【MySQL】SQL优化之explain等工具使用
在应用的开发过程中,由于初期数据量小,开发人员写SQL语句时更重视功能上的实现,但是当应用系统正式上线后,随着生产数据量的急剧增长,很多SQL语句开始逐渐显露出性能问题,对生产的影响也越来越大,此时这些有问题的SQL语句就成为整个系统性能的瓶颈,因此我们必须要对它们进行优化,接下来将介绍SQL优化过程中几种常用的工具的使用方式。
一、查看SQL执行频率
MySQL客户端连接成功后,通过show [session|global] status命令可以提供服务器状态信息。show [session|global] status可以根据需要加上参数"session"或者"global"来显示session级(当前连接)的统计结果和global(自数据库从上次启动至今)的统计结果。如果不写,默认使用的参数为“session”。
下面命令显示了当前session中所有统计参数的值。
show status like 'Com_______';

show status like 'Innodb_rows_%';
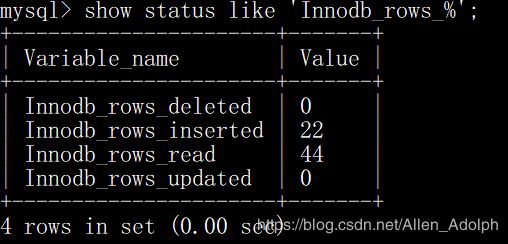
其中Com_xxx表示每个xxx类语句执行的次数,像select语句执行的次数,update语句执行的次数等。而Innodb_rows开头的则表示的是以innodb为引擎的表的统计数据。
二、定位低效率执行的SQL
可以通过以下两种方式定位执行效率较低的SQL语句。
-
慢查询日志:通过慢查询日志定位那些执行效率较低的SQL语句,用
--log-slow-queries[=file_name]选项启动时,mysqld写一个包含所有执行时间超过long_query_time秒的 SQL 语句的日志文件。 -
show processlist:慢查询日志在查询结束以后才记录,所以在应用反映执行效率出现问题的时候查询日志并不能定位问题,可以使用
show processlist命令查看当前MySQL在进行的线程,包括线程的状态、是否锁表,可以实时地查看SQL的执行情况,同时对一些锁表操作进行优化。

1) id列,用户登录mysql时,系统分配的“connection_id”,可以使用函数connection_id()查看
2) user列,显示当前用户,如果不是root,这个命令就只显示用户权限范围的sql语句
3) host列,显示这个语句是从哪个ip哪个端口上发的,可以用来追踪出现问题语句的用户
4) db列,显示这个进程目前连接的是哪个数据库
5) command列,显示当前连接的执行的命令,一般取值为休眠(Sleep),查询(query),链接额(connect)等
6) time列,显示这个状态持续的时间,单位是秒
7) state列,显示使用当前连接的sql语句的状态,很重要的列。state描述的是语句执行过程中的某个状态。一个sql语句,以查询为例,可能经过copying to tmp table、sorting result、sending data等状态才可以完成。
8)info列,显示这个sql语句,是判断问题语句的一个重要数据。
三、explain分析执行计划
通过以上步骤查询到效率低的SQL语句后,可以通过EXPLAIN或者DESC命令获取MySQL如何执行SELECT语句的信息,包括在SELECT语句执行过程中表如何连接和连接的顺序。
查询SQL语句的执行计划:
explain select * from tb_item where id = 1;

explain select * from tb_item where title = '阿尔卡特 (OT-979) 冰川白 联通3G手机3';

接下来解析下各个字段的含义:
| 字段 | 含义 |
|---|---|
| id | select查询的序列号,是一组数字,表示的是查询中执行select子句或者是操作表的顺序。 |
| select_type | 表示SELECT的类型,常见的取值有SIMPLE(简单表,即不使用连接或者子查询)、PRIMARY(出查询,即外层的查询)、UNION(UNION中的第二个或者后面的查询语句)、SUBQUERY(子查询中的第一个SELECT)等 |
| table | 输出结果集的表 |
| type | 表示表的连接类型,性能由好到差的连接类型为(system、const、eq_ref、ref、ref_or_null、index_merge、index_subquery、range、index、all) |
| possible_key | 表示查询时,可能使用到的索引 |
| key | 表示实际使用的索引 |
| key_len | 索引字段的长度 |
| rows | 扫描行的数量 |
| extra | 执行情况的说明和描述 |
1. 环境准备
首先需要准备三个表用以测试说明explain。

CREATE TABLE `t_role` (
`id` varchar(32) NOT NULL,
`role_name` varchar(255) DEFAULT NULL,
`role_code` varchar(255) DEFAULT NULL,
`description` varchar(255) DEFAULT NULL,
PRIMARY KEY(`id`),
UNIQUE KEY `unique_role_name` (`role_name`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE `t_user` (
`id` varchar(32) NOT NULL,
`username` varchar(45) NOT NULL,
`password` varchar(96) NOT NULL,
`name` varchar(45) NOT NULL,
PRIMARY KEY(`id`),
UNIQUE KEY `unique_user_username`(`username`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
CREATE TABLE `user_role` (
`id` int(11) NOT NULL auto_increment,
`user_id` varchar(32) DEFAULT NULL,
`role_id` varchar(32) DEFAULT NULL,
PRIMARY KEY(`id`),
KEY `fk_ur_user_id` (`user_id`),
KEY `fk_ur_role_id` (`role_id`),
CONSTRAINT `fk_ur_role_id` FOREIGN KEY(`role_id`) REFERENCES `t_role`(`id`) ON DELETE NO ACTION ON UPDATE NO ACTION,
CONSTRAINT `fk_ur_user_id` FOREIGN KEY(`user_id`) REFERENCES `t_user`(`id`) ON DELETE NO ACTION ON UPDATE NO ACTION
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
insert into `t_user` (`id`, `username`, `password`, `name`)values('1', 'super', '123456', '超级管理员');
insert into `t_user` (`id`, `username`, `password`, `name`)values('2', 'admin', '123456', '系统管理员');
insert into `t_user` (`id`, `username`, `password`, `name`)values('3', 'jo', '123456', 'test02');
insert into `t_user` (`id`, `username`, `password`, `name`)values('4', 'stu1', '123456', '学生1');
insert into `t_user` (`id`, `username`, `password`, `name`)values('5', 'stu2', '123456', '学生2');
insert into `t_user` (`id`, `username`, `password`, `name`)values('6', 't1', '123456', '老师1');
INSERT INTO `t_role` (`id`, `role_name`, `role_code`, `description`) VALUES('5', '学生', 'student', '学生');
INSERT INTO `t_role` (`id`, `role_name`, `role_code`, `description`) VALUES('7', '老师', 'teacher', '老师');
INSERT INTO `t_role` (`id`, `role_name`, `role_code`, `description`) VALUES('8', '教学管理员', 'teachmanager', '教学管理员');
INSERT INTO `t_role` (`id`, `role_name`, `role_code`, `description`) VALUES('9', '管理员', 'admin', '管理员');
INSERT INTO `t_role` (`id`, `role_name`, `role_code`, `description`) VALUES('10', '超级管理员', 'super', '超级管理员');
INSERT INTO user_role(id, user_id, role_id) VALUES(NULL, '1', '5'), (NULL, '1', '7'), (NULL, '2', '8'), (NULL, '3', '9'), (NULL, '4', '8'), (NULL, '5', '10');
2. explain之id
id字段是select查询的序列号,是一组数字,表示的是查询中执行select子句或者是操作表的顺序。id情况有三种:
1)id相同表示加载表的顺序是从上到下。
explain select * from t_role r, t_user u, user_role ur where r.id = ur.role_id and u.id = ur.user_id;

2)id不同id值越大,优先级越高,越先被执行。
EXPLAIN SELECT * FROM t_role WHERE id = (SELECT role_id FROM user_role WHERE user_id = (SELECT id FROM t_user WHERE username = 'stu1'));

3)id有相同,也有不同,同时存在。id相同的可以认为是一组,从上往下顺序执行;在所有的组中,id的值越大,优先级越高,约先执行。
EXPLAIN SELECT * FROM t_role r, (SELECT * FROM user_role ur WHERE ur.`user_id` = `2`) a WHERE r.id = a.role_id;

3. explain 之 select_type
表示SELECT的类型,常见的取值,如下表所示:
| select_type | 含义 |
|---|---|
| SIMPLE | 简单的select查询,查询中不包含子查询或者UNION |
| PRIMARY | 查询中若包含任何复杂的子查询,最外层查询标记为该标识 |
| SUBQUERY | 在SELECT或WHERE列表中包含了子查询 |
| DERIVED | 在FROM列表中包含的子查询,被标记为DERIVED(衍生)MYSQL会递归执行这些子查询,把结果放在临时表中 |
| UNION | 若第二个SELECT出现在UNION之后,则标记为UNION;若UNION包含在FROM子句的子查询中,外层SELECT将被标记为:DERIVED |
| UNION RESULT | 从UNION表获取结果的SELECT |
4. explain之table
该列中的元素表示展示的这一行数据是关于哪一张表的。
5. explain之type
type显示的是访问类型,是较为重要的一个指标,取值以及含义如下:
| type | 含义 |
|---|---|
| NULL | MySQL不访问任何表,索引,直接返回结果。例如:select now(); |
| system | 表只有一行记录(等于系统表),这是const类型的特例,一般不会出现 |
| const | 表示通过索引一次就找到了,const用于比较primary key或者unique索引。因为只匹配一行数据,所以很快。如将主键置于where列表中,MySQL就能将该查询转换为一个常量。const将“主键”或“唯一”索引的所有部分与常量值进行比较 |
| eq_ref | 类似ref,区别在于使用的是唯一索引,使用主键的关联查询,关联查询出的记录只有一条。常见于主键或唯一索引扫描 |
| ref | 非唯一性索引扫描,返回匹配某个单独值的所有行。本质上也是一种索引访问,返回所有匹配某个单独值的所有行(多个) |
| range | 只检索给定返回的行,使用一个索引来选择行。where之后出现between, <, >, in 等操作。 |
| index | index 与 ALL的区别为 index 类型只是遍历了索引树,通常比ALL快,ALL是遍历数据文件。 |
| all | 将遍历全表以找到匹配的行 |
结果值从效率上看最好到最坏的顺序是:
Null > system > const > er_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
一般来说,我们需要保证查询至少达到range级别,最好达到ref。
6. explain之key
possible_keys:显示可能应用在这张表的索引,一个或多个;
key:实际使用的索引,如果为null,则没有使用索引;
key_len:表索引中使用的字节数,该值为索引字段的最大可能长度,并非实际使用长度,在不损失精确性的前提下,长度越短越好。
7. explain之rows
扫描行的数量。
8. explain之extra
其他的额外的执行计划信息,在该列展示。
| extra | 含义 |
|---|---|
| using filesort | 说明mysql会对数据使用一个外部的索引排序,而不是按照表内的索引顺序进行读取,成为“文件排序” |
| using temporary | 使用了临时表保存中间结果,MySQL在对查询结果排序时使用临时表。常见于order by和group by |
| using index | 表示相应的select操作使用了覆盖索引,避免访问表的数据行,效率不错。 |
四、show profile分析SQL
MySQL 从 5.0.37 版本开始增加了对show profiles和show profile 语句的支持。show profiles能够在做SQL优化时帮助我们了解时间都耗费到哪里去了。
通过have_profiling参数,能够看到当前MySQL是否支持profile
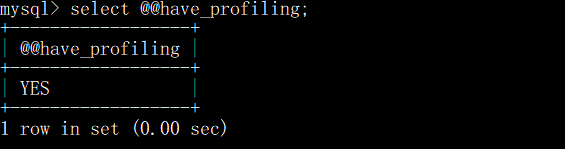
默认profiling是关闭的,可以通过set语句在Session级别开启profiling:
# 查看是否开启profiling
mysql> select @@profiling;
+-------------+
| @@profiling |
+-------------+
| 0 |
+-------------+
1 row in set (0.00 sec)
# 开启profiling
set profiling=1; // 开启profiling开关;
通过profile,我们能够更清楚地了解SQL执行的过程。
首先,我们可以执行一系列的操作,如下所示:
show database;
use db01;
show tables;
select * from tb_item where id < 5;
select count(*) from tb_item;
执行完上述命令之后,再执行show profiles指令,来查看sql语句执行的耗时,如下图示:
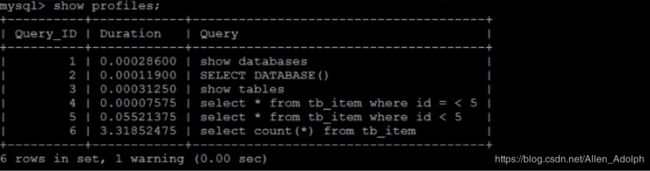
通过show profile for query query_id 语句可以查看到该SQL执行过程中每个线程的状态和消耗的时间:

TIP:
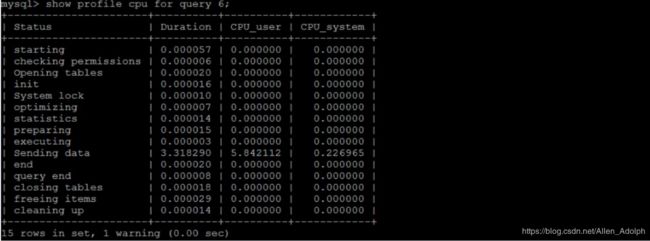
sending data 状态表示MySQL线程开始访问数据行并把结果返回给客户端,而不仅仅是返回个客户端。
由于在sending data状态下,MySQL线程往往需要做大量的磁盘读取操作,所以经常是整个查询中耗时最长的状态。
在获取到最消耗时间的线程状态后,MySQL支持进一步选择all、cpu、block io、context swith、page faults等明细类型类查看MySQL在使用什么资源上耗费了过高的时间。例如,选择查看CPU的耗费时间:
五、trace分析优化器执行计划
MySQL 5.6 提供了对SQL的追踪trace,通过trace文件能够进一步了解为什么优化器选择A计划,而不是选择B计划。
打开trace,设置格式为 JSON,并设置trace最大能够使用的内存大小,避免解析过程中因为默认内存过小而不能够完整展示。
SET optimizer_trace="enabled=on", end_markers_in_json=on;
SET optimizer_trace_max_mem_size=1000000;
执行SQL语句
select * from t1 where c2='b' and c4=20
最后,检查information_schema.optimizer_trace就可以知道MySQL是如何执行SQL的:
select * from information_schema.optimizer_trace\G;
*************************** 1. row ***************************
QUERY: explain select * from t1 where c2='b' and c4=20
TRACE: {
"steps": [
{
"join_preparation": { ---优化准备工作
"select#": 1,
"steps": [
{
"expanded_query": "/* select#1 */ select `t1`.`c1` AS `c1`,`t1`.`c2` AS `c2`,`t1`.`c3` AS `c3`,`t1`.`c4` AS `c4` from `t1` where ((`t1`.`c2` = 'b') and (`t1`.`c4` = 20))"
}
] /* steps */
} /* join_preparation */
},
{
"join_optimization": { ---优化工作的主要阶段,包括逻辑优化和物理优化两个阶段
"select#": 1,
"steps": [ ---优化工作的主要阶段,逻辑优化阶段
{
"condition_processing": { ---逻辑优化,条件化简
"condition": "WHERE",
"original_condition": "((`t1`.`c2` = 'b') and (`t1`.`c4` = 20))",
"steps": [
{
"transformation": "equality_propagation", --逻辑优化,条件化简,等式处理
"resulting_condition": "((`t1`.`c2` = 'b') and multiple equal(20, `t1`.`c4`))"
},
{
"transformation": "constant_propagation", --逻辑优化,条件化简,常量处理
"resulting_condition": "((`t1`.`c2` = 'b') and multiple equal(20, `t1`.`c4`))"
},
{
"transformation": "trivial_condition_removal", --逻辑优化,条件化简,条件去除
"resulting_condition": "((`t1`.`c2` = 'b') and multiple equal(20, `t1`.`c4`))"
}
] /* steps */
} /* condition_processing */
},
{ ---逻辑优化,条件化简,结束
"table_dependencies": [ ---逻辑优化,找出表之间的相互依赖关系,非直接可用的优化方式
{
"table": "`t1`",
"row_may_be_null": false,
"map_bit": 0,
"depends_on_map_bits": [
] /* depends_on_map_bits */
}
] /* table_dependencies */
},
{
"ref_optimizer_key_uses": [ ---逻辑优化,找出备选的索引
{
"table": "`t1`",
"field": "c2",
"equals": "'b'",
"null_rejecting": false
},
{
"table": "`t1`",
"field": "c4",
"equals": "20",
"null_rejecting": false
},
{
"table": "`t1`",
"field": "c2",
"equals": "'b'",
"null_rejecting": false
},
{
"table": "`t1`",
"field": "c4",
"equals": "20",
"null_rejecting": false
}
] /* ref_optimizer_key_uses */
},
{
"rows_estimation": [ --逻辑优化,估算每个表的元组个数,单表上进行全表扫描和索引扫描的代价估算,每个索引都估算扫描代价
{
"table": "`t1`",
"range_analysis": {
"table_scan": { --逻辑优化, 估算每个表的元组个数. 单表上进行全表扫描的代价
"rows": 7,
"cost": 4.5
} /* table_scan */,
"potential_range_indices": [ ---逻辑优化, 列出备选的索引. 后续版本字符串变为potential_range_ind
{
"index": "PRIMARY", ---逻辑优化, 本行表明主键索引不可用
"usable": false, -- 这个表明这个索引不能用于该语句
"cause": "not_applicable"
},
{
"index": "ind_c2", ---逻辑优化, 索引ind_c2
"usable": true,
"key_parts": [
"c2",
"c1"
] /* key_parts */
},
{
"index": "ind_c4", ---逻辑优化, 索引ind_c4
"usable": true,
"key_parts": [
"c4",
"c1"
] /* key_parts */
},
{
"index": "ind_c2_c4", ---逻辑优化, 索引ind_c2_c4
"usable": true,
"key_parts": [
"c2",
"c4",
"c1"
] /* key_parts */
}
] /* potential_range_indices */,
"setup_range_conditions": [ ---逻辑优化, 如果有可下推的条件,则带条件考虑范围查询
] /* setup_range_conditions */,
"group_index_range": { ---逻辑优化, 如带有GROUPBY或DISTINCT,则考虑是否有索引可优化这种操作. 并考虑带有MIN/MAX的情况
"chosen": false,
"cause": "not_group_by_or_distinct"
} /* group_index_range */,
"analyzing_range_alternatives": { ---逻辑优化,开始计算每个索引做范围扫描的花费(等值比较是范围扫描的特例)
"range_scan_alternatives": [
{
"index": "ind_c2",
"ranges": [
"b <= c2 <= b"
] /* ranges */,
"index_dives_for_eq_ranges": true,
"rowid_ordered": true,
"using_mrr": false,
"index_only": false,
"rows": 4,
"cost": 5.81,
"chosen": false,
"cause": "cost"
},
{
"index": "ind_c4",
"ranges": [
"20 <= c4 <= 20"
] /* ranges */,
"index_dives_for_eq_ranges": true,
"rowid_ordered": true,
"using_mrr": false,
"index_only": false,
"rows": 2,
"cost": 3.41, ---逻辑优化,这个索引的代价最小
"chosen": true ---逻辑优化,这个索引的代价最小,被选中. (比前面的table_scan 和其他索引的代价都小)
},
{
"index": "ind_c2_c4",
"ranges": [
"b <= c2 <= b AND 20 <= c4 <= 20"
] /* ranges */,
"index_dives_for_eq_ranges": true,
"rowid_ordered": true,
"using_mrr": false,
"index_only": false,
"rows": 2,
"cost": 3.41,
"chosen": false,
"cause": "cost"
}
] /* range_scan_alternatives */,
"analyzing_roworder_intersect": {
"intersecting_indices": [
{
"index": "ind_c2_c4",
"index_scan_cost": 1.0476,
"cumulated_index_scan_cost": 1.0476,
"disk_sweep_cost": 1.75,
"cumulated_total_cost": 2.7976,
"usable": true,
"matching_rows_now": 2,
"isect_covering_with_this_index": false,
"chosen": true
},
{
"index": "ind_c4",
"cumulated_total_cost": 2.7976,
"usable": false,
"cause": "does_not_reduce_cost_of_intersect"
},
{
"index": "ind_c2",
"cumulated_total_cost": 2.7976,
"usable": false,
"cause": "does_not_reduce_cost_of_intersect"
}
] /* intersecting_indices */,
"clustered_pk": {
"clustered_pk_added_to_intersect": false,
"cause": "no_clustered_pk_index"
} /* clustered_pk */,
"chosen": false,
"cause": "too_few_indexes_to_merge"
} /* analyzing_roworder_intersect */
} /* analyzing_range_alternatives */, ---逻辑优化,开始计算每个索引做范围扫描的花费. 这项工作结算
"chosen_range_access_summary": { ---逻辑优化,开始计算每个索引做范围扫描的花费. 总结本阶段最优的.
"range_access_plan": {
"type": "range_scan",
"index": "ind_c4",
"rows": 2,
"ranges": [
"20 <= c4 <= 20"
] /* ranges */
} /* range_access_plan */,
"rows_for_plan": 2,
"cost_for_plan": 3.41,
"chosen": true -- 这里看到的cost和rows都比 indx_user 要来的小很多---这个和[A]处是一样的,是信息汇总.
} /* chosen_range_access_summary */
} /* range_analysis */
}
] /* rows_estimation */ ---逻辑优化, 估算每个表的元组个数. 行估算结束
},
{
"considered_execution_plans": [ ---物理优化, 开始多表连接的物理优化计算
{
"plan_prefix": [
] /* plan_prefix */,
"table": "`t1`",
"best_access_path": {
"considered_access_paths": [
{
"access_type": "ref",
"index": "ind_c2",
"rows": 4,
"cost": 2.8,
"chosen": true
},
{
"access_type": "ref", ---物理优化, 计算indx_user索引上使用ref方查找的花费,
"index": "ind_c4",
"rows": 2,
"cost": 2.4,
"chosen": true
},
{
"access_type": "ref",
"index": "ind_c2_c4",
"rows": 2,
"cost": 2.4,
"chosen": false
},
{
"access_type": "range",
"cause": "heuristic_index_cheaper",
"chosen": false
}
] /* considered_access_paths */
} /* best_access_path */,
"cost_for_plan": 2.4,
"rows_for_plan": 2,
"chosen": true
}
] /* considered_execution_plans */
},
{
"attaching_conditions_to_tables": { --逻辑优化,尽量把条件绑定到对应的表上
"original_condition": "((`t1`.`c4` = 20) and (`t1`.`c2` = 'b'))",
"attached_conditions_computation": [
] /* attached_conditions_computation */,
"attached_conditions_summary": [
{
"table": "`t1`",
"attached": "(`t1`.`c2` = 'b')"
}
] /* attached_conditions_summary */
} /* attaching_conditions_to_tables */
},
{
"refine_plan": [
{
"table": "`t1`" ---逻辑优化,下推索引条件"pushed_index_condition";其他条件附加到表上做为过滤条件"table_condition_attached"
}
] /* refine_plan */
}
] /* steps */
} /* join_optimization */ ---逻辑优化和物理优化结束
},
{
"join_explain": {
"select#": 1,
"steps": [
] /* steps */
} /* join_explain */
}
] /* steps */
}
MISSING_BYTES_BEYOND_MAX_MEM_SIZE: 0
INSUFFICIENT_PRIVILEGES: 0
1 row in set (0.00 sec)