Spark快速入门系列(5) | Spark环境搭建—standalone(2) 配置历史日志服务器
大家好,我是不温卜火,是一名计算机学院大数据专业大二的学生,昵称来源于成语—
不温不火,本意是希望自己性情温和。作为一名互联网行业的小白,博主写博客一方面是为了记录自己的学习过程,另一方面是总结自己所犯的错误希望能够帮助到很多和自己一样处于起步阶段的萌新。但由于水平有限,博客中难免会有一些错误出现,有纰漏之处恳请各位大佬不吝赐教!暂时只有csdn这一个平台,博客主页:https://buwenbuhuo.blog.csdn.net/
此篇为大家带来的是Spark环境搭建—standalone(2) 配置历史日志服务器。

目录
- 一. 配置步骤

默认情况下,Spark程序运行完毕关闭窗口之后,就无法再查看运行记录的Web UI(4040)了,但通过 HistoryServer 可以提供一个服务, 通过读取日志文件, 使得我们可以在程序运行结束后, 依然能够查看运行过程。本篇博客,博主就为大家带来在Spark上配JobHistoryServer的详细过程。
在 Spark-shell 没有退出之前, 我们是可以看到正在执行的任务的日志情况:http://hadoop102:4040. 但是退出 Spark-shell 之后, 执行的所有任务记录全部丢失.
所以需要配置任务的历史服务器, 方便在任何需要的时候去查看日志.
一. 配置步骤
在配置之前,如果spark服务还在启动中请先停止!
[bigdata@hadoop002 spark]$ sbin/stop-all.sh

- 1. 配置
spark-default.conf文件, 开启 Log
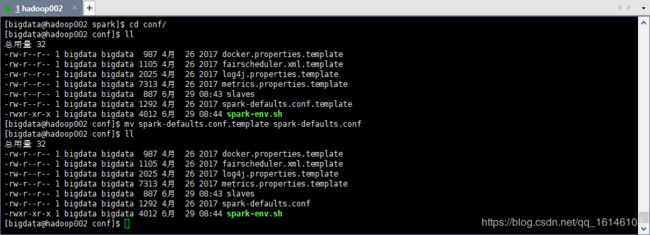
[bigdata@hadoop002 conf]$ mv spark-defaults.conf.template spark-defaults.conf
//在spark-defaults.conf文件中, 添加如下内容:
[bigdata@hadoop002 conf]$ vim spark-defaults.conf
spark.eventLog.enabled true
spark.eventLog.dir hdfs://hadoop002:9000/spark-job-log

注意:
hdfs://hadoop201:9000/spark-job-log 目录必须提前存在, 名字随意
[bigdata@hadoop002 spark]$ hadoop fs -mkdir /spark-job-log

- 2. 修改
spark-env.sh文件,添加如下配置
[bigdata@hadoop002 conf]$ vim spark-env.sh
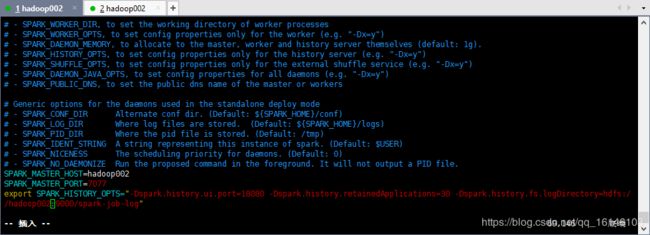
export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=18080 -Dspark.history.retainedApplications=30 -Dspark.history.fs.logDirectory=hdfs://hadoop002:9000/spark-job-log"
参数描述:
spark.eventLog.dir:Application在运行过程中所有的信息均记录在该属性指定的路径下;
spark.history.ui.port=18080 WEBUI访问的端口号为18080
spark.history.fs.logDirectory=hdfs://hadoop002:9000/spark-job-log 配置了该属性后,在start-history-server.sh时就无需再显式的指定路径,Spark History Server页面只展示该指定路径下的信息
spark.history.retainedApplications=30指定保存Application历史记录的个数,如果超过这个值,旧的应用程序信息将被删除,这个是内存中的应用数,而不是页面上显示的应用数。
- 3. 分发配置文件
// 可依次操作 也可分发
xsync spark-defaults.conf
xsync spark-env.sh
- 4. 启动历史服务
// 1. 需要先启动 HDFS
[bigdata@hadoop002 hadoop-2.7.2]$ sbin/start-dfs.sh
// 2. 启动spark
[bigdata@hadoop002 spark]$ sbin/start-all.sh
// 2. 然后再启动:
[bigdata@hadoop002 spark]$ sbin/start-history-server.sh

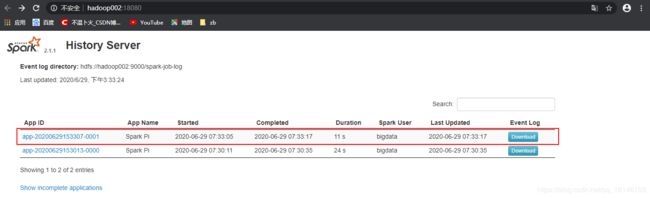
- 5. 登录Web界面
ui 地址: http://hadoop002:18080

- 6. 启动任务, 查看历史服务器
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://hadoop002:7077 \
--executor-memory 1G \
--total-executor-cores 6 \
./examples/jars/spark-examples_2.11-2.1.1.jar 100
本次的分享就到这里了,

好书不厌读百回,熟读课思子自知。而我想要成为全场最靓的仔,就必须坚持通过学习来获取更多知识,用知识改变命运,用博客见证成长,用行动证明我在努力。
如果我的博客对你有帮助、如果你喜欢我的博客内容,请“点赞” “评论”“收藏”一键三连哦!听说点赞的人运气不会太差,每一天都会元气满满呦!如果实在要白嫖的话,那祝你开心每一天,欢迎常来我博客看看。
码字不易,大家的支持就是我坚持下去的动力。点赞后不要忘了关注我哦!

