达梦DCA培训笔记
根据达梦DCA培训的讲师笔记,自己跟着做了一遍并整理。
1、达梦数据库的安装
1.1 收集软件信息
// 操作系统
[root@localhost ~]# cat /etc/issue
NeoKylin Linux General Server release 6.0 (Dhaulagiri)
Kernel \r on an \m
// Linux内核
[root@localhost ~]# uname -r
2.6.32-220.el6.x86_64
1.2 收集硬件信息
// CPU信息
[root@localhost ~]# cat /proc/cpuinfo
// 磁盘信息
[root@localhost ~]# fdisk -l
[root@localhost ~]# df -h
1.3 规划安装路径(软件,数据库文件)
[root@localhost ~]# mkdir /dm7
1.4 规划用户(不建议使用root,创建dmdba用户)
// 查看dmdba用户是否存在
[root@localhost ~]# id dmdba
id: dmdba:无此用户
You have mail in /var/spool/mail/root
// 创建用户组
[root@localhost ~]# groupadd dinstall
You have new mail in /var/spool/mail/root
// 创建dmdba并指定用户组
[root@localhost ~]# useradd -g dinstall dmdba
// 校验用户是否创建成功
[root@localhost ~]# id dmdba
uid=500(dmdba) gid=501(dinstall) 组=501(dinstall)
// 给用户设置密码(我这里是dm123456)
[root@localhost ~]# passwd dmdba
// 修改安装路径的权限
[root@localhost /]# ll -dl /dm7
drwxr-xr-x 2 root root 4096 10月 26 11:07 /dm7
[root@localhost /]# chown dmdba.dinstall -R /dm7
[root@localhost /]# ll -dl /dm7
drwxr-xr-x 2 dmdba dinstall 4096 10月 26 11:07 /dm7
1.5 配置环境变量(可选项,方便实用达梦命令)
[root@localhost /]# cd /home/dmdba
[root@localhost dmdba]# vi .bash_profile
// 在.bash_profile最后增加
export DM_HOME=/dm7
export PATH=$DM_HOME/bin:$DM_HOME/tool:$PATH:$HOME/bin
// 验证是否配置成功
[root@localhost dmdba]# source .bash_profile
[root@localhost dmdba]# echo $DM_HOME
/dm7
1.6 配置文件最大打开数量
[root@localhost dmdba]# vi /etc/security/limits.conf
// 在最后增加
dmdba soft nofile 4096
dmdba hard nofile 65536
// 查看配置(需要重启)
[root@localhost dmdba]# ulimit -a
1.7 准备安装包(使用winscp等软件把安装包放入/installdoc目录)
[root@localhost /]# mkdir /installdoc
[root@localhost /]# cd /installdoc/
[root@localhost installdoc]# ls -l
总用量 575428
-rw-r--r-- 1 root root 589234176 10月 14 10:51 dm7_setup_rh6_64_ent_7.6.0.197_20190917.iso
// 挂载
[root@localhost installdoc]# mount -o loop dm7_setup_rh6_64_ent_7.6.0.197_20190917.iso /mnt
[root@localhost installdoc]# cd /mnt/
[root@localhost mnt]# ls -l
总用量 575058
-r-xr-xr-x 1 root root 584382798 9月 16 11:04 DMInstall.bin
-r-xr-xr-x 1 root root 2266249 9月 12 16:45 DM_Install_en.pdf
-r-xr-xr-x 1 root root 2207674 9月 12 16:45 DM_Install_zh.pdf
-r-xr-xr-x 1 root root 868 9月 12 16:48 release_en.txt
-r-xr-xr-x 1 root root 973 9月 12 16:48 release_zh.txt
1.8 达梦数据库安装
[root@localhost mnt]# export DISPLAY=:0.0
[root@localhost mnt]# xhost +
access control disabled, clients can connect from any host
[root@localhost mnt]# su - dmdba
[dmdba@localhost mnt]$ ./DMInstall.bin
解压安装程序.........


[root@localhost ~]# /dm7/script/root/root_installer.sh
移动 /dm7/bin/dm_svc.conf 到/etc目录
修改服务器权限
创建DmAPService服务
移动服务脚本文件(/dm7/bin/DmAPService 到 /etc/rc.d/init.d/DmAPService)
创建服务(DmAPService)完成
启动DmAPService服务
Starting DmAPService: [ OK ]

1.9 卸载软件
// 已经存在数据库的需要先停止数据库,执行uninstall.sh
// 不存在数据库的可以直接执行uninstall.sh
1.10 创建数据库
-
dmint
// 注:这里创建的SYSDBA的默认密码是SYSDBA [dmdba@localhost bin]$ ./dminit path=/dm7/data/ db_name=DM01 instance_name=TEST1 port_num=5237 initdb V7.6.0.197-Build(2019.09.12-112648)ENT db version: 0x7000a file dm.key not found, use default license! License will expire on 2020-09-12 log file path: /dm7/data/DM01/DM0101.log log file path: /dm7/data/DM01/DM0102.log write to dir [/dm7/data/DM01]. create dm database success. 2019-10-26 13:34:40 // 使用root用户执行 [root@localhost ~]# /dm7/script/root/dm_service_installer.sh -t dmserver -p TEST1 -i /dm7/data/DM01/dm.ini 移动服务脚本文件(/dm7/bin/DmServiceTEST1 到 /etc/rc.d/init.d/DmServiceTEST1) 创建服务(DmServiceTEST1)完成 -
dbca.sh(数据库配置助手)
[dmdba@localhost dm7]$ dbca.sh 2019-10-26 13:14:53 [com.dameng.dbca.Startup] [INFO] 启动DBCA


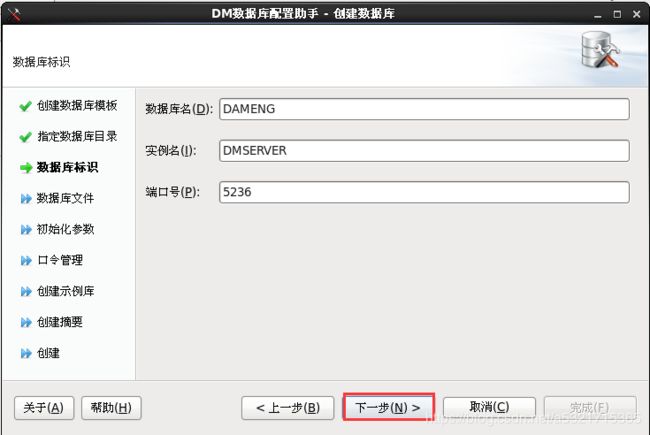
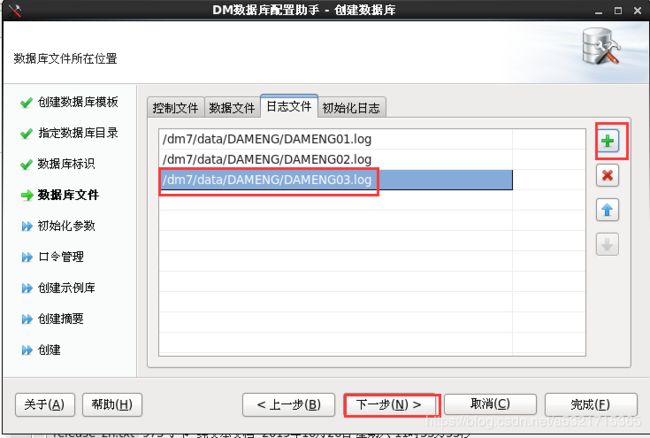
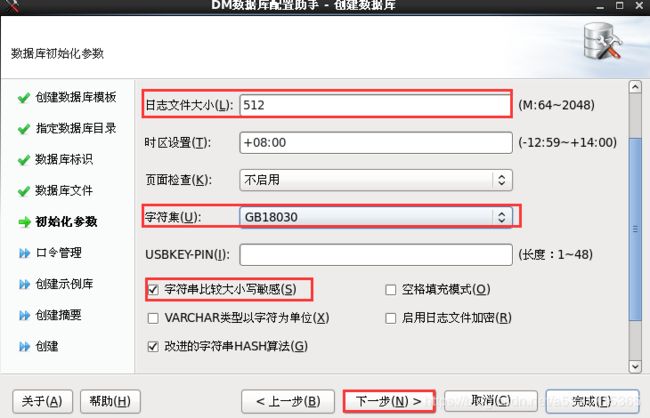

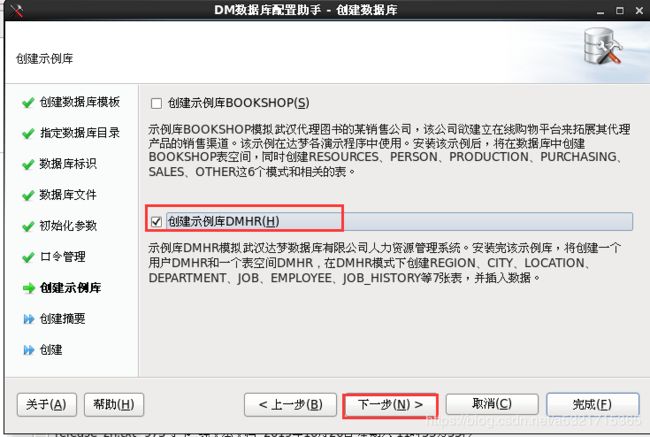
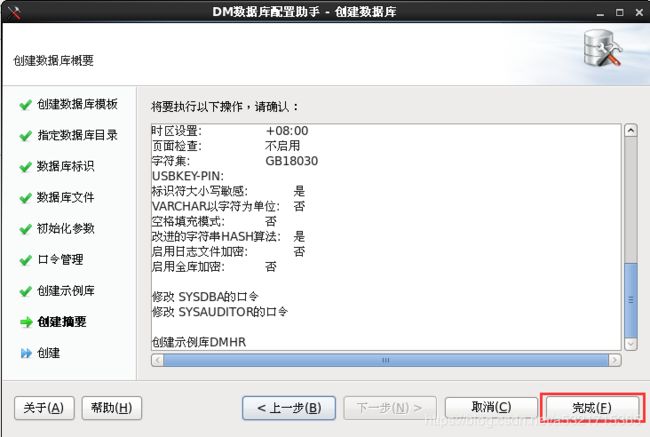
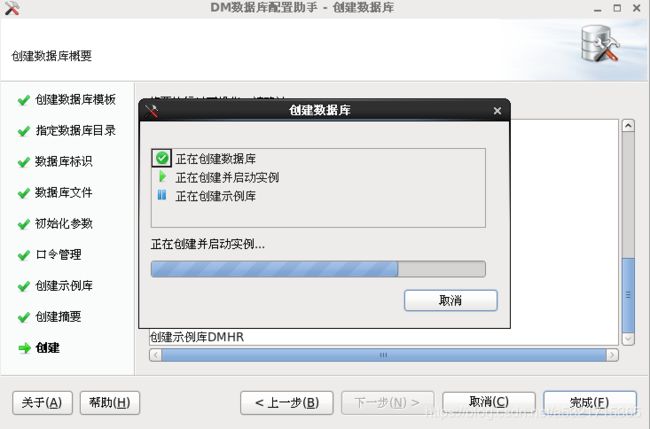
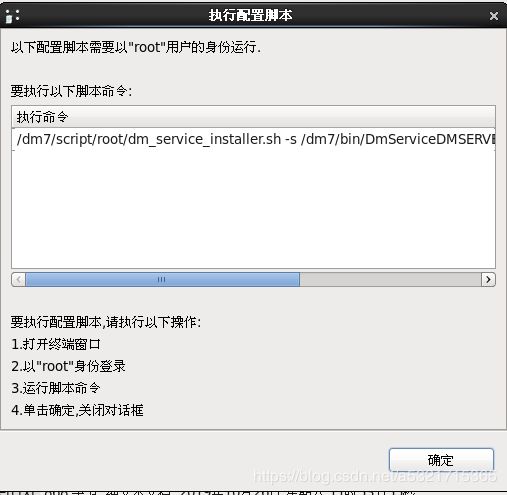
[root@localhost ~]# /dm7/script/root/dm_service_installer.sh -s /dm7/bin/DmServiceDMSERVER
移动服务脚本文件(/dm7/bin/DmServiceDMSERVER 到 /etc/rc.d/init.d/DmServiceDMSERVER)
创建服务(DmServiceDMSERVER)完成
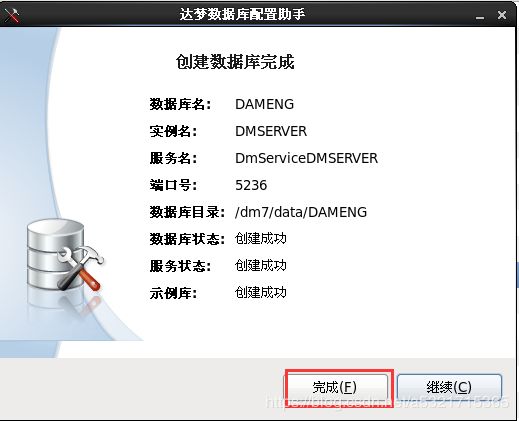
1.11 连接数据库
-
bin目录下disql
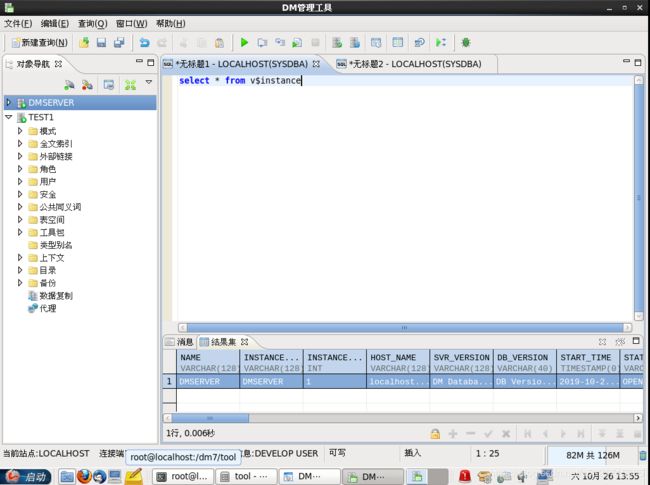
[dmdba@localhost bin]$ disql sysdba/dameng123 服务器[LOCALHOST:5236]:处于普通打开状态 登录使用时间: 21.114(毫秒) disql V7.6.0.197-Build(2019.09.12-112648)ENT SQL> select * from v$instance; [dmdba@localhost bin]$ disql SYSDBA/SYSDBA:5237 -
tool目录下manager
[dmdba@localhost tool]$ ./manager
2、数据库的实例管理
2.1 数据库的状态
- shutdown:关闭
- mount:配置模式
- open:打开
- suspend:挂起
2.2 状态切换
- shutdown ==> mount
shutdown ==> open
mount ==> open
open ==> mount
open ==> shutdown
open ==> suspend
suspend ==> open
2.3 启动过程
1.shutdown ==> mount
分配共享内存,启动后台的进程或者进程,打开控制文件
2.mount ==> open
根据控制文件,打开所有的数据文件和重做日志文件
// 使用脚本启动服务
// LINUX6
# service DmServiceTEST1 start/stop/restart
// LINUX7
# systemctl start/stop/restart DmServiceTEST1
2.4 数据库的状态切换
// 数据库状态查看
SQL> select status$ from v$instance;
// open到mount
SQL> alter database mount;
// mount 状态到open
SQL> alter database open;
3、DM7的体系结构
实例:共享内存+后台的进程或线程
数据库:存放到磁盘的文件
一般是一个数据库对应一个实例,但是DSC(DM共享集群)是多个实例对应一个数据库
达梦的服务器组成:客户端+服务器(实例+数据库)
客户端不能直接去访问数据库,客户端把请求交给实例,实例去访问数据库,数据库把访问信息返还给实例,实例再交给客户端
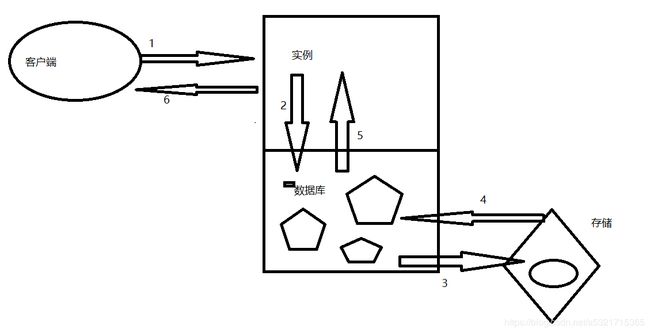
3.1 DM逻辑结构
- 数据库由一个或多个表空间组成
- 每个表空间由一个或多个数据文件组成
- 每个数据文件由一个或多个簇组成
- 页是数据库中最小的分配单位,也是数据库中使用的最小的IO单元
3.2 DM物理存储结构
-
配置文件:dm.ini,dmarch.ini
-
控制文件:dm.ctl,ctl_bak_path,ctl_bak_num
SQL> select para_name,para_value from v$dm_ini where para_name='CTL_BAK_PATH'; 行号 PARA_NAME PARA_VALUE ---------- ------------ ------------------------ 1 CTL_BAK_PATH /dm7/data/DAMENG/ctl_bak SQL> select para_name,para_value from v$dm_ini where para_name='CTL_BAK_NUM'; 行号 PARA_NAME PARA_VALUE ---------- ----------- ---------- 1 CTL_BAK_NUM 10 -
数据文件:数据文件以dbf为扩展名
SQL> select file_name,tablespace_name from dba_data_files; 行号 FILE_NAME TABLESPACE_NAME ---------- --------------------------- --------------- 1 /dm7/data/DAMENG/SYSTEM.DBF SYSTEM 2 /dm7/data/DAMENG/DMHR.DBF DMHR 3 /dm7/data/DAMENG/MAIN.DBF MAIN 4 /dm7/data/DAMENG/TEMP.DBF TEMP 5 /dm7/data/DAMENG/ROLL.DBF ROLL -
重做日志文件:重做日志文件又叫redo日志,主要用于数据库的备份和恢复
-
归档文件:利用归档日志,系统可被恢复至故障发生的前一刻,也可以还原到指定的时间点,如果没有归档日志文件,则只能利用备份进行恢复。
-
逻辑日志文件
-
备份文件:以bak为扩展名的文件
-
日志文件:跟踪日志,事件日志
3.3 DM的内存结构
3.3.1 共享内存
// 总空间查询:0表示不限制
SQL> select para_name,para_value from v$dm_ini where para_name='MEMORY_TARGET'; 行号 PARA_NAME PARA_VALUE ---------- ------------- ---------- 1 MEMORY_TARGET 0// 系统内存池大小(减少系统调用)
SQL> select para_name,para_value from v$dm_ini where para_name='MEMORY_POOL'; 行号 PARA_NAME PARA_VALUE ---------- ----------- ---------- 1 MEMORY_POOL 200
3.3.2 数据缓冲区:buffer

存放的内容:LRU(最小使用算法)链表
状态:free,dirty,clean,pending
如何去设置buffer的大小
// 查看大小 SQL> select para_name,para_value from v$dm_ini where para_name='BUFFER'; 行号 PARA_NAME PARA_VALUE ---------- --------- ---------- 1 BUFFER 100 // 查看最大值 SQL> select para_name,para_value from v$dm_ini where para_name='MAX_BUFFER'; 行号 PARA_NAME PARA_VALUE ---------- ---------- ---------- 1 MAX_BUFFER 100 // 建议: OLTP:BUFFER大小设置为整个物理内存的40-60% OLAP:BUFFER大小设置为整个物理内存的60-80% // 查看参数类型:IN FILE,静态参数 select name,type from v$parameter where name='BUFFER'; 行号 NAME TYPE ---------- ------ ------- 1 BUFFER IN FILE // 修改参数 // 1:修改配置文件和内存;2:只配置文件,需要重启服务后生效 SQL> sp_set_para_value(2,'BUFFER',64); SQL> select para_name,para_value from v$dm_ini where para_name='BUFFER'; 行号 PARA_NAME PARA_VALUE ---------- --------- ---------- 1 BUFFER 64达梦的参数类型
- sys/session:动态参数,要同时修改内存和配置文件
- read only:数据库运行状态下是不能修改的,在mount状态修改
- in file:静态参数,修改配置文件即可,生效需要重启服务
recycle:快速回收池
select para_name,para_value from v$dm_ini where para_name='RECYCLE'; 行号 PARA_NAME PARA_VALUE ---------- --------- ---------- 1 RECYCLE 64keep:保留池
SQL> select para_name,para_value from v$dm_ini where para_name='KEEP'; 行号 PARA_NAME PARA_VALUE ---------- --------- ---------- 1 KEEP 8
3.3.3 字典缓冲区
SQL> select para_name,para_value from v$dm_ini where para_name like '%DICT%';
行号 PARA_NAME PARA_VALUE
---------- ----------------------- ----------
1 DICT_BUF_SIZE 5
2 PLN_DICT_HASH_THRESHOLD 20
// DICT_BUF_SIZE:字典缓冲区的大小
// PLN_DICT_HASH_THRESHOLD:关联登记
当cache_pool_size的值大于等于该值的时候,记录执行计划中关联的数据字典。
3.3.4 sql缓冲区
分析:一条sql的执行过程?Select id,name from abc where id=1;
- 语法分析
- 语义分析(存放数据的数据字典表,产生物理读)
- 权限判断
- 查找数据块是否内存(在内存,逻辑读,不在内存,把数据块从磁盘读到buffer)
- 找是否有可用的执行计划。有的直接按照执行计划把结果展示出来。如果没有,生成执行计划,再把数据展示出来
Sql缓冲区中存放的是:最近使用的sql,DMSQL代码,执行计划和最近查询的结果集,减少硬解析
SQL> select para_name,para_value from v$dm_ini where para_name='CACHE_POOL_SIZE'; 行号 PARA_NAME PARA_VALUE ---------- --------------- ---------- 1 CACHE_POOL_SIZE 20
3.3.5 日志缓冲区
改变数据块信息
update/delete的时候
达梦:每3s写一次或是commit
SQL> select para_name,para_value from v$dm_ini where para_name like '%RLOG%'; 行号 PARA_NAME PARA_VALUE ---------- ------------------------ ---------- 1 CKPT_RLOG_SIZE 100 2 RLOG_CRC 0 3 RLOG_BUF_SIZE 512 4 RLOG_POOL_SIZE 128 5 RLOG_PARALLEL_ENABLE 0 6 RLOG_APPEND_LOGIC 0 7 RLOG_APPEND_SYSTAB_LOGIC 0 8 RLOG_RESERVE_SIZE 40960 9 RLOG_CHECK_SPACE 1 10 RLOG_SAFE_SPACE 128 11 RLOG_SAFE_PERCENT 25 12 RLOG_SEND_APPLY_MON 64 13 RLOG_CRC_IN_RFIL 1 // RLOG_BUF_SIZE:日志缓冲区大小 单位:page 设置成2的幂次方 // RLOG_POOL_SIZE:最大日志缓冲区大小 单位:M
3.3.6 排序区
// 对数据进行排序,如果内存排序无法完成,把部分排序转到磁盘(temp)
SQL> select para_name,para_value from v$dm_ini where para_name like '%SORT%';
行号 PARA_NAME PARA_VALUE
---------- -------------------- ----------
1 SORT_BUF_SIZE 2
2 SORT_BLK_SIZE 1
3 SORT_BUF_GLOBAL_SIZE 1000
4 SORT_FLAG 0
5 SORT_OPT_SIZE 0
6 BASE_SORT_CPU 36000
7 LARGE_SORT_CPU 40000
8 SMALL_SORT_CPU 200
// SORT_BUF_SIZE ---大小,值要结合自身的业务。
3.3.7 HASH区
SQL> select para_name,para_value from v$dm_ini where para_name like '%HJ%';
行号 PARA_NAME PARA_VALUE
---------- ------------------ ----------
1 HJ_BUF_GLOBAL_SIZE 500
2 HJ_BUF_SIZE 50
3 HJ_BLK_SIZE 1
// HJ_BUF_SIZE
3.3.8 重做日志文件的管理
-
查看日志文件
SQL> select path, rlog_size from v$rlogfile; 行号 PATH RLOG_SIZE ---------- ----------------------------- -------------------- 1 /dm7/data/DAMENG/DAMENG01.log 536870912 2 /dm7/data/DAMENG/DAMENG02.log 536870912 3 /dm7/data/DAMENG/DAMENG03.log 536870912 -
增加一个日志文件
SQL> alter database add logfile '/dm7/data/DAMENG/DAMENG04.log' size 512; 操作已执行 SQL> select path, rlog_size from v$rlogfile; 行号 PATH RLOG_SIZE ---------- ----------------------------- -------------------- 1 /dm7/data/DAMENG/DAMENG01.log 536870912 2 /dm7/data/DAMENG/DAMENG02.log 536870912 3 /dm7/data/DAMENG/DAMENG03.log 536870912 4 /dm7/data/DAMENG/DAMENG04.log 536870912 -
修改日志文件的大小
SQL> alter database resize logfile '/dm7/data/DAMNEG/DAMENG04.log' to 1024; -
注:生产环境中建议所有日志文件的大小要一致
4、表空间管理
4.1 达梦表空间介绍
// 达梦表空间有哪些?
SQL> select tablespace_name from dba_tablespaces;
行号 TABLESPACE_NAME
---------- ---------------
1 SYSTEM
2 ROLL
3 TEMP
4 MAIN
5 DMHR
6 HMAIN
// SYSTEM:数据字典和全局的系统数据
// ROLL:存放了数据库运行过程中产生的回滚记录
UNDO_RETENTION: 单位是秒。
sp_set_para_double_value(2,’UNDO_RETENTION’,2400)
// TEMP:临时表空间,临时字段,临时表都默认存放在临时表控件
// MAIN:数据库默认的一个表空间,创建数据对象时,如果不指定存储位置,默认存放到该表空间
// HMAIN:huge表空间
4.2 如何去规划表空间及相关案例
-
案例1:创建一个表空间
SQL> create tablespace tbs1 datafile '/dm7/data/DAMENG/tbs1_01.dbf' size 32; // 表空间初始文件大小是页大小的4096倍 -
案例2:创建一个表空间,初始大小是50M,最大100M
SQL> create tablespace tbs2 datafile '/dm7/data/DAMENG/tbs2_01.dbf' size 50 autoextend on maxsize 100; -
案例3:创建一个表空间,初始值50M,每次扩展1M,最大100M
SQL> create tablespace tbs3 datafile '/dm7/data/DAMENG/tbs3_01.dbf' size 50 autoextend on next 1 maxsize 100; -
案例4:创建一个表空间,初始50M,表空间由2个数据文件组成,分别存储到不同的磁盘上,每次扩展1M,每个数据文件最大100M
SQL> create tablespace tbs4 datafile '/dm7/data/DAMENG/tbs4_01.dbf' size 50 autoextend on next 1 maxsize 100, '/dm7/data/tbs4_02.dbf' size 50 autoextend on next 1 maxsize 100;
4.3 维护表空间
表空间不足的时候,如何去维护表空间
创建大表空间,数据导出,导入
resize数据文件大小
增加数据文件
SQL> alter tablespace tbs2 add datafile '/dm7/data/DAMENG/tbs2_02.dbf' size 50 autoextend on maxsize 100; // 查看表空间 SQL> select file_name,tablespace_name from dba_data_files; 行号 FILE_NAME TABLESPACE_NAME ---------- ---------------------------- --------------- 1 /dm7/data/DAMENG/SYSTEM.DBF SYSTEM 2 /dm7/data/tbs4_02.dbf TBS4 3 /dm7/data/DAMENG/tbs4_01.dbf TBS4 4 /dm7/data/DAMENG/tbs3_01.dbf TBS3 5 /dm7/data/DAMENG/tbs2_02.dbf TBS2 6 /dm7/data/DAMENG/tbs2_01.dbf TBS2 7 /dm7/data/DAMENG/tbs1_01.dbf TBS1 8 /dm7/data/DAMENG/DMHR.DBF DMHR 9 /dm7/data/DAMENG/MAIN.DBF MAIN 10 /dm7/data/DAMENG/TEMP.DBF TEMP 11 /dm7/data/DAMENG/ROLL.DBF ROLL更换存储位置:
// 达梦的表空间状态:0-online;1-offline // 注意:SYSTEM,ROLL,TEMP不能是offline SQL> select TABLESPACE_NAME,STATUS from dba_tablespaces; 行号 TABLESPACE_NAME STATUS ---------- --------------- ----------- 1 SYSTEM 0 2 ROLL 0 3 TEMP 0 4 MAIN 0 5 DMHR 0 6 TBS1 0 7 TBS2 0 8 TBS3 0 9 TBS4 0 10 HMAIN NULL // 更改TBS1的存储位置 a.表空间offline SQL> alter tablespace tbs1 offline; b.修改存储位置 SQL> alter tablespace tbs1 rename datafile '/dm7/data/DAMENG/tbs1_01.dbf' to '/dm7/data/tbs1_01.dbf'; c.表空间online SQL> alter tablespace tbs1 online;
4.4 删除表空间
SQL> drop tablespace tbs2;
// 如果表空间存在数据,不允许直接删除
5、用户管理
5.1 达梦数据库有哪些用户
SQL> select username from dba_users;
行号 USERNAME
---------- ----------
1 SYSSSO
2 DMHR
3 SYSDBA
4 SYS
5 SYSAUDITOR
// SYS:达梦数据库内置管理员用户,不能登录数据库,数据库使用的大部分的数据字典和动态性能视图sys
// SYSDBA:数据库的管理员
// SYSAUDITOR:审计用户
// SYSSSO:安全用户
// SYSDBO:数据操作员(安全版才存在)
// 如何规划用户?
名字:字母开头,a-z,0-9,$#_
位置:表空间的位置
5.2 口令策略
用户密码最长为48个字节,创建用户时使用password policy字句来指定口令策略。dm.ini中有PWD_POLICY
系统的口令策略:
- 0:无策略
- 1:禁止与用户名相同
- 2:口令长度不小于9
- 4:至少包含一个大写字母(A-Z)
- 8:至少包含一个数字(0-9)
- 16:至少包含一个标点符号(英文状态下输入,除’'和空格)
口令策略可以单独使用,也可以组合使用,比如:需要应用策略4和8,那么设置口令策略为4+8=12
// 查看数据库密码策略 SQL> select para_name,para_value from v$dm_ini where para_name='PWD_POLICY'; 行号 PARA_NAME PARA_VALUE ---------- ---------- ---------- 1 PWD_POLICY 2 // 密码策略设置为6 SQL> sp_set_para_value(1,'PWD_POLICY',6); DMSQL 过程已成功完成 已用时间: 10.577(毫秒). 执行号:43. // 再次查看数据库密码策略 SQL> select para_name,para_value from v$dm_ini where para_name='PWD_POLICY'; 行号 PARA_NAME PARA_VALUE ---------- ---------- ---------- 1 PWD_POLICY 6密码尝试登录次数:FAILED_LOGIN_ATTEMPS
密码锁定时间:PASSWORD_LOCK_TIME
密码过期时间:PASSWORD_LIFE_TIME
SQL> select b.username, a.failed_num, a.failed_attemps from sysusers a right join all_users b on a.id=b.user_id; 行号 USERNAME FAILED_NUM FAILED_ATTEMPS ---------- ---------- ----------- -------------- 1 SYSDBA 0 0 2 SYS 0 0 3 SYSAUDITOR 0 0 4 SYSSSO 0 0 5 DMHR 3 0
5.3 策略案例分析
-
案例1:
为数据库设置一个用户,该账户可以创建自己的表,有属于自己的独立表空间,用户的密码要求每60天变更一次
// 创建一个表空间 SQL> create tablespace test datafile '/dm7/data/DAMENG/test01.dbf' size 32; // 创建用户,指定密码,表空间和密码过期时间 SQL> create user test identified by Dameng123 limit password_life_time 60 default tablespace test; // 校验是否创建成功 [dmdba@localhost ~]$ disql test/Dameng123 SQL> select user; 行号 USER() ---------- ------ 1 TEST // 根据下面的知识,创建用户默认是public角色,没有创建表权限,这里需要给用户赋予此权限 SQL> grant create table to test;
5.4 规划用户权限
系统权限:create drop alter 能够对数据库做什么操作。
对象权限: (表,视图,过程等等)select ,delete,update,insert
5.5 案例分析
-
案例1:
// 查看角色 SQL> select role from dba_roles; 行号 ROLE ---------- ---------------- 1 DBA 2 DB_AUDIT_ADMIN 3 DB_AUDIT_OPER 4 DB_AUDIT_PUBLIC 5 DB_POLICY_ADMIN 6 DB_POLICY_OPER 7 DB_POLICY_PUBLIC 8 PUBLIC 9 RESOURCE 10 SYS_ADMIN // 查看用户角色 SQL> select grantee,granted_role from dba_role_privs where grantee='TEST'; 行号 GRANTEE GRANTED_ROLE ---------- ------- ------------ 1 TEST PUBLIC // 查看角色权限 SQL> select grantee,privilege from dba_sys_privs where grantee='PUBLIC'; 行号 GRANTEE PRIVILEGE ---------- ------- ---------------- 1 PUBLIC INSERT TABLE 2 PUBLIC UPDATE TABLE 3 PUBLIC DELETE TABLE 4 PUBLIC SELECT TABLE 5 PUBLIC REFERENCES TABLE 6 PUBLIC GRANT TABLE 7 PUBLIC INSERT VIEW 8 PUBLIC UPDATE VIEW 9 PUBLIC DELETE VIEW 10 PUBLIC SELECT VIEW 11 PUBLIC GRANT VIEW 12 PUBLIC EXECUTE PROCEDURE 13 PUBLIC GRANT PROCEDURE 14 PUBLIC SELECT SEQUENCE 15 PUBLIC GRANT SEQUENCE 16 PUBLIC EXECUTE PACKAGE 17 PUBLIC GRANT PACKAGE 18 PUBLIC SELECT ANY DICTIONARY 19 PUBLIC SELECT MATERIALIZED VIEW 20 PUBLIC GRANT DOMAIN 21 PUBLIC USAGE DOMAIN 22 PUBLIC DUMP TABLE -
案例2:
规划一个账号每60天变更一次密码,密码尝试连接2次失败,账号锁定5分钟,用户还可以查询dmhr.employee表
// 创建用户 SQL> create user test1 identified by Test12345 limit password_life_time 60,failed_login_attemps 2,password_lock_time 5; // 解锁用户 SQL> alter user test1 account unlock; // 赋予权限 SQL> grant select on dmhr.employee to test1;注:一般情况,创建完用户,给resource角色,就基本上可以满足需求。具体需要根据生产环境的来。
-
案例3:
企业招聘一个录入信息人员,权限是固定的,只能录入city表。
角色:一类权限的集合。把某些特定的权限给一个固定的角色,然后再把角色给用户
// 创建角色 SQL> create role r1; // 赋予权限给角色 SQL> grant insert on dmhr.city to r1; // 创建用户 SQL> create user test2 identified by Dameng123; // 赋予角色给用户 SQL> grant r1 to test2; SQL> desc dmhr.city; 行号 NAME TYPE$ NULLABLE ---------- --------- ----------- -------- 1 CITY_ID CHAR(3) N 2 CITY_NAME VARCHAR(40) Y 3 REGION_ID INTEGER Y // 使用创建的用户登录 SQL> conn test2/Dameng123; // 测试插入语句(由于这里存在外键约束,所以数据无法插入成功,不过权限已经赋予了) SQL> insert into dmhr.city(city_id,city_name,region_id) values ('WX','无锡',8);
5.6 用户维护
// 删除权限
SQL> revoke insert on dmhr.ctiy form r1;
// 修改密码
SQL> alter user test2 identified by Dameng12345;
// 锁定/解锁账户
SQL> alter user test2 account lock/unlock;
// 删除账号
SQL> drop user test2;
// 删除账号(用户下有创建表),慎用!删除前记得做备份
SQL> drop user test2 cascade;
// 删除角色
SQL> drop role r1;
6、DMSQL(SELECT)
SQL:结构化查询语句
- DDL:定义语句 create、drop、alter、truncate
- DML:管理语句 select、update、delete,insert
- DCL:控制语句 grant、revoke
- TCL:事务控制 commit、rollback
6.1 简单查询
// 语法:select () from ()
// 第一个括号:*,column_name,alias,expr,||,distinct
// 第二个括号:table_name
SQL> select * from dmhr.city;
SQL> select city_id,city_name from dmhr.city;
SQL> select employee_name,salary as tol from dmhr.employee limit 10;
SQL> select employee_name,salary+1000 from dmhr.employee limit 10;
SQL> select employee_name||'的工资是:'||salary as desc1 from dmhr.employee limit 2;
行号 DESC1
---------- -----------------------------
1 马学铭的工资是:30000
2 程擎武的工资是:9000
SQL> select distinct department_id from dmhr.employee;
6.2 过滤查询
// 语法:select () from () where ();
// 第一个括号:*, column_name,alias, expr,||, distinct
// 第二个括号:table_name
// 第三个括号:过滤条件
// 比较查询:=,!=,>,>=,<,<=
SQL> select employee_name,salary from dmhr.employee where salary >= 25000;
行号 EMPLOYEE_NAME SALARY
---------- ------------- -----------
1 马学铭 30000
2 苏国华 30000
3 郑晓同 30000
// 逻辑运算:and,or
SQL> select employee_name,salary from dmhr.employee where employee_name='马学铭';
行号 EMPLOYEE_NAME SALARY
---------- ------------- -----------
1 马学铭 30000
SQL> select employee_name,salary from dmhr.employee where employee_name='马学铭' or employee_name='苏国华';
行号 EMPLOYEE_NAME SALARY
---------- ------------- -----------
1 马学铭 30000
2 苏国华 30000
// 模糊查询:like %匹配0个或多个字符;_匹配1个字符
SQL> select employee_name,salary from dmhr.employee where employee_name like '王%' limit 2;
行号 EMPLOYEE_NAME SALARY
---------- ------------- -----------
1 王岳荪 5000
2 王金玉 3133
SQL> select employee_name,salary from dmhr.employee where employee_name like '王_' limit 2;
行号 EMPLOYEE_NAME SALARY
---------- ------------- -----------
1 王辉 9685
2 王欣 9755
// is null,is not null
SQL> select employee_name,commission_pct from dmhr.employee where commission_pct is not null limit 2;
行号 EMPLOYEE_NAME COMMISSION_PCT
---------- ------------- --------------
1 马学铭 0
2 程擎武 0
// in 枚举
SQL> select employee_name,salary from dmhr.employee where employee_name in ('陈仙','郑吉群','马学铭','程擎武');
行号 EMPLOYEE_NAME SALARY
---------- ------------- -----------
1 马学铭 30000
2 程擎武 9000
3 郑吉群 15000
4 陈仙 12000
// between...and
SQL> select employee_name,salary from dmhr.employee where salary between 20000 and 30000;
行号 EMPLOYEE_NAME SALARY
---------- ------------- -----------
1 马学铭 30000
2 苏国华 30000
3 郑晓同 30000
// 排序
SQL> select employee_name,salary from dmhr.employee order by salary desc;
6.3 多表查询
// 语法:select () from () join() on ().
// 第三个括号:表名
// 第四个括号:关联字段
// 内连接 自然连接
SQL> select e.employee_name,d.department_name from dmhr.employee e natural join dmhr.department d limit 2;
行号 EMPLOYEE_NAME DEPARTMENT_NAME
---------- ------------- ---------------
1 马学铭 总经理办
2 林子程 技术支持部
SQL> select e.employee_name,d.department_name from dmhr.employee e join dmhr.department d using(department_id) limit 2;
行号 EMPLOYEE_NAME DEPARTMENT_NAME
---------- ------------- ---------------
1 马学铭 总经理办
2 程擎武 行政部
SQL> select e.employee_name,d.department_name from dmhr.employee e join dmhr.department d on e.department_id=d.department_id limit 2;
行号 EMPLOYEE_NAME DEPARTMENT_NAME
---------- ------------- ---------------
1 马学铭 总经理办
2 程擎武 行政部
6.4 外连接
// 外连接-左外连接:把写在left join左边的全部显示,右边的只显示满足条件的,不满足条件的用Null代替。
SQL> select e.employee_name,d.department_name from dmhr.employee e left join dmhr.department d on e.department_id=d.department_id limit 2;
行号 EMPLOYEE_NAME DEPARTMENT_NAME
---------- ------------- ---------------
1 马学铭 总经理办
2 程擎武 行政部
// 外连接-右外连接:把写在right join右边的全部显示,左边的只显示满足条件的,不满足条件的用Null代替。
SQL> select e.employee_name,d.department_name from dmhr.employee e right join dmhr.department d on e.department_id=d.department_id limit 2;
行号 EMPLOYEE_NAME DEPARTMENT_NAME
---------- ------------- ---------------
1 马学铭 总经理办
2 陈辰 总经理办
// 外连接-全外连接
SQL> select e.employee_name,d.department_name from dmhr.employee e full join dmhr.department d on e.department_id=d.department_id limit 2;
行号 EMPLOYEE_NAME DEPARTMENT_NAME
---------- ------------- ---------------
1 马学铭 总经理办
2 程擎武 行政部
6.5 分组查询
// 语法:select 聚合函数 () from () group by () having();
// 聚合函数:sum,avg,max,min,count
// 算出各个部门的平均工资
SQL> select avg(salary),department_id from dmhr.employee group by department_id having avg(salary)>=16000;
行号 AVG(SALARY) DEPARTMENT_ID
---------- ------------ -------------
1 16589.500000 303
2 19252.841270 703
// 算出各个部门的工资和,找出部门工资和大于500000的部门。
SQL> select department_id,sum(salary) from dmhr.employee group by department_id having sum(salary)>500000;
行号 DEPARTMENT_ID SUM(SALARY)
---------- ------------- --------------------
1 703 2425858
2 705 564024
// 注:having是分组后的数据进行过虑,不能单独使用,having前面一定是有group by。
// 注:在select后出现的列,都要出现在group by后,聚合函数列不算。
6.6 子查询
// 子查询的结果是主查询的条件,子查询先于主查询运行。
// a.返回值是唯一的。
// 语法:select () from () where () = ()
// 找出和马学铭同一个部门的人员
SQL> select employee_name,department_id from dmhr.employee where department_id=(select department_id from dmhr.employee where employee_name='马学铭');
行号 EMPLOYEE_NAME DEPARTMENT_ID
---------- ------------- -------------
1 马学铭 101
2 陈辰 101
3 杨毓 101
4 严云飞 101
5 郑旭明 101
// b.返回值是多行的
// 语法:select () from () where () >/< any/all ();
// 找出比1002部门所有人员工资都高的人
select employee_name,department_id,salary from dmhr.employee where salary >all(select salary from dmhr.employee where department_id=1002);
7、表、视图、索引
7.1 模式
模式:一组数据对象的集合,在创建用户的时候,就会生成一个跟用户同名的模式
7.2 表
达梦支持的表:默认的表(索引组织表),堆表,临时表,分区表,外部表等
如何规划表?
–命名:字符开头a-z,0-9,$#_
–数据类型:int,char,varchar,date,clob,blob,number等
–存储位置:自己规划的表空间,未指定则是默认空间
–约束:非空,唯一,主键,检查,外键
–注释:comment
-
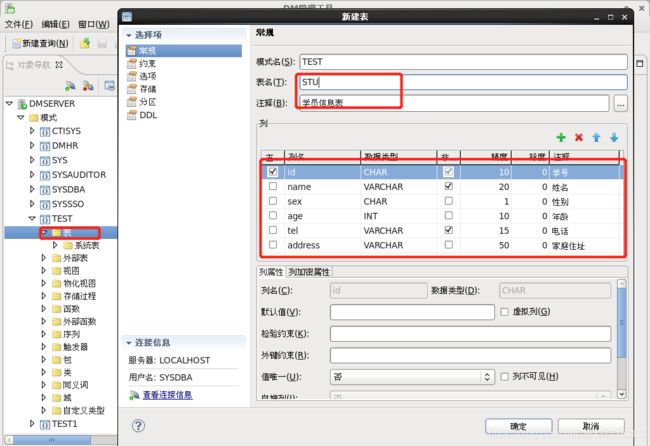
案例1:规划一张学员信息表
表名:STU
列:学号(id,char(10)),姓名(name,varchar(20)),性别(sex,char(1)),
年龄(age,int),电话(tel,varchar(15)),家庭住址(address,varchar(50))
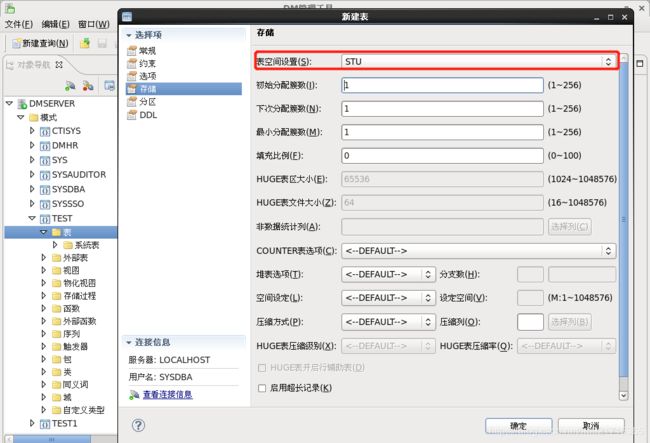
表空间:STU
约束:主键–学号,非空–姓名,电话
备注:学员信息表

// 创建的SQL
create table "TEST"."STU"
(
"id" CHAR(10) not null ,
"name" VARCHAR(20) not null ,
"sex" CHAR(1),
"age" INT unique ,
"tel" VARCHAR(15) not null ,
"address" VARCHAR(50),
primary key("id")
)
storage(initial 1, next 1, minextents 1, fillfactor 0, on "STU")
;
comment on table "TEST"."STU" is '学员信息表';
comment on column "TEST"."STU"."id" is '学号';
comment on column "TEST"."STU"."name" is '姓名';
comment on column "TEST"."STU"."sex" is '性别';
comment on column "TEST"."STU"."age" is '年龄';
comment on column "TEST"."STU"."tel" is '电话';
comment on column "TEST"."STU"."address" is '家庭住址';
// 查看表结构
SQL> desc test.stu;
行号 NAME TYPE$ NULLABLE
---------- ------- ----------- --------
1 id CHAR(10) N
2 name VARCHAR(20) N
3 sex CHAR(1) Y
4 age INTEGER Y
5 tel VARCHAR(15) N
6 address VARCHAR(50) Y
SQL> sp_tabledef('TEST','STU'); #区分大小写
行号 COLUMN_VALUE
---------- ---------------------------------------------------------------------------------------------------------------------------------------------
1 CREATE TABLE "TEST"."STU" ( "id" CHAR(10) NOT NULL, "name" VARCHAR(20) NOT NULL, "sex" CHAR(1), "age" INT, "tel" VARCHAR(15) NOT NULL, "address" VARCHAR(50), CLUSTER PRIMARY KEY("id"), UNIQUE("age")) STORAGE(ON "STU", CLUSTERBTR) ;
SQL> select dbms_metadata.get_ddl('TABLE','STU','TEST');
行号 DBMS_METADATA.GET_DDL('TABLE','STU','TEST')
---------- ---------------------------------------------------------------------------------------------------------------------------------------------
1 CREATE TABLE "TEST"."STU"
(
"id" CHAR(10) NOT NULL,
"name" VARCHAR(20) NOT NULL,
"sex" CHAR(1),
"age" INT,
"tel" VARCHAR(15) NOT NULL,
"address" VARCHAR(50),
CLUSTER PRIMARY KEY("id"),
UNIQUE("age")) STORAGE(ON "STU", CLUSTERBTR) ;
// 如何查看表在哪个表空间
SQL> select table_name,tablespace_name from dba_tables where table_name='STU';
行号 TABLE_NAME TABLESPACE_NAME
---------- ---------- ---------------
1 STU STU
// 如何查看表有哪些约束
SQL> select table_name,constraint_name,constraint_type from dba_constraints where table_name='STU';
行号 TABLE_NAME CONSTRAINT_NAME CONSTRAINT_TYPE
---------- ---------- --------------- ---------------
1 STU CONS134218775 P
2 STU CONS134218774 U
-
案例2:创建表的时候指定约束
SQL> create table test.t2(id int); SQL> alter table test.t2 modify id int not null; // 上面两条语句等价于 SQL> create table test.t3(id int not null); // 唯一约束 SQL> create table test.t4(id int unique); // 主键约束 SQL> create table test.t5(id int primary key); SQL> create table test.t6(id int); SQL> alter table test.t6 add constraint t6_pri primary key(id); // 检查约束 SQL> create table test.t8(id int); SQL> alter table test.t8 add constraint t9_check check(id>=5); SQL> create table test.t7(id int check(id>=5)); // 外键约束 SQL> create table test.t9(sid int primary key,pid int); SQL> create table test.t10(id int primary key, sid int foreign key references test.t9(sid)); // 增加备注 SQL> comment on column test.t2.id is '编号'; -
如何导入数据
- start语句
[dmdba@localhost ~]$ pwd /home/dmdba [dmdba@localhost ~]$ cat q.sql insert into test.t2 values(1); insert into test.t2 values(2); insert into test.t2 values(3); [dmdba@localhost ~]$ disql sysdba/dameng123 SQL> start /home/dmdba/q.sql SQL> insert into test.t2 values(1); SQL> select * from test.t2; 行号 ID ---------- ----------- 1 1 2 2 3 3- bin/dts工具
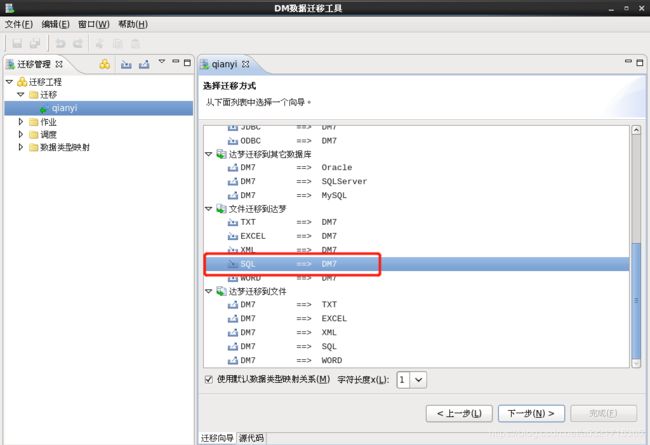
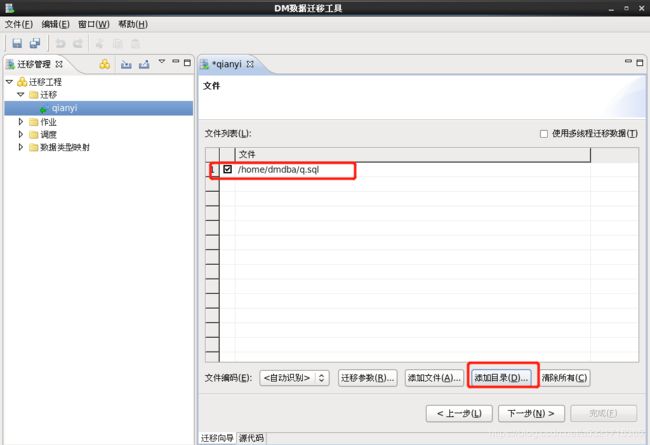


-
如何去维护表
// 增加/删除列 SQL> alter table test.t2 add name varchar(20) default 'eason'; SQL> alter table test.t2 drop name; // 启用和禁用约束: SQL> alter table test.t9 disable constraint CONS134218782; SQL> alter table test.t9 enable constraint CONS134218782; // 删除表 SQL> drop table test.t2
7.3 视图
分类:简单视图、复杂视图、物化视图
注:简单视图和复杂视图不占用磁盘空间
-
创建视图
SQL> create view v1 as select * from dmhr.employee; SQL> select * from v1 limit 2; 行号 EMPLOYEE_NAME JOB_ID ---------- ------------- ------ 1 马学铭 11 2 程擎武 21 -
查看视图
SQL> select view_name,text from dba_views where view_name='V1'; 行号 VIEW_NAME TEXT ---------- --------- ----------------------------------------------- 1 V1 SELECT EMPLOYEE_NAME,JOB_ID FROM DMHR.EMPLOYEE -
修改视图
SQL> create or replace view v1 as select employee_name from dmhr.employee; SQL> select view_name,text from dba_views where view_name='V1'; 行号 VIEW_NAME TEXT ---------- --------- ---------------------------------------- 1 V1 SELECT EMPLOYEE_NAME FROM DMHR.EMPLOYEE -
删除视图
SQL> drop view v1;
7.4 序列
-
创建序列
SQL> create sequence s1 2 start with 1 3 increment by 1 4 maxvalue 10 5 nocache 6 nocycle; -
序列的应用
SQL> create table test.t11(id int primary key); SQL> insert into test.t11 values(s1.nextval); SQL> insert into test.t11 values(s1.nextval); SQL> select * from test.t11; 行号 ID ---------- ----------- 1 1 2 2
7.5 同义词
表或视图的别名,分为普通同义词(相当于私用同义词)和公共同义词(所有用户都可以使用,只有sysdba可以创建)
-
创建同义词
// 公共同义词 SQL> create public synonym ss1 for dmhr.employee; // 普通同义词 SQL> create synonym ss2 for dmhr.employee; -
修改同义词
SQL> create or replace synonym ss2 for dmhr.employee; -
删除同义词
SQL> drop public synonym ss1; SQL> drop synonym ss2;
7.6 索引
达梦的分类:二级索引,唯一索引,复合索引,函数索引,分区索引等
默认的表是索引组织表,利用rowid创建一个默认的索引,所以我们创建的索引是二级索引
-
查看索引
SQL> select table_name,index_name from dba_indexes where table_name='T11'; 行号 TABLE_NAME INDEX_NAME ---------- ---------- ------------- 1 T11 INDEX33555483 -
索引的作用
加快表的查询,对数据库做DML操作的时候,数据库会自动维护索引。索引是一棵倒置的树,使用索引,就是对这个索引树进行遍历。 建立索引的规则: 1、经常查询的列 2、连接条件列 3、谓词经常出现的列(where) 4、查询是返回表的一小部分数据 不适合创建索引的情况: 1、列上有大量的null 2、列上的数据有限(例如:性别) -
创建索引
// 1.规划索引表空间 // 2.表的数据是无须的,索引的数据是有序的 案例:复制dmhr.employee为emp,给employee_id建立所以 // 建立表 SQL> create table test.emp as select * from dmhr.employee; // 建立表空间 SQL> create tablespace indx datafile '/dm7/data/DAMENG/indx01.dbf' size 32; // 建立索引 SQL> create index ind_mep on test.emp(employee_id) tablespace indx; -
查询索引
SQL> select table_name,index_name from dba_indexes where table_name='EMP'; 行号 TABLE_NAME INDEX_NAME ---------- ---------- ------------- 1 EMP INDEX33555484 2 EMP IND_MEP -
维护索引
// 重建索引 SQL> alter index ind_emp rebuild; // 删除索引 SQL> drop index ind_emp;
8、备份、还原
8.1 备份
备份分类:物理备份、逻辑备份
物理备份:
冷备:dmap服务打开的状态下,数据库是关闭的
热备:dmap服务一定是打开的,数据库是打开的,数据库要开归档
逻辑备份:
导入导出:dexp、dimp
集群:数据守护(dw)、DSC(RAC)
达梦支持的第三方备份软件:爱数、鼎甲
- 数据库开归档:
命令方式开归档:
// mount状态
SQL> alter database mount;
// 设置归档路径
SQL> alter database add archivelog 'type=local,dest=/dm7/arch,file_size=64,space_limit=0';
// 开归档
SQL> alter database archivelog;
// open状态
SQL> alter database open;
// 查询数据库状态
SQL> select name,status$,arch_mode from v$database;
行号 NAME STATUS$ ARCH_MODE
---------- ------ ----------- ---------
1 DAMENG 4 Y
// 查询归档参数
select * from v$dm_arch_ini;
- 图形工具开归档:
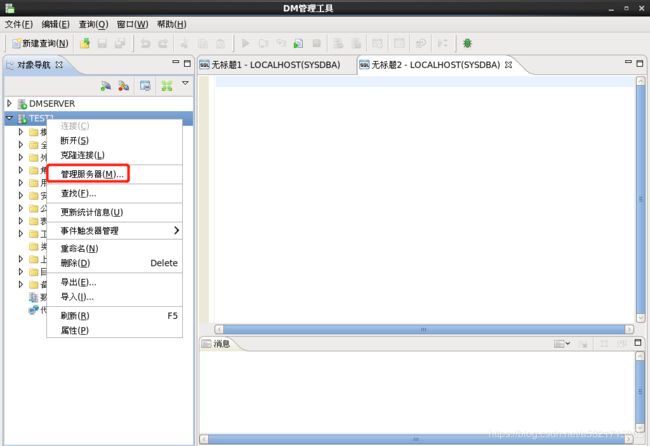

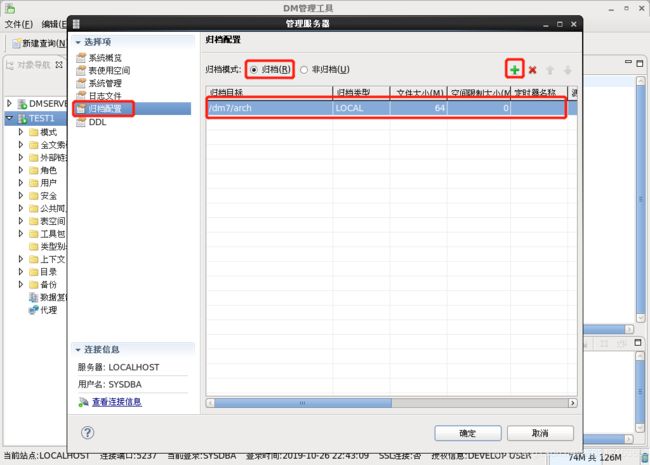

- 通过bin/dmrman去做备份(冷备):dmap服务需要开启,数据库实例关闭
[dmdba@localhost dm7]$ cd /dm7/bin
[dmdba@localhost bin]$ ./dmrman
dmrman V7.6.0.197-Build(2019.09.12-112648)ENT
RMAN> backup database '/dm7/data/DAMENG/dm.ini'
backup database '/dm7/data/DAMENG/dm.ini'
file dm.key not found, use default license!
checking if the database under system path [/dm7/data/DAMENG] is running...[4].
checking if the database under system path [/dm7/data/DAMENG] is running...[3].
checking if the database under system path [/dm7/data/DAMENG] is running...[2].
checking if the database under system path [/dm7/data/DAMENG] is running...[1].
checking if the database under system path [/dm7/data/DAMENG] is running...[0].
checking if the database under system path [/dm7/data/DAMENG] is running, write dmrman info.
EP[0] max_lsn: 64171
BACKUP DATABASE [DAMENG],execute......
CMD CHECK LSN......
BACKUP DATABASE [DAMENG],collect dbf......
CMD CHECK ......
DBF BACKUP SUBS......
total 1 packages processed...
total 3 packages processed...
total 4 packages processed...
total 5 packages processed...
total 6 packages processed...
total 7 packages processed...
total 8 packages processed...
total 9 packages processed...
total 10 packages processed...
total 11 packages processed...
total 12 packages processed...
DBF BACKUP MAIN......
BACKUPSET [/dm7/data/DAMENG/bak/DB_DAMENG_FULL_20191026_230952_000918] END, CODE [0]......
META GENERATING......
total 13 packages processed...
total 13 packages processed!
CMD END.CODE:[0]
backup successfully!
time used: 8082.198(ms)
- 命令行方式下全备、增备(热备)::dmap服务需要开启,数据库实例开启
[dmdba@localhost bin]$ cd /dm7/
[dmdba@localhost dm7]$ mkdir backup
[dmdba@localhost bin]$ disql SYSDBA/dameng123
// 完全备份
SQL> backup database full backupset '/dm7/backup/full_bak';
// 增量备份:是基于完全备份的,如果没有变化,则取消备份
SQL> backup database increment backupset '/dm7/backup/incr_bak';
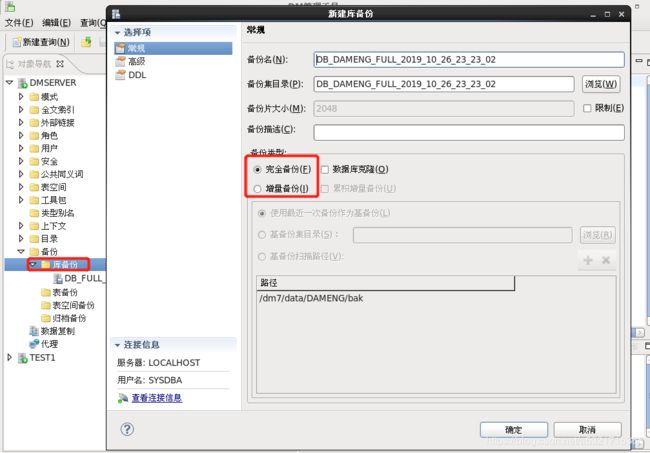
- 利用管理工具进行备份(热备)
备份库右击指定工作目录,新增/dm7/backup可以把上面用命令做的备份显示出来
-
注意事项
备份的数据库和表空间,如果做还原,是还原到当前时刻;如果备份的表做还原,还原到表的备份时刻。
system表空间和roll表空间损坏,要重新初始化数据库实例,再用备份去还原
备份表空间:
backup tablespace dmhr backupset ‘/dm7/backup/dmhr_bak’;
备份表:backup table dmhr.employee backupset ‘/dm7/backup/dmhr_bak’;
8.2 还原
SQL> restore tablespace tbs2 from backupset '/dm7/backup/full_bak/';
SQL> alter tablespace tbs2 online;
9、作业操作
定期去执行任务
例如:定期做备份、定期收集统计信息等
9.1 配置作业


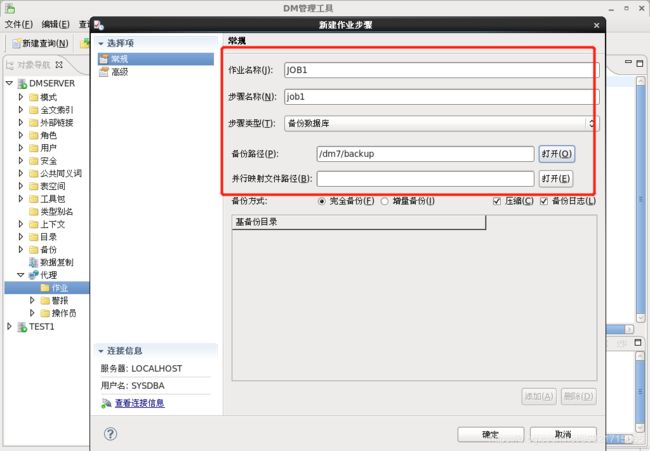
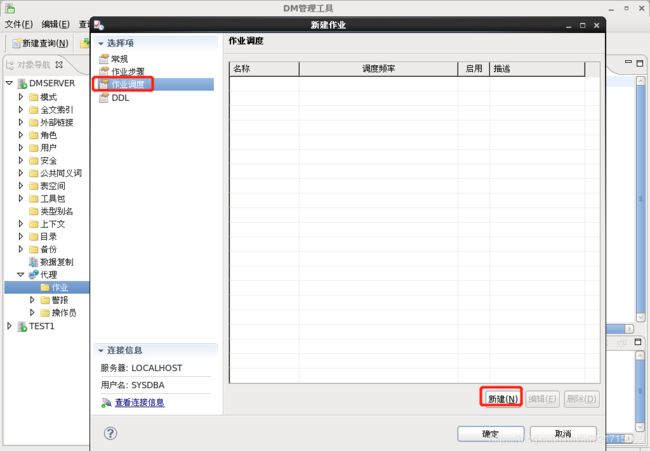

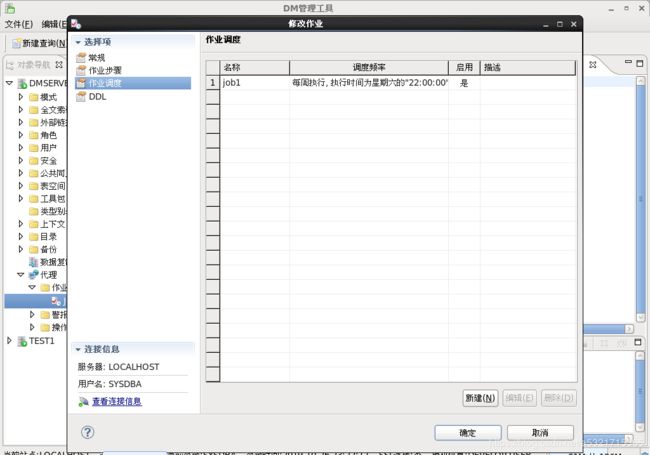
9.2 查看作业
// 作业的基本情况
SQL> select * from sysjob.sysjobs;
// 历史执行情况
SQL> select * from sysjob.sysjobhistories;
// 调度情况
SQL> select * from sysjob.sysjobschedules;
// 步骤情况
SQL> select * from sysjob.sysjobsteps;
10、存储过程和触发器
10.1 存储过程
// 写匿名块
// declare (可选项)
// begin
// body;
// exception
// end;
SQL> set serveroutput on
SQL> begin
2 print('hello world');
3 end;
4 /
hello world
SQL> begin
2 for i in 1..5 loop
3 print(i);
4 end loop;
5 end;
6 /
1
2
3
4
5
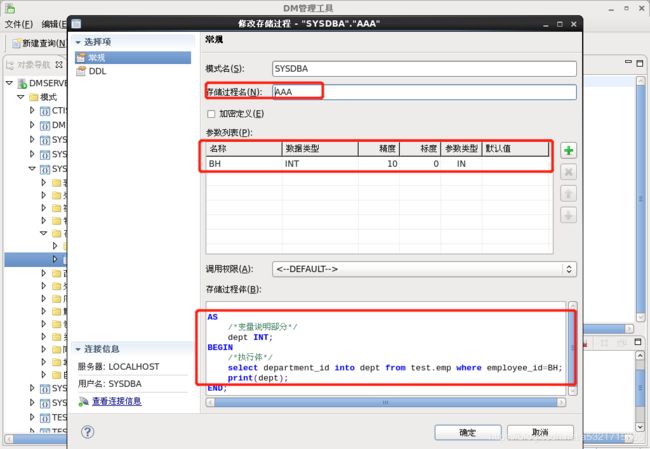
// 实例:根据员工的编号找出员工的所在部门
CREATE OR REPLACE PROCEDURE "SYSDBA"."AAA"("BH" IN INT)
AS
/*变量说明部分*/
dept INT;
BEGIN
/*执行体*/
select department_id into dept from test.emp where employee_id=BH;
print(dept);
END;
// 调用存储过程
SQL> call AAA(1001);
101
10.2 触发器
分类:表级别、库级别、模式级别、视图级别
库级别触发器:对数据库做drop操作的时候记录操作时间/用户
// 案例:员工表工资发生改动,记录改动前和改动后的值
create trigger "SYSDBA"."EEE"
before UPDATE of "SALARY"
on "SYSDBA"."EMP"
for each row
BEGIN
insert into TAB1 values(:old.salary,:new.salary);
END;