【MapReduce】MapReduce(DataJoin)实现数据连接+Bloom Filter优化
- 数据:
file1:categoryname addressID
Beijing Red Star 1
Shenzhen Thunder 3
Guangzhou Honda 2
Beijing Rising 1
Guangzhou Development Bank 2
Tencent 3
Bank of Beijing 1
Nanchang Univ 5
Beijing Red Star 1
Nanchang Univ 5
Beijing Red Star 5
Shenzhen Thunder 6
Guangzhou Honda 5
Beijing Rising 6
Guangzhou Development Bank 3
Tencent 5
Bank of Beijing 6
Nanchang Univ 7
Beijing Red Star 1
Shenzhen Thunder 354
Guangzhou Honda 2
Beijing Rising 1
Guangzhou Development Bank 2
Tencent 334
Bank of Beijing 33
Nanchang Univ 5
Beijing Red Star 1
Nanchang Univ 5
Beijing Red Star 51
Shenzhen Thunder 6
Guangzhou Honda 52
Beijing Rising 66
Guangzhou Development Bank 3
Tencent 5
Bank of Beijing 6
Nanchang Univ 7
Beijing Red Star 1
Shenzhen Thunder 3
Guangzhou Honda 2
Beijing Rising 1
Guangzhou Development Bank 2
Tencent 3
Bank of Beijing 1
Nanchang Univ 5
Beijing Red Star 1
Nanchang Univ 5
Beijing Red Star 5
Shenzhen Thunder 8
Guangzhou Honda 5
Beijing Rising 27
Guangzhou Development Bank 3
Tencent 5
Bank of Beijing 9
Nanchang Univ 7
Beijing Red Star 1
Shenzhen Thunder 3
Guangzhou Honda 2
Beijing Rising 1
Guangzhou Development Bank 2
Tencent 3
Bank of Beijing 11
Nanchang Univ 5
Beijing Red Star 3
Nanchang Univ 5
Beijing Red Star 5
Shenzhen Thunder 6
Guangzhou Honda 5
Beijing Rising 6
Guangzhou Development Bank 3
Tencent 5
Bank of Beijing 6
Nanchang Univ 7
Beijing Red Star 1
Shenzhen Thunder 3
Guangzhou Honda 2
Beijing Rising 1
Guangzhou Development Bank 2
Tencent 3
Bank of Beijing 1
Nanchang Univ 5
Beijing Red Star 1
Nanchang Univ 5
Beijing Red Star 23
Shenzhen Thunder 6
Guangzhou Honda 5
Beijing Rising 6
Guangzhou Development Bank 3
Tencent 5
Bank of Beijing 6
Nanchang Univ 7
file2:addressID cityname
1 Beijing
2 Guangzhou
3 Shenzhen
4 Xian
5 xiamen
6 nanchang
7 sichuan
10 xinjiang
12 shanrao
23 heze
111 fuyang
输出格式:
categoryname addressID cityname
例如:
factoryname addressID addressname
Beijing Red Star 1 Beijing
Beijing Red Star 1 Beijing
Bank of Beijing 1 Beijing
Beijing Rising 1 Beijing
Beijing Red Star 1 Beijing
Beijing Rising 1 Beijing
Beijing Red Star 1 Beijing
Beijing Red Star 1 Beijing
Bank of Beijing 1 Beijing
- 实现:
比较复杂的实现代码见:此处
注意这里实现的连接是内连接。
Bloom Filter的完整实例化代码可以写成:
public static int getOptimalBloomFilterSize(int numRecords, float falsePosRate) {
int size = (int) (-numRecords * (float) Math.log(falsePosRate) / Math
.pow(Math.log(2), 2));
return size;
}
public static int getOptimalK(float numMembers, float vectorSize) {
return (int) Math.round(vectorSize / numMembers * Math.log(2));
}
int numMembers = Integer.parseInt("10000");
float falsePosRate = Float.parseFloat("0.01");
int vectorSize = getOptimalBloomFilterSize(numMembers, falsePosRate);
int nbHash = getOptimalK(numMembers, vectorSize);
BloomFilter filter = new BloomFilter(vectorSize, nbHash, Hash.MURMUR_HASH);
也可以一句话实现:
static private BloomFilter filter1 = new BloomFilter(13287713, 9, MURMUR_HASH);
基本思路是先处理处两个表中共有的addressID,存储filter中,在对两个表进行map的时候过滤掉addressID不在filter中的记录。
可以将filter的内容写入文件存到HDFS,然后从HDFS中读入内容进行判断(实现代码可以参考链接中的博客)。这里我直接使用了本地生成的filter。
实现代码:
package com.company;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.filecache.DistributedCache;
import org.apache.hadoop.mapreduce.lib.input.MultipleInputs;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import static org.apache.hadoop.util.hash.Hash.MURMUR_HASH;
import org.apache.hadoop.util.bloom.BloomFilter;
import org.apache.hadoop.util.bloom.Key;
import javax.security.auth.kerberos.KerberosTicket;
import java.io.*;
import java.util.ArrayList;
public class Sy83 {
static private BloomFilter filter1 = new BloomFilter(13287713, 9, MURMUR_HASH);
static private BloomFilter filter = new BloomFilter(13287713, 9, MURMUR_HASH);
public static class MapLeft extends Mapper<LongWritable, Text, Text, Text>{
@Override
public void map(LongWritable key, Text value, Mapper.Context context) throws IOException, InterruptedException {
String line = value.toString();
System.out.println(line);
String[] keyValue = line.split(" ");
//System.out.println(keyValue.length);
if(keyValue.length<2) return ;
String actoryname = "L", addressID = keyValue[keyValue.length-1];
if(!filter.membershipTest(new Key(addressID.getBytes()))) {
System.out.println("not:"+addressID);
return ;
}
for(int i = 0; i < keyValue.length-1; i++) {
if(i!=0) actoryname += " ";
actoryname += keyValue[i];
}
System.out.println(addressID + " " + actoryname);
context.write(new Text(addressID), new Text(actoryname));
}
}
public static class MapRight extends Mapper<Object, Text, Text, Text>{
public void map(Object key, Text value, Mapper.Context context) throws IOException, InterruptedException {
String line = value.toString();
System.out.println("xx"+line);
String[] keyValue = line.split(" ");
if(keyValue.length<2) return ;
String addressname = "R", addressID = keyValue[0];
for(int i = 1; i < keyValue.length; i++) {
if(i>1) addressname += " ";
addressname += keyValue[i];
}
if(!filter.membershipTest(new Key(addressID.getBytes()))) {
System.out.println("not:"+addressID);
return ;
}
System.out.println(addressID + " " + addressname);
context.write(new Text(addressID), new Text(addressname));
}
}
public static class ReduceTable extends Reducer<Text, Text, Text, Text> {
boolean flag = false;
public void reduce(Text key, Iterable<Text> values, Context context) throws
IOException, InterruptedException {
if(!flag) {
context.write(new Text("factoryname addressID"), new Text(" addressname"));
flag = true;
}
ArrayList<Text> left = new ArrayList<Text>();
ArrayList<Text> right = new ArrayList<Text>();
try{
for (Text value : values) {
String v = value.toString();
//System.out.println(v.substring(1, v.length()));
if(value.charAt(0)=='L') left.add(new Text(v.substring(1, v.length())));
else right.add(new Text(v.substring(1, v.length())));
}
}catch (Exception e){ e.printStackTrace();}
System.out.println();
if(left.size()==0 || right.size()==0) return ;
for(Text L : left)
for(Text R: right)
context.write(new Text(L+" "+key), new Text(" "+R));
}
}
public static void main(String[] args) throws Exception {
long startTime=System.nanoTime(); //获取开始时间
Job job = new Job(new Configuration(), "Jion table");
JobConf conf=new JobConf(Sy83.class);
FileSystem fs=FileSystem.get(conf);
String in1 = "testdata/lab8/myfiles/file1";
String in2 = "testdata/lab8/myfiles/file2";
//String out = "testdata/lab8/out1"+ System.currentTimeMillis();
String out = "testdata/lab8/outx";
if(fs.exists(new Path(out))){
fs.delete(new Path(out), true);
System.out.println("存在此输出路径,已删除!!!");
}
FSDataInputStream In1 = fs.open(new Path(in1));
FSDataInputStream In2 = fs.open(new Path(in2));
BufferedReader br1 = new BufferedReader(new InputStreamReader(In1));
BufferedReader br2 = new BufferedReader(new InputStreamReader(In2));
String line;
while ((line = br2.readLine()) != null) {
//System.out.println(line + " " + line.getBytes().length);
if(line.getBytes().length==0) break ;
String[] parts = line.split(" ");
String addressID = parts[0];
if(!filter1.membershipTest(new Key(addressID.getBytes())))
filter1.add(new Key(addressID.getBytes()));
}
while ((line = br1.readLine()) != null) {
//System.out.println(line + " " + line.getBytes().length);
if(line.getBytes().length==0) break ;
String[] parts = line.split(" ");
String addressID = parts[parts.length-1];
if(filter1.membershipTest(new Key(addressID.getBytes())))
filter.add(new Key(addressID.getBytes()));
}
br1.close(); br2.close();
System.out.println("filter already!");
job.setJarByClass(Sy81.class);
MultipleInputs.addInputPath(job, new Path(in1), TextInputFormat.class, MapLeft.class);
MultipleInputs.addInputPath(job, new Path(in2), TextInputFormat.class, MapRight.class);
job.setReducerClass(ReduceTable.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileOutputFormat.setOutputPath(job, new Path(out));
if(job.waitForCompletion(true)){
long endTime=System.nanoTime(); //获取结束时间
System.out.println("程序运行时间: "+(endTime-startTime)+"ns");
System.exit(0);
}else System.exit(1);
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
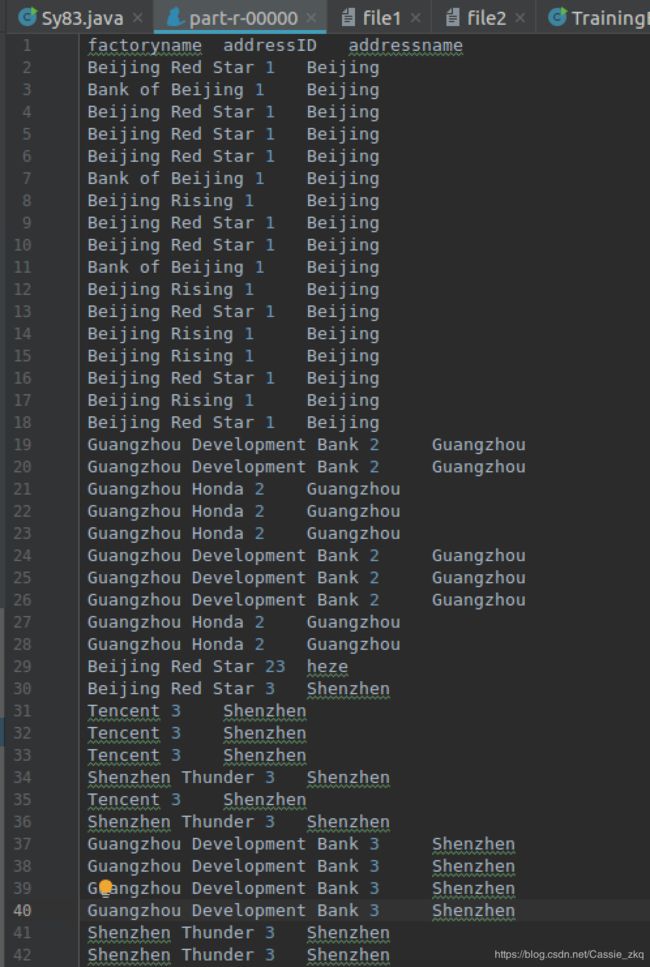
- 结果截图(部分):