情会造成不必要的线程开销,当然可以通过线程池机制改善。
Java NIO : 同步非阻塞,客户端发送的连接请求都会注册到多路复用器上,多路复用器轮询到连接有I/O请求时才启动一个线程进行处理。
Java AIO: 异步非阻塞,服务器实现模式为一个有效请求一个线程,客户端的I/O请求都是由OS先完成了再通知服务器应用去启动线程进行处理。
NIO比BIO的改善之处是把一些无效的连接挡在了启动线程之前,减少了这部分资源的浪费(因为我们都知道每创建一个线程,就要为这个线程分配一定的内存空间)
AIO比NIO的进一步改善之处是将一些暂时可能无效的请求挡在了启动线程之前,比如在NIO的处理方式中,当一个请求来的话,开启线程进行处理,但这个请求所需要的资源还没有就绪,此时必须等待后端的应用资源,这时线程就被阻塞了。
适用场景分析:
BIO方式适用于连接数目比较小且固定的架构,这种方式对服务器资源要求比较高,并发局限于应用中,JDK1.4以前的唯一选择,但程序直观简单易理解,如之前在Apache中使用。
NIO方式适用于连接数目多且连接比较短(轻操作)的架构,比如聊天服务器,并发局限于应用中,编程比较复杂,JDK1.4开始支持,如在 Nginx,Netty中使用。
AIO方式使用于连接数目多且连接比较长(重操作)的架构,比如相册服务器,充分调用OS参与并发操作,编程比较复杂,JDK7开始支持,在成长中,Netty曾经使用过,后来放弃。
阻塞与非阻塞
传统的 IO 流都是阻塞式的。也就是说,当一个线程调用 read() 或 write() 时,该线程阻塞,直到有一些数据被读取或写入,该线程在此期间不能执行其他任务。
因此,在完成网络通信进行 IO 操作时,由于线程会阻塞,所以服务器端必须为每个客户端都提供一个独立的线程进行处理,当服务器端需要处理大量客户端时,性能急剧下降。
Java NIO 是非阻塞模式的。当线程从某通道进行读写数据时,若没有数据可用时,该线程可以进行其他任务。线程通常将非阻塞 IO 的空闲时间用于在其他通道上执行 IO 操作,所以单独的线程可以管理多个输入和输出通道。因此,NIO 可以让服务器端使用一个或有限几个线程来同时处理连接到服务器端的所有客户端。
同步与异步
如果调用方需要保持等待 直到IO操作完成进而通过返回 获得结果,则是同步的;如果调用方在IO操作的执行过程中不需要保持等待,而是在操作完成后被动的接受(通过消息或回调)被调用方推送的结果,则是异步的。
选择器Selectors
选择器(Selector) 是 SelectableChannle 对象的多路复用器,Selector 可以同时监控多个 SelectableChannel 的 IO 状况,也就是说,利用 Selector 可使一个单独的线程管理多个 Channel。Selector 是非阻塞 IO 的核心.使用单个线程来处理多个channel相对于多线程来处理多个通道的好处显而易见;节省了开辟新线程和不同的线程之间切换的开销。
两个关键类: Channel和Selector。他们是NIO的核心概念。
可以将Channel比作汽车,selector比作车辆调度系统,他负责每辆车运行状态。Buffer类可以比作车上的座位.
通俗解释
首先创建Selector选择器,创建服务端Channel并绑定到一个Socket对象,并将该通信信道注册到选择器上设置为非阻塞模式。然后就可以调用Selector的selectedKeys方法检查已经注册的所有通信信道是否有事情发生,如有事情发生会返回所有selectionKey,通过这个对象的Channel方法就可以去的这个通信信道的对象,从而读取通信数据Buffer。
通常情况下,一个线程以阻塞方式专门负责监听客户端连接请求,另一个线程专门负责处理请求,这个处理请求的线程才会真正采用NIO的方式。
让Selector来监控一个集合中的所有的通道,当有的通道数据准备好了以后,就可以直接到这个通道获取数据。当线程2去问该线程时,它会知道告诉我们通道 N 已经准备好了,而不需要线程2去轮询
AIO——异步IO
AIO 最主要的特点就是回调。
NIO 很好用,它解决了阻塞式 IO 的等待问题,但是它的缺点是需要我们去轮询才能得到结果。
而异步 IO 可以解决这个问题,线程只需要初始化一下,提供一个回调方法,然后就可以干其他的事情了。当数据准备好以后,系统会负责调用回调方法。
并行和并发的区别
并发(concurrency)和并行(parallellism) 解释一:并行是指两个或者多个事件在同一时刻发生;而并发是指两个或多个事件在同一时间间隔发生。 解释二:并行是在不同实体上的多个事件,并发是在同一实体上的多个事件。 解释三:在一台处理器上“同时”处理多个任务,在多台处理器上同时处理多个任务。如hadoop分布式集群 所以并发编程的目标是充分的利用处理器的每一个核,以达到最高的处理性能。
守护线程是什么(后台线程)
Daemon线程,一种支持型线程。被用作程序中后台调度以及支持性工作。 在Java中调用Thread.setDaemon(true)可设置线程调用线程为守护线程(必须在start函数前设置),isDaemon()判断是否是后台线程;值得注意的是守护线程中的finally块并不会每次执行; jvm的垃圾收集器就是一个后台线程 当非后台线程结束时,程序中至,同时杀死所有后台线程
Java锁分类
-
公平锁/非公平锁
-
可重入锁
-
独享锁/共享锁
-
互斥锁/读写锁
-
乐观锁/悲观锁
-
分段锁
-
偏向锁/轻量级锁/重量级锁
-
自旋锁
上面是很多锁的名词,这些分类并不是全是指锁的状态,有的指锁的特性,有的指锁的设计,下面总结的内容是对每个锁的名词进行一定的解释。
公平锁/非公平锁
公平锁是指多个线程按照申请锁的顺序来获取锁。 非公平锁是指多个线程获取锁的顺序并不是按照申请锁的顺序,有可能后申请的线程比先申请的线程优先获取锁。有可能,会造成优先级反转或者饥饿现象。 对于Java ReentrantLock而言,通过构造函数指定该锁是否是公平锁,默认是非公平锁。非公平锁的优点在于吞吐量比公平锁大。 对于Synchronized而言,也是一种非公平锁。由于其并不像ReentrantLock是通过AQS的来实现线程调度,所以并没有任何办法使其变成公平锁。
可重入锁
可重入锁又名递归锁,是指在同一个线程在外层方法获取锁的时候,在进入内层方法会自动获取锁。说的有点抽象,下面会有一个代码的示例。 对于Java ReentrantLock而言, 他的名字就可以看出是一个可重入锁,其名字是Re entrant Lock重新进入锁。 对于Synchronized而言,也是一个可重入锁。可重入锁的一个好处是可一定程度避免死锁。
synchronized void setA() throws Exception{
Thread.sleep(1000);
setB();
}
synchronized void setB() throws Exception{
Thread.sleep(1000);
}上面的代码就是一个可重入锁的一个特点,如果不是可重入锁的话,setB可能不会被当前线程执行,可能造成死锁。
独享锁/共享锁
独享锁是指该锁一次只能被一个线程所持有。 共享锁是指该锁可被多个线程所持有。
对于Java ReentrantLock而言,其是独享锁。但是对于Lock的另一个实现类ReadWriteLock,其读锁是共享锁,其写锁是独享锁。 读锁的共享锁可保证并发读是非常高效的,读写,写读 ,写写的过程是互斥的。 独享锁与共享锁也是通过AQS来实现的,通过实现不同的方法,来实现独享或者共享。 对于Synchronized而言,当然是独享锁。
互斥锁/读写锁
上面讲的独享锁/共享锁就是一种广义的说法,互斥锁/读写锁就是具体的实现。 互斥锁在Java中的具体实现就是ReentrantLock 读写锁在Java中的具体实现就是ReadWriteLock
乐观锁/悲观锁
乐观锁与悲观锁不是指具体的什么类型的锁,而是指看待并发同步的角度。 悲观锁认为对于同一个数据的并发操作,一定是会发生修改的,哪怕没有修改,也会认为修改。因此对于同一个数据的并发操作,悲观锁采取加锁的形式。悲观的认为,不加锁的并发操作一定会出问题。 乐观锁则认为对于同一个数据的并发操作,是不会发生修改的。在更新数据的时候,会采用尝试更新,不断重新的方式更新数据。乐观的认为,不加锁的并发操作是没有事情的。
从上面的描述我们可以看出,悲观锁适合写操作非常多的场景,乐观锁适合读操作非常多的场景,不加锁会带来大量的性能提升。 悲观锁在Java中的使用,就是利用各种锁。 乐观锁在Java中的使用,是无锁编程,常常采用的是CAS算法,典型的例子就是原子类,通过CAS自旋实现原子操作的更新。
分段锁
分段锁其实是一种锁的设计,并不是具体的一种锁,对于ConcurrentHashMap而言,其并发的实现就是通过分段锁的形式来实现高效的并发操作。 我们以ConcurrentHashMap来说一下分段锁的含义以及设计思想,ConcurrentHashMap中的分段锁称为Segment,它即类似于HashMap(JDK7与JDK8中HashMap的实现)的结构,即内部拥有一个Entry数组,数组中的每个元素又是一个链表;同时又是一个ReentrantLock(Segment继承了ReentrantLock)。 当需要put元素的时候,并不是对整个hashmap进行加锁,而是先通过hashcode来知道他要放在那一个分段中,然后对这个分段进行加锁,所以当多线程put的时候,只要不是放在一个分段中,就实现了真正的并行的插入。 但是,在统计size的时候,可就是获取hashmap全局信息的时候,就需要获取所有的分段锁才能统计。 分段锁的设计目的是细化锁的粒度,当操作不需要更新整个数组的时候,就仅仅针对数组中的一项进行加锁操作。
偏向锁/轻量级锁/重量级锁
这三种锁是指锁的状态,并且是针对Synchronized。在Java 5通过引入锁升级的机制来实现高效Synchronized。这三种锁的状态是通过对象监视器在对象头中的字段来表明的。 偏向锁是指一段同步代码一直被一个线程所访问,那么该线程会自动获取锁。降低获取锁的代价。 轻量级锁是指当锁是偏向锁的时候,被另一个线程所访问,偏向锁就会升级为轻量级锁,其他线程会通过自旋的形式尝试获取锁,不会阻塞,提高性能。 重量级锁是指当锁为轻量级锁的时候,另一个线程虽然是自旋,但自旋不会一直持续下去,当自旋一定次数的时候,还没有获取到锁,就会进入阻塞,该锁膨胀为重量级锁。重量级锁会让其他申请的线程进入阻塞,性能降低。
自旋锁
在Java中,自旋锁是指尝试获取锁的线程不会立即阻塞,而是采用循环的方式去尝试获取锁,这样的好处是减少线程上下文切换的消耗,缺点是循环会消耗CPU。
sleep() 和 wait()
sleep方法属于Thread类中方法,表示让一个线程进入睡眠状态,等待一定的时间之后,自动醒来进入到可运行状态,不会马上进入运行状态,因为线程调度机制恢复线程的运行也需要时间,一个线程对象调用了sleep方法之后,并不会释放他所持有的所有对象锁,所以也就不会影响其他进程对象的运行。但在sleep的过程中过程中有可能被其他对象调用它的interrupt(),产生InterruptedException异常,如果你的程序不捕获这个异常,线程就会异常终止,进入TERMINATED状态,如果你的程序捕获了这个异常,那么程序就会继续执行catch语句块(可能还有finally语句块)以及以后的代码。 注意sleep()方法是一个静态方法,也就是说他只对当前对象有效,通过t.sleep()让t对象进入sleep,这样的做法是错误的,它只会是使当前线程被sleep 而不是t线程 wait属于Object的成员方法,一旦一个对象调用了wait方法,必须要采用notify()和notifyAll()方法唤醒该进程;如果线程拥有某个或某些对象的同步锁,那么在调用了wait()后,这个线程就会释放它持有的所有同步资源,而不限于这个被调用了wait()方法的对象。wait()方法也同样会在wait的过程中有可能被其他对象调用interrupt()方法而产生
1.这两个方法来自不同的类:Thread和Object; 2.对锁的处理不同:sleep方法没有释放锁,wait方法释放了锁,使得其他线程可以使用同步控制块或者方法(锁代码块和方法锁); 3.使用范围不同:wait,notify和notifyAll只能在同步控制方法或者同步控制块(synchronized)里面使用,而sleep可以在任何地方使用 4.sleep必须捕获异常,而wait,notify和notifyAll不需要捕获异常
42.notify()和 notifyAll()有什么区别? notify:唤醒一个沉睡的线程 notifyAll:唤醒所有的 被wait的线程,想要继续运行的话,它必须满足2个条件: 1.由其他线程notify或notifyAll了,并且当前线程被通知到了 2.经过和其他线程进行锁竞争,成功获取到锁了 其实在实现层面,notify和notifyAll都达到相同的效果,都只会有一个线程继续运行。但notifyAll免去了,线程运行完了通知其他线程的必要,因为已经通知过了。
run()和 start()
run:指期待此线程所执行的内容; start:使得此线程进入就绪状态,并不能保证立即执行。
1.启动一个线程的方法是 start()
2.结束线程用的是interrupt()方法,而stop()是强制结束线程,并不推荐使用,同时stop()方法已被弃用
3.daemon线程是守护线程,当主线程结束时,守护线程会自动结束
4.一个线程等待另外一个线程的方法是wait()方法
并发包的主要类族组成:
线程同步类:CoutDownLatch,Semaphore,CyclicBarrier。
并发集合类:ConcurrentHashMap,ConcurrentSkipListMap,CopyOnWriteArrayList,BlockingQueue
线程管理类:线程池
锁相关类:以Lock接口为核心,派生出了大量的锁:ReentrantLock
线程池
使用线程池的优点:
1.降低资源的消耗:重复利用线程,减少线程创建和销毁的消耗。
2.提高响应速度。当任务到达的时候不用等待创建线程就可以立即工作。
3.提高线程的可管理性。
用线程池原因
访问量压力,线程创建资源,创建时间消耗
当用户访问量很大的情况下,不用线程池的话,对于服务器来说,每一个用户的请求都建立一个工作
线程来处理,对于服务器来说压力很大,很大访问量的情况下,可能会造成服务器的崩溃,
另外创建线程要花费昂贵的资源和时间,有时创建一个线程在销毁的时间加在一起可能远远大于这个工
作线程处理这个请求消耗的时间。
如果任务来了才创建线程那么响应时间会变长,而且一个进程能创建的线程数有限。
线程池的好处:通过对多个任务重用线程,其好处是,因为在请求到达时线程已经存在,所以也消除了
线程创建所带来的延迟。这样,就可以立即为请求服务,使应用程序响应更快。而且,通过适当地调整
线程池中的线程数目,也就是当请求的数目超过某个阈值时,就使用饱和策略使请求保持等待,直到获
得一个线程来处理为止,从而可以防止资源不足。
创建线程所要的资源
线程池的处理流程:
当提交一个新任务时,线程池(执行execute方法)的处理流程
1.如果当前运行的线程少于核心线程池(corePoolSize),则创建新线程执行任务(需要全局锁)
2.如果运行的线程等于多于核心线程池(corePoolSize),则将任务加入阻塞队列(BlockingQueue)
3.如果阻塞队列已满,则创建非核心线程来处理任务(需要全局锁)
4.如果创建新线程使得当前运行线程超出maximumPoolSize任务将被拒绝,并调用饱和策略来处理
内部参数,含义
new ThreadPoolExecutor()
1.线程池中核心线程数的最大值:
线程池新建线程的时候,如果当前线程总数小于核心池线程数量,则新建的是核心线程,如果超过核心池线程数量,则新建的是非核心线程。
2.线程池的最大线程的数量: 线程总数 = 核心线程数 + 非核心线程数。
3.阻塞队列:用于保存等待执行的任务,有3种;
a) ArrayBlockingQueue:基于数组的一个阻塞队列FIFO,
这个队列接受到任务之后,如果当前线程小于核心线程数,则新建核心线程处理任务;
如果当前线程等于核心线程数,则进入队列等待。
如果这个队列也满了,则新建非核心线程执行任务,如果线程总数大于线程池最大数量,则发生错误。
b) LinkedBlockingQueue:基于链表的阻塞队列FIFO,
1这个队列接受到任务之后,如果当前线程小于核心线程数,则新建核心线程处理任务;
2如果当前线程等于核心线程数,则进入队列等待。
3由于这个队列没有最大值限制,即超过核心线程数的任务都将添加到队列中,这就导致最大线程池的
设置失效。吞吐量高于上面的
c) SynchronousQueue:一个不存储元素的阻塞队列
D)PriorityBlockingQueue:具有自定义排序优先级
4.饱和策略:当队列和线程池满了,采取策略,默认是AboutPolicy(抛出异常)。
d) AboutPolicy:直接抛出异常
e) CallerRunsPolicy:用调用者所在的线程来运行任务。
f) DiscardOldestPolicy:丢弃队列里最近一个任务,并执行当前任务
g) DiscardPolicy:不处理,丢弃掉
\5. 线程活动保持的时间
\6. 活动保持时间单位
\7. 线程工厂,用来创建线程
如何确定使用哪一种线程池
任务的分类:
CPU密集型(使用线程数量较小的线程池,Ncpu+1)、IO密集型(可配置较多线程2*Ncpu)、混合型(如果可以拆分,尽量拆分为Cpu密集型+IO密集型)
任务的优先级:高、中、低(可以配置阻塞队列为优先级队列priorityBlockQueue)
任务的执行时间:长、中、短
任务的依赖性:是否依赖其他的系统资源,如数据库链接(使用大的有界队列来解决,为什么不使用无界队列呢?我认为加入其他资源发生了故障,就会不断的加入队列,占据大量内存导致系统不可用)。
怎么设计一个线程池
线程池管理类(创建线程 添加客户端请求的新任务 执行任务 回收执行完任务的线程,单例 ) 任务类
队列 工作线程
实现线程池主要包括以下4个基本组成部分:
1)线程池管理类:主要用于实现
\1. 创建线程
\2. 添加客户端请求的新任务,
\3. 执行任务
\4. 如何回收已经执行完任务的线程。线程池管理类的实现采用了单例设计模式,通过单例设计模式可以保证系统中一个类只有一个实例被外
界访问,在线程池管理类中主要有增加任务的方法(addTask)、批量增加任务的方法
(batchAddTask)、得到实例的方法(getInstanse)以及执行任务的方法(execute)
2 任务类的实现
任务类(Task)其实就是一个线程类,它实现了Runnable接口,在run()方法里面可以定义任务要完成
的操作。
3 任务队列的实现
按先来先服务的顺序用于存放新加入的任务,以便让工作线程来执行
4)工作线程类
线程池中的线程,它主要用于处理任务队列中的任务。
工作线程类也是一个线程类,它也实现了Runnable接口,在run()方法里面它首先判断任务队列里面是
否有任务,如果没有就等待新任务加入,如果有任务就从任务队列中取出任务并执行,在线程池中可以
设定工作线程的个数。
线程池种类
| 名称 | 特点: | 创建方法 | |
|---|---|---|---|
| 可缓存线程池 | CachedThreadPool() | 线程数无限制 、有空闲线程则复用空闲线程,若无空闲线程则新建线程、一定程序减少频繁创建/销毁线程,减少系统开销 | ExecutorService cachedThreadPool = Executors.newCachedThreadPool(); |
| 定长线程池 | FixedThreadPool() | 可控制线程最大并发数(同时执行的线程数) 超出的线程会在队列中等待 | ExecutorService fifixedThreadPool = Executors.newFixedThreadPool(int nThreads); |
| 预先安排线程池 | ScheduledThreadPool() | 支持定时及周期性任务执行。 | |
| 单线程化的线程池 | SingleThreadExecutor() | 有且仅有一个工作线程执行任务 、所有任务按照指定顺序执行,即遵循队列的入队出队规则 | ExecutorService singleThreadPool = Executors.newSingleThreadExecutor |
四种:
1.newCachedThreadPool:创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲
线程,若无可回收,则新建线程。
特点:工作线程的创建数量几乎没有限制(其实也有限制的,数目为Interger. MAX_VALUE), 这样可灵活
的往线程池中添加线程。
如果长时间没有往线程池中提交任务,即如果工作线程空闲了指定的时间(默认为1分钟),则该工作线
程将自动终止。终止后,如果你又提交了新的任务,则线程池重新创建一个工作线程。
在使用CachedThreadPool时,一定要注意控制任务的数量,否则,由于大量线程同时运行,很有会
造成系统瘫痪。
2.newFixedThreadPool:创建一个指定工作线程数量的线程池。每当提交一个任务就创建一个工作线
程,如果工作线程数量达到线程池初始的最大数,则将提交的任务存入到池队列中。它具有线程池提高
程序效率和节省创建线程时所耗的开销的优点。但是,在线程池空闲时,即线程池中没有可运行任务
时,它不会释放工作线程,还会占用一定的系统资源。
3.newScheduleThreadPool:创建一个定长的线程池,而且支持定时的以及周期性的任务执行。
4.newSingleThreadExecutor:创建一个单线程化的Executor,即只创建唯一的工作者线程来执行任
务,它只会用唯一的工作线程来执行任务,保证所有任务按照指定顺序(FIFO, ,LIFO,优先级)执行。如
果这个线程异常结束,会有另一个取代它,保证顺序执行。单工作线程最大的特点是可保证顺序地执行
各个任务,并且在任意给定的时间不会有多个线程是活动的。
线程池状态
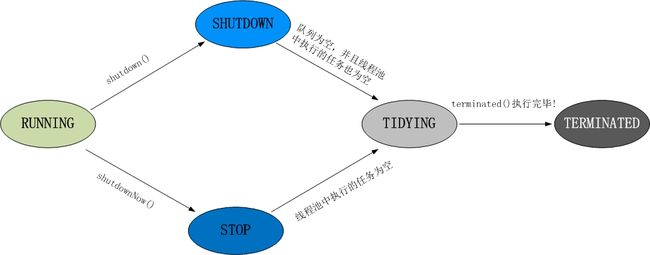
1、RUNNING
(1) 状态说明:线程池处在RUNNING状态时,能够接收新任务,以及对已添加的任务进行处理。 (02) 状态切换:线程池的初始化状态是RUNNING。换句话说,线程池被一旦被创建,就处于RUNNING状态,并且线程池中的任务数为0!
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
2、 SHUTDOWN
(1) 状态说明:线程池处在SHUTDOWN状态时,不接收新任务,但能处理已添加的任务。 (2) 状态切换:调用线程池的shutdown()接口时,线程池由RUNNING -> SHUTDOWN。
3、STOP
(1) 状态说明:线程池处在STOP状态时,不接收新任务,不处理已添加的任务,并且会中断正在处理的任务。 (2) 状态切换:调用线程池的shutdownNow()接口时,线程池由(RUNNING or SHUTDOWN ) -> STOP。
4、TIDYING
(1) 状态说明:当所有的任务已终止,ctl记录的”任务数量”为0,线程池会变为TIDYING状态。当线程池变为TIDYING状态时,会执行钩子函数terminated()。terminated()在ThreadPoolExecutor类中是空的,若用户想在线程池变为TIDYING时,进行相应的处理;可以通过重载terminated()函数来实现。 (2) 状态切换:当线程池在SHUTDOWN状态下,阻塞队列为空并且线程池中执行的任务也为空时,就会由 SHUTDOWN -> TIDYING。 当线程池在STOP状态下,线程池中执行的任务为空时,就会由STOP -> TIDYING。
5、 TERMINATED
(1) 状态说明:线程池彻底终止,就变成TERMINATED状态。 (2) 状态切换:线程池处在TIDYING状态时,执行完terminated()之后,就会由 TIDYING -> TERMINATED。
线程池框架Executor
Executor主要由三部分组成:任务、任务执行、异步计算结果
ThreadPoolExecutor是线程池的核心实现类,用来执行任务的提交。其可以生成:FixedThreadPool、SingleThreadExecutor、CachedThreadPool
ScheduledThreadPoolExecutor是另一个实现类,可以指定延迟后运行命令,或者周期执行命令。
Future和FutureTask表示异步计算的结果。
Runnable和Callable表示可执行的任务。
线程池的 submit()和 execute()
execute:开启线程执行池中的任务。
方法submit:也可以做到,它的功能是提交指定的任务去执行并且返回Future对象,即执行的结果。
两者的三个区别:
1、接收的参数不一样
2、submit有返回值,而execute没有
用到返回值的例子,比如说我有很多个做validation的task,我希望所有的task执行完,然后每个task告诉我它的执行结果,是成功还是失败,如果是失败,原因是什么。 然后我就可以把所有失败的原因综合起来发给调用者。
个人觉得cancel execution这个用处不大,很少有需要去取消执行的。
而最大的用处应该是第二点。 3、submit方便Exception处理 意思就是如果你在你的task里会抛出checked或者unchecked exception, 而你又希望外面的调用者能够感知这些exception并做出及时的处理,那么就需要用到submit,通过捕获Future.get抛出的异常。
有多少种方式保证线程安全
确保线程安全的方法有这几个:竞争与原子操作、同步与锁、可重入、过度优化。
我能想到的有三种方式: 1)原子操作。2)副本。如ThreadLocal、CopyOnWrite等。3)不可变。
锁的升级原理是什么?
原因: 因为Sycronized是重量级锁(也是悲观锁),每次在要进行锁的请求的时候,如果当前资源被其他线程占有要将当前的线程阻塞加入到阻塞队列,然后清空当前线程的缓存,等到锁释放的时候再通过notify或者notifyAll唤醒当前的线程,并让其处于就绪状态。这样线程的来回切换是非常消耗系统资源的,而且有的时候,线程刚挂起资源就释放了。而Java的线程是映射到操作系统的原生线程之上的每次线程的阻塞或者唤醒都要经过用户态到核心态或者核心态到用户态的转化,这样是十分浪费资源的,这样就会造成性能上的降低,因此JVM对Sychronized进行了优化,将Sycronized分为三种锁的级别:偏向锁,轻量级锁,重量级锁。 很多的时候,对于一个可能发生并发访问的对象而言,其实很少会被竞争,就算有些资源存在竞争也是在很少的一段时间资源就会被释放,而这样的情况下将线程挂起是十分浪费性能的。 偏向锁(乐观锁): 当锁对象第一次被线程获取的时候,虚拟机会将锁对象的对象头中的锁标志位设置成为01,并将偏向锁标志设置为1,线程通过CAS的方式将自己的ID值放置到对象头中(因为在这个过程中有可能会有其他线程来竞争锁,所以要通过CAS的方式,一旦有竞争就会升级为轻量级锁了),如果成功线程就获得了该轻量级锁。这样每次再进入该锁对象的时候不用进行任何的同步操作,直接比较当前锁对象的对象头是不是该线程的ID,如果是就可以直接进入。
偏向锁升级为轻量级锁 偏向锁是一种无竞争锁,一旦出现了竞争大多数情况下就会升级为轻量级锁。现在我们假设有线程1持有偏向锁,线程2来竞争偏向锁会经历以下几个过程:
-
首先线程2会先检查偏向锁标记,如果是1,说明当前是偏向锁,那么JVM会找到线程1,看线程1是否还存活着
-
如果线程1已经执行完毕,就是说线程1不存在了(线程1自己是不会去释放偏向锁的),那么先将偏向锁置为0,对象头设置成为无锁的状态,用CAS的方式尝试将线程2的ID放入对象头中,不进行锁升级,还是偏向锁
-
如果线程1还活着,先暂停线程1,将锁标志位变成00(轻量级锁)然后在线程1的栈帧中开辟出一块空间(Display Mark Word)将对象头的Mark Word置换到线程一的栈帧当中,而对象头中此时存储的是指向当前线程栈帧的指针。此时就变成了轻量级锁。继续执行线程1,然后线程2采用CAS的方式尝试获取锁。
轻量级锁与偏向锁最大的不同之处 轻量级锁和偏向锁的不同之处就在于轻量级锁对于获取锁对象采用CAS的同步方式而偏向锁直接是把整个同步过程给取消。
轻量级锁(乐观锁) 轻量级锁如何创建在上面已经讲过了,接下来说说轻量级锁如何获取锁对象,轻量级锁是通过CAS也就是自旋的方式尝试获取锁对象,一旦失败会先检查,对象头中存储的是否是指向当前线程栈帧的指针,如果是,就可以获取对象,如果不是说明存在竞争那么就要膨胀为重量级锁。轻量级锁的解锁也是通过CAS的方式尝试将对象头的Mark Word和线程中的Display Mark Word替换回来,如果成功,就释放锁,如果失败说明还有许多其他等待锁的线程(说明此时已经不是轻量级锁而是重量级锁了),会将这些线程唤醒,然后释放锁。
轻量级锁膨胀为重量级锁
一旦有两条以上的线程竞争锁,轻量级锁膨胀为重量级锁,锁的状态变成10,此时对象头中存储的就是指向重量级锁的栈帧的指针。而且其他等待锁的线程要进入阻塞状态,等待重量级锁释放再来被唤醒然后去竞争。
死锁?
指两个或两个以上的进程在执行过程中,因为争夺资源造成的一种互相等待的现象。若无外力作用下,他们都将无法推进下去。
死锁的四个必要条件: 1.互斥条件:一个资源每次只能被一个进程使用; 2.占有且等待:一个进程因请求资源而阻塞时,对以获取的资源保持不放; 3.不可强行占有:进程以获取的资源,在未使用完成之前,不能强行剥夺; 4.循环等待条件:若干进程之间形成一种首尾相连的循环等待资源关系;
防止死锁?
设置加锁顺序:死锁发生在多个线程需要相同的锁,但是获得不同的顺序。假如一个线程需要锁,那么他必须按照一定得顺序获得锁。
设置加锁时限:在获取锁的时候尝试加一个获取锁的时限,超过时限不需要再获取锁,放弃操作(对锁的请求。) 若一个线程在一定的时间里没有成功的获取到锁,则会进行回退并释放之前获取到的锁,然后等待一段时间后进行重试。在这段等待时间中其他线程有机会尝试获取相同的锁,这样就能保证在没有获取锁的时候继续执行比的事情。
死锁检测:当一个线程获取锁的时候,会在相应的数据结构中记录下来,相同下,如果有线程请求锁,也会在相应的结构中记录下来。当一个线程请求失败时,需要遍历一下这个数据结构检查是否有死锁产生。
ThreadLocal 及其使用场景
ThreadLocal:线程变量,一个以ThreadLocal对象为键,任意对象为值的存储结构。用于保存某个线程共享变量,使其线程之间互不影响;
ThreadLocal在每个线程中对该变量会创建一个副本,即每个线程内部都会有一个该变量,且在线程内部任何地方都可以使用,线程之间互不影响,这样一来就不存在线程安全问题,也不会严重影响程序执行性能。
但是要注意,虽然ThreadLocal能够解决上面说的问题,但是由于在每个线程中都创建了副本,所以要考虑它对资源的消耗,比如内存的占用会比不使用ThreadLocal要大。
一个线程一个变量,而且线程跨越多少个函数,则这个变量也跨越多少个函数。 有一种作用域是线程作用域,线程一般是跨越几个函数的。为了在几个函数之间共用一个变量,所以才出现:线程变量,这种变量在Java中就是ThreadLocal变量。ThreadLocal是跨函数的,虽然全局变量也是跨函数的,但是跨所有的函数,而且不是动态的。 ThreadLocal类是修饰变量的,是在控制它的作用域,是为了增加变量的种类而已,这才是ThreadLocal类诞生的初衷,它的初衷可不是解决线程冲突的。
1)实际的通过ThreadLocal创建的副本是存储在每个线程自己的threadLocals中的;
2)为何threadLocals的类型ThreadLocalMap的键值为ThreadLocal对象,因为每个线程中可有多个threadLocal变量,就像上面代码中的longLocal和stringLocal;
3)在进行get之前,必须先set,否则会报空指针异常;
如果想在get之前不需要调用set就能正常访问的话,必须重写initialValue()方法。
最常见的ThreadLocal使用场景为 用来解决数据库连接、Session管理等。
ThreadLocal应用场景
答:总的来说ThreadLocal主要是解决2种类型的问题:
· 解决并发问题:使用ThreadLocal代替synchronized来保证线程安全。同步机制采用了“以时间换空间”的方式,而ThreadLocal采用了“以空间换时间”的方式。前者仅提供一份变量,让不同的线程排队访问,而后者为每一个线程都提供了一份变量,因此可以同时访问而互不影响。
· 解决数据存储问题:ThreadLocal为变量在每个线程中都创建了一个副本,所以每个线程可以访问自己内部的副本变量,不同线程之间不会互相干扰。如一个Parameter对象的数据需要在多个模块中使用,如果采用参数传递的方式,显然会增加模块之间的耦合性。此时我们可以使用ThreadLocal解决。
应用场景:
Spring使用ThreadLocal解决线程安全问题
l 如一个Parameter对象的数据需要在多个模块中使用,如果采用参数传递的方式,显然会增加模块之间的耦合性。此时我们可以使用ThreadLocal解决。
l 我们知道在一般情况下,只有无状态的Bean才可以在多线程环境下共享,在Spring中,绝大部分Bean都可以声明为singleton作用域。就是因为Spring对一些Bean(如RequestContextHolder、TransactionSynchronizationManager、LocaleContextHolder等)中非线程安全状态采用ThreadLocal进行处理,让它们也成为线程安全的状态,因此有状态的Bean就可以在多线程中共享了。
l 一般的Web应用划分为展现层、服务层和持久层三个层次,在不同的层中编写对应的逻辑,下层通过接口向上层开放功能调用。在一般情况下,从接收请求到返回响应所经过的所有程序调用都同属于一个线程。
ThreadLocal是解决线程安全问题一个很好的思路,它通过为每个线程提供一个独立的变量副本解决了变量并发访问的冲突问题。在很多情况下,ThreadLocal比直接使用synchronized同步机制解决线程安全问题更简单,更方便,且结果程序拥有更高的并发性。
总结
A:ThreadLocal提供线程内部的局部变量,在本线程内随时随地可取,隔离其他线程。
B:ThreadLocal的设计是:每个Thread维护一个ThreadLocalMap哈希表,这个哈希表的key是ThreadLocal实例本身,value才是真正要存储的值Object。
C:对ThreadLocal的常用操作实际是对线程Thread中的ThreadLocalMap进行操作。
D:ThreadLocalMap的底层实现是一个定制的自定义HashMap哈希表,ThreadLocalMap的阈值threshold = 底层哈希表table的长度 len * 2 / 3,当实际存储元素个数size 大于或等于 阈值threshold的 3/4 时size >= threshold*3/4,则对底层哈希表数组table进行扩容操作。
E:ThreadLocalMap中的哈希表Entry[] table存储的核心元素是Entry,存储的key是ThreadLocal实例对象,value是ThreadLocal 对应储存的值value。需要注意的是,此Entry继承了弱引用 WeakReference,所以在使用ThreadLocalMap时,发现key == null,则意味着此key ThreadLocal不在被引用,需要将其从ThreadLocalMap哈希表中移除。
F:ThreadLocalMap使用ThreadLocal的弱引用作为key,如果一个ThreadLocal没有外部强引用来引用它,那么系统 GC 的时候,这个ThreadLocal势必会被回收。所以,在ThreadLocal的get(),set(),remove()的时候都会清除线程ThreadLocalMap里所有key为null的value。如果我们不主动调用上述操作,则会导致内存泄露。
G:为了安全地使用ThreadLocal,必须要像每次使用完锁就解锁一样,在每次使用完ThreadLocal后都要调用remove()来清理无用的Entry。这在操作在使用线程池时尤为重要。
H:ThreadLocal和synchronized的区别:同步机制(synchronized关键字)采用了以“时间换空间”的方式,提供一份变量,让不同的线程排队访问。而ThreadLocal采用了“以空间换时间”的方式,为每一个线程都提供一份变量的副本,从而实现同时访问而互不影响。
I:ThreadLocal主要是解决2种类型的问题:A. 解决并发问题:使用ThreadLocal代替同步机制解决并发问题。B. 解决数据存储问题:如一个Parameter对象的数据需要在多个模块中使用,如果采用参数传递的方式,显然会增加模块之间的耦合性。此时我们可以使用ThreadLocal解决。
ThreadLocal主要用途
答:
\1. ThreadLocal类用来提供线程内部的局部变量。
\2. ThreadLocal实例通常来说都是private static类型的,作用是:ThreadLocal的作用是提供线程内的局部变量,不同的线程之间不会相互干扰,这种变量在线程的生命周期内起作用,减少同一个线程内多个函数或组件之间一些公共变量的传递的复杂度。
上述可以概述为:ThreadLocal提供线程内部的局部变量,在本线程内随时随地可取,隔离其他线程。
ThreadLocal实现原理
· 通常,如果我不去看源代码的话,我猜ThreadLocal是这样子设计的:每个ThreadLocal类都创建一个Map,然后用线程的ID threadID作为Map的key,要存储的局部变量作为Map的value,这样就能达到各个线程的值隔离的效果。这是最简单的设计方法,JDK最早期的ThreadLocal就是这样设计的。
· 但是,JDK后面优化了设计方案,现时JDK8 ThreadLocal的设计是:每个Thread维护一个ThreadLocalMap哈希表,这个哈希表的key是ThreadLocal实例本身,value才是真正要存储的值Object。
· 这个设计与我们一开始说的设计刚好相反,这样设计有如下几点优势:
1) 这样设计之后每个Map存储的Entry数量就会变小,因为之前的存储数量由Thread的数量决定,现在是由ThreadLocal的数量决定。
2) 当Thread销毁之后,对应的ThreadLocalMap也会随之销毁,生命周期与线程相同,能减少内存的使用。
ThreadLocal常用操作的底层实现原理吗?如存储set(T value),获取get(),删除remove()等操作。
3.1 调用get()操作获取ThreadLocal中对应当前线程存储的值时:
1 ) 获取当前线程Thread对象,进而获取此线程对象中维护的ThreadLocalMap对象。
2 ) 判断当前的ThreadLocalMap是否存在:
· 如果存在,则以当前的ThreadLocal 为 key,调用ThreadLocalMap中的getEntry方法获取对应的存储实体 e。找到对应的存储实体 e,获取存储实体 e 对应的 value值,即为我们想要的当前线程对应此ThreadLocal的值,返回结果值。
· 如果不存在,则证明此线程没有维护的ThreadLocalMap对象,调用setInitialValue方法进行初始化。返回setInitialValue初始化的值。
· setInitialValue方法的操作如下:
1 ) 调用initialValue获取初始化的值。
2 ) 获取当前线程Thread对象,进而获取此线程对象中维护的ThreadLocalMap对象。
3 ) 判断当前的ThreadLocalMap是否存在:
· 如果存在,则调用map.set设置此实体entry。
· 如果不存在,则调用createMap进行ThreadLocalMap对象的初始化,并将此实体entry作为第一个值存放至ThreadLocalMap中。
3.2 调用set(T value)操作设置ThreadLocal中对应当前线程要存储的值时,进行了如下操作:
1 ) 获取当前线程Thread对象,进而获取此线程对象中维护的ThreadLocalMap对象。
2 ) 判断当前的ThreadLocalMap是否存在:
如果存在,则调用map.set设置此实体entry。
如果不存在,则调用createMap进行ThreadLocalMap对象的初始化,并将此实体entry作为第一个值存放至ThreadLocalMap中。
ThreadLocalMap的内部底层实现
答:
ThreadLocalMap的底层实现是一个定制的自定义HashMap哈希表,核心组成元素有:
1 ) Entry[] table;:底层哈希表 table, 必要时需要进行扩容,底层哈希表 table.length 长度必须是2的n次方。
其中Entry[] table;哈希表存储的核心元素是Entry,Entry包含:
a) ThreadLocal k;:当前存储的ThreadLocal实例对象
b) Object value;:当前 ThreadLocal 对应储存的值value
2 ) int size;:实际存储键值对元素个数 entries
3 ) int threshold;:下一次扩容时的阈值,阈值 threshold = 底层哈希表table的长度 len * 2 / 3。
当size >= threshold时,遍历table并删除key为null的元素,如果删除后size >=
threshold*3/4时,需要对table进行扩容
需要注意的是,此Entry继承了弱引用 WeakReference,所以在使用ThreadLocalMap时,发现key == null,则意味着此key ThreadLocal不在被引用,需要将其从ThreadLocalMap哈希表中移除
ThreadLocalMap的构造方法是延迟加载的,也就是说,只有当线程需要存储对应的ThreadLocal的值时,才初始化创建一次(仅初始化一次)。初始化步骤如下:
1) 初始化底层数组table的初始容量为 16。
2) 获取ThreadLocal中的threadLocalHashCode,通过threadLocalHashCode & (INITIAL_CAPACITY - 1),即ThreadLocal 的 hash 值 threadLocalHashCode % 哈希表的长度 length 的方式计算该实体的存储位置。
3) 存储当前的实体,key 为 : 当前ThreadLocal value:真正要存储的值
4)设置当前实际存储元素个数 size 为 1
5)设置阈值setThreshold(INITIAL_CAPACITY),为初始化容量 16 的 2/3。
ThreadLocal的get()操作实际是调用ThreadLocalMap的getEntry(ThreadLocal key)方法,此方法快速适用于获取某一存在key的实体 entry
1 ) 计算要获取的entry的存储位置,存储位置计算等价于:ThreadLocal的 hash 值 threadLocalHashCode % 哈希表的长度 length。
2 ) 根据计算的存储位置,获取到对应的实体 Entry。判断对应实体Entry是否存在 并且 key是否相等:
存在对应实体Entry并且对应key相等,即同一ThreadLocal,返回对应的实体Entry。
不存在对应实体Entry 或者 key不相等,则通过调用getEntryAfterMiss(ThreadLocal key, int i, Entry e)方法继续查找。
getEntryAfterMiss(ThreadLocal key, int i, Entry e)方法操作如下:
1 ) 获取底层哈希表数组table,循环遍历对应要查找的实体Entry所关联的位置。
2 ) 获取当前遍历的entry 的 key ThreadLocal,比较key是否一致,一致则返回。
3 ) 如果key不一致 并且 key 为 null,则证明引用已经不存在,这是因为Entry继承的是WeakReference,这是弱引用带来的坑。调用expungeStaleEntry(int staleSlot)方法删除过期的实体Entry。
4 ) key不一致 ,key也不为空,则遍历下一个位置,继续查找。
5 ) 遍历完毕,仍然找不到则返回null。
ThreadLocal的set(T value)操作实际是调用ThreadLocalMap的set(ThreadLocal key, Object value)方法,该方法进行了如下操作:
1 ) 获取对应的底层哈希表table,计算对应threalocal的存储位置。
2 ) 循环遍历table对应该位置的实体,查找对应的threadLocal。
3 ) 获取当前位置的threadLocal,如果key threadLocal一致,则证明找到对应的threadLocal,将新值赋值给找到的当前实体Entry的value中,结束。
4 ) 如果当前位置的key threadLocal不一致,并且key threadLocal为null,则调用replaceStaleEntry(ThreadLocal key, Object value,int staleSlot)方法,替换该位置key == null 的实体为当前要设置的实体,结束。
5 ) 如果当前位置的key threadLocal不一致,并且key threadLocal不为null,则创建新的实体,并存放至当前位置 i tab[i] = new Entry(key, value);,实际存储键值对元素个数size + 1,由于弱引用带来了这个问题,所以要调用cleanSomeSlots(int i, int n)方法清除无用数据,才能判断现在的size有没有达到阀值threshhold,如果没有要清除的数据,存储元素个数仍然 大于 阈值 则调用rehash方法进行扩容
**弱引用WeakReference会造成内存泄露问题吗
答:
但是使用弱引用可以多一层保障:弱引用ThreadLocal不会内存泄漏,对应的value在下一次ThreadLocalMap调用get(),set(),remove()的时候会被清除。
因此,ThreadLocal内存泄漏的根源是:由于ThreadLocalMap的生命周期跟Thread一样长,如果没有手动删除对应key就会导致内存泄漏,而不是因为弱引用。
首先,回答这个问题之前,我需要解释一下什么是强引用,什么是弱引用。
我们在正常情况下,普遍使用的是强引用:
A a = new A(); B b = new B();
当 a = null;b = null;时,一段时间后,JAVA垃圾回收机制GC会将 a 和 b 对应所分配的内存空间给回收。
但考虑这样一种情况:
C c = new C(b); b = null;
当 b 被设置成null时,那么是否意味这一段时间后GC工作可以回收 b 所分配的内存空间呢?答案是否定的,因为即使 b 被设置成null,但 c 仍然持有对 b 的引用,而且还是强引用,所以GC不会回收 b 原先所分配的空间,既不能回收,又不能使用,这就造成了 内存泄露。
那么如何处理呢?
可以通过c = null;,也可以使用弱引用WeakReference w = new WeakReference(b);。因为使用了弱引用WeakReference,GC是可以回收 b 原先所分配的空间的。
回到ThreadLocal的层面上,ThreadLocalMap使用ThreadLocal的弱引用作为key,如果一个ThreadLocal没有外部强引用来引用它,那么系统 GC 的时候,这个ThreadLocal势必会被回收,这样一来,ThreadLocalMap中就会出现key为null的Entry,就没有办法访问这些key为null的Entry的value,如果当前线程再迟迟不结束的话,这些key为null的Entry的value就会一直存在一条强引用链:Thread Ref -> Thread -> ThreaLocalMap -> Entry -> value 永远无法回收,造成内存泄漏。
其实,ThreadLocalMap的设计中已经考虑到这种情况,也加上了一些防护措施:在ThreadLocal的get(),set(),remove()的时候都会清除线程ThreadLocalMap里所有key为null的value。
但是这些被动的预防措施并不能保证不会内存泄漏:
· 使用static的ThreadLocal,延长了ThreadLocal的生命周期,可能导致的内存泄漏分配使用了ThreadLocal又不再调用get(),set(),remove()方法,那么就会导致内存泄漏。
为什么使用弱引用而不是强引用?
为了应对非常大和长时间的用途,哈希表使用弱引用的 key。
下面我们分两种情况讨论:
· key 使用强引用:引用的ThreadLocal的对象被回收了,但是ThreadLocalMap还持有ThreadLocal的强引用,如果没有手动删除,ThreadLocal不会被回收,导致Entry内存泄漏。
· key 使用弱引用:引用的ThreadLocal的对象被回收了,由于ThreadLocalMap持有ThreadLocal的弱引用,即使没有手动删除,ThreadLocal也会被回收。value在下一次ThreadLocalMap调用get(),set(),remove()的时候会被清除。
· 比较两种情况,我们可以发现:由于ThreadLocalMap的生命周期跟Thread一样长,如果都没有手动删除对应key,都会导致内存泄漏,
怎么避免内存泄漏
每次使用完ThreadLocal,都调用它的remove()方法,清除数据。
在使用线程池的情况下,没有及时清理ThreadLocal,不仅是内存泄漏的问题,更严重的是可能导致业务逻辑出现问题。所以,使用ThreadLocal就跟加锁完要解锁一样,用完就清理。
ThreadLocal应用场景
答:总的来说ThreadLocal主要是解决2种类型的问题:
· 解决并发问题:使用ThreadLocal代替synchronized来保证线程安全。同步机制采用了“以时间换空间”的方式,而ThreadLocal采用了“以空间换时间”的方式。前者仅提供一份变量,让不同的线程排队访问,而后者为每一个线程都提供了一份变量,因此可以同时访问而互不影响。
· 解决数据存储问题:ThreadLocal为变量在每个线程中都创建了一个副本,所以每个线程可以访问自己内部的副本变量,不同线程之间不会互相干扰。如一个Parameter对象的数据需要在多个模块中使用,如果采用参数传递的方式,显然会增加模块之间的耦合性。此时我们可以使用ThreadLocal解决。
应用场景:
Spring使用ThreadLocal解决线程安全问题
l 如一个Parameter对象的数据需要在多个模块中使用,如果采用参数传递的方式,显然会增加模块之间的耦合性。此时我们可以使用ThreadLocal解决。
l 我们知道在一般情况下,只有无状态的Bean才可以在多线程环境下共享,在Spring中,绝大部分Bean都可以声明为singleton作用域。就是因为Spring对一些Bean(如RequestContextHolder、TransactionSynchronizationManager、LocaleContextHolder等)中非线程安全状态采用ThreadLocal进行处理,让它们也成为线程安全的状态,因此有状态的Bean就可以在多线程中共享了。
l 一般的Web应用划分为展现层、服务层和持久层三个层次,在不同的层中编写对应的逻辑,下层通过接口向上层开放功能调用。在一般情况下,从接收请求到返回响应所经过的所有程序调用都同属于一个线程。
ThreadLocal是解决线程安全问题一个很好的思路,它通过为每个线程提供一个独立的变量副本解决了变量并发访问的冲突问题。在很多情况下,ThreadLocal比直接使用synchronized同步机制解决线程安全问题更简单,更方便,且结果程序拥有更高的并发性。
总结
A:ThreadLocal提供线程内部的局部变量,在本线程内随时随地可取,隔离其他线程。
B:ThreadLocal的设计是:每个Thread维护一个ThreadLocalMap哈希表,这个哈希表的key是ThreadLocal实例本身,value才是真正要存储的值Object。
C:对ThreadLocal的常用操作实际是对线程Thread中的ThreadLocalMap进行操作。
D:ThreadLocalMap的底层实现是一个定制的自定义HashMap哈希表,ThreadLocalMap的阈值threshold = 底层哈希表table的长度 len * 2 / 3,当实际存储元素个数size 大于或等于 阈值threshold的 3/4 时size >= threshold*3/4,则对底层哈希表数组table进行扩容操作。
E:ThreadLocalMap中的哈希表Entry[] table存储的核心元素是Entry,存储的key是ThreadLocal实例对象,value是ThreadLocal 对应储存的值value。需要注意的是,此Entry继承了弱引用 WeakReference,所以在使用ThreadLocalMap时,发现key == null,则意味着此key ThreadLocal不在被引用,需要将其从ThreadLocalMap哈希表中移除。
F:ThreadLocalMap使用ThreadLocal的弱引用作为key,如果一个ThreadLocal没有外部强引用来引用它,那么系统 GC 的时候,这个ThreadLocal势必会被回收。所以,在ThreadLocal的get(),set(),remove()的时候都会清除线程ThreadLocalMap里所有key为null的value。如果我们不主动调用上述操作,则会导致内存泄露。
G:为了安全地使用ThreadLocal,必须要像每次使用完锁就解锁一样,在每次使用完ThreadLocal后都要调用remove()来清理无用的Entry。这在操作在使用线程池时尤为重要。
H:ThreadLocal和synchronized的区别:同步机制(synchronized关键字)采用了以“时间换空间”的方式,提供一份变量,让不同的线程排队访问。而ThreadLocal采用了“以空间换时间”的方式,为每一个线程都提供一份变量的副本,从而实现同时访问而互不影响。
I:ThreadLocal主要是解决2种类型的问题:A. 解决并发问题:使用ThreadLocal代替同步机制解决并发问题。B. 解决数据存储问题:如一个Parameter对象的数据需要在多个模块中使用,如果采用参数传递的方式,显然会增加模块之间的耦合性。此时我们可以使用ThreadLocal解决。
二、Synchronized同步法
1、基本思路
使用同步块和wait、notify的方法控制三个线程的执行次序。具体方法如下:从大的方向上来讲,该问题为三线程间的同步唤醒操作,主要的目的就是ThreadA->ThreadB->ThreadC->ThreadA循环执行三个线程。为了控制线程执行的顺序,那么就必须要确定唤醒、等待的顺序,所以每一个线程必须同时持有两个对象锁,才能进行打印操作。一个对象锁是prev,就是前一个线程所对应的对象锁,其主要作用是保证当前线程一定是在前一个线程操作完成后(即前一个线程释放了其对应的对象锁)才开始执行。还有一个锁就是自身对象锁。主要的思想就是,为了控制执行的顺序,必须要先持有prev锁(也就前一个线程要释放其自身对象锁),然后当前线程再申请自己对象锁,两者兼备时打印。之后首先调用self.notify()唤醒下一个等待线程(注意notify不会立即释放对象锁,只有等到同步块代码执行完毕后才会释放),再调用prev.wait()立即释放prev对象锁,当前线程进入休眠,等待其他线程的notify操作再次唤醒。
synchronized 和 volatile
1)volatile本质是告诉JVM当前变量在寄存器中的值是不确定的,需要从主存中读取。synchronized则是锁定当前变量,只有当前线程可以访问该变量,其它线程被阻塞。
2)volatile仅能使用在变量级别,synchronized则可以使用在变量、方法。
3)volatile仅能实现变量修改的可见性,而synchronized则可以保证变量修改的可见性和原子性。《Java编程思想》上说,定义long或double时,如果使用volatile关键字(简单的赋值与返回操作),就会获得原子性。(常规状态下,这两个变量由于其长度,其操作不是原子的)
4)volatile不会造成线程阻塞,synchronized会造成线程阻塞。
5)使用volatile而不是synchronized的唯一安全情况是类中只有一个可变的域。
5、当一个域的值依赖于它之前的值时,volatile就无法工作了,如n=n+1,n++等。如果某个域的值受到其他域的值的限制,那么volatile也无法工作,如Range类的lower和upper边界,必须遵循lower<=upper的限制。
6、使用volatile而不是synchronized的唯一安全的情况是类中只有一个可变的域。
synchronized 和 Lock
lock与synchronize区别
1)Lock是一个接口,而synchronized是Java中的关键字,synchronized是内置的语言实现;
2)synchronized在发生异常时,会自动释放线程占有的锁,因此不会导致死锁现象发生;而Lock在发生异常时,如果没有主动通过unLock()去释放锁,则很可能造成死锁现象,因此使用Lock时需要在finally块中释放锁;
3)Lock可以让等待锁的线程响应中断,而synchronized却不行,使用synchronized时,等待的线程会一直等待下去,不能够响应中断;
4)通过Lock可以知道有没有成功获取锁,而synchronized却无法办到。
5)Lock可以提高多个线程进行读操作的效率。
在性能上来说,如果竞争资源不激烈,两者的性能是差不多的,而当竞争资源非常激烈时(即有大量线程同时竞争),此时Lock的性能要远远优于synchronized。所以说,在具体使用时要根据适当情况选择。
1.首先synchronized是java内置关键字,在jvm层面,Lock是个java类;
2.synchronized无法判断是否获取锁的状态,Lock可以判断是否获取到锁;
3.synchronized会自动释放锁(a 线程执行完同步代码会释放锁 ;b 线程执行过程中发生异常会释放锁),Lock需在finally中手工释放锁(unlock()方法释放锁),否则容易造成线程死锁;
4.用synchronized关键字的两个线程1和线程2,如果当前线程1获得锁,线程2线程等待。如果线程1阻塞,线程2则会一直等待下去,而Lock锁就不一定会等待下去,如果尝试获取不到锁,线程可以不用一直等待就结束了;
5.synchronized的锁可重入、不可中断、非公平,而Lock锁可重入、可判断、可公平(两者皆可)
6.Lock锁适合大量同步的代码的同步问题,synchronized锁适合代码少量的同步问题。
synchronized 和 ReentrantLock
答:ThreadLocal和synchronized关键字都用于处理多线程并发访问变量的问题,只是二者处理问题的角度和思路不同。
a:ThreadLocal是一个Java类,将他的实例对象作为一个线程的局部变量,通过对当前线程中的局部变量的操作来解决不同线程的变量访问的冲突问题。所以,ThreadLocal提供了线程安全的共享对象机制,每个线程都拥有其副本。
b:Java中的synchronized是一个保留字,它依靠JVM的锁机制来实现临界区的函数或者变量的访问中的原子性。在同步机制中,通过对象的锁机制保证同一时间只有一个线程访问变量。此时,被用作“锁机制”的变量时多个线程共享的。
c:同步机制(synchronized关键字)采用了以“时间换空间”的方式,提供一份变量,让不同的线程排队访问。而ThreadLocal采用了“以空间换时间”的方式,为每一个线程都提供一份变量的副本,从而实现同时访问而互不影响。
可重入性:
两者都是同一个线程每进入一次,锁的计数器都自增1,所以要等到锁的计数器下降为0时才能释放锁。
锁的实现:
Synchronized是依赖于JVM实现的,而ReenTrantLock是JDK实现的,有什么区别,说白了就类似于操作系统来控制实现和用户自己敲代码实现的区别。
性能的区别:
在Synchronized优化以前,synchronized的性能是比ReenTrantLock差很多的,但是自从Synchronized引入了偏向锁,轻量级锁(自旋锁)后,两者的性能就差不多了,在两种方法都可用的情况下,官方甚至建议使用synchronized,其实synchronized的优化我感觉就借鉴了ReenTrantLock中的CAS技术。都是试图在用户态就把加锁问题解决,避免进入内核态的线程阻塞。
功能区别:
便利性:很明显Synchronized的使用比较方便简洁,并且由编译器去保证锁的加锁和释放,而ReenTrantLock需要手工声明来加锁和释放锁,为了避免忘记手工释放锁造成死锁,所以最好在finally中声明释放锁。
锁的细粒度和灵活度:很明显ReenTrantLock优于Synchronized
ReenTrantLock独有的能力:
\1. ReenTrantLock可以指定是公平锁还是非公平锁。而synchronized只能是非公平锁。所谓的公平锁就是先等待的线程先获得锁。
\2. ReenTrantLock提供了一个Condition(条件)类,用来实现分组唤醒需要唤醒的线程们,而不是像synchronized要么随机唤醒一个线程要么唤醒全部线程。
\3. ReenTrantLock提供了一种能够中断等待锁的线程的机制,通过lock.lockInterruptibly()来实现这个机制。
ReenTrantLock实现的原理:
ReenTrantLock的实现是一种自旋锁,通过循环调用CAS操作来实现加锁。它的性能比较好也是因为避免了使线程进入内核态的阻塞状态。
什么情况下使用ReenTrantLock:
答案是,如果你需要实现ReenTrantLock的三个独有功能时。
21.说一下 atomic 的原理?
22.yield与join方法的区别?
Yield是一个静态的原生(native)方法 Yield告诉当前正在执行的线程把运行机会交给线程池中拥有相同优先级的线程。 Yield不能保证使得当前正在运行的线程迅速转换到可运行的状态 它仅能使一个线程从运行状态转到可运行状态,而不是等待或阻塞状态
join()方法可以使得一个线程在另一个线程结束后再执行。如果join()方法在一个线程实例上调用,当前运行着的线程将阻塞直到这个线程实例完成了执行。
1.sleep()方法
在指定时间内让当前正在执行的线程暂停执行,但不会释放“锁标志”。不推荐使用。
sleep()使当前线程进入阻塞状态,在指定时间内不会执行。
如何唤醒
2.wait()方法
在其他线程调用对象的notify或notifyAll方法前,导致当前线程等待。线程会释放掉它所占有的“锁标志”,从而使别的线程有机会抢占该锁。
当前线程必须拥有当前对象锁。如果当前线程不是此锁的拥有者,会抛出IllegalMonitorStateException异常。
唤醒当前对象锁的等待线程使用notify或notifyAll方法,也必须拥有相同的对象锁,否则也会抛出IllegalMonitorStateException异常。
waite()和notify()必须在synchronized函数或synchronized block中进行调用。如果在non-synchronized函数或non-synchronized block中进行调用,虽然能编译通过,但在运行时会发生IllegalMonitorStateException的异常。
②wait() 与 notify/notifyAll() 的执行过程
由于 wait() 与 notify/notifyAll() 是放在同步代码块中的,因此线程在执行它们时,肯定是进入了临界区中的,即该线程肯定是获得了锁的。
当线程执行wait()时,会把当前的锁释放,然后让出CPU,进入等待状态。
当执行notify/notifyAll方法时,会唤醒一个处于等待该 对象锁 的线程,然后继续往下执行,直到执行完退出对象锁锁住的区域(synchronized修饰的代码块)后再释放锁。
从这里可以看出,notify/notifyAll()执行后,并不立即释放锁,而是要等到执行完临界区中代码后,再释放。故,在实际编程中,我们应该尽量在线程调用notify/notifyAll()后,立即退出临界区。即不要在notify/notifyAll()后面再写一些耗时的代码。
wait() 与 notify/notifyAll()都是放在同步代码块中才能够执行的。如果在执行wait() 与 notify/notifyAll() 之前没有获得相应的对象锁,就会抛出:java.lang.IllegalMonitorStateException异常。
第一,记住wait必须要进行异常捕获
第二,记住调用wait或者notify方法必须采用当前锁调用,即必须采用synchronized中的对象
3.yield方法
暂停当前正在执行的线程对象。
yield()只是使当前线程重新回到可执行状态,所以执行yield()的线程有可能在进入到可执行状态后马上又被执行。
yield()只能使同优先级或更高优先级的线程有执行的机会。
4.join方法
join()等待该线程终止。
等待调用join方法的线程结束,再继续执行。如:t.join();//主要用于等待t线程运行结束,若无此句,main则会执行完毕,导致结果不可预测
1.sleep()方法
在指定时间内让当前正在执行的线程暂停执行,但不会释放“锁标志”。不推荐使用。
sleep()使当前线程进入阻塞状态,在指定时间内不会执行。
2.wait()方法
在其他线程调用对象的notify或notifyAll方法前,导致当前线程等待。线程会释放掉它所占有的“锁标志”,从而使别的线程有机会抢占该锁。
当前线程必须拥有当前对象锁。如果当前线程不是此锁的拥有者,会抛出IllegalMonitorStateException异常。
唤醒当前对象锁的等待线程使用notify或notifyAll方法,也必须拥有相同的对象锁,否则也会抛出IllegalMonitorStateException异常。
waite()和notify()必须在synchronized函数或synchronized block中进行调用。如果在non-synchronized函数或non-synchronized block中进行调用,虽然能编译通过,但在运行时会发生IllegalMonitorStateException的异常。
3.yield方法
暂停当前正在执行的线程对象。
yield()只是使当前线程重新回到可执行状态,所以执行yield()的线程有可能在进入到可执行状态后马上又被执行。
yield()只能使同优先级或更高优先级的线程有执行的机会。
4.join方法
join()等待该线程终止。
等待调用join方法的线程结束,再继续执行。如:t.join();//主要用于等待t线程运行结束,若无此句,main则会执行完毕,导致结果不可预测
yield()不会释放锁,只是通知调度器自己可以让出cpu时间片,但只是建议,调度器也不一定采纳
sleep只能让正在执行的线程暂停执行,但不会释放锁
wait方法在其他线程调用对象的notify或notifyAll方法前会导致当前线程等待。线程会释放占有的锁。
yield只能使当前线程重新回到可执行状态,不会释放锁
volatile
volatile是java中的一个类型修饰符。它是被设计用来修饰被不同线程访问和修改的变量。如果不加入volatile,基本上会导致这样的结果:要么无法编写多线程程序,要么编译器 失去大量优化的机会。
1,可见性
可见性指的是在一个线程中对该变量的修改会马上由工作内存(Work Memory)写回主内存(Main Memory),所以会马上反应在其它线程的读取操作中。顺便一提,工作内存和主内存可以近似理解为实际电脑中的高速缓存和主存,工作内存是线程独享的,主存是线程共享的。
2,禁止指令重排序优化
禁止指令重排序优化。大家知道我们写的代码(尤其是多线程代码),由于编译器优化,在实际执行的时候可能与我们编写的顺序不同。编译器只保证程序执行结果与源代码相同,却不保证实际指令的顺序与源代码相同。这在单线程看起来没什么问题,然而一旦引入多线程,这种乱序就可能导致严重问题。volatile关键字就可以从语义上解决这个问题。
注意,禁止指令重排优化这条语义直到jdk1.5以后才能正确工作。此前的JDK中即使将变量声明为volatile也无法完全避免重排序所导致的问题。所以,在jdk1.5版本前,双重检查锁形式的单例模式是无法保证线程安全的。因此,下面的单例模式的代码,在JDK1.5之前是不能保证线程安全的
1) 指令重排序
在执行程序时,编译器和cpu为了提高效率会对指令进行重排序,通过插入Memory Barrier禁止重排序,为上一层提供可见性保证
处理器指令重排、内存屏障,问处理器一般会怎么指令重排,是问重排序的三种:编译器优化的重排序、指令级并行的重排序和内存系统的重排序;
1、编译器优化重排序:编译器在不改变单线程程序语义的前提下,可以重新安排语句的执行顺序。
2、指令级并行的重排序:如果不存l在数据依赖性,处理器可以改变语句对应机器指令的执行顺序。
3、内存系统的重排序:处理器使用缓存和读写缓冲区,这使得加载和存储操作看上去可能是在乱序执行。
1.java的内存模型 原子性+可见性+重排序
java 内存模型规定了所有的变量都存储在主内存中,但是每个线程会有自己的工作内存,线程的工作内存保存了该线程中使用了的变量(从主内存中拷贝的),线程对变量的操作都必须在工作内存中进行,不同线程之间无法直接访问对方工作内存中的变量,线程间变量值从传递都要经过主内存完成
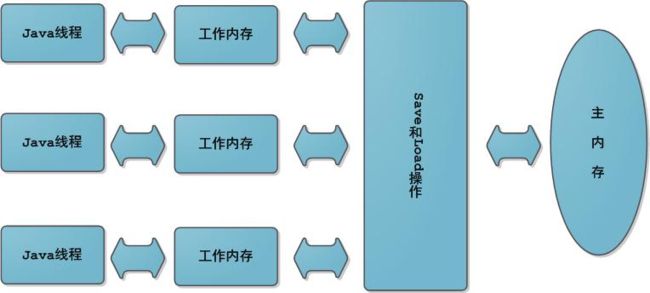
2.其实 Java JMM 内存模型是围绕并发编程中原子性、可见性、有序性三个特征来建立的,
原子性:就是说一个操作不能被打断,要么执行完要么不执行,类似事务操作,Java 基本类型数据的访问大都是原子操作,long 和 double 类型是 64 位,在 32 位 JVM 中会将 64 位数据的读写操作分成两次 32 位来处理,所以 long 和 double 在 32 位 JVM 中是非原子操作,也就是说在并发访问时是线程非安全的,要想保证原子性就得对访问该数据的地方进行同步操作,譬如 synchronized 或者使用原子类AutomicDoule等。
可见性:就是说当一个线程对共享变量做了修改后其他线程可以立即感知到该共享变量的改变。从 Java 内存模型我们就能看出来多线程访问共享变量都要经过线程工作内存到主存的复制和主存到线程工作内存的复制操作,所以普通共享变量就无法保证可见性了;Java 提供了 volatile 修饰符来保证变量的可见性,每次使用 volatile 变量都会主动从主存中刷新,除此之外 synchronized、Lock、final 都可以保证变量的可见性。
有序性:就是说 Java 内存模型中的指令重排不会影响单线程的执行顺序,但是会影响多线程并发执行的正确性,所以在并发中我们必须要想办法保证并发代码的有序性;在 Java 里可以通过 volatile 关键字保证一定的有序性,还可以通过 synchronized、Lock 来保证有序性,因为 synchronized、Lock 保证了每一时刻只有一个线程执行同步代码相当于单线程执行,所以自然不会有有序性的问题;
除此之外 Java 内存模型通过 happens-before 原则如果能推导出来两个操作的执行顺序就能先天保证有序性,否则无法保证。
)happens-before,即**先行发生原则,定义了操作A必然先行发生于操作B的一些规则,**
比如在同一个线程内控制流前面的代码一定先行发生于控制流后面的代码、
一个释放锁unlock的动作一定先行发生于后面对于同一个锁进行锁定lock的动作等等,只要符合这些规则,则不需要额外做同步措施,如果某段代码不符合所有的happens-before规则,则这段代码一定是线程非安全的
volatile 实现原理
2.什么是原子性
一个操作是不可中断的,要么全部执行成功要么全部执行失败,比如银行转账
3.什么是可见性
当多个线程访问同一变量时,一个线程修改了这个变量的值,其他线程就能够立即看到修改的值
4.什么是有序性
程序执行的顺序按照代码的先后顺序执行
`int` `a = ``0``; ``//1``int` `b = ``2``; ``//2`
像这2句代码1会比2先执行,但是jvm在正真执行时不一定是1在2之前,这里涉及一个概念叫做指令重排,处理器为了提高程序运行效率,可能会对输入代码进行优化,它不保证程序中各个语句的执行先后顺序同代码中的顺序一致,但是它会保证程序最终执行结果和代码顺序执行的结果是一致的。比如上面的代码语句1和语句2谁先执行对最终的程序结果并没有影响,那么就有可能在执行过程中,语句2先执行而语句1后执行。 在指令重排时会考虑指令之间的数据依赖性,比如2依赖了1的数值,那么处理器会保证1在2之前执行。 但是在多线程的情况下,指令重排就会有影响了。
5.volatile到底做了什么
-
禁止了指令重排
-
保证了不同线程对这个变量进行操作时的可见性,即一个线程修改了某个变量值,这个新值对其他线程是立即可见的
-
不保证原子性(线程不安全)
Java中的多线程是一种抢占式的机制,而不是分时机制。抢占式的机制是有多个线程处于可运行状态,但是只有一个线程在运行。
-
Volatile:与锁相比,Volatile 变量是一种非常简单但同时又非常脆弱的同步机制,它在某些情况下将提供优于锁的性能和伸缩性。如果严格遵循 volatile 的使用条件 —— 即变量真正独立于其他变量和自己以前的值 —— 在某些情况下可以使用 volatile 代替 synchronized 来简化代码。然而,使用 volatile 的代码往往比使用锁的代码更加容易出错。
-
-
您只能在有限的一些情形下使用 volatile 变量替代锁。要使 volatile 变量提供理想的线程安全,必须同时满足下面两个条件:
-
(1)对变量的写操作不依赖于当前值。
-
(2)该变量没有包含在具有其他变量的不变式中。
-
-
实际上,这些条件表明,可以被写入 volatile 变量的这些有效值独立于任何程序的状态,包括变量的当前状态。
-
第一个条件的限制使 volatile 变量不能用作线程安全计数器。**虽然增量操作(x++)看上去类似一个单独操作,实际上它是一个由读取-修改-写入操作序列组成的组合操作,必须以原子方式执行,而 volatile 不能提供必须的原子特性。实现正确的操作需要使 x 的值在操作期间保持不变,而 volatile 变量无法实现这点。
-
vol**atile 实现原理**
Volatile和Synchronized
1 粒度不同,前者针对变量 ,后者锁对象和类
2 syn阻塞,volatile线程不阻塞
3 syn保证三大特性,volatile不保证原子性
4 syn编译器优化,volatile不优化
volatile具备两种特性:
\1. 保证此变量对所有线程的可见性,指一条线程修改了这个变量的值,新值对于其他线程来说是可见的,但并不是多线程安全的。
\2. 禁止指令重排序优化。
Volatile如何保证内存可见性:
1.当写一个volatile变量时,JMM会把该线程对应的本地内存中的共享变量刷新到主内存。
2.当读一个volatile变量时,JMM会把该线程对应的本地内存置为无效。线程接下来将从主内存中读取共享变量。
sleep 和 wait
\1. sleep是Thread方法,wait、notify、notifyAll是Object方法
\2. sleep可以在任何地方使用,wait、notify、notifyAll只能在同步代码块中使用。
\3. sleep放弃CPU资源但是不释放锁,wait会释放锁
wait()和sleep()共同点 :
\1. 他们都是在多线程的环境下,都可以在程序的调用处阻塞指定的毫秒数,并返回。 \2. wait()和sleep()都可以通过interrupt()方法打断线程的暂停状态 ,从而使线程立刻抛出InterruptedException。 如果线程A希望立即结束线程B,则可以对线程B对应的Thread实例调用interrupt方法。如果此刻线程B正在wait/sleep/join,则线程B会立刻抛出InterruptedException,在catch() {} 中直接return即可安全地结束线程。 需要注意的是,InterruptedException是线程自己从内部抛出的,并不是interrupt()方法抛出的。对某一线程调用 interrupt()时,如果该线程正在执行普通的代码,那么该线程根本就不会抛出InterruptedException。但是,一旦该线程进入到 wait()/sleep()/join()后,就会立刻抛出InterruptedException 。 不同点 : 1.每个对象都有一个锁来控制同步访问。Synchronized关键字可以和对象的锁交互,来实现线程的同步。 sleep方法没有释放锁,而wait方法释放了锁,使得其他线程可以使用同步控制块或者方法。 2.wait,notify和notifyAll只能在同步控制方法或者同步控制块里面使用,而sleep可以在任何地方使用 3.sleep必须捕获异常,而wait,notify和notifyAll不需要捕获异常
4.sleep是线程类(Thread)的方法,导致此线程暂停执行指定时间,给执行机会给其他线程,但是监控状态依然保持,到时后会自动恢复。调用sleep不会释放对象锁。
5.wait是Object类的方法,对此对象调用wait方法导致本线程放弃对象锁,进入等待此对象的等待锁定池,只有针对此对象发出notify方法(或notifyAll)后本线程才进入对象锁定池准备获得对象锁进入运行状态。
线程间协作:wait、notify、notifyAll
在 Java 中,可以通过配合调用 Object 对象的 wait() 方法和 notify()方法或 notifyAll() 方法来实现线程间的通信。在线程中调用 wait() 方法,将阻塞等待其他线程的通知(其他线程调用 notify() 方法或 notifyAll() 方法),在线程中调用 notify() 方法或 notifyAll() 方法,将通知其他线程从 wait() 方法处返回。
Object 是所有类的超类,它有 5 个方法组成了等待/通知机制的核心:notify()、notifyAll()、wait()、wait(long)和 wait(long,int)。在 Java 中,所有的类都从 Object 继承而来,因此,所有的类都拥有这些共有方法可供使用。而且,由于他们都被声明为 final,因此在子类中不能覆写任何一个方法。
这里详细说明一下各个方法在使用中需要注意的几点。
wait()
public final void wait() throws InterruptedException,IllegalMonitorStateException
该方法用来将当前线程置入休眠状态,直到接到通知或被中断为止。在调用 wait()之前,线程必须要获得该对象的对象级别锁,即只能在同步方法或同步块中调用 wait()方法。进入 wait()方法后,当前线程释放锁。在从 wait()返回前,线程与其他线程竞争重新获得锁。如果调用 wait()时,没有持有适当的锁,则抛出 IllegalMonitorStateException,它是 RuntimeException 的一个子类,因此,不需要 try-catch 结构。
notify()
public final native void notify() throws IllegalMonitorStateException
该方法也要在同步方法或同步块中调用,即在调用前,线程也必须要获得该对象的对象级别锁,的如果调用 notify()时没有持有适当的锁,也会抛出 IllegalMonitorStateException。
该方法用来通知那些可能等待该对象的对象锁的其他线程。如果有多个线程等待,则线程规划器任意挑选出其中一个 wait()状态的线程来发出通知,并使它等待获取该对象的对象锁(notify 后,当前线程不会马上释放该对象锁,wait 所在的线程并不能马上获取该对象锁,要等到程序退出 synchronized 代码块后,当前线程才会释放锁,wait所在的线程也才可以获取该对象锁),但不惊动其他同样在等待被该对象notify的线程们。当第一个获得了该对象锁的 wait 线程运行完毕以后,它会释放掉该对象锁,此时如果该对象没有再次使用 notify 语句,则即便该对象已经空闲,其他 wait 状态等待的线程由于没有得到该对象的通知,会继续阻塞在 wait 状态,直到这个对象发出一个 notify 或 notifyAll。这里需要注意:它们等待的是被 notify 或 notifyAll,而不是锁。这与下面的 notifyAll()方法执行后的情况不同。
notifyAll()
public final native void notifyAll() throws IllegalMonitorStateException
该方法与 notify ()方法的工作方式相同,重要的一点差异是:
notifyAll 使所有原来在该对象上 wait 的线程统统退出 wait 的状态(即全部被唤醒,不再等待 notify 或 notifyAll,但由于此时还没有获取到该对象锁,因此还不能继续往下执行),变成等待获取该对象上的锁,一旦该对象锁被释放(notifyAll 线程退出调用了 notifyAll 的 synchronized 代码块的时候),他们就会去竞争。如果其中一个线程获得了该对象锁,它就会继续往下执行,在它退出 synchronized 代码块,释放锁后,其他的已经被唤醒的线程将会继续竞争获取该锁,一直进行下去,直到所有被唤醒的线程都执行完毕。
深入理解
如果线程调用了对象的 wait()方法,那么线程便会处于该对象的等待池中,等待池中的线程不会去竞争该对象的锁。
当有线程调用了对象的 notifyAll()方法(唤醒所有 wait 线程)或 notify()方法(只随机唤醒一个 wait 线程),被唤醒的的线程便会进入该对象的锁池中,锁池中的线程会去竞争该对象锁。
优先级高的线程竞争到对象锁的概率大,假若某线程没有竞争到该对象锁,它还会留在锁池中,唯有线程再次调用 wait()方法,它才会重新回到等待池中。而竞争到对象锁的线程则继续往下执行,直到执行完了 synchronized 代码块,它会释放掉该对象锁,这时锁池中的线程会继续竞争该对象锁。
CopyOnWriteArrayList适合使用在读操作远远大于写操作的场景里,比如缓存。
ReadWriteLock 当写操作时,其他线程无法读取或写入数据,而当读操作时,其它线程无法写入数据,但却可以读取数据 。适用于 读取远远大于写入的操作。
ConcurrentHashMap是一个线程安全的Hash Table,它的主要功能是提供了一组和HashTable功能相同但是线程安全的方法。ConcurrentHashMap可以做到读取数据不加锁,并且其内部的结构可以让其在进行写操作的时候能够将锁的粒度保持地尽量地小,不用对整个ConcurrentHashMap加锁。
wait、notify 和 notifyAII
i. 三者都必须在同步块或同步函数中使用
ii. 调用wait就是将线程加入到等待队列,
iii. 调用notify是将等待队列中一个线程移动到同步队列,notifyAll是将等待队列中所有线程放入到同步队列。
iv. 调用notify或notifyAll后线程不会立即从等待队列中返回,必须等到调用notify或notifyaAll的线程将锁释放后,线程才有机会从等待队列中返回。锁释放后等待的线程会出现竞争,只有竞争到的线程才会从wait方法中返回,其他线程只能继续等待。
为什么wait()方法要被try catch包围,且捕获InterruptedException?
不仅是wait,还有sleep、join等方法也会抛出InterruptedException,当等待状态线程遇到interupt标志为true时,会抛出异常
ThreadLocal和synchronized的区别?
答:ThreadLocal和synchronized关键字都用于处理多线程并发访问变量的问题,只是二者处理问题的角度和思路不同。
a:ThreadLocal是一个Java类,将他的实例对象作为一个线程的局部变量,通过对当前线程中的局部变量的操作来解决不同线程的变量访问的冲突问题。所以,ThreadLocal提供了线程安全的共享对象机制,每个线程都拥有其副本。
b:Java中的synchronized是一个保留字,它依靠JVM的锁机制来实现临界区的函数或者变量的访问中的原子性。在同步机制中,通过对象的锁机制保证同一时间只有一个线程访问变量。此时,被用作“锁机制”的变量时多个线程共享的。
c:同步机制(synchronized关键字)采用了以“时间换空间”的方式,提供一份变量,让不同的线程排队访问。而ThreadLocal采用了“以空间换时间”的方式,为每一个线程都提供一份变量的副本,从而实现同时访问而互不影响。
线程间通信
1.共享内存的方法
1.1 用synchronized情况下:多线程环境下,会造成线程阻塞,现在假如有2个线程同时要对内存中的一个数据进行操作,那么他们都把内存中的值读到自己工作内存中。方法用synchronized修饰的话同一时间只能有一个线程进行操作,对数据更新完后重新刷回主内存,自动释放所。然后下一个线程来读取内存中的值。实现线程通信。
1.2 voletile,用它修饰的变量,线程在对他进行操作时其他线程是可见的,数据更新完以后直接刷回主内存,其他线程读的话,即使工作内存有数据,也不读,读取的是主内存的值,从而实现通信。
\2. Synchronized+wait+notify:在生产者消费者模式中。生产者生产到库存满了以后就不在生产,调用wait方法,挂起,然后在调用notify方法唤醒消费者进行消费。这也达到了线程间的通信。
3.Lock+condition+await+signal:他与上面的实现相似,Condition.await对应的是wait,它需要显示的加锁和释放锁。
4.管道通信:他在两个线程之间建立一个通道,就是有pipeInputStream和pipeOutputStream,inputStream接受信息,outputStram用于发送信息。
interrupted
下面简单的举例情况:
\1. 比如我们会启动多个线程做同一件事,比如抢12306的火车票,我们可能开启多个线程从多个渠道买火车票,只要有一个渠道买到了,我们会通知取消其他渠道。这个时候需要关闭其他线程
java为我们提供了一种调用interrupt()方法来请求终止线程的方法。
每一个线程都有一个boolean类型标志,用来表明当前线程是否请求中断,当一个线程调用interrupt() 方法时,线程的中断标志将被设置为true。
所以说调用线程的interrupt() 方法不会中断一个正在运行的线程,这个机制只是设置了一个线程中断标志位,如果在程序中你不检测线程中断标志位,那么即使
设置了中断标志位为true,线程也一样照常运行。
当线程调用Thread.sleep()、Thread.join()、object.wait()再或者调用阻塞的i/o操作方法时,都会使得当前线程进入阻塞状态。那么此时如果在线程处于阻塞状态是调用interrupt() 方法设置线程中断标志位时会出现什么情况呢! 此时处于阻塞状态的线程会抛出一个异常,并且会清除线程中断标志位(设置为false)。这样一来线程就能退出阻塞状态。当然抛出异常的方法就是造成线程处于阻塞状态的Thread.sleep()、Thread.join()、object.wait()这些方法。
线程间通信
1.共享内存的方法:
1.1 用synchronized情况下:多线程环境下,会造成线程阻塞,现在假如有2个线程同时要对内存中的一个数据进行操作,那么他们都把内存中的值读到自己工作内存中。方法用synchronized修饰的话同一时间只能有一个线程进行操作,对数据更新完后重新刷回主内存,自动释放所。然后下一个线程来读取内存中的值。实现线程通信。
1.2 voletile,用它修饰的变量,线程在对他进行操作时其他线程是可见的,数据更新完以后直接刷回主内存,其他线程读的话,即使工作内存有数据,也不读,读取的是主内存的值,从而实现通信。
\2. Synchronized+wait+notify:在生产者消费者模式中。生产者生产到库存满了以后就不在生产,调用wait方法,挂起,然后在调用notify方法唤醒消费者进行消费。这也达到了线程间的通信。
3.Lock+condition+await+signal:他与上面的实现相似,Condition.await对应的是wait,它需要显示的加锁和释放锁。
4.管道通信:他在两个线程之间建立一个通道,就是有pipeInputStream和pipeOutputStream,inputStream接受信息,outputStram用于发送信息。
我们可以通过调用Thread.currentThread().isInterrupted()或者Thread.interrupted()来检测线程的中断标志是否被置位。
这两个方法的区别是Thread.currentThread().isInterrupted()是线程对象的方法,调用它后不清除线程中断标志位;而Thread.interrupted()是一个静态方法,调用它会清除线程中断标志位。
CAS:
CAS是乐观锁技术,当多个线程尝试使用CAS同时更新同一个变量时,只有其中一个线程能更新变量的值,而其它线程都失败,失败的线程并不会被挂起,而是被告知这次竞争中失败,并可以再次尝试。
CAS 操作中包含三个操作数 —— 需要读写的内存位置(V)、进行比较的预期原值(A)和拟写入的新值(B)。如果内存位置V的值与预期原值A相匹配,那么处理器会自动将该位置值更新为新值B。否则处理器不做任何操作。无论哪种情况,它都会在 CAS 指令之前返回该位置的值。(在 CAS 的一些特殊情况下将仅返回 CAS 是否成功,而不提取当前值。)CAS 有效地说明了“ 我认为位置 V 应该包含值 A;如果包含该值,则将 B 放到这个位置;否则,不要更改该位置,只告诉我这个位置现在的值即可。 ”这其实和乐观锁的冲突检查+数据更新的原理是一样的。
JAVA对CAS的支持:
在JDK1.5 中新增(J.U.C)就是建立在CAS之上的。相对于对于 synchronized 这种阻塞算法,CAS是非阻塞算法的一种常见实现。所以J.U.C在性能上有了很大的提升。
CAS缺点:
\1. ABA问题:
比如说一个线程one从内存位置V中取出A,这时候另一个线程two也从内存中取出A,并且two进行了一些操作变成了B,然后two又将V位置的数据变成A,这时候线程one进行CAS操作发现内存中仍然是A,然后one操作成功。尽管线程one的CAS操作成功,但可能存在潜藏的问题。AtomicStamp解决,相当于增加一个version
\2. 循环时间长开销大:
自旋CAS(不成功,就一直循环执行,直到成功)如果长时间不成功,会给CPU带来非常大的执行开销。如果JVM能支持处理器提供的pause指令那么效率会有一定的提升,pause指令有两个作用,第一它可以延迟流水线执行指令(de-pipeline),使CPU不会消耗过多的执行资源,延迟的时间取决于具体实现的版本,在一些处理器上延迟时间是零。第二它可以避免在退出循环的时候因内存顺序冲突(memory order violation)而引起CPU流水线被清空(CPU pipeline flush),从而提高CPU的执行效率。
-
只能保证一个共享变量的原子操作:
当对一个共享变量执行操作时,我们可以使用循环CAS的方式来保证原子操作,但是对多个共享变量操作时,循环CAS就无法保证操作的原子性,这个时候就可以用锁,或者有一个取巧的办法,就是把多个共享变量合并成一个共享变量来操作。比如有两个共享变量i=2,j=a,合并一下ij=2a,然后用CAS来操作ij。从Java1.5开始JDK提供了AtomicReference类来保证引用对象之间的原子性,你可以把多个变量放在一个对象里来进行CAS操作**。**
CAS无锁操作
CAS的语义是“我认为V的值应该为A,如果是,那么将V的值更新为B,否则不修改并告诉V的值实际为多少”,CAS是项乐观锁技术,当多个线程尝试使用CAS同时更新同一个变量时,只有其中一个线程能更新变量的值,而其它线程都失败,失败的线程并不会被挂起,而是被告知这次竞争中失败,并可以再次尝试。CAS有3个操作数,内存值V,旧的预期值A,要修改的新值B。当且仅当预期值A和内存值V相同时,将内存值V修改为B,否则什么都不做。
读写锁
在一些程序中存在读者写者问题,也就是说,对某些资源的访问会存在两种可能的情况,
一种是访问必须是排它性的,就是独占的意思,这称作写操作;
另一种情况就是访问方式可以是共享的,就是说可以有多个线程同时去访问某个资源,这种就称作读操作
读写锁,可以有多个线程同时占用读模式的读写锁,但是只能有一个线程占用写模式的读写锁,
读写锁的三种状态:
1.当读写锁是写加锁状态时,在这个锁被解锁之前,所有试图对这个锁加锁的线程都会被阻塞。
2.当读写锁在读加锁状态时,所有试图以读模式对它进行加锁的线程都可以得到访问权,但是以写模式对它进行加锁的线程将会被阻塞。
3.当读写锁在读模式的锁状态时,如果有另外的线程试图以写模式加锁,读写锁通常会阻塞随后的读模式锁的请求,这样可以避免读模式锁长期占用,而等待的写模式锁请求则长期阻塞,被饿死。
AQS
AQS(同步器)是实现众多锁对象的基础,它的设计采用了模板方法模式。就是它定义了一系列的模板方法比如acquire()、acquireShared()等,和一些等待被实现类来实现的方法比如tryAcquire()、tryRelease()、tryAcquireShared()等,在模板方法中会去调用这些被重写的方法。
然后AQS这个类中有一个被volatile修饰的int型的变量state,在AQS字类中这个变量被赋予不同的语义来表示锁的不同状态,首先锁的大类被分成了共享锁和互斥锁,在共享锁中这个state表示同时可获取锁的线程数,当有线程获取了锁后锁状态自减。然后ReentantLook是一个互斥锁的实现,他不但是一个互斥锁还是一个可重入锁,它用state来表示锁能否被获取以及重入的次数。最后将这个state玩到极致的是ReentrantReadWriteLook,它将state这个变量分为了高16位和低16位来分别表示读锁和写锁。
然后AQS中还维护了一个同步队列和若干个等待队列,两者都是双向链表的结构,当获取锁失败后会进入同步队列,通过自旋来不断获取锁状态。当发生Condition.await的时候就会加入等待队列(这时线程的状态会变为等待状态),只有其他的线程发出了signal的信号的时候才会移出等待队列加入同步队列以获取所状态。
还有公平锁和非公平锁的实现是通过等待队列的下一个获取锁的线程来决定的。
锁降级是对于读写锁来说的,锁降级就是将写锁降级为读锁。这是为了保证数据的可见性,加入一个锁直接释放掉的写锁然后另一个线程又获得了写锁那此线程的操作就可能被覆盖。同时不支持锁升级的原因也是为了保证数据的可见性。
LockSupport
LockSupport中的park() 和 unpark() 的作用分别是阻塞线程和解除阻塞线程
Condition
Condition除了支持上面的功能之外,它更强大的地方在于:能够更加精细的控制多线程的休眠与唤醒。对于同一个锁,我们可以创建多个Condition,在不同的情况下使用不同的Condition。 例如,假如多线程读/写同一个缓冲区:当向缓冲区中写入数据之后,唤醒"读线程";当从缓冲区读出数据之后,唤醒"写线程";并且当缓冲区满的时候,"写线程"需要等待;当缓冲区为空时,"读线程"需要等待。 如果采用Object类中的wait(), notify(), notifyAll()实现该缓冲区,当向缓冲区写入数据之后需要唤醒"读线程"时,不可能通过notify()或notifyAll()明确的指定唤醒"读线程",而只能通过notifyAll唤醒所有线程(但是notifyAll无法区分唤醒的线程是读线程,还是写线程)。 但是,通过Condition,就能明确的指定唤醒读线程。
简单说一下AQS,抽象队列同步器。
Cas是juc的基础,aqs是juc的核心,ReentrantLock、CountDownLatch、Semaphore等等都用到了它。AQS实际上以双向队列的形式连接所有的Entry,比方说ReentrantLock,所有等待的线程都被放在一个Entry中并连成双向队列,前面一个线程使用ReentrantLock好了,则双向队列实际上的第一个Entry开始运行。
AQS定义了对双向队列所有的操作,而只开放了tryLock和tryRelease方法给开发者使用,开发者可以根据自己的实现重写tryLock和tryRelease方法,以实现自己的并发功能。
CyclicBarrier和CountDownLatch的区别
个人感觉CyclicBarrier就是用来给多个线程之间进行互相等待其他所有线程而设计的,而CountDownLatch是给一个起"调度"作用的线程用的,这个线程关键职责就是等待进行其他工作线程返回
CountDownLatch 是计数器, 线程完成一个就记一个, 就像 报数一样, 只不过是递减的.
而CyclicBarrier更像一个水闸, 线程执行就想水流, 在水闸处都会堵住, 等到水满(线程到齐)了, 才开始泄流.
ReentrantLock
1.ReentrantLock 类实现了Lock ,它拥有与synchronized 相同的并发性和内存语义,但是添加了类似锁投票、定时锁等待和可中断锁等候的一些特性。此外,它还提供了在激烈争用情况下更佳的性能。(换句话说,当许多线程都想访问共享资源时,JVM可以花更少的时候来调度线程,把更多时间用在执行线程上。)
Reentrant 锁意味着什么呢?简单来说,它有一个与锁相关的获取计数器,如果拥有锁的某个线程再次得到锁,那么获取计数器就加1,然后锁需要被释放两次才能获得真正释放。这模仿了synchronized 的语义;如果线程进入由线程已经拥有的监控器保护的synchronized 块,就允许线程继续进行,当线程退出第二个(或者后续)synchronized块的时候,不释放锁,只有线程退出它进入的监控器保护的第一个synchronized 块时,才释放锁。
Synchronuzed原理
锁存在于对象头中,数组的对象头3个字宽,非数组为2个字宽。一个字宽4字节。
其中Mark Word中有HashCode、分代年龄、锁标志位。
锁的四种状态:无锁、偏向锁、轻量级、重量级。锁膨胀升级后不能降级
-
偏向锁
当一个线程访问同步块,会标记为偏向状态,会在对象头记录线程ID,以后进入退出只需要判断ID的值是否一致。一旦有第二个线程访问,看到偏向状态后,它首先判断持有偏向锁的线程是否存活,如果死亡则将对象头设置为无锁状态;若存活则执行原线程操作栈,如果仍需要偏向锁,则会膨胀为轻量级锁。
-
轻量级锁
a) 加锁
线程执行同步块之前,JVM会在线程栈帧中创建锁记录空间,并将MarkWord复制到锁记录空间中。线程使用CAS将对象头中Mark Word替换为指向所记录指针,如果成功则获得了锁,若失败说明有其他线程竞争锁,当前线程使用自旋来获取锁。
b) 解锁
解锁时,线程尝试用CAS将栈帧中的锁记录Mark Word替换回对象头,如果失败表示存在锁竞争,锁会膨胀为重量级锁。
总结synchronized获取锁过程
一个线程访问同步块,在对象头记录线程id,并设置为偏向锁。每次进入判断线程ID是否一致。若第二个线程需要获取锁,试图将自己ID放到对象头,如果失败,则膨胀为轻量级锁。在轻量级锁下,线程获取锁会将markword复制到自己的线程栈中,并将对象头中markword替换为指向锁记录的指针,若成功就获取了锁,若失败就自旋获取锁。当锁释放事,线程尝试用CAS操作将对象头部分恢复为markword,若失败,说明存在锁竞争,膨胀为重量级锁。
原子更新基本类型类
AtomicBoolean:原子更新布尔类型
AtomicInteger:原子更新整型
AtomicLong:原子更新长整型
原子方法:
int addAndGet(int) 将输入值与实例值相加,并返回结果
boolean compareAndSet(int expect,int update)如果等于预期值,则更新
int getAndIncrement() 自增一,并返回
void lazySet(int) 延迟设值
int getAndSet(int) 设为参数值,并返回旧值
传入构造器
原子更新**数组**
AtomicIntegerArray 原子更新整形数组中元素
AtomicLongArray 原子更新长整型数组里的元素
AtomicReferenceArray 原子更新引用数组里的元素
例如AtomicIntegerArray类方法
int addAndGet(int i,int delta ) 以原子方式将输入值与数组中索引i的元素相加
boolean compareAndSet(int i,int expect,int update) 如果等于预期值,则将i角标元素设成update值
传入构造器
注意 : 当数组通过构造传入原子更新数组类,原子类会复制一份数组,所以更新不影响原本传入的数组
原子更新引用
AtomicReference 原子更新引用类型
AtomicReferenceFeildUpdater 原子更新引用类型字段
AtomicMarkableReference 原子更新带有标记为的引用类型
对象引用set进原子类
原子更新字段类
AtomicIntegerFieldUpdater 原子更新整型的字段更新器
AtomicLongFieldUpdater 原子更新长整型字段的更新器
AtomicStampedReference 原子更新带有版本号的引用类型,防止ABA
atomic原子类
\1. 原子类由CAS操作保证原子性,由volatile关键字保证可见性。
2.可以粗略分成五类:
1.整型、长整型、布尔型、引用类型的原子类
AtomicInteger、AtomicLong、AtomicBoolean、AtomicReference
2.整型数组、长整型数组、引用数组的原子类
AtomicIntegerArray、AtomicLongArray、AtomicReferenceArray
3.整型字段、长整型字段、引用字段更新的原子类
AtomicIntegerFieldUpdater、AtomicLongFieldUpdater、AtomicReferenceFieldUpdater
4.解决ABA问题的原子类
AtomicMarkableReference、AtomicStampedReference
5.jdk 1.8新增的更高性能的原子累加器
LongAdder、DoubleAdder、LongAccumulator、DoubleAccumulator
3.原子类的底层操作都是通过Unsafe类完成,每个原子类内部都有一个Unsafe类的静态引用。Unsafe类中大部分都是native方法。
private static final Unsafe unsafe = Unsafe.getUnsafe();
AtomicInteger内部由一个int域来保存值,其由volatile关键字修饰,用于保证可见性。类似的,AtomicLong内部是一个long型的value,AtomicBoolean内部也是一个int,但其只会取值0或1。
private volatile int value;
AtomicInteger中有一个**compareAndSet方法,通过CAS对变量进行原子更新。它通过调用Unsafe的native函数实现:unsafe.compareAndSwapInt(this, valueOffset, expect, update)。**
多线程编程序需要注意的地方
\1. 对临界区数据的同步操作
\2. 数据库连接尽量使用连接池
\3. 保证不出现死锁现象。
死锁:两个或更多线程阻塞着等待其它处于死锁状态的线程所持有的锁。死锁通常发生在多个线程同时但以不同的顺序请求同一组锁的时候,死锁会让你的程序挂起无法完成任务。
生产者消费者模式说明:
\1. 生产者只在仓库未满时进行生产,仓库满时生产者进程被阻塞;
\2. 消费者只在仓库非空时进行消费,仓库为空时消费者进程被阻塞;
\3. 当消费者发现仓库为空时会通知生产者生产;
\4. 当生产者发现仓库满时会通知消费者消费;
实现的关键:
共享内存中的两个同步方法,及同步方法中wait()方法的调用。
synchronized 保证了对象只能被一个线程占用。
wait 保证了当线程在等待过程中释放锁,使得其他对象有机会获得锁。
用wait/notify/notifyAll实现和用Lock的Condition实现。
用wait/notify/notifyAll 实现生产者消费者模型:
高并发情况的解决方案
1、尽量使用缓存技术来做。用户缓存,页面缓存等一切缓存,使用特定的机制进行刷新。利用消耗内存空间来换取用户的效率,同时减少数据库的访问次数。
2、把数据库的查询语句进行优化,一般复杂的SQL语句就不要使用ORM框架自带的做法来写,采用自己来写SQL,例如hibernate的hql中的复杂语句就会很耗时。
3、优化数据库的表结构,在关键字、主键、访问率极高的字段中加入索引。但尽量只是在数字类型上面加,因为使用字段is null 的时候,索引的效果就会失效。
4、报表统计的模块,尽量使用定时任务执行,如果非要实时进行刷新,那么就可以采用缓存来做数据。
5、可以使用静态页面的地方,尽量使用静态页面,减少页面的解析时间。同时页面中的图片过多时,可以考虑把图片单独做成一个服务器,这样可以减少业务服务器的压力。
6、使用集群的方式来解决单台服务器的性能问题。
7、把项目拆分成多个应用小型服务器的形式来进行部署。采用数据同步机制(可以使用数据库同步形式来做)达到数据一致性。
8、使用负载均衡模式来让每一个服务器资源进行合理的利用。
9、缓存机制中,可以使用redis来做内存数据库缓存起来。也可以使用镜像分担,这样可以让两台服务器进行访问,提高服务器的访问量。
四、反射
1.什么是反射?
反射
反射是什么:指程序可以访问、检测和修改它本身状态或行为的一种能力。能够直接操作内部属性,从而写出灵活的代码
反射能干什么:在运行时判断一个对象所属的类;在运行时构建任意一个类所属的对象;在运行时判断任意一个类所具有的成员变量和方法;在运行时调用任意一个对象的方法;生成动态代理。
反射的作用:
1、动态地创建类的实例,将类绑定到现有的对象中,或从现有的对象中获取类型。
2、应用程序需要在运行时从某个特定的程序集中载入一个特定的类
反射原理:类的加载是指将类的.class文件中的二进制数据读入到内存中,将其放在运行时数据区的方法区里面,然后在堆区创建一个java.lang.Class的对象,用于封装类在方法区内的数据结构!我们知道我们对于一个类可以创建很多个对象,但是这些对象共享同样的数据结构,而这个数据结构就是在 加载过程中创建的这个class对象。我们可以通过类名.class或者对象名.getClass()获取这个对象!无论创建了多少个实例对象,这个class的对象始终只有一个,类里面所有的结构都可以通过class对象获取,因此class对象就像一面镜子一样,可以反射一个类的内存结构,因此class是整个反射的入口!通过class对象我们可以反射的获取某个对象的数据结构,访问对应数据结构中的数据!
类的加载的最终产品是位于堆(heap)中的class对象
(1)反射的概述
JAVA反射机制是在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法;对于任意一个对象,都能够调用它的任意一个方法和属性;这种动态获取的信息以及动态调用对象的方法的功能称为java语言的反射机制。
要想解剖一个类,必须先要获取到该类的字节码文件对象。而解剖使用的就是Class类中的方法.所以先要获取到每一个字节码文件对应的Class类型的对象.
以上的总结就是什么是反射
反射就是把java类中的各种成分映射成一个个的Java对象
例如:一个类有:成员变量、方法、构造方法、包等等信息,利用反射技术可以对一个类进行解剖,把个个组成部分映射成一个个对象
(2)使用反射的步骤
1.步骤
获取想要操作的类的Class对象
调用Class类中的方法
使用反射API来操作这些信息
2.获取Class对象的方法
调用某个对象的getClass()方法
Person p=new Person(); Class clazz=p.getClass();
调用某个类的class属性来获取该类对应的Class对象
Class clazz=Person.class;
使用Class类中的forName()静态方法; (最安全/性能最好)**为什么?**
Class clazz=Class.forName("类的全路径"); (最常用)
3.获取方法和属性信息
当我们获得了想要操作的类的Class对象后,可以通过Class类中的方法获取并查看该类中的方法和属性。
2.什么是 java 序列化?什么情况下需要序列化?
Java序列化是指把Java对象转换为字节序列的过程;而Java反序列化是指把字节序列恢复为Java对象的过程。该字节序列包括该对象的数据、有关对象的类型的信息和存储在对象中数据的类型。
作用:实现进程间的对象传送,发送方需要把这个Java对象转换为字节序列,然后在网络上传送;另一方面,接收方需要从字节序列中恢复出Java对象。
序列化的好处:
一:是实现了数据的持久化,通过序列化可以把数据永久地保存到硬盘上(通常存放在文件里)
二:利用序列化实现远程通信,即在网络上传送对象的字节序列。
实现:实现了Externalnalizable接口
一个java中的类只有实现了Serializable接口,它的对象才是可序列化的。如果要序列化某些类的对象,这些类就必须实现Serializable接口。Serializable是一个空接口,没有什么具体内容,它的目的只是简单的标识一个类的对象可以被序列化。
为什么要进实现Serializable接口:为了保存在内存中的各种对象的状态(也就是实例变量,不是方法),并且可以把保存的对象状态再读出来,这是java中的提供的保存对象状态的机制—序列化。
在什么情况下需要使用到Serializable接口呢? 1、当想把的内存中的对象状态保存到一个文件中或者数据库中时候; 2、当想用套接字在网络上传送对象的时候;
3、当想通过RMI传输对象的时候;
序列化和反序列化
1.**什么是序列化:**
序列化是一种将对象以一连串的字节描述的过程;
Java平台允许我们在内存中创建可复用的Java对象,使用Java对象序列化,在保存对象时,会把其状态保存为一组字节,在未来,再将这些字节组装成对象。必须注意地是,对象序列化保存的是对象的”状态”,即它的成员变量。由此可知,对象序列化不会关注类中的静态变量。
反序列化是一种将这些字节重建成一个对象的过程。
2.**序列化的必要性:应用**
对象的序列化主要有两种用途:
1) 把对象的字节序列永久地保存到硬盘上,通常存放在一个文件中;
2) 在网络上传送对象的字节序列。
当两个进程在进行远程通信时,彼此可以发送各种类型的数据。无论是何种类型的数据,都会以二进制序列的形式在网络上传送。发送方需要把这个Java对象转换为字节序列,才能在网络上传送;接收方则需要把字节序列再恢复为Java对象。
Java序列化机制就是为了解决这个问题而产生。
3.**如何序列化一个对象?实现:**
一个对象能够序列化的前提是实现Serializable接口,Serializable接口没有方法,更像是个标记。
有了这个标记的Class就能被序列化机制处理。
因为声明实现 Serializable 接口后保存读取对象就可以使用 ObjectOutputStream、ObjectInputStream 流了,ObjectOutputStream 的 writeObject(Object obj) 方法将对象转化为字节写到流中,ObjectInputStream 的 readObject() 方法从流中读取字节转为对象,Serializable 虽然是一个空接口,但是在调用 writeObject 方法时却充当了一种健全的校验作用,如果对象没有实现 Serializable 则在调用 writeObject 时就会抛出异常,所以说 Serializable 算是一种接口标识机制。,**序列化和反序列化的实质在于 ObjectOutputStream 的 writeObject 和 ObjectInputStream 的 readObject 方法实现,常见的 String、Date、Double、ArrayList、LinkedList、HashMap、TreeMap 等都默认实现了 Serializable。**
4.**Java中序列化ID的作用:**
简单来说,Java的序列化机制是通过在运行时判断类的serialVersionUID来验证版本一致性的。在进行反序列化时,JVM会把传来的字节流中的serialVersionUID与本地相应实体(类)的serialVersionUID进行比较,如果相同就认为是一致的,可以进行反序列化,否则就会出现序列化版本不一致的异常。
序列化及反序列化相关知识
1、在Java中,只要一个类实现了java.io.Serializable接口,那么它就可以被序列化。
2、通过ObjectOutputStream和ObjectInputStream对对象进行序列化及反序列化
3、虚拟机是否允许反序列化,不仅取决于类路径和功能代码是否一致,一个非常重要的一点是两个类的序列化 ID 是否一致(就是 private static final long serialVersionUID)
4、序列化并不保存静态变量。
5、要想将父类对象也序列化,就需要让父类也实现Serializable 接口。
6、Transient 关键字的作用是控制变量的序列化,在变量声明前加上该关键字,可以阻止该变量被序列化到文件中,在被反序列化后,transient 变量的值被设为初始值,如 int 型的是 0,对象型的是 null。
7、服务器端给客户端发送序列化对象数据,对象中有一些数据是敏感的,比如密码字符串等,希望对该密码字段在序列化时,进行加密,而客户端如果拥有解密的密钥,只有在客户端进行反序列化时,才可以对密码进行读取,这样可以一定程度保证序列化对象的数据安全。
问:Serializable 是一个空接口,为什么实现它就可以序列化,有啥作用?
答:
子类实现 Serializable 接口而父类未实现时,父类不会被序列化,也不会报序列化错误,但是如果父类没有默认构造方法则在反序列化时会出异常
五、对象拷贝
1.为什么要使用克隆?
很重要并且常见的常见就是:某个API需要提供一个List集合,但是又不希望调用者的修改影响到自身的变化,因此需要克隆一份对象,以此达到数据隔离的目的。
2.如何实现对象克隆?
3.深拷贝和浅拷贝区别是什么?
浅拷贝:按位拷贝对象,它会创建一个新对象,这个对象有着原始对象属性值的一份精确拷贝。如果属性是基本类型,拷贝的就是基本类型的值;如果属性是内存地址(引用类型),拷贝的就是内存地址 ,因此如果其中一个对象改变了这个地址,就会影响到另一个对象。
深拷贝:会拷贝所有的属性,并拷贝属性指向的动态分配的内存。当对象和它所引用的对象一起拷贝时即发生深拷贝。深拷贝相比于浅拷贝速度较慢并且花销较大。
object.clone默认实现的是浅复制。
浅拷贝和深拷贝得理解:定义一个数组int[] a={3,1,4,2,5}; int[] b=a; 数组b只是对数组a的又一个引用,即浅拷贝。 如果改变数组b中元素的值,其实是改变了数组a的元素的值,要实现深度复制,可以用clone或者System.arrayCopy clone和System.arrayCopy都是对一维数组的深度复制;因为java中没有二维数组的概念,只有数组的数组。所以二维数组a中存储的实际上是两 个一维数组的引用。当调用clone函数时,是对这两个引用进行了复制。
深浅复制的概念
浅度克隆:被复制对象(一个新的对象实例)的所有变量都含有与原来的对象相同的值,对于基本数据类型的属性复制一份给新产生的对象,对于非基本数据类型的属性仅仅复制一份引用给新产生的对象(新实例中引用类型属性还是指向原来对象引用类型属性)。
深度克隆:被复制对象(一个新的对象实例)的所有变量都含有与原来的对象相同的值,而那些引用其他对象的变量将指向被复制过的新对象(新内存空间),而不再是原有的那些被引用的对象,换言之深度克隆把要复制的对象所引用的对象都复制了一遍,也就是在浅度克隆的基础上,对于要克隆的对象中的非基本数据类型的属性对应的类也实现克隆,这样对于非基本数据类型的属性复制的不是一份引用。
B、深克隆与浅克隆的区别:深克隆的过程是通过序列化来完成的,而序列化的过程可以将对象及所牵涉的所有引用链中的对象一起通过字节流的方式转移到特定的存储单元中(这个存储单元可以是内存也可以是硬盘,对于克隆通常是序列化至内存),再通过反序列化的过程读出这些序列化的字节流重构出对象,这样就完成了一个新对象的产生。而浅克隆不用序列化,这种克隆方式仅仅只是将指定的当前对象复制出来一个,这种复制过程不包括原对象引用的各个对象
C、克隆出的对象与原对象具有相同的属性及方法,但克隆的对象与原对象是属于两个不同的独立对象,因此二者占据内存中不同的空间地址。这就好比两个人长的极为相像但他们毕竟还是属于两个人,可以住在不同的场所。
六、Java Web
网络编程:
网络
Java.net包中J2E的API包含有类和接口,他们提供低层次的通信细节。你可以直接使用这些类和接口,来专注于解决问题,而不用关注通信细节。
物理层:激活、维持、关闭通信端点之间的机械特性、电气特性、功能特性以及过程特性。该层为上层协议提供了一个传输数据的物理媒体。
数据链路层:数据链路层在不可靠的物理介质上提供可靠的传输。该层的作用包括:物理地址寻址、数据的成帧、流量控制、数据的检错、重发等。
网络层:网络层负责对子网间的数据包进行路由选择。此外,网络层还可以实现拥塞控制、网际互连等功能。
传输层:第一个端到端,即主机到主机的层次。传输层负责将上层数据分段并提供端到端的、可靠的或不可靠的传输。此外,传输层还要处理端到端的差错控制和流量控制问题。
会话层:会话层管理主机之间的会话进程,即负责建立、管理、终止进程之间的会话。会话层还利用在数据中插入校验点来实现数据的同步。
表示层:表示层对上层数据或信息进行变换以保证一个主机应用层信息可以被另一个主机的应用程序理解。表示层的数据转换包括数据的加密、压缩、格式转换等。
应用层:为操作系统或网络应用程序提供访问网络服务的接口。
七层模型和协议的对应关系:
1.网络层:---------------------IP(网络之间的互联协议)
2.传输层:--------------------------TCP(传输控制协议),UDP(用户数据报协议)
3.应用层:------------------------------Telnet(Internet远程登陆服务的标准协议和主要方式),FTP(文本传输协议),HTTP(超文本传送协议)
网络编程三要素:
1):IP地址.
2):端口.
3):协议:规则,数据传递/交互规则.
HTTP
HTTP:超文本传输协议,HTTP允许传输任意类型的数据对象。基于TCP/IP通信协议来传递数据,使用的语言为HTML(HyperText Markup Language)超文本标记语言,它是一个世界语言(唯一的语言)
请求消息服务器会得到的数据有:
请求行(request line)、请求头部(header)、空行和请求数据四个部分组成。
1.请求行:
请求方式:两种GET、POST
请求的资源路径
HTTP协议版本:两种:1.0和1.1 且两者差异较大
2.请求消息头,属性名,属性值
3.请求体(与请求头之间必须有空行 为HTTP分段的依据(规定))
响应消息浏览器会收到的数据:
由四个部分组成,分别是:状态行、消息报头、空行和响应正文。
编程中的网络结构:
1.c/s client/server
特点:
该结构的软件,服务器端和客户端都需要编写。
开发成本较高,维护较为麻烦。
优点:
客户端在本地可以分担一些运算。
2.B/S browser/server
特点:
该结构的软件,只开发服务器端,不开发客户端,因为客户端直接由浏览器取代。
开发成本相对较低,维护更为简单;
缺点:
所有的运算都要在服务器端完成。
状态代码:由三位数字组成,第一个数字为响应类别,共5种
1XX:指示信息--表示请求已接受,继续处理
2XX:成功,表示请求已被成功接收,理解,接受(200,请求成功)
3XX:重定向,要完成请求必须进行更进一步的操作
4XX:客户端错误--请求有语法错误或请求无法实现(404,页面未找到,请求资源不存在,输入错误)
5XX:服务器端错误,服务器未能实现合法请求(500,发生不可预期错误)
URL
从JDK1.5开始,java.net包对统一资源定位符(uniform resource locator URL)和统一资源标识符(uniform resource identifier URI)作了非常有用的区分。
URI是个纯粹的句法结构,用于指定标识Web资源的字符串的各个不同部分。URL是URI的一个特例,它包含了定位Web资源的足够信息。
在Java类库中,URI类不包含任何访问资源的方法,它唯一的作用就是解析。相反的是,URL类可以打开一个到达资源的流。因此URL类只能作用于那些 Java类库知道该如
何处理的模式。
URN函数就像是一个人的名字,URL就像是一个人的住址.换句话说就是URN提供定义,而URL就是提供一个方法来找到它.
URI**:**统一资源标识符(uniform resource identifier)
Web上可用的每种资源如HTML文档、图像、视频片段、程序等都是一个来URI来定位的。
URI一般由三部组成:
1.访问资源的命名机制
2.存放资源的主机名
3.资源自身的名称,由路径表示,着重强调于资源。
例如:/ServletDemo/mydemo3
URN:统一资源名称 (Uniform Resource Name)
唯一标识一个实体的标识符,但是不能给出实体的位置。系统可以先在本地寻找一个实体,在它试着在Web上找到该实体之前。它也允许Web位置改变,然而这个实体却还是能够被找到。
标识持久性Internet资源。URN可以提供一种机制,用于查找和检索定义特定命名空间的架构文件。尽管普通的URL可以提供类似的功能,但是在这方面,URN更加强
大并且更容易管理,因为URN可以引用多个URL。
与URL不同,URN与地址无关。URN和URL都属于URI。
统一资源标识符(Uniform Resource Identifier,或URI)是一个用于标识某一互联网资源名称的字符串。由:协议,IP地址,端口号,文件名,操作数
例如:http://example.org/wiki/Main_Page 代表了以HTML的形式通过http协议获取example.org主机地址的/wiki/Main_Page资源.
URL为最常见的URI
两者区别:URI表示资源是什么,URL表示资源的具体位置,URI是URL的抽象。Java中URL对象对应网络获取的应用层协议的一个表示,而URI对象纯粹用于解析和处理字符串。
URL:统一资源定位符(uniform resource locator)
URL是Internet上用来描述信息资源的字符串,主要用在各种WWW客户程序和服务器程序上,特别是著名的Mosaic。
采用URL可以用一种统一的格式来描述各种信息资源,包括文件、服务器的地址和目录等。
URL一般由三部组成:
1.协议(或称为服务方式)
2.存有该资源的主机IP地址(有时也包括端口号)
3.主机资源的具体地址。如目录和文件名等
例如:http://localhost:8080/ServletDemo/mydemo3
由:协议,IP地址,端口号(与IP用冒号相连),文件名,(?之后的都是操作数())操作数
例如:http://example.org/wiki/Main_Page 代表了以HTML的形式通过http协议获取example.org主机地址的/wiki/Main_Page资源.
绝对URL
protocol://userInfo@host:port/path?query#fragment
host 提供所需资源服务器的名字(主机/服务器IP地址)
userInfo 可选,服务器登录信息
port 可选,服务在其默认端口运行,无需此部分
path :指定服务器上的一个特定目录 文件系统,路径相对于服务器的文档根目录,向公众开放的服务器不会将其整个文件系统展示给客户端,而只是展示指定目录中的内容
query 向服务器提供附加参数,一般只在http URL中使用,其中包含表单数据,作为输入提供给服务端的运行程序
fragment 指向远程资源的某个特定部分 HTML 锚 XML XPointer 段 ref 片段标识符在HTML文档中用id属性创建
包含片段标识符的是URL引用,不是URL
相对URL 继承了父文档部分信息的URL
在相对URL中,缺少的各部分都与所在文档的URL中对应的部分相同
例如浏览http://www.ibiblio.org/java/faq/javatutoial.html时
相当于http://www.ibiblio.org/java/faq/javafaq.html
则相当于http://www.ibiblio.org/projects/ipv61
URLEncoder 转码类
URLDecoder 解码
构造器:
public URL(String spec) 根据 String 表示形式创建 URL 对象。
public URL(String protocol,String host,int port ,String file)
常用方法:
public String getPath() { //返回路径
return path;
}
public String getProtocol() { //协议
return protocol;
}
public int getPort() { //端口号
return port;
}
public String getFile() { //文件
return file;
}
public String getRef() { url引用
return ref;
}
InputStream openStream() 打开到此 URL 的连接并返回一个用于从该连接读入的 InputStream。(相当于url.openConnection().getInputStream()的简写)用此流可读取服务器端,返回的相应消息
URLConnection:url连接器对象,将连接封装成了对象
获取一个URL的URLConnection:
url.openConnection();
getInputStream() 返回URL的输入流,用于读取资源
getOutputStream() 返回URL的输出流,用于写入资源
基础知识
IP地址和端口号
IP地址:互联网协议地址(Internet Protocol Address) ,是IP Address的缩写.主要为计算机网络相互连接进行通信而设计的协议。
在因特网中,它是能使连接到网上的所有计算机网络实现相互通信的一套规则,规定了计算机在因特网上进行通信时应当遵守的规则。任何厂家生产的计算机系统,只要遵守IP协议就可以与因特网互连互通。
IP地址被用来给Internet上的电脑一个编号。
IP地址是一个32位的二进制数,通常被分割为4个“8位二进制数”(也就是4个字节)。IP地址通常用“点分十进制”表示成(a.b.c.d)的形式,其中,a,b,c,d都是0~255之间的十进制整数。例:点分十进IP地址(100.4.5.6),实际上是32位二进制数(01100100.00000100.00000101.00000110)。
Internet委员会定义了5种IP地址类型以适合不同容量的网络,即A类~E类。
| 类别 | 最大网络数 | IP地址范围 | 最大主机数 | 私有IP地址范围 |
|---|---|---|---|---|
| A | 126(2^7-2) | 0.0.0.0-127.255.255.255 | 16777214 | 10.0.0.0-10.255.255.255 |
| B | 16384(2^14) | 128.0.0.0-191.255.255.255 | 65534 | 172.16.0.0-172.31.255.255 |
| C | 2097152(2^21) | 192.0.0.0-223.255.255.255 | 254 | 192.168.0.0-192.168.255.255 |
特殊的网址:
每一个字节都为0的地址(“0.0.0.0”)对应于当前主机;
IP地址中的每一个字节都为1的IP地址(“255.255.255.255”)是当前子网的广播地址;
IP地址中凡是以“11110”开头的E类IP地址都保留用于将来和实验使用。
IP地址中不能以十进制“127”作为开头,该类地址中数字127.0.0.1到127.255.255.255用于回路测试,如:127.0.0.1可以代表本机IP地址,用“http://127.0.0.1”就可以测试本机中配置的Web服务器。
网络ID的第一个8位组也不能全置为“0”,全“0”表示本地网络。
在Java中对应有对象,
端口号:端口包括物理端口和逻辑端口。
物理端口:是用于连接物理设备之间的接口,
逻辑端口:是逻辑上用于区分服务的端口。
TCP/IP协议中的端口就是逻辑端口,通过不同的逻辑端口来区分不同的服务。一个IP地址的端口通过16bit进行编号,最多可以有65536个端口。端口是通过端口号来标记的,端口号只有整数,范围是从0 到65535。
端口有什么用呢?我们知道,一台拥有IP地址的主机可以提供许多服务,比如Web服务、FTP服务、SMTP服务等,这些服务是1个IP地址来实现。主机是通过“IP地址+端口号”来区分不同的服务的。
端口号小于256的定义为常用端口(不可自定义),服务器一般都是通过常用端口号来识别的。
任何TCP/IP实现所提供的服务都用1---1023之间的端口号,是由ICANN来管理的;客户端只需保证该端口号在本机上是惟一的就可以了。
客户端口号因存在时间很短暂又称临时端口号;大多数TCP/IP实现给临时端口号分配1024---5000之间的端口号。大于5000的端口号是为其他服务器预留的。
对servlet的个人理解
一、什么是Servlet
1.servlet是一个基于Java技术的动态网页技术,运行在服务器端,由Servlet容器Tomcat管理,用于生成动态内容,他也是jsp的前身。
2.Servlet本质就是实现了特定的接口的java类,编写一个servlet',实际就是按照Servlet规范编写了一个java类。下来就是说如何实现这个Servlet,可以直接或间接实现servlet这个接口
Servlet的实现
l 实现Servlet接口。要实现5个方法,3个生命周期有关的方法,init、service、destory、getServletInfo、getServletConfig
l 继承GenericServlet。 只需要重写service即可。
l 继承HttpServlet。 重写doget dopost方法。
servlet生命周期
1,初始化阶段:Servlet被装载后,Servlet容器创建一个Servlet实例并且调用Servlet的init()方法进行初始化。在Servlet的整个生命周期内,init()方法只被调用一次。 ////当web.xml文件中如果
2, 响应客户请求阶段 客户发送一个请求,Servlet是调用service()方法对请求进行响应的,通过源代码可见,service()方法中对请求的方式进行了匹配,选择调用doGet,doPost等这些方法,然后再进入对应的方法中调用逻辑层的方法,实现对客户的响应。
3,终止阶段: 当WEB应用被终止,或Servlet容器终止运行,或Servlet容器重新装载Servlet新实例时,Servlet容器会先调用Servlet的destroy()方法,在destroy()方法中可以释放掉Servlet所占用的资源。
Servlet被服务器实例化后,容器运行其init方法,请求到达时运行其service方法,service方法自动派遣运行与请求对应的doXXX方法(doGet,doPost)等,当服务器决定将实例销毁的时候调用其destroy方法。
servlet在多线程下其本身并不是线程安全的。
如果在类中定义成员变量,而在service中根据不同的线程对该成员变量进行更改,那么在并发的时候就会引起错误。最好是在方法中,定义局部变量,而不是类变量或者对象的成员变量。由于方法中的局部变量是在栈中,彼此各自都拥有独立的运行空间而不会互相干扰,因此才做到线程安全。
Servlet是线程不安全的,在Servlet类中可能会定义共享的类变量,这样在并发的多线程访问的情况下,不同的线程对成员变量的修改会引发错误。
init方法: 是在servlet实例创建时调用的方法,用于创建或打开任何与servlet相的资源和初始 化servlet的状态,Servlet规范保证调用init方法前不会处理任何请求
service方法:是servlet真正处理客户端传过来的请求的方法,由web容器调用, 根据HTTP请求方法(GET、POST等),将请求分发到doGet、doPost等方法
destory方法:是在servlet实例被销毁时由web容器调用。Servlet规范确保在destroy方法调用之 前所有请求的处理均完成,需要覆盖destroy方法的情况:释放任何在init方法中 打开的与servlet相关的资源存储servlet的状态
1.jsp 和 servlet 有什么区别?
一、Servlet是什么?JSP是什么?它们的联系与区别是什么?
1、什么是Servet?
Servlet,就是编写在服务器端创建对象的Java类,习惯上称为Servlet类,
简单的说,Servlt就是嵌入了HTML的Java类
2、什么是JSP?
java服务器页面,简单点来说,JSP就是嵌入了Java代码的HTML;
jsp只是servlet的一个变种,方便书写html内容才出现的。servlet是根本,所有jsp能做
的,servlet全能做。
运行过程的区别:
· 客户在第一次请求JSP时,JSP Engine先把JSP程序转换成servlet代码(JSP本质上是servlet),接着将他编译成类文件,以后每次对此类文件执行;
· 访问servlet时,可以直接对其编译好的类文件执行。
程序组成的区别**:**
· 在Html中内嵌java代码组成jsp文件;
· servlet是由纯java代码组成。
主要职能的区别:
· jsp主要负责页面效果展现
· servlet主要负责逻辑控制
============================================================================
JSP 在本质上就是 SERVLET,但是两者的创建方式不一样.Servlet 完全是 JAVA 程序代码构成,擅长于流程控制和事务处理,通过 Servlet来生成动态网页很不直观.JSP 由 HTML 代码和 JSP 标签构成,可以方便地编写动态网页.因此在实际应用中采用 Servlet 来控制业务流程,而采用 JSP 来生成动态网页.
Servlet是一个特殊的Java程序,它运行于服务器的JVM中,能够依靠服务器的支持向浏览器提供显示内容。
JSP本质上是Servlet的一种简易形式,JSP会被服务器处理成一个类似于Servlet的Java程序,可以简化页面内容的生成。
Servlet和JSP最主要的不同点在于,Servlet的应用逻辑是在Java文件中,并且完全从表示层中的HTML分离开来。而JSP的情况是Java和HTML可以组合成一个扩展名为.jsp的文件。有人说,Servlet就是在Java中写HTML,而JSP就是在HTML中写Java代码,当然这个说法是很片面且不够准确的。
JSP侧重于视图,Servlet更侧重于控制逻辑,在MVC架构模式中,JSP适合充当视图(view)而Servlet适合充当控制器(controller)。
jsp和servlet的区别、共同点、各自应用的范围?
JSP是Servlet技术的扩展,本质上就是Servlet的简易方式。JSP编译后是“类servlet”。
Servlet和JSP最主要的不同点在于:Servlet的应用逻辑是在Java文件中,并且完全从表示层中的HTML里分离开来。而JSP的情况是Java和HTML可以组合成一个扩展名为.jsp的文件。
JSP侧重于视图,Servlet主要用于控制逻辑。在struts框架中,JSP位于MVC设计模式的视图层,而Servlet位于控制层.
JSP 在本质上就是 SERVLET,但是两者的创建方式不一样.Servlet 完全是 JAVA 程序代码构成,擅长于流程控制和事务处理,通过 Servlet来生成动态网页很不直观.JSP 由 HTML 代码和 JSP 标签构成,可以方便地编写动态网页.因此在实际应用中采用 Servlet 来控制业务流程,而采用 JSP 来生成动态网页.
Servlet是一个特殊的Java程序,它运行于服务器的JVM中,能够依靠服务器的支持向浏览器提供显示内容。
JSP本质上是Servlet的一种简易形式,JSP会被服务器处理成一个类似于Servlet的Java程序,可以简化页面内容的生成。
Jsp只会在客户端第一次发请求的时候被编译,之后的请求不会再编译,同时tomcat能自动检测jsp变更与否,变更则再进行编译。
第一次编译并初始化时调用: init() ;销毁调用: destroy() 。在整个jsp生命周期中均只调用一次。
servlet生命周期:init 、service、destory
除了init只初始化一次外、其他 用户端运行JSP时方法都会运行一次
JSP内置对象有: 1.request对象 客户端的请求信息被封装在request对象中,通过它才能了解到客户的需求,然后做出响应。它是HttpServletRequest类的实例。 2.response对象 response对象包含了响应客户请求的有关信息,但在JSP中很少直接用到它。它是HttpServletResponse类的实例。 3.session对象 session对象指的是客户端与服务器的一次会话,从客户连到服务器的一个WebApplication开始,直到客户端与服务器断开连接为止。它是HttpSession类的实例. 4.out对象 out对象是JspWriter类的实例,是向客户端输出内容常用的对象 5.page对象 page对象就是指向当前JSP页面本身,有点象类中的this指针,它是java.lang.Object类的实例 6.application对象 application对象实现了用户间数据的共享,可存放全局变量。它开始于服务器的启动,直到服务器的关闭,在此期间,此对象将一直存在;这样在用户的前后连接或不同用户之间的连接中,可以对此对象的同一属性进行操作;在任何地方对此对象属性的操作,都将影响到其他用户对此的访问。服务器的启动和关闭决定了application对象的生命。它是ServletContext类的实例。 7.exception对象 exception对象是一个例外对象,当一个页面在运行过程中发生了例外,就产生这个对象。如果一个JSP页面要应用此对象,就必须把isErrorPage设为true,否则无法编译。他实际上是java.lang.Throwable的对象 8.pageContext对象 pageContext对象提供了对JSP页面内所有的对象及名字空间的访问,也就是说他可以访问到本页所在的SESSION,也可以取本页面所在的application的某一属性值,他相当于页面中所有功能的集大成者,它的本 类名也叫pageContext。 9.config对象 config对象是在一个Servlet初始化时,JSP引擎向它传递信息用的,此信息包括Servlet初始化时所要用到的参数(通过属性名和属性值构成)以及服务器的有关信息(通过传递一个ServletContext对象)
service()方法是接收请求,返回响应的方法。每次请求都执行一次,该方法被HttpServlet封装为doGet和doPost方法
Servlet和JSP最主要的不同点在于,Servlet的应用逻辑是在Java文件中,并且完全从表示层中的HTML分离开来。而JSP的情况是Java和HTML可以组合成一个扩展名为.jsp的文件。有人说,Servlet就是在Java中写HTML,而JSP就是在HTML中写Java代码,当然这个说法是很片面且不够准确的。
JSP侧重于视图,Servlet更侧重于控制逻辑,在MVC架构模式中,JSP适合充当视图(view)而Servlet适合充当控制器(controller)。
ServletContext对象:servlet容器在启动时会加载web应用,并为每个web应用创建唯一的servlet context对象,可以把ServletContext看成是一个Web应用的[服务器]端组件的共享内存,在ServletContext中可以存放共享数据。ServletContext对象是真正的一个全局对象,凡是web容器中的Servlet都可以访问。
整个web应用只有唯一的一个ServletContext对象
servletConfig对象:用于封装servlet的配置信息。从一个servlet被实例化后,对任何客户端在任何时候访问有效,但仅对servlet自身有效,一个servlet的ServletConfig对象不能被另一个servlet访问。
Servlet的生命周期
1.加载:容器通过类加载器使用Servlet类对应的文件来加载Servlet
2.创建:通过调用Servlet的构造函数来创建一个Servlet实例
3.初始化:通过调用Servlet的init()方法来完成初始化工作,这个方法是在Servlet已经被创建,但在向客户端提供服务之前调用。
4.处理客户请求:Servlet创建后就可以处理请求,当有新的客户端请求时,Web容器都会创建一个新的线程来处理该请求。接着调用Servlet的
Service()方法来响应客户端请求(Service方法会根据请求的method属性来调用doGet()和doPost())
5.卸载:容器在卸载Servlet之前需要调用destroy()方法,让Servlet释放其占用的资源。
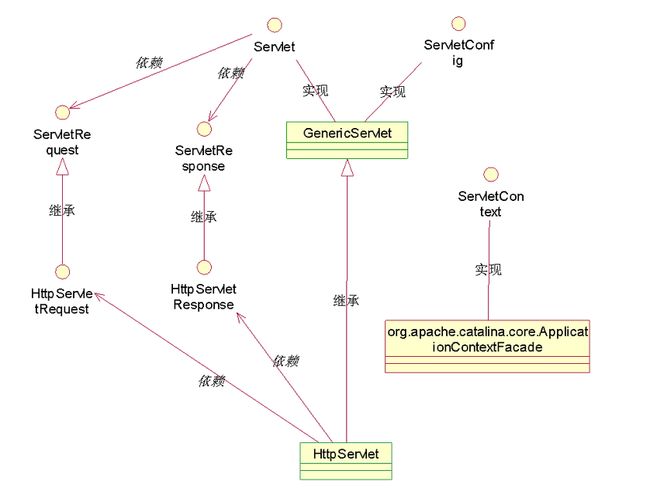
2.JSP有哪些内置对象,作用分别是什么?rrppcaose
· request:封装客户端的请求,其中包含post/get请求的参数
· response:封装服务端对客户做出的响应
· pageContext:可以用它来获取其他对象
· page:当前JSP页,相当于java程序的this
· config:封装web应用的配置文件
· appication:封装服务器运行时的环境
· out:输出服务器端响应的输出流对象
· session:封装用户会话的对象
· exception:封装页面抛出的异常
· 补充:用servlet来生成动态网页的内容是很繁琐的,另一方面,html和文本都是硬编码,一旦修改就需要重新编译。
· jsp很好的解决了这个问题:他是Servlet的一个补充,可以专门用来为用户展示视图,而Servlet作为控制器专门负责处理用户请求并转发或重定向。
· -jsp其实也是一个Servlet,能够运行Servlet的容器一般也是JSP容器,可以提供JSP页面的运行环境,tomcat是一个Servler/jsp的容器。
· 第一次请求一个JSP页面时,Servlet/JSP容器首先将jsp页面转化成JSP页面实现类,这是一个实现了JspPage接口或者httpJspPage子接口的一个java类。
· jspPage接口实现是Servlet接口的一个子接口,因为每一个JSP都是一个Servlet,转化成功后,容器会编译Servlet类,之后容器加载和实例化Java的字节码
· 对同一个JSP页面做后续的操作时,容器会先查看这个JSP是否被修改过,如果有就会重新编译并执行。如果没有则执行内存中已经存在的Servlet实例,
Jsp
讲解JSP中的四种作用域。
答:JSP中的四种作用域包括page、request、session和application,具体来说:
- page代表与一个页面相关的对象和属性。
- request代表与Web客户机发出的一个请求相关的对象和属性。一个请求可能跨越多个页面,涉及多个Web组件;需要在页面显示的临时数据可以置于此作用域。
- session代表与某个用户与服务器建立的一次会话相关的对象和属性。跟某个用户相关的数据应该放在用户自己的session中。
- application代表与整个Web应用程序相关的对象和属性,它实质上是跨越整个Web应用程序,包括多个页面、请求和会话的一个全局作用域。
jsp静态包含和动态包含的区别
1、<%@include file="xxx.jsp"%>为jsp中的编译指令,其文件的包含是发生在jsp向servlet转换的时期,而
2、使用静态包含只会产生一个class文件,而使用动态包含会产生多个class文件
3、使用静态包含,包含页面和被包含页面的request对象为同一对象,因为静态包含只是将被包含的页面的内容复制到包含的页面中去;而动态包含包含页面和被包含页面不是同一个页面,被包含的页面的request对象可以取到的参数范围要相对大些,不仅可以取到传递到包含页面的参数,同样也能取得在包含页面向下传递的参数
2.jsp 有哪些内置对象?作用分别是什么?
exception是JSP九大内置对象之一,其实例代表其他页面的异常和错误。只有当页面是错误处理页面时,即isErroePage为 true时,该对象才可以使用。
request:封装客户端的请求,其中包含post/get请求的参数
response:封装服务端对客户做出的响应
pageContext:可以用它来获取其他对象
page:当前JSP页,相当于java程序的this
config:封装web应用的配置文件
appication:封装服务器运行时的环境
out:输出服务器端响应的输出流对象
session:封装用户会话的对象
exception:封装页面抛出的异常
补充:用servlet来生成动态网页的内容是很繁琐的,另一方面,html和文本都是硬编码,一旦修改就需要重新编译。
jsp很好的解决了这个问题:他是Servlet的一个补充,可以专门用来为用户展示视图,而Servlet作为控制器专门负责处理用户请求并转发或重定向。
-jsp其实也是一个Servlet,能够运行Servlet的容器一般也是JSP容器,可以提供JSP页面的运行环境,tomcat是一个Servler/jsp的容器。
第一次请求一个JSP页面时,Servlet/JSP容器首先将jsp页面转化成JSP页面实现类,这是一个实现了JspPage接口或者httpJspPage子接口的一个java类。
jspPage接口实现是Servlet接口的一个子接口,因为每一个JSP都是一个Servlet,转化成功后,容器会编译Servlet类,之后容器加载和实例化Java的字节码
对同一个JSP页面做后续的操作时,容器会先查看这个JSP是否被修改过,如果有就会重新编译并执行。如果没有则执行内存中已经存在的Servlet实例,
Jsp
3.说一下 jsp 的 4 种作用域?
JSP中的四种作用域包括page、request、session和application,具体来说:
- page代表与一个页面相关的对象和属性。
- request代表与Web客户机发出的一个请求相关的对象和属性。一个请求可能跨越多个页面,涉及多个Web组件;需要在页面显示的临时数据可以置于此作用域。
- session代表与某个用户与服务器建立的一次会话相关的对象和属性。跟某个用户相关的数据应该放在用户自己的session中。
- application代表与整个Web应用程序相关的对象和属性,它实质上是跨越整个Web应用程序,包括多个页面、请求和会话的一个全局作用域。
jsp静态包含和动态包含的区别
1、<%@include file="xxx.jsp"%>为jsp中的编译指令,其文件的包含是发生在jsp向servlet转换的时期,而
2、使用静态包含只会产生一个class文件,而使用动态包含会产生多个class文件
3、使用静态包含,包含页面和被包含页面的request对象为同一对象,因为静态包含只是将被包含的页面的内容复制到包含的页面中去;而动态包含包含页面和被包含页面不是同一个页面,被包含的页面的request对象可以取到的参数范围要相对大些,不仅可以取到传递到包含页面的参数,同样也能取得在包含页面向下传递的参数
4.session 和 cookie 有什么区别?
Cookie:
1.数据存放在客户的浏览器上
2.cookie不是很安全,别人可以分析存放在本地的COOKIE并进行COOKIE欺骗,如果主要考虑到安全应当使用session
Session:
1.数据存放在服务器上
2.session会在一定时间内保存在服务器上。当访问增多,会比较占用你服务器的性能,如果主要考虑到减轻服务器性能方面,应当使用COOKIE
3.所以:将登陆信息等重要信息存放为SESSION;其他信息如果需要保留,可以放在COOKIE中
5.说一下 session 的工作原理?
产生的原因:
浏览器和服务器采用http无状态的通讯,为了保持客户端的状态,使用session来达到这个目的。
服务器采用一个独一无二的标示session_id来标示不同的用户,不同的是:浏览器每次请求都会带上由服务器为它生成的session_id.
工作流程:
当客户端访问服务器时,服务器根据需求设置session,将会话信息保存在服务器上,同时将标示session的session_id传递给客户端浏览器,浏览器将这个session_id保存在内存中(还有其他的存储方式,例如写在url中),我们称之为无过期时间的cookie。浏览器关闭后,这个cookie就清掉了,它不会存在用户的cookie临时文件。 以后浏览器每次请求都会额外加上这个参数值,再服务器根据这个session_id,就能取得客户端的数据状态。
如果客户端浏览器意外关闭,服务器保存的session数据不是立即释放,此时数据还会存在,只要我们知道那个session_id,就可以继续通过请求获得此session的信息;但是这个时候后台的session还存在,但是session的保存有一个过期时间,一旦超过规定时间没有客户端请求时,他就会清除这个session。
存储机制
下面介绍一下session的存储机制,默认的session是保存在files中,即以文件的方式保存session数据。如果要做服务器的lvs,即多台server的话,我们一般使用memcached的方式session,否则会导致一些请求找不到session。
Session和cookie
https://blog.csdn.net/fangaoxin/article/details/6952954
什么是cookie?Session和cookie有什么区别?
服务端需要记录用户的状态时,就需要用某种机制来识具体的用户,这个机制就是Session.
Cookie是会话技术,将用户的信息保存到浏览器的对象.
联系:
每次HTTP请求的时候,客户端都会发送相应的Cookie信息到服务端。实际上大多数的应用都是用 Cookie 来实现Session跟踪的,第一次创建Session的时候,服务端会在HTTP协议中告诉客户端,需要在 Cookie 里面记录一个Session ID,以后每次请求把这个会话ID发送到服务器,我就知道你是谁了。客户端的浏览器禁用了 Cookie ,会使用一种叫做URL重写的技术来进行会话跟踪,即每次HTTP交互,URL后面都会被附加上一个诸如 sid=xxxxx 这样的参数,服务端据此来识别用户
区别:
(1)cookie数据存放在客户的浏览器上,session数据放在服务器上
(2)cookie不是很安全,别人可以分析存放在本地的COOKIE并进行COOKIE欺骗,如果主要考虑到安全应当使用session
(3)session会在一定时间内保存在服务器上。当访问增多,会比较占用你服务器的性能,如果主要考虑到减轻服务器性能方面,应当使用COOKIE
(4)单个cookie在客户端的限制是3K,就是说一个站点在客户端存放的COOKIE不能3K。
结论:
将登陆信息等重要信息存放为SESSION;其他信息如果需要保留,可以放在COOKIE中。
为什么用session?
由于HTTP协议是无状态的协议,所以典型的场景比如购物车,当你点击下单按钮时,由于HTTP协议无状态,所以并不知道是哪个用户操作的,所以服务端要为特定的用户创建了特定的Session,用用于标识这个用户,并且跟踪用户,这样才知道购物车里面有几本书。
1.这个Session是保存在服务端的,有一个唯一标识。在服务端保存Session的方法很多,内存、数据库、文件都有。集群的时候也要考虑Session的转移,在大型的网站,一般会有专门的Session服务器集群,用来保存用户会话,这个时候 Session 信息都是放在内存的,使用一些缓存服务比如Memcached之类的来放 Session。session会在一定时间内保存在服务器上。当访问增多,会比较占用你服务器的性能,如果主要考虑到减轻服务器性能方面,应当使用COOKIE
\2. 思考一下服务端如何识别特定的客户?这个时候Cookie就登场了。每次HTTP请求的时候,客户端都会发送相应的Cookie信息到服务端。实际上大多数的应用都是用 Cookie 来实现Session跟踪的,第一次创建Session的时候,服务端会在HTTP协议中告诉客户端,需要在 Cookie 里面记录一个Session ID,以后每次请求把这个会话ID发送到服务器,我就知道你是谁了。有人问,如果客户端的浏览器禁用了 Cookie 怎么办?一般这种情况下,会使用一种叫做URL重写的技术来进行会话跟踪,即每次HTTP交互,URL后面都会被附加上一个诸如 sid=xxxxx 这样的参数,服务端据此来识别用户。
\3. Cookie其实还可以用在一些方便用户的场景下,设想你某次登陆过一个网站,下次登录的时候不想再次输入账号了,怎么办?这个信息可以写到Cookie里面,访问网站的时候,网站页面的脚本可以读取这个信息,就自动帮你把用户名给填了,能够方便一下用户。这也是Cookie名称的由来,给用户的一点甜头。cookie不是很安全,别人可以分析存放在本地的COOKIE并进行COOKIE欺骗,如果主要考虑到安全应当使用session
所以,总结一下:
Session是在服务端保存的一个数据结构,用来跟踪用户的状态,这个数据可以保存在集群、数据库、文件中;
Cookie是客户端保存用户信息的一种机制,用来记录用户的一些信息,也是实现Session的一种方式。
6.如果客户端禁止 cookie 能实现 session 还能用吗?
如果浏览器不支持使用/接受Cookie,则不能使用Session.
虽然Session真正的数据是存储在服务器上的,但每个Session都对应了一个由Web服务器指定的唯一识别符Seesion_id,而在浏览器里是使用Cookie来存储这个Seesion_id的.所以使用Session,浏览器必须支持Cookie.
过滤器+拦截器
过滤器作用
请求和回应的过滤,传入的request,response提前过滤掉一些信息,或者提前设置一些参数,然后再传入servlet或者springmvc的web'进行业务逻辑,比如过滤掉非法url(不是login.do的地址请求,如果用户没有登陆都过滤掉),或者在传入servlet或者springmvc的web前统一设置字符集,或者去除掉一些非法字符(聊天室经常用到的,一些骂人的话)。
拦截器作用:
拦截器,在AOP中用于在某个方法被访问之前,进行拦截然后在之前或之后加入某些操作。比如日志,安全等。作用:比如通过它来进行权限验证,或者判断用户是否登陆,或者是像12306 判断当前时间是否是购票时间。
Servlet过滤器的基本原理
在请求进入容器之后,还未进入Servlet之前进行预处理;在请求结束返回给前端之前进行后期处理。处理完成后,它会交给下一个过滤器处理,直到请求发送到目标为止。
拦截器:
拦截器链,就是将拦截器按一定的顺序联结成一条链。在访问被拦截的方法或字段时,拦截器链中的拦截器就会按其之前定义的顺序被调用。
一般拦截器方法都是通过动态代理的方式实现。
区别
①拦截器是基于动态代理的,而过滤器是基于函数回调。
②拦截器不依赖于servlet容器,通过动态代理实现,过滤器依赖于servlet容器。
③拦截器可以在方法前后,异常前后等调用,而过滤器只能在请求前和请求后各调用一次。
④拦截器可以利用依赖注入,因此在Spring框架程序中,优先拦截器
过滤器
过滤器是一个程序,它先于与之相关的servlet或JSP页面运行在服务器上。它是随你的web应用启动而启动的,只初始化一次,以后就可以拦截相关请求,只有当你的web应用停止或重新部署的时候才销毁。
forward()与redirect()的区别?
Servlet API中forward()与redirect()的区别?
1.从地址栏显示来说
forward是服务器请求资源,服务器直接访问目标地址的URL,把那个URL的响应内容读取过来,然后把这些内容再发给浏览器.浏览器根本不知道服务器发送的内容从哪里来的,所以它的地址栏还是原来的地址.
redirect是服务端根据逻辑,发送一个状态码,告诉浏览器重新去请求那个地址.所以地址栏显示的是新的URL.所以redirect等于客户端向服务器端发出两次request,同时也接受两次response。
2.从数据共享来说
forward:转发页面和转发到的页面可以共享request里面的数据.
redirect:不能共享数据.
因为: forward方法只能在同一个Web应用程序内的资源之间转发请求.forward 是服务器内部的一种操作.很明显,redirect无法访问服务器保护起来的资源,但是可以从一个网站redirect到其他网站。
3.从运用地方来说
forward:一般用于用户登陆的时候,根据角色转发到相应的模块.
redirect:一般用于用户注销登陆时返回主页面和跳转到其它的网站等.
4.从效率来说
.forword更加高效,所以在满足需求的情况下,尽量使用forword,
前端发来的请求判断是ajax还是http?
答案:如果requestType能拿到值,并且值为XMLHttpRequest,表示客户端的请求为异步请求,那自然是ajax请求了,反之如果为null,则是普通的请求 (报文头可以自己设置的,严格的说,木有办法,但我们的应用中可以不进行包头手动设置)
7.spring mvc 和 struts 的区别是什么?
8.如何避免 sql 注入?
9.什么是 XSS 攻击,如何避免?
10.什么是 CSRF 攻击,如何避免?
七、异常
异常
1.Throwable 是所有异常的父类,它有两个直接子类 Error 和 Exception,其中
Exception 又被继续划分为被检查的异常和运行时的异常(即不受检查的异常);
2.Error 表示系统错误,通常不能预期和恢复(譬如 JVM 崩溃、内存不足oom等);
检查异常
1.javac强制要求做预备处理工作(使用try…catch…finally或者throws)。
2.在方法中要么用try-catch语句捕获它并处理,要么用throws子句声明抛出它,否则编译不会通过。
3.这样的异常一般是由程序的运行环境导致的。因为程序可能被运行在各种未知的环境下,而程序员无法干预用户如何使用他编写的程序,于是程序员就应该为这样的异常时刻准备着。如SQLException , IOException,ClassNotFoundException 等。
运行时异常
1.javac在编译时,不会提示和发现这样的异常,不会强制要求处理,但是如果出现错误,程序就停止,一般情况下为了代码的健壮性,写代码时应该给予处理。
2.这样的异常发生的原因多半是代码写的有问题。如除0错误ArithmeticException,错误的强制类型转换错误ClassCastException,数组索引越界ArrayIndexOutOfBoundsException,使用了空对象NullPointerException等等。
异常:
异常是指程序运行时(非编译)所发生的非正常情况或错误,当程序违反了语音规则,jvm就会将出现的错误表示一个异常抛出。
异常也是java 的对象,定义了基类 java。lang。throwable作为异常父类。 这些异常类又包括error和exception。两大类
error类异常主要是运行时逻辑错误导致,一个正确程序中是不应该出现error的。当出现error一般jvm会终止。
exception表示可恢复异常,包括检查异常和运行时异常。 检查异常是最常见异常比如 io异常sql异常,都发生在编译阶段。这类通过try、catch捕捉
而运行时异常,编译器没有强制对其进行捕捉和处理。一般都会把异常向上抛出,直到遇到处理代码位置,若没有处理块就会抛到最上层,多线程用thread。run()抛出,单线程用main()抛出。常见的运行异常包括 空指针异常 类型转换异常 数组月结异常 数组存储异常 缓冲区溢出异常 算术异常等,
1.java的异常体系?
在 Java 中,所有的异常都有一个共同的祖先 Throwable(可抛出)。Throwable 指定代码中可用异常传播机制通过 Java 应用程序传输的任何问题的共性。
Throwable 有两个重要的子类:Exception(异常)和 Error(错误),二者都是 Java 异常处理的重要子类,各自都包含大量子类。
Exception(异常)是应用程序中可能的可预测、可恢复问题。一般大多数异常表示中度到轻度的问题。异常一般是在特定环境下产生的,通常出现在代码的特定方法和操作中。在 EchoInput 类中,当试图调用 readLine 方法时,可能出现 IOException 异常。
Error(错误)表示运行应用程序中较严重问题。大多数错误与代码编写者执行的操作无关,而表示代码运行时 JVM(Java 虚拟机)出现的问题。例如,当 JVM 不再有继续执行操作所需的内存资源时,将出现 OutOfMemoryError。
Exception 类有一个重要的子类 RuntimeException。RuntimeException 类及其子类表示“JVM 常用操作”引发的错误。例如,若试图使用空值对象引用、除数为零或数组越界,则分别引发运行时异常(NullPointerException、ArithmeticException)和 ArrayIndexOutOfBoundException。
2.受检异常 非检测异常?
受检异常:
可检测异常经编译器验证,对于声明抛出异常的任何方法,编译器将强制执行处理或声明规则,例如:sqlExecption 这个异常就是一个检测异常。你连接 JDBC 时,不捕捉这个异常,编译器就通不过,不允许编译。
非检测异常:
非检测异常不遵循处理或声明规则。在产生此类异常时,不一定非要采取任何适当操作,编译器不会检查是否已解决了这样一个异常。例如:一个数组为 3 个长度,=E5__你使用下标为3时,就会产生数组下标越界异常。这个异常 JVM 不会进行检测,要靠程序员来判断。有两个主要类定义非检测异常:RuntimeException 和 Error。
Error 子类属于非检测异常,因为无法预知它们的产生时间。若 Java 应用程序内存不足,则随时可能出现 OutOfMemoryError;起因一般不是应用程序的特殊调用,而是 JVM 自身的问题。另外,Error 一般表示应用程序无法解决的严重问题。
RuntimeException 类也属于非检测异常,因为普通 JVM 操作引发的运行时异常随时可能发生,此类异常一般是由特定操作引发。但这些操作在 Java 应用程序中会频繁出现。因此,它们不受编译器检查与处理或声明规则的限制。
3封装一个API的时候什么情况下抛出异常?
如果调用方可以从异常中采取措施进行恢复的,就使用checked exception,如果客户什么也做不了,就用unchecked exception。这里的措施指的是,不仅仅是记录异常,还要采取措施来恢复。
74.throw 和 throws 的区别?
75.final、finally、finalize 有什么区别?
76.try-catch-finally 中哪个部分可以省略?
77.try-catch-finally 中,如果 catch 中 return 了,finally 还会执行吗?
try-catch-finally 规则( 异常处理语句的语法规则 )
1) 必须在 try 之后添加 catch 或 finally 块。try 块后可同时接 catch 和 finally 块,但至少有一个块。
2) 必须遵循块顺序:若代码同时使用 catch 和 finally 块,则必须将 catch 块放在 try 块之后。 3) catch 块与相应的异常类的类型相关。 4) 一个 try 块可能有多个 catch 块。若如此,则执行第一个匹配块。即Java虚拟机会把实际抛出的异常对象依次和各个catch代码块声明的异常类型匹配,如果异常对象为某个异常类型或 其子类的实例,就执行这个catch代码块,不会再执行其他的 catch代码块 5) 可嵌套 try-catch-finally 结构。 6) 在 try-catch-finally 结构中,可重新抛出异常。 由此可以看出,catch只会匹配一个,因为只要匹配了一个,虚拟机就会使整个语句退出
78.常见的异常类有哪些?
\5. Java的四种引用,强弱软虚,用到的场景。
强:通常情况下都是,不会被回收
弱:内存紧张时会回收,可以用于缓存
软:检查到即回收,可以用于缓存
虚:几乎和没有引用一样,适用于跟踪对象的回收
\6. Hashcode的作用。
\7. ArrayList、LinkedList、Vector的区别。
\8. String、StringBuffer与StringBuilder的区别。
\9. Map、Set、List、Queue、Stack的特点与用法。
\10. HashMap和HashTable的区别。
\11. HashMap和ConcurrentHashMap的区别,HashMap的底层源码。
\12. TreeMap、HashMap、LindedHashMap的区别。
\13. Collection包结构,与Collections的区别。
\14. try catch finally,try里有return,finally还执行么?
\15. Excption与Error包结构。OOM你遇到过哪些情况,SOF你遇到过哪些情况。
\16. Java面向对象的三个特征与含义。
封装、继承、多态
\17. Override和Overload的含义去区别。
\18. Interface与abstract类的区别。
\19. Static class 与non static class的区别。
\20. java多态的实现原理。
\21. 实现多线程的两种方法:
\22. 线程同步的方法:sychronized、lock、reentrantLock等。
\23. 锁的等级:方法锁、对象锁、类锁。
\24. 写出生产者消费者模式。
\25. ThreadLocal的设计理念与作用。
\26. ThreadPool用法与优势。
\27. Concurrent包里的其他东西:ArrayBlockingQueue、CountDownLatch等等。
\28. wait()和sleep()的区别。
\29. foreach与正常for循环效率对比。
\30. Java IO与NIO。
\31. 反射的作用于原理。
\32. 泛型常用特点,List
\33. 解析XML的几种方式的原理与特点:DOM、SAX、PULL。
\34. Java与C++对比。
\35. Java1.7与1.8新特性。
\36. 设计模式:单例、工厂、适配器、责任链、观察者等等。
\37. JNI的使用。
Java Native Interface:
并发和多线程的区别:
流:
文件:
File类:文件和目录路径名的抽象表示形式。在Java.io包下,File不能访问文件本身,这时要借助IO流。
File.separator 文件静态属性,目录分割符
方法:
boolean createNewFile() 创建一个新的文件,不包含上级目录(使用时上级目录必须不存在,否则会引发异常)不存在时创建,存在时不创建
boolean mkdir() 创建此抽象路径名指定的目录。
boolean mkdirs() 创建此抽象路径名指定的目录,包括所有必需但不存在的父目录。
boolean exists() 测试此抽象路径名表示的文件或目录是否存在。存在true
String getName() 返回由此抽象路径名表示的文件或目录的名称。(文件不存在也可用)
String getParent() 返回此抽象路径名父目录的路径名字符串;如果此路径名没有指定父目录,则返回 null。
File getParentFile() 返回此抽象路径名父目录的抽象路径名;如果此路径名没有指定父目录,则返回 null。
String getAbsolutePath() 返回此抽象路径名的绝对路径名字符串。
boolean delete() 删除此抽象路径名表示的文件或目录。(如果含有子文件或子文件夹则不能删除)(谨慎删除,不进回收站)(只能一级一级的删)(当文件被流正在操作,不能被删除,返回false)
boolean isFile() 测试此抽象路径名表示的文件是否是一个标准文件。(是的前提是存在)
boolean isHidden() 测试此抽象路径名指定的文件是否是一个隐藏文件。
String[] list() 返回一个字符串数组,这些字符串指定此抽象路径名表示的当前目录中的文件和目录。(得到子文件列表,若为空目录,返回一个空的数组)(必须应用于文件夹,否则产生空指针异常,若为系统及目录,也会发生异常)(包含隐藏文件)
File [] listFiles() 返回一个抽象路径名数组,这些路径名表示此抽象路径名表示的目录中的文件。(得到子文件列表)(必须应用于文件夹)
boolean renameTo(File dest) 重新命名此抽象路径名表示的文件。(可用来实现文件的移动)
文件过滤器:
String[] list(FilenameFilter filter) 返回一个字符串数组,这些字符串指定此抽象路径名表示的目录中满足指定过滤器的文件和目录。
File[] listFiles(FileFilter filter) 返回抽象路径名数组,这些路径名表示此抽象路径名表示的目录中满足指定过滤器的文件和目录。
File[] listFiles() 返回一个抽象路径名数组,这些路径名表示此抽象路径名表示的目录中的文件。
long getFreeSpace() 返回此抽象路径名指定的分区中未分配的字节数。
long getTotalSpace() 返回此抽象路径名指定的分区大小。(总容量)
long getUsableSpace() 返回此抽象路径名指定的分区上可用于此虚拟机的字节数。
文件读取:
1.需要有一个目标文件
2.需要一个传输通道
3.需要一个缓冲区
4.执行操作
5.关闭通道和缓冲区
文件写入:
1.需要有一个目标文件
2.需要一个传输通道
3.需要一个缓冲区
4.执行操作
5.关闭通道和缓冲区
IO流:
l0(Input Output)流
I0流用来处理设备之间的数据传输。Java对数据的操作是通过流的方式Java用于操作流的对象都在|O包中。
流按操作数据分为两种:字节流与字符流。流按流向分为:输入流,输出流。
Io流:
字节流的两个顶层父类;InputStream ,OutputStream.
字符流的两个顶层父类:Reader,Writer
字符流和字节流:
字符流:
reader:是所有输入字符流的父类,是一个抽象类
BufferedReader:一种缓冲处理流
InputStreamReader:转换流,将字节流转换为字符流
StringReader:基本的介质流,从字符串读取数据
ByteArrayReader:基本的介质流,从char数组读取数据
FileReader:基本的介质流,从本地文件读取数据
PipedReader:是从其他线程共用的管道中读取数据
FilerReader
PushbackReader
Writer:是所有输出字符流的父类,是一个抽象类
BufferedWrite:一种缓冲处理流
OutputStreamWriter:转换流,将字节流转换为字符流
FileWriter:基本的介质流,从本地文件写入数据
StringWriter:基本的介质流,从字符串中写入数据
charArrayWriter:基本的介质流,从char数组中写入数据
PrinterWriter
PipedWriter:是从其他线程共用的管道中写入数据
FilerWriter
字节流:
InputStream:所有的输入字节流的父类,是一个抽象类
FileInputStream:基本的介质流,从本地文件读取数据
StringBufferInputStream:基本的介质流,从StringBuffer读取数据
ByteArrayInputStream:基本的介质流,从Byte数组读取数据
FilerInputStream:和他的子类都是装饰流(装饰器模式的主角)
BufferedInputStream
DataInputStream
PushbakInputStream
ObjectInputStream:和他的子类都是装饰流(装饰器模式的主角)
PipedInputStream:是从其他线程共用的管道中读取数据
SequenceInputStream
OutputStream:是所有输出字节流的父类,是一个抽象类
FileOutputStream:基本的介质流,从本地文件中写入数据
ByteArrayOutputString:基本的介质流,从Byte数组中写入数据
FilerOutputStream:和他的子类都是装饰流
BufferedOutputStream
DataOutputStream
PrintStream
ObjectOutputStream
PipedOutputStream:是从其他线程共用的管道中读取数据
概念和作用:流是一组有顺序的,有起点和终点的字节集合,是对数据传输的总称或抽象。即数据在两设备间的传输称为流,流的本质是数据传输,根据数据传输特性将流抽象为各种类,方便更直观的进行数据操作。
流的分类:
根据处理的数据类型不同:字符流,字节流
根据数据流向不同:输入流,输出流, 输入流和输出流相对于内存设备而言.
根据同数据源之间的关系:节点流,处理流
字节流和字符流:
字符流的由来: 因为数据编码的不同,而有了对字符进行高效操作的流对象。本质其实就是基于字节流读取时,去查了指定的码表。 简单说:字节流+编码表
字节流和字符流的**区别:**
-
读写单位不同:字节流以字节(8bit)为单位,字符流以字符为单位,根据码表映射字符,一次可能读多个字节。
-
处理对象不同:字节流能处理所有类型的数据(如图片、avi等),而字符流只能处理字符类型的数据。
-
字节流:一次读入或读出是8位二进制。一次能读一个字节
-
字符流:一次读入或读出是16位二进制。一次能读两个字节
设备上的数据无论是图片或者视频,文字,它们都以二进制存储的。二进制的最终都是以一个8位为数据单元进行体现,所以计算机中的最小数据单元就是字节。意味着,字节流可以处理设备上的所有数据,所以字节流一样可以处理字符数据。
结论:**只要是处理纯文本数据,就优先考虑使用字符流。 除此之外都使用字节流。**
输出流和输入流:
输入流只能进行读操作,输出流只能进行写操作,程序中需要根据传送的数据的不同的特性而使用不同的流
-
输入流:InputStream或者Reader:从文件中读到程序中;
-
输出流:OutputStream或者Writer:从程序中输出到文件中;
节点流和处理流:
节点流:(可单独使用)直接与数据源相连,读入或读出。
常用节点流:
-
父 类 :InputStream 、OutputStream、 Reader、 Writer
-
文 件 :FileInputStream 、 FileOutputStrean 、FileReader 、FileWriter 文件进行处理的节点流
-
数 组 :ByteArrayInputStream、 ByteArrayOutputStream、 CharArrayReader 、CharArrayWriter 对数组进行处理的节点流(对应的不再是文件,而是内存中的一个数组)
-
字符串 :StringReader、 StringWriter 对字符串进行处理的节点流
-
管 道 :PipedInputStream 、PipedOutputStream 、PipedReader 、PipedWriter 对管道进行处理的节点流
处理流:(不可单独使用,处理流也称包装流)处理流和节点流一块使用,在节点流的基础上,再套接一层,套接在节点流上的就是处理流。(最常用的处理流——包装流)如BufferedReader.处理流的构造方法总是要带一个其他的流对象做参数。一个流对象经过其他流的多次包装,称为流的链接。
常用的处理流:
-
缓冲流:BufferedInputStrean 、BufferedOutputStream、 BufferedReader、BufferedWriter 增加缓冲功能,避免频繁读写硬盘。(实现了缓冲功能的输入,输出流。使用了缓冲功能的输入,输出流效率更高,速度更快)
-
转换流:转换流:InputStreamReader 、OutputStreamReader实现字节流和字符流之间的转换。(两者之间进行转换,但不能将输入转为输出,也不能将输出转为输入)
InputStreamReader 、OutputStreamWriter 要InputStream或OutputStream作为参数,实现从字节流到字符流的转换。
-
数据流: DataInputStream 、DataOutputStream 等-提供将基础数据类型写入到文件中,或者读取出来。
-
Java中的打印流:字节打印流PrintStream和字符打印流PrintWriter。通过定义的构造方法可以发现,有一个构造方法可以直接接收OutputStream类的实例,与OutputStream相比起来,PrintStream可以更方便的输出数据,相当于把OutputStream类重新包装了一下,使之输出更方便。
构造器:public PrintStream(OutputStream out) --指定输出位置
关于IO流的创建:
1.单独声明
2.在try-catc语句块中创建,使用
3.try-catch单独关闭,关闭前判断对象是否为空(若创建失败则对象为空)
流的操作原理:
关闭流,关闭资源。在关闭前会先调用flush刷新缓冲中的数据到目的地。
fw.close() ;
字符流:常用方法:
newline();//可以在任意平台加入换行符
readline();//按行读取
创建一个输出流:
如果文件不存在,则会自动创建。如果文件存在,则会被覆盖。
FileWriter fw=new FileWriter ("demo.txt") ;
如果构造函数中加入true,可以实现对文件进行续写!
FileWriter fw =new FileWriter ("demo. txt", true) ;
创建读取字符数据的流对象。
在创建读取流对象时,必须要明确被读取的文件。一定要确定该文件是存在的。
用一个读取流关联一一个 已存在文件。
FileReader fr=new FileReader ("demo. txt") ;
readline的底层实现:
创建字节输出流对象。用于操作文件,
OutputStream fos= new FileOutputstream ("bytedemo. txt") ;
写数据。直接写入到了目的地中。
fos.write ("abedefg" .getBytes()) ;
fos. flush() ;
fos .close () ;//关闭资源动作要完成。
缓冲流:将文本写入字符输出流,缓冲各个字符,从而提供单个字符、数组和字符串的高双写入。缓冲区仅仅是提高效率问题,它依靠流对象进行读写操作,它的关闭,导致流对象也随之关闭
装饰设计模式:
对一组对象的功能(类中的方法)进行增强时,就可以使用该模式进行问题的解决。
装饰和继承都能实现一样的特点:进行功能的扩展增强。
有什么区别呢?
进行的继承,可能导致继承体系越来越臃肿。不够灵活。装饰比继承灵活。
例如:既然加入的都是同一种技术--缓冲。前一种是让缓冲和具体的对象相结合。可不可以将缓冲进行单独的封裝,哪个对象需要緩冲就将哪个对象和缓冲关联。
特点:装饰器和被装饰的类都必需所属同一个接口或者父类。
Socket s=new Socket(11111);
PrintWriter out=new PrintWriter(s.getOutPutStream(),true);//获取了socket的输出流并进行装饰,并自动刷新。
由于Bufferedreader具有一个readLine()方法,可以方便的读入一行内容,所以经常把读取文本内容的输入流包装成BufferedReader,同理BufferedWriter具有newLine()方法
Bufferedwritex bufw = new Buffexedwxiter (new outputstreamWxiter (System.out1) ;
转换流:
字节流没有readline()方法,要使用标准输入流还要readline,就先将字节流转化为字符流,默认的输入输出流 不要关闭,因系统中只含一个,关闭后就在此程序中无法再次使用
InputstreamReader :字节到字符的桥梁。解码。
Outputstreamlriter:字符到字节的桥梁。编码。
例如:
// 这两句代码的功能是等同的。
// FileWriter:其实就是转换流指定了本机默认码表的体现。而且这个转换流的子类对象,可以方便操作文本文件。
// 简单说:操作文件的字节流+本机默认的编码表。这是按照默认码表未操作文件的便捷类。
// 如果操作文本文件需要明确具体的编码。pileWriter就不行 了。必须用转换流。
使用转换流的场景:
1,源或者目的对应的设备是字节流,但是操作的却是文本数据,可以使用转换作为桥梁。
提高对文本操作的便捷。
2,一旦操作文本涉 及到具体的指定编码表时,必须使用转换流。
流的操作规律:
之所以要弄清楚这个规律,是因为流对象太多,开发时不知道用哪个对象合适。
想要知道开发时用到哪些对象。只要通过四个明确即可。
1,明确源和目的 源: Inputstream Reader 目的: Outputstrean writer 2, ;明确数据是否是纯文本数据。 源: 是纯文本:Reader 否: Inputstream 3.明确具体的设备: 源: 键盘:System.in 硬盘:File 内存:数组 网络:Socket流 目的设备: 硬盘:File 控制台:System.out 内存:数组 网络:Socket流 4.是否需要额外功能: 例如:高效——加入缓冲区