深度学习 | 实战8 - 梯度截断
————————————————————————————
原文发表于夏木青 | JoselynZhao Blog,欢迎访问博文原文。
————————————————————————————
Github源码
深度学习教程与实战案列系列文章
深度学习 | 绪论
深度学习 | 线性代数基础
深度学习 | 机器学习基础
深度学习 | 实践方法论
深度学习 | 应用
深度学习 | 安装conda、opencv、pycharm以及相关问题
深度学习 | 工具及实践(TensorFlow)
深度学习 | TensorFlow 命名机制和变量共享、变量赋值与模型封装
深度学习 | TFSlim介绍
深度学习 | TensorFlow可视化
深度学习 | 训练及优化方法
深度学习 | 模型评估与梯度下降优化
深度学习 | 物体检测
深度学习| 实战1-python基本操作
深度学习 | 实战2-TensorFlow基础
深度学习 | 实战3-设计变量共享网络进行MNIST分类
深度学习 | 实战4-将LENET封装为class,并进行分类
深度学习 | 实战5-用slim 定义Lenet网络,并训练测试
深度学习 | 实战6-利用tensorboard实现卷积可视化
深度学习 | 实战7- 连体网络MINIST优化
深度学习 | 实战8 - 梯度截断
深度学习 | 实战9- 参数正则化
要求
要求:在lenet MNIST分类中,应用梯度截断,使得梯度更新时,让每个变量的梯度分量保持在 min=-0.001, max=0.001的范围内。
比较使用如上要求的梯度截断,和不使用梯度截断时,训练过程中,loss的变化情况。
网络采用 lenet,
batch size=8,iter=1000,每隔10步打印一次 mnist.validation.next_batch(100) 的loss和 accuracy。
提交:代码和文档。文档中有训练中的loss,accuracy更新截图。
实验与结果
运行截图
图 1 train.py程序运行截图(无梯度截断)
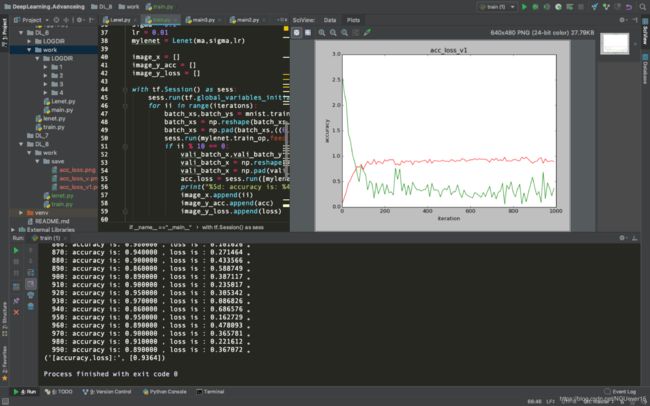
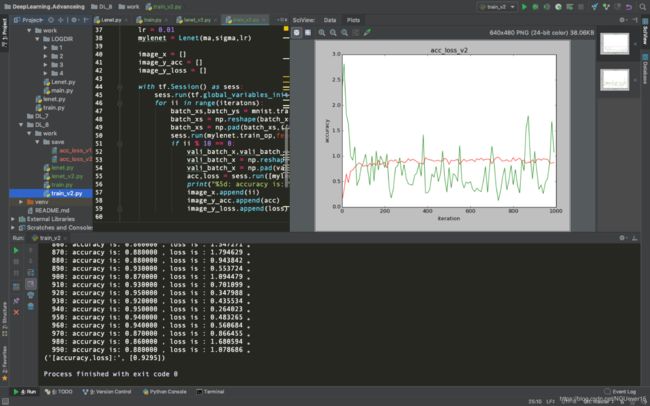
图 2 train_v2程序运行截图(有梯度截断)
实验结果
图 3 train.py实验结果(无梯度截断)
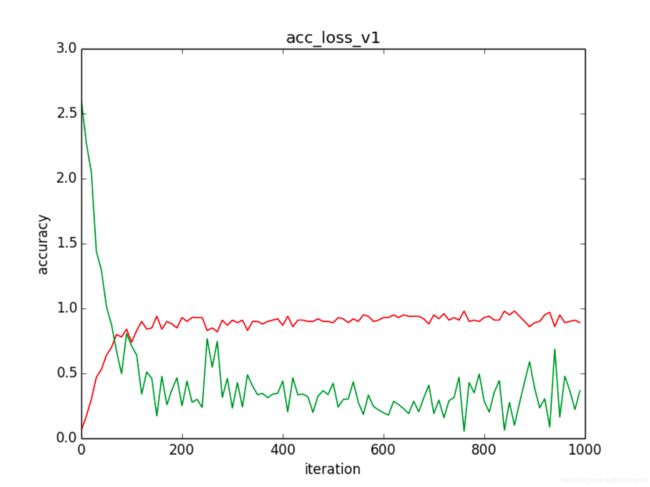
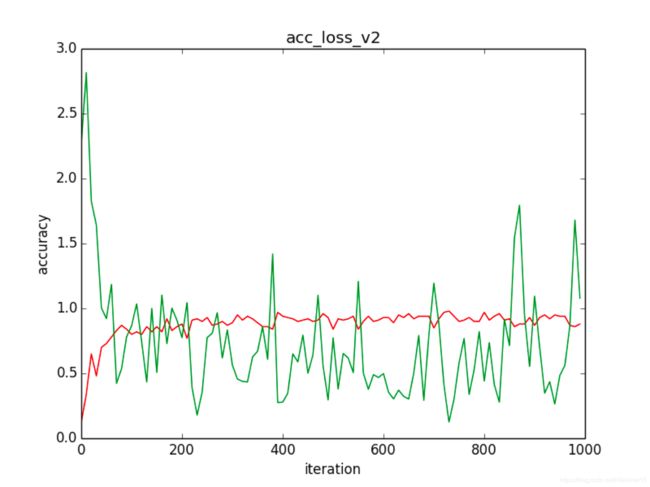
图 4 train_v2.py 运行结果(有梯度截断)
源码展示
LENET
class Lenet():
def __init__(self,mu,sigma,lr=0.02):
self.mu = mu
self.sigma = sigma
self.lr = lr
self.min = -0.001
self.max = 0.001
self._build_graph()
def _build_graph(self,network_name = "Lenet"):
self._setup_placeholders_graph()
self._build_network_graph(network_name)
self._compute_loss_graph()
self._compute_acc_graph()
self._create_train_op_graph()
def _setup_placeholders_graph(self):
self.x = tf.placeholder("float",shape=[None,32,32,1],name='x')
self.y_ = tf.placeholder("float",shape = [None,10],name ="y_")
def _cnn_layer(self,scope_name,W_name,b_name,x,filter_shape,conv_stride,padding_tag="VALID"):
with tf.variable_scope(scope_name):
conv_W = tf.Variable(tf.truncated_normal(shape=filter_shape, mean=self.mu, stddev=self.sigma), name=W_name)
conv_b = tf.Variable(tf.zeros(filter_shape[3]),name=b_name)
conv = tf.nn.conv2d(x, conv_W, strides=conv_stride, padding=padding_tag) + conv_b
return conv
def _pooling_layer(self,scope_name,x,pool_ksize,pool_strides,padding_tag="VALID"):
with tf.variable_scope(scope_name):
pool = tf.nn.max_pool(x, ksize=pool_ksize, strides=pool_strides, padding=padding_tag)
return pool
def _fully_connected_layer(self,scope_name,W_name,b_name,x,W_shape):
with tf.variable_scope(scope_name):
fc_W = tf.Variable(tf.truncated_normal(shape=W_shape, mean=self.mu, stddev=self.sigma),name=W_name)
fc_b = tf.Variable(tf.zeros(W_shape[1]),name=b_name)
fc = tf.matmul(x, fc_W) + fc_b
return fc
def _build_network_graph(self,scope_name):
with tf.variable_scope(scope_name):
conv1 =self._cnn_layer("conv1","w1","b1",self.x,[5,5,1,6],[1, 1, 1, 1])
self.conv1 = tf.nn.relu(conv1)
self.pool1 = self._pooling_layer("pool1",self.conv1,[1, 2, 2, 1],[1, 2, 2, 1])
conv2 = self._cnn_layer("conv2","w2","b2",self.pool1,[5,5,6,16],[1, 1, 1, 1])
self.conv2 = tf.nn.relu(conv2)
self.pool2 = self._pooling_layer("pool2",self.conv2,[1, 2, 2, 1],[1, 2, 2, 1])
self.fc0 = self._flatten(self.pool2)
fc1 = self._fully_connected_layer("fc1","wfc1","bfc1",self.fc0,[400,120])
self.fc1 = tf.nn.relu(fc1)
fc2 = self._fully_connected_layer("fc2","wfc2","bfc2",self.fc1,[120,84])
self.fc2 = tf.nn.relu(fc2)
self.y = self._fully_connected_layer("fc3","wfc3","bfc3",self.fc2,[84,10])
def _flatten(self,conv):
conv1 = tf.reshape(conv, [-1, 400])
return conv1
def _compute_loss_graph(self):
with tf.name_scope("loss_function"):
loss = tf.nn.softmax_cross_entropy_with_logits(labels = self.y_,logits = self.y)
self.loss = tf.reduce_mean(loss)
def _compute_acc_graph(self):
with tf.name_scope("acc_function"):
correct_prediction = tf.equal(tf.argmax(self.y,1),tf.argmax(self.y_,1))
self.accuracy = tf.reduce_mean(tf.cast(correct_prediction,tf.float32))
def _create_train_op_graph(self):
with tf.name_scope("train_function"):
var_list = tf.trainable_variables()
self.optimizer = tf.train.AdamOptimizer(self.lr)
self.gradients = self.optimizer.compute_gradients(self.loss, var_list)
self.capped_gradients = [(tf.clip_by_value(grad, self.min, self.max), var) for grad, var in self.gradients if
grad is not None]
self.train_op = self.optimizer.apply_gradients(self.capped_gradients)
train
from lenet_v2 import *
if __name__ =="__main__":
mnist = input_data.read_data_sets('../../../data/mnist', one_hot=True)
x_test = np.reshape(mnist.test.images,[-1,28,28,1])
x_test = np.pad(x_test, ((0, 0), (2, 2), (2, 2), (0, 0)), 'constant') # print("Updated Image Shape: {}".format(X_train[0].shape))
tf.logging.set_verbosity(old_v)
iteratons = 1000
batch_size = 8
ma = 0
sigma = 0.1
lr = 0.01
mylenet = Lenet(ma,sigma,lr)
image_x = []
image_y_acc = []
image_y_loss = []
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for ii in range(iteratons):
batch_xs,batch_ys = mnist.train.next_batch(batch_size)
batch_xs = np.reshape(batch_xs,[-1,28,28,1])
batch_xs = np.pad(batch_xs,((0, 0), (2, 2), (2, 2), (0, 0)), 'constant')
sess.run(mylenet.train_op,feed_dict ={mylenet.x:batch_xs,mylenet.y_:batch_ys})
if ii % 10 == 0:
vali_batch_x,vali_batch_y = mnist.validation.next_batch(100)
vali_batch_x = np.reshape(vali_batch_x,[-1,28,28,1])
vali_batch_x = np.pad(vali_batch_x,((0, 0), (2, 2), (2, 2), (0, 0)), 'constant')
acc,loss = sess.run([mylenet.accuracy,mylenet.loss],feed_dict ={mylenet.x:vali_batch_x,mylenet.y_:vali_batch_y})
print("%5d: accuracy is: %4f , loss is : %4f 。" % (ii, acc, loss))
image_x.append(ii)
image_y_acc.append(acc)
image_y_loss.append(loss)
plt.plot(image_x, image_y_acc, 'r', label="accuracy")
plt.plot(image_x, image_y_loss, 'g', label="loss")
plt.xlabel("iteration")
plt.ylabel("accuracy")
plt.title("acc_loss_v2")
plt.savefig('./save/acc_loss_v2.png')
plt.show()
print('[accuracy,loss]:', sess.run([mylenet.accuracy], feed_dict={mylenet.x:x_test,mylenet.y_:mnist.test.labels}))