libsvm C++中使用 菜鸟级别
本次使用libsvm进行二分类。
数据集UCI的Adult:http://archive.ics.uci.edu/ml/datasets/Adult
工具:libsvm
语言:C++
看了很多libsvm C++的博客,有些人的和一坨屎一样。
感谢这两位博主:
https://blog.csdn.net/lhanchao/article/details/53367532
https://blog.csdn.net/zilongreco/article/details/41390385
给了非常多的有用信息。
我自己文笔拙劣,说不准自己都没有把意思讲明白,但是我确实想分享给大家,不当之处还请见谅!
libsvm结构体:
里面介绍了svm_problem、svm_node等等的结构体,给了非常大的帮助,再次感谢。
想要写C++的用libsvm的代码,必须要看懂结构体。
下面的是libsvm源码里面的
struct svm_node
{
int index;
double value;
};
struct svm_problem
{
int l;
double *y;
struct svm_node **x;
};svm_node是储存一个特征的序号和值的。index是序号,值是value。
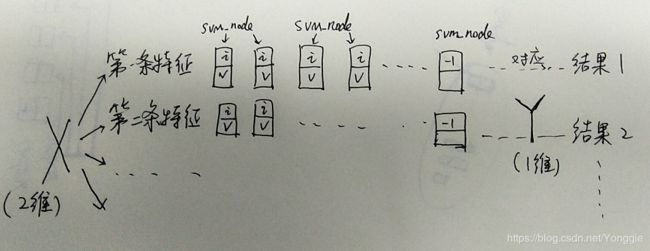
举个例子:2个特征1个结果的数据,一个特征对应一个node。
svm_problem是储存整个特征的结构体
int l是数据条数,就是你有多少条数据;y是每条数据中的分类结果;x是一个二维数组,装你数据所有的特征。
用个比较像二维数组的图来说,这个图里的大X和大Y就是svm_problem里面的x和y。
做分类无非就这么几步:
1.加载数据
2.清洗数据包括归一化之类的
3.喂训练数据训练
4.预测验证
清洗代码我使用Python写的,在文章后面。
准备工作:
用libsvm你首先得下载吧?
下载好了,直接打开它,找到里面的svm.h、svm-train.c、svm.cpp(这个貌似不用)。
你用其他小工具的话,只需要把这几个文件搞到同一目录就好,反正引入文件而已,没什么好说的。
你用VS的话,新建一个项目,把svm.h引入进去,把svm-train.c和svm.cpp引入进去。
这样你的项目就变成这样的目录,我项目名字叫libsvm_play,算是玩玩。
导进去之后你找到svm.cpp中的main。
他这个main,是用控制台的,我们这个版本是用代码直接运行的,所以我们不要他这个main,直接删掉或者注释掉。

对了VS的话你最好设置下不用pch.h……
代码分析:
加载数据和清洗数据代码是用Python写的,在文章后面,我们略过不谈。
我把清洗好的数据放在了Data这个二维数组里。
TrainingNumber是训练数据量、FeatureNumber是特征数量(包括了分类结果)。
我先new了新的存放特征的x_space,然后再把svm_problem的指针指向它,还方便些。
x_node的index等于-1,就表明一条数据的特征的输入结束。
一定要记得加-1!
void FeedData(svm_problem *problem){
if (param.gamma == 0) param.gamma = 0.5;
problem->l = TrainingNumber;
problem->y = new double[problem->l];
svm_node *x_space = new svm_node[(FeatureNumber + 1)*problem->l];//to restore feature
problem->x = new svm_node *[problem->l]; //every X points to one sample
int cnt = 0;
for (int i = 0;i < TrainingNumber;i++) {
int before = cnt;
for (int j = 0;j < FeatureNumber-1;j++) {
x_space[cnt].index = j;
x_space[cnt].value = Data[i][j];
cnt++;
}
x_space[cnt].index = -1;
cnt++;
problem->x[i] = &x_space[before];
problem->y[i] = Data[i][FeatureNumber - 1];
}
}
整个文件放上来,
代码略长,其中关键的只有我上面的把数据喂进SVM,train SVM只需要调用一个函数就行了,predict同样也只需要调用函数,一行而已。
#include
#include
#include
#include
#include
#include
附:
由于这个数据集是字符型的,C++又是相对底层的语言,我用python进行了数据清洗,让数据编程能直接喂到SVM的数据。
放一下Python代码:
class Modifier:
def __init__(self):
self.Data=[]
self.RawData=[]
self.NUMOFDATA=0
self.NUMOFFEATURE=0
self.GetClass={}
self.SecondFeatureMin = 12285
self.SecondFeatureMax = 1484705
self.Second = self.SecondFeatureMax - self.SecondFeatureMin
def LoadData(self, PATH):
with open(PATH, 'r') as f:
for line in f:
self.RawData.append([thing.strip() for thing in line.split(',')])
self.RawData = self.RawData[:-1]
self.NUMOFDATA = len(self.RawData)
def ShowRawData(self):
for item in self.RawData:
print(item)
def WashData(self):
attribute = len(self.RawData[0])
# print("attribute: {}".format(attribute))
index = 0
while index < attribute:
# print('index: {}'.format(index))
cnt = 0
temp = [i[index] for i in self.RawData]
for item in temp:
if item not in self.GetClass:
self.GetClass[item] = cnt
cnt += 1
index += 1
self.NUMOFFEATURE = index
# print("feature number is {}.".format(self.NUMOFFEATURE))
for line in self.RawData:
t = []
for j, f in enumerate(line):
if j == 0:
t.append(float(f) / 10)
elif j == 2:
t.append(round(float(f) / self.Second, 4))
elif j == 10 or j == 11:
t.append(float(f) / 2000)
elif j == 12:
t.append(float(f) / 10)
elif j==14:
t.append(self.GetClass[f] )
else:
t.append(self.GetClass[f]/10)
self.Data.append(t)
# print("data length is {}".format(len(self.Data[0])))
def ShowData(self):
for item in self.Data:
print(item)
def WriteData(self,PATH):
with open(PATH,'w') as f:
for item in self.Data:
f.write(','.join([str(i) for i in item])+'\n')
if __name__=='__main__':
m=Modifier()
m.LoadData(r"C:\Users\Lenovo\Desktop\adult.csv")
#m.ShowRawData()
m.WashData()
#m.ShowData()
m.WriteData(r"C:\Users\Lenovo\Desktop\adult_new.csv")