DroNet: Learning to Fly by Driving 论文解读: Deep-Learning在无人机导航中的应用
本篇为DroNet的解读. 原论文:
Antonio Loquercio, Ana I. Maqueda, Carlos R. del-Blanco, , and Davide Scaramuzza, “DroNet: Learning to Fly by Driving”, IEEE ROBOTICS AND AUTOMATION LETTERS, VOL. 3, NO. 2, APRIL 2018
文章目录
- DroNet: Learning to Fly by Driving
- 简介
- 主要贡献
- 关于网络与训练方法
- 数据集
- 飞机运动控制方法
- 实验结果
DroNet: Learning to Fly by Driving
简介
DroNet是一个结构非常简单但是又非常强大的网络结构, 可以通过输入的每帧图像输出当前飞行器yaw的目标角度值与前方障碍物的概率值, 从而可以利用这两个信息推断出飞行器当前运动时的yaw应转角度 θ k \theta_k θk与前进飞行速度 v k v_k vk, 从而达到自主导航的目的. 对比论文发布当时的其他相关网络模型, 达到了最好的准确度与处理速度的平衡.
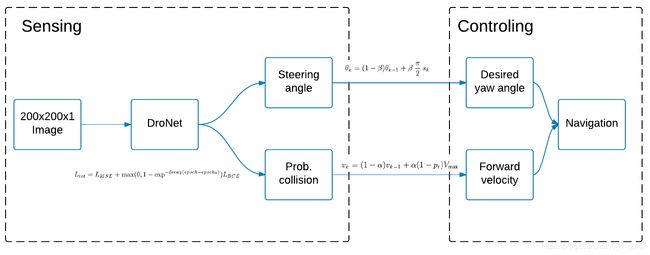 该系统在非机载处理资源上运行(Intel Core i7 2.6 GHz CPU)上可以达到30Hz的控制指令输出. 可想如果机载选择TX2此类处理器, 采用gpu进行推理计算的话, 速度应该也不会差, 可以满足实时性的要求.
该系统在非机载处理资源上运行(Intel Core i7 2.6 GHz CPU)上可以达到30Hz的控制指令输出. 可想如果机载选择TX2此类处理器, 采用gpu进行推理计算的话, 速度应该也不会差, 可以满足实时性的要求.
该模型的训练数据采用室外场景下在地面交通工具上采集的数据集, 比如自行车, 汽车等在城市环境内第一视角的图像与其他数据. 实验结果惊奇的发现该方法不仅在室外不同视角下表现极好(5m飞行高度), 在室内场景中也有极强的泛化能力. 飞机可以在没有先验信息的环境中也可以有一个非常好的导航效果.
主要贡献
文章以"无人机应该像其他地面交通工具一样, 在roadway中有相同的behavior"为出发点, 通过来自于地面交通工具的数据集, 做了以下主要工作:
- 提出了一种 residual convolutional architecture (DroNet), 可以预测飞机要转的偏航角与前方发生与障碍物碰撞的概率, 可以为飞机在城市环境中提供安全的飞行. 通过来自于室外场景下汽车, 自行车的数据集来训练该网络.
- 建立了一个关于预测是前方障碍物概率的数据集.
- 为飞机实际的导航提出了一种很好的方式, 可以到到很好的performance和real-time.
- 通过一些扩展场景的检验, 发现该系统的泛化能力极强, 可以在没有任何先验信息的环境中正常运行, 包括数据集中没有的室内走廊场景, 一个比较高的高度(视角不一样)等场景.
文章作者还提到该方法并不是为了替代传统的"map-localize-plan"方法, 作者认为将来有一天传统方法与基于深度学习的方法会互补.
关于网络与训练方法
网络的结构图如下:
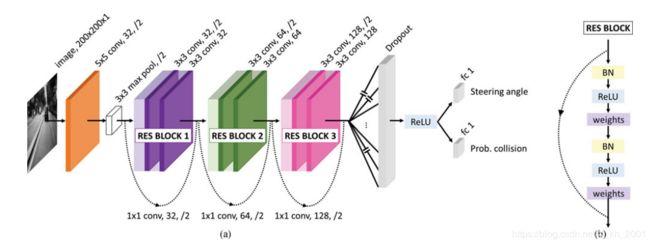 输出的转角与障碍物信息两个功能在前面共用同一个网络结构(共享同一套参数). 输入的图像是一张200x200x1的灰度图, 通过一个5x5的卷积核降维后, 通过三层res block, 然后经过dropout(作者实验时设的是0.5)后再分叉, 通过Relu后作用于两个全连接层(节点数为1)分别输出信息(大小范围均在0-1之间). 关于为何有这样的设计想法, 作者并未多提.
输出的转角与障碍物信息两个功能在前面共用同一个网络结构(共享同一套参数). 输入的图像是一张200x200x1的灰度图, 通过一个5x5的卷积核降维后, 通过三层res block, 然后经过dropout(作者实验时设的是0.5)后再分叉, 通过Relu后作用于两个全连接层(节点数为1)分别输出信息(大小范围均在0-1之间). 关于为何有这样的设计想法, 作者并未多提.
通过代码看到最终collision这个全连接节点最终输出还被作用了一个sigmod函数, 这个论文中并未提到为何. 猜测是用于归一化(概率值必须大于0小于1, 而刚开始训练的时候loss大多依据(后面会讲到)steering的loss, 可能会出现[-1, 0]之间的数, 所以要归一化到(0,1)) / 某种意义上的数据增强? 具体只能等跑训练代码的时候看一下实际该参数的值.
cnn_models.py
85 # Collision channel
86 coll = Dense(output_dim)(x)
87 coll = Activation('sigmoid')(coll)
关于训练方法:
关于转角的预测本质是一个回归问题, 关于障碍物的检测本质是一个二分类问题(虽然最后输出的是概率, 但是从数据集本质来看是一个二分类问题,这个后续详述). 该网络比较特殊(两种不同的问题模型的输出, 共享网络), 所以要设计出一种合理的loss函数.
根据两类问题的本质, 转角预测本质为回归问题所以采用均方误差(MSE)衡量loss; 障碍物概率预测本质为二分类问题所以采用二值交叉熵(BCE)来衡量学习到的分布与样本真实分布的差异, 作为loss. 但是整个网络不能简单使用两个loss叠加来来作为最终的loss, 会导致特别差的收敛结果, 因为回归问题和分类问题在模型刚开始训练的时候, 梯度大小差异非常大参考文献.
实际中, 回归问题的梯度在刚开始的时候会非常大, MSE的梯度正比于转角的误差值. 所以策略就是刚开始的时候几乎只选择用转角的loss, 后面随着epoch的增加慢慢增大障碍物概率检测的loss的权重, 等到两者loss在一个数量级可比的时候, optimizer就会自动为两者找到一个很好的solution. 该方式的解释也在上一个参考文献链接里, 不设权重或者权重恒定的方法都会导致不好的结果或者收敛时间过长. 所以依据此作者提出了下面的loss:
L t o t = L M S E + max ( 0 , 1 − exp − d e c a y ( e p o c h − e p o c h 0 ) ) L B C E L_{t o t}=L_{M S E}+\max \left(0,1-\exp ^{-d e c a y\left(e p o c h-e p o c h_{0}\right)}\right) L_{B C E} Ltot=LMSE+max(0,1−exp−decay(epoch−epoch0))LBCE
该方式就可以达到上面所说的期望的训练过程中的loss函数变化情况. 作者在实验时选择 d e c a y = 1 10 decay=\frac{1}{10} decay=101, e p o c h 0 = 10 epoch_{0}=10 epoch0=10.
optimizer选择Adam, 初始学习率设为0.001, decay=1e-5.
最后作者为 optimization 还采用了 hard negative mining来建立负样本集, 在每一个epoch中选择loss最高的k个样本, 采用上面计算loss的式子计算整体loss(整体?TODO). k会随着时间会减小.
数据集
关于转角预测(Steering angle)采用来自Udacity’s project的公共数据集, 该数据集是基于汽车拍摄的. 里面有三个摄像头以及imu, gps, steering angle等其他同步的数据, 作者只选用前置摄像头与steering angle作为模型训练时所采用的数据.
关于用于计算障碍物概率的数据集, 由于没有合适的数据集, 作者们自制了一套相关数据集,137个场景序列中包含了32000张图片. 根据视野障碍物是否离得特别近来标注 0(无碰撞风险) 和 1(有碰撞风险). 例图如下, 绿色表示无碰撞风险, 红色表示有碰撞风险.

飞机运动控制方法
整体的导航思路很简单, 飞机一直在同一高度飞行, 只控制飞机的两个自由度, 机体坐标系下前进的速度 v k v_k vk和世界坐标系下的yaw值 θ k \theta_k θk.
-
根据网络输出的前方发生与障碍物碰撞的概率 p t p_t pt计算前进的速度 v k v_k vk:
v k = ( 1 − α ) v k − 1 + α ( 1 − p t ) V max v_{k}=(1-\alpha) v_{k-1}+\alpha\left(1-p_{t}\right) V_{\max } vk=(1−α)vk−1+α(1−pt)Vmax
公式很简单, 即前方发生碰撞概率越大, 前进的速度越低, 发生碰撞概率为1的时候速度为0.然后加了低通滤波使速度输出更平滑( 0 < α < 1 0<\alpha<1 0<α<1). -
根据网络输出的steering angle换算成实际要转的偏航角大小. 网络输出的范围为[-1, 1], 换算成 [ − π 2 , π 2 ] \left[-\frac{\pi}{2}, \frac{\pi}{2}\right] [−2π,2π]. 然后也同理加了个低通滤波:
θ k = ( 1 − β ) θ k − 1 + β π 2 s k \theta_{k}=(1-\beta) \theta_{k-1}+\beta \frac{\pi}{2} s_{k} θk=(1−β)θk−1+β2πsk
然后根据这两个值赋给飞机就可以控制飞机运动了. 作者在试验中选择的 α = 0.7 \alpha=0.7 α=0.7和 β = 0.5 \beta=0.5 β=0.5. V max V_{\max } Vmax根据实验场景不同选择合适的值即可.
实验结果
作者在大量场景中进行了测试, 具体的测试结果这里不在赘述.
DroNet模型是一个平衡结果准确性与运算速度的最佳的模型.
@author Kehan Xue
@e-mail [email protected]
2019/06/08