【图像分割综述】 Image Segmentation Review 【代码总汇】code
前言:在目前的应用中,图像分割可以分为以下几大类
1、自动驾驶领域-车道线分割,车道分割,instance分割等
2、普通图像 - 基于类别的图像分割/基于instance的图像分割
3、医学图像 - 2/3D 图像分割,通常是非instance的
图像分割、姿态估计、目标检测 在 卷积神经网络出现之后,常常是分开做的任务,maskrcnn出现后把这三个任务做成了一个模型,但是依然很多人把这些当初不同类型的任务。但是,这三个类型任务,可以说是都属于“基于图像pixle的密度预测”!
学习代码:
- https://github.com/snakers4/ds_bowl_2018 这个是kaggle大佬的代码,基于Pytorch;包含了:GCN、vggUnet、Inception4、InceptionResnet、LinkNet、TernausNet等一些模型,可以很好的应用到自己 的任务中。
- https://github.com/zijundeng/pytorch-semantic-segmentation 基于Pytorch,里面包含了fcn8~32、segnet、unet、pspnet等模型,也是比较值得学习的。
- https://github.com/rishizek/tensorflow-deeplab-v3 这个是deeplab类的,基于tensorflow,复现的还算比较好,而且提供类很多可视化的东西,tensorboard上可以看到效果图以及loss图等。
- https://github.com/weiliu89/caffe/tree/fcn 这是fcn的改进版本,PARSENET的官方代码,比原始FCN 提升了5~6个点
数据集介绍:
可以参考我这篇博客 https://blog.csdn.net/github_36923418/article/details/81453519 ,里面介绍了目前图像分割主要采用的一些数据集。
方法综述:
1、FCN- Fully convolutional networks for semantic segmentation _cvpr2015

这是一篇非常经典的工作,直到现在依然有着很深远的影响,甚至FCN结构也被拓展到了“目标检测”上。
首先,文章采用了VGG-16(也尝试过AlexNet和GoogLeNet),并且把最后的fc层转化成了卷积层,"分类网络参数转化为全卷积网络"!从上面的图中可以看出,虽然是“分类网络”的参数,但是因为“早年的”conv层和fc层之间采用reshape进行链接,所以具有一定的空间能力,因此上图可以看出,网络有一定的空间能力。
网络结构设计采用的是,在“原生网络”的基础之上再在后面增加了“1*1->21”的卷积层,这样一来最后就是输出的prediction map,然后再通过deconvlution层以及bilinearly upsample层,这样的话,整个的预测结果就由粗到细的得到了最后的。

如上图所示,FCN有三种结构,FCN-8s FCN-16s FCN-32s这三种结构是预测map的大小不同,并且每一个后者多是基于前者finetune的,而且增加了skip connection。
2、SegNet -A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation_2015
这也是非常经典的一个网络模型,他的出现让很多人开始思考Encoder 和Decoder结构作为网络模型设计的基础方案,当然这也的结构并不是在这个时候才出现的。 http://mi.eng.cam.ac.uk/projects/segnet/ 这是它的官网,还有专门对应的数据集。

这个网络结构,放在今天其实还是非常好理解的,前面的Encoder来自于VGG16网络剔除了fc层。后面每一个模块由upsample+conv组合而成,最后采用1*1->class number ->softmax来得到最后的结果。关于skip connection在这里并不是我们现在理解的把“feature map”传递过来,而是传递的max pooling的坐标信息用于upsample上采样的时候用“Pooling indices”。
3、HED -Holistically-Nested Edge Detection ijcai2015
这篇文章是把图像分割换了场景应用到了边缘检测!基于FCN,当然增加了很多方法,我实测过,文章中提出的一些方法对于结果上还是有提升的。官方代码:https://github.com/s9xie/hed
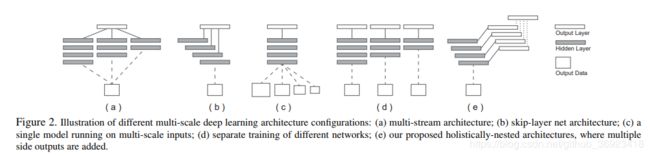
上面这张图是文章讨论 不同方法处理multi-scale的处理方式,或者说是如何在不同的deep应用上原始信息。

这是本文的主要网络结构, 可以看出,这个每个降采样阶段都会有一个输出用于”中继监督“以及”结果融合“,这里中继监督作者考虑的不同stage要有不同的权重,但是好像都给了1
可以看出,这个每个降采样阶段都会有一个输出用于”中继监督“以及”结果融合“,这里中继监督作者考虑的不同stage要有不同的权重,但是好像都给了1 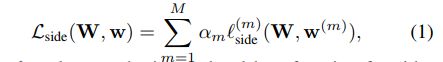
,当然,”结果融合“也是由参数的,但是这个”是可学习参数“,这个用pytorch实现起来也很方便。相当于是加权平均!
这篇文章有一个升级版本:Pushing the Boundaries of Boundary Detection Using Deep Learning,在loss上增加了一些改进,和epoch联系起来,具体可以阅读下这篇文章。https://arxiv.org/pdf/1511.07386.pdf
![]()
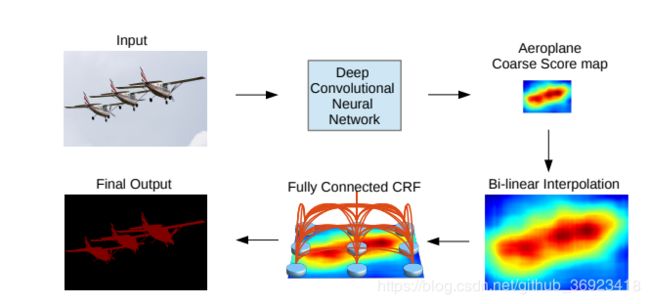
4、DeepLab v1 - Semantic Image Segmentation with Deep Convolutional Nets and Fully Connected CRFs
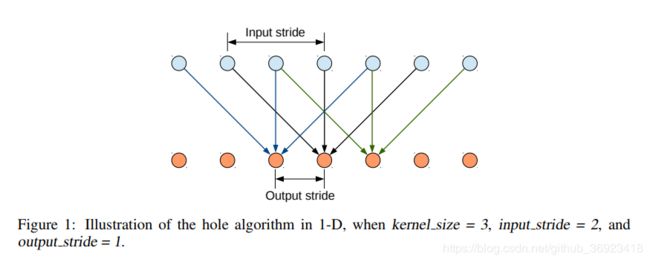
这篇文章在arxiv上居然是2014年提交的,这还是很惊人的!!!,这篇文章中出现了后面常用的两个模块”带洞卷积“以及”CRF“,但是”CRF“到了2018年底又不怎么被采用了,也有人把CRF做成了convlution crf 也有开源代码!
 、
、
这应该是空洞卷积的早年的一个模型。文中把VGG16首先转换成了全卷积网络,但是依然输出是输入的1/32,然后跳过了最后两个subsample,这样就是1/8了然后在不改变网络结构的基础之上引入”空洞“算法来提高网络模型的能力。
We have also successfully experimented with reducing the number of channels at the fully connected layers from 4,096 down to 1,024
Multi-scale PredictionSpecifically, we attach to the input image and the output of each of the first four max pooling layers a two-layer MLP。
把网络输出的结果,上采样之后再进行CRF,”Full Connected CRF“ 。
5、DeepLab v2 - DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs _2016/2017
这篇文章是去年那篇的升级版本。我们熟知的ASPP就是再这个时候被提出来的,ASPP模块是将不同”rate的空洞卷积“应用在同一个feature map上之后把结果结合起来,其实后来的RFB也相当于是这个的升级plus版本。主要是为了”提高感受野“以及“用感受野的提升来应对尺度变化带来的一些损失”

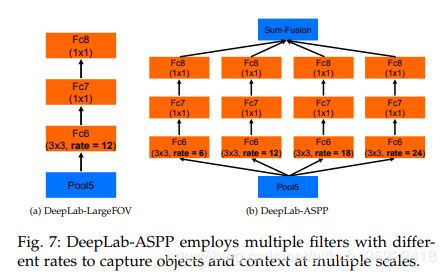
从这张图(右)也能看出 主要的网络上的改进,基础网络依然是VGG16。和去年的deeplab有区别的主要就是后边部分被换成了ASPP,但是这个时候的ASPP和我们现在的ASPP还是有一定差别的。
这篇文章也给出了后来大家一直沿用的学习率策略![]() 。
。
6、ParseNet - LookingWider to See Better_2015
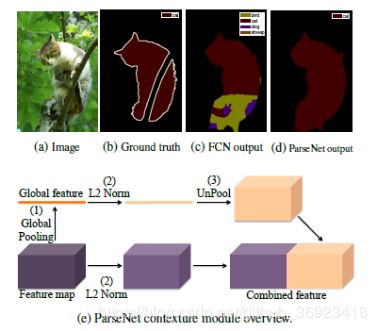
这篇文章主要就是提出了上图这个模块,利用global pooling对feature map进行全局pooling成向量,然后upsample到feature map的size之后和feature map拼接到一起,主要是想利用高纬度的语义信息来强化改feature map。这模块直接应用在FCN上,从上图中可以看出效果也是比较明显的。
7、MULTI-SCALE CONTEXT AGGREGATION BY DILATED CONVOLUTIONS_2016
这是大佬Fisher Yu的论文,