使用Spark Streaming分析国泰安股票交易数据
一、前言
这个小程序是《云计算》这门课的一次小作业,实现过程涉及到挺多知识,主要使用Spark Streaming来处理流数据,该数据来自国泰安股票交易数据,程序实现上使用一个进程模拟写入HDFS或本地文件夹的流数据,使用另一个进程运行Spark程序处理流数据。
二、环境搭建
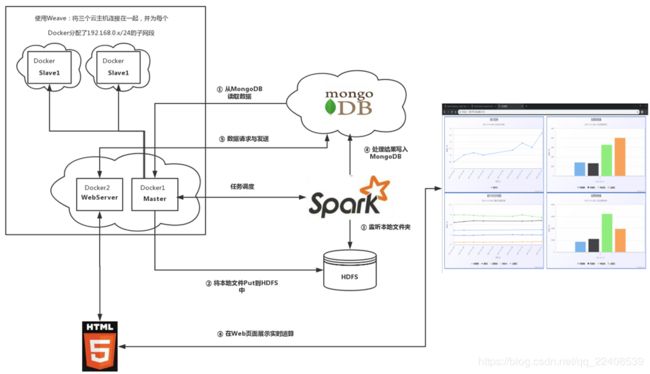
该程序的Spark运行环境搭建在四台腾讯云服务器上,其中有三台作为一个集群,另外一台使用MongoDB作为数据库服务器,存储原始数据和处理后的数据。对于集群,为了方便实现,这里使用Weave将这三台云主机连接在一起,成为一个局域网,然后为每台云主机中的Docker容易分配一个192.168.0.x/24的子网段,这些Docker容器用于充当一个Master或Slave结点,还有一个Docker容器用做Web服务器。
三、数据准备及处理
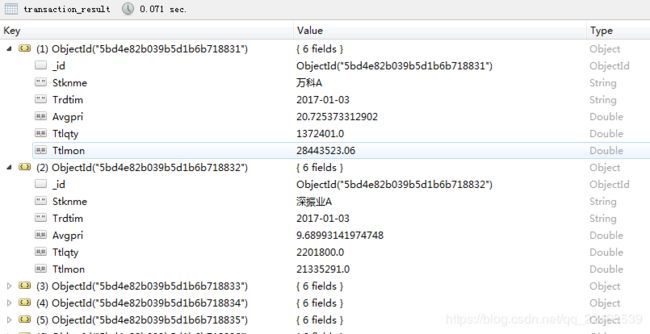
处理分析的数据来源于国泰安股票交易数据,下载并选择部分字段存储在MongoDB中。
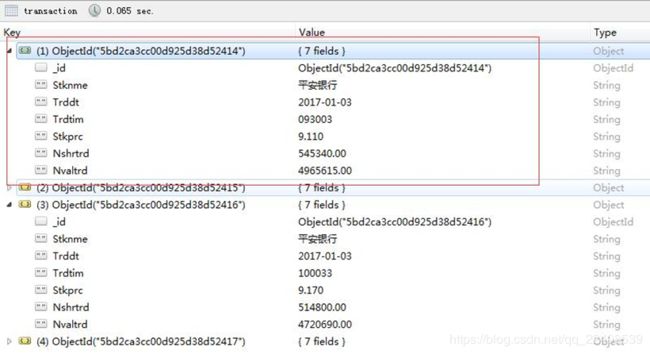
然后通过Spark Streaming来处理这些原始数据。
![]()
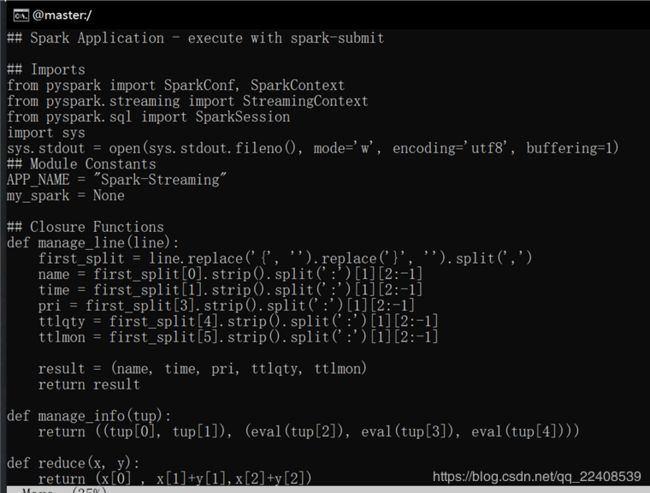
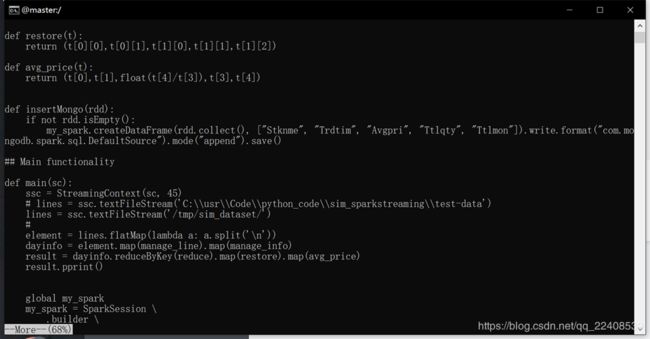
先对原始数据进行flatMap以及映射操作,获得一个包含五个元素的元组 。

之后再对元组进行map操作。

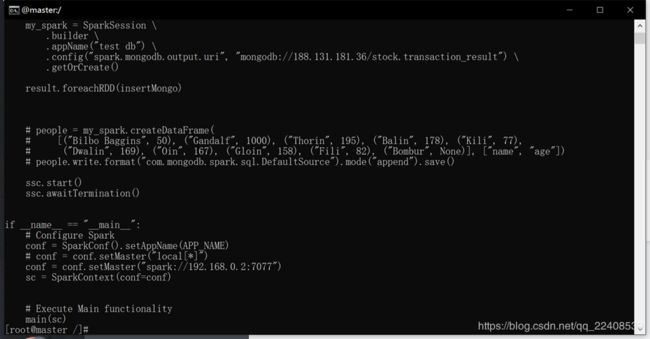
最后将reduceByKey()后再进行map结果写入MongoDB数据库中。
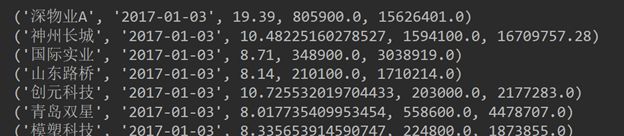
最终获得处理之后的数据
四、代码实现
1、运行Spark程序处理流数据
2、模拟写入HDFS的数据流
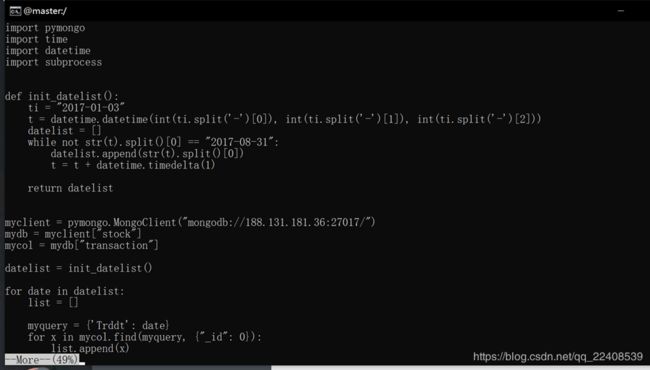

3、webserver的编写

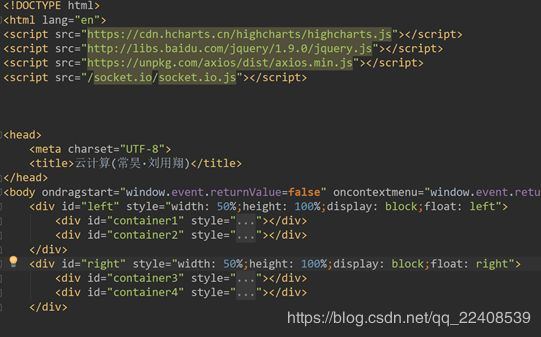
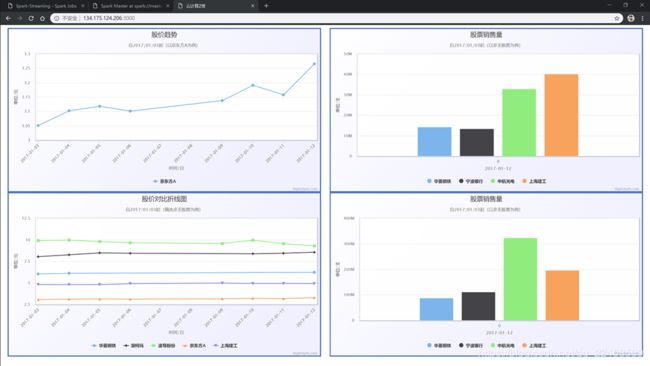
五、结果展示
在Web页面中展示实时计算结果