python爬取网页url,简单实现一下pagerank并可视化
为什么要写这个,主要还是想记录一下这个学期爬虫的期末课设

一开始看到这个头是大的,不过还好网上资源丰富只要一点点挖掘,总能找到对你有帮助的。
爬虫部分
首先打开新浪首页,可以看到href后面的就是我们需要的url
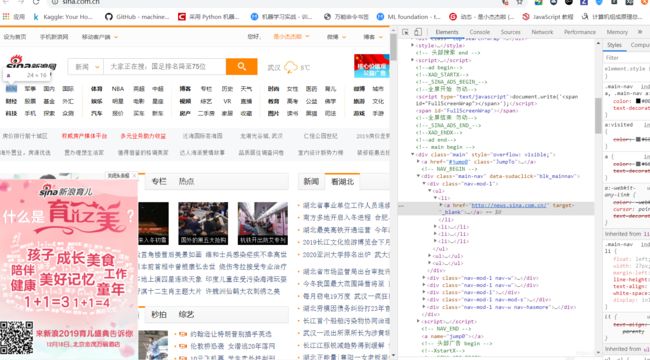
构造也简单,就是类别加在了sina.com的前面。我的想法就是通过这些子链接打开对应网页再对子网页进行爬取链接,反正正则匹配就好,把所有带html、https、http……这些连接全部爬下来。写了一段代码,也得到url,但是有两个地方没达到要求。
1.没有设置广度优先爬取的深度,导致过多网址以及不是本网站的网址
2.不能很好的保存下网址之间的关系
这个时候就感觉到这个爬虫比起平时自己写的爬取一些简单网页内容的爬虫复杂很多,既要解决爬取的深度问题还要同时保留网址的关系,所以就开始google。csdn找找,没找到合适的,又去GitHub搜,在一个儿童搜索引擎的项目中我最终找到一个类似的,设置了深度以及让网页按网页层级保留。
点这里去看代码
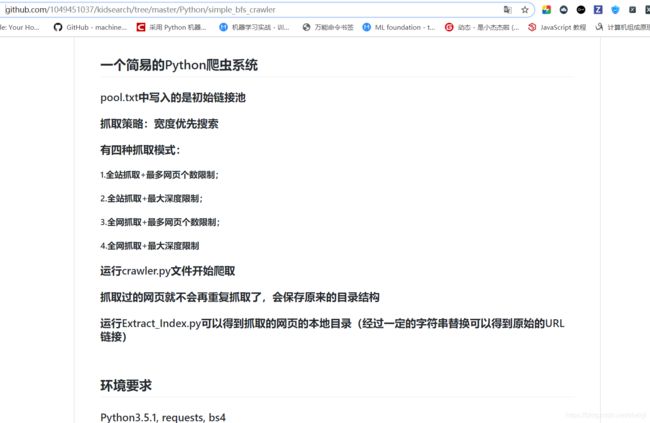
当然,在后面的过程中我也找到了同样有用的代码
from urllib import request
from urllib import error
from bs4 import BeautifulSoup
import re
from multiprocessing import Pool
from multiprocessing import Manager
import time
def getHtml(url, ua_agent='Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:61.0) Gecko',
num_retries=5):
headers = {"User-Agent": ua_agent}
req = request.Request(url, headers=headers)
html = None
try:
response = request.urlopen(req)
html = response.read().decode('utf-8')
except error.URLError or error.HTTPError as e:
if num_retries > 0:
if hasattr(e, 'code') and 500 <= e.code < 600:
getHtml(url, ua_agent, num_retries - 1)
return html
def get_urls(html):
"""
获取当前页面中所有的超链接的列表信息
"""
links = []
soup = BeautifulSoup(html, "html.parser")
url_list = soup.find_all('a')
for link in url_list:
links.append(link.get('href'))
return links
# 匹配规则^http或者com$,cn$
def save_file(murl, fileName):
with open(fileName, 'ab') as f:
f.write(murl.encode())
def CrawlInfo(url, q):
# 获取当前节点的信息
global crawl_queue
crawl_queue = [] # 声明待爬队列
hlinks = []
html = getHtml(url)
links = get_urls(html)
for murl in links:
if re.findall("^http", str(murl)):
murl = str(murl) + "\r\n"
hlinks.append(murl)
save_file(murl, "sina_url.txt")
elif re.findall("^java", str(murl)):#去除带有javascript标签的url
links.remove(murl)
elif re.findall("gsp$",str(murl)) or re.findall("shtml$", str(murl)) or re.findall("[0-9]*$", str(murl)):
murl = "https://www.sina.com" + str(murl) + "\r\n"
hlinks.append(murl)
save_file(murl, "sina_url.txt")
elif re.findall(".*?", str(murl)):
murl = str(murl)
hlinks.append(murl)
save_file(murl, "sina_url.txt")
else:
pass
for _ in hlinks:
crawl_queue.append(_)
time.sleep(0.001)
q.put(url)
if __name__ == "__main__":
# 使用进程池
pool = Pool()
q = Manager().Queue()
crawled_queue = [] # 已爬队列
seedUrl = "https://www.sina.com.cn/"
CrawlInfo(seedUrl, q)
crawl_queue.append(seedUrl)
crawl_queue = list(set(crawl_queue))
while crawl_queue:
url = crawl_queue.pop(0)
pool.apply_async(func=CrawlInfo, args=(url, q))
url = q.get()
crawled_queue.append(url)
pool.close()
pool.join()
这段代码运用了多进程,所以爬取速度很快,url之间的关系基本可以从存储的先后得到(因为爬取队列先爬取父网页链接,之后才能得到子网页的,并且基于新浪站内网址的规律很明显)只不过还是没有深度限制。
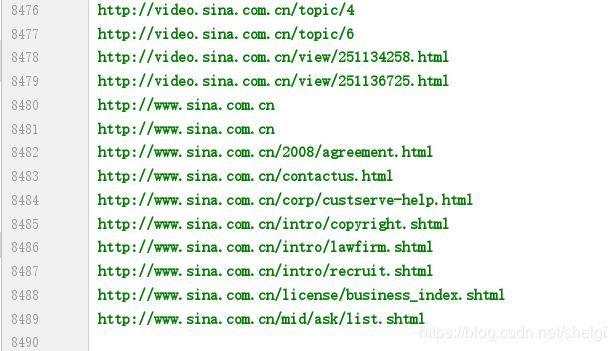
经过一番折腾修改,最后得到了很多网址
用第一种得到8000+,设置的深度是100,广度不限
第二种因为速度很快而且没有深度限制,所以只运行了一会我就停了,得到3000+
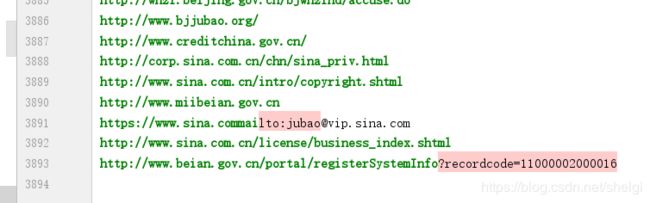
小心使用多进程!!!别爬取太久,首先得到再多数据没那个必要,第二这个会对网站服务器的压力很大,好一点的大网站可能会有反爬机制会封ip或者是服务器撑得住大访问量,但是对于小网站可能就很危险。我们只是学习,别引起一些不必要的麻烦
最后这个就是网络关系图,这里面是一个个分类中的子页面
PageRank部分
爬虫一开始就是讲的这个算法,思想很简单,主要思想可以概括为
a. 如果多个网页指向某个网页A,则网页A的排名较高。
b. 如果排名高A的网页指向某个网页B,则网页B的排名也较高,即网页B的排名受指向其的网页的排名的影响。
计算方法:
PageRank算法3总的来说就是预先给每个网页一个PR值(下面用PR值指代PageRank值),由于PR值物理意义上为一个网页被访问概率,所以一般是 1 N \frac{1}{N} N1,其中N为网页总数。另外,一般情况下,所有网页的PR值的总和为1。如果不为1的话也不是不行,最后算出来的不同网页之间PR值的大小关系仍然是正确的,只是不能直接地反映概率了。
预先给定PR值后,通过下面的算法不断迭代,直至达到平稳分布为止。
一般的PageRank计算公式为:
P R ( X ) = α ∑ Y i ∈ S ( X ) P R ( Y i ) n i + 1 − α N PR(X)=\alpha\sum_{Y_i\in{S(X)}}{\frac{PR(Y_i)}{n_i}+\frac{1-\alpha}{N}} PR(X)=αYi∈S(X)∑niPR(Yi)+N1−α
其中S(X)表示,指向网页X的所有网页的集合, n i n_i ni表示网页 Y i Y_i Yi的出边数量,N表示所有网页总数,α一般取0.85。
具体的博客可以查看下面的链接
博客1
博客2
可视化部分
对于python的可视化,最先想到的就是matplotlib.但是这个太基本了,几乎都用烂了,而且也没法实现我想展示的网络关系,交互性也不强,所以我用了一下networkx、bokeh。networkx在我之前微博用户关系绘制就用到了,而bokeh对于学生了解的可能不多,因为学校教的都是matplotlib、seaborn,但是像pyecharts、bokeh这类交互性的可视化库只能自己去了解使用。
bokeh使用文档
在这里面可以搜索任何自己想实现的图形,会找到使用方法并且附带有代码例子。
可视化的代码部分
'''
实现这个之前我们得到了新浪首页以及它的子页面链接
然后我们选取其中的链接运用pagerank计算网页的访问概率
类似于A B就是指网页从A可以跳转到B
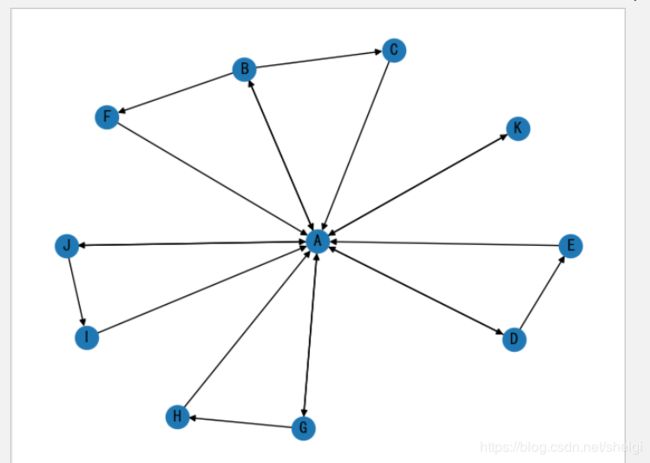
其中网页链接我们首先来个定义,为了简单输入,我们把链接用单个字母代替(选取部分链接计算,未取全部)
规定:
A:http://sina.com.cn
B:http://blog.sina.com.cn
C:http://blog.sina.com.cn/s/blog_1308439a00102yjem.html
D:http://auto.sina.com.cn
E:http://auto.sina.com.cn/sales
F:http://blog.sina.com.cn/lm/2018
G:http://news.sina.com.cn
H:http://news.sina.com.cn/c/2019-11-29/doc-iihnzahi4276587.shtml
I:http://video.sina.com.cn/topic
J:http://video.sina.com.cn
K:http://travel.sina.com.cn
'''
import math
import numpy as np
import networkx as nx
import matplotlib.pyplot as plt
import pandas as pd
from bokeh.plotting import figure, output_file, show
from bokeh.models import Plot, Range1d, MultiLine, Circle, HoverTool, BoxZoomTool, ResetTool
from bokeh.models.graphs import from_networkx
from bokeh.transform import cumsum
from bokeh.palettes import Category20c,Spectral4
def plot_graph(edges):
G = nx.DiGraph()
for edge in edges:
G.add_edge(edge[0], edge[1])
nx.draw(G, with_labels=True)
plt.show()
def mypagerank(edges):
nodes = []
for edge in edges:
if edge[0] not in nodes:
nodes.append(edge[0])
if edge[1] not in nodes:
nodes.append(edge[1])
print(nodes)
N = len(nodes)
i = 0
node_to_num = {}
for node in nodes:
node_to_num[node] = i
i += 1
for edge in edges:
edge[0] = node_to_num[edge[0]]
edge[1] = node_to_num[edge[1]]
print(edges)
S = np.zeros([N, N])
for edge in edges:
S[edge[1], edge[0]] = 1
print(S)
for j in range(N):
sum_of_col = sum(S[:, j])
for i in range(N):
if sum_of_col != 0:
S[i, j] /= sum_of_col
else:
S[i, j] = 1 / N
print(S)
alpha = 0.85
A = alpha * S + (1 - alpha) / N * np.ones([N, N])
print(A)
# 生成初始的PageRank值,记录在P_n中,P_n和P_n1均用于迭代
P_n = np.ones(N) / N
P_n1 = np.zeros(N)
e = 100000 # 误差初始化
k = 0 # 记录迭代次数
print('loop...')
while e > 0.00000001: # 开始迭代
P_n1 = np.dot(A, P_n) # 迭代公式
e = P_n1 - P_n
e = max(map(abs, e)) # 计算误差
P_n = P_n1
k += 1
print('iteration %s:' % str(k), P_n1)
print('final result:', P_n)
return P_n
def plot_values(df):
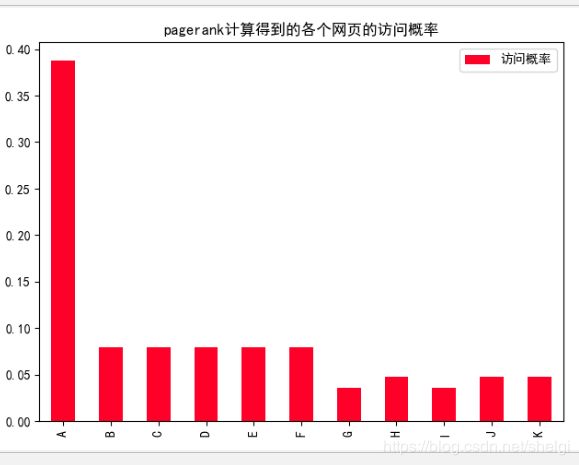
df.plot(kind='bar',colormap='gist_rainbow',title="pagerank计算得到的各个网页的访问概率")
plt.xticks(range(len(nodes)),nodes)
plt.show()
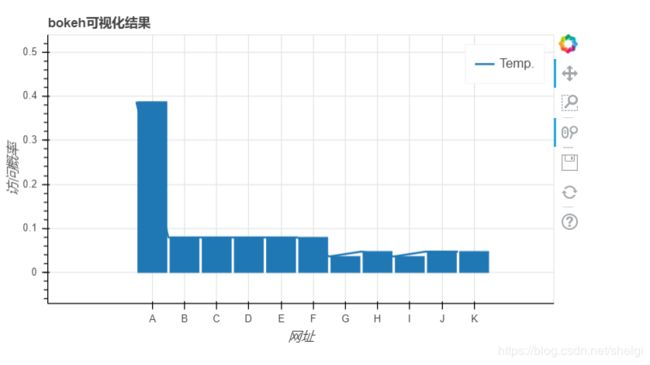
def bokeh_plot(df):
xdata = df['节点']
ydata = df['访问概率']
p = figure(x_range=xdata, plot_height=350,title="bokeh可视化结果",x_axis_label="网址",y_axis_label='访问概率')
p.vbar(x=xdata, top=ydata, width=0.9)
p.line(range(len(xdata)),ydata, legend_label="Temp.", line_width=2)
output_file('./各网址访问概率.html')
show(p)
def bokeh_plot2(edges):
G = nx.DiGraph()
for edge in edges:
G.add_edge(edge[0], edge[1])
SAME_CLUB_COLOR, DIFFERENT_CLUB_COLOR = "black", "red"
edge_attrs = {}
for start_node, end_node, _ in G.edges(data=True):
edge_color = SAME_CLUB_COLOR if G.nodes[start_node]== G.nodes[end_node] else DIFFERENT_CLUB_COLOR
edge_attrs[(start_node, end_node)] = edge_color
nx.set_edge_attributes(G, edge_attrs, "edge_color")
# Show with Bokeh
plot = Plot(plot_width=400, plot_height=400,
x_range=Range1d(-1.1, 1.1), y_range=Range1d(-1.1, 1.1))
plot.title.text = "Graph Interaction Demonstration"
node_hover_tool = HoverTool(tooltips=[("index", "@index"), ("club", "@club")])
plot.add_tools(node_hover_tool, BoxZoomTool(), ResetTool())
graph_renderer = from_networkx(G, nx.spring_layout, scale=1, center=(0, 0))
graph_renderer.node_renderer.glyph = Circle(size=15, fill_color=Spectral4[0])
graph_renderer.edge_renderer.glyph = MultiLine(line_color="edge_color", line_alpha=0.8, line_width=1)
plot.renderers.append(graph_renderer)
output_file("网络关系图.html")
show(plot)
def bokeh_plot3(nodes,res):
output_file("pie.html")
x=dict(zip(nodes,res))
data = pd.Series(x).reset_index(name='value').rename(columns={'index': 'country'})
data['angle'] = data['value'] / data['value'].sum() * 2 * math.pi
data['color'] = Category20c[len(x)]
p = figure(plot_height=350, title="Pie Chart",tooltips="@country: @value", x_range=(-0.5, 1.0))
p.wedge(x=0, y=1, radius=0.4,
start_angle=cumsum('angle', include_zero=True), end_angle=cumsum('angle'),
line_color="white", fill_color='color', legend_field='country', source=data)
show(p)
if __name__ == '__main__':
# 读入有向图,存储边
f = open('url.txt', 'r')
edges = [line.strip('\n').split(' ') for line in f]
print(edges)
plot_graph(edges)
res=mypagerank(edges)
nodes=['A','B','C','D','E','F','G','H','I','J','K']
data={"节点":nodes,"访问概率":res}
df = pd.DataFrame(data)
plot_values(df)
bokeh_plot(df)
bokeh_plot2(edges)
bokeh_plot3(nodes,res)
按照url关系设置的输入样式

可视化结果
- 网络关系图
- 访问概率图
- bokeh实现的几个可交互图

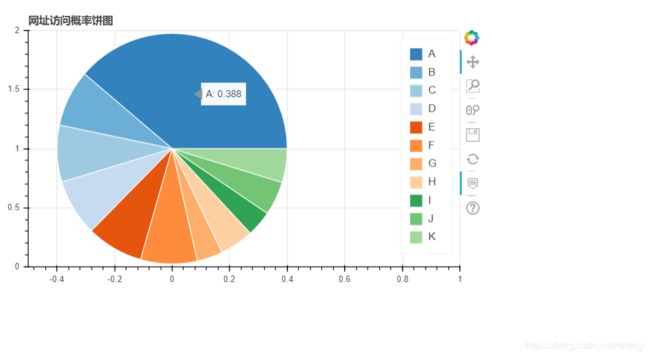
最后
差不多就是这样吧,爬虫怎么说呢其实套路是一样的,几种请求方式,几种解析方法,最后保存的操作。做来做去只要每部分能熟练运用两三样基本一般的网站都能爬(注意不要滥用爬虫,前段时间有被抓的例子要吸取教训哈哈哈)记录一下,要去开始写论文做ppt了
