Titanic | 实战(三)
1. 获取和加载数据
import os
import pandas as pd
TITANIC_PATH = os.path.join("datasets", "titanic")
def load_titanic_data(filename, titanic_path=TITANIC_PATH):
# 加载数据
csv_path = os.path.join(titanic_path, filename)
return pd.read_csv(csv_path)
train_data = load_titanic_data("train.csv") # 数据已经分为训练集和测试集
test_data = load_titanic_data("test.csv")
train_data.head()
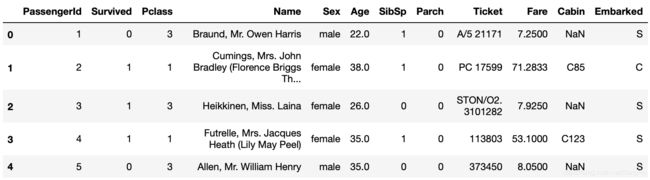
数据的意义:

2. 探索数据
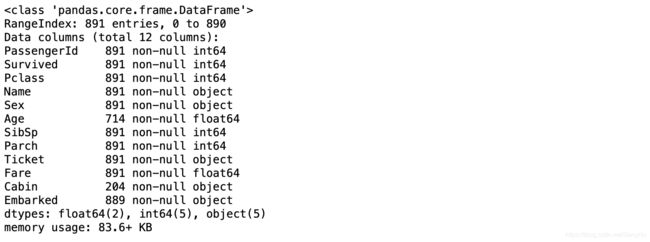
# 检查有哪些数据项有残缺值
train_data.info()
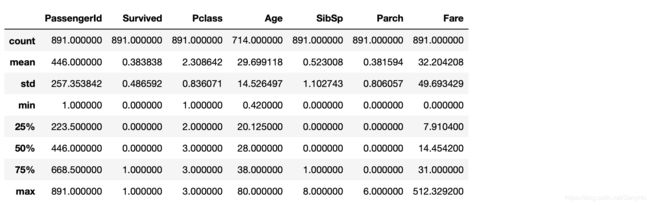
# 检查哪些数据是数值的
train_data.describe()
# 检查目标值是否为0或1
train_data["Survived"].value_counts()

# 查看哪些数据是为类别属性
train_data["Pclass"].value_counts()

train_data["Sex"].value_counts()

train_data["Embarked"].value_counts()

3. 预处理
try:
from sklearn.impute import SimpleImputer # Scikit-Learn 0.20+
except ImportError:
from sklearn.preprocessing import Imputer as SimpleImputer
num_attribs = ["Age", "SibSp", "Parch", "Fare"]
# 处理数值属性中的残缺值
num_preprocess = SimpleImputer(strategy="median")
num_preprocess.fit_transform(train_data[num_attribs])

from sklearn.base import BaseEstimator, TransformerMixin
from sklearn.pipeline import Pipeline
class MostFrequentImputer(BaseEstimator, TransformerMixin):
"""处理类别变量的残缺值"""
def fit(self, X, y=None):
self.most_frequent_ = pd.Series([X[c].value_counts().index[0] for c in X], index=X.columns)
return self
def transform(self, X, y=None):
return X.fillna(self.most_frequent_)
try:
from sklearn.preprocessing import OrdinalEncoder # just to raise an ImportError if Scikit-Learn < 0.20
from sklearn.preprocessing import OneHotEncoder
except ImportError:
from future_encoders import OneHotEncoder # Scikit-Learn < 0.20
cat_attribs = ["Pclass", "Sex", "Embarked"]
# 创建一个处理类别变量中残缺值的pipeline
cat_pipeline = Pipeline([
("imputer", MostFrequentImputer()),
("cat_encoder", OneHotEncoder(sparse=False)),
])
try:
from sklearn.compose import ColumnTransformer
except ImportError:
from future_encoders import ColumnTransformer # Scikit-Learn < 0.20
# 创建一个预处理类别变量和数值变量的pipeline
preprocess_pipeline = ColumnTransformer([
("num", SimpleImputer(strategy="median", num_attribs)),
("cat", cat_pipeline, cat_attribs),
])
X_train = preprocess_pipeline.fit_transform(train_data)
X_train

4. 建立预测模型
y_train = train_data["Survived"]
from sklearn.svm import SVC
# 建立一个支持向量机的分类器
svm_clf = SVC(gamma="auto")
svm_clf.fit(X_train, y_train)

X_test = preprocess_pipeline.transform(test_data)
y_pred = svm_clf.predict(X_test)
from sklearn.model_selection import cross_val_score
# 检测模型的准确程度
svm_scores = cross_val_score(svm_clf, X_train, y_train, cv=10)
svm_scores.mean()
![]()
from sklearn.ensemble import RandomForestClassifier
forest_clf = RandomForestClassifier(n_estimators=100, random_state=42)
forest_scores = cross_val_score(forest_clf, X_train, y_train, cv=10)
forest_scores.mean()
![]()
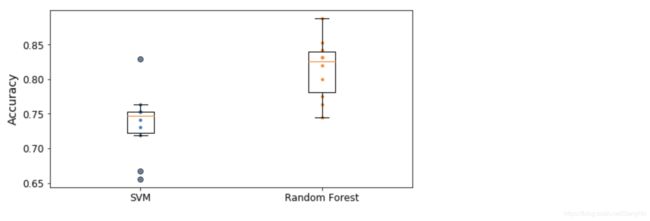
plt.figure(figsize=(8, 4))
plt.plot([1]*10, svm_scores, ".")
plt.plot([2]*10, forest_scores, ".")
plt.boxplot([svm_scores, forest_scores], labels=("SVM","Random Forest"))
plt.ylabel("Accuracy", fontsize=14)
plt.show()
5.特征工程
train_data["AgeBucket"] = train_data["Age"] // 15 * 15
train_data[["AgeBucket", "Survived"]].groupby(['AgeBucket']).mean()

train_data["RelativesOnboard"] = train_data["SibSp"] + train_data["Parch"]
train_data[["RelativesOnboard", "Survived"]].groupby(['RelativesOnboard']).mean()
